Spring应用
Spring介绍
介绍
Spring是一款开源的轻量级微服务开发框架,体系完善,可以快速实现业务开发和功能扩展,代码移植性强,只要服務器支持servlet就可以部署。
核心功能
IOC、注解、MVC、事务、AOP、持久层、SpringBoot
以下基于核心功能描述
maven引入
spring-context由spring-core、spring-bean和spring-aop等核心组件组成,core负责容器管理、bean负责bean的加载、定义和生命周期、aop负责增强扩展
junit
junit
4.11
test
org.springframework
spring-context
5.1.4.RELEASE
IOC——概述
IOC是一类编程思想,是指通过容器管理应用实例,调用方只需要向容器申请实例调用即可,不用再硬编码创建实例,提高了扩展性和复用性,降低了耦合性,同时降低垃圾的产生。
IOC——IOC 容器
IOC——scope
1、scope类型
在Spring 2.0之前,有singleton和prototype两种;
在Spring 2.0之后,为支持web应用的ApplicationContext,增强另外三种:request,session和global session类型,它们只实用于web程序,通常是和XmlWebApplicationContext共同使用。
1、singleton
此取值时表明容器中创建时只存在一个实例,所有引用此bean都是单一实例。如同每个国家都有一个总统,国家的所有人共用此总统,而这个国家就是一个spring容器,总统就是spring创建的类的bean,国家中的人就是其它调用者,总统是一个表明其在spring中的scope为singleton,也就是单例模型。
此外,singleton类型的bean定义从容器启动到第一次被请求而实例化开始,只要容器不销毁或退出,该类型的bean的单一实例就会一直存活,典型单例模式,如同servlet在web容器中的生命周期。
单例情况下: 不能使用共享成员变量 , 在并发情况下本来是true , 但另一线程进来 , 变为false , 期望结果是true , 并发会导致数据不准确
2、prototype
请求方spring容器在进行输出prototype的bean对象时,会每次都重新生成一个新的对象,虽然这种类型的对象的实例化以及属性设置等工作都是由容器负责的,但是只要准备完毕,并且对象实例返回给请求方之后,容器就不在拥有当前对象的引用,请求方需要自己负责当前对象后继生命周期的管理工作,包括该对象的销毁。也就是说,容器每次返回请求方该对象的一个新的实例之后,就由这个对象“自生自灭”,最典型的体现就是spring与struts2进行整合时,要把action的scope改为prototype。
属性值为prototype时 , 并发时线程是安全的
如同分苹果,将苹果的bean的scope属性声明为prototype,在每个人领取苹果的时候,我们都是发一个新的苹果给他,发完之后,别人爱怎么吃就怎么吃,爱什么时候吃什么时候吃,但是注意吃完要把苹果核扔到垃圾箱!对于那些不能共享使用的对象类型,应该将其定义的scope设为prototype。
3、request
再次说明request,session和global session类型只实用于web程序,通常是和XmlWebApplicationContext共同使用。
Spring容器,即XmlWebApplicationContext 会为每个HTTP请求创建一个全新的RequestPrecessor对象,当请求结束后,该对象的生命周期即告结束,如同java web中request的生命周期。当同时有100个HTTP请求进来的时候,容器会分别针对这10个请求创建10个全新的RequestPrecessor实例,且他们相互之间互不干扰,简单来讲,request可以看做prototype的一种特例,除了场景更加具体之外,语意上差不多。
4、session
对于web应用来说,放到session中最普遍的就是用户的登录信息,对于这种放到session中的信息,我们可以使用如下形式的制定scope为session:
Spring容器会为每个独立的session创建属于自己的全新的UserPreferences实例,比request scope的bean会存活更长的时间,其他的方面没区别,如果java web中session的生命周期。
5、global session
global session只有应用在基于porlet的web应用程序中才有意义,它映射到porlet的global范围的session,如果普通的servlet的web 应用中使用了这个scope,容器会把它作为普通的session的scope对待。
总结
| 取值范围 | 说明 |
|---|---|
| singleton | 单例,并发情况线程不安全 生命周期: 随着ioc创建而创建 ioc容器会一直拥有此bean的引用以保证不被回收 随着ioc卸载而消亡 |
| prototype | 多例,影响效率,并发情况线程安全 生命周期: 随着线程调用getBean()而创建 ioc容器不会拥有此bean的引用,靠gc回收 |
| request | web环境下,为每个requset创建独立bean,生命周期同prototype |
| session | web环境下,为每个session创建独立bean,即存在于session域中,存活时间比request有所提升,生命周期同prototype |
| global session | web环境下,应用在portlet环境,如果没有portlet环境会被当作session,生命周期同prototype |
2、scope配置
1、xml方式
进行bean的配置时,指定scope。

2、注解方式
前提为配置spring为注解配置。

IOC——最基本的初始化、销毁方法

IOC——工厂创建
1、无参构造创建
之前的bean定义均是无参构造的应用
2、静态工厂方法创建
此时bean里加上一个静态方法 getFighterInstance1,一个实例方法getFighterInstance2
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Fighter {
public static Fighter getFighterInstance1(){
return new Fighter();
}
public Fighter getFighterInstance2(){
return new Fighter(10,"J-20","A");
}
// 服役年限
private int age;
// 战机名称
private String name;
// 战机型号
private String model;
}然后applicationContext.xml中通过factory-method来创建
3、成员方法创建
这个也简单,是指用一个bean实例的方法来创建另一个bean
//基于上面的fighter1来执行
【注:】
利用方法来创建实例是非常常见的,如DriverManager创建connector实例
IOC——DI(Dependency Injection)
1、介绍
通过IOC创建对象后还要为对象初始化属性,初始化属性的行为就是依赖注入,依赖注入的方式有构造器注入和set注入,set注入也叫属性填充。
2、注入方法
首先因示例关系加入一个class,后面会用
@Data
@AllArgsConstructor
@NoArgsConstructor
public class FighterService {
private Fighter fighter;
public Fighter create(){
fighter.setAge(0);
fighter.setModel("C");
return fighter;
}
}1、构造器注入
2、set注入
- 普通数据类型
- 引用数据类型
- 数组数据类型
- 集合数据类型
-
- 注入,允许有相同的值。
-
注入,不允许有相同的值。 -
-
注入,键和值都只能为String类型。
-
5
歼20
A
5
Java
C++
Python
1
2
3
北京
上海
pp1
pp2
【注:】
1、set注入时的property标签的name值是set方法的部分内容,例如setUrl,那么name值为url,即去掉set后首字母小写,我之前一直以为name值是变量值,结果用setUrl 错了半天
2、构造器注入无法主动解决循环依赖,要么在设计时避免循环,要么用@Lazy懒加载,基本就是破坏循环的条件,使得一方可以先创建成功


IOC——Spring bean装配
1、介绍
1.1、通过 Spring 容器中的实例完成bean的组合的行为
1.2、装配是依赖注入的抽象;依赖注入是装配的具体实现,例如构造器实现装配、或者set注入实现装配
1.3、装配的方式:
(1)xml装配;
(2)注解装配;
(3)自动装配。
2、自动装配
Spring 容器支持自动装配,这意味着容器不需要
IOC——导入properties文件
IOC——切分配置文件
即主配置文件会引入其它多分配置文件,目的是方便功能区分
1、创建一个分文件

2、beans标签导入
xmlns:p="http://www.springframework.org/schema/p"

3、导入分文件

IOC——Spring相关API
applicationContext
接口类型,代表应用上下文,可以通过其实例获得spring容器中的Bean

IOC——getBean()
下面代码是ClassPathXmlApplicationContext的顶级父类AbstractApplicationContext定义的
public Object getBean(String name) throws BeansException {
this.assertBeanFactoryActive();
return this.getBeanFactory().getBean(name);
}
public T getBean(String name, Class requiredType) throws BeansException {
this.assertBeanFactoryActive();
return this.getBeanFactory().getBean(name, requiredType);
}
public Object getBean(String name, Object... args) throws BeansException {
this.assertBeanFactoryActive();
return this.getBeanFactory().getBean(name, args);
}
public T getBean(Class requiredType) throws BeansException {
this.assertBeanFactoryActive();
return this.getBeanFactory().getBean(requiredType);
}
public T getBean(Class requiredType, Object... args) throws BeansException {
this.assertBeanFactoryActive();
return this.getBeanFactory().getBean(requiredType, args);
} 从中发现getBean()根据id、name、反射类等属性来获取Bean,其中根据反射类获取必须要求IOC容器中对应类型的bean有且只有一个
IOC——Spring配置数据源
maven再添上下面坐标
mysql
mysql-connector-java
5.1.34
com.alibaba
druid
1.2.4
配置1:jdbc.properties
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://192.168.0.2:3306/test1
jdbc.account=root
jdbc.password=961003配置2: applicationContext.xml
其中为了支持导入properties,添加了context依赖

bean调用引入的context依赖
${jdbc.driver}
jdbc:mysql://192.168.0.2:3306/test1
root
961003
测试
@Test
public void test2(){
// 基于spring启动druid
ApplicationContext ioc = new ClassPathXmlApplicationContext("applicationContext.xml");
DruidDataSource dataSource = (DruidDataSource) ioc.getBean("datasource");
System.out.println(dataSource.toString());
}IOC——Spring注解


【补:】一些常用的注解
@ImportResource(locations = {""classpath:spring.xml}):导入bean配置文件
@ConfigurationProperties(prefix = "aliyun.oss"):将yml配置文件的相关数据实例化
@Aspect:切面配置
@Transactional(rollbackFor = Exception.class):事务处理
@CacheNamespace(implementation= MybatisRedisCache.class):Mybatis二级缓存配置
IOC——bean生命周期

源码描述:初始化bean执行init方法的流程

1、Spring容器从XML文件读取bean的定义,所有bean定义被集中到BeanDefinition;
2、BeanFactoryPostProcessor#postProcessBeanFactory增强处理beanFactory;
3、BeanFactory通过反射机制获取无参构造器,然后无参实例化;
4、Spring容器 执行prepare 方法,即通过bean 的set 方法属性填充。
5、如果bean 实现了BeanNameAware 接口,Spring 传递bean 的ID 到setBeanName 方法
6、如果Bean 实现了BeanFactoryAware 接口, Spring传递beanfactory 给setBeanFactory 方法。
7、如果bean实现了BeanPostProcessor接口,postProcessBeforeInitialization()将被调用
8、执行@PostConstructor指定的method
9、如果实现InitializingBean 接口并且重写afterPropertiesSet 方法,afterPropertySet 方法会被调用
10、执行init-method属性指定的method
11、postProcessAfterInitialization() 方法将被调用
IOC——参与bean生命周期的函数
这些函数的重写定义可以让程序有很高的扩展性,以下按照加载顺序排列
1、BeanPostProcessor 的postProcesserBeforeInitialization()方法会被调用。
2、实现InitializingBean 接口重写afterPropertiesSet 方法,afterPropertySet 方法会被调用
3、BeanPostProcessor 的postProcessAfterInitialization() 方法会被调用。
4、添加@PostConstructor注解方法,注解方法会被调用
5、实现DisposableBean接口并重写destry 方法,destroy方法将调用
6、添加@PreDestory注解方法,注解方法会被调用
IOC——最重要的bean生命周期函数
@PostConstructor注解方法和@PreDestory注解方法是最核心的生命周期函数,第一个是setup,在容器加载bean 后被调用。第二个方法是teardown,在容器卸载bean 前被调用。
IOC——依赖问题
一个完整的对象包含两部分:当前对象实例化和对象属性的实例化,在Spring中,对象的实例化是通过反射无参构造器实现的,然后做属性填充,如果填充引用对象,可以分为三类情况,即顺序依赖、循环依赖和代理依赖。
1、顺序依赖是指对象a 属性填充对象b,然后从容器获取或者创建b 并返回给a;
2、循环依赖是指对象a 引用的对象还没创建,此时需要创建对象b ,但是b 进行属性填充又刚好需要a;
3、代理依赖是指对象a 引用的对象还没创建,此时需要创建引用对象b ,但是b进行属性填充又刚好需要a 而且a 需要动态代理
refresh 方法针对以上三种情况给出了解决方案
顺序依赖

