Scala学习笔记-基础篇
Scala 学习笔记
- 1、语法
-
- 1.变量与常量
- 2.标识符
- 3.字符串
- 4.控制台标准输入
- 2、数据类型
-
- 1.概览
- 2.基本数据类型
- 3.自动类型转换
- 4.强制类型转换
-
- - 原码、反码、补码
- 3.运算符
-
-
- 1.算数运算符
- 2.关系运算符
- 3.==与equals
- 4.逻辑运算符
- 5赋值运算符
- 6.位运算符
- 7.运算符的本质
-
- 4.流程控制
-
- 1.分支控制
- 2.循环控制
-
- 1.for
-
- 范围遍历-to
- 集合遍历
- 循环守卫
- 循环步长
- 循环嵌套
- 引入变量
- 练习
- 2.循环返回值
- 3.while
-
- 1.循环中断
-
- 异常
- breakable
- 5.函数编程
-
- 函数基础
-
- 1.函数基本语法
- 2.函数和方法的区别
- 3.函数定义
- 4.函数参数
- 5.函数至简原则*
-
- 匿名函数简化
- 函数高级
-
- 1.高阶函数
- 2.匿名函数
- 3.函数柯里化&闭包
- 4.递归*
- 5.控制抽象
- 6.惰性函数
- 6.面向对象
-
- 1.包
- 2.类和对象
-
- 类
- 创建对象
- 构造器
- 继承
- 多态
- 抽象类
- 单例对象
- 特质-Trait
-
- 语法
- 特质混入
- 特质叠加顺序
- 钻石问题特征叠加
- 指定调用的特征
- 总结
- 特质自身类型
- 拓展
-
- 类型检查与转换
- 枚举类和应用类
- 7.集合
-
- 数组
-
- 不可变数组
- 可变数组
- 可变数组转换为不可变数组
- 多维数组
- 列表List
- Set集合
- Map集合
- 元组
- 集合总结
-
- 属性与操作
- 衍生集合
- 集合计算初级函数
- 集合计算高级函数
- 队列
- 并行集合
- 8.模式匹配
- 9.异常处理
- 10.隐式转换
- 11.泛型
1、语法
1.变量与常量
- scala可以做自动类型推到,编译器可以推断出来的类型可以不用说明
- 变量声明时必须要初始化
- 类型确定后不能修改
// 变量
var var_name [: type] = value
// 常量
val val_name [: type] = value
定义方法参数时定义变量
def student(name : String, var age : Int) Unit={
}
2.标识符
- 以字母或者下划线开头,后接字母、数字、下划线
- 就可以使用特使字符,但又两点要求:1.不能使用$;2.特殊字符不能和数字、字母组合
- 以操作符开头,且只包含操作符(±*/# !等)
- 用反引号``包括的任意字符串,即使是Scala 关键字(39 个)也可以
package, import, class, object, trait, extends, with, type, for
private, protected, abstract, sealed, final, implicit, lazy, override
try, catch, finally, throw
if, else, match, case, do, while, for, return, yield
def, val, var
this, super
new
true, false, null
e.g.
var +-*/\^&%#@!^&* = "sdf"
println(+-*/\^&%#@!^&*)
3.字符串
// 1.拼接
def main(args: Array[String]): Unit = {
var name : String = "jack"
var age : Int = 18
println(name + "现在" + age + "岁了。")
}
// 2.复制输出
println(name * 3)
// 3.格式化输出,类似C语言
printf("%s现在%d岁了", name, age)
// 4.字符串模板(字符串插值) : 通过${}获取变量
println(s"${name}现在${age}岁了")
// 格式化字符串模板,可以进行四舍五入
val num: Double = 0.378
println(f"保留两位小数:${num}%2.2f")
保留两位小数:0.38
println(1.333.formatted("%2.2f"))
// 除了变量外不对其他字符转义:raw
println(raw"保留两位小数:${num}%2.2f")
保留两位小数:0.378%2.2f
// 5.三引号表示字符串,保持多行字符串原格式输出(如写sql),stripMargin方法忽略便捷输出(空格,|)
val sql : String = s"""
|select *
|form table
|""".stripMargin
4.控制台标准输入
def main(args: Array[String]): Unit = {
print("请输入姓名:")
val name : String = StdIn.readLine()
print("请输入年龄:")
val age : Int = StdIn.readInt()
println(s"${name},${age}")
}
// 文件输入
Source.fromFile("src/test/test").foreach(print)
// 文件输出可以使用Java
2、数据类型
1.概览
- 实线表示继承关系,虚线表示可以进行自动类型转换(映射转换)
- 不论是Java还是Scala,在声明变量是,默认将数字解析成int,小数解析成double,
如果在Java中long a = 2334456734345;
编译器会报错:Integer number too large,即是说在数字小的时候可以定义为long类型是因为发生了自动类型转换。Scala同样是这样的。

2.基本数据类型
// 1.整数
Byte,Short,Int,Long
// 2.浮点
Float,Double
// 3.字符 - 底层保存的是ASCII码
Char
// 4.布尔
Boolean
// 5.Unit
表示无值,和其他语言中void等同。用作不返回任何结果的方法的结果类型。Unit只有一个实例值,写成()。
// 6.Null
null,Null类型只有一个实例值null
// 7.Nothing
Nothing类型在Scala的类层级最低端;它是任何其他类型的子类型。当一个函数,我们确定没有正常的返回值,可以用Nothing来指定返回类型,这样有一个好处,就是我们可以把返回的值(异常) 赋给其它的函数或者变量(兼容性)
3.自动类型转换
// 会优先转换成可用的最近的上级,
public static void main(String[] args) {
byte b = 10;
test(b);
}
private static void test(byte b) {
System.out.println("byte");
}
private static void test(short s) {
System.out.println("short");
}
private static void test(char c) {
System.out.println("char");
}
private static void test(int i) {
System.out.println("int");
}
4.强制类型转换
- Byte-Short-Char 之间不会自动类型转换,想要进行计算可以先转换成Int类型
- 转换String为Int时必须符合强转规则才能转换
def main(args: Array[String]): Unit = {
var a: Int = 10
var b: Byte = a.toByte
var f: Int = "12.6".toFloat.toInt
}
- 原码、反码、补码
// 原码
原码就是符号位加上真值的绝对值, 即用第一位表示符号, 其余位表示值.
