SaprkStreaming广告日志分析实时数仓
一、系统简介
参考尚硅谷的spark教程中的需求,参考相关思路,详细化各种代码,以及中间很多逻辑的实现方案采用更加符合项目开发的方案,而不是练习,包括整体的流程也有很大的差别,主要是参考需求描述和部分代码功能实现。
需求一:广告黑名单
实现实时的动态黑名单机制:将每天对某个广告点击超过 100 次的用户拉黑。
注:黑名单保存到 MySQL 中。
1)读取 Kafka 数据之后,并对 MySQL 中存储的黑名单数据做校验;
2)校验通过则对给用户点击广告次数累加一并存入 MySQL;
3)在存入 MySQL 之后对数据做校验,如果单日超过 100 次则将该用户加入黑名单。
需求二:广告点击量实时统计
描述:实时统计每天各地区各城市各广告的点击总流量,并将其存入 MySQL。
1)单个批次内对数据进行按照天维度的聚合统计;
2)结合 MySQL 数据跟当前批次数据更新原有的数据。
需求三:最近一小时广告点击量
1)开窗确定时间范围;
2)在窗口内将数据转换数据结构为((adid,hm),count);
3)按照广告 id 进行分组处理,组内按照时分排序。
二、涉及技术栈
代码开发:scala
大数据组件:hadoop,kafka,zookeeper
数据库:mysql
代码迭代方式:gitee
(gitee地址:[email protected]:sawa0725/spark-streaming-demand.git,也是作为初学者的一次练手,有实现方式错误的地方,欢迎各位提出意见!)
三、项目架构流程
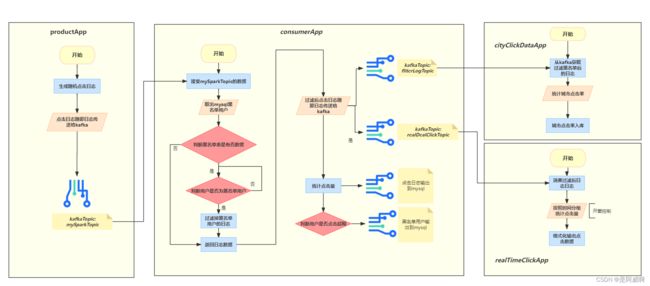
四、开发模式
spark开发模式
参考spark开发模式-三层架构
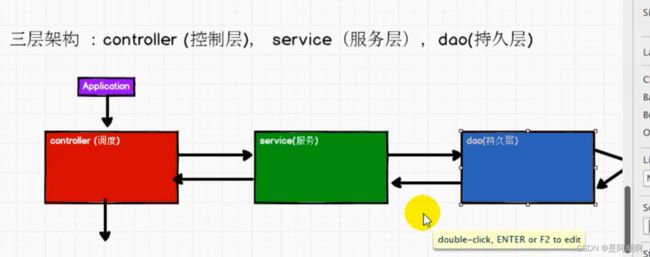
项目结构介绍
application--应用层,应用的起始
common--部分类抽象出来的一部分,共通类,多个类的共同代码
controller--控制层,主体流程控制
service --服务层,计算逻辑
dao--持久层主要负责对数据的读取,跟文件、数据库等打交道
util--工具类,在哪儿都能用(字符串判断等)
bean:实体类
service是需求逻辑实现的重点模块
Dao是数据交互实现的重点模块
五、Util模块解析

EnvUtil
因为Dao层要跟文件和数据库等交互,所以需要读到一些spark环境存入到线程中,以供Dao使用
包含功能
1、环境线程的准备
2、spark环境的get、set和clear
代码展示
package spark.SparkStreamingProject.util
import org.apache.spark.SparkContext
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.StreamingContext
object EnvUtil {
private val scLocal = new ThreadLocal[SparkContext]()//定义sparkContext到内存线程中
private val sparkLocal = new ThreadLocal[SparkSession]()//定义SparkSession到内存线程中
private val sscLocal = new ThreadLocal[StreamingContext]()//定义StreamingContext到内存线程中
//三个环境分别生成get、set、clean函数
def scGet(): SparkContext = {
scLocal.get()
}
def scSet(sc: SparkContext): Unit = {
scLocal.set(sc)
}
def scClean(): Unit = {
scLocal.remove()
}
def sparkGet(): SparkSession = {
sparkLocal.get()
}
def sparkSet(spark:SparkSession): Unit = {
sparkLocal.set(spark)
}
def sparkClean(): Unit = {
sparkLocal.remove()
}
def sscGet(): StreamingContext = {
sscLocal.get()
}
def sscSet(ssc: StreamingContext): Unit = {
sscLocal.set(ssc)
}
def sscClean(): Unit = {
sscLocal.remove()
}
}
jdbcUtil
包含功能
获取mysql连接 此处实现逻辑可以变更为使用资源池来管理mysql连接
代码展示
package SparkStreamingProject.util
import com.alibaba.druid.pool.DruidDataSourceFactory
import java.sql.Connection
import java.util.Properties
object jdbcUtil extends Serializable {
def mysqlConnect(): Connection = {
val properties = new Properties()
val config: Properties = PropertiesUtil.load("config.properties")
properties.setProperty("driverClassName", "com.mysql.jdbc.Driver")
properties.setProperty("url", config.getProperty("jdbc.url"))
properties.setProperty("username", config.getProperty("jdbc.user"))
properties.setProperty("password", config.getProperty("jdbc.password"))
properties.setProperty("maxActive",
config.getProperty("jdbc.datasource.size")
)
//获取 MySQL 连接
DruidDataSourceFactory.createDataSource(properties).getConnection
}
}
KafkaUtil
包含功能
获取KafkaPara用于消费topic数据
获取KafkaProducer,用于生产topic数据
代码实现
package SparkStreamingProject.util
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig}
import org.apache.kafka.common.serialization.StringDeserializer
import java.util.Properties
object KafkaUtil {
//获取kafkaProductor
def getKafkaPara(topicName: String): Map[String, Object] = {
val config: Properties = PropertiesUtil.load("config.properties")
val broker_list: String = config.getProperty("kafka.broker.list")
val kafkaPara = Map(
"bootstrap.servers" -> broker_list,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
//消费者组
"group.id" -> topicName,
//如果没有初始化偏移量或者当前的偏移量不存在任何服务器上,可以使用这个配置属性
//可以使用这个配置,latest 自动重置偏移量为最新的偏移量
"auto.offset.reset" -> "latest",
//如果是 true,则这个消费者的偏移量会在后台自动提交,但是 kafka 宕机容易丢失数据
//如果是 false,会需要手动维护 kafka 偏移量
"enable.auto.commit" -> (true: java.lang.Boolean)
)
kafkaPara
}
def createKafkaProducer(): KafkaProducer[String, Any] = {
val config: Properties = PropertiesUtil.load("config.properties")
val prop = new Properties()
// 添加配置
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, config.getProperty("kafka.broker.list"))
prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
// 根据配置创建 Kafka 生产者
new KafkaProducer[String, Any](prop)
}
}
PropertiesUtil
包含功能
加载资源包文件,读取配置数据
代码实现
package SparkStreamingProject.util
import java.io.InputStreamReader
import java.util.Properties
object PropertiesUtil {
