CloudCanal-2.0 自定义代码实时加工能力(自定义实时ETL)说明与介绍
简介
CloudCanal 2.0中我们将迎来一项重磅更新——自定义代码实时加工能力。自定义代码实时加工允许用户使用Java语言编写自定义的数据行处理逻辑,然后将代码jar包上传CloudCanal平台后,数据同步任务在执行全量、增量时会自动应用用户的自定义处理逻辑,然后再写入对端数据源。 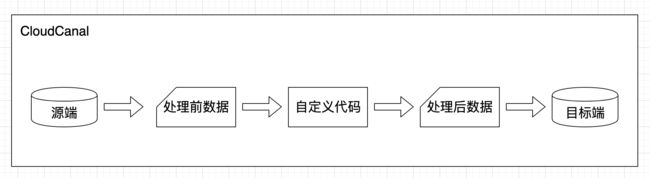
应用场景
自定义代码实时加工是一种非常灵活的实时数据加工手段,在自定义代码中用户可以进行跨实例查询、微服务调用、缓存查询等各种操作,然后对实时接收到的数据行进行编辑。数据编辑支持用户自定义新增行、修改行、删除行。其中修改行支持用户新增列、修改列、删除列。自定义代码实时加工可用于以下场景:
数据清洗
构建实时数仓、数据湖以及进行数据治理时都需要对数据进行清洗,涉及数据过滤、加工、标准化。在这个过程中,用户可以上传自定义代码,引入自己的一些企业内部数据标准化处理的二方包或者调用一些微服务或者反查数据库对收到的实时数据进行编辑。这样同步到对端后,就是直接已经清洗好的数据。 
宽表构建
数据同步到数仓、数据湖中时,必然面临的一个问题就是处理多个源端关联表的关系,引入自定义代码,可以很容易的来处理这些关系,生成对端数据源需要的宽表行。在CloudCanal平台上,我们会订阅一张主表,也就是多个关系中的主体,作为驱动表。这张表内的数据行在同步的时候是不完整的。构建一个写入到对端的宽表行,需要补足其中缺失的列,这些列也就是其他表中的数据。在自定义代码中,用户可以反查自己的数据库取到这些数据,组装成一个完整的宽表行,返回给CloudCanal,然后再写入对端。下面我们以一个具体的MySQL->ElasticSearch的同步来解释如何采用CloudCanal自定义代码功能完成宽表行构建。
源端表结构和数据
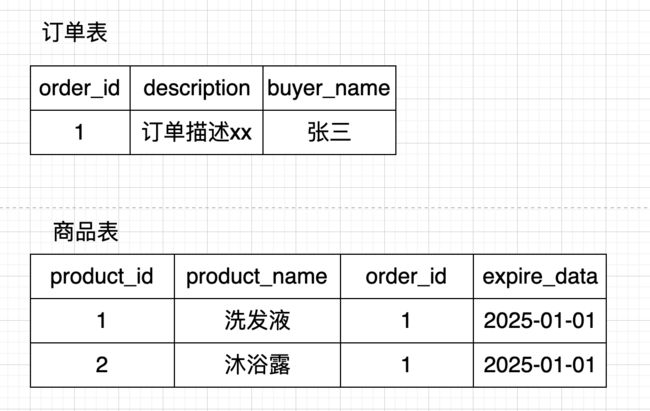
对端ES索引结构以及预期的宽表行数据
其中Field product_detail的类型为nested,保存订单和商品的一对多关系
具体的JSON Array信息如下,保存一个订单关联的所有商品的明细信息
{
"detail": [{
"product_id": 1,
"product_name": "洗发液",
"expire_data": "2025 - 01 - 01"
},
{
"product_id": 2,
"product_name": "沐浴露",
"expire_data": "2025 - 01 - 01"
}
]
}宽表行构建操作步骤
- ES索引创建一个订单商品索引,其中商品这个field采用NESTED类型
- CloudCanal订阅订单表(关系主体)
- 编写自定义代码,对于收到的订单表的行,取到其中的order_id信息,用于反查源端商品表(可以跨实例反查)
- 对收到的订单表的行,新增一个自定义列,保存关联的所有商品信息(以json array存储),生成宽表行
- 将宽表行写入到ES,完成数据写入
- 用户可以从ES订单商品索引中检索完整的包含关联商品明细的订单信息。
宽表行的构建过程可以参考下图: 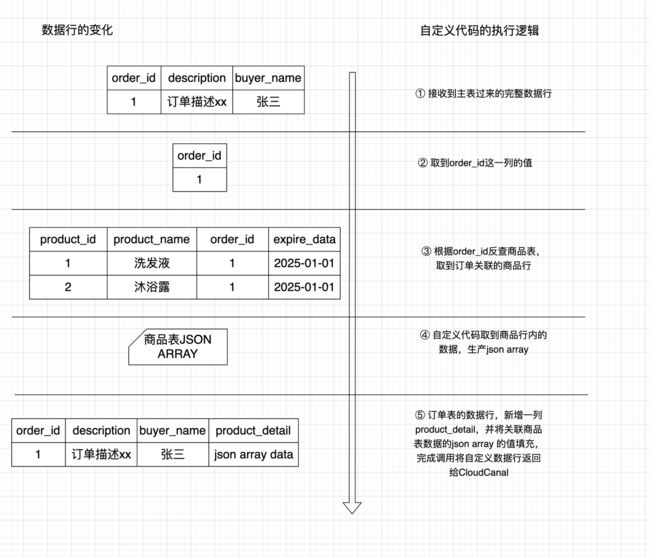
自定义_id列
CloudCanal写入ES的时候允许用户选择源端某些列作为对端自定义_id列。在创建任务数据处理阶段,在上传自定义代码包之后,在对端映射列的下拉选项中可以选择。对于ES而言,相同_id上的doc,再次写入的时候会以upsert的方式写入。例如_id=1的文档在ES中已经存在,则当一个新的文档(id=1)再次写入时,会将对应field执行update操作。这个特性主要用于确保:从表的更新也能及时反馈到对端的索引上。用户创建MySQL->ES的任务时,只需要设置_id为join的关联列。这样后续从表中的字段有更新时,可以根据join列在对端索引上进行更新。
只订阅不映射
自定义代码有时候需要依赖源端的列来进行计算,但是实际上不需要同步到对端。这时候可以在创建任务数据处理阶段,
