一次java系统调优 从150到最高1800的过程
前言
在做公司系统压力测试(500个线程并发)的时候 某个服务的接口 压测初始结果如下
初始指标(最高):
吞吐量 150/s
TPS: 240
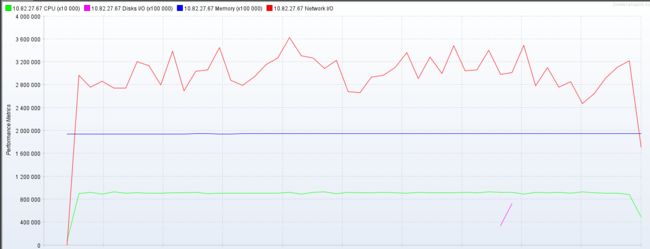
CPU,内存,带宽,磁盘io 如下图所示
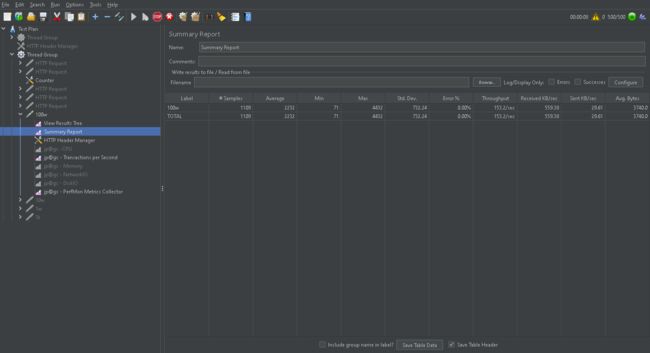

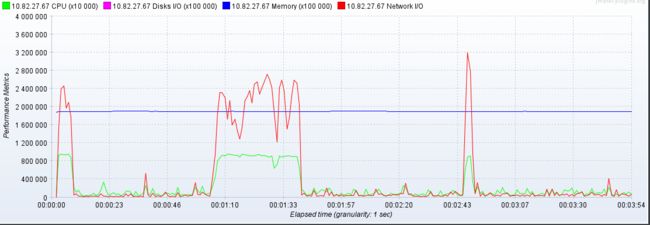
可以看到资源使用是有问题的 cpu和带宽并没有给足压力 说明并不是资源所导致的瓶颈,所以现在分析代码
怎么分析代码在哪里耗时比较久呢?
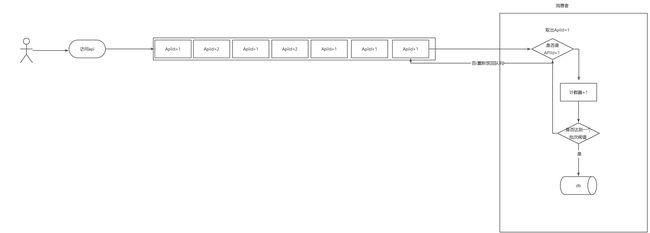
主链路梳理
-
前置拦截器
耗时节点 次数 查询缓存 4 查询数据库 3 刷新缓存 2 写数据库 1 -
处理请求
耗时节点 次数 查询数据库 1 查询缓存 1
具体测试耗时分析
前置拦截器分析
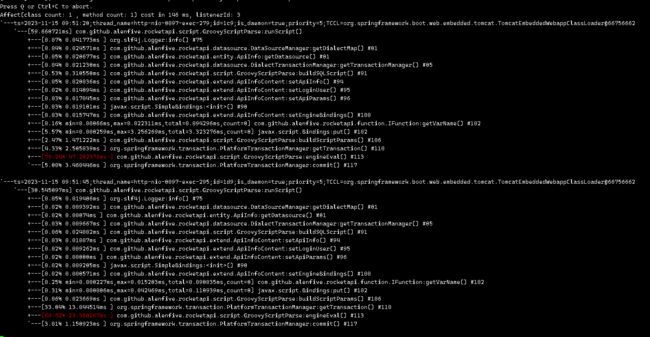
通过arthas 分析 前置拦截器的每个耗时点的时间
利用trance 监听执行

监控结果如下 可以看出来是数据库写入是最耗时的

业务分析
这个写入数据库 我看到是非常简单的逻辑 就是记录api调用的次数
优化方案
一般写入数据库可以采用合并更新的方式减少写入的次数和访问db的次数
比如 一次访问记一次 优化成 访问一次将这次访问的记录放入到队列当中,然后消费者消费 和并次数 最终使用一次update来完成,当然了放到队列当中是有可能导致数据丢失,需要考虑业务是否允许容忍这部分的丢失,一切的技术都是服务于业务
处理请求节点分析
trace 截图如下 可以看到那次查询数据库是最为耗时的