def load(propertiesName: String): Properties = {
val prop = new Properties()
prop.load(
new InputStreamReader(
Thread.currentThread().getContextClassLoader.getResourceAsStream(propertiesName), "UTF-8"
)
)
prop
}
}RandomUtil
包含功能
根据给定的长度返回随机数,可以自定义头尾 返回自定义长度的随机字母的字符串,可以自定义头尾(项目中没用到,作为练习scala的随机数方法) 返回自定义长度的随机字母+数字的字符串,可以自定义头尾,数字权重为9,字母为1
代码实现
package SparkStreamingProject.util
import scala.util.Random
object RandomUtil {
//根据给定的长度返回随机数,可以自定义头尾
//length=8=>八个随机数拼成的字符串
def randomIntList(head: String = "", tail: String = "", length: Int): String = {
val random = new Random()
var result=""+head
for (i<- 1 to length){
result+=random.nextInt(9)+1
}
result += tail
result
}
//返回自定义长度的随机字母的字符串,可以自定义头尾
def randomLetterList(head: String = "", tail: String = "", length: Int): String = {
val letter: List[String] = List("a","b","c","d","e","f","g","h","r","j","k","l","m","k","o","p","q","r","s","t","u","v","w","x","y","z")
val random = new Random()
var result = "" + head
for (i <- 1 to length) {
result+=letter(random.nextInt(25))
}
result += tail
result
}
//返回自定义长度的随机字母+数字的字符串,可以自定义头尾,数字权重为9,字母为1
def randomLetterAndIntList(head: String = "", tail: String = "",length: Int): String = {
val letter: Array[String] = Array("a", "b", "c", "d", "e", "f", "g", "h", "r", "j", "k", "l", "m", "k", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z")
var result = "" + head
val random = new Random()
for (i <- 1 to length) {
if (random.nextInt(9) < 8) {
result += random.nextInt(9)
}else{
result += letter(random.nextInt(25))
}
}
result+=tail
result
}
}
六、Bean模块解析
case class ClickLog(time:String,cityId:String,cityName:String,provName:String,userId:String,advAddres:String)
七、Common模块解析
EnvInit
包含功能
getSparkConf 获取conf:SparkConf,判断是否支持hive,判断是否使用本地spark环境
getSparkContext 获取sc:SparkContext
getSparkSession 获取spark:SparkSession,判断使用本地spark还是集群,判断是否支持hive
getStreamingContext 获取StreamingContext
代码展示
package SparkStreamingProject.controller
import SparkStreamingProject.service.AppService
class AppController {
private val service = new AppService
def producerMainProcess(): Unit = {
//模拟生成页面点击日志,传输到kafka
service.productDataToKafkaMain()
}
def consumerMainProcess(): Unit = {
service.dataDealMain()
}
def cityDataProcessing(): Unit = {
service.cityClickMain()
}
def realTimeProcessing(): Unit = {
service.realTimeClickMain()
}
}
八、Application模块解析
包含功能
productApp 生产数据的应用起点
consumerApp 黑名单需求的应用起点
cityClickDataApp 城市点击量统计的应用起点
realTimeClickApp 实时点击量统计的应用起点
相互依赖关系
代码展示
package SparkStreamingProject.application
import SparkStreamingProject.common.EnvInit
import SparkStreamingProject.controller.AppController
import org.apache.spark.SparkContext
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.StreamingContext
import spark.SparkStreamingProject.util.EnvUtil._
object productApp extends App with EnvInit{
//设置日志打印级别INFO、WARNING、ERROR
//Logger.getLogger("org").setLevel(Level.INFO)
private val controller = new AppController
//构建环境
private val spark: SparkSession = getSparkSession(true, true)
import spark.implicits._
private val sc: SparkContext = spark.sparkContext
private val ssc: StreamingContext = getStreamingContext(sc)
ssc.checkpoint("cp") //需要设定检查点路径
//加入到线程中
//scSet(sc)
println("|--------------环境加入到线程中--------------|")
scSet(sc)
sparkSet(spark)
sscSet(ssc)
println("|------------生产数据应用开始启动-------------|")
controller.producerMainProcess()
println("|-----------------关闭环境------------------|")
//关闭环境
scClean()
sparkClean()
sscClean()
}
package SparkStreamingProject.application
import SparkStreamingProject.application.productApp.{getSparkSession, getStreamingContext}
import SparkStreamingProject.controller.AppController
import org.apache.spark.SparkContext
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.StreamingContext
import spark.SparkStreamingProject.util.EnvUtil._
object consumerApp extends App {
//设置日志打印级别INFO、WARNING、ERROR
//Logger.getLogger("org").setLevel(Level.ERROR)
val controller = new AppController
//构建环境
private val spark: SparkSession = getSparkSession(true, true)
import spark.implicits._
private val sc: SparkContext =spark.sparkContext
private val ssc: StreamingContext = getStreamingContext(sc)
ssc.checkpoint("cp") //需要设定检查点路径
//加入到线程中
println("|--------------环境加入到线程中--------------|")
sparkSet(spark)
sscSet(ssc)
scSet(sc)
