白话ES搜索相关性问题
之前使用es,更多的是使用term查询,和agg聚合分析。对相关性关注较少。实际上es擅长的是做模糊搜索,相关性搜索。
ES是一个开源的通用的检索工具,能满足百分之八十的需求。相关性这个问题,是一个非常有意思的问题,值得深思。搞清楚相关性打分规则,有利于提高召回内容的相关性。深入了解以后,能帮我们解决剩下的百分之二十的需求。
1、为什么会研究搜索相关性问题
两个需求。其中第二个需求实现,费了不少功夫。怎么调都不对,所以对相关性有了研究。
- 命中某个字段优先返回。 原生的相关性算法,可以通过对某个字段加权来满足此需求。
- 连续命中的部分越多,优先返回。此需求在当个字段中检索,效果还好,在多个字段中检索,效果不是很好。另外,经研究相关性得分计算过程,得知连续命中这个点,在相关性得分计算中并不考虑。具体可以看下文的BM25算法的计算过程。
- 但是需求1和需求2同时满足,并不太容易。在长文本字段中,词频的影响,例如关键词在title和content都出现了。但是在title出现了一次,在content出现了N次,召回结果会因为在content中出现的次数多,而排序在前边。最终导致需求1不能满足。如果一定要满足需求1,给某个字段加权很多。又会导致召回的结果相关性不是那么好。因为相关性得分都是根据某个字段加权来的。
2、ES中的相关性算法
ES 5.0 之前,默认的相关性算分采用的是 TF-IDF,而之后则默认采用 BM25
2.1 TF-IDF 是什么
TF-IDF 是ES5.0之前使用的,相关性算法。考虑词频,逆文档率,和词的长度影响。综合得到一个分数。
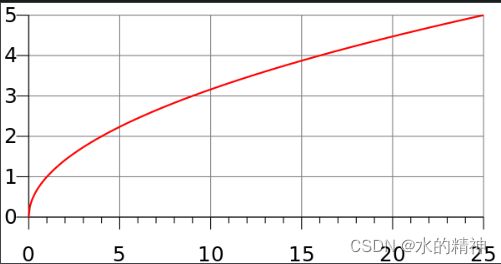
- TF 是词频,比如某个关键词在文章A中出现了10次,在文章B中出现了20次。理想情况下,出现的次数越多。相关性就越大一点。实际计算是,对关键词在文章中出现的次数开平方。平方根的曲线如图所示:
- IDF 是逆文档率。关键词在越多的文章中出现,该词的得分影响就越小。比如你我他这种关键词,可能在每篇文章中都出现了。那么实际上对文档的得分没有什么意义。IDF的计算公式如下:
idf(t) = 1 + log ( numDocs / (docFreq + 1)) numDocs: 是文章总数。例如一共有100篇文章。 docFreq :包含该关键词的文档总数。例如其中一共有10篇文章出现了关键词 “中国” 词 t 的逆向文档频率( idf )是:索引中文档数量除以所有包含该词的文档数,然后求其对数。 注意: 这里的log是指以e为底的对数,不是以10为底的对数。 - 字段长度影响。例如,“联合利剑”在标题字段出现了,在正文也出现了。理想情况下,命中标题,相关性可能会更大一些。标题和正文,一般区别就是,标题比正文短很多。在评分中,字段的长度也会作为相关性分数中的一项去计算。计算公式是:词的个数的平方根,再求倒数。例如标题中有 16个词,先开平方,得到4,再求倒数则为 0.25。正文中有100个词,先开平方得到10,再求倒数,则得到0.1。显然0.25 > 0.1,所以标题更重要。
实际检索,实际上是会进行分词的,不管是句子精准匹配,还是模糊搜索。都需要分词后去匹配。所以总的相关性分数,实际上是拆分后每个词的分数的总和。在lucene中的相关性计算分数公式如下:
score(q,d) =
queryNorm(q)
· coord(q,d)
· ∑ (
tf(t in d)
· idf(t)²
· t.getBoost()
· norm(t,d)
) (t in q)
score(q,d) 文档d对查询q的相关性得分
queryNorm(q) 查询的规范化因子
coord(q,d) 协调因子
∑ 文档d的查询q中每个词t的权重之和
tf(t in d) 文档d中t词的词频(出现次数)
idf(t) t词的逆文档频率
t.getBoost() 已应用于查询的boost。匹配的关键词可以设置权重
norm(t,d) 是字段长度归一值,与检索时字段的Boost (如果存在)相结合2.2 BM25是什么
BM25算法是在TF-IDF之上的补充。其实仔细想一下,还是能够发现TF-IDF的缺陷的。如下:
- 词频。假如数据质量很低,某个词在文章中出现的频率特别高。这会影响召回的效果。发现仅仅只是词频高。 在词频足够高的情况下是会影响到其它评分项的。针对此问题,BM25的做了补充,给了用户使用上更多的自定义空间。其中关于词频这个问题,给了一个参数 k1来控制词频影响的重要程度。具体如何使用,如何调整,在下边。
- 字段长短问题。像开篇提出来的那样,希望命中某个字段就优先返回。这个需求,其实涉及到了词频的问题。在ES使用的BM25算法中,词频阻止实现这个需求。比如一个词在标题中出现了一次,但是在正文中出现了10词甚至更多,这样我们并不能实现在命中标题就将数据排序在前。即使去调标题的权重,也仅能达到70的效果。在BM25算法中,提供了另外一个参数b。可以加对大长文本字段的惩罚。从而达到我们想要的命中标题字段就优先返回。
2.3 BM25在ES中的具体实现(BM25算法公式)
我们直接使用 "explain": true, 参数,在kibana上,分析一个DSL语句。然后一步一步的分析。
我搜索的关键词是 “联合利剑”,然后被分成了三个词,联合,合利,利剑。所以文档的总得分是,“联合”得分 + “合利”得分 + “利剑”得分