继续查看那个耗时 方法
再继续分析

业务分析
这个是查询用户的数据
优化方案
是否可以添加缓存?
- 这部分数据不会经常变动,但是查询的却是比较频繁
- 和业务确认 这部分允许短时间内的数据不一致的情况 所以我们可以添加本地缓存。经过确认15分钟之内
优化
tomcat 参数优化(在下面的代码提升之后的参数调优)
提升这个参数并没有多大的提升 反而比默认的参数性能要差)是不是可以这么认为这个tomcat的参数并不是其性能点
tomcat:
uri-encoding: UTF-8
threads:
#最大工作线程数,默认200, 4核8g内存,线程数经验值800
#操作系统做线程之间的切换调度是有系统开销的,所以不是越多越好。
max: 400
# 最小工作空闲线程数,默认10, 适当增大一些,以便应对突然增长的访问量
min-spare: 50
# 等待队列长度,默认100
accept-count: 300
max-connections: 10000
默认参数与优化后的参数对比图
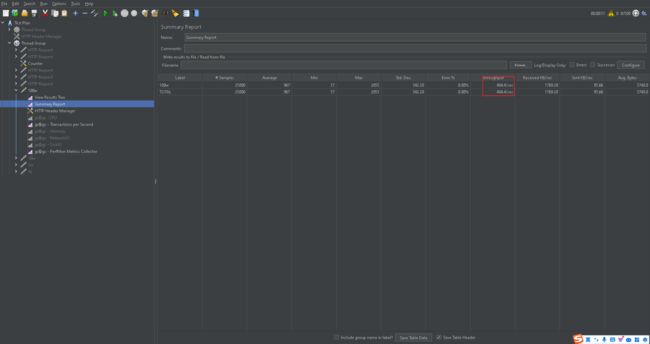
默认参数跑压测结果
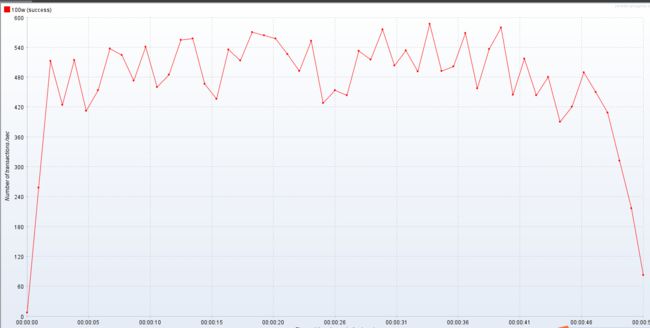
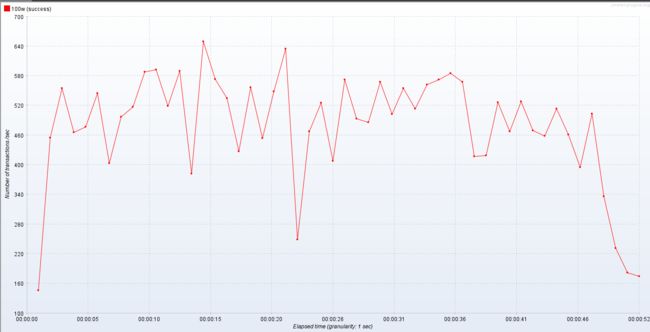
优化后的参数跑压测结果对别