println("|------------消费数据应用开始启动-------------|")
//需求一根据consumerMainProcess()实现
controller.consumerMainProcess()
println("|-----------------关闭环境------------------|")
//关闭环境
sscClean()
scClean()
sparkClean()
}
package SparkStreamingProject.application
import SparkStreamingProject.application.productApp.{getSparkSession, getStreamingContext}
import SparkStreamingProject.controller.AppController
import _root_.spark.SparkStreamingProject.util.EnvUtil._
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkContext
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.StreamingContext
object cityClickDataApp extends App {
//设置日志打印级别INFO、WARNING、ERROR
Logger.getLogger("org").setLevel(Level.ERROR)
val controller = new AppController
private val spark: SparkSession = getSparkSession(true, true)
import spark.implicits._
private val sc: SparkContext = spark.sparkContext
private val ssc: StreamingContext = getStreamingContext(sc)
ssc.checkpoint("cp1") //需要设定检查点路径
//加入到线程中
println("|--------------环境加入到线程中--------------|")
sparkSet(spark)
sscSet(ssc)
scSet(sc)
println("|------------地市点击量统计应用开始启动-------------|")
controller.cityDataProcessing()
println("|-----------------关闭环境------------------|")
//关闭环境
sscClean()
scClean()
sparkClean()
}
package SparkStreamingProject.application
import SparkStreamingProject.application.productApp.{getSparkSession, getStreamingContext}
import SparkStreamingProject.controller.AppController
import org.apache.spark.SparkContext
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.StreamingContext
import spark.SparkStreamingProject.util.EnvUtil._
object realTimeClickApp extends App {
//设置日志打印级别INFO、WARNING、ERROR
//Logger.getLogger("org").setLevel(Level.ERROR)
val controller = new AppController
//构建环境
private val spark: SparkSession = getSparkSession(true, true)
import spark.implicits._
private val sc: SparkContext = spark.sparkContext
private val ssc: StreamingContext = getStreamingContext(sc)
ssc.checkpoint("cp2") //需要设定检查点路径
//加入到线程中
println("|--------------环境加入到线程中--------------|")
sparkSet(spark)
sscSet(ssc)
scSet(sc)
println("|------------实时点击数据统计应用开始启动-------------|")
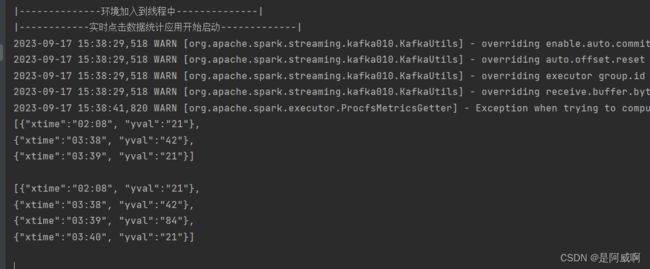
controller.realTimeProcessing()
println("|-----------------关闭环境------------------|")
//关闭环境
sscClean()
scClean()
sparkClean()
}
九、Controller模块解析
包含功能
productDataToKafkaMain 模拟生成页面点击日志,传输到kafka的主流程
consumerMainProcess 实现黑名单加载和点击日志落地的主流程
cityDataProcessing 实现城市点击率统计的主流程
realTimeProcessing 实现实时统计的主流程
代码展示
package SparkStreamingProject.controller
import SparkStreamingProject.service.AppService
class AppController {
private val service = new AppService
def producerMainProcess(): Unit = {
//模拟生成页面点击日志,传输到kafka
service.productDataToKafkaMain()
}
def consumerMainProcess(): Unit = {
service.dataDealMain()
}
def cityDataProcessing(): Unit = {
service.cityClickMain()
}
def realTimeProcessing(): Unit = {
service.realTimeClickMain()
}
}
十、Service模块解析(重点模块)
包含功能
productDataToKafkaMain 生产数据的主函数
dataDealMain 黑名单需求数据处理主函数
cityClickMain 城市点击需求数据处理主函数
realTimeClickMain 实时统计需求数据处理主函数
createData 创建随机的用户点击日志数据
getKafkaData 从kafka获取指定主题数据
filterBlackUser 筛选掉黑名单用户的点击日志
addUserClickInfo 用户点击之日入库mysql
isBlackUserJudge 是否是黑名单用户的判断
代码展示
package SparkStreamingProject.service
import SparkStreamingProject.dao.AppDao
import SparkStreamingProject.util.RandomUtil.{randomIntList, randomLetterAndIntList}
import SparkStreamingProject.util.jdbcUtil.mysqlConnect
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.Minutes
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import spark.SparkStreamingProject.bean.ClickLog
import spark.SparkStreamingProject.util.EnvUtil.sscGet
import java.sql.Connection
import java.text.SimpleDateFormat
import java.util.Date
import scala.collection.mutable.{ArrayBuffer, ListBuffer}
import scala.util.Random
class AppService extends Serializable{
private val dao = new AppDao()
//kafka生产者传递数据数据
def productDataToKafkaMain(): Unit = {
while(true){
createData.foreach(
(data: String) =>{
// 向Kafka中生成数据
dao.setDataToKafka("mySparkTopic",data)
println(data)
}
)
Thread.sleep(15000)
}
}
//消费者接收kafka数据
def dataDealMain(): Unit = {
val debugFlag=false
val clickLogData: DStream[ClickLog] = getKafkaData
//过滤黑名单用户,返回过滤后的日志
val filterBlack: DStream[ClickLog] = filterBlackUser(clickLogData).cache()
