数据结构和算法-知识点总结
简介
从广义上讲,数据结构就是指一组数据的存储结构,算法就是操作数据的一组方法。
从狭义上讲,是指某些著名的数据结构和算法,比如队列、栈、堆、二分查找、动态规划等。我们要讲的这些经典数据结构和算法,都是前人智慧的结晶,是前人从很多实际操作场景中抽象出来的,经过非常多的求证和检验,可以高效地帮助我们解决很多实际的开发问题。
数据结构和算法是相辅相成的。数据结构是为算法服务的,算法要作用在特定的数据结构之上。 因此,我们无法孤立数据结构来讲算法,也无法孤立算法来讲数据结构。比如,因为数组具有随机访问的特点,常用的二分查找算法需要用数组来存储数据。但如果我们选择链表这种数据结构,二分查找算法就无法工作了,因为链表并不支持随机访问。
数据结构是静态的,它只是组织数据的一种方式。如果不在它的基础上操作、构建算法,孤立存在的数据结构就是没用的。
常用的10 个数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie 树;
常用的10 个算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法。
学习方法
- 边学边练,适度刷题
- 多问、多思考、多互动
- 打怪升级学习法
- 知识需要沉淀,不要想试图一下子掌握所有
复杂度
复杂度也叫渐进复杂度,包括时间复杂度和空间复杂度,用来分析算法执行效率与数据规模之间的增长关系
常见的复杂度并不多,从低阶到高阶有:O(1)、O(logn)、O(n)、O(nlogn)、O(n2 ),越高阶复杂度的算法,执行效率越低。
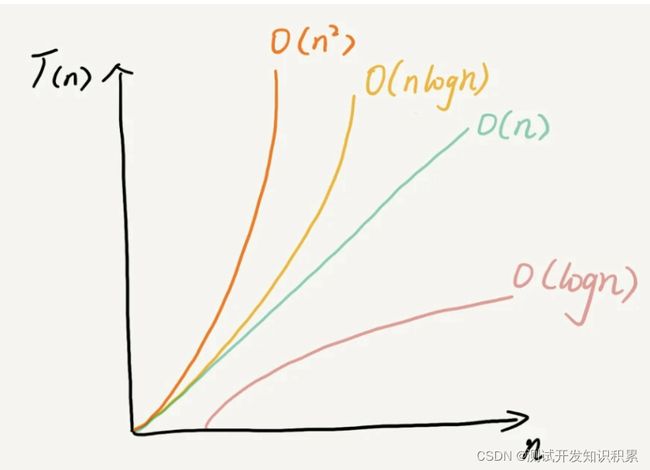
虽然把代码跑一遍,通过统计、监控等得到算法执行的时间和占用的内存大小(这种评估算法执行效率的方法叫做事后统计法),但是这种统计方法有非常大的局限性,1. 测试结果非常依赖测试环境。2. 测试结果受数据规模的影响很大。所以,我们需要一个不用具体的测试数据来测试,就可以粗略地估计算法的执行效率的方法。
大 O 复杂度表示法
假设每行代码对应的 CPU 执行的个数、执行的时间都一样,为 unit_time
int cal(int n) {
int sum = 0; //unit_time
int i = 1; //unit_time
for (; i <= n; ++i) { // n*unit_time
sum = sum + i; // n*unit_time
}
return sum;
}
这段代码总的执行时间 T(n) = (2n+2)*unit_time,可以看出来,所有代码的执行时间 T(n) 与每行代码的执行次数成正比。
又比如:
int cal(int n) {
int sum = 0;
int i = 1;
int j = 1;
for (; i <= n; ++i) {
j = 1;
for (; j <= n; ++j) {
sum = sum + i * j;
}
}
}
这段代码总的执行时间 T(n) = (2n^2+2n+3)*unit_time
总结公式:大 O 时间复杂度表示法
T(n) 表示代码执行的时间;n 表示数据规模的大小;
f(n) 表示每行代码执行的次数总和。
O表示代码的执行时间 T(n) 与 f(n) 表达式成正比。
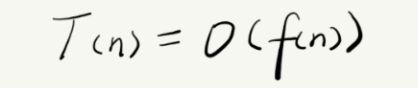
