阿里PB级Kubernetes日志平台建设实践
阿里PB级Kubernetes日志平台建设实践
QCon是由InfoQ主办的综合性技术盛会,每年在伦敦、北京、纽约、圣保罗、上海、旧金山召开。有幸参加这次QCon10周年大会,作为分享嘉宾在刘宇老师的运维专场发表了《阿里PB级Kubernetes日志平台建设实践》,现将PPT和文字稿整理下来,希望和更多的爱好者分享。
计算形态的发展与日志系统的演进

在阿里的十多年中,日志系统伴随着计算形态的发展在不断演进,大致分为3个主要阶段:

- 在单机时代,几乎所有的应用都是单机部署,当服务压力增大时,只能切换更高规格的IBM小型机。日志作为应用系统的一部分,主要用作程序Debug,通常结合grep等Linux常见的文本命令进行分析。
- 随着单机系统成为制约阿里业务发展的瓶颈,为了真正的Scale out,飞天项目启动:2009年开始了飞天的第一行代码,2013年飞天5K项目正式上线。在这个阶段各个业务开始了分布式改造,服务之间的调用也从本地变为分布式,为了更好的管理、调试、分析分布式应用,我们开发了Trace(分布式链路追踪)系统、各式各样的监控系统,这些系统的统一特点是将所有的日志(包括Metric等)进行集中化的存储。
- 为了支持更快的开发、迭代效率,近年来我们开始了容器化改造,并开始了拥抱Kubernetes生态、业务全量上云、Serverless等工作。要实现这些改造,一个非常重要的部分是可观察性的工作,而日志是作为分析系统运行过程的最佳方式。在这阶段,日志无论从规模、种类都呈现爆炸式的增长,对日志进行数字化、智能化分析的需求也越来越高,因此统一的日志平台应运而生。
日志平台的重要性与建设目标

日志不仅仅是服务器、容器、应用的Debug日志,也包括各类访问日志、中间件日志、用户点击、IoT/移动端日志、数据库Binlog等等。这些日志随着时效性的不同而应用在不同的场景:
- 准实时级别:这类日志主要用于准实时(秒级延迟)的线上监控、日志查看、运维数据支撑、问题诊断等场景,最近两年也出现了准实时的业务洞察,也是基于这类准实时的日志实现。
- 小时/天级别:当数据积累到小时/天级别的时候,这时一些T+1的分析工作就可以开始了,例如用户留存分析、广告投放效果分析、反欺诈、运营监测、用户行为分析等。
- 季度/年级别:在阿里,数据是我们最重要的资产,因此非常多的日志都是保存一年以上或永久保存,这类日志主要用于归档、审计、攻击溯源、业务走势分析、数据挖掘等。
在阿里,几乎所有的业务角色都会涉及到各式各样的日志数据,为了支撑各类应用场景,我们开发了非常多的工具和功能:日志实时分析、链路追踪、监控、数据清洗、流计算、离线计算、BI系统、审计系统等等。其中很多系统都非常成熟,日志平台主要专注于智能分析、监控等实时的场景,其他功能通常打通的形式支持。
阿里日志平台现状

目前阿里的日志平台覆盖几乎所有的产品线和产品,同时我们的产品也在云上对外提供服务,已经服务了上万家的企业。每天写入流量16PB以上,对应日志行数40万亿+条,采集客户端200万,服务数千Kubernetes集群,是国内最大的日志平台之一。