// 反码
正数的反码是其本身,
负数的反码是在其原码的基础上, 符号位不变,其余各个位取反.
// 补码
正数的补码就是其本身,
负数的补码是在其原码的基础上, 符号位不变, 其余各位取反, 最后+1. (即在反码的基础上+1)
3.运算符
1.算数运算符
+,-,*,/,%
2.关系运算符
==,!=,<,>,<=,>=
3.==与equals
Java中==比较的是对象,而equals比较的是值
而在Scala中,==与equals是相等的,但需要注意的是,==的底层实现其实是调用了equals,所以,如果需要判断两个对象的内容是否相等时,需要从写equals方法,在使用==就能正确判断了.
Scala中判断对象的引用是否相等时,可以使用eq()方法
4.逻辑运算符
&&,||,!
// 逻辑运算符的短路特性:如果前面的表达式使得条件成立,那么便不会执行后面的表达式,即使表达式不合法.
// 比如1/0是不合法的,但是因为1==1成立,所以没有执行1/0==0,如果输出1/0就会报java.lang.ArithmeticException异常.
println(1 == 1 || 1 / 0 == 0)
//如果str==null,那么直接返回,不会出现空指针异常,而如果str!=null,则可以进行下一步判断.
return str!=nu1l &&"".equaLs(str. trim))
5赋值运算符
- 注意Scala中没有++,–运算符
=,+=,-=,/=,/=,<<=,>>,^=,|
def main(args: Array[String]): Unit = {
var n1: Int = 2
n1 <<= 1
println(n1)
n1 >>= 1
println(n1)
n1 ^= 1
println(n1)
n1 |= 1
println(n1)
}
//输出
4
2
3
3
6.位运算符
&,|,<<,>>(相当于*或/2的n次方),<<<,>>>(无符号)
^:异或
~:取反
7.运算符的本质
// n1与n2都是对象,对象下有.+()这个方法,所以对于scala来说,进行运算本身就是在调用方法.
// 通常在进行计算时,往往会用 n1 + n2 的形式,其中的空格其实就相当于.,编译器会自动补全,成为后缀运算符表示法
val n1: Int = 1
val n2: Int = 1
println(n1.+(n2))
println(7.5 toString)
4.流程控制
1.分支控制
- 同Java, 可以嵌套使用
def main(args: Array[String]): Unit = {
val age: Int = StdIn.readInt()
if (age > 18){
println("已成年")
} else {
println("未成年")
}
}
// 在Scala中,每一个表达式都是有值的.比如if语句的值就是其最后一行代码的返回值,如果print就是Unit.
def main(args: Array[String]): Unit = {
println("请输入年龄:")
val age: Int = StdIn.readInt()
val unit: Unit = if (age > 18) {
println("已成年")
} else {
println("未成年")
}
print(unit)
}
//这时就会出现一个问题,我定义的类型是Unit,但最后一行输出String,会不会报错
def main(args: Array[String]): Unit = {
println("请输入年龄:")
val age: Int = StdIn.readInt()
val unit: Unit = if (age > 18) {
println("已成年")
} else {
println("未成年")
"最后一行的值"
}
print(unit)
}
//结果是不会,因为返回值虽然是String,但是可以不返回,反过来就不行了;
请输入年龄:
12
未成年
()
//这是在第一个if的最后一行后面会报错.总结来说就是,如果我不需要返回值(Unit),你可以有返回值但我不会返回;但是如果我需要返回值(String),你不能没有返回值.
def main(args: Array[String]): Unit = {
println("请输入年龄:")
val age: Int = StdIn.readInt()
val unit: String = if (age > 18) {
println("已成年")
} else {
println("未成年")
"最后一行的值"
}
print(unit)
}
//实现三目运算符 age>18?"已成年":"未成年"
val result: String = if (age > 18) {
"已成年"
} else {
"未成年"
}
print(result)
}
//当语句只有一句时,Scala同样可以省略大括号
val result: String = if (age > 18) "成年" else "未成年"
print(result)
2.循环控制
1.for
范围遍历-to
- P38
// 运算符的本质都是方法调用,同样的,在这里的to也是方法调用
for (i <- 0 to 9) {
println(i)
}
for (i: Int <- 0.to(9)) {
println(i)
}
// scala中有一个Predef的对象,对象中定义了很多方法与类型,其中,就有包装方法:传一个Int,返回一个RichInt类型,做了一个隐式转换
// 不包含边界
//不适用new 关键字时表示使用他的伴生对象
for (i <- Range(0, 9)) {
println(i)
}
// 底层就是使用了上面的Range().创建伴生对象时默认调用apply方法.