常见问题1:主表发生变化,主动反查宽表,如果只是宽表字段发生变化,这种情况呢?怎么维护到es中对应的索引中?
答:CloudCanal宽表构建是基于主表触发的,一般而言,关联表也需要及时反馈的目标端有如下方式:新建一个任务,把原来任务反查的表(从表)作为主表,全部订阅。创建任务的时候指定自定义_id列为参与宽表构建的关联列,这样从表的更新都会在对端索引对应的文档上进行update。
数据汇聚
数据汇聚是当前用户构建数据中台、实时数仓等都会面临的问题。这里面主要涉及数据标准化、数据清理等工作。结合自定义代码,用户可以结合自己的数据标准化要求,自由的加工、拼接来自多个源端表内的数据,完成数据汇集的工作。
使用须知
- 新增列的值类型必须能支持转换成String: 现在不支持用户在自定义代码中指定列类型,当前CloudCanal将用户设置的Object值,都全部按照String处理,写入对端关系型数据库时指定的java sql type为varchar
- 全量、增量共享一个自定义代码包: 自定义代码包是整个任务级别共享的,全量、增量全部会使用自定义的代码包
- 源端不订阅的列,即使自定义代码中添加了也不会同步:源端订阅的表,如果某些字段没有被订阅,则会加入列黑名单。后续自定义代码中,如果自己再次新增了这个列,注意这个列也不会同步到对端,会被裁剪掉。
- 用于全量和增量实现不同,全量和增量自定义代码收到的列信息有所区别:全量是在自定义代码之后才进行列过滤,所以在自定义代码中会收到实际没有订阅的列的信息;增量是在自定义代码之前进行列过滤,自定义代码中收到的消息已经裁减掉没有订阅的列。
- 自定义代码处理的一批数据,如果需要写入关系型数据库,则列必须对齐:默认CloudCanal采用batch写入,如果一批数据中,有的x列,有的y列,批量写入不能共用一个SQL模板
- 自定义代码中如果新增行,则不支持DDL同步:例如源端执行新增列的DDL以后,源端过来的行全部会包含新增列的内容。但是自定义代码包中没有感知这个变化,所以新增的行仍然使用原来的列数。这就导致一批数据的列不对其,会直接被CloudCanal拦截
最佳实践
- 数据编辑请使用SDK提供的RecordBuilder操作,不要自己修改内部对象,可能导致不符合预期的结果
- 数据处理的时候不要随意改变List中Record的顺序,以免乱序引发数据不一致
SDK使用
顶级接口
SDK提供的接口比较简洁,用户在自定义代码中实现CloudCanalProcessor接口完成自定义逻辑即可。其中的process方法会将CloudCanal实时同步的一批数据吐给用户,由用户自定义的处理这些行。
public interface CloudCanalProcessor {
List process(List customRecordList, CustomProcessorContext customProcessorContext);
} 用户自定义处理上下文CustomProcessContext
顶级接口process包含一个入参CustomProcessContext,这个对象中包含了一个Map,保存CloudCanal传递个用户自定义处理器的上下文信息。其中的Key由SDK中的ContextKey的实现类指定。 
当前支持的Key主要如下,允许用户从context中直接获取CloudCanal帮助初始化好的源端和目标端的DataSource。针对关系型数据库,这个对象实际上是一个DruidDataSource,并且常驻在CloudCanal内存中,用户不需要自己close改数据源,改数据源会在运行时被重用。
public class RdbContextKey implements ContextKey {
public static final String SOURCE_DATASOURCE = "srcDataSource";
public static final String TARGET_DATASOURCE = "dstDataSource";
public RdbContextKey() {
}
}SDK支持的数据处理操作
- 修改行
- 新增列
- 删除列
- 修改已有列的列值
- 新增行