循环依赖

代理依赖
IOC——三个缓存
三个缓存
private final Map singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of singleton factories: bean name to ObjectFactory. */
private final Map> singletonFactories = new HashMap<>(16);
/** Cache of early singleton objects: bean name to bean instance. */
private final Map earlySingletonObjects = new HashMap<>(16); 基于依赖问题的解决可以发现,如果是顺序依赖,一级依赖足够,如果是循环依赖,二级缓存足够,如果是代理依赖,则需要三个缓存
三级换成能否取消
可以,最初spring不支持aop,只有两个缓存,后来支持aop,增加了三级换成,二级缓存完全可以改造后融入三级缓存功能,这里我理解是为了版本兼容和符合开闭原则
IOC——BeanDefinition
通过配置文件、BeanDefinitionRegistryPostProcessor加载关于bean的元数据以及增强处理的元数据;
- Bean 的类名
- Bean 配置信息,作用域、生命周期回调、延迟加载、初始方法、销毁方法等
- Bean 之间的依赖设置,dependencies
- 构造参数、属性设置
有哪些配置可以提供元数据
- XML配置文件
- 基于注解的配置
- 基于java的配置,如postProcessor接口。
标签格式:id是唯一标识,name支持多个标识,class指定bean类型(标识只绑定当前bean,其它bean禁止使用)
注解格式:只能指定唯一标识
@Component("person")
public class Person{
}以ClassPathXmlApplicationContext为例
Person类
@Data
@AllArgsConstructor
public class Person {
public Person(){
System.out.println("new Persong");
}
private String name;
private int age;
private String password;
private void init(){
System.out.println("init");
}
private void destroy(){
System.out.println("destroy"+age);
}
}测试代码
@Test
public void test1(){
ApplicationContext ioc = new ClassPathXmlApplicationContext("/applicationContext.xml");
// Person p = (Person)ioc.getBean(id|name); 可以根据bean的id、name获取bean实例
Person p1 = (Person)ioc.getBean("person");
Person p2 = (Person)ioc.getBean("n1");
System.out.println(p1.toString());
p1.setAge(10);
System.out.println(p2.toString());
}IOC——Spring框架的单例bean是线程安全的吗?
IOC——BeanFactory
IOC——XMLBeanFactory
IOC——ApplicationContext
ApplicationContext实现类
- FileSystemXmlApplicationContext :此容器从一个XML文件中加载bean定义,基于全路径名设置配置文件;
- ClassPathXmlApplicationContext:此容器也从一个XML文件中加载bean定义,基于classpath设置配置文件;
- XmlWebApplicationContext:此容器加载一个XML文件,此文件定义了包含web功能的所有bean;
- AnnotationConfigWebApplicationContext:用于配置类的加载;
- ServletWebServerApplicationContext:是SpringBoot默认的Context;
ApplicationContext 和BeanFactory的区别
- BeanFactory 是Spring 框架最核心的接口,用来管理bean的生命周期,生命周期指的是负责bean的实例化、属性填充、初始化、调用和消亡。
- ApplicationContext 是整个Spring的启动类,创建和管理BeanFactory ,加载配置信息,为BeanFactory 初始化BeanFactoryPostprocessor、BeanDefinitionMap 和BeanPostprocessor,最后由BeanFactory 管理BeanDefinitionMap 提供的业务bean
IOC——BeanPostProcessor
在bean生命周期的初始化阶段(exportObj = initializingBean(bean))做前置后置或者环绕增强,如AbstractAutoProxyCreator,就是专用来做AOP增强的BeanPostProcessor
IOC——BeanFactoryPostProcessor
用作BeanDefinition 的后置处理,常见的有PlaceholdConfigurerSupport和ConfigurationClassPostProcessor,一个是用来做参数校验并注入占位符,一个是用来为配置类做CGLIB增强
IOC——BeanDefinitionRegistryPostProcessor
BeanDefinitionRegistryPostProcessor 是BeanFactoryPostProcessor 子接口,用于注册BeanDefinition,在obtainFreshBeanFactory() 装配完BeanFactoryPostProcessor 实现类后执行BeanDefinitionRegistryPostProcessor#postProcessBeanDefinitionRegistry(BeanDefinitionRegistry bdr):void,比如ConfigurationClassPostProcessor就是以此函数解析@Configuration类型的@Bean、@Import等标识 去生成BeanDefinition
IOC——BeanDefinitionRegistry
介绍
注册BeanDefiniton到BeanDefinitionMap的对象,提供registry(BeanDefinition bd)方法;
注册原理 /底层源码
执行beanFactory的beanDefinitionMap.put(BeanDefinition bd);
场景
一般是BeanDefinitionRegistryPostProcessor、ImportBeanDefinitionRegistrar的实现类的重写方法会获取该对象,方法以此来注册beanDefinition,beanFactory也提供注册服务
IOC——ImportBeanDefinitionRegistrar
ConfigurationClassPostProcessor#postProcessBeanDefinitionRegistry():void 用来解析配置类的@Import注解,不同于以往import的配置类,这次import的是实现了ImportBeanDefinitionRegistrar的普通类,以ConfigurationTest.java为例
package com.zzq.core.configuration;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import com.zzq.core.importbeandefinitionregistrar.ImportBeanDefinitionRegistrarTest;
@Configuration
@Import(ImportBeanDefinitionRegistrarTest.class) //导入
public class ConfigurationTest {
}ImportBeanDefinitionRegistrarTest.java:重写registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry),重写内容是自定义beanDefinition并通过beanDefinitionRegistry注册beanDefinition
package com.zzq.core.importbeandefinitionregistrar;
import org.springframework.beans.MutablePropertyValues;
import org.springframework.beans.factory.config.BeanDefinition;
import org.springframework.beans.factory.support.BeanDefinitionRegistry;
import org.springframework.beans.factory.support.GenericBeanDefinition;
import org.springframework.context.annotation.ImportBeanDefinitionRegistrar;
import org.springframework.core.type.AnnotationMetadata;
import com.zzq.core.importbeandefinitionregistrar.bean.TestBean;
import com.zzq.other.autowired.autowiredtest1.AutowiredTest;
public class ImportBeanDefinitionRegistrarTest implements ImportBeanDefinitionRegistrar{
@Override
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) {
BeanDefinition beanDefinition = new GenericBeanDefinition();
beanDefinition.setBeanClassName(TestBean.class.getName());
MutablePropertyValues values = beanDefinition.getPropertyValues();
values.addPropertyValue("id", 1);
values.addPropertyValue("name", "ZhangSan");
//这里注册bean
registry.registerBeanDefinition("testBean", beanDefinition );
}
}IOC——BeanFactory和FactoryBean的区别
beanFactory
beanFactory是applicationContext的实现接口,beanFactory也是applicationContext维护的IOC管理实例,项目启动时applicationContext要执行初始化流程,其中就包括beanFactory实例的创建和维护,beanFactory维护着一二三级缓存、beanDefinitionMap等元信息,拥有getBean(beanName),contains(beanName)等方法。
factoryBean
factoryBean是一个泛型接口,你需要去实现getObject()、getObjectClass()、isSingleton(),然后把@Service等实例化注解放到FactoryBean实现类上。有趣的是spring不仅仅将实现类实例放入IOC,还会调用getObject方法将返回值放入IOC,当getBean("&beanName")时候获取的是实现类实例,而 getBean("beanName")时候获取的则是getObject方法的返回值。
factoryBean的目的是为一些复杂实例提供一个初始化的流程模板,相对于开发者自定义一个配置类然后通过@Bean调用配置方法来实现这个流程更加轻量化
FactoryBean的使用用例- 知乎 (zhihu.com) https://zhuanlan.zhihu.com/p/229003633#:~:text=1%20%E5%8D%95%E4%BE%8B%E7%9A%84%20factoryBean%20%E5%AF%B9%E8%B1%A1%E6%9C%AC%E8%BA%AB%E4%BC%9A%E5%9C%A8%20spring%20%E5%AE%B9%E5%99%A8%E5%90%AF%E5%8A%A8%E6%97%B6%E4%B8%BB%E5%8A%A8%E5%88%9D%E5%A7%8B%E5%8C%96%E3%80%82%20%E8%80%8C%20subBean,%E5%AF%B9%E8%B1%A1%EF%BC%9B%E5%A6%82%E6%9E%9C%E8%A6%81%E8%8E%B7%E5%8F%96%E5%B7%A5%E5%8E%82%E5%AF%B9%E8%B1%A1%20factoryBean%20%EF%BC%8C%E9%9C%80%E8%A6%81%E4%BD%BF%E7%94%A8%20getBean%20%28%22%26%22%20%2B%20beanName%29.%20%E6%9B%B4%E5%A4%9A%E9%A1%B9%E7%9B%AE
https://zhuanlan.zhihu.com/p/229003633#:~:text=1%20%E5%8D%95%E4%BE%8B%E7%9A%84%20factoryBean%20%E5%AF%B9%E8%B1%A1%E6%9C%AC%E8%BA%AB%E4%BC%9A%E5%9C%A8%20spring%20%E5%AE%B9%E5%99%A8%E5%90%AF%E5%8A%A8%E6%97%B6%E4%B8%BB%E5%8A%A8%E5%88%9D%E5%A7%8B%E5%8C%96%E3%80%82%20%E8%80%8C%20subBean,%E5%AF%B9%E8%B1%A1%EF%BC%9B%E5%A6%82%E6%9E%9C%E8%A6%81%E8%8E%B7%E5%8F%96%E5%B7%A5%E5%8E%82%E5%AF%B9%E8%B1%A1%20factoryBean%20%EF%BC%8C%E9%9C%80%E8%A6%81%E4%BD%BF%E7%94%A8%20getBean%20%28%22%26%22%20%2B%20beanName%29.%20%E6%9B%B4%E5%A4%9A%E9%A1%B9%E7%9B%AE
IOC——@Autowired修饰静态变量注入失效解决方案
@Autowired修饰set方法
@Component
public class TestBean {
// 静态变量
private static DictService dictService;
// 构造方法注入静态变量
@Autowired
public void setDictService(DictService dictService){
TestBean.dictService = dictService;
}
public static void getDict(String type) throws Exception {
// 注入成功后,在静态方法里面使用静态变量
dictService.getDict(type);
}
}@PostConstructor
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
@Component
public class RedisUtil {
private static RedisTemplate redisTemplates;
@Autowired
private RedisTemplate redisTemplate;
//或者autowired来装配applicationContext实例,然后在initialize中调用applicationContext.getBean(...)来实现对象赋值
@PostConstruct
public void initialize() {
redisTemplates = this.redisTemplate;
}
/**
* 添加元素
*
* @param key
* @param value
*/
public static void set(Object key, Object value) {
if (key == null || value == null) {
return;
}
redisTemplates.opsForValue().set(key, value);
}
}
【扩展:】
@Autowired的用法其实有很多
可以使用 @Autowired直接标注类中的字段,快速使用。
可以使用 @Autowired 标注构造器、方法,这样可以方便注入多个 Bean。
可以 @Autowired标注 Array (数组),Collections(集合),甚至是 Map (散列表),将所有匹配到的 Bean 注入进来。
【注:】
使用 @Autowired 注入属性到 Map 中,key 必须是 String 类型。
Spring不能直接@autowired注入Static变量问题和解决方案_autowired static不起作用-CSDN博客https://blog.csdn.net/HC199854/article/details/119575907
IOC——bean实例操作applicationContext
如果希望bean实例可以操作applicationContext,可以尝试实现ApplicationContextAware
@Component
public class SpringUtil implements ApplicationContextAware {
private static ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
if(SpringUtil.applicationContext == null) {
SpringUtil.applicationContext = applicationContext;
}
}
//获取applicationContext
public static ApplicationContext getApplicationContext() {
return applicationContext;
}
//通过name获取 Bean.
public static Object getBean(String name){
return getApplicationContext().getBean(name);
}
//通过class获取Bean.
public static T getBean(Class clazz){
return getApplicationContext().getBean(clazz);
}
//通过name,以及Clazz返回指定的Bean
public static T getBean(String name,Class clazz){
return getApplicationContext().getBean(name, clazz);
}
} 也可以直接@Autowired 来修饰ApplicationContext属性
@SpringBootTest
class SpringSecurityDemoApplicationTests {
@Autowired
private ApplicationContext context;
@Test
void test() {
BeanFactory factory = context.getAutowireCapableBeanFactory();
System.out.println("applicationUtils:"+factory.getBean("applicationUtils").toString());
}
}Spring MVC——介绍
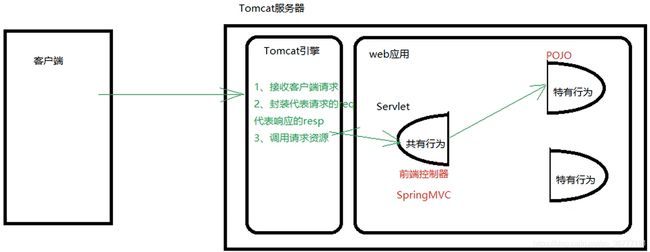
以前基于Servlet做开发,一个web接口对应一个servlet实现,当接口量多时需要维护大量的Servlet实现,这些实现中有大量的内容是公有的,结果就会造成冗余和维护麻烦,SpringMVC就是解决这种问题的web框架,实质是一个Servlet的封装,强悍之处在于开发的web接口都被纳入到此Servlet的管理之中,客户端请求只能发给这个Servlet,然后根据url映射到各自的web接口(控制器)。
人话:前端控制器就是前台,当你去前台预约工作时,前台会让相应部门做好接待
优点:一个Servlet的架构让通用功能不再冗余,万佛归一
Spring MVC——运行流程
这个Servlet就是DispatchServlet(调度服务),运行原理如下
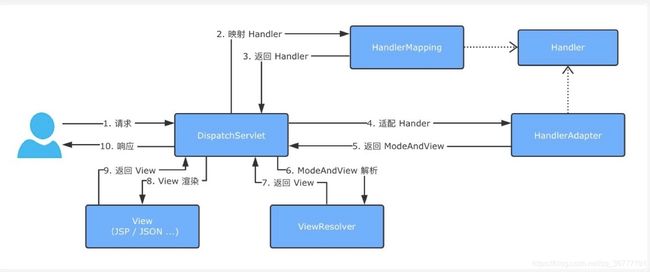 1、DispatcherServlet接收请求数据
1、DispatcherServlet接收请求数据
2、DispatcherServlet转发请求到HandlerMapping处理映射器
3、处理映射器找到具体的处理器Handler(根据xml配置、注解查找),生成处理器对象及拦截器(Interceptor)一并返回给Dispatcher
4、DispatcherServlet调用HanlerAdapter处理适配器
5、HandlerAdapter经过适配Handler调用具体的处理器(Controller)
6、Controller执行完成返回ModelAndView
7、HandlerAdapter将controller执行结果ModelAndView返回给Dispatcher
8、DispatcherServlet将ModelAndView传给ViewResolver视图解析器
9、ViewResolver返回具体View
10、DispatcherServlet根据View进行视图渲染,最后响应出去
Spring MVC——搭建
maven导入坐标
我们只需要配置mvc,只需这一个坐标即可(内置了spring-web、spring-context)
org.springframework
spring-webmvc
5.0.11.RELEASE
web.xml配置DispatcherServlet