for (i <- 0 until 9) {
println(i)
}
集合遍历
for (i <- Array(11, 22, 33)) {
println(i)
}
for (i <- Set(11, 22, 33)) {
println(i)
}
for (i <- List(11, 22, 33)) {
println(i)
}
循环守卫
- 使用条件决定某些循环是否执行
- 类似与continue效果
for(i <- 1 to 10 if i != 5){
println(i)
}
循环步长
- 步长不能为0
- 步长可以为浮点小数
// 没两个取一个
for (i <- 1 to 10 by 2){
println(i)
}
//如果步长为负数,条件不成立的话是没有任何输出的
for (i <- 10 to 1 by -2){
println(i)
}
for (i <- 1 to 10 reserve){
println(i)
}
// 一次走半步
for (i <- 1.0 to 10.0 by 0.5){
println(i)
}

循环嵌套
// 可以使用Java方式
for (i <- 1 to 5){
for (j <- 1 to 4){
println(i + "," + j)
}
}
// Scala简洁版
for (i <- 1 to 5; j <- 1 to 4){
println(i + "," + j)
}
//九九乘法表
for (i <- 1 to 9; j <- 1 to i){
print(s"${i} * ${i} = ${i * j} \t")
if (i == j) pirntln()
}
引入变量
// 变量与循环变量相关
for (i <- 1 to 10; val j - 10 - i){
println(i + "," + j)
}
// 直接使用{}定义
for {
i <- 1 to 10
j = 10 - i
}
{
println(i + "," + j)
}
练习
输出等腰三角形的*,以第一个为中心,两边对称.

2.循环返回值
- yield , 在当前循环生成一个集合
- 可以批量操作集合,效果高
// for 默认返回值都为 Unit=(),但是可以使用集合来获得返回值
// yield
val b = for (i <- 1 to 10) yield i
println(b)
3.while
- 不推荐使用while与do-while
- 推荐使用for循环
var a: Int = 10
while(a > 0) {
println(a + ",")
a -= 1
}
do {
println(a + ",")
a += 1
} while(a < 10)
1.循环中断
异常
- 使用抛出异常方式来模拟break功能
try {
for (i <- 1 to 10) {
if (i == 3)
throw new RuntimeException
println(i)
}
} catch {
case e: RuntimeException =>
}
println("循环体外")
breakable
Breaks.breakable(
for (i <- 1 to 10) {
if (i == 3)
Breaks.break()
println(i)
}
)
println("循环体外")
// 简化
import scala.util.control.Breaks._
breakable(
for (i <- 1 to 10) {
if (i == 3)
break()
println(i)
}
)
println("循环体外")
5.函数编程
- 面向对象:盖浇饭
- 面向过程:炒饭
函数基础
1.函数基本语法
def function_name(function_parameter: function_type[ = parameter_default_value], y: Int): function_return_type = {
function_body
}
2.函数和方法的区别
- 为完成某一功能的程序语句的集合, 称为函数。
- 类中的函数称之方法。
任意地方都可以定义函数,比如方法内或者类的内部,但类内定义的函数通常称为方法,因为可以直接使用类名调用,是这个类的属性[面向对象思维]
3.函数定义
def main(args: Array[String]): Unit = {
a(1)
def a(aa: Int): Unit = {
b(2)
def b(bb: Int): Unit = {
c(3)
def c(cc: Int): Unit = {
println(aa)
}
}
}
}
4.函数参数
// 无参,无返回值
def f1(): Unit = {}
// 无参,有返回值
def f2(): String = {
return "无参有返回值"
}
// 有参,无返回值
def f3(num: Int): Unit = {
println(num)
}
// 有参,有返回值
def f4(num: Int): Int = {
return num
}
// 多参,无返回值
def f5(num1: Int, num2: Int): Unit = {
println(num1 + num2)
}
// 多参,有返回值
def f5(num1: Int, num2: Int): Int = {
return num1 + num2
}
- 参数
// 可变参数[最后]
def f1(str: String*): Unit = {
println(str)
}
//输出
WrappedArray(input)
// 参数默认值
def f2(str: String = "默认值"): Unit = {
println(str)
}
// 带名参数
def f3(name: String, age: Int): Unit = {
println(name + "," + age)
}
f3(age = 18, name = "shimmer")
5.函数至简原则*
- 能省则省
- return可以省略,Scala会使用最后一行代码作为返回值
- 函数体只有一行时,可以省略{}
- 如果返回值类型可以由编译器推断出来,那么可以省略。但是当有return关键词时,不能省略返回值
- 如果返回值为Unit,则return无效
- 如果期望无返回值类型,可以省略=
- 如果函数无参数,但声明了参数列表[即只有一个小括号],那么调用时小括号可写可不写。
- 如果声明函数时没有写小括号,那么调用不能写小括号
- 如果不关心函数名称,只关心处理逻辑,那么可以省略函数名(def)
// 8.匿名函数,lambda表达式
(name: String) => { println(name) }
// 把匿名函数赋给一个变量,就可以像函数一样调用
val fun = (name: String) => {
println(name)
}
fun("cool")
// 将函数作为参数传递
def main(args: Array[String]): Unit = {
val fun = (name: String) => {
println(name)
}
def fun1(func: String => Unit): Unit = {
func("cool")
}
fun1(fun)
}
匿名函数简化
- 参数类型可以省略,会根据形参进行自动推导
- 只有一个参数,括号可以省略,但没有参数是括号不可以省略
- 函数体只有一行,省略{}
- 如果参数只出现一次,则参数省略且后面的参数可以用_代替,即省略lambda表达式的=>
- 如果可以推断出,当前传入的println是一个函数体而不是调用语句,则可以省略_
def fun1(func: String => Unit): Unit = {
func("cool")
}
(name: String) => {
println(name)
}
// 简化
fun1(name => println(name))
// 4.