//过滤后数据传给实时统计模块
filterBlack.foreachRDD(
rdd=>{
rdd.foreachPartition(
(iter: Iterator[ClickLog]) => {
iter.foreach(
(data: ClickLog) =>{
//dao.setDataToKafka("clickTopic",Array(data.time,data.userId,data.cityId,data.cityName,data.provName,data.advAddres).mkString(","))
dao.setDataToKafka("realTimeTopic",Array(data.time,data.userId,data.cityId,data.cityName,data.provName,data.advAddres).mkString(","))
}
)
})
}
)
//计算每日点击量,写入mysql,每天点击量超限,拉入黑名单
addUserClickInfo(filterBlack)
sscGet().start()
sscGet().awaitTermination()
}
def cityClickMain(): Unit = {
val sql=
"""
|insert into area_city_ad_count values(?,?,?,?,?,?)
|ON DUPLICATE KEY
|UPDATE count=count + ?;
|""".stripMargin
//获取黑名单过滤后的日志信息
val filterClickData: InputDStream[ConsumerRecord[String, String]] = dao.getKafkaData("clickTopic")
//按照天的维度统计点击量
val reduceData: DStream[Array[Any]] = filterClickData.transform(
rdd => {
rdd.map((data: ConsumerRecord[String, String]) => {
data.value().split(",")
}).map((data: Array[String]) => {
/*格式转换
Array(data.time,data.userId,data.cityId,data.cityName,data.provName,data.advAddres)
=>((data.time,data.cityId,data.cityName,data.provName,data.advAddres),count)
* */
((data(0).substring(0, 8), data(2), data(3), data(4), data(5)), 1)
}).reduceByKey(_ + _).map(data =>{
Array(data._1._1,data._1._2,data._1._3,data._1._4,data._1._5,data._2,data._2)
})
}
)
//数据入库
reduceData.foreachRDD(rdd => {
rdd.foreachPartition(rddPartition => {
//建立mysql链接
val mysqlConn: Connection = mysqlConnect()
rddPartition.foreach(
(data: Array[Any]) => {
dao.executeOneData(mysqlConn, sql, data, true)
}
)
mysqlConn.close()
})
})
sscGet().start()
sscGet().awaitTermination()
}
def realTimeClickMain(): Unit = {
//获取实时点击数据
val clickData: InputDStream[ConsumerRecord[String, String]] = dao.getKafkaData("realTimeTopic")
//数据规整
val clickTimeDS: DStream[String] = clickData.map(_.value().split(",")(0))
val realTimeData: DStream[(String, Int)] =
clickTimeDS.map(data => (data.substring(8, 12), 1))
val resultData: DStream[(String, Int)] = realTimeData.reduceByKeyAndWindow(_ + _, _ - _, Minutes(5), Minutes(1))
resultData.foreachRDD(rdd=>{
val list = ListBuffer[String]()
val value: Array[(String, Int)] = rdd.sortByKey(true).collect()
value.foreach(
(data: (String, Int)) => {
list.append(s"""{"xtime":"${data._1.substring(0, 2)+":"+data._1.substring(2, 4)}", "yval":"${data._2}"}""")
})
println("["+list.mkString(",\n")+"]\n")
})
sscGet().start()
sscGet().awaitTermination()
}
//生产随机数据
private def createData(): Array[String] = {
val dataArray: ArrayBuffer[String] = ArrayBuffer.empty
val random: Int = new Random().nextInt(15)
val cityInfoList: List[(String, String, String)] = List(
("0551", "合肥", "安徽"),
("0552", "蚌埠", "安徽"),
("0553", "芜湖", "安徽"),
("0554", "淮南", "安徽"),
("0555", "马鞍山", "安徽"),
("0556", "安庆", "安徽"),
("0557", "宿州", "安徽"),
("0558S", "阜阳", "安徽"),
("0558K", "亳州", "安徽"),
("0559", "黄山", "安徽"),
("0550", "滁州", "安徽"),
("0561", "淮北", "安徽"),
("0562", "铜陵", "安徽"),
("0563", "宣城", "安徽"),
("0564", "六安", "安徽"),
("0566", "池州", "安徽")
)
val format: SimpleDateFormat = new SimpleDateFormat("yyyyMMddhhmmss")
for (i <- 0 to 20) {
dataArray +=
format.format(new Date(System.currentTimeMillis())) + "," +
cityInfoList(random)._1 + "," +
cityInfoList(random)._2 + "," +
cityInfoList(random)._3 + "," +
//randomIntList(head="3405",tail="X",length = 8) + "," +
//randomLetterAndIntList(head="http://",tail=".com",length = 4)
randomIntList(head = "3405", tail = "X", length = 8) + "," +
randomLetterAndIntList(head = "http://", tail = ".com", length = 4)
}
dataArray.toArray
}
private def getKafkaData: DStream[ClickLog] = {
val mySparkTopicDStream: InputDStream[ConsumerRecord[String, String]] =
dao.getKafkaData("mySparkTopic")
//mySparkTopicDStream.map(_.value()).print()//debug
val clickLogData: DStream[ClickLog] = {
mySparkTopicDStream.map(data => {
ClickLog(
data.value().split(",")(0),
data.value().split(",")(1),
data.value().split(",")(2),
data.value().split(",")(3),
data.value().split(",")(4),
data.value().split(",")(5)
)
}).cache()
}
clickLogData
}
//日志中过滤掉黑名单数据
private def filterBlackUser(clickLogData: DStream[ClickLog]): DStream[ClickLog] = {
val debugFlag=false
//1、取出黑名单用户
//2、过滤掉黑名单用户
val sql="select userid,state from user_black_list where 1 =?"