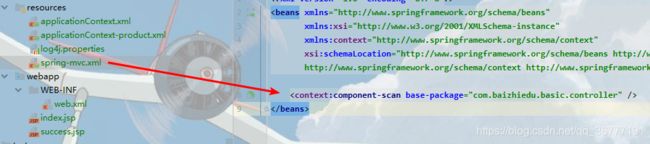
创建Controller和视图, 使用注解配置映射地址

配置spring-mvc.xml,添加扫描注解类配置
Spring MVC——Controller是不是单例
控制器也是单例,之所以保证了线程安全是因为整个单例的操作都是无状态的,每个request处理过后都无法扰动单例对象本身数据
Spring MVC——注解



【注:】
- 如果有全局url,那么return "success.jsp"是指在/user下找寻jsp返回,因此要用绝对路径来写:return "/success.jsp"
- return "/success.jsp" 实质是转发,通return "forward:/success.jsp",如果用重定向是return "redirect:/success.jsp"
Spring MVC——配置文件
扫描@Component注解
指定扫描组件范围
集成了SpringContext和SpringWeb的SpringMVC框架拥有两个IOC,service层的IOC是父容器,而spring-mvc.xml搭建的是子容器,这也就解释了为什么Controller可以调用service层。通常子容器先自查bean的有无,没有再去父容器查找。
背景介绍完了,现在的问题是如何避免两个容器重复包扫描同一类型的实例
解决方法
- include-filter: 保留符合条件的component,和exclude-filter相对
- exclude-filter: 去除符合条件的component
- type: 有多种类型,目前我只用过annotation
- expression: 指定type的具体功能接口
自定义配置(修改自带的请求映射器、请求处理器、视图处理器)
SpringMVC 默认有相关的配置,但是不一定符合需求,我们如何自定义相关配置

案例:自定义视图处理器
spring-mvc.xml默认会加载视图处理器实现类(InternalResourceViewResolver)

手动加载此类,以便传递自定义参数


总结

Spring MVC——返回数据
返回页面
- 直接返回字符串

- 通过ModelAndView对象返回
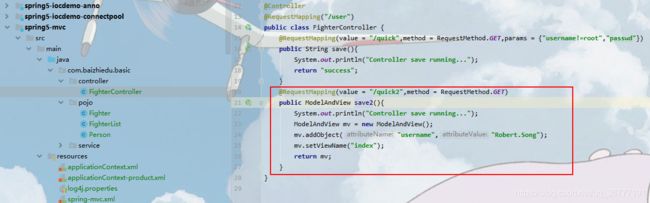
 测试
测试
【注:】上述两种返回模式有多种写法,总结如下
返回json数据
加入@ResponseBody表明返回数据不是页面,spring-mvcweb内置的jackson依赖会自动处理为json格式

Spring MVC——请求和响应的数据格式
常用的请求数据content-type:
- application/x-www-form-urlencoded
- multipart/form-data
- application/json
- application/xml
Spring MVC——cors
Spring Boot 配置CROS Filter_corsfilter 根据实际配置_在奋斗的大道的博客-CSDN博客https://blog.csdn.net/zhouzhiwengang/article/details/121082578
Spring MVC——文件处理
maven
commons-fileupload
commons-fileupload
1.4
commons-io
commons-io
2.6
spring-mvc.xml
Spring MVC——内置拦截器
流程图:servlet、过滤器、拦截器、控制器
拦截器配置方式:
1、spring-mvc.xml
2、@Interceptor
3、实现WebMvcConfigurer重写addInterceptors方法
@Configuration
public class MyMvcConfig implements WebMvcConfigurer {
@Bean
public MyInterceptor getMyInterceptor(){
System.out.println("注入了MyInterceptor");
return new MyInterceptor();
}
@Override
public void addInterceptors(InterceptorRegistry registry) {
// getMyInterceptor()执行过就会直接返回实例
registry.addInterceptor(getMyInterceptor()).addPathPatterns("/**");
}Spring MVC——异常处理
1、servlet的全局异常处理,可以通过异常状态码和异常类型拦截
500
/page/error/500.jsp
java.lang.NullPointerException
/page/error/nullPoint.jsp
2、SpringMVC内置处理器
3、SpringMVC通过注解实现异常处理器
@ControllerAdvice
public class AppWideExceptionHandler {
@ExceptionHandler(Exception.class)
@ResponseBody
public MyResult exception(HttpServletRequest request, Exception ex){
String msg="异常信息>>>>>异常名:"+ex.getClass()+"||方法名:"+ex.getStackTrace()[0].getMethodName()+"||类名:"+ex.getStackTrace()[0].getClassName()+"||行数:"+ex.getStackTrace()[0].getLineNumber();
return MyResult.error(msg);
}
}Spring MVC——Filter
1、过滤器是Java web三大组件(Servlet,Filter、listener)之一
过滤器可以把对资源的请求拦截下来,从而实现一些特殊的功能
过滤器一般完成一些通用的操作,比如:权限控制,统一编码处理,敏感字符处理等等
1.1、基本步骤
1.2、Filter执行流程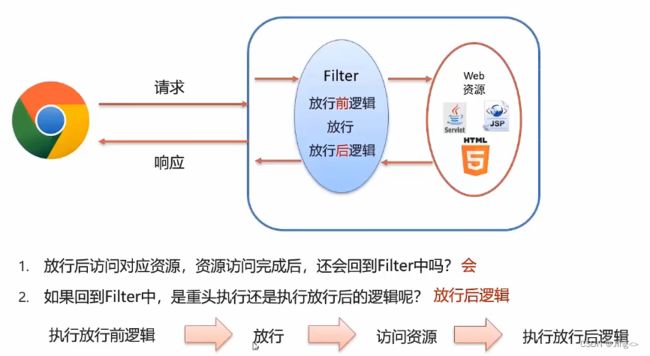
- 从filterconfig中拿到filterchain,filterchain开启链路,流式执行过滤器的doFilter方法
- 方法中对request数据进行处理;
- 然后调用chain.dofilter()放行;
- chain.dofilter()下面的逻辑用来对response数据进行处理;
1.3、url-pattern设置
匹配方式:
精准匹配:对请求资源做全名匹配,如/user/login.jsp
路径匹配:对请求资源做表达式匹配,如/*
后缀名匹配:对请求资源做后缀名匹配,如/user/*.jsp
缺省匹配:即默认支持所有请求资源,格式固定/
优先级:
整合所有的url-pattern设置路由表,不免出现几个路径冲突的情况,需要通过优先级解决
精准匹配 > 路径、后缀名匹配(二者不可同时存在)> 匹配器(如jsp匹配器) > 缺省匹配
1.4、过滤器和拦截器
拦截器与过滤器的区别和使用场景
过滤器 和 拦截器的 6个区别
区别
1、拦截器是基于java的反射机制的,而过滤器是基于函数的回调。
2、拦截器依赖ioc容器,而过滤器依赖于servlet容器。
3、拦截器只处理action请求,而过滤器可以处理所有请求。
4、拦截器可以用ioc资源,如数据源、事务、依赖注入,而过滤器则做不到。
5、拦截器每次都会执行preHandle()、postHandle() 和afterCompletion(),而过滤器init 方法只能在容器初始化时被调用一次,过滤则通过doFilter() 处理。
6、调用顺序不同
过滤器在servlet处理前过滤请求,在servlet 处理后过滤响应。
拦截器在servlet 和controller 之间处理请求。
【注:】
如果拦截器preHandle()为true则允许在视图渲染前执行postHandle(),也允许在视图渲染后执行afterCompletion()
执行顺序
Filter 请求过滤 -> Interceptor 前置 -> controller -> Interceptor 后置 -> 视图渲染 -> AfterCompletion -> Filter 响应过滤
控制执行顺序
过滤器:@Order注解控制执行顺序,值越小级别越高越先执行。
@Order(Ordered.HIGHEST_PRECEDENCE)
@Component
public class MyFilter2 implements Filter {拦截器:默认顺序是注册顺序,也可以通过Order手动设置,值越小越先执行。
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new MyInterceptor2()).addPathPatterns("/**").order(2);
registry.addInterceptor(new MyInterceptor1()).addPathPatterns("/**").order(1);
registry.addInterceptor(new MyInterceptor()).addPathPatterns("/**").order(3);
}
使用场景
过滤器:编码格式、敏感字符、权限认证;
拦截器:异常处理(统一处理所有controller 的异常),日志记录(记录请求信息以便监控、信息统计、计算PV(Page View)等);
Spring MVC——listener
listener可以绑定触发事件,自动执行指定代码
1、servlet提供application,session,request三个对象创建、销毁或往其中添加修改删除属性时自动执行代码的功能组件。
监听器的分类:
2、使用步骤:

Spring MVC——Java web三大组件装配方式
推荐第2种作为Spring MVC的装配方式
1、web.xml配置servlet、filter、listener
2、注解,@WebFilter、@WebListener、@WebServlet,还要在启动类添加@ServletComponentScan,将组件实例注入到spring容器并导入ServletContext;
3、也可通过@Bean注册实例,如FilterRegistrationBean
@Bean
public FilterRegistrationBean orderFilter() {
FilterRegistrationBean filter = new FilterRegistrationBean<>();
filter.setName("reqFilter");
filter.setFilter(new ReqFilter());
// 指定优先级
filter.setOrder(-1);
return filter;
} init-param 与context-param的区别是什么?
context-param和init-param都是在webapp/WEB-INF/web.xml文件中配置的参数。它们之间的区别在于作用范围和获取方式。
context-param是全局的参数,它对整个web应用程序有效。可以在web.xml的
init-param是针对某个特定的Servlet或Filter的参数,它只在该Servlet或Filter的init方法初始化过程中有效。在web.xml中的
demo01
com.lanou3g.Demo01
username
张飞
demo01
/demo01
public class Demo01 extends HttpServlet{
private ServletConfig config;
@Override
//当创建实例后该方法会被执行用来初始化,如果是Filter则该方法的参数是FilterConfig
public void init(ServletConfig config) throws ServletException {
this.config = config;
}
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
传入参数 配置时的 username(相当于key)
用key获取对应的value
String value = this.config.getInitParameter("username");
System.out.println(value);
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
}
}以上,context-param适用于整个应用程序共享的参数;init-param适用于Servlet或Filter单独使用的参数。
AOP
定义
面向切面编程,通过动态代理对OOP实现增强。利用AOP可以实现功能复用,解耦合,提高开发效率。
组成
- Aspect(切面): Aspect 声明类似于 Java 中的类声明,在 Aspect 中会包含着一些 Pointcut 以及相应的 Advice。
- Joint point(连接点):表示在程序中明确定义的点,典型的包括方法调用,对类成员的访问以及异常处理程序块的执行等等,它自身还可以嵌套其它 joint point。
- Pointcut(切点):表示一组 joint point,这些 joint point 或是通过逻辑关系组合起来,或是通过通配、正则表达式等方式集中起来,它定义了相应的 Advice 将要发生的地方。
- Advice(增强):Advice 定义了在 Pointcut 里面定义的程序点具体要做的操作,它通过 before、after 和 around 来区别是在每个 joint point 之前、之后还是代替执行的代码。
- Target(目标对象):织入 Advice 的目标对象。
- Proxy (代理对象):最终暴露外部被调用。
- Weaving(织入):将 Aspect 和其他对象连接起来, 并创建 Adviced object 的过程
基于IoC配置文件的应用
1、beans添加aop命名空间
2、引入依赖,由于引入的springwebmvc内部的aspectjweaver版本是1.8.13且optional为true,因此需要再手动引入一遍
org.aspectj
aspectjweaver
1.8.13
3、定义下图几个类
【注:】MyAspect的arround方法,需要配置上执行参数



4、配置。IoC是按照子、父IoC的顺序加载Bean,因此建议在spring-mvc.xml下配置target、aspect和aop:config 实例
5、如图,单元测试:执行target对象的切入点

6、结果

基于AOP注解的应用
1、定义下图的aspect和target。当前包为com.baizhiedu.basic.aop_anno


2、包扫描、实例化代理对象
如此便完成了,更便捷
事务(TransactionDefinition)
事务的特性
- 原子性(Atomicity):事务是一个原子操作,由一系列动作组成。事务的原子性确保动作要么全部完成,要么完全不起作用。
- 一致性(Consistency):一旦事务完成(不管成功还是失败),系统必须确保它所建模的业务处于一致的状态,而不会是部分完成部分失败。在现实中的数据不应该被破坏。
- 隔离性(Isolation):可能有许多事务会同时处理相同的数据,因此每个事务都应该与其他事务隔离开来,防止数据损坏。
- 持久性(Durability):一旦事务完成,无论发生什么系统错误,它的结果都不应该受到影响,这样就能从任何系统崩溃中恢复过来。通常情况下,事务的结果被写到持久化存储器中。
Spring事务的配置方式
Spring支持编程式事务管理以及声明式事务管理两种方式。
1. 编程式事务管理
编程式事务管理是侵入性事务管理,使用TransactionTemplate或者直接使用PlatformTransactionManager,对于编程式事务管理,Spring推荐使用TransactionTemplate。
2. 声明式事务管理
声明式事务管理建立在AOP之上,其本质是对方法前后进行拦截,然后在目标方法开始之前创建或者加入一个事务,执行完目标方法之后根据执行的情况提交或者回滚。声明式事务属于无侵入式,不会影响业务逻辑的实现,只需要在配置文件中做相关的事务规则声明或者通过注解的方式即可。
事务的传播机制
事务的传播性一般用在事务嵌套的场景,比如一个事务方法里面调用了另外一个事务方法,那么两个方法是各自作为独立的方法提交还是内层的事务合并到外层的事务一起提交,事务传播机制可以通过ThreadLocal管理事务哪些运行,哪些挂起。
常用的事务传播机制如下:
- PROPAGATION_REQUIRED
Spring默认的传播机制,能满足绝大部分业务需求,如果外层有事务,则当前事务加入到外层事务,一块提交,一块回滚。如果外层没有事务,新建一个事务执行 - PROPAGATION_REQUES_NEW
该事务传播机制是每次都会新开启一个事务,同时把外层事务挂起,当当前事务执行完毕,恢复上层事务的执行。如果外层没有事务,执行当前新开启的事务即可 - PROPAGATION_SUPPORT
如果外层有事务,则加入外层事务,如果外层没有事务,则直接使用非事务方式执行。完全依赖外层的事务 - PROPAGATION_NOT_SUPPORT
该传播机制不支持事务,如果外层存在事务则挂起,执行完当前代码,则恢复外层事务,无论是否异常都不会回滚当前的代码 - PROPAGATION_NEVER
该传播机制不支持外层事务,即如果外层有事务就抛出异常 - PROPAGATION_MANDATORY
与NEVER相反,如果外层没有事务,则抛出异常 - PROPAGATION_NESTED
该传播机制的特点是可以保存状态保存点,当前事务回滚到某一个点,从而避免所有的嵌套事务都回滚,即各自回滚各自的,如果子事务没有把异常吃掉,基本还是会引起全部回滚的。
【注:】
要避免使用异常,例如@Transactional(propagation="PROPAGATION_REQUIRED")修饰methodA、methodB,然后methodA内部调用methodB,且执行的methodB通过try catch消化掉异常信息。
在这个背景下,如果methodA被调用,且执行到内部的methodB时出现异常,这时候由于try catch将异常消化的缘故会继续执行剩余的代码块,当代码块走完后即methodA调用完成后会被代理执行事务提交。遗憾的是这种情况下不但不能提交,反而会引起异常TransactionException。