为何选择自建
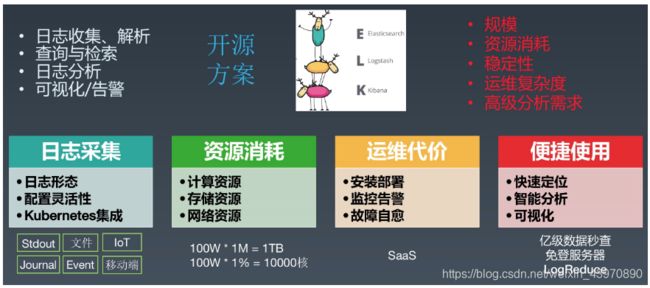
日志系统存在了十多年,目前也有非常多的开源的方案,例如最典型的ELK(Elastic Search、Logstash、Kibana),通常一个日志系统具备以下功能:日志收集/解析、查询与检索、日志分析、可视化/告警等,这些功能通过开源软件的组合都可以实现,但最终我们选择自建,主要有几下几点考虑:
- 数据规模:这些开源日志系统可以很好的支持小规模的场景,但很难支持阿里这种超大规模(PB级)的场景。
- 资源消耗:我们拥有百万规模的服务器/容器,同时日志平台的集群规模也很大,我们需要减少对于采集以及平台自身的资源消耗。
- 多租户隔离:开源软件搭建的系统大部分都不是为了多租户而设计的,当非常多的业务 / 系统使用日志平台时,很容易因为部分用户的大流量 / 不恰当使用而导致打爆整个集群。
- 运维复杂度:在阿里内部有一套非常完整的服务部署和管理系统,基于内部组件实现会具备非常好的运维复杂度。
- 高级分析需求:日志系统的功能几乎全部来源与对应的场景需求,有很多特殊场景的高级分析需求开源软件没办法很好的支持,例如:上下文、智能分析、日志类特殊分析函数等等。
Kubernetes日志平台建设难点
围绕着Kubernetes场景的需求,日志平台建设的难点主要有以下几点:
- 日志采集:采集在Kubernetes中极其关键和复杂,主要因为Kubernetes是一个高度复杂的场景,K8s中有各式各样的子系统,上层业务支持各种语言和框架,同时日志采集需要尽可能的和Kubernetes系统打通,用K8的形式来完成数据采集。
- 资源消耗:在K8s中,服务通常都会拆的很小,因此数据采集对于服务自身的资源消耗要尽可能的少。这里我们简单的做一个计算,假设有100W个服务实例,没个采集Agent减少1M的内存、1%的CPU开销,那整体会减少1TB的内存和10000个CPU核心。
- 运维代价:运维一套日志平台的代价相当之大,因此我们不希望每个用户搭建一个Kubernetes集群时还需再运维一个独立的日志平台系统。因此日志平台一定是要SaaS化的,应用方/用户只需要简单的操作Web页面就能完成数据采集、分析的一整套流程。
- 便捷使用:日志系统最核心的功能是问题排查,问题排查的速度直接决定了工作效率、损失大小,在K8s场景中,更需要一套高性能、智能分析的功能来帮助用户快速定位问题,同时提供一系列简单有效的可视化手段进行辅助。
阿里PB级Kubernetes日志平台建设实践
Kubernetes日志数据采集
无论是在ITOM还是在未来的AIOps场景中,日志获取都是其中必不可少的一个部分,数据源直接决定了后续应用的形态和功能。在十多年中,我们积累了一套物理机、虚拟机的日志采集经验,但在Kubernetes中不能完全适用,这里我们以问题的形式展开:
问题1:DaemonSet or Sidecar