当 n 很大时, T(n) 公式中的低阶、常量、系数三部分并不左右增长趋势,可以忽略。我们只需要记录一个最大量级就可以了,如果用大 O 表示法表示刚讲的那两段代码的时间复杂度,就可以记为:T(n) = O(n); T(n) = O(n^2)。
n^2表示n的平方
时间复杂度分析
一、时间复杂度计算规则:
1、基本操作,即只有常数项,认为时间复杂度是O(1)
int i = 8;
int j = 6;
int sum = i + j;
代码的执行时间不随 n 的增大而增长,这样代码的时间复杂度我们都记作 O(1)。
一般情况下,只要算法中不存在循环语句、递归语句,即使有成千上万行的代码,其时间复杂度也是Ο(1)。
2、只关注循环执行次数最多的一段代码
int cal(int n) {
int sum = 0;
int i = 1;
for (; i <= n; ++i) { // 循环执行次数最多的是第 4、5 行代码
sum = sum + i;
}
return sum;
}
T(n) = O(n)
3、加法法则:总复杂度等于量级最大的那段代码的复杂度
int cal(int n) {
int sum_1 = 0;
int p = 1;
for (; p < 100; ++p) {
sum_1 = sum_1 + p;
}
int sum_2 = 0;
int q = 1;
for (; q < n; ++q) {
sum_2 = sum_2 + q;
}
int sum_3 = 0;
int i = 1;
int j = 1;
for (; i <= n; ++i) { // 量级最大的那段代码
j = 1;
for (; j <= n; ++j) {
sum_3 = sum_3 + i * j;
}
}
return sum_1 + sum_2 + sum_3;
}
T(n) = O(n^2)
4、乘法法则:嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
int cal(int n) {
int ret = 0;
int i = 1;
for (; i < n; ++i) { // T2(n)
ret = ret + f(i); // 嵌套
}
}
int f(int n) {
int sum = 0;
int i = 1;
for (; i < n; ++i) { // T1(n)
sum = sum + i;
}
return sum;
}
T(n) = T1(n) * T2(n) = O(n*n) = O(n2)
5、对数阶时间复杂度:O(logn)、O(nlogn)
i=1;
while (i <= n) {
i = i * 2;
}
从代码中可以看出,变量 i 的值从 1 开始取,每循环一次就乘以 2。当大于 n 时,循环结束。实际上,变量 i 的取值就是一个等比数列。

所以,我们只要知道 x 值是多少,就知道这行代码执行的次数了。通过 2^x=n 求解 x ,x=log2n,所以,这段代码的时间复杂度就是O(log2n)。
i=1;
while (i <= n) {
i = i * 3;
}
这段代码的时间复杂度就是O(log3n)。
