深入跨域 - 从初识到入门 | 京东物流技术团队
前言
跨域这两个字就像一块狗皮膏药一样黏在每一个前端开发者身上,无论你在工作上或者面试中无可避免会遇到这个问题。如果在网上搜索跨域问题,会出现许许多多方案,这些方案有好有坏,但是对于阐述跨域的原理和在什么情况下需要用什么方案,缺少系统性的说明。大家在工作中可能因为大佬们已经配置好了,不会产生跨域,但是作为一个前端的开发人员,面对跨域的问题,还是需要从原理上去理解跨域的原因,在不同的情况中,我们该如何去处理。
1 业务场景
1.1 介绍
WMS6.0是一款专门为仓储业务打造的合作开发平台,前台BP可以独立开发或者定制现有的流程,接入到WMS6.0中,实现自定义业务,使前台BP只需要关注自己的业务,不用专注其他功能,提升前台BP的开发效率。。
作为一个合作平台,WMS6.0 PC端支持独立页面扩展和页面内部功能扩展,支持前台BP可以进行独立部署,实现最大程度的解耦。接入方案如下:
- 独立页面扩展,以完全独立业务模块的方式接入。针对部分合作方需要自己完全独立开发页面的情况,WMS6.0提供了微前端的框架进行接入。
- 页面内部功能扩展,以预留插槽的方式接入。如图1中标注部分所示,整体页面被划分为多个区域,其中包含了通用的数据模块 + bp接入模块。当合作方有个性化的数据统计需求时,可以进行独立开发,然后接入现有公用页面中。
在bp接入平台的过程中,我们遇到了各种各样的问题,如前后端如何联调、如何在不冲突的情况下自定义全局属性、如何部署上线等等,下面我们主要就前后端联调中遇到的跨域问题进行讨论。
在使用上述预留插槽的接入方式时,为了通用模块与接入模块之间的数据同步等方便进行,WMS6.0中并没有使用老式的iframe,而是采用了vue注册的方式,实现在同一个页面中加载。因此合作方在独立模块中发起的服务端请求,其来源其实仍是当前通用页面。
而WMS6.0并不能确保所有的合作方服务端均在同一个域名下,由此也就产生了各种交互问题。
1.2 wms6.0请求链路

我们先来看一下WMS6.0现有的通用网络请求整体链路。
当用户触发了网络请求,会通过基站或者仓库的路由发出,然后通过网络到达物流网关,物流网关把请求转发到Nginx,Nginx会把请求分发到具体的服务器上进行数据处理。
下面我们就抽取一个WMS6.0通过物流网关访问的请求,作为实例来看一下。
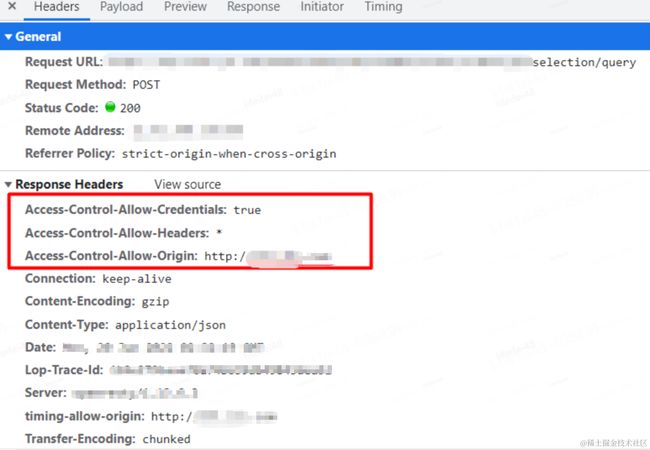
通过response Headers(相应头)我们可以看到,公司现有的物流网关会对指定域名的页面进行CORS跨域处理。通过Access-Control-Allow-Origin: http://a..com,我们可以知道物流网关可以接受来自指定域 http://a..com 的跨域资源请求,不会产生跨域报错。
但是咱们部分bp合作方的接口并不是通过物流网关的,这就需要我们自己对此类接口进行跨域处理了。假如没有进行跨域处理,那么就会报下面的错了。
1.3 跨域的产生
- Access to XMLHttpRequest at ‘’ from origin '’ has been blocked by CORS policy
- Response to preflight request doesn’t pass access control check
- No ‘Access-Control-Allow-Origin’ header is present on the requested resource.