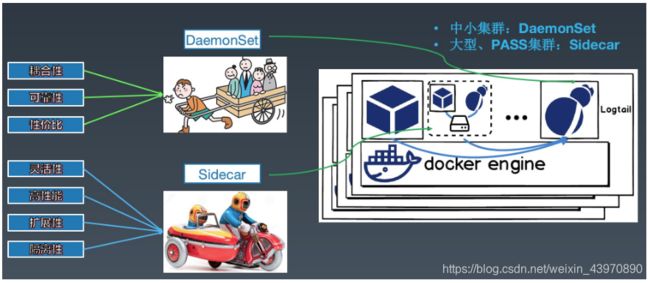
日志最主要的采集工具是Agent,在Kubernetes场景下,通常会分为两种采集方式:
- DaemonSet方式:在K8S的每个node上部署日志agent,由agent采集所有容器的日志到服务端。
- Sidecar方式:一个POD中运行一个sidecar的日志agent容器,用于采集该POD主容器产生的日志。
每种采集方式都有其对应的优缺点,这里简单总结如下:
| DaemonSet方式 | Sidecar方式 | |
|---|---|---|
| 采集日志类型 | 标准输出+部分文件 | 文件 |
| 部署运维 | 一般,需维护DaemonSet | 较高,每个需要采集日志的POD都需要部署sidecar容器 |
| 日志分类存储 | 一般,可通过容器/路径等映射 | 每个POD可单独配置,灵活性高 |
| 多租户隔离 | 一般,只能通过配置间隔离 | 强,通过容器进行隔离,可单独分配资源 |
| 支持集群规模 | 中小型规模,业务数最多支持百级别 | 无限制 |
| 资源占用 | 较低,每个节点运行一个容器 | 较高,每个POD运行一个容器 |
| 查询便捷性 | 较高,可进行自定义的查询、统计 | 高,可根据业务特点进行定制 |
| 可定制性 | 低 | 高,每个POD单独配置 |
| 适用场景 | 功能单一型的集群 | 大型、混合型、PAAS型集群 |
在阿里内部,对于大型的PAAS集群,主要使用Sidecar方式采集数据,相对隔离性、灵活性最好;而对与功能比较单一(部门内部/产品自建)的集群,基本都采用DaemonSet的方式,资源占用最低。
问题2:如何降低资源消耗

我们数据采集Agent使用的是自研的Logtail,Logtail用C++/Go编写,相对开源Agent在资源消耗上具有非常大的优势,但我们还一直在压榨数据采集的资源消耗,尤其在容器场景。通常,为了提高打日志和采集的性能,我们都使用本地SSD盘作为日志盘。这里我们可以做个简答的计算:假设每个容器挂载1GB的SSD盘,1个物理机运行40个容器,那每台物理机需要40GB的SSD作为日志存储,那5W物理机则会占用2PB的SSD盘。
为了降低这部分资源消耗,我们和蚂蚁金服团队的同学们一起开发了FUSE的日志采集方式,使用FUSE(Filesystem in Userspace,用户态文件系统)虚拟化出日志盘,应用直接将日志写入到虚拟的日志盘中,最终数据将直接从内存中被Logtail采集到服务端。这种采集的好处有:
- 物理机无需为容器提供日志盘,真正实现日志无盘化。
- 应用程序视角看到的还是普通的文件系统,无需做任何额外改造。
- 数据采集绕过磁盘,直接从内存中将数据采集到服务端。
- 所有的数据都存在服务端,服务端支持横向扩展,对于应用来说他们看到的日志盘具有无线存储空间。
问题3:如何与Kubernetes无缝集成
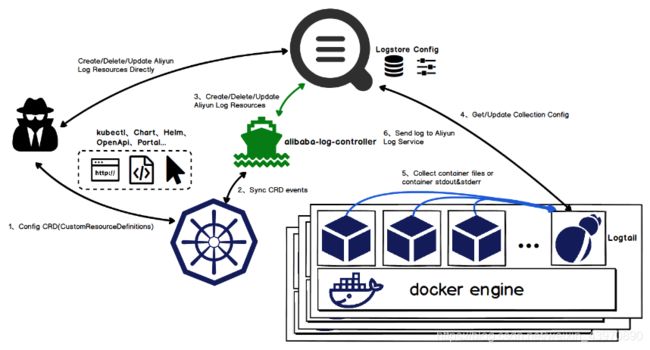