fun1(println(_))
// 5.
fun1(println)
函数高级
1.高阶函数
- 函数作为值进行传递
// 目的是将函数作为一个值进行传递,而不是传递函数执行的结果。指定参数类型就不需要写下划线了,没指定参数类型需要用下划线来指明函数是一个整体,而不是函数的执行结果
val a = f _
val b: Int => Int = f
println(a)
//输出
scala.Demo4$$$Lambda$11/1265210847@2fc14f68
- 函数作为参数传递
def f1(op: (Int, Int) => Int, a: Int, b: Int): Int = op(a, b)
println(f1((a, b) => a * b, 2, 3))
println(f1(_ * _, 2, 3))
- 函数作为函数的返回值返回
def f2(): Int => Unit = {
def f3(m: Int): Unit = {
println(s"函数f3:${m}")
}
f3
}
val f4 = f2()
println(f4)
f4(12138)
- 举例
def main(args: Array[String]): Unit = {
val arr: Array[Int] = Array(11, 22, 33)
def arrayOperation(array: Array[Int], op: Int=>Int): Array[Int] = {
for(ele <- array) yield op(ele)
}
val ints: Array[Int] = arrayOperation(arr, _ + 1)
println(ints.mkString("Array(", ", ", ")"))
}
- 练习

def main(args: Array[String]): Unit = {
def fun(int: Int): String => (Char => Boolean) = {
def f1(string: String): Char => Boolean = {
def f2(char: Char): Boolean = {
if (0 == int && "" == string && 0 == char) false else true
}
f2
}
f1
}
println(fun(0)("")(0))
}
// 匿名函数简写
def fun(int: Int): String => (Char => Boolean) = {
string =>
char => if (0 == int && "" == string && 0 == char) false else true
}
println(fun(0)("")(0))
2.匿名函数
def function_option(fun: (Int, Int) => Int) = {
fun(1, 2)
}
val sum = (a: Int, b: Int) => a + b
val difference = (a: Int, b: Int) => a - b
println(function_option(sum))
println(function_option(difference))
// 简化
println(function_option(_ + _))
println(function_option(-_ + _))
3.函数柯里化&闭包
- 闭包:如果一个函数,访问到了它的外部变量的值,那么这个函数和它所处的环境,成为闭包。当外部函数执行完毕后,将参数打包进内部函数,然后释放资源结束外部执行,这样即延长了外部参数的生命周期 ,又减少了资源消耗
- 函数柯里化:把一个参数列表的多个参数,变成多个参数列表
def fun(int: Int)(string: String)(char: Char): Boolean = {
if (0 == int && "" == string && 0 == char) false else true
}
println(fun(0)("")(0))

4.递归*
- 阶乘
def factorial(num: Int): Int = {
if (num == 1) 1
else num * factorial(num -1 )
}
println(factorial(5))
// 优化栈内存:尾递归调用
def tailFact(n: Int): Int = {
@tailrec
def loop(n: Int, currRes: Int): Int = {
if (n == 1) return currRes
loop(n -1, currRes * n)
}
loop(n, 1)
}
println(tailFact(5)
5.控制抽象
- 值调用:传值参数
- 名调用:传名参数,传一段代码
// 控制抽象会将代码内用到的a替换为传进来的代码段,就是说如果我传进来一个函数,那么有几处用到a,就会调用几次函数
def f(a: =>Int): Unit = {
println("a:" + a)
println("a:" + a)
}
f(19)
- 使用控制抽象特性实现while循环功能
def myWhile(condition: => Boolean): (=> Unit) => Unit = {
def doLoop(op: => Unit): Unit = {
if (condition) {
op
myWhile(condition)(op)
}
}
doLoop _
}
var n = 10
myWhile(n>0)({
println(n)
n = n - 1
})
// 简化
def myWhile1(condition: => Boolean)(op: => Unit): Unit = {
if (condition) {
op
myWhile(condition)(op)
}
}
n = 10
myWhile1(n > 0){
println(n)
n = n - 1
}
6.惰性函数
- 惰性函数:当函数的返回值声明为lazy时,函数的执行将被推迟,直到我们首次对此取值,该函数才会执行
lazy val res: Int = sum(11, 22)
println("2. 函数调用")
println("3. res = " + res)
println("4. res = " + res)
def sum(a: Int, b: Int): Int = {
println("1. sum函数执行")
a + b
}
- 理解
所谓的懒加载就是:在第一次需要用到该变量的时候才进行加载,之后这个值就可以保留使用,再遇到需要使用的时候就可以直接使用。其类似于控制抽象。
6.面向对象
1.包
-
逻辑所属:包名和源文件所在路径不要求一致
-
可以使用{}嵌套表示层级关系,内层可以直接访问外层对象,外层访问内层需要导包
-
包对象(package object)在Scala中可以为每个包定义一个同名的包对象,定义在包对象中的成员,作为其对
应包下所有class和object的共享变量,可以被直接访问。包对象声明要和包的层级相同才可以使用 -
导包
- import全局导入,局部导入,方法内可用
- 通配符导入 import java.util._
- 给类起名 import java.util.{ArrayList=>JL}
- 导入相同包的多个类:import java.util.{HashSet,ArrayList}
- 屏蔽类:import java.util.{ArrayList=>,}