出现这个异常的原因有:
1、methodB共享了methodA的事务,当methodB异常时就已经为事务设置了rollback的标识,因此methodA无法成功提交
2、methodB的异常被catch掉,导致methodA无法上报异常最终触发了提交,发生了戏剧性的一幕
事务的传播原理
Spring采用Threadlocal 保证单个线程中的数据库操作使用的是同一个数据库连接,Mybatis逻辑同理。另一种用法就是事务,Spring的业务层使用事务时不需要管理connection对象,通过ThreadLocal实现了传播级别,巧妙地管理多个事务配置之间的切换,挂起和恢复。
事务的隔离级别
事务的隔离级别定义一个事务可能受其他并发务活动活动影响的程度,可以把事务的隔离级别想象为这个事务对于事物处理数据的自私程度。
在一个典型的应用程序中,多个事务同时运行,经常会为了完成他们的工作而操作同一个数据。并发虽然是必需的,但是会导致以下问题:
- 脏读(Dirty read)
脏读发生在一个事务读取了被另一个事务改写但尚未提交的数据时。如果这些改变在稍后被回滚了,那么第一个事务读取的数据就会是无效的。 - 不可重复读(Nonrepeatable read)
不可重复读发生在一个事务执行相同的查询两次或两次以上,但每次查询结果都不相同时。这通常是由于另一个并发事务在两次查询之间更新了数据。
不可重复读重点在修改。
- 幻读(Phantom reads)
幻读和不可重复读相似。当一个事务(T1)读取几行记录后,另一个并发事务(T2)插入了一些记录时,幻读就发生了。在后来的查询中,第一个事务(T1)就会发现一些原来没有的额外记录。
幻读重点在新增或删除。
在理想状态下,事务之间将完全隔离,从而可以防止这些问题发生。然而,完全隔离会影响性能,因为隔离经常涉及到锁定在数据库中的记录(甚至有时是锁表)。完全隔离要求事务相互等待来完成工作,会阻碍并发。因此,可以根据业务场景选择不同的隔离级别。
| 隔离级别(具体原理了解mvcc) | 含义 |
|---|---|
| ISOLATION_DEFAULT | 使用后端数据库默认的隔离级别 |
| ISOLATION_READ_UNCOMMITTED | 特性:允许读取其它事务尚未提交的更改 缺点:可能导致脏读、幻读或不可重复读。 |
| ISOLATION_READ_COMMITTED | 特性:允许从已经提交的并发事务读取。(Oracle 默认级别) 缺点:可防止脏读,但幻读和不可重复读仍可能会发生。 |
| ISOLATION_REPEATABLE_READ | 特性:对相同字段的多次读取的结果是一致的,除非数据被当前事务本身改变。(MYSQL默认级别) 缺点:可防止脏读和不可重复读,但幻读仍可能发生。 |
| ISOLATION_SERIALIZABLE | 特性:完全服从ACID的隔离级别,确保不发生脏读、不可重复读和幻影读。 缺点:这在所有隔离级别中也是最慢的,因为它通常是通过完全锁定当前事务所涉及的数据表来完成的。 |
【补:】
- 未提交读(read uncommitted):可读取其它事务未提交的数据,但是数据rollback的话数据就是脏数据,其它事务读取这种数据的操作称为脏读;
- 提交读(read committed):可读取其它事务已提交的数据和自身事务未提交的数据
- 但如果事务A提交了更新数据,事务B在数据提交前后的查询结果不一样,这种情况称为不可重复读,即记录被修改;
- 如果事务A提交了增删数据,事务B在数据提交前后的查询数据量不一样,这种情况称为幻读,即记录量被增删;
- 可重复读(repeatable read):在无当前读的情况下实现了可重复读和幻读
- 创建readview的事务执行了当前读使得readview更新可能出现幻读,即记录量被增删;
- 同样当前读也可能导致不可重读,即记录被修改;
- 序列化读(serializable):强制性对事务排序,通过锁来维护数据安全实现的,没办法并行,高并发下锁竞争和超时会导致低效,看业务场景选择吧。
【注:】
- 1-3均为写写互斥;4不仅写写互斥,还读写互斥;
- MySQL相关命令
- 查看当前会话的隔离级别:select @@tx_isolation;
- 查看系统的隔离级别:select @@global.tx_isolation;
- 设置会话的隔离级别,隔离级别由低到高设置依次为:
- set session transaction isolation level read uncommitted;
- set session transaction isolation level read committed;
- set session transaction isolation level repeatable read;
- set session transaction isolation level serializable;
- 设置当前系统的隔离级别,隔离级别由低到高设置依次为:
- set global transaction isolation level read uncommitted;
- set global transaction isolation level read committed;
- set global transaction isolation level repeatable read;
- set global transaction isolation level serializable;
- session隔离级别优先级高,如果没有再选用系统隔离;MySQL默认的事务处理级别是'REPEATABLE-READ',而Oracle和SQL Server是READ_COMMITED
好文推荐——真正理解MySQL四种隔离级别
好文推荐——依据功能和具体实现方式划分的各种锁
只读 @Transactional(readOnly=true)
如果一个事务只对数据库执行读操作,那么该数据库就可能利用那个事务的只读特性,采取某些优化措施。通过把一个事务声明为只读,可以给后端数据库一个机会来应用那些它认为合适的优化措施。由于只读的优化措施是在一个事务启动时由后端数据库实施的, 因此,只有对于那些具有可能启动新事务的传播行为(PROPAGATION_REQUIRES_NEW、PROPAGATION_REQUIRED、 ROPAGATION_NESTED)的方法来说,将事务声明为只读才有意义。
事务超时
为了使一个应用程序很好地执行,它的事务不能运行太长时间。因此,声明式事务的下一个特性就是它的超时。
假设事务的运行时间变得格外的长,由于事务可能涉及对数据库的锁定,所以长时间运行的事务会不必要地占用数据库资源。这时就可以声明一个事务在特定秒数后自动回滚,不必等它自己结束。
由于超时时钟在一个事务启动的时候开始的,因此,只有对于那些具有可能启动一个新事务的传播行为(PROPAGATION_REQUIRES_NEW、PROPAGATION_REQUIRED、ROPAGATION_NESTED)的方法来说,声明事务超时才有意义。
回滚规则
在默认设置下,事务只在出现运行时异常(runtime exception)时回滚,而在出现受检查异常(checked exception)时不回滚(这一行为和EJB中的回滚行为是一致的)。
不过,可以声明在出现特定受检查异常时像运行时异常一样回滚。同样,也可以声明一个事务在出现特定的异常时不回滚,即使特定的异常是运行时异常。
Spring编程式事务配置参考
-
开启注解事务,xml配置
-
@EnableTransactionManagement
Spring声明式事务配置参考
- 事务管理注解总开关:@EnableTransactionManagement,等同于xml配置方式的
- 事务的传播性:@Transactional(propagation=Propagation.REQUIRED)
- 事务的隔离级别:@Transactional(isolation = Isolation.READ_UNCOMMITTED)
【注:】
如果是springboot直接用@Transactional即可,因为@SpringBootApplication内置@EnableAutoConfiguration,@EnableAutoConfiguration又内置了@EnableTransactionManagement
好文推荐
读取未提交数据(会出现脏读, 不可重复读) 基本不使用
- 只读:
@Transactional(readOnly=true)
该属性用于设置当前事务是否为只读事务,设置为true表示只读,false则表示可读写,默认值为false。 - 事务的超时性:
@Transactional(timeout=30) - 回滚:
指定单一异常类:@Transactional(rollbackFor=RuntimeException.class)
指定多个异常类:@Transactional(rollbackFor={RuntimeException.class, Exception.class})
该属性用于设置需要进行回滚的异常类数组,当方法中抛出指定异常数组中的异常时,则进行事务回滚。
Mybatis——介绍
介绍
Mybatis 是一个开源的基于动态代理实现的半ORM 轻量级持久框架,核心部分仍然是JDBC,通过配置数据源、连接池实现connection 管理,开发时只需要关注SQL 语句,即prepareStatement 的使用
传统jdbc开发问题:
数据库连接创建,释放频繁,影响性能;
sql语句硬编码到程式,维护不便;
查询操作:需要手动把结果集中数据手动封装到实体;
增删改操作时,需要手动将实体数据设置到sql语句的占位符;
解决方案:使用数据库连接池初始化连接资源;
将sql语句抽象到xml文件中;
使用反射,内省等技术,自动将实体与表进行属性和字段的映射;
如何配置
Mybatis可以通过xml文件添加配置,通过xxxmapper.xml添加sql标签,也可以为xxxmapper接口添加sql注解,配置文件最后通过包扫描或者mapper路径匹配收集sql数据
优点
1、基于sql语句编程,灵活;2、持久层对外提供接口,隐藏JDBC,代码简洁;3、兼容多数据库;4、集成Spring;5、支持对象与字段的映射配置,维护方便;6、插件扩展
缺点
SQL语句依赖数据库,无法随意切换数据库
使用场景
对性能有调优需求,功能迭代快的产品
Mybatis——预编译
Mybatis——#{} 和${}
${}直接字符串替换,缺少检查机制,但简单高效;#{}则是预编译,先用占位符描述sql,然后校验传参是否合法,最后参数替换占位符,防止SQL注入
Mybatis——引入依赖
com.alibaba
druid
1.1.21
mysql
mysql-connector-java
5.1.32
org.mybatis
mybatis
3.4.6
junit
junit
4.12
test
Mybatis——JDBC回顾
下面是PreparedStatement实例操作sql(Statement实例操作略)
@Test
public void testPreparedStatement() {
Connection connection = null;
PreparedStatement preparedStatement = null;
try {
// 连接数据库
connection = JDBCTools.getConnection();
// 使用占位符的SQl语句
String sql = "insert into customers(name,email,birth)"
+ "values(?,?,?)";
// 使用preparedStatement的setXxx方法设置每一个位置上的值
preparedStatement = connection.prepareStatement(sql);
// 设置name字段
preparedStatement.setString(1, "ATGUIGU");
// 设置email字段
preparedStatement.setString(2, "[email protected]");
// 设置birth字段
preparedStatement.setDate(3,
new Date(new java.util.Date().getTime()));
// 执行更新操作
preparedStatement.executeUpdate();
} catch (Exception e) {
e.printStackTrace();
} finally {
// 释放资源
JDBCTools.release(null, preparedStatement, connection);
}
}Mybatis——Mybatis案例
1、创建user表,类型是 int、varchar、varchar