对数之间是可以互相转换的,log3n 就等于 log3 2 * log2n,所以 O(log3n) = O(C * log2n),其中 C=log32 是一个常量。基于我们前面的一个理论:在采用大 O 标记复杂度的时候,可以忽略系数,即 O(Cf(n)) = O(f(n))。所以,O(log2n) 就等于 O(log3n)。因此,在对数阶时间复杂度的表示方法里,我们忽略对数的“底”,统一表示为 O(logn)。
6、O(m+n)、O(m*n)
代码的复杂度由两个数据的规模来决定
int cal(int m, int n) {
int sum_1 = 0;
int i = 1;
for (; i < m; ++i) {
sum_1 = sum_1 + i;
}
int sum_2 = 0;
int j = 1;
for (; j < n; ++j) {
sum_2 = sum_2 + j;
}
return sum_1 + sum_2;
}
二、几种常见时间复杂度

复杂度量级分类:多项式量级和非多项式量级,其中非多项式量级只有两个:O(2^n) 和 O(n!)。
非多项式量级的算法问题叫作 NP(Non-Deterministic Polynomial,非确定多项式)问题。当数据规模 n 越来越大时,非多项式量级算法的执行时间会急剧增加,求解问题的执行时间会无限增长。所以,非多项式时间复杂度的算法其实是非常低效的算法。
三、
空间复杂度分析
void print(int n) {
int i = 0;
int[] a = new int[n];
for (i; i <n; ++i) {
a[i] = i * i;
}
for (i = n-1; i >= 0; --i) {
print out a[i]
}
}
第 2 行代码中,我们申请了一个空间存储变量 i,但是它是常量阶的,跟数据规模 n 没有关系,所以我们可以忽略。第 3 行申请了一个大小为 n 的 int 类型数组,除此之外,剩下的代码都没有占用更多的空间,所以整段代码的空间复杂度就是 O(n)。
我们常见的空间复杂度就是 O(1)、O(n)、O(n2 ),像 O(logn)、O(nlogn) 这样的对数阶复杂度平时都用不到。
最好、最坏情况时间复杂度
// n表示数组array的长度
int find(int[] array, int n, int x) {
int i = 0;
int pos = -1;
for (; i < n; ++i) {
if (array[i] == x) {
pos = i;
break;
}
}
return pos;
}
在数组中查找一个数据,要查找的变量 x 可能出现在数组的任意位置。如果数组中第一个元素正好是要查找的变量 x,那就不需要继续遍历剩下的 n-1 个数据了,那时间复杂度就是 O(1)。但如果数组中不存在变量 x,那我们就需要把整个数组都遍历一遍,时间复杂度就成了 O(n)。所以,不同的情况下,这段代码的时间复杂度是不一样的。
为了表示代码在不同情况下的不同时间复杂度,我们需要引入三个概念:最好情况时间复杂度、最坏情况时间复杂度和平均情况时间复杂度。
最好情况时间复杂度就是,在最理想的情况下,执行这段代码的时间复杂度。
最坏情况时间复杂度就是,在最糟糕的情况下,执行这段代码的时间复杂度。
平均情况时间复杂度
最好情况时间复杂度和最坏情况时间复杂度对应的都是极端情况下的代码复杂度,发生的概率其实并不大。为了更好地表示平均情况下的复杂度,我们需要引入另一个概念:平均情况时间复杂度,后面我简称为平均时间复杂度。