Kubernetes一个非常大的突破是使用声明式的API来完成服务部署、集群管理等工作。但在K8s集群环境下,业务应用/服务/组件的持续集成和自动发布已经成为常态,使用控制台或SDK操作采集配置的方式很难与各类CI、编排框架集成,导致业务应用发布后用户只能通过控制台手动配置的方式部署与之对应的日志采集配置。
因此我们基于Kubernetes的CRD(CustomResourceDefinition)扩展实现了采集配置的Operator,用户可以直接使用K8s API、Yaml、kubectl、Helm等方式直接配置采集方式,真正把日志采集融入到Kubernetes系统中,实现无缝集成。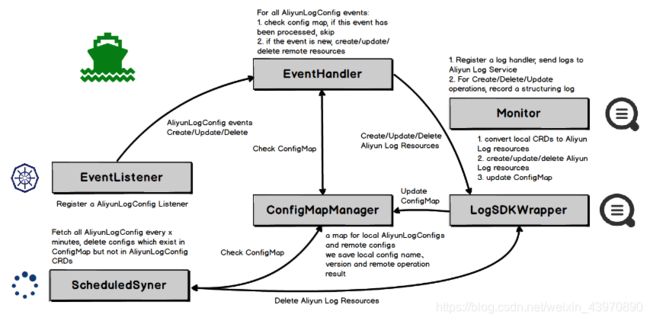
问题4:如何管理百万级Logtail

对于人才管理有个经典的原则:10个人要用心良苦,100个人要杀伐果断,1000个人要甩手掌柜。而同样对于Logtail这款日志采集Agent的管理也是如此,这里我们分为3个主要过程:
- 百规模:在好几年前,Logtail刚开始部署时,也就在几百台物理机上运行,这个时期的Logtail和其他主流的Agent一样,主要完成数据采集的功能,主要流程为数据输入、处理、聚合、发送,这个时期的管理基本靠手,采集出现问题的时候人工登录机器去看问题。
- 万规模:当越来越多的应用方接入,每台机器上可能会有多个应用方采集不同类型的数据,手动配置的接入过程也越来越难以维护。因此我们重点在多租户隔离以及中心化的配置管理,同时增加了很多控制相关的手段,比如限流、降级等。
- 百万规模:当部署量打到百万级别的时候,异常发生已经成为常态,我们更需要的是靠一系列的监控、可靠性保证机制、自动化的运维管理工具,让这些机制、工具来自动完成Agent安装、监控、自恢复等一系列工作,真正做到甩手掌柜。
Kubernetes日志平台架构
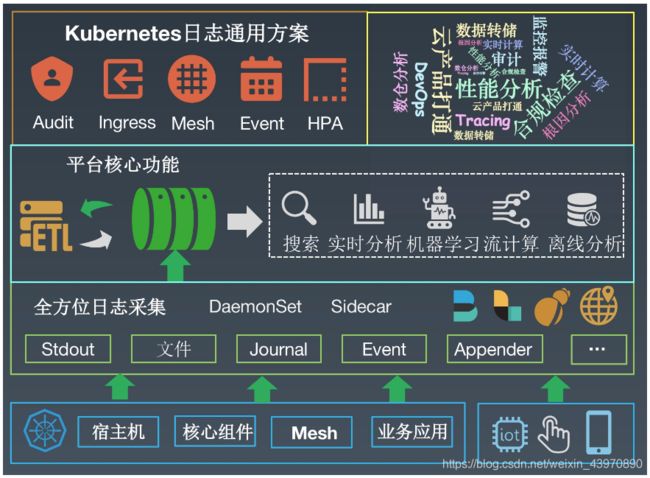
上图是阿里Kubernetes日志平台的整体架构,从底到上分为日志接入层、平台核心层以及方案整合层:
- 平台提供了非常多的手段用来接入各种类型的日志数据。不仅仅只有Kubernetes中的日志,同时还包括和Kubernetes业务相关的所有日志,例如移动端日志、Web端应用点击日志、IoT日志等等。所有数据支持主动Push、被动Agent采集,Agent不仅支持我们自研的Logtail,也支持使用开源Agent(Logstash、Fluentd、Filebeats等)。
-
日志首先会到达平台提供的实时队列中,类似于Kafka的consumer group,我们提供实时数据订阅的功能,用户可以基于该功能实现ETL的相关需求。平台最核心的功能包括:
- 实时搜索:类似于搜索引擎的方式,支持从所有日志中根据关键词查找,支持超大规模(PB级)。
- 实时分析:基于SQL92语法提供交互式的日志分析方法。
- 机器学习:提供时序预测、时序聚类、根因分析、日志聚合等智能分析方法。