val array: Array[Any] = Array("1")
var filterBlack: DStream[ClickLog] = null
//只有一个参数1,limit=-1表示不限制 查询条数
//只取第一个数据UserId
val mysqlConn: Connection = mysqlConnect
val blackUserId: Array[Array[Any]] = dao.getData(mysqlConn,sql, array, -1,debugFlag)
var blackUserIdHead: Array[Any] = Array.empty
if (blackUserId.isEmpty){
filterBlack=clickLogData
}else{
blackUserIdHead = blackUserId.map(_.head)
filterBlack = clickLogData.transform(rdd => {
rdd.filter(
(data: ClickLog) => {
val bool: Boolean = blackUserIdHead.contains(data.userId)
if (bool) println(s"${data.userId}是黑名单用户,过滤此条数据,不写入日志表...${data.toString}...${data.userId},${data.advAddres},${data.time},${data.cityId},${data.cityName},${data.provName}")
!bool
}
)
}
)
}
mysqlConn.close()
filterBlack
}
//过滤后数据加载到日志表
private def addUserClickInfo(filterBlack: DStream[ClickLog]): Unit = {
val debugFlag=true
val sql = "insert into user_ad_count values(?,?,?,?)"
//超限条数
val clickLimit=5
//过滤后的数据进行分组求和获取点击量
val dateUserAdToCount: DStream[Array[Any]] = filterBlack.transform(
(rdd: RDD[ClickLog]) => {
rdd.map(
data => ((data.time.substring(0, 8), data.userId, data.advAddres), 1)
).reduceByKey(_ + _).map((data: ((String, String, String), Int)) => {
Array(data._1._1, data._1._2, data._1._3, data._2)
})
}
)
//数据入库
dateUserAdToCount.foreachRDD((rdd: RDD[Array[Any]]) => {
rdd.foreachPartition(
(iter: Iterator[Array[Any]]) => {
//建立mysql链接
val mysqlConn: Connection = mysqlConnect()
//数据写入日志表
val cnt: Int = dao.executeBatch(mysqlConn, sql, iter, debugFlag = debugFlag)
println(s"日志表加载数据 $cnt 条")
mysqlConn.close()
})
rdd.foreachPartition((iter: Iterator[Array[Any]]) => {
//此用户是否为黑名单,是的话加入黑名单表
isBlackUserJudge(clickLimit, iter)
})
})
}
//超限用户入黑名单表
private def isBlackUserJudge(clickLimit:Int, iter: Iterator[Array[Any]]): Unit = {
val debugFlag=false
val mysqlConn: Connection = mysqlConnect
iter.foreach((data: Array[Any]) =>{
if(debugFlag) println(s"开始判断是否是黑名单用户 ${data.mkString("-")}")
val params: Array[Any] = Array(data(1),data(1),data(1),data(2),clickLimit)
val sql=
s"""select ? from user_ad_count where userid=?
|group by ?,?
|having sum(count)> ?
|""".stripMargin
val sql1= "insert into user_black_list() values(?,1)"
val sql2="select 1 from user_black_list where userid=?"