先看看“联合”这个词的分数计算。可以看到公式就是: boost * idf * tf
boost : 是给到权重分数,这个可以在查询语句中传入。
idf: 其实就是逆文档率。计算公式 log(1 + (N - n + 0.5) / (n + 0.5)),其中 N是总的文档数,n为出现“联合”一次的文档数。
tf:是词频。 freq / (freq + k1 * (1 - b + b * dl / avgdl)) 。freq 是词在该文档出现的次数,b和k1在上边提到过,在ES默认的BM25算法中,都是默认值,b为0.75,k1为1.2(下边再说为什么默认是这两个值,以及如何调)。dl 为该文档中检索字段的长度,avgdl检索字段的平均长度。
{
"value" : 77.40897,
"description" : "weight(title:联合 in 422639) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 77.40897,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 22.0,
"description" : "boost",
"details" : [ ]
},
{
"value" : 6.267289,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 44240,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 23316810,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.56142133,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 50.0,
"description" : "dl, length of field (approximate)",
"details" : [ ]
},
{
"value" : 93.51748,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
}以上例子是一个最简单的案例,仅仅在一个字段中做检索。假如在多个字段中做检索,会更复杂一些。下边结合ES的参数再分析,这里先不展开。
2.4 BM25中,如何调调参,会有什么效果
在上边的公式中,得分为: boost * idf * tf 。可调整的只有b和k1这两个参数。
其中boost是某个查询字段的权重,可以在查询语句中传入。
idf 公式: log(1 + (N - n + 0.5) / (n + 0.5)) 其中N和n都取决于数据,无法控制。
tf:是词频。得分公式为: freq / (freq + k1 * (1 - b + b * dl / avgdl))。 b和k1只包在这个公式中。b是和长度相关联的,b在公式的分母上,还是以title为例,当title大于平均长度,则 dl / avgdl 大于1, 那么b越大且大于1,就会加大对长度的惩罚力度,如果b越小,则会削弱对长文本的惩罚力度。因为b在分母上且和文档长度相关。 k1也是在分母上,但是可以再次调整词频对分数的影响。适当的增大k1的值可以减小词频对相关性分数的影响。对于词频的得分公式,举例如下。根据总的得分公式,boost * idf * tf ,其实我们关注的是,tf是趋向于1的,tf越小,相关性总分数越小。tf越趋向于1,总得分越和句子的长短以及词频越无关。
- 当检索的字段的内容,大于该字段的平均字段的长度。假如平均长度位10,检索字段为20,则dl / avgdl 为2。我们用默认的b取值0.75,k默认取值1.2。假设检索的目标关键词在被检索文档字段中出现了5次。则得分公式为 5/ (5 + 1.2 *(1 - 0.75 + 0.75 * 20 / 10)) 。
从整体上,b趋向于0,会屏蔽文本长度对分数的影响。b越大,会加大对长文本的惩罚力度。b为0.75,k1为1.2。该默认才是,是经历过学术界大量数据测试得出的数据。在ES官方博客上,有说到,不要去轻易动这两个参数。很可能带来更差的效果。很多问题优先考虑使用其它的方式解决。调b和k1是很复杂的事情。效果收益并不很明显。
参考文档如下:(这是官方的文档,值得好好琢磨)
Practical BM25 - Part 3: Considerations for Picking b and k1 in Elasticsearch | Elastic Blog
2.5 b 和 k1的取值范围
b 取值范围在[0,1]。 最佳范围在 [0.3, 0.9]
k1 取值范围在 [0, 3]。最佳范围在[0.5, 2]
- b needs to be between 0 and 1. Many experiments test values in increments of around 0.1 and most experiments seem to show the optimal b to be in a range of 0.3-0.9 (Lipani, Lupu, Hanbury, Aizawa (2015); Taylor, Zaragoza, Craswell, Robertson, Burges (2006); Trotman, Puurula, Burgess (2014); etc.)