- 导入绝对路径:nuw root.import java.util.HashMap
- 默认导入
import java.lang._
import scala._
import scala.Predef._
2.类和对象
类
class Student {
private val name: String = "alice"
@BeanProperty
var age: Int = _
}
- 封装
// 属性私有化,get,set
// Scala中的public属性,底层实际为private, 并通过get方法(oj.field0) 和set方法(obj.field_ =(value))对其进行操作。所以Scala并不推荐将属性设为private, 再为其设置public的get和set方法的做法。但由于很多Java框架都利用反射调用getXXX和setXXX方法,有时候为了和这些框架兼容,也会为Scala的属性设置getXXX和setXXX方法(通过@BeanProperty注解实现)
(1) Scala 中属性和方法的默认访问权限为public,但Scala中无public关键字。
(2) private 为私有权限,只在类的内部和伴生对象中可用。
(3) protected 为受保护权限,Scala 中受保护权限比Java中更严格,同类、子类可以访问,同包无法访问。
(4) private[包名],增加包访问权限,包名下的其他类也可以使用
创建对象
package scala
object Demo6 {
def main(args: Array[String]): Unit = {
val person: Person = new Person()
// 无法访问idCard与name属性
println(s"Person: idCard name ${person.age} ${person.sex}")
}
}
class Student extends Person {
// 无法访问私有属性idCard变量
println(s"Person: idCard $name $sex $age")
}
class Person {
private var idCard: String = "12138"
protected var name: String = "alice"
var sex: String = "female"
private[scala] var age: Int = 18
def printInfo(): Unit = {
println(s"Person: $idCard $name $sex $age")
}
}
构造器
- 可以定义跟类名相同的方法,但那不是构造方法,就是普通方法
- 在主钩造器中定义参数列表与构造体中定义变量作用效果是相同的
// 没有参数时可以省略()
class 类名(形参列表) {
//类体
def this(形参列表) {
// 辅助构造器
}
def this(形参列表) {
// 第二个辅助构造器可以调用前面的辅助构造器,但不能调用后面的
}
}
object Demo7 {
def main(args: Array[String]): Unit = {
val stu = new Stu("alice", 18)
}
}
class Stu() {
var name: String = _
var age: Int = _
println(s"主构造方法:$name,$age")
def this(name: String, age: Int) {
this()
this.name = name
this.age = age
println(s"辅助造方法:$name,$age")
}
}
// 直接定义参数列表
class Stu2(var name: String, var age: Int)
// 无修饰声明其参数不属于成员属性,可以通过方法获得
class Stu3(name: String,age: Int)
继承
- 继承后要先调用父类构造器,后调用子类构造器:父类主钩造器->子类主钩造器->子类辅助构造器
- 如果父类的主构造器有参数,那么集成时必须传参,所以要求子类必须也要有参数,然后直接将参数传给父类主构造器
// 重写方法
override def info(): Unit = super.info()
多态
- Java:动态绑定方法,静态绑定属性
- Scala:全部为动态绑定,是谁的对象,就由谁实现
- 将子类对象赋给父类引用,以实现多种功能。
抽象类
// abstract 关键字标记抽象类
abstract class Person{}
// 属性没有初始化为抽象属性
var|val name: String
// 方法没有实现(方法体)为抽象方法
def hello(): String
- 代码
abstract class A {
// var不可以使用override关键字,因为其本身是可变的,直接修改就可以
var name: String
// val需要使用override重写
val age: Int
// 默认是Unit
def info()
}
- 匿名子类:直接new一个抽象类,使用匿名内部类的形式来实现其抽象属性与抽象方法的重写。
单例对象
- scala没有静态操作,所以使用单例对象模拟全局一份的操作
- 伴生对象与伴生对象的所属类内的属性方法可以互相访问
- 构造器私有化,在参数列表前面加上private
- apply:对于伴生对象或单例对象中的apply方法,可以省略apply的书写,即直接调用 -> 类名(参数列表)
// 名字相同,并且在同一文件内
class Student3() {}
object Student3{}
- 单例设计模式
class Student3 private {}
object Student3 {
private val student = new Student3
def getInstance(): Student3 = student
}
特质-Trait
- 单继承,多实现
语法
abstract class A {
var name: String
var age: Int
// 默认是Unit
def info()
}
trait C {
var sex: String
}
class B extends A with C {
override var name: String = "alice"
override var age: Int = 19
override var sex: String = "female"
override def info(): Unit = {
println(s"B: $name,$age,$sex")
}
}
特质混入
- with关键字实现多特质
- 动态混入:匿名子类实现,在new子类的同时 with 一个特质{实现其抽象内容}
特质叠加顺序
- super:从后往前叠加,而且父类与特征是平等的
钻石问题特征叠加
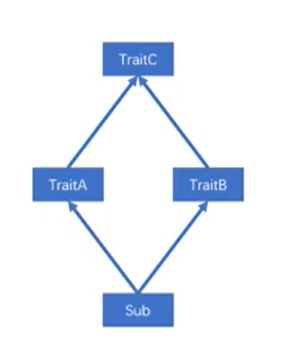
- 解答

指定调用的特征
super[A].mothod()
总结
- 优先使用特质。-个类扩展多个特质是很方便的,但却只能打展一个抽象类。
- 如果你需要构造函数参数,使用抽象类。因为抽象类可以定义带参数的构造函数,而特质不行(有无参构造)
特质自身类型
- 自身类型可以实现依赖注入功能
class D(var name: String, var age: Int)
trait E {
_: D =>
def insert(): Unit = {