// n表示数组array的长度
int find(int[] array, int n, int x) {
int i = 0;
int pos = -1;
for (; i < n; ++i) {
if (array[i] == x) {
pos = i;
break;
}
}
return pos;
}
要查找的变量 x 在数组中的位置,有 n+1 种情况:在数组的 0~n-1 位置中和不在数组中。我们把每种情况下,查找需要遍历的元素个数累加起来,然后再除以 n+1,就可以得到需要遍历的元素个数的平均值,即:
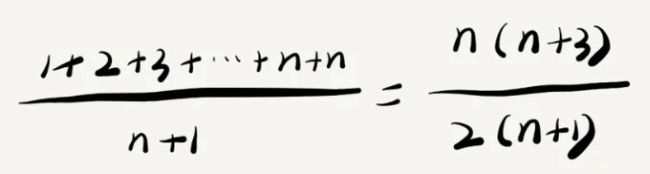
时间复杂度的大 O 标记法中,可以省略掉系数、低阶、常量,这个公式简化之后,得到的平均时间复杂度就是 O(n)。
按元素出现的概率算。要查找的变量 x,要么在数组里,要么就不在数组里,概率为1/2。数据出现在0到n-1位置的概率为1/n,所以,根据概率乘法法则,要查找的数据出现在 0~n-1 中任意位置的概率就是 1/(2n)。
如果我们把每种情况发生的概率也考虑进去,那平均时间复杂度的计算过程就变成了这样:
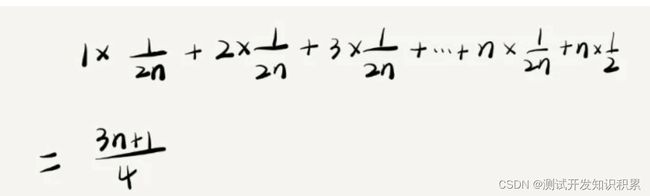
这个值就是概率论中的加权平均值,也叫作期望值,所以平均时间复杂度的全称应该叫加权平均时间复杂度或者期望时间复杂度。
均摊时间复杂度
大部分情况下,我们并不需要区分最好、最坏、平均三种复杂度。平均复杂度只在某些特殊情况下才会用到,而均摊时间复杂度应用的场景比它更加特殊、更加有限。
对一个数据结构进行一组连续操作中,大部分情况下时间复杂度都很低,只有个别情况下时间复杂度比较高,而且这些操作之间存在前后连贯的时序关系,这个时候,我们就可以将这一组操作放在一块儿分析,看是否能将较高时间复杂度那次操作的耗时,平摊到其他那些时间复杂度比较低的操作上。而且,在能够应用均摊时间复杂度分析的场合,一般均摊时间复杂度就等于最好情况时间复杂度。
尽管很多数据结构和算法书籍都花了很大力气来区分平均时间复杂度和均摊时间复杂度,但其实我个人认为,均摊时间复杂度就是一种特殊的平均时间复杂度,我们没必要花太多精力去区分它们。你最应该掌握的是它的分析方法,摊还分析。至于分析出来的结果是叫平均还是叫均摊,这只是个说法,并不重要。
用空间换时间、时间换空间设计思想
当内存空间充足的时候,如果我们更加追求代码的执行速度,我们就可以选择空间复杂度相对较高、但时间复杂度相对很低的算法或者数据结构。相反,如果内存比较紧缺,比如代码跑在手机或者单片机上,这个时候,就要反过来用时间换空间的设计思路。
对于执行较慢的程序,可以通过消耗更多的内存(空间换时间)来进行优化;而消耗过多内存的程序,可以通过消耗更多的时间(时间换空间)来降低内存的消耗。
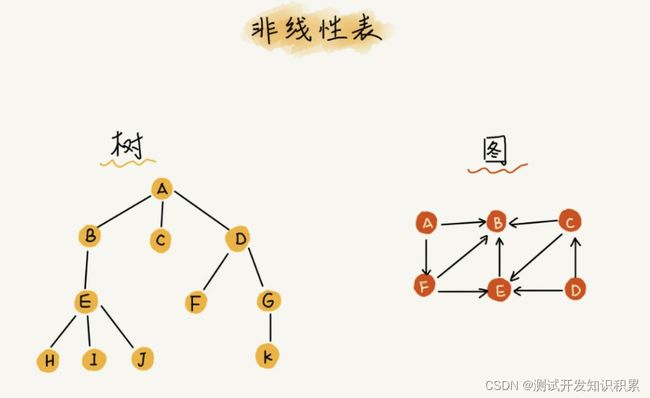
线性表、非线性表
线性表就是数据排成像一条线一样的结构。每个线性表上的数据最多只有前和后两个方向。数组、链表、队列、栈等都是线性表结构。

非线性表,比如二叉树、堆、图等。之所以叫非线性,是因为,在非线性表中,数据之间并不是简单的前后关系。
数据结构-数组
数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
数组中的数据可以随机访问,因为它有连续的内存空间。但是要想在数组中删除、插入一个数据,为了保证连续性,就需要做大量的数据搬移工作。