2、创建一个项目,然后布局如下,如果你上面的依赖加载成功的话,这里应该不会报啥问题

3、实体类
public class User {
private Integer id;
private String name;
private String pwd;
public User(Integer id, String name, String pwd) {
this.id = id;
this.name = name;
this.pwd = pwd;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPwd() {
return pwd;
}
public void setPwd(String pwd) {
this.pwd = pwd;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
", pwd='" + pwd + '\'' +
'}';
}
}4、UserMapper.xml
insert into user values (#{id},#{name},#{pwd});
update user set name = #{name} where id = 10
delete from user where pwd = #{pwd}
5、jdbc.properties
driver=com.mysql.jdbc.Driver
url=jdbc:mysql://192.168.0.2:3306/mybatis
username=root
password=root6、sqlMapConfig.xml
7、单元测试
@Slf4j
public class Test {
@org.junit.Test
public void mybatisQuickStart1() throws IOException {
// 加载核心配置文件
InputStream inputStream = Resources.getResourceAsStream("sqlMapConfig.xml");
// 获取sqlSessionFactory
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
// 获取sqlSession对象
SqlSession sqlSession = sqlSessionFactory.openSession();
// 查询操作
selectAll(sqlSession);
}
public void selectAll(SqlSession sqlSession){
List list = sqlSession.selectList("userMapper.findAll");
Iterator iterator = list.iterator();
while (iterator.hasNext()){
log.debug(iterator.next().toString());
}
}
}Mybatis——Mapper接口绑定
2、XML绑定:在mybatis-config文件配置
Sql语句比较简单用注解绑定,SQL比较复杂用xml绑定,一般用xml绑定,建议统一方式,别一会儿注解一会儿xml。
5、XML实现接口绑定的格式要求
Mybatis——如何获取自动生成的(主)键值
Mybatis——动态SQL编程
介绍
3、动态 SQL 含有很多扩展,可以根据传参拼接成合适的SQL,重用性高;
mybatis动态SQL - trim where set标签 - 简书 (jianshu.com)https://www.jianshu.com/p/d27f60937da9
Mybatis——批量插入
mapper方法:int addEmpsBatch(@param("emps") List employees);
insert into emp(ename,gender,email,did)
values
(#{emp.ename},#{emp.gender},#{emp.email},#{emp.dept})
Mybatis——参数传递方式
public UserselectUser(String name,String area);通过参数排序下标设置xml的SQL参数,#{0}代表接收的是 dao 层中的第一个参数,#{1}代表 dao 层中第二参数,以此类推。
2、使用 @param 注解指定别名
public interface usermapper {
user selectuser(@param(“user”) string userName);
}在 xml 中使用别名作为单个参数
3、多个参数封装成 map
List findByConditionByMap(HashMap map); 在 xml 中使用key作为单个参数,自动加载value
Mybatis——ResultMap
resultMap 是一种“查询结果集---Bean对象”属性名称映射关系,使用resultMap关系可将查询结果集中的列映射到bean对象的各个属性,用于一对一、一对多映射
mybatis:resultType、resultMap(级联,association,association分步,collection,collection分步,延迟,discriminator)_yubin1285570923的博客-CSDN博客https://blog.csdn.net/yubin1285570923/article/details/97553278?ops_request_misc=&request_id=&biz_id=102&utm_term=association%20resulttype&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-97553278.142%5Ev92%5EchatgptT3_1&spm=1018.2226.3001.4187 1、连接查询(在resultMap里面可以配置连接条件,利用association标签)
2、适用于表的一对多连接查询,(如,订单对应多个订单明细时,需要根据连接条件订单id匹配订单明细,并且消除重复的订单信息(订单明细中的),如下程序);
Mybatis——懒/延迟加载
Mybatis仅支持association关联对象和collection关联集合对象的延迟加载,association指的就是一对一,collection指的就是一对多查询。
在Mybatis配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=true|false。它的原理是,使用CGLIB创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用a.getB().getName(),拦截器invoke()方法发现a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完成a.getB().getName()方法的调用。
不光是Mybatis,几乎所有的包括Hibernate,支持延迟加载的原理都是一样的
Mybatis——缓存
MyBatis 内置了一个强大的事务性查询缓存机制,包括一级缓存,二级缓存,它可以非常方便地配置和定制。一级缓存是sqlSession级别的缓存,二级缓存是Mapper 命名空间级别的缓存。
MyBatis 默认是开启一级缓存的,即同一个 sqlSession 每次查询都会先去缓存中查询,没有数据的话,再去数据库获取数据。它的默认配置就是启用二级缓存的,所以这个不用我们操心。因为Mybatis二级缓存是基于mapper级别的,所以还需要在各个Mapper 命名空间中进行进一步设置。
1、Spring Boot 开启二级缓存:首先yml中配置mybatis-plus.configuration.cache-enabled=true,然后sql语句存在于mapper.xml上时,在
加上这个标签,二级缓存就会启用,它的默认属性如下:
- 映射语句文件中的所有 select 语句将会被缓存。
- 映射语句文件中的所有 insert,update 和 delete 语句会刷新缓存。
- 缓存会使用 Least Recently Used(LRU,最近最少使用的)算法来收回。
- 根据时间表(比如 no Flush Interval,没有刷新间隔), 缓存不会以任何时间顺序来刷新。
- 缓存会存储列表集合或对象(无论查询方法返回什么)的 1024 个引用。
- 缓存会被视为是 read/write(可读/可写)的缓存,意味着对象检索不是共享的,而且可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
2、可用的清除策略有:
- LRU – 最近最少使用:移除最长时间不被使用的对象。
- FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
- SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象。
- WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
- 默认的清除策略是 LRU。
3、如果sql语句用注解,则需要给接口添加@CacheNamespace
使用二级缓存时,sql语句的映射要么全xml格式表示,要么注解表示,二选一,不然可能会出现无法利用二级缓存或二级缓存没有及时清空的bug问题
如果命中缓存后会提示 Cache hit ratio ...
4、使用Redis管理二级缓存
4.1、配置插件如下:
@Slf4j
public class MybatisRedisCache implements Cache {
// 读写锁
private final ReadWriteLock readWriteLock = new ReentrantReadWriteLock(true);
//这里使用了redis缓存,使用springboot自动注入
private RedisTemplate redisTemplate;
private String id;
public MybatisRedisCache(String id) {
if (id == null) {
throw new IllegalArgumentException("Cache instances require an ID");
}
this.id = id;
}
@Override
public String getId() {
return this.id;
}
@Override
public void putObject(Object key, Object value) {
if (redisTemplate == null) {
//由于启动期间注入失败,只能运行期间注入,这段代码可以删除
redisTemplate = (RedisTemplate) SpringUtil.getBean("redisTemplate");
}
if (value != null) {
redisTemplate.opsForValue().set(key.toString(), value);
redisTemplate.expire(key.toString(),1, TimeUnit.HOURS);
}
}
@Override
public Object getObject(Object key) {
if (redisTemplate == null) {
//由于启动期间注入失败,只能运行期间注入,这段代码可以删除
redisTemplate = (RedisTemplate) SpringUtil.getBean("redisTemplate");
}
try {
if (key != null) {
return redisTemplate.opsForValue().get(key.toString());
}
} catch (Exception e) {
e.printStackTrace();
log.error("缓存出错 ");
}
return null;
}
@Override
public Object removeObject(Object key) {
if (redisTemplate == null) {
//由于启动期间注入失败,只能运行期间注入,这段代码可以删除
redisTemplate = (RedisTemplate) SpringUtil.getBean("redisTemplate");
}
if (key != null) {
redisTemplate.delete(key.toString());
}
return null;
}
@Override
public void clear() {
log.debug("清空缓存");
if (redisTemplate == null) {
redisTemplate = (RedisTemplate) SpringUtil.getBean("redisTemplate");
}
Set keys = redisTemplate.keys("*:" + this.id + "*");
if (!CollectionUtils.isEmpty(keys)) {
redisTemplate.delete(keys);
}
}
@Override
public int getSize() {
if (redisTemplate == null) {
//由于启动期间注入失败,只能运行期间注入,这段代码可以删除
redisTemplate = (RedisTemplate) SpringUtil.getBean("redisTemplate");
}
Long size = redisTemplate.execute((RedisCallback) RedisServerCommands::dbSize);
return size.intValue();
}
@Override
public ReadWriteLock getReadWriteLock() {
return this.readWriteLock;
}
} 4.2、添加属性给cache:
4.2.1、注解cache配置
@CacheNamespace(implementation = MybatisRedisCache.class)
public interface UserMapper(
@Select("select * from t_user where user_id = #{userId}")
@Options(useCache = true)
List getUser(User u);
} 4.2.2、xml文件cache配置
【注:】
- Mapper中的数据表类也需要实现序列化;
- Mybatis-Plus的BaseMapper方法使用@CacheNamespace,如果是自定义sql则按照上述3的要求配置
Mybatis——拦截器
介绍
Interceptor 接口提供三个方法,intercept、plugin和setProperties。
setProperties:自定义properties,SqlSessionFactoryBuilder.build("xxx.xml") 将文件配置加载后由XmlConfigBuilder 创建Configuration 实例,并属性填充,其中interceptorChain 属性的填充就是迭代所有interceptors 完成实例化并执行setProperties(Properties ps) 方法;
plugin:在创建Executor、ParameterHandler、ResultSetHandler和StatementHandler时会通过InterceptorChain做迭代,即判断拦截器对当前实例有无拦截点设置,如果有则生成JDK动态代理对象并返回。这个功能封装就是plugin方法,官方为plugin提供了通用处理方法,直接重写到自定义的plugin 方法即可:return Plugin.wrap(target, this);
intercept:用于拦截指定方法并通过传参增强功能,如分页查询,日期填充,id策略;
public interface Interceptor {
Object intercept(Invocation invocation) throws Throwable;
Object plugin(Object target);
void setProperties(Properties properties);
}四大拦截对象
只能拦截 Executor、ParameterHandler、ResultSetHandler和StatementHandler,基本上都是拦截Executor

- Executor 是 Mybatis的内部执行器,它负责调用StatementHandler 操作数据库;
- StatementHandler 是Mybatis 封装JDBC 的对象,整合调用ParameterHandler、ResultSetHandler、boundsql、mappedstatement等资源;
- ParameterHandler 是Mybatis 实现Sql 入参设置的对象,插件可以改变Sql的参数设置;
- ResultSetHandler 是Mybatis 把ResultSet 集合映射成POJO的对象;
@Signature
用于指定拦截点的接口、方法和方法参数
<-- mybatis-config.xml -->
---------------------------------------------------------------
// ExamplePlugin.java
@Intercepts({@Signature(
type= Executor.class,
method = "update",
args = {MappedStatement.class,Object.class})})
public class ExamplePlugin implements Interceptor {
public Object intercept(Invocation invocation) throws Throwable {
return invocation.proceed();
}
public Object plugin(Object target) {
return Plugin.wrap(target, this);
}
public void setProperties(Properties properties) {
}
}Mybatis——Mybatis分页原理
Mybatis——执行原理
1、加载配置:配置来源于两个地方,一处是配置文件,一处是Java代码的注解,将SQL的配置信息加载成为一个个MappedStatement对象(包括了传入参数映射配置、执行的SQL语句、结果映射配置),存储在内存中。
2、SQL解析:当API接口层接收到请求时,会接收到传入SQL的ID和传入对象(可以是Map、JavaBean或者基本数据类型),Mybatis会根据ID从Configuration.mappedStatements找到对应的MappedStatement,然后根据传入参数对象对MappedStatement进行解析,解析后可以得到最终要执行的SQL。
3、SQL执行:将最终得到的SQL拿到数据库进行执行,得到操作数据库的结果。
4、结果映射:将操作数据库的结果按照映射的配置进行转换,可以转换成HashMap、JavaBean或者基本数据类型,并将最终结果返回