println(s"insert into db: ${this.name}")
}
}
拓展
类型检查与转换
obj.isInstanceOf[T]:判断obj是否为T类型
obj.asInstanceOf[T]:将obj强转为T类型
classOf:获取对象的类名
枚举类和应用类
// 继承 Enumeration
object F extends Enumeration {
val RED: F.Value = Value(1, "red")
val BLACK: F.Value = Value(2, "black")
}
// 继承App
object G extends App {}
// 别名定义-type
type myString = String
val name: myString = "别名"
7.集合
-
Scala 的集合有三大类:序列Seq、集Set、映射Map,所有的集合都扩展自Iterable特质。
-
对于几乎所有的集合类,Scala 都同时提供了可变和不可变的版本,分别位于以下两
个包不可变集合: scala.collection.immutable
可变集合:
scala.collection.mutable -
Scala 不可变集合,就是指该集合对象不可修改,每次修改就会返回一个新对象,而不会对原对象进行修改。类似于java中的String对象。
-
可变集合,就是这个集合可以直接对原对象进行修改,而不会返回新的对象。类似
于java中StringBuilder 对象。 -
推荐在集合操作时,不可变用符号,可变用方法

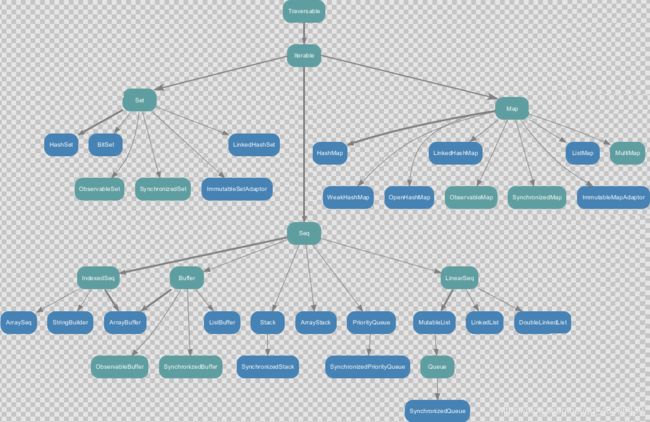
数组
不可变数组
// 使用伴生对象所属的类创建
val arr: Array[Int] = new Array[Int](10)
// 使用伴生对象的apply方法
val arr1 = Array(11, 22, 33, 44, 55)
- 使用索引访问与赋值
println(arr1(0))
arr1(0) = 99
for (elem <- arr1) {println(elem)}
- 数组遍历
// 普通遍历
for (elem <- 0 until arr.length) println(elem)
for (elem <- arr.indices) println(elem)
def indices: Range = Range(0, xs.length)
// 增强遍历
for (elem <- arr) println(elem)
// 迭代器
val iterator = arr.iterator
while (iterator.hasNext) println(iterator.next())
// foreach-传一个函数
arr.foreach((elem) => println(elem))
arr.foreach(print)
- 数组输出
println(arr.mkString(","))
- 添加元素-返回新的数组对象
// 追加到末尾
val arr3 = arr.:+(999)
// 插入到开头
val arr3 = arr.+:(999)
// 简化
val arr4 = 666 +: 777 +: arr :+ 888 :+ 999
可变数组
- Array继承自java.io.Serializable/Cloneable,本身就有toString方法,所以不会进行Scala隐式转换。
- ArrayBuffer在输出时没有制定了重载的特质方法
override def toString(): String = super[Iterable].toString()
override def toString = mkString(className + “(”, ", ", “)”)
val arrBuffer: ArrayBuffer[Int] = new ArrayBuffer[Int]()
val arrBuffer1 = ArrayBuffer(11, 22, 33)
- 添加元素
111 +=: arrBuffer += 222
// 可变集合推荐使用字母方法
arrBuffer.prepend(333)
arrBuffer.append(444)
// 在索引1的位置添加,原本1上的数据后移
arrBuffer.insert(1, 999)
arrBuffer.insertAll(2, arr)
- 删除元素
arrBuffer.remove(1)
// 起始位置,删除数量
arrBuffer.remove(1, 10)
// 先查询寻找,找不到不操作,找到删除,并且只会删除第一个符合条件的元素
arrBuffer -= 999
可变数组转换为不可变数组
val array: Array[Int] = arrBuffer.toArray
val buffer: mutable.Buffer[Int] = array.toBuffer
多维数组
// 定义与赋值
val arr2: Array[Array[Int]] = Array.ofDim[Int](2, 3)
arr2(1)(1)
// 循环
for (i <- arr2.indices; j <- arr2(i).indices) println(arr2(i)(j))
// foreach
arr2.foreach( line => line.foreach(println))
arr2.foreach(_.foreach(println))
列表List
- list本省是一个抽象类,不能new创建,可以通过伴生对象的apply方法
val list = List(11, 22, 33)
println(list)
- 访问
// 直接索引访问
println(list(1))
// 遍历
list.foreach(println)
// 添加元素
val list1 = 10 +: list :+ 30
// NIL 创建一个空列表,::再表头添加元素
val list3: List[Int] = Nil.::(13)
val list4: List[Int] = 11 :: 22 :: 33 :: Nil
// 追加list类型
val list5 = list :: list4
// 合并元素
val list6 = list ::: list4
val list7 = list ++ list4
- 可变列表ListBuffer
val list = new ListBuffer[Int]()
val list1 = ListBuffer[Int](11, 22, 33)
list.append(11)
list.prepend(22)
list.insert(1, 44)
println(list)
// 合并列表
// ++ 创建一个新的缓存,++=可以保存更改
val list2 = list ++ list1
// 修改列表
list(index) = value
list.update(index, value)
list.remove(index)
list -= value
Set集合
-
无需不重复
-
可变/不可变都叫Set
- 不可变Set
// set 本身是一个 trait,使用伴生对象来创建与初始化
val set = Set(11, 22, 33)
// 不能加集合类型
val set1 = set + 44
// 合并集合
val set2 = set ++ set1
// 删除元素
val set3 = set - 11
- 可变Set