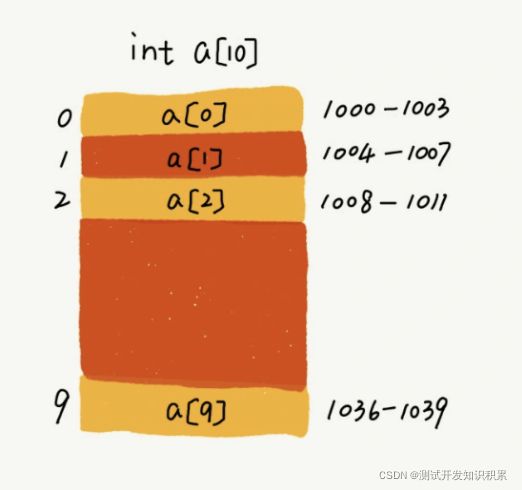
int[] a = new int[10],计算机给数组 a[10],分配了一块连续内存空间 1000~1039,其中,内存块的首地址为 base_address = 1000。
当计算机需要随机访问数组中的某个元素时,会首先通过寻址公式 a[i]_address = base_address + i * data_type_size 计算出该元素存储的内存地址。所以数组的下标以9开始
数组和链表的区别:链表适合插入、删除,时间复杂度 O(1);数组支持随机访问,根据下标随机访问的时间复杂度为 O(1)。
数组的插入操作
假设数组的长度为 n,现在,如果我们需要将一个数据插入到数组中的第 k 个位置。
如果数组中的数据是有序的,在某个位置插入一个新的元素,如果在数组的末尾插入元素,那就不需要移动数据了,这时的时间复杂度为 O(1)。但如果在数组的开头插入元素,那所有的数据都需要依次往后移动一位,所以最坏时间复杂度是 O(n)。 因为我们在每个位置插入元素的概率是一样的,所以平均情况时间复杂度为 (1+2+…n)/n=O(n)。
但如果数组中存储的数据并没有任何规律,如果要将某个数据插入到第 k 个位置,可以直接将第 k 位的数据搬移到数组元素的最后,把新的元素直接放入第 k 个位置,时间复杂度降为 O(1)。
数组的删除操作
跟插入数据类似,如果我们要删除第 k 个位置的数据,为了内存的连续性,也需要搬移数据,不然中间就会出现空洞,内存就不连续了。
如果删除数组末尾的数据,则最好情况时间复杂度为 O(1);如果删除开头的数据,则最坏情况时间复杂度为 O(n);平均情况时间复杂度也为 O(n)。
实际上,在某些特殊场景下,我们并不一定非得追求数组中数据的连续性。如果我们将多次删除操作集中在一起执行,删除的效率是不是会提高很多呢?
数组 a[10]中存储了 8 个元素:a,b,c,d,e,f,g,h。现在,我们要依次删除 a,b,c 三个元素。
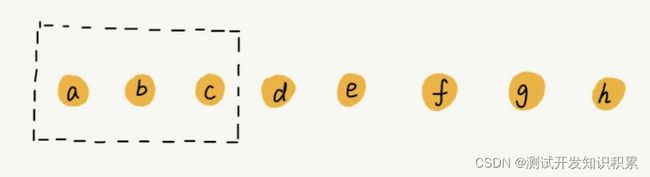
为了避免 d,e,f,g,h 这几个数据会被搬移三次,我们可以先记录下已经删除的数据。每次的删除操作并不是真正地搬移数据,只是记录数据已经被删除。当数组没有更多空间存储数据时,我们再触发执行一次真正的删除操作,这样就大大减少了删除操作导致的数据搬移。这也是JVM 标记清除垃圾回收算法的核心思想,
容器不能完全替换数组
针对数组类型,很多语言都提供了容器类,比如 Java 中的 ArrayList、C++ STL 中的 vector。
数组本身在定义的时候需要预先指定大小,因为需要分配连续的内存空间。如果我们申请了大小为 10 的数组,当第 11 个数据需要存储到数组中时,我们就需要重新分配一块更大的空间,将原来的数据复制过去,然后再将新的数据插入。
JAVA中的ArrayList 最大的优势就是可以将很多数组操作的细节封装起来。比如前面提到的数组插入、删除数据时需要搬移其他数据等。另外,它还有一个优势,就是支持动态扩容,每次存储空间不够的时候,它都会将空间自动扩容为 1.5 倍大小。不过,这里需要注意一点,因为扩容操作涉及内存申请和数据搬移,是比较耗时的。所以,如果事先能确定需要存储的数据大小,最好在创建 ArrayList 的时候事先指定数据大小。