val blackFlag: Boolean = dao.dataIsExist(mysqlConn, sql, params,debugFlag)
if(blackFlag){
if(!dao.dataIsExist(mysqlConn,sql2,Array(data(1)),debugFlag)){
dao.executeOneData(mysqlConn,sql1,Array(data(1)),debugFlag)
println(s"用户${params(1)}是黑名单用户,点击广告${data(2)}超过${clickLimit}次,拉入黑名单")
}
} else {
if (debugFlag) println(s"用户${params(1)}不是黑名单用户")
}
})
mysqlConn.close()
}
}
十一、Dao模块解析
包含功能
getKafkaData 获取指定主题的kafka数据流,返回字符数据流
setDataToKafka 生产数据到kafka
executeOneData 执行 SQL 语句,单条数据插入和更新,返回布尔值成功与否
executeBatch 执行 SQL 语句,批量数据插入,第三个参数为debug开关
dataCnt sql查询结果的条数
dataIsExist 查询一条数据是否存在
getData 获取 MySQL 数据,传入limit参数,返回limit条数据,数据形式为二维数组,如果limit=-1则返回所有的数据
rddFile 读取路径下文件,返回RDD
rddHadoopFile 读取hadoop路径下件并在结尾增加文件名,返回RDD
rddReadWhole 读取整个路径下的文件,返回成一个RDD(文件名,文件内容)
dataFrameFile 读取路径下文件返回DF,目前支持json和csv个性化读取,其他的同统一load
sparkToMysqlRead 连mysql库读整表数据,返回DataFrame--sparkSql方式
sparkSocket 获取指定主机ip和端口的socket通信数据,返回数据流
sparkToHiveSQL 查询hiveSql返回结果DataFrame--sparkSql方式
代码展示
package SparkStreamingProject.dao
import SparkStreamingProject.util.KafkaUtil.{createKafkaProducer, getKafkaPara}
import org.apache.hadoop.io.{LongWritable, Text}
import org.apache.hadoop.mapreduce.InputSplit
import org.apache.hadoop.mapreduce.lib.input.{FileSplit, TextInputFormat}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import org.apache.spark.SparkContext
import org.apache.spark.rdd.{NewHadoopRDD, RDD}
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.dstream.{InputDStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import spark.SparkStreamingProject.util.EnvUtil.{scGet, sparkGet, sscGet}
import java.sql.{Connection, PreparedStatement, ResultSet}
import java.util.Properties
/*
* 1、读取hadoop路径下件并在结尾增加文件名,返回RDD
* 2、读取文件系统路径下文件,返回RDD
* 3、读取路径下文件返回DF,目前支持json和csv个性化读取,其他的同统一load
* 4、读取整个路径下的文件,返回成一个RDD(文件名,文件内容)
* 5、连mysql库读整表数据,返回DataFrame
* 6、查询hiveSql返回结果DataFrame
* 7、获取指定主题的kafka数据流,返回字符数据流
* 8、获取指定主机ip和端口的socket通信数据,返回数据流
* */
class AppDao extends Serializable{
private val sc: SparkContext = scGet()
private val spark: SparkSession = sparkGet()
private val ssc: StreamingContext = sscGet()
//生产数据到kafka
def setDataToKafka(topicName:String,data:Any): Unit = {
val record: ProducerRecord[String, Any] = new ProducerRecord[String, Any](topicName, data)
val producer: KafkaProducer[String, Any] = createKafkaProducer()
producer.send(record)
}
//获取指定主题的kafka数据流,返回字符数据流
def getKafkaData(topicName:String): InputDStream[ConsumerRecord[String, String]] = {
//定义 Kafka 参数
val kafkaPara: Map[String, Object] = getKafkaPara(topicName)
val inputDStream: InputDStream[ConsumerRecord[String, String]] =
KafkaUtils.createDirectStream[String, String](
sscGet(),
//ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set(topicName), kafkaPara)
)
inputDStream
}
//执行 SQL 语句,单条数据插入和更新,返回布尔值成功与否
/*
* 举例 insert into mytable(?,?)
* 数据:array(1,2)
* 插入一条
* */
def executeOneData(mysqlConn:Connection,sql:String,data:Array[Any],debugFlag:Boolean=false): Int = {
var resultCnt=0
try {
//设置不自动 Commit参数
mysqlConn.setAutoCommit(false)
//预编译SQL语句,设置参数
val statement: PreparedStatement = mysqlConn.prepareStatement(sql)
//设置第一个参数
if (data != null && !data.isEmpty) {
for (i <- data.indices) {
statement.setObject(i + 1, data(i))
}
}
//批量执行,返回每个执行的条数
val counts: Array[Int] = statement.executeBatch()
if (debugFlag) {
println("单条提交sql:" + statement.toString)
}
statement.close()
resultCnt=counts.sum
}catch {
case e: Exception => e.printStackTrace()
}
resultCnt
}
//执行 SQL 语句,批量数据插入,第三个参数为debug开关,打开后会打印
/*举例 insert into mytable(?,?)
数据:Array(Array(1,0),Array(2,1))
插入两条
* 举例 update table
* set col1=?
* where col2=?