**报错解析:**
从源“本地路径”访问 “目标路径(请求链接)”的文本传输请求已被CORS策略阻塞:对预检请求的响应未通过访问控制检查。请求的资源上不存在’Access- control - allow - origin '报头。
错误原因:
本地路径和目标路径不在同一个域名下引起的跨域问题。
同时需要注意的是,就算两个域名是同一个二级域名、不同三级域名的时候,例如 a.baidu.com 和 b.baidu.com ,也是属于不同域的,仍会出现这个问题。
那么到底什么是跨域,跨域既然影响了我们的开发工作,那又为什么要有对跨域的限制呢?下面让我们来了解一下跨域的历史产生原因和作用吧。
2 跨域
2.1 演变史
以下内容为个人猜测,仅供参考,勿喷
- **第一阶段**
互联网始于1969年的美国。在互联网的最早期,美军在ARPA(阿帕网,美国guofang部研究计划署)制定的协定下,首先用于军事连接。
随后主要都是美国高校连入的网络,如美国西南部的加利福尼亚大学洛杉矶分校、斯坦福大学研究学院、UCSB(加利福尼亚大学)和犹他州大学的四台主要的计算机。服务器上存放的都是公开资料。
这个时候网站更像是一个公共图书馆,账户密码都没有,更没存放着什么机密资料
- 第二阶段
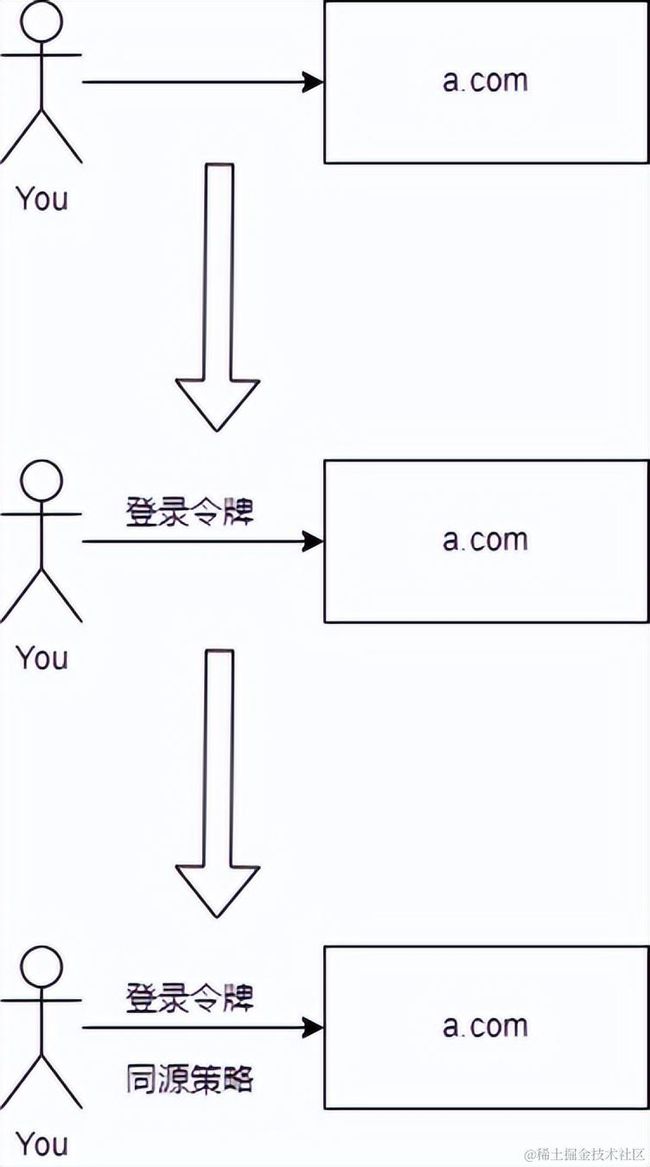
后来,有人觉得可以在上面放一些私人资料,私人信息。于是为了安全,便有了账户和密码。可是如果每次访问都需要输入账户和密码,是一件很烦的事情。
所以浏览器实现了cookie,用来存储用户登陆的账户和密码。当用户访问了曾经已经登陆过的网站,浏览器将会自动在请求中加入账户和密码,而账户和密码通常是通过 Request Header(请求头) 中的cookie或指定的头信息进行通信的。
而直接存储账户和密码太过于危险,如果被攻破,损失相当大。所以浏览器都不直接存储账户和密码,而是存储登陆令牌。
- 第三阶段 - 现代浏览器同源策略
但是存储登陆令牌也有一个问题,如果你登陆了某个流氓网站,同时这个流氓网站在它的JS里访问了你已经登录的其他网站,那么就能够拿到你已经登录的其他网站里面的一些重要数据。
所以浏览器为了安全是不能够让这个流氓网站访问你已经登录的其他网站的。由此产生了浏览器的同源策略:哪里来的,就只能访问哪里的数据。
综上,我们就可以基本了解对跨域的定义了,如下:
2.2 定义
跨域是指向一个与当前页面所在域不同的目标地址发送请求的过程,这样之所以会产生跨域报错是因为浏览器的同源策略限制。看起来同源策略影响了我们开发的顺畅性。实则不然,同源策略存在的必要性之一是为了隔离攻击。
MDN上对同源策略的解释为:
同源策略限制了从同一个源加载的文档或脚本如何与来自另一个源的资源进行交互。这是一个用于隔离潜在恶意文件的重要安全机制。
下面就拿同源策略隔离的主要攻击之一CSRF为例讲述下同源策略存在的必要性:
2.3 举例说明重要性-跨站请求伪造(CSRF)
CSRF,cross-site request forgery,又称跨站请求伪造,指非法网站挟持用户cookie在已登陆网站上实施非法操作的攻击,这是基于部分页面使用cookie在网站免登和用户信息留存。
正常网站免登的请求流程如下:
- 我们进入一个网站,发送登陆请求给后端
- 后端接受登陆请求,判断登陆信息是否准确
- 判断信息准确后,后端会发送response给浏览器
- 浏览器接受response返给用户,并将response header中的set-cookie进行保存。或者cookie通过报文返回,进而使用脚本进行缓存
- 用户关闭当前网站窗口后再次打开时,浏览器会自动将cookie加入request header实现免登