但有时候使用数组会更合适
1.Java ArrayList 无法存储基本类型,比如 int、long,需要封装为 Integer、Long 类,而 Autoboxing、Unboxing 则有一定的性能消耗,所以如果特别关注性能,或者希望使用基本类型,就可以选用数组。
2. 如果数据大小事先已知,并且对数据的操作非常简单,用不到 ArrayList 提供的大部分方法,也可以直接使用数组。
3. 当要表示多维数组时,用数组往往会更加直观。比如 Object[][] array;而用容器的话则需要这样定义:ArrayList > array。
4. 对于业务开发,直接使用容器就足够了,省时省力。毕竟损耗一丢丢性能,完全不会影响到系统整体的性能。但如果是做一些非常底层的开发,比如开发网络框架,性能的优化需要做到极致,这个时候数组就会优于容器,成为首选。
数据结构-链表(Linked list)
1、链表是一种常见的基本数据结构,是一种线性表,但它不像数组,不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用

2、链表通过指针将一组零散的内存块串联在一起,这些内存块称为链表的“结点”。每个结点分为数据区和链接区,数据区保存数据,链接区保存下一个结点的地址,记录下个结点地址的指针叫作后继指针next。
单链表
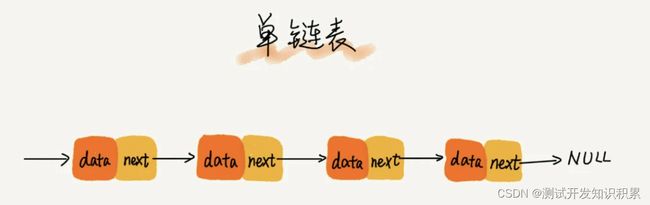

第一个节点叫作头结点,最后一个节点叫作尾节点。
尾结点的指针不是指向下一个结点,而是指向一个空地址 NULL,表示这是链表上最后一个结点。
在链表中插入或者删除一个数据 并不需要为了保持内存的连续性而搬移结点,因为链表的存储空间本身就不是连续的。针对链表的插入和删除操作,只需要考虑相邻结点的指针改变,所以对应的时间复杂度是 O(1)。

链表要想随机访问第 k 个元素,就没有数组那么高效了。因为链表中的数据并非连续存储的,所以无法像数组那样,根据首地址和下标,通过寻址公式就能直接计算出对应的内存地址,而是需要根据指针一个结点一个结点地依次遍历,直到找到相应的结点,需要 O(n) 的时间复杂度。
循环链表
是一种特殊的单链表。单链表的尾结点指针指向空地址,而循环链表的尾结点指针是指向链表的头结点。
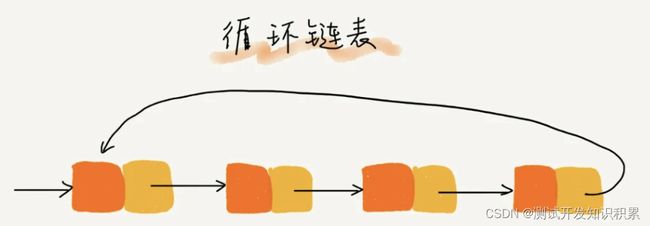
和单链表相比,循环链表的优点是从链尾到链头比较方便。当要处理的数据具有环型结构特点时,就特别适合采用循环链表。比如著名的约瑟夫问题。
双向链表
单向链表只有一个方向,结点只有一个后继指针 next 指向后面的结点。而双向链表支持两个方向,每个结点不止有一个后继指针 next 指向后面的结点,还有一个前驱指针 prev 指向前面的结点。

存储同样多的数据,双向链表要比单链表占用更多的内存空间。虽然两个指针比较浪费存储空间,但可以支持双向遍历,这样也带来了双向链表操作的灵活性。
从结构上来看,双向链表可以支持 O(1) 时间复杂度的情况下找到前驱结点,正是这样的特点,也使双向链表在某些情况下的插入、删除等操作都要比单链表简单、高效。