对比
| 类型 | 接口平均响应值(毫秒) | 吞吐量/s | TPS(平均) | CPU 使用率 | 带宽使用率 | 占用内存 |
|---|---|---|---|---|---|---|
| 默认参数 | 967 | 484 | 490 | 90% | 3,000,000 | 2G |
| 优化后参数 | 951 | 483 | 520 | 90% | 3,000,000 | 2G |
结论
综合来看也就tps涨那么一丢丢 所以当前至少这个tomcat参数不是整个系统的瓶颈(不是关键瓶颈)。
再度优化
那到底什么是整个系统的瓶颈呢?
是不是还有可以做异步或者加缓存的代码节点没有发现? 我可以查看tomcat线程是不是有阻塞的,然后研究是不是可以做成异步,带着这个思路去看。
如何查看tomcat 线程是不是有阻塞?可以jstack 或者 arthas 查看
这里我选择arthas查看
查看当前最繁忙的10个线程
thread -n 10
随机截取两个片段
1.txt2.txt
可以看到有一个rpc调用是一个阻塞点
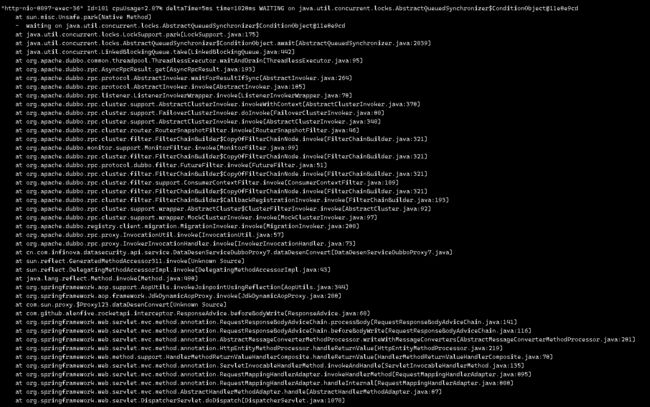
一个日志打印也是阻塞点(这个阻塞点还不少 所以优化日志打印或者关闭日志打印)
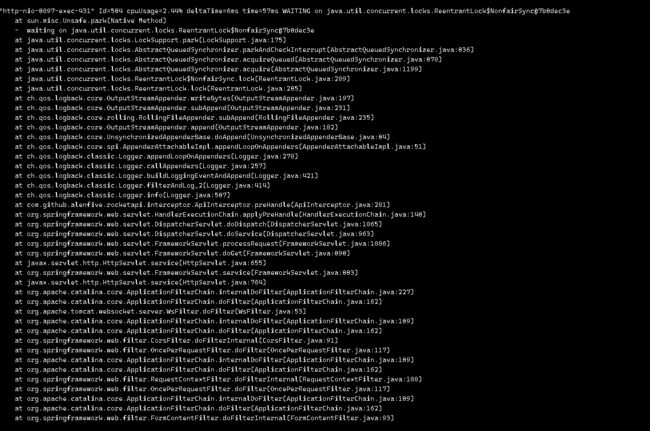
日志打印优化
优化代码
if (logger.isTraceEnabled()) {
logger.trace("Using MessageSource [" + this.messageSource + "]");
}
logger.trace("Using MessageSource [" + this.messageSource + "]");
配置优化
直接error级别的日志打印
结果如下
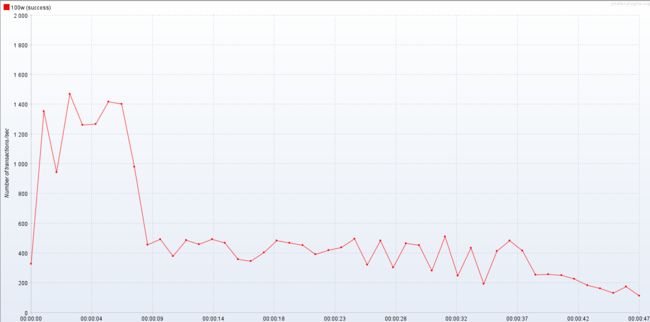
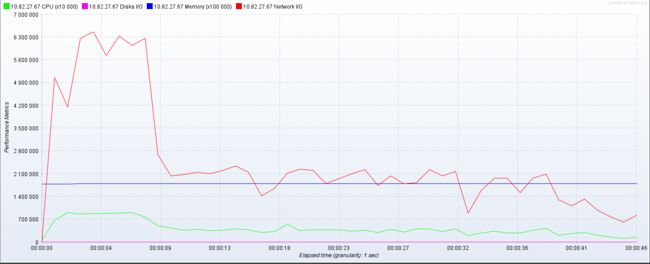
![]() 居然提升这么多 吓人,简直起飞
居然提升这么多 吓人,简直起飞
虽然部分时间段非常非常高,但是最终趋于稳定 大概提升 15%左右 由此可见日志也不能乱打印 需要打印有效日志 或者选一个好一点的非阻塞式日志框架 这个logback性能还是有点问题
rpc调用添加缓存
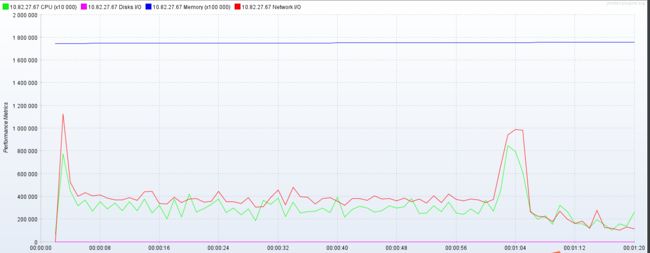
这个时候我们给那个rpc调用阻塞点 添加一个缓存 查看效果
挖槽最高吞吐量居然达到了 1800/s, 此时此刻我只想吟诗一首
代码神手,优化奇才,
调和阴阳,掌舵未来。
从百倍速,至于千倍速,
跃然纸上,效能飙升。


