java框架004——jdbc(Java Database Connectivity)包括MySQL的安装和使用教程
一、JDBC简介
JDBC(Java Database Connectivity)是一个独立于特定数据库管理系统、通用的SQL数据库存取和操作的公共接口(一组API),定义了用来访问数据库的标准的Java类库,使用这个类库可以以一种标准的方法、方便地访问数据库资源
JDBC为访问不同的数据库提供了一种统一的途径,为开发者屏蔽了一些细节问题。
JDBC的目标是使Java程序员使用JDBC可以连接任何提供了JDBC驱动程序的数据库系统,这样就使得程序员无需对特定的数据库系统的特点有过多的了解,从而大大简化和加快了开发过程。
总结:学习JDBC要了解其API,下载对应数据库系统的JDBC驱动程序
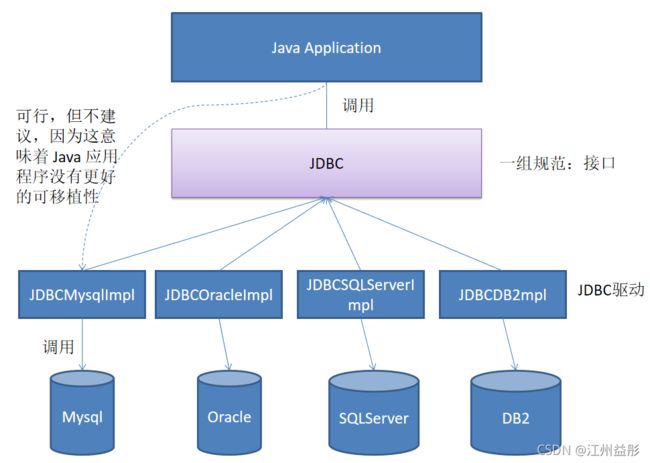
二、JDBC体系结构
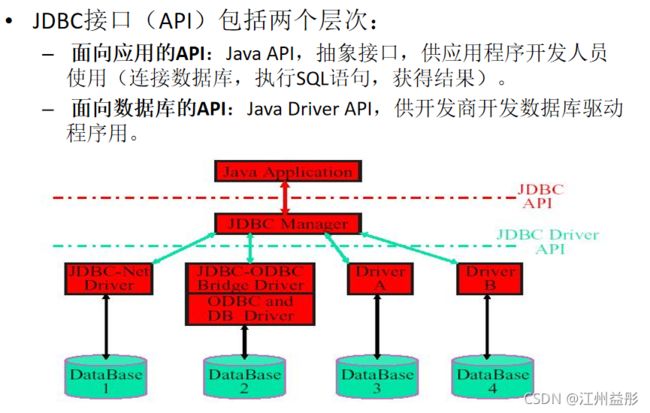
三、JDBC驱动程序
JDBC驱动程序:各个数据库厂商根据JDBC的规范制作的 JDBC 实现类的类库
四、JDBC API
JDBC API 是一系列的接口,它使得应用程序能够进行数据库联接,执行SQL语句,并且得到返回结果。

五、数据库的增删改查例子
整体思路:
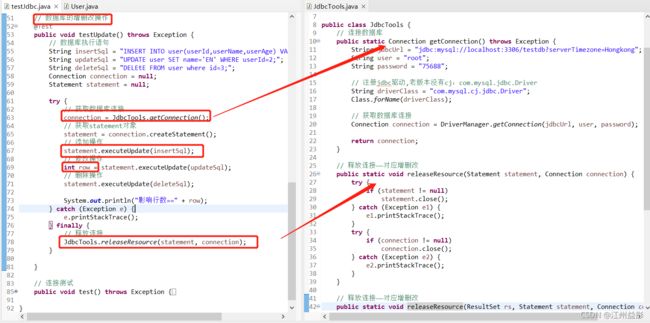
创建数据库—>注册jdbc驱动,连接数据库(Driver)–>获取数据库连接(Connection)–>获取(Statement)–>通过Statement的相关方法进行增删改查int excuteUpdate(String sql);ResultSet executeQuery(String sql)
5.1、创建数据库