比如删除给定指针指向的结点:已经找到了要删除的结点,但是删除某个结点 q 需要知道其前驱结点,而单链表并不支持直接获取前驱结点,所以,为了找到前驱结点,我们还是要从头结点开始遍历链表,直到 p->next=q,说明 p 是 q 的前驱结点。但是对于双向链表来说,这种情况就比较有优势了。因为双向链表中的结点已经保存了前驱结点的指针,不需要像单链表那样遍历。所以,针对第二种情况,单链表删除操作需要 O(n) 的时间复杂度,而双向链表只需要在 O(1) 的时间复杂度内就搞定了。
同理,如果我们希望在链表的某个指定结点前面插入一个结点,双向链表比单链表有很大的优势。双向链表可以在 O(1) 时间复杂度搞定,而单向链表需要 O(n) 的时间复杂度。
除了插入、删除操作有优势之外,对于一个有序链表,双向链表的按值查询的效率也要比单链表高一些。因为,我们可以记录上次查找的位置 p,每次查询时,根据要查找的值与 p 的大小关系,决定是往前还是往后查找,所以平均只需要查找一半的数据。
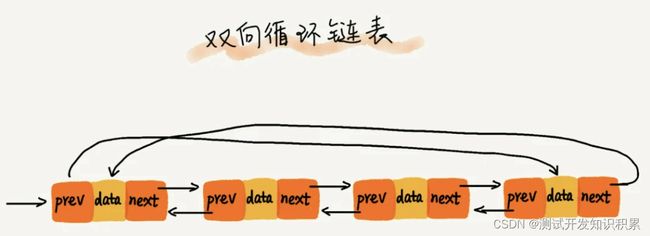
双向循环链表
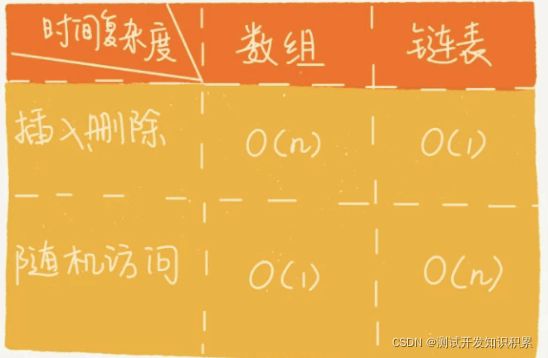
数组和链表对比
数组和链表是两种截然不同的内存组织方式。正是因为内存存储的区别,它们插入、删除、随机访问操作的时间复杂度正好相反。
数组简单易用,在实现上使用的是连续的内存空间,可以借助 CPU 的缓存机制,预读数组中的数据,所以访问效率更高。而链表在内存中并不是连续存储,所以对 CPU 缓存不友好,没办法有效预读。数组的缺点是大小固定,一经声明就要占用整块连续内存空间。如果声明的数组过大,系统可能没有足够的连续内存空间分配给它,导致“内存不足(out of memory)”。如果声明的数组过小,则可能出现不够用的情况。这时只能再申请一个更大的内存空间,把原数组拷贝进去,非常费时。链表本身没有大小的限制,天然地支持动态扩容,我觉得这也是它与数组最大的区别。你可能会说,我们 Java 中的 ArrayList 容器,也可以支持动态扩容啊?我们上一节课讲过,当我们往支持动态扩容的数组中插入一个数据时,如果数组中没有空闲空间了,就会申请一个更大的空间,将数据拷贝过去,而数据拷贝的操作是非常耗时的。我举一个稍微极端的例子。如果我们用 ArrayList 存储了了 1GB 大小的数据,这个时候已经没有空闲空间了,当我们再插入数据的时候,ArrayList 会申请一个 1.5GB 大小的存储空间,并且把原来那 1GB 的数据拷贝到新申请的空间上。听起来是不是就很耗时?除此之外,如果你的代码对内存的使用非常苛刻,那数组就更适合你。因为链表中的每个结点都需要消耗额外的存储空间去存储一份指向下一个结点的指针,所以内存消耗会翻倍。而且,对链表进行频繁的插入、删除操作,还会导致频繁的内存申请和释放,容易造成内存碎片,如果是 Java 语言,就有可能会导致频繁的 GC(Garbage Collection,垃圾回收)。所以,在我们实际的开发中,针对不同类型的项目,要根据具体情况,权衡究竟是选择数组还是链表。
实现LRU缓存淘汰算法
缓存淘汰策略:先进先出策略 FIFO(First In,First Out)、最少使用策略 LFU(Least Frequently Used)、最近最少使用策略 LRU(Least Recently Used)。
维护一个有序单链表,越靠近链表尾部的结点是越早之前访问的。当有一个新的数据被访问时,我们从链表头开始顺序遍历链表。
1.如果此数据之前已经被缓存在链表中了,我们遍历得到这个数据对应的结点,并将其从原来的位置删除,然后再插入到链表的头部。