- k1 is typically evaluated in the 0 to 3 range, though there’s nothing to stop it from being higher. Many experiments have focused on increments of 0.1 to 0.2 and most experiments seem to show the optimal k1 to be in a range of 0.5-2.0
2.6 什么时候去调b 和k1
没有任何办法的时候,才调它。并且根据以上最佳取值范围内,以0.1递增,测试在自己数据集上的检索效果。
2.7 其它的方法调整相关性
还是根据官方博客,所说的那样,有以下方法可以去尝试。以下效果都会好于调BM25参数。
- Boosting or adding constant scores for things like exact phrase matches in a bool query
- Making use of synonyms to match other terms the user may be interested in
- Adding fuzziness, typeahead, phonetic matching, stemming, and other text/analysis components to help with misspellings, language differences, etc.
- Adding or using a function score to decay the scores of older documents or documents which are further geographically from the end user
调整boost 取值范围[0, 1] 大于1则会做归一化。实际上越大,则越会放大相关性分数。通常,我们在检索多个字段的时候,假如某个字段的权重不够高,但是我们的需求是让该字段优先级更高一点。就可以通过调这个参数。
官方参考链接:
Practical BM25 - Part 3: Considerations for Picking b and k1 in Elasticsearch | Elastic Blog
2.7.1 指定检索字段的boost权重
注意在相关性总得分公式中boost * idf * tf,boost大于1,则对相关性提分,小于1,则对相关性减分。但是新的评分 _score 会在应用权重提升之后被归一化 ,每种类型的查询都有自己的归一算法。
案例如下:
GET /demo_index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": {
"query": "联合利剑",
"boost": 2
}
}
},
{
"match": {
"content": "联合利剑"
}
}
]
}
},
"explain": true
}不过检索多个字段我还是喜欢multi_match,或者query_string语法。里边有更多的参数可以调,可以使用
GET demo_index/_search
{
"explain": true,
"query": {
"multi_match": {
"query": "联合利剑",
"type": "best_fields",
"tie_breaker": 0.3,
"analyzer": "search_analyzer",
"fields": [
"title^10",
"content^1"
],
"minimum_should_match": "80%"
}
},
"highlight": {
"fields": {
"content": {},
"title": {}
}
}
}其中这三个参数至关重要!它解决了我在开篇提到的需求2(连续命中越多得分越大)
"tie_breaker": 0.3,默认值为0。使用单个最佳匹配查询子句的分数。同时,也可以通过参数 tie_breaker 控制其他查询子句的分数对 _score 的影响。相关性得分计算公式:_score = max(BM25) + ∑ other(BM25)*tie_breaker
"analyzer": "search_analyzer"。 这个是非常重要的(这里search_analyzer是我自定义的,如果没有修改。就指定为ik_smart。)。假如使用了中文分词器,建议在index的时候使用ik_max_word。检索的时候指定 ik_smart。检索的效果会更好一些。否则,如下不同分词器效果展示。如果检索使用ik_max_word,会检索出来很多不相关的内容。单个字命中,召回的数据会严重影响搜索相关性。
注意:关于analyzer并不是固定的。分场景来设置。如果关注句子匹配的效果,可以设置成 ik_max_word。如果是关注模糊匹配的召回效果,使用ik_smart会更好一些。
"minimum_should_match": "80%" ,该参数会减少召回不相关的内容。可以把连续命中更多的内容返回。
注意:以上一几个参数的效果。也仅仅只能达到70%的效果。想要90%以上的效果,还要再来点黑科技。
不同分词效果展示
GET _analyze
{
"text": [
"联合利剑"
],
"analyzer": "ik_smart"
}
# ik_smart分词效果
{
"tokens" : [
{
"token" : "联合",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "利剑",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
}
]
}
GET _analyze
{
"text": [
"联合利剑"
],
"analyzer": "ik_max_word"