* 数据:Array(Array(1,0),Array(2,1));
* 更新col1=1的数据的col2=0
* 更新col1=2的数据的col2=1
* */
def executeBatch(mysqlConn:Connection,sql: String, dataList:Iterator[Array[Any]] ,debugFlag:Boolean=false): Int = {
var resultCnt=0
try{
//设置不自动 Commit参数
mysqlConn.setAutoCommit(false)
//预编译SQL语句,设置参数
val statement: PreparedStatement = mysqlConn.prepareStatement(sql)
//设置第一个参数
for(data<-dataList) {
if (data != null && !data.isEmpty) {
for (i <- data.indices) {
statement.setObject(i+1, data(i))
}
statement.addBatch()
}
}
if (debugFlag) {
println("批量提交sql:"+statement.toString)
}
//批量执行,返回每个执行的条数
val counts: Array[Int] = statement.executeBatch()
//提交刚才的更新
mysqlConn.commit
if (dataList.nonEmpty) {
resultCnt=counts.sum/dataList.length
}else {
resultCnt=counts.sum
}
statement.close()
} catch
{
case e: Exception => e.printStackTrace()
}
resultCnt
}
//判断一条数据是否存在
def dataIsExist(mysqlConn:Connection,sql: String, data:Array[Any],debugFlag:Boolean=false): Boolean = {
var result = false
try {
//设置不自动 Commit参数
mysqlConn.setAutoCommit(false)
//预编译SQL语句,设置参数
val statement: PreparedStatement = mysqlConn.prepareStatement(sql)
if (debugFlag) {
println("判断数据是否存在sql:" + statement.toString)
}
if (data != null && !data.isEmpty) {
for (i <- data.indices) {
statement.setObject(i + 1, data(i))
}
result = statement.executeQuery().next()
}
statement.close()
} catch {
case e: Exception => e.printStackTrace()
}
result
}
//查询数据操作返回条数
def dataCnt(mysqlConn:Connection,sql: String, data: Array[Any]): Long = {
//获取查询的count(*)结果到 resultCnt 并返回
var resultCnt:Long=0
try {
//设置不自动 Commit参数
mysqlConn.setAutoCommit(false)
//预编译SQL语句,设置参数
val statement: PreparedStatement = mysqlConn.prepareStatement(sql)
if (data != null && !data.isEmpty) {
for (i <- data.indices) {
statement.setObject(i + 1, data(i))
}
}
val result: ResultSet = statement.executeQuery()
while (result.next()) {
resultCnt = result.getLong(1)
}
} catch {
case e: Exception => e.printStackTrace()
}
resultCnt
}
//获取 MySQL 数据,传入limit参数,返回limit条数据,数据形式为二维数组,如果limit=-1则返回所有的数据
def getData(mysqlConn:Connection,sql: String, data: Array[Any],limit:Int=1,debugFlag:Boolean=false): Array[Array[Any]] = {
var resultList: List[Array[Any]] = List()
try {
//设置不自动 Commit参数
mysqlConn.setAutoCommit(false)
//预编译SQL语句,设置参数
val statement: PreparedStatement = mysqlConn.prepareStatement(sql)
if (data != null && !data.isEmpty) {
for (i <- data.indices) {
statement.setObject(i + 1, data(i))
}
}
val result: ResultSet = statement.executeQuery()
if (debugFlag) {
println("获取查询数据sql:" + statement.toString)
}
if (limit == -1){
while (result.next()) {
var list: Array[Any] =Array.empty
for (i <- 1 to result.getMetaData().getColumnCount) {
list :+= result.getObject(result.getMetaData().getColumnName(i)).toString
}
resultList=resultList :+ list
}
}else {
while (result.next()) {
for (j <- 1 to limit) {
var list: Array[Any] =Array.empty
for (i <- 1 to result.getMetaData().getColumnCount) {
list :+= result.getObject(result.getMetaData().getColumnName(i)).toString