2.如果此数据没有在缓存链表中,又可以分为两种情况:如果此时缓存未满,则将此结点直接插入到链表的头部;如果此时缓存已满,则链表尾结点删除,将新的数据结点插入链表的头部。
如何优雅的写出链表代码?6大学习技巧
一、理解指针或引用的含义
1.含义:将某个变量(对象)赋值给指针(引用),实际上就是就是将这个变量(对象)的地址赋值给指针(引用)。
2.示例:
p—>next = q; 表示p节点的后继指针存储了q节点的内存地址。
p—>next = p—>next—>next; 表示p节点的后继指针存储了p节点的下下个节点的内存地址。
二、警惕指针丢失和内存泄漏(单链表)
1.插入节点
在节点a和节点b之间插入节点x,b是a的下一节点,,p指针指向节点a,则造成指针丢失和内存泄漏的代码:p—>next = x;x—>next = p—>next; 显然这会导致x节点的后继指针指向自身。
正确的写法是2句代码交换顺序,即:x—>next = p—>next; p—>next = x;
2.删除节点
在节点a和节点b之间删除节点b,b是a的下一节点,p指针指向节点a:p—>next = p—>next—>next;
三、利用“哨兵”简化实现难度
1.什么是“哨兵”?
链表中的“哨兵”节点是解决边界问题的,不参与业务逻辑。如果我们引入“哨兵”节点,则不管链表是否为空,head指针都会指向这个“哨兵”节点。我们把这种有“哨兵”节点的链表称为带头链表,相反,没有“哨兵”节点的链表就称为不带头链表。
2.未引入“哨兵”的情况
如果在p节点后插入一个节点,只需2行代码即可搞定:
new_node—>next = p—>next;
p—>next = new_node;
但,若向空链表中插入一个节点,则代码如下:
if(head == null){
head = new_node;
}
如果要删除节点p的后继节点,只需1行代码即可搞定:
p—>next = p—>next—>next;
但,若是删除链表的最有一个节点(链表中只剩下这个节点),则代码如下:
if(head—>next == null){
head = null;
}
从上面的情况可以看出,针对链表的插入、删除操作,需要对插入第一个节点和删除最后一个节点的情况进行特殊处理。这样代码就会显得很繁琐,所以引入“哨兵”节点来解决这个问题。
3.引入“哨兵”的情况
“哨兵”节点不存储数据,无论链表是否为空,head指针都会指向它,作为链表的头结点始终存在。这样,插入第一个节点和插入其他节点,删除最后一个节点和删除其他节点都可以统一为相同的代码实现逻辑了。
4.“哨兵”还有哪些应用场景?
这个知识有限,暂时想不出来呀!但总结起来,哨兵最大的作用就是简化边界条件的处理。
四、重点留意边界条件处理
经常用来检查链表是否正确的边界4个边界条件:
1.如果链表为空时,代码是否能正常工作?
2.如果链表只包含一个节点时,代码是否能正常工作?
3.如果链表只包含两个节点时,代码是否能正常工作?
4.代码逻辑在处理头尾节点时是否能正常工作?
五、举例画图,辅助思考
核心思想:释放脑容量,留更多的给逻辑思考,这样就会感觉到思路清晰很多。
六、多写多练,没有捷径
5个常见的链表操作:
1.单链表反转
2.链表中环的检测
3.两个有序链表合并
4.删除链表倒数第n个节点
5.求链表的中间节点
ArrayList底层是数组;LinkHashMap底层是双向链表