- 删除行
核心数据结构与元数据
用户需要处理的数据行对应的核心数据结构是CustomRecord。其中包含的内容主要如下。
private int opsFlag = 0; //操作标记位0表示不做任何处理,-1删除行,1新增行,2修改行,用户无需感知
private Set customAddFields = new LinkedHashSet(); //记录新增列的列名,内部元数据,用户无需感知
private CustomRecord.Coordination coordination; //记录CustomRecord关联的内部Record的坐标,用户无需感知
private Map recordMetaMap = new LinkedHashMap(); // 保存了数据行的元数据信息,例如消息来自源端哪个库哪个表
private Map fieldMapAfter = new LinkedHashMap();//记录变更后的列值
private Map fieldMapBefore = new LinkedHashMap();//记录变更前的列值 用户在具体使用时只要关心其中的recordMetaMap即可,其中的key值由SDK提供的类来给出。例如关系型数据库可以获取的meta信息均记录在RdbMetaKeys
public class RdbMetaKeys {
//数据行来源的db
public static final String DB_NAME = "dbName";
//数据行来源的schema
public static final String SCHEMA_NAME = "schemaName";
//数据行来源的tableName
public static final String TABLE_NAME = "tableName";
//数据行来源的action(全量固定为INSERT,增量为INSERT/UPDATE/DELETE)
public static final String ACTION_NAME = "actionName";
public RdbMetaKeys() {
}
}数据行编辑器
用户不需要关心CustomRecord内部元数据的管理,使用SDK提供的RecordBuilder可以完成对数据行的所有操作。RecordBuilder采用Builder模式实现,支持链式调用。熟悉Lombok的朋友应该很容易上手。值得注意的是,只有修改行相关的操作(修改列、新增列、删除列)才能 支持链式调用。操作完毕后直接返回CustomRecord对象。
他的接口定义如下:
/**
* 创建一个新的数据行,Map的key为列名,value为具体的值。
*/
RecordBuilder createRecord(Map fieldValueMap);
/**
* 删除当前RecordBuilder关联的数据行
*/
RecordBuilder deleteRecord();
/**
* 新增一个列
*/
RecordBuilder addField(String addFieldName, Object addFieldValue);
/**
* 新增多个列
*/
RecordBuilder addField( Map fieldValueMap);
/**
* 删除一个列
*/
RecordBuilder dropField(String dropFieldName);
/**
* 删除多个列
*/
RecordBuilder dropField( List dropFieldNames);
/**
* 更新已有的列的列值
*/
RecordBuilder updateField(Map fieldValueMap);
新增列的映射关系
在自定义代码中,用户往往会新增列。CloudCanal默认使用“同名映射规则”。因为新增的列是没有在创建任务的时候指定映射关系的,所以新增的列默认均使用同名映射规则。假设我新增的列为name,则CloudCanal认为该列也应该被写到对端的name字段中。因此,在自定义代码处理中,为了确保能正确写入对端,新增列的列名可以使用对端用户自己想要映射的列名,这样会直接写入对端。