val set1: mutable.Set[Int] = mutable.Set(11, 22, 33)
// 添加元素
val set2 = set1 + 11
set2 += 11
// 返回值为是否添加成功
set1.add(44)
// 删除元素
set -= 11
set.remove(11)
// 合并集合
val set3 = set ++ set1
set ++= set1
Map集合
- 散列表-键值对
- 不可变ImmutableMap
val map: Map[String, Int] = Map[String, Int]("a" -> 11, "b" -> 22)
// 遍历
map.foreach(println)
map.foreach( kv: (String, Int) => println(kv))
// map : key-value
for (key <- map.keys){
println(key + "," + map.get(key))
}
// 正常的get方法回返回对应Option类型(一个Some类型),想要获得value可以使用.get
println(map.get("a").get)
// 如果元素不存在则返回一个None,None调用.get会报空指针异常
// 如果有key-c,则输出其value,没有输出0
map.getOrElse("c", 0)
// 简单访问
map("a")
- 可变Map
val set = mutable.Map[String, Int]("a" -> 11, "b" -> 22)
// 添加元素-底层使用update-底层使用+=
map.put("c", 5)
// 里面的括号表示键值对,外面的括号表示里面的是一个参数,如果不加外面的括号的话,编译器会理解为这是两个参数
map += (("e", 7))
// 删除元素
map.remove(key)
map -= key
// 更新
map.update("a", 99)
// 合并
// map1的值添加到map中,如果存在,则进行更新操作
map ++= map1
val map2 = map ++ map1
元组
- 类似于容器,最大只能有22个元素
// 定义
val tuple: (String, Int, Char, Boolean) = ("hello", 1, 'a', true)
//访问
println(tuple._1)
println(tuple._2)
println(tuple._3)
println(tuple._4)
println(tuple.rofuctElement(1))
// 遍历
for (elem <- tuple.profuctIterator)
println(elem)
// 元组嵌套
集合总结
属性与操作
- 获取集合长度
list.length
- 获取集合大小
list.size
- 循环遍历
for(elem <- list) println(elem)
- 迭代器
for (elem <- list.iterator) println(elem)
- 生成字符串
println(list)
println(list.mkString(","))
- 是否包含
list.contains(value)
衍生集合
val lsit1 = List(1, 3, 4, 5, 2, 89)
val lsit2 = List(3, 4, 2, 45, 19)
// 获取集合的头
list1.head
// 获取集合的尾-去掉头,返回为一个集合
list1.tail
// 集合最后一个数据-不停的去头,得到最后一个
list1.last
// 集合初始数据
list1.init
// 反转
list.reverse
// 前n
list1.take(n)
list1.takeRiget(n)
// 去掉前n
list1.drop(n)
list1.dropRight(n)
// 并集 等价于 ::: ,所有数据合并,如果时set则会去重
val union = list1.union(list2)
// 交集
val intersection = list1.intersect(list2)
// 差集
val diff = list1.diff(list2)
// 拉链-对应位置组合为元组,多余的去掉
list1.zip(list2)
// 滑窗,返回值为iterator类型,遍历后得到List
list1.sliding(size, step)
集合计算初级函数
val list = List(5,1,8,4,3)
// 求和
list.sum
// 求乘积
list.product
// 最大值
list.max
list.maxBy( _._2 )
// 最小值
list.min
// 排序
val sortedList = list.sorted
println(sortenList.reverse)
println(List.sorted(Ordering[Int].reverse))
list.sortBy( _._2 )(Ordering[Int].reverse)
list.sortWith( (a: Int, b: Int) => {
a < b
})
list.sortWith( _ > _ )
集合计算高级函数
116
// 过滤
filter
// 转化/映射(map)
map
// 扁平化
flatten
// 扁平化+映射
flatMap
// 分组(group)
group
// reduce
reduce,fold
// 其他
sortBy
sortWith
take
- e.g.
package scala
import scala.collection.mutable
/**
* @description:
* @author: shimmer
* @create: 2021/6/12 15:21
*/
object Demo10 {
def main(args: Array[String]): Unit = {
// 过滤与映射
val list: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9)
val res: List[Int] = list.filter(_ % 2 == 0).map(_*2)
res.foreach(println)
// 扁平化
val list1 = List(List(1, 2, 3), List(4, 5, 6), List(7, 8, 9))
val flattenList: List[Int] = list1.flatten
println(flattenList)
// 扁平映射
// flatMap->相当于先将集合map后得到新的集合,然后对新的集合做扁平化处理
// 分组groupBy
val group: Map[Int, List[Int]] = list.groupBy(_ % 2)
println(group)
// 规约reduce
val sum: Int = list.reduce(_ + _)
// reduce 底层使用的其实就是reduceLeft
list.reduceLeft(_ + _)
// reduceRight 底层实际上是一个递归调用,比如:(1 - (2 - (3 - 4)))
list.reduceRight(_ - _)
println()
// fold 规约,区别于reduce在于,他需要给定一个初始值,而reduce可以认为初始值就是集合第一个值
println(list.fold(9)(_ + _))
// e.g.