Mybatis——Executor-type介绍
mybatis提供三种sql执行器,分别是SIMPLE、REUSE、BATCH。
1、SIMPLE是默认执行器,根据对应的sql直接执行,不会做一些额外的操作。
2、REUSE是可重用执行器,重用对象是Statement(即该执行器会缓存同一个sql的Statement,省去Statement的重新创建,优化性能)(即会重用预处理语句)
3、BATCH执行器会重用预处理语句,并执行批量更新。
Mybatis——Executor-type执行效果
1、SIMPLE、REUSE:可通过insert、update、delete方法的返回值判断sql是否执行成功,返回非0表示执行sql成功的条数,返回0表示sql执行失败
2、BATCH:insert、update、delete方法返回值一直会是负数-2147482646,在该模式下insert、update、delete返回值将无任何意义,不能作为判断sql执行成功的判断依据
Mybatis——全流程描述
加载xml配置文件到内存,执行XmlConfigBuilder创建Configuration实例,然后解析配置信息填充Configuration实例,比如常见的interceptorChain,mapperedStatements,mapperRegistry都在这一时期完成配置
SqlSessionFactory sqlSessionFactory = sqlSessionFactoryBuilder.build("...xml");创建Executor,无参构造默认是SimpleExecutor,拦截器在这一时期基于责任链模式和JDK动态代理创建Executor代理对象并返回
sqlSession sq = sqlSessionFactory.openSession();基于JDK动态代理生成mapper实例
xxxMapper mapper = sq.getMapper(xxx.class);当调用接口方法时,获取sqlSession对象,sqlSession 根据接口全限名+方法名拼接字符串作为key值,从mappedStatements定位mappedStatement。然后executor以传参和mappedStatement为参数执行自身方法,将结果返回。
mapper.query(...);SpringBoot
1. SpringBoot基础
1.1 什么是SpringBoot?
- 简化Spring应用开发,实现了约定大于配置
- 创建独立的Spring引用程序main方法运行
- 嵌入的tomcat无需部署war文件
- 简化maven配置
- 自动配置
1.2 SpringBoot有哪些优点?
- 独立运行
Spring Boot 而且内嵌了各种 servlet 容器,Tomcat、Jetty 等,现在不再需要打成war 包部署到容器中,Spring Boot 只要打成一个可执行的 jar 包就能独立运行,所有的依赖包都在一个 jar 包内。 - 简化配置
spring-boot-starter-web 启动器自动依赖其他组件,简少了 maven 的配置。 - 自动配置
Spring Boot 能根据当前类路径下的类、jar 包来自动配置 bean,如添加一个 spring-boot-starter-web 启动器就能拥有 web 的功能,无需其他配置。 - 无代码生成和XML配置
Spring Boot 配置过程中无代码生成,也无需 XML 配置文件就能完成所有配置工作,这一切都是借助于条件注解完成的,这也是 Spring4.x 的核心功能之一。 - 避免大量的Maven导入和各种版本冲突
- 应用监控
Spring Boot 提供一系列端点可以监控服务及应用,做健康检测。
1.3 SpringBoot的核心注解是什么?由那些注解组成?
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan(excludeFilters = {
@Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),
@Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })
public @interface SpringBootApplication {主要组合包含了以下 3 个注解:
- @SpringBootConfiguration:
组合了 @Configuration 注解,表示启动类是一个配置类。 - @EnableAutoConfiguration:
向Spring容器导入了一个Selector,用来加载classpath下SpringFactories中所定义的自动配置类,也可以关闭某个自动配置的选项,如关闭数据源自动配置功能: @SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })。 - @ComponentScan:
Spring组件扫描,可以指定多个扫描路径,如@ComponentScan({"com.sx.srb"}),默认是扫描启动类所在路径。
1.4 什么是JavaConfig?
Spring JavaConfig 是 Spring 社区的产品,它提供了配置 Spring IoC 容器的纯Java 方法。因此它有助于避免使用 XML 配置。使用 JavaConfig 的优点在于:
- 面向对象的配置。
由于配置被定义为 JavaConfig 中的类,因此用户可以充分利用 Java 中的面向对象功能。一个配置类可以继承另一个,重写它的@Bean 方法等。 - 减少或消除 XML 配置。
基于依赖注入原则的外化配置的好处已被证明。但是,许多开发人员不希望在 XML 和 Java 之间来回切换。JavaConfig 为开发人员提供了一种纯 Java 方法来配置与 XML 配置概念相似的 Spring 容器。从技术角度来讲,只使用 JavaConfig 配置类来配置容器是可行的,但实际上很多人认为将JavaConfig 与 XML 混合匹配是理想的。 - 类型安全和重构友好。
JavaConfig 提供了一种类型安全的方法来配置 Spring容器。由于 Java 5.0 对泛型的支持,现在可以按类型而不是按名称检索 bean,不需要任何强制转换或基于字符串的查找。
1.5 SpringBoot自动配置原理是什么?
- SpringBoot启动会加载大量的自动配置类
- 看需要的功能有没有在SpringBoot默认写好的自动配置类当中;
- 再看这个自动配置类中到底配置了哪些组件;(只要我们要用的组件存在在其中,我们就不需要再手动配置了)
- @EnableAutoConfiguration选择路径是各个jar包的resource/meta-inf/spring.factories,只需在该文件指定配置类全名,开发项目就会基于反射和yml配置实例化。
// 路径为resource/meta-inf/spring.factories org.springframework.boot.autoconfigure.EnableAutoConfiguration=\ com.sg.config.SwaggerConfig
1.6 你如何理解SpringBoot配置加载顺序?
1. 开发者工具 `Devtools` 全局配置参数;
2. 单元测试上的 `@TestPropertySource` 注解指定的参数;
3. 单元测试上的 `@SpringBootTest` 注解指定的参数;
4. 命令行指定的参数,如 `java -jar springboot.jar --name="码霸霸"`;
5. 命令行中的 `SPRING_APPLICATION_JSONJSON` 指定参数, 如 `java -Dspring.application.json='{"name":"码霸霸"}' -jar springboot.jar`;
6. `ServletConfig` 初始化参数;
7. `ServletContext` 初始化参数;
8. JNDI参数(如 `java:comp/env/spring.application.json`);
9. Java系统参数(来源:`System.getProperties()`);
10、操作系统环境变量参数;
11、`RandomValuePropertySource` 随机数,仅匹配:`ramdom.*`;
12、JAR包外面的配置文件参数(`application-{profile}.properties(YAML)`);
13、JAR包里面的配置文件参数(`application-{profile}.properties(YAML)`);
14、JAR包外面的配置文件参数(`application.properties(YAML)`);
15、JAR包里面的配置文件参数(`application.properties(YAML)`);
16、`@Configuration`配置文件上 `@PropertySource` 注解加载的参数;
17、默认参数(通过 `SpringApplication.setDefaultProperties` 指定);1.7 运行 SpringBoot 有哪几种方式?
- 打包用命令或者放到容器中运行
- 用 Maven/ Gradle 插件运行
- 直接执行 main 方法运行
1.8 SpringBoot 需要独立的容器运行吗?
不需要,内置了 Tomcat/ Jetty 等容器。
1.9 开启SpringBoot 特性有哪几种方式?
- 继承spring-boot-starter-parent项目
- 导入spring-boot-dependencies项目依赖
1.10 SpringBoot、Spring MVC和Spring有什么区别?
- Spring
Spring最重要的特征是依赖注入。所有Spring Modules不是依赖注入就是IOC控制反转。
当我们恰当的使用DI或者是IOC的时候,可以开发松耦合应用。 - Spring MVC
Spring MVC提供了一种分离式的方法来开发Web应用。通过运用像DispatcherServelet,MoudlAndView 和 ViewResolver 等一些简单的概念,开发 Web 应用将会变的非常简单。 - SpringBoot
Spring和Spring MVC的问题在于需要配置大量的参数。
SpringBoot通过一个自动配置和启动的项来解决这个问题。
1.11 SpringBoot启动时都做了什么?
- SpringBoot在启动的时候从类路径下的META-INF/spring.factories中获取EnableAutoConfiguration指定的值
- 将这些值作为自动配置类导入容器 , 自动配置类就生效 , 帮我们进行自动配置工作;
- 整个J2EE的整体解决方案和自动配置都在springboot-autoconfigure的jar包中;
- 它会给容器中导入非常多的自动配置类(xxxAutoConfiguration), 就是给容器中导入这个场景需要的所有组件 , 并配置好这些组件;
- 有了自动配置类 , 免去了我们手动编写配置注入功能组件等的工作;
2. SpringBoot配置
2.1 什么是YAML?
YAML 是一种配置文件格式。在配置文件中添加复杂的配置可以展示出非常结构化的效果。可以直观看出 YAML 的各层配置数据。
2.2 YAML 配置的优势在哪里 ?
-
- 配置有序
- 支持数组,数组中的元素可以是基本数据类型也可以是对象
- 格式间接,层次分明
相比 properties 配置文件,YAML 还有一个缺点,就是不支持 @PropertySource 注解导入自定义的 YAML 配置。
2.3 SpringBoot 是否可以使用 XML 配置 ?
Spring Boot 推荐使用 Java 配置而非 XML 配置,但是 Spring Boot 中也可以使用 XML 配置,通过 @ImportResource 注解可以引入一个 XML 配置。
2.4 SpringBoot核心配置文件是什么?
bootstrap.properties和application.properties
2.5 bootstrap.properties和application.properties 有何区别 ?
SpringBoot两个核心的配置文件:
- bootstrap(.yml 或者 .properties):boostrap 由父 ApplicationContext 加载的,比applicaton优先加载,配置在应用程序上下文的引导阶段生效。一般来说我们在 SpringCloud Config 或者Nacos中会用到它。且boostrap里面的属性不能被覆盖;
- application (.yml或者.properties):由ApplicatonContext 加载,用于 SpringBoot项目的自动化配置。
2.6 什么是Spring Profiles?
主要用来区分环境;
Spring Profiles 允许用户根据配置文件(dev,test,prod 等)来注册 bean。因此,当应用程序在开发中运行时,只有某些 bean 可以加载,而在 PRODUCTION中,某些其他 bean 可以加载。假设我们的要求是 Swagger 文档仅适用于 QA 环境,并且禁用所有其他文档。这可以使用配置文件来完成。Spring Boot 使得使用配置文件非常简单。
2.7 如何在自定义端口上运行SpringBoot应用程序?
SpringBoot默认监听的是8080端口;为了在自定义端口上运行 SpringBoot 应用程序,您可以在application.properties 中通过
server.port = 8888指定端口;这样就可以将监听的端口修改为8888。
3. SpringBoot 安全性
3.1 如何实现SpringBoot应用程序的安全性?
为了实现SpringBoot的安全性,使用spring-boot-starter-security依赖项,必须添加安全配置。配置类需要扩展WebSecurityConfigurerAdapter类并覆盖其方法。
3.2 Spring Security 和Shiro各自的优缺点 ?
Shiro和Spring Security相比,主要有如下一些特点:
- Spring Security 是一个重量级的安全管理框架;Shiro 则是一个轻量级的安全管理框架
- Spring Security 概念复杂,配置繁琐;Shiro 概念简单、配置简单
- Spring Security 功能强大,支持单机、分布式、oauth;Shiro 相对简单,可以做认证、授权和session管理
3.3 SpringBoot 如何解决跨域问题 ?
跨域可以在前端通过 JSONP 来解决,但是 JSONP 只可以发送 GET 请求,无法发送其他请求,因此我们推荐在后端通过 (CORS,Cross-origin resource sharing) 来解决跨域问题。在传统的 SSM 框架中,都是通过 CORS 来解决跨域问题,只不过之前我们是在 XML 文件中配置 CORS ,现在可以通过实现WebMvcConfigurer接口然后重写addCorsMappings方法解决跨域问题。
@Configuration
public class CorsConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/**")
.allowedOrigins("*")
.allowCredentials(true)
.allowedMethods("GET", "POST", "PUT", "DELETE", "OPTIONS")
.maxAge(3600);