- 流计算:对接各类流计算引擎,例如:Flink、Spark Stream、Storm等。
- 离线分析:对接离线分析引擎,例如Hadoop、Max Compute等。
- 基于全方位的数据源以及平台提供的核心功能,并结合Kubernetes日志特点以及应用场景,向上构建Kubernetes日志的通用解决方案,例如:审计日志、Ingress日志分析、ServiceMesh日志等等。同时对于有特定需求的应用方/用户,可直接基于平台提供的OpenAPI构建上层方案,例如Trace系统、性能分析系统等。
下面我们从问题排查的角度来具体展开平台提供的核心功能。
PB级日志查询

排查问题的最佳手段是查日志,大部分人脑海中最先想到的是用 grep 命令查找日志中的一些关键错误信息, grep 是Linux程序员最受欢迎的命令之一,对于简单的问题排查场景也非常实用。如果应用部署在多台机器,那还会配合使用pgm、pssh等命令。然而这些命令对于Kubernetes这种动态、大规模的场景并不适用,主要问题有:
- 查询不够灵活,grep命令很难实现各种逻辑条件的组合。
- grep是针对纯文本的分析手段,很难将日志格式化成对应的类型,例如Long、Double甚至JSON类型。
- grep命令的前提条件是日志存储在磁盘上。而在Kubernetes中,应用的本地日志空间都很小,并且服务也会动态的迁移、伸缩,本地的数据源很可能会不存在。
- grep是典型的全量扫描方式,如果数据量在1GB以内,查询时间还可以接受,但当数据量上升到TB甚至PB时,必须依赖搜索引擎的技术才能工作。
我们在2009年开始在飞天平台研发过程中,为够解决大规模(例如5000台)下的研发效率、问题诊断等问题,开始研支持超大规模的日志查询平台,其中最主要的目标是“快”,对于几十亿的数据也能够轻松在秒级完成。
日志上下文

当我们通过查询的方式定位到关键的日志后,需要分析当时系统的行为,并还原出当时的现场情况。而现场其实就是当时的日志上下文,例如:
- 一个错误,同一个日志文件中的前后数据
- 一行LogAppender中输出,同一个进程顺序输出到日志模块前后顺序
- 一次请求,同一个Session组合
- 一次跨服务请求,同一个TraceId组合
在Kubernetes的场景中,每个容器的标准输出(stdout)、文件都有对应的组合方式构成一个上下文分区,例如Namesapce+Pod+ContainerID+FileName/Stdout。
为支持上下文,我们在采集协议中对每个最小区分单元会带上一个全局唯一并且单调递增的游标,这个游标对单机日志、Docker、K8S以及移动端SDK、Log4J/LogBack等输出中有不一样的形式。
为日志而生的分析引擎
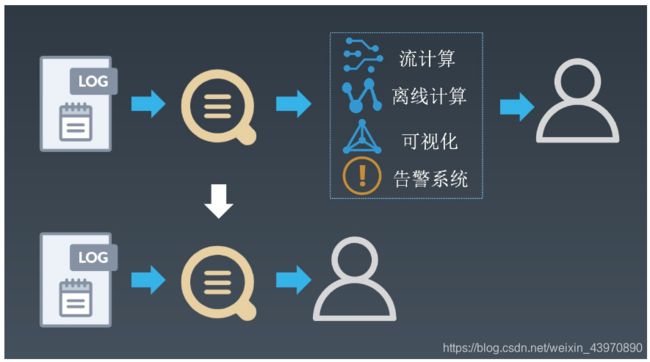
在一些复杂的场景中,我们需要对日志中的数据进行统计来发现其中规律。例如根据ClientIP进行聚合来查找攻击源IP、将数据聚合计算P99/P9999延迟、从多个维度组合分析等。传统的方式需要配合流计算或离线计算的引擎进行聚合计算,再对接可视化系统进行图形化展示或对接告警系统。这种方式用户需要维护多套系统,数据实时性变差,并且各个系统间的衔接很容易出现问题。