具体使用步骤
创建RecordBuilder实例
- 新增Record需要使用RecordBuilder.RecordBuilder.createRecordBuilder(): createRecordBuilder 无参数
- 其他Record操作使用RecordBuilder.modifyRecordBuilder(customRecord): modifyRecordBuilder 方法接收一个参数,传递需要处理的customRecord
调用RecordBuilder实例提供的处理方法
使用RecordBuilder提供的方法,可以完成列的增删改、行的新增与删除。
处理完毕后使用build方法生成最终的CustomRecord
使用RecordBuilder完成一系列操作后,可以调用build,生成最终的CustomRecord对象
详细的示例可以参考《使用案例》章节提供的示例代码
如何调试自定义代码
建议部署测试环境和生产环境的CloudCanal,仅在测试环境开启debug模式,调试自定义代码。
代码debug
- 先正常创建一个自定义代码处理的同步任务,并且设置不要自动启动
- 点击功能列表选择修改参数,设置debugMode=true,并且设置调试端口debugPort(端口只允许设置范围为8787-8797之间的端口号)


- 在IDE中以远程debug模式启动(我们以IDEA为例)
- 右上角新增启动配置
- 选择Remote JVM Debug -填 写ip地址(容器所在宿主机ip)和端口,远程调试端口为8787



- 在CloudCanal平台上启动任务
- 进入自定义代码断点后即可进行调试
- 【重要!!】调试完毕后请重新修改参数debugMode=false并重启任务,否则该任务会无法正常执行
自定义处理代码日志
用户自定义代码中使用如下方式定义logger后,可以在指定路径下查看日志。日志路径为:/home/clougence/logs/cloudcanal/tasks/${taskName}/custom_processor.log
private static final String LOG_NAME = "custom_processor";
private static final Logger customLogger = LoggerFactory.getLogger(LOG_NAME);debug日志
在任务详情页可以打开参数设置,开启自定义代码的debug日志,这样代码处理前后的数据内容会进行完整的打印,这会占用较多磁盘空间和影响性能,线上环境慎用。日志会打印在任务日志路径下的custom_process.log中 
如何自定义类名
样例工程中的resource目录下的内容是打包自定义处理插件必备的。如果需要修改类名,可以修改resource/META-INF/cloudcanal/plugin.properties中的类名,需要使用全限定名称。 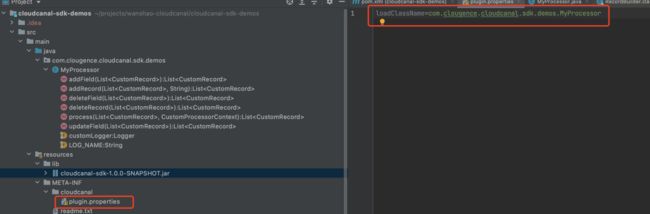
创建自定义代码包任务
创建任务
在创建任务的第四步,数据处理,可以选择配置数据处理插件 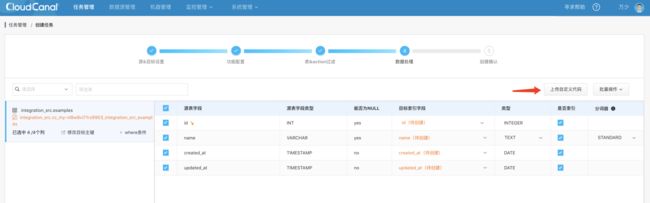 然后选择上传代码包
然后选择上传代码包 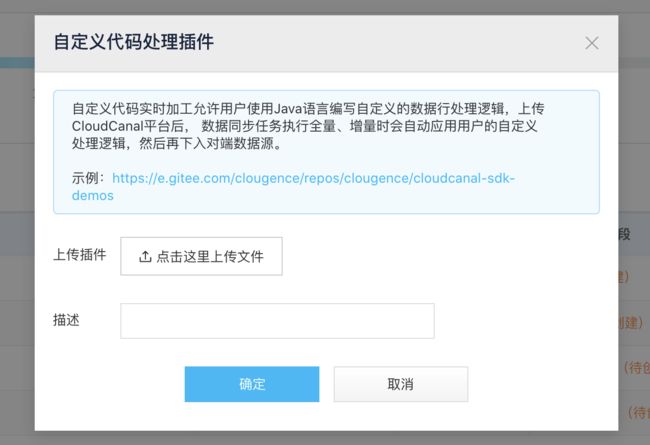
代码包管理
任务完成创建后,可以在页面管理自己的代码包 
Tips:
- 全量和增量阶段共享一个代码包
- 激活的代码包重启后才会生效
使用案例
案例一:数据基本处理
本次我们以MySQL->MySQL的数据同步为例,包含结构迁移、全量迁移和增量实时同步。
准备的表结构如下:
/* -- 学生表 --*/
CREATE TABLE `student` (
`id` int(4) NOT NULL AUTO_INCREMENT COMMENT '学号',
`name` varchar(20) DEFAULT NULL COMMENT '名字',