}
}项目中前后端分离部署,所以需要解决跨域的问题。
我们使用cookie存放用户登录的信息,在spring拦截器进行权限控制,当权限不符合时,直接返回给用户固定的json结果。
当用户登录以后,正常使用;当用户退出登录状态时或者token过期时,由于拦截器和跨域的顺序有问题,出现了跨域的现象。
我们知道一个http请求,先走filter,到达servlet后才进行拦截器的处理,如果我们把cors放在filter里,就可以优先于权限拦截器执行。
@Configuration
public class CorsConfig {
@Bean
public CorsFilter corsFilter() {
CorsConfiguration corsConfiguration = new CorsConfiguration();
corsConfiguration.addAllowedOrigin("*");
corsConfiguration.addAllowedHeader("*");
corsConfiguration.addAllowedMethod("*");
corsConfiguration.setAllowCredentials(true);
UrlBasedCorsConfigurationSource urlBasedCorsConfigurationSource = new UrlBasedCorsConfigurationSource();
urlBasedCorsConfigurationSource.registerCorsConfiguration("/**", corsConfiguration);
return new CorsFilter(urlBasedCorsConfigurationSource);
}
}3.4 什么是 CSRF 攻击?
CSRF 代表跨站请求伪造。这是一种攻击,迫使最终用户在当前通过身份验证的Web 应用程序上执行不需要的操作。CSRF 攻击专门针对状态改变请求,而不是数据窃取,因为攻击者无法查看对伪造请求的响应。
3.5 SpringBoot 中的监视器是什么
Spring boot actuator 可访问生产环境中正在运行的应用状态;
比如有几个指标必须在生产环境中进行检查和监控,监视器可以指定管理端口,并公开监控指标,管理者可直接访问端点检查状态;
默认公开的只有health和info,其余均需配置公开。
org.springframework.boot
spring-boot-starter-actuator
2.0.4.RELEASE
org.springframework.boot
spring-boot-starter-web
server.tomcat.uri-encoding=UTF-8
# 程序运行端口
server.port=8888
# 监视程序运行端口
management.server.port=8090
# 激活所有的内置Endpoints
management.endpoints.web.exposure.include=*
management.endpoints.web.exposure.exclude=env,beans
# 开启shutdown这个endpoint
management.endpoint.shutdown.enabled=true3.6 如何在SpringBoot中禁用Actuator端点安全性?
默认情况下,所有敏感的HTTP端点都是安全的,只有具有ACTUATOR角色的用户才能访问它们。可以用 management.security.enabled=false 来禁用安全性。当执行端点在防火墙后时,才建议禁用安全性。
3.7 如何监视所有SpringBoot微服务?
SpringBoot提供监视器端点以监控各个微服务的度量。这些端点对于查看应用的状态是否正常运行很有帮助。但是,使用监视器的一个主要缺点或困难是,我们必须单独打开应用端点以了解其状态或健康状况。想象一下涉及 50 个应用程序的微服务,管理员将不得不击中所有 50 个应用程序的执行终端。为了处理这种情况,引入了spring boot admin。 它建立在 Spring Boot Actuator 之上,提供了一个 Web UI,使我们能够可视化多个应用程序的度量。
4. SpringBoot进阶
4.1 什么是 WebSockets?
WebSocket是一种计算机通信协议,通过单个TCP连接提供全双工通信信道。
- WebSocket是双向的 -使用 WebSocket 客户端或服务器可以发起消息发送。
- WebSocket是全双工的 -客户端和服务器通信是相互独立的。
- 单个TCP连接 -初始连接使用 HTTP,然后将此连接升级到基于套接字的连接。然后这个单一连接用于所有未来的通信
- 与http相比,WebSocket消息数据交换要轻得多。
4.2 什么是 FreeMarker 模板?
FreeMarker 是 Java WEB模板引擎,主要优点是表示层和业务层的完全分离。程序员可以处理应用程序代码,而设计人员可以处理 html 页面设计。最后使用freemarker 可以将这些结合起来,给出最终的输出页面。
4.3 Swagger用过麽?他用来做什么?
Swagger广泛用于可视化API,使用SwaggerUl为前端开发人员提供在线沙箱。Swagger 是用于生成RESTful Web服务的可视化表示的工具,规范和完整框架实现。它使文档能够以与服务器相同的速度更新。当通过Swagger 正确定义时,消费者可以使用最少量的实现逻辑来理解远程服务并与其进行交互。
4.4 前后端分离,如何维护接口文档 ?
大部分情况下,我们都是通过 Spring Boot 做前后端分离开发,前后端分离一定会有接口文档。传统的方法就是使用 word 或者 md 来维护接口文档,但是效率太低,接口一变,所有人手上的文档都得变。在 Spring Boot 中,这个问题常见的解决方案是 Swagger ,使用 Swagger 我们可以快速生成一个接口文档网站,接口一旦发生变化,文档就会自动更新,所有开发工程师访问这一个在线网站就可以获取到最新的接口文档,非常方便。
4.5 SpringBoot项目如何热部署?
这可以使用 DEV 工具来实现。通过这种依赖关系,您可以节省任何更改,嵌入式tomcat 将重新启动。Spring Boot 有一个开发工具(DevTools)模块,它有助于提高开发人员的生产力。Java 开发人员面临的一个主要挑战是将文件更改自动部署到服务器并自动重启服务器。开发人员可以重新加载 Spring Boot 上的更改,而无需重新启动服务器。这将消除每次手动部署更改的需要。Spring Boot 在发布它的第一个版本时没有这个功能。这是开发人员最需要的功能。DevTools 模块完全满足开发人员的需求。该模块将在生产环境中被禁用。它还提供 H2 数据库控制台以更好地测试应用程序。
org.springframework.boot
spring-boot-devtools4.6 SpringBoot 中的starter到底是什么 ?
SpringBootStarter是基于 Spring 已有功能来实现的。SpringBootStarter的核心注解是自动配置注解(@EnableAutoConfiguration,属SpringBoot注解),在这个配置类中通过条件注解来决定一个配置是否生效(@Conditional系列,均属Spring注解),允许开发者自定义Starter,新注入的属性会代替掉默认属性。开发者只需要引入依赖就可以完成依赖配置。
4.7 自定义一个Starter
(102条消息) 如何自定义starter_田维常的博客-CSDN博客
org.springframework.boot
spring-boot-autoconfigure
2.0.0.RELEASE
org.springframework.boot
spring-boot-configuration-processor
2.0.0.RELEASE
true
import org.springframework.boot.context.properties.ConfigurationProperties;
@ConfigurationProperties(prefix = "spring.tian")
public class TianProperties {
// 姓名
private String name;
// 年龄
private int age;
// 性别
private String sex = "M";
//get and set
}public class TianService {
private TianProperties properties;
public TianService() {
}
public TianService(TianProperties userProperties) {
this.properties = userProperties;
}
public void sayHello(){
System.out.println("hi, 我叫: " + properties.getName() +
", 今年" + properties.getAge() + "岁"
+ ", 性别: " + properties.getSex());
}
}@Configuration
@EnableConfigurationProperties(TianProperties.class)
@ConditionalOnClass(TianService.class)
@ConditionalOnProperty(prefix = "spring.tian", value = "enabled", matchIfMissing = true)
public class TianServiceAutoConfiguration {
@Autowired
private TianProperties properties;
@Bean
@ConditionalOnMissingBean(TianService.class)
public TianService tianService() {
return new TianService(properties);
}
}resource/meta-inf/spring.factories
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.tian.TianServiceAutoConfiguration然后做成jar包,名称就可以叫做 spring-boot-tian-starter.jar
然后创建一个Spring Boot项目test
在项目中把自定义starter添加pom依赖
com.tian
spring-boot-tian-starter
1.0-SNAPSHOT
TestApplication启动类
@SpringBootApplication
@EnableEurekaServer
public class TestApplication {
public static void main(String[] args) {
SpringApplication.run(TestApplication.class, args);
}
}application.properties中配置
spring.tian.name=tian
spring.tian.age=22
spring.tian.sex=M写一个TestController.java类
RestController
@RequestMapping("/my")
public class TestController {
@Resource
private TianService tianService;
@PostMapping("/starter")
public Object starter() {
tianService.sayHello();
return "ok";
}
}最后启动项目,输入http://localhost:9091/my/starter,后台打印
hi, 我叫: tian, 今年22岁, 性别: M
这就成功的现实了自定义的starter。4.8 spring-boot-starter-parent 有什么用?
新创建一个 SpringBoot 项目,默认都是有 parent 的,这个 parent 就是 spring-boot-starter-parent ,spring-boot-starter-parent 主要有如下作用:
- 定义了 Java 编译版本为 1.8 。
- 使用 UTF-8 格式编码。
- 继承自 spring-boot-dependencies,这个里边定义了依赖的版本,也正是因为继承了这个依赖,所以我们在写依赖时才不需要写版本号。
- 执行打包操作的配置。
- 自动化的资源过滤。
- 自动化的插件配置。
- 针对 application.properties 和 application.yml 的资源过滤,包括通过 profile 定义的不同环境的配置文件,例如 application-dev.properties 和 application-dev.yml。
4.9 SpringBoot 打成的jar和普通的jar有什么区别 ?
SpringBoot 项目最终打包成的 jar 是可执行 jar ,这种 jar 可以直接通过 java -jar xxx.jar 命令运行,不可以作为普通的jar 被其他项目依赖,即使依赖了也无法使用。
SpringBoot 的 jar 无法被其他项目依赖,主要还是他和普通 jar 的结构不同。普通的 jar 包,解压后直接就是包名,包里就是我们的代码,而 Spring Boot 打包成的可执行 jar 解压后,在 \BOOT-INF\classes 目录下才是我们的代码,因此无法被直接引用。如果非要引用,可以在 pom.xml 文件中增加build配置,将 Spring Boot 项目打成两个 jar,一个可执行,一个可引用。
4.10 如何使用SpringBoot实现异常处理?
Spring 提供了@RestControllerAdvice 处理异常的非常有用的方法。 我们通过实现一个 ControlerAdvice 类,通过@ExceptionHandler注解来拦截控制器类抛出的所有异常。
4.11 微服务中如何实现 session 共享?
在微服务中,一个完整的项目被拆分成多个不相同的独立的服务,各个服务独立部署在不同的服务器上,各自的 session 被从物理空间上隔离开了,但是经常,我们需要在不同微服务之间共享 session ,常见的方案就是 Spring Session + Redis 来实现 session 共享。将所有微服务的session 统一保存在 Redis 上,当各个微服务对 session 有相关的读写操作时,都去操作 Redis 上的 session 。这样就实现了 session 共享,Spring Session 基于 Spring 中的代理过滤器实现,使得 session 的同步操作对开发人员而言是透明的,非常简便。
4.12 SpringBoot 中如何实现定时任务?
SpringBoot 中对于定时任务的支持主要还是来自 Spring 框架。
在 SpringBoot 中使用定时任务主要有两种不同的方式,一个就是使用 Spring 中的 @Scheduled 注解,另一个则是使用第三方分布式框架 XXL-JOB、Quartz等。
- 使用Spring中的 @Scheduled的方式主要通过@Scheduled注解来实现。
- 使用Quartz,则按照Quartz的方式,定义Job和Trigger即可。