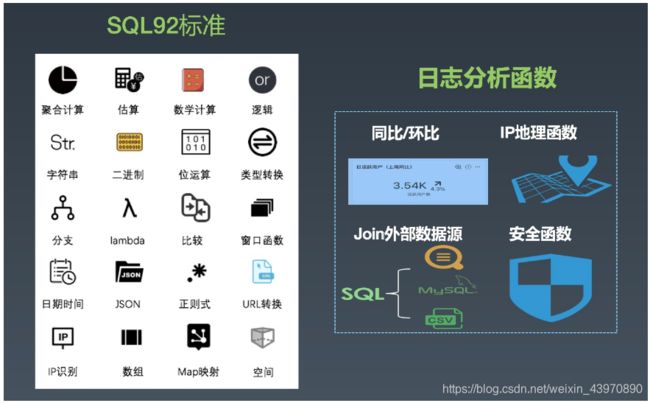
因此我们平台原生集成了日志分析、可视化、告警等相关的功能,尽可能减少用户配置链路。通过多年的实践,我们发现用户最容易接受的还是SQL的分析方式,因此我们分析基于SQL92标准实现,在此基础上扩展了很多针对日志分析场景的高级函数,例如:
- 同比环比:前后数据对比是日志分析中最常用的方式之一,我们提供了同比/环比函数,一个函数即可计算今日PV同比昨日、上周的增幅。
- IP地理函数:基于淘宝高精度IP地理库,提供IP到国家、省、市、运营商、经纬度等的转换,例如常见的Nginx访问日志、K8s Ingress访问日志中的remote-ip可以直接用来分析地理位置分布。
- Join外部数据源:将日志和 MySQL、CSV等做Join分析,例如根据ID从数据库中查找用户对应的信息、和CMDB中的网络架构数据做关联等。
- 安全函数:支持日志安全分析中的常见方式,例如高危IP库查找、SQL注入分析、高危SQL检测等。
智能日志分析
在日志平台上,应用方/用户可以通过日志接入、查询、分析、可视化、告警等功能可以完成异常监控、问题调查与定位。但随着计算形态、应用形态以及开发人员职责的不断演变,尤其在近两年Kubernetes、ServiceMesh、Serverless等技术的兴起,问题的复杂度不断上升,常规手段已经很难适用。于是我们开始尝试向AIOps领域发展,例如时序分析、根因分析、日志聚类等。
时序分析
- 通过时序预测相关方法,我们可以对CPU、存储进行时序建模,进行更加智能的调度,让整体利用率如丝般平滑;存储团队通过对磁盘空间的增长预测,提前制定预算并采购机器;在做部门/产品预算时,根据历年账单预测全年的消费,进行更优的成本控制。
- 稍微大一些的服务可能会有几百、上千甚至上万台的机器,通过人肉很难发现每台机器行为(时序)的区别,而通过时序聚类就可以快速得到集群的行为分布,定位出异常的机器;同时对于单条时序,可以通过时序异常相关的检测方法,自动定位异常点。
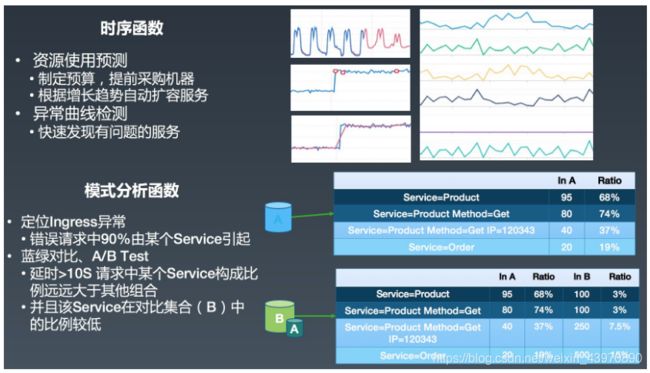
根因分析
时序相关的函数主要用来发现问题,而查找问题根源还需要模式分析相关的方法(根因分析,Root Cause Analysis)。例如K8s集群整体Ingress错误率(5XX比例)突然上升时,如何排查是因为某个服务问题、某个用户引起、某个URL引起、某个浏览器引起、某些地域网络问题、某个节点异常还是整体性的问题?通常这种问题都需要人工从各个维度去排查,例如:
- 按照Service去Group,查看Service之间的错误率有无差别
- 没有差别,然后排查URL
- 还没有,按照浏览器
- 浏览器有点关系,继续看移动端、PC端
- 移动端错误率比较高,看看是Android还是IOS
- ...