}
resultList=resultList :+ list
}
}
}
if (debugFlag) {
if(resultList.isEmpty) println("未获取到数据...")
val result = resultList.map { arr =>
println("获取的数据长度="+arr.length)
if (arr.length == 1) arr.mkString
else if(arr.length == 0) "未查询到值"
else arr.mkString(s"查询的数据:[", ", ", "]")
}.mkString("\n")
println(result)
}
result.close()
statement.close()
} catch {
case e: Exception => e.printStackTrace()
}
resultList.toArray
}
//获取指定主机ip和端口的socket通信数据,返回数据流
def sparkSocket(hostName:String,hostIp:Int): ReceiverInputDStream[String] = {
ssc.socketTextStream(hostName, hostIp)
}
//连mysql库读整表数据,返回DataFrame--sparkSql方式
def sparkToMysqlRead(hostIp: String, tableName: String, props: Properties): DataFrame = {
spark.read.jdbc(s"jdbc:mysql://$hostIp:3306/mysql", tableName, props)
}
//查询hiveSql返回结果DataFrame--sparkSql方式
def sparkToHiveSQL(hiveSQL: String): DataFrame = {
spark.sql(hiveSQL)
}
//读取hadoop路径下件并在结尾增加文件名,返回RDD
def rddHadoopFile(path: String): RDD[String] = {
val value: RDD[String] = sc.newAPIHadoopFile[LongWritable, Text, TextInputFormat](path)
.asInstanceOf[NewHadoopRDD[LongWritable, Text]]
.mapPartitionsWithInputSplit(
(inputSplit: InputSplit, iterator: Iterator[(LongWritable, Text)]) => {
val file: FileSplit = inputSplit.asInstanceOf[FileSplit]
val fileName = file.getPath.getName
iterator.map(line => {
line._2.toString + fileName
})
})
value
}
//读取路径下文件,返回RDD
def rddFile(path: String): RDD[String] = {
sc.textFile(path)
}
//读取路径下文件返回DF,目前支持json和csv个性化读取,其他的同统一load
def dataFrameFile(fileType: String, delimiter: String = ",", header: Boolean = true, path: String): DataFrame = {
fileType.toLowerCase match {
case "json" => spark.read.json(path)
case "csv" => spark.read.option("inferSchema", "true") //推断数据类型
.option("delimiter", delimiter) //可设置分隔符,默认,不设置参数为","本程序默认值也给的","
.option("nullValue", null) // 设置空值
.option("header", header) // 表示有表头,若没有则为false
.csv(path) // 文件路径
case _ => spark.read.load(path)
}
}
//读取整个路径下的文件,返回成一个RDD(文件名,文件内容)
def rddReadWhole(path: String): RDD[(String, String)] = {
sc.wholeTextFiles(path)
}
}
十二、演示
前置依赖
zookeeper、kafka集群启动
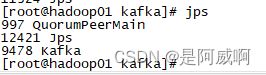
相关topic建立

mysql建表
黑名单表
CREATE TABLE `user_black_list` (
`userid` varchar(16) NOT NULL,
`state` varchar(1)
);
用户单日广告点击次数表
CREATE TABLE user_ad_count (
click_time varchar(255),
userid CHAR (1),
adid varchar(16),
count BIGINT,
);
CREATE TABLE area_city_ad_count (
time VARCHAR(30),
area VARCHAR(30),
city VARCHAR(30),
prov VARCHAR(30),
adid VARCHAR(50),
count BIGINT,
PRIMARY KEY (time,area,prov,city,adid)
);
ALTER DATABASE mysql CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
ALTER TABLE area_city_ad_count CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;功能演示
生产数据:
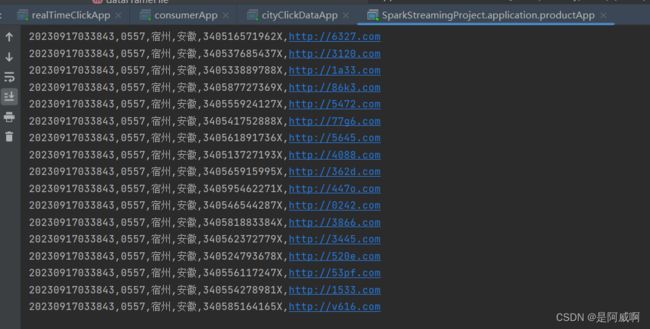
黑名单数据处理

黑名单表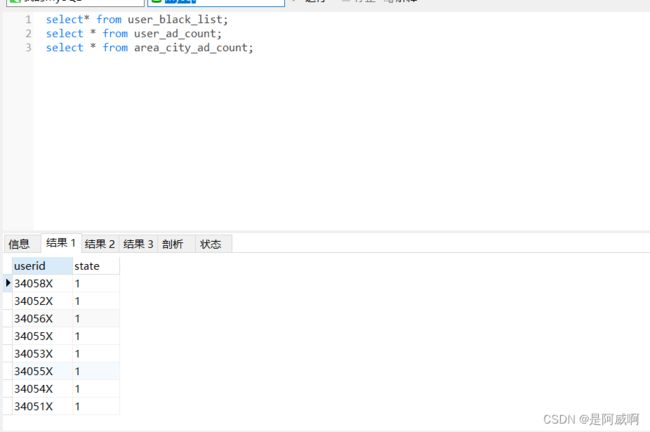
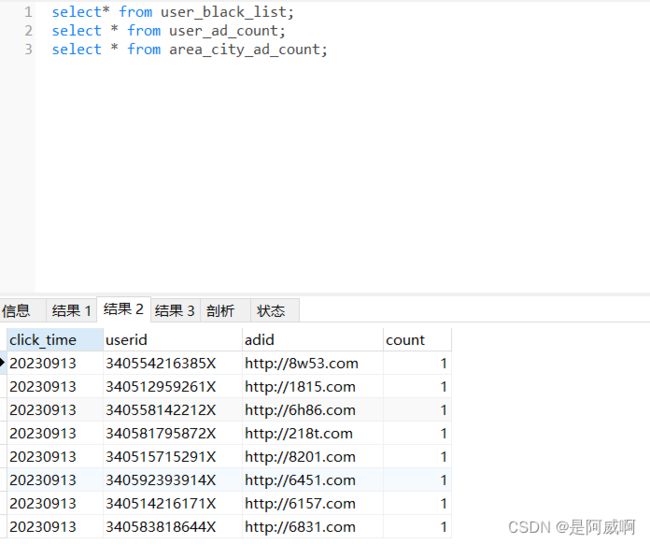
用户点击表
城市点击统计
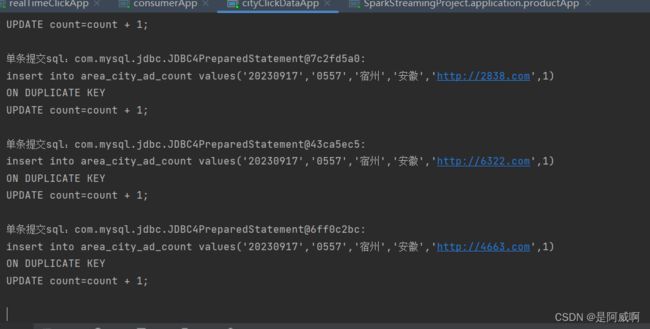
城市点击统计表
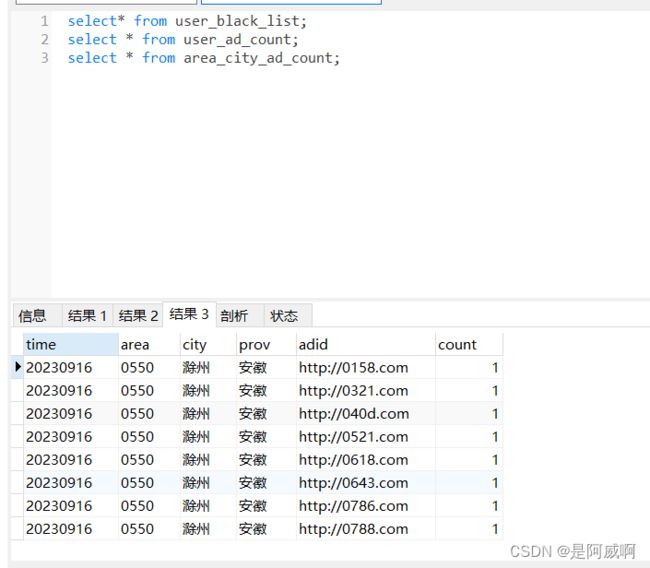
实时统计