`score` int(3) NOT NULL COMMENT '成绩',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=27 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='学生信息表'我们的数据加工需求如下:
修改行
新增列
针对过来的所有数据,都进行新增列的操作。新增的列名字分别为col_varchar和col_int,列值分别为null和9999
修改列
针对来自源端integration_src库和源端student表的行,才进行修改列的操作。把分数为0的同学改为分数99
删除列
针对来自源端integration_src库和源端student表的行,才进行删除列的操作。针对这一批的所有数据,删除name这一列
新增行
每一批数据过来时,满足业务判断条件,则新增两行新的数据,主键采用自增id。新增的两行同时包含两个自定义的新增列,但是不包含name列。 
删除行
针对来自源端integration_src库和源端student表的行,如果分数小于60的行则会被删除
源表数据
| id | name | score |
|---|---|---|
| 1 | 万少 | 90 |
| 2 | update99 | 0 |
| 7 | 张删 | 50 |
| 8 | 张删 | 30 |
| 9 | 万少 | 10 |
| 10 | 万少 | 10 |
| 11 | 布丁 | 0 |
| 12 | 布丁 | 0 |
| 16 | 万少 | 0 |
| 17 | 张删 | 0 |
| 25 | 万少 | 77 |
| 26 | need99 | 0 |
预期对端同步后的数据
| id | name | score | col_varchar | col_int |
|---|---|---|---|---|
| 1 | NULL | 90 | NULL | 9999 |
| 2 | NULL | 99 | NULL | 9999 |
| 11 | NULL | 99 | NULL | 9999 |
| 12 | NULL | 99 | NULL | 9999 |
| 16 | NULL | 99 | NULL | 9999 |
| 17 | NULL | 99 | NULL | 9999 |
| 25 | NULL | 77 | NULL | 9999 |
| 26 | NULL | 99 | NULL | 9999 |
| 1637224973 | NULL | 100 | new_varchar_value | 9999 |
| 1637224975 | NULL | 100 | new_varchar_value | 9999 |
示例代码&SDK下载
参考示例代码:https://gitee.com/clougence/cloudcanal-sdk-demos/tree/master
TIPS: 当前SDK直接集成在demo工程内,后续会独立出来
用户落地案例
- CloudCanal自定义代码助力德勤乐融MySQL同步ES构建宽表场景
- CloudCanal助力万店掌MySQL
FAQ
- 传递给自定义代码处理的一批数据的顺序怎样?是否来自多个表?答:传递给用户的一批数据会包含来自多个表的数据。自定义代码的处理现在是并行化的,也就是源端变更会变成多个批次,由多个并行的用户自定义processor处理。虽然是并行化处理的,但是整体上数据行的顺序仍然是保序的,只是针对每一批的数据处理是并行的。
社区快讯
我们创建 CloudCanal 微信粉丝群啦,在里面,你可以得到最新版本发布信息和资源链接,你能看到其他用户一手评测、使用情况,你更能得到热情的问题解答,当然你还可以给我们提需求和问题。快快加入吧。
扫描下方二维码,添加我们小助手微信拉您进群,接头语(“加 CloudCanal 社区群”)
加入CloudCanal粉丝群掌握一手消息和获取更多福利,请添加我们小助手微信:suhuayue001
CloudCanal-免费好用的企业级数据同步工具,欢迎品鉴。 了解更多产品可以查看官方网站: http://www.clougence.com CloudCanal社区:https://www.askcug.com/