**受攻击场景:**
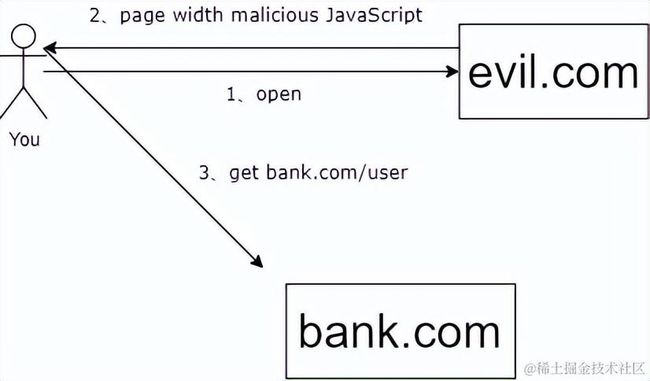
bank.com网站是一家银行,在用户登录以后,bank.com网站在用户的当前终端上设置了一个Cookie,这其中包含了一些隐私信息(比如存款金额)。
如果这个时候,七大姑在社交app上给你发了一篇养生文章链接,其实这个网页是个diaoyu网站evil.com,访问链接后就把你重定向到一个嵌入了 iframe 的攻击网站。
而这个时候如果没有跨域限制,这个iframe会自动加载银行网站的留存信息,读取到bank.com网站的Cookie,那么用户的信息就会泄露,更可怕的是,Cookie往往是用来保存用户的登录状态,如果用户没有退出登录,其他的网站就可以冒充用户,为所欲为,控制 iframe 的 DOM,通过一系列骚操作把你卡里的钱转走。
**没有同源策略:**
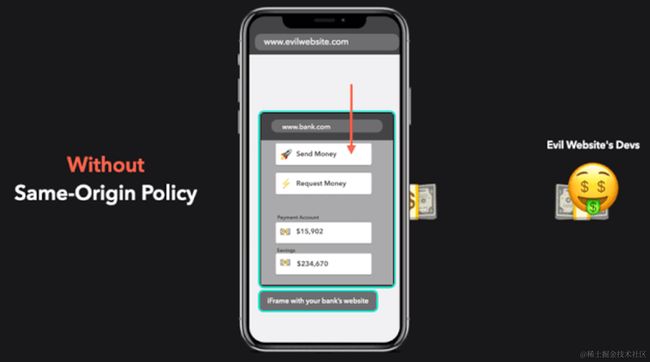
**有同源策略:**

而同源策略,也就是跨域限制的出现,限制了cookie的命名区域,使攻击者无法直接获取cookie的内容本身。
下面就让我们一起来了解一下什么是同源策略。
3 url的组成
在了解同源策略之前,我们需要先对一个url的各个组成部分进行初步了解:

- 协议部分:该URL的协议部分为“http:”,这代表网页使用的是什么通信协议。在Internet中可以使用多种协议,如HTTP、HTTPS、FTP等等。本例中使用的是HTTP协议。在"HTTP"后面的“//”为分隔符。
- 域名部分:该URL的域名部分为“www.a.com”。一个URL中,也可以使用IP地址作为域名使用。
- 端口部分:跟在域名后面的是端口,域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口,http为80,https为443,FTP为21。
- 虚拟目录部分:从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。本例中的虚拟目录是“/news/”。
- 文件名部分:从域名后的最后一个“/”开始到“?”为止,是文件名部分。如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分。如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。本例中的文件名是“index.html”。文件名部分也不是一个URL必须的部分。
- 参数部分:从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询字符串。本例中的参数部分为“boardID=5&ID=24618&page=1”。查询字符串中允许有多个参数,参数与参数之间用“&”作为分隔符。
- 锚部分:从“#”开始到最后,都是锚部分。本例中的锚部分是“name”。锚部分也不是一个URL必须的部分。
以上,我们已经大致了解了一个url的基本组成。
4 同源策略(SOP - same origin policy)
它是由 Netscape(美国网景公司) 提出的一个重要的安全策略,现在所有支持 JavaScript 的浏览器都会使用这个策略。
4.1 作用
同源策略作为浏览器安全的基石,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,则浏览器的正常功能可能都会受到影响,如个人信息将不再具有安全性。可以说 Web 是构建在同源策略基础之上的,浏览器只是针对同源策略的一种实现。
它的核心就在于它认为自任何站点加载的内容都是不安全的。当被浏览器半信半疑的脚本运行在沙箱时,它们应该只被允许访问来自同一站点的资源,而不是那些来自其它站点可能怀有恶意的资源。