val map1: mutable.Map[String, Int] = mutable.Map("a" -> 1, "b" -> 2)
val map2: mutable.Map[String, Int] = mutable.Map("c" -> 1, "b" -> 3)
val map3: mutable.Map[String, Int] = map1.foldLeft(map2)(
(elem, kv) => {
val key: String = kv._1
val value: Int = kv._2
elem(key) = elem.getOrElse(key, 0) + value
elem
})
println(map3)
}
}
队列
def main(args: Array[String]): Unit = {
val queue = new mutable.Queue[String]()
queue.enqueue("a", "b", "c")
println(queue)
queue.dequeue()
println(queue)
// 不可变集合本身的改变没有意义
val queueIm = Queue[String]("d", "e", "f")
println(queueIm)
}
并行集合
println((1 to 10).map(elem => Thread.currentThread().getId))
println((1 to 10).par.map(elem => Thread.currentThread().getId))
8.模式匹配
- 类似于switch-case
def main(args: Array[String]): Unit = {
val int: Int = 2
val str: String = int match {
case 1 => "one"
case 2 => "two"
case 3 => "three"
case _ => "other"
}
println(str)
}
- case 模式守卫
- 元组的模式匹配
// 双冒号
val first :: second :: other = List(1, 2, 3, 4)
print(s"$first,$second,$other")
// 进阶用法
val tuples = List(("a", 1), ("b", 2), ("c", 3), ("a", 18))
for(("a", count) <- tuples) {
println("a" + "->" + count)
}
// 对象匹配
val stu = new Student("alice", 18)
val res = stu match {
case Student("alice", 18) => "alice, 18"
case _ => "else"
}
println(res)
object Student {
def apply(name: String, age: Int): Student = new Student(name, age)
def unapply(stu: Student): Option[(String, Int)] = {
if (stu == null) None else Some((stu.name, stu.age))
}
}
- 样例类
/**
* 样例类默认主构造器里的所有参数为类的属性,并且默认实现 apply() 与 unapply() 方法.new 关键字使用的是类,不使用 new 使用的是其伴生对象的 apply() 方法,所以使用样例类是可以不适用使用new,以为其默认实现了apply方法.如是说如果自定义的类没有实现他的伴生对象的 apply() 方法就只能通过 new 关键字创建对象.
*/
case class Student(name: String, age: Int)
- 偏函数

9.异常处理
- Scala 只有运行时异常
- 使用 throw 关键字抛出异常对象,所有异常都是 Throwable 的子类. throw 表达式是有类型的,为Nothing
- 使用 @throws 注解声明异常
def main(args: Array[String]): Unit = {
try{
val compute: Int = 10 / 0
} catch {
case e: ArithmeticException => e.printStackTrace()
case e: Exception => println("Exception")
} finally {
println("end")
}
}
10.隐式转换
- 当编译器第一次编译失败的时候,会在当前的环境中查找能让代码编译通过的方法,用于将类型进行转换,实现二次编译
object Demo13 {
def main(args: Array[String]): Unit = {
// 隐式类-只能定义为内部类
// implicit class MyInt(val num: Int) {
// def myMax(n: Int): Int = if (n < num) num else n
// def myMin(n: Int): Int = if (n < num) n else num
// }
// 隐式函数
implicit def convert(num: Int): MyInt2 = new MyInt2(num)
println(12.myMax(15))
println(18.myMax(15))
// 隐式参数: 隐式参数在底层实际上是一个柯里化的表达,即 sayHello() 本身是一个空参函数,然后通过柯里化传入一个隐式参数,
// sayHello(implicit name: String) 完整的写法应该是 sayHello()(implicit name: String),
// 所以,如果省略 函数本身的 () ,那么调用时也必须省略括号,如果函数本身的 () 没有省略,那么调用时可写可不写
// 另外,编译器在寻找隐式参数时,实际上是根据参数类型来寻找的,也就是说,在同一个作用域内,同一类型的隐式参数只能有一个
implicit val str: String = "alice"
def sayHello(implicit name: String): Unit = println(s"hello, $name")
sayHello
// 简化写法: 因为编译器不关心隐式参数的参数名,则可以以省略参数名,这里的 implicitly 是 preDef 里面定义好的方法
def sayHi(): Unit = println(s"hi, ${implicitly[String]}")
sayHi()
}
}
class MyInt2(val num: Int) {
def myMax(n: Int): Int = if (n < num) num else n
def myMin(n: Int): Int = if (n < num) n else num
}
11.泛型
// 1. 泛型的限定
// 上限
class Generic[T <: String]
// 下限
class Generic[T >: Int]
// 2. 上下文限定
def fun[A: B](a: A) = println(a)
// 就等于
def fun[A](a: A)(implicit arg: B[A]) = println(a)
- e.g.
object Demo14 {
def main(args: Array[String]): Unit = {
//协变[+E]: 父类泛型指向子类泛型
// val childList: MyCollection[Parent] = new MyCollection[Child]
//逆变[-E]: 子类引用泛型指向父类泛型
val parentList: MyCollection[Child] = new MyCollection[Parent]
// 泛型的限定
def test[A <: Child](a: A): Unit = println(a.getClass.getName)
test[Child](new Child())
}
}
class Parent {}
class Child extends Parent {}
// 定义泛型集合
class MyCollection[-E] {}