这种问题的排查在维度越多时复杂度越高,排查时间也越久,可能等到发现问题的时候影响面已经全面扩大了。因此我们开发了根因分析相关的函数,可以直接从多维数据中定位对目标(例如延迟、失败率等)影响最大的一组(几组)维度组合。
为了更加精确的定位问题,我们还支持对比两个模式的差异,例如今天发生异常时,和昨天正常的模式进行对比,快速找到问题的原因;在发布时进行蓝绿对比以及A/B Test。
智能日志聚类
上面我们通过智能时序函数发现问题、通过根因分析定位到关键的维度组合,但涉及到最终的代码问题排查,还是离不开日志。当日志的数据量很大时,一次次的手动过滤太过耗时,我们希望可以通过智能聚类的方式,把相似的日志聚类到一起,最终可以通过聚类后的日志快速掌握系统的运行状态。
上下游生态对接

Kubernetes日志平台主要的目标在解决DevOps、Net/Site Ops、Sec Ops等问题上,然而这些并不能满足所有用户对于日志的所有需求,例如超大规模的日志分析、BI分析、极其庞大的安全规则过滤等。平台的强大更多的是生态的强大,我们通过对接上下游广泛的生态来满足用户越来越多的日志需求和场景。
优秀应用案例分析
案例1:混合云PAAS平台日志管理
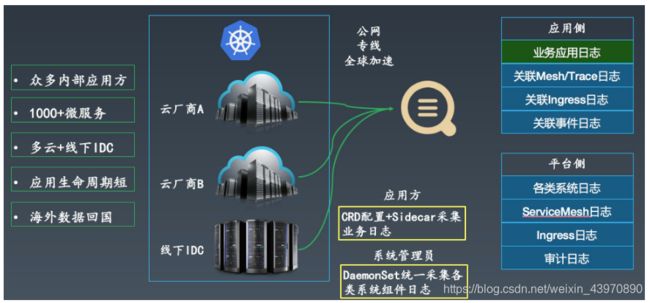
某大型游戏公司在进行技术架构升级,大部分业务会迁移到基于Kubernetes搭建的PAAS平台上,为提高平台整体的可用性,用户采集混合云架构,对于日志的统一建设与管理存在很大困难:
- 众多内部应用方:不希望应用方过多的接触日志采集、存储等细节,并且能够为应用方提供全链路的日志;
- 1000+微服务:需要支持大规模的日志采集方式;
- 多云+线下IDC:希望多个云厂商以及线下IDC采用的是同一套采集方案;
- 应用周期短:部分应用的运行生命周期极短,需要能够及时将数据采集到服务端;
- 海外数据回国:海外节点的日志回国分析,需尽可能保证传输稳定性和可靠性。
用户最终选择使用阿里云Kubernetes日志平台的方案,使用Logtail的方案解决采集可靠性问题,通过公网、专线、全球加速的配合解决网络问题,由系统管理员使用DaemonSet统一采集所有系统组件级别的日志,应用方只需使用CRD采集自己的业务日志。对于平台侧,系统管理员可以访问所有系统级别日志,并进行统一的监控和告警;对于应用侧,应用方不仅可以查到自己的业务日志,还能访问到和业务相关的中间件、Ingress、系统组件日志,进行全链路的分析。
案例2:二次开发日志管理平台

在阿里有很多大的业务部门希望基于我们标准的日志平台进行二次开发,来满足他们部门的一些特殊需求,例如:
- 通过各类规则以及接口限制规范数据接入。
- 通过TraceID将整个调用链串联,构建Trace平台。
- 部门内部多用户的权限细化管理。
- 部门内部各个子部门的成本结算。
- 与一内部些管控、运维系统打通。
这些需求可以基于我们提供的OpenAPI以及各语言的SDK快速的实现,同时为了减少前端的工作量,平台还提供Iframe嵌入的功能,支持直接将部分界面(例如查询框、Dashboard)直接嵌入到业务部门自己的系统中。
未来工作展望

目前阿里Kubernetes日志平台在内外部已经有非常多的应用,未来我们还将继续打磨平台,为应用方/用户提供更加完美的方案,后续工作主要集中在以下几点:
- 数据采集进一步精细化,持续优化可靠性和资源消耗,做到极致化的多租户隔离,争取在PAAS平台使用DaemonSet采集所有应用的日志。
- 提供更加便捷、智能的数据清洗服务,在平台内部就可以完成异构数据的清洗、规整等工作。
- 构建面向Ops领域的、可自动更新的、支持异构数据的知识图谱,让问题排查的经验可以积累在知识库中,实现异常搜索与推理。
- 提供交互式的训练平台,构建更加智能的Automation能力,真正实现Ops的闭环。

原文链接
本文为云栖社区原创内容,未经允许不得转载。