因此,出于安全原因,对于跨源HTTP请求,浏览器禁止发起请求,或者允许发起请求,服务端也能收到请求并正常返回结果,但是浏览器会对返回结果进行拦截。 例如,XMLHttpRequest 和Fetch API 遵循同源策略,这意味着使用这些API的Web应用程序只能从加载应用程序的同一个域请求HTTP资源,除非服务器同意访问。譬如服务器对预检请求的响应 Header 中有 Access-Control-Allow-Origin: *,那么跨域请求即可正确访问。
简单来说,同源策略就是浏览器的一个安全限制,它阻止了不同【域】之间进行的数据交互。
那么是如何定义一个请求是否满足同源要求的呢?
4.2 同源的判断标准
- 协议相同
- 域名相同
- 端口相同
4.3 跨域示例
| URL | 说明 | 是否允许通信 |
|---|---|---|
| http://www.a.com/a.jshttp://www.a.com/b.js | 同一域名,不同路径 | 允许 |
| http://www.a.com:8080/a.jshttp://www.a.com/a.js | 同一域名,不同端口 | 不允许 |
| http://www.a.com/a.jshttps://www.a.com/a.js | 同一域名,不同协议 | 不允许 |
| http://www.a.comhttp://www.b.com | 域名不同 | 不允许 |
| http://www.a.com/a.jshttp://script.a.com/a.js | 主域相同,子域不同 | 不允许 |
4.4 同源策略的限制内容
- 禁止跨域操作DOM,也就是无法接触非同源网页的 DOM。
- 禁止跨域资源请求,也就是无法向非同源地址发送 AJAX 请求(可以发送,但浏览器会拒绝接受响应)。
- 禁止跨域读取 Cookie、LocalStorage,也就是无法读取非同源网页的 Cookie、LocalStorage。
4.5 允许跨域的情况
另外,我们知道通过 JavaScript 脚本可以拿到其他窗口的window对象。如果是非同源的网页,目前允许一个窗口可以接触其他网页的window对象的九个属性和四个方法。
- window.closed - 只读,判断当前窗口是否关闭
- window.frames - 只读,获取窗口中所有命名的框架
- window.length - 只读,获取当前窗口中frames的数量(包括iframes)
- window.location - 可读写。非同源的情况下,只允许调用location.replace()方法和写入location.href属性
- window.opener - 只读,获取对创建该窗口的window对象的引用
- window.parent - 只读,父窗口
- window.self - 只读,对自己的引用,window.window == window.self
- window.top - 只读,获取最顶层窗口对象的引用
- window.window - 只读,对自己的引用,window.window == window
- window.blur() - 失焦
- window.close() - 关闭当前窗口
- window.focus() - 聚焦当前窗口
- window.postMessage() - 跨域通信API
4.6 允许跨域加载资源的标签

5 跨域解决方案一览图

6 后续
综上,我们完成了对跨域的初识,后面我们将对跨域的解决方案进行探讨,从上述的九种跨域解决方案进行一一描述,敬请期待。
作者:京东物流 李菲菲
来源:京东云开发者社区 自猿其说Tech 转载请注明来源