核心流程代码优化
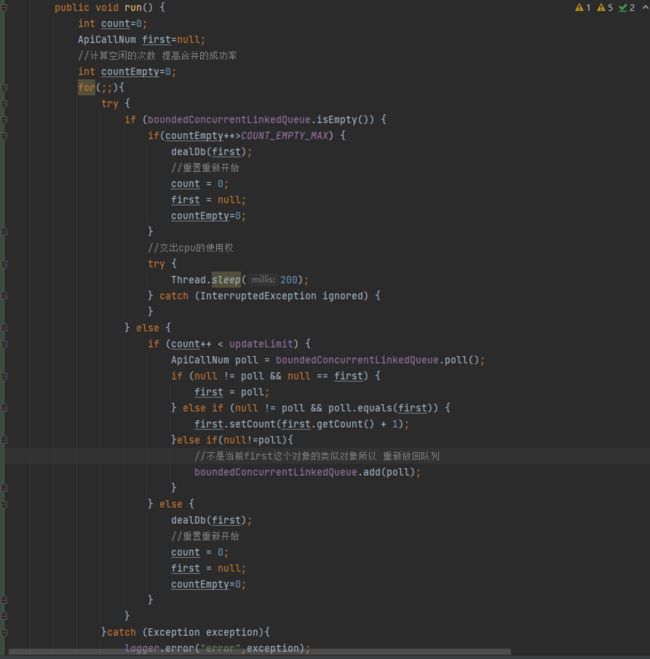
合并api请求次数入库的核心代码如下 通过添加一个countEmpty来提高合并的成功率 不然还是update操作时太少了几乎还是1
优化前后对比
| 类型 | 接口平均响应值(毫秒) | 最高吞吐量/s | 吞吐量/s | TPS(平均) | CPU 使用率 | 带宽使用率 | 占用内存 |
|---|---|---|---|---|---|---|---|
| 优化前 | 2232 | 200 | 153 | 180 | 60% | 1500,000 | 2G |
| 优化后 | 643 | 1811 | 623 | 800 | 40% | 500,000 | 2G |
一些小的提升没想到居然如此之大。所以还是好好写代码,写好代码吧。
难道就优化到这里了吗?
是不是还忘记了啥?JVM还没有优化,内存还没有优化,数据还没有优化
再次用arthas 查看程序的阻塞点还有哪些?
可以看到 tomcat的线程有一些在等待队列当中的任务。

并没有查看到一些阻塞点,怎么办 还能提升吗?
- 查看程序有没有进行垃圾回收(这个是java程序源优化时必须要关注的点)
- 提升一下内存看是否有效
- 再次修改tomcat参数 但是这一点我认为已经没有必要了 因为有一部分tomcat的线程还是空闲状态,并没有在跑,所以他还不是满压状态。所以排除这一点。
有没有进行垃圾回收?

可以看到使用的是 Parallel Scavenge 垃圾回收器
- gc.ps_scavenge.count:垃圾回收次数
- gc.ps_scavenge.time(ms):垃圾回收消耗时间
- gc.ps_marksweep.count:标记-清除算法的次数
- gc.ps_marksweep.time(ms):标记-清除算法的消耗时间
Parallel Scavenge收集器的特点是它的关注点与其他收集器不同,CMS等收集器的关注点是尽可能 地缩短垃圾收集时用户线程的停顿时间,而Parallel Scavenge收集器的目标则是达到一个可控制的吞吐量.(Throughput)。所谓吞吐量就是处理器用于运行用户代码的时间与处理器总消耗时间的比值。 如果虚拟机完成某个任务,用户代码加上垃圾收集总共耗费了100分钟,其中垃圾收集花掉1分 钟,那吞吐量就是99%。停顿时间越短就越适合需要与用户交互或需要保证服务响应质量的程序,良 好的响应速度能提升用户体验;而高吞吐量则可以最高效率地利用处理器资源,尽快完成程序的运算 任务,主要适合在后台运算而不需要太多交互的分析任务。 Parallel Scavenge收集器提供了两个参数用于精确控制吞吐量,分别是控制最大垃圾收集停顿时间 的-XX:MaxGCPauseMillis参数以及直接设置吞吐量大小的-XX:GCTimeRatio参数 。
是否可以减少垃圾回收次数?
由于他是回收老年代又是与用户线程并发执行的垃圾回收器 几乎不会停顿用户线程,所以这个垃圾回收影响程序不大。并且此时并没有触发FULL GC,所以貌似没有优化点 可以尝试一下 使用新的垃圾收集器G1看是否有提升(我认为提升应该不大 G1对大内存的垃圾回收有优势)。
果然几乎没有提升
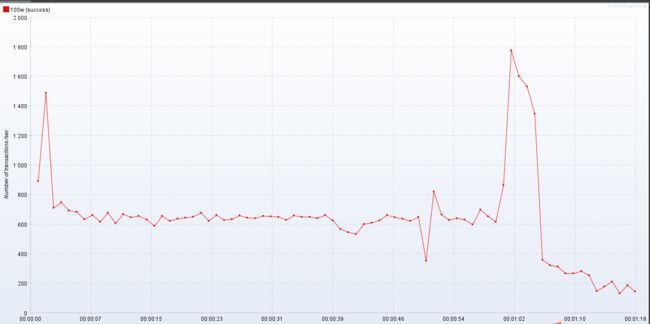