}
# ik_max_word 分词效果
{
"tokens" : [
{
"token" : "联合",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "联",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "合利",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "合",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "利剑",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "利",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "剑",
"start_offset" : 3,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 6
}
]
}
2.7.2 使用function_score 打分函数,来调整打分
例如,开篇提的需求,想把连续命中越多的越优先放在前边。那么可以通过使用句子匹配,对完全命中的排在前边。下边例子中,我希望完全命中title的加分。
GET demo_index/_search
{
"_source": [
"title",
"content"
],
"query": {
"function_score": {
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "联合利剑",
"type": "best_fields",
"tie_breaker": 0.3,
"fields": [
"title",
"content"
],
"minimum_should_match": "80%"
}
}
]
}
},
"functions": [
{
"filter": {
"match_phrase": {
"title": "联合利剑"
}
},
"weight": 10
}
],
"score_mode": "max",
"boost_mode": "multiply"
}
}
}
function_score 有很多的参数,有很多新鲜的玩法。这里不过多展开了,这里提供一个官网的地址
Function score query | Elasticsearch Guide [8.7] | Elastic
注意:function函数会在检索过程中的每一条数据上应用。增加了单次检索的时间复杂度。所以会略微影响性能。
2.7.3 使用rescore 来调整打分
rescore 和 function_score不同的是,resocore是一种粗排再精排的思路。也就是function_score是对全局的数据排序。而rescore 只是对一次召回的结果进行重新排序。优点是性能影响小,缺点是影响召回的质量。
使用语法如下:
GET demo_index/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"content": {
"query": "联合利剑",
"minimum_should_match": "80%"
}
}
},
{
"match": {
"title": {
"query": "联合利剑"
}
}
}
]
}
},
"rescore": {
"window_size": 10,
"query": {
"rescore_query": {
"match_phrase": {
"title": {
"query": "联合利剑",
"slop": 0
}
}
}
}
}
}2.7.4 使用修改BM25中的 b和k1参数
这里根据经验,在词频和句子长度对得分影响大的时候可以尝试修改。
PUT /demo_index
{
"settings": {
"similarity": {
"my_similarity": {
"type": "BM25",
"b": 0.8,
"k1": 1.5
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"similarity": "my_similarity"
}
}
}
}效果演示如下:使用explain来看得分计算过程。
POST demo_index/_search
{
"explain": true,
"query": {
"match": {
"title": "联合利剑"
}
}
}
可以看到召回结果中,得分计算过程,b已经被改成了0.8默认为0.75
2.7.5 使用script脚本排序
脚本排序是定义一个脚本。在检索的时候。使用function_score函数,指定使用定义好的脚本。来做排序。相应的更加灵活。但是非常影响性能,随着脚本复杂程度增加,会带来数十倍的性能损失。因为其需要对每一条被检索的数据做复杂的脚本计算。如果真的需要这么做,考虑能不能将分数提前计算好,用一个字段来承载。
3、ES相关性检索中的一些坑
不同的index,各自计算各自的分数。因为不同的index TF和IDF都不一样。可能会出现,同一条数据在A index 得分大于 B index。导致一个奇怪的效果,就是召回的结果中,明明数据a 比b好,但是a排在了b的后边。
即使是同一index,不同的shard,也一样有以上的问题。es中数据维护的单元是shard。shard又是由segment组成的。这会影响最后的召回效果。如果可以的话将segment 合并成一个。如果数据不是太多,尽可能维护更少的shard。(单个shard最多不超过50G,不要小于30G)
搜索不是100的事情,不管如何都做不到100%召回结果。只能通过上边提的方法,去尝试调整。另外不同的场景,分情况讨论,或者使用不同的方式来解决,也能最终解决问题。