提升内存试试
同样的并没有较大的提升,图就不贴了,所以我认为现在的问题就是我发的不够快 我的测试并发量不够
提升并发量试试(1000个线程)

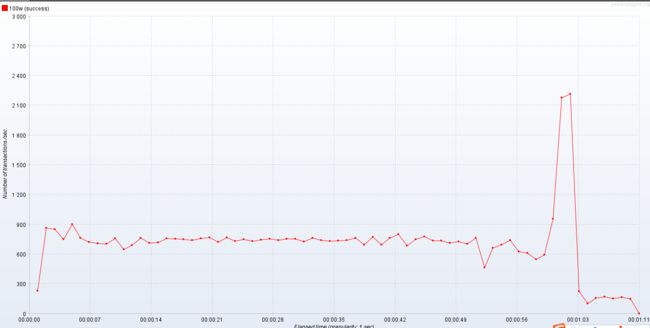

貌似并不是我们想的那样啊,并不是我发的不够快
再次通过arthas 看看1000的并发下 tomcat线程在干啥 有没有阻塞的
通过下面来看 还是和500并发的一样 有部分线程还是waiting
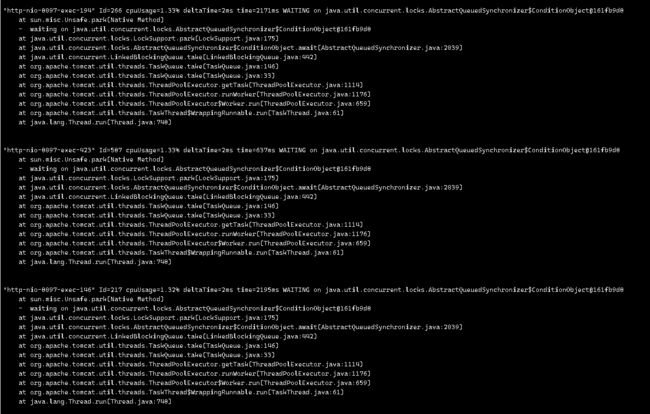
这个是为啥呢?我想这个资源貌似没有用到极致例如cpu和带宽,还有内存
我认为是我还是发的不够快 ,所以我决定搭建一个Jmeter集群来进行压测。
3台 jmeter worker节点

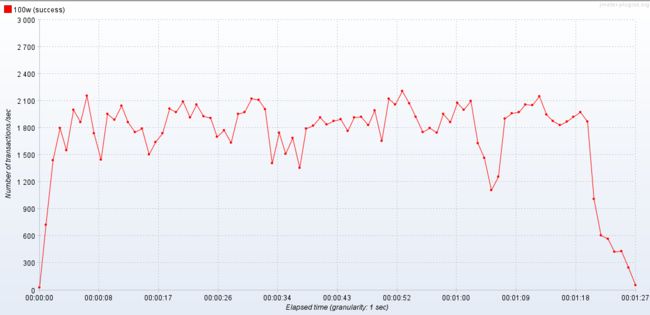
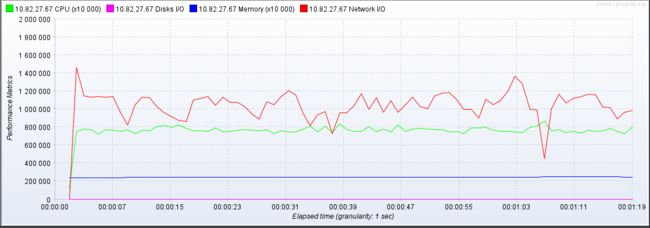
可以看到cpu已经几乎到顶了,貌似没有啥优化点了。
done