5.2、新建动态web工程

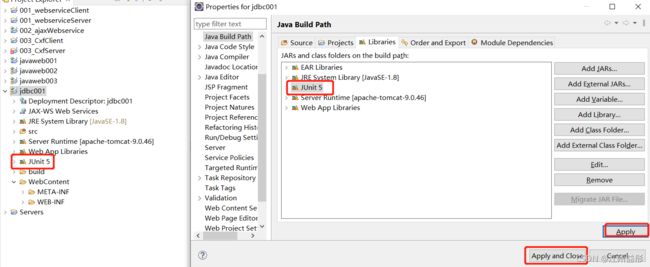
为了测试方便,使用junit测试,加入junit


5.3、连接数据库
几种常用数据库的JDBC URL

对于 Oracle 数据库连接,采用如下形式:
jdbc:oracle:thin:@localhost:1521:sid
对于 SQLServer 数据库连接,采用如下形式:
jdbc:microsoft:sqlserver//localhost:1433; DatabaseName=sid
对于 MYSQL 数据库连接,采用如下形式:
jdbc:mysql://localhost:3306/sid?serverTimezone=GMT%2B8";
//serverTimezone=Asia/Shanghai
//serverTimezone=Hongkong
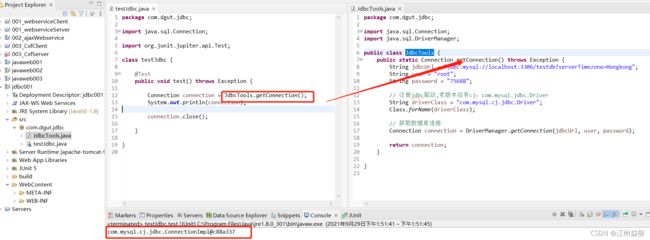
连接数据库
5.4、访问数据库
数据库连接被用于向数据库服务器发送命令和 SQL 语句,在连接建立后,需要对数据库进行访问,执行 sql 语句
在 java.sql 包中有 3 个接口分别定义了对数据库的调用的不同方式:
Statement
PrepatedStatement
CallableStatement
Statement的api介绍
通过调用 Connection 对象的 `createStatement()` 方法创建Statement对象
该对象用于执行静态的 SQL 语句,并且返回执行结果
Statement 接口中定义了下列方法用于执行 SQL 语句:
ResultSet executeQuery(String sql)//数据库的查询
int excuteUpdate(String sql)//数据库的增删改
5.4.1、数据库的增删改操作——executeUpdate()
5.4.2、数据库的查操作——executeQuery()和ResultSet对象
通过调用 Statement 对象的 executeQuery() 方法创建该ResultSet对象
ResultSet 对象以逻辑表格的形式封装了执行数据库操作的结果集,ResultSet 接口由数据库厂商实现
ResultSet 对象维护了一个指向当前数据行的游标,初始的时候,游标在第一行之前,可以通过 ResultSet 对象的 next() 方法移动到下一行
ResultSet 接口的常用方法:
boolean next()
getString()
next()方法获取数据的原理

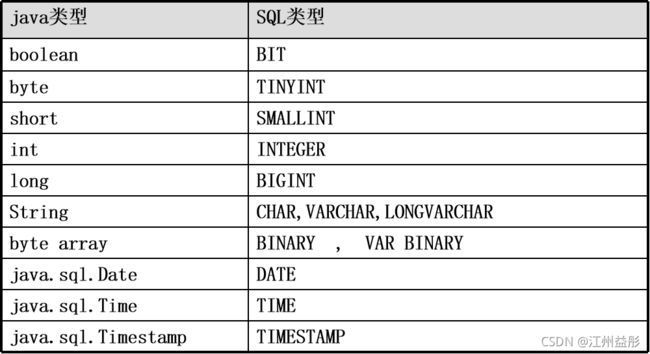
数据类型转换表
说明:右图注释应该是“释放连接--对应查询操作”

5.5、PreparedStatement VS Statement
。代码的可读性和可维护性.
。PreparedStatement 能最大可能提高性能:
——DBServer会对预编译语句提供性能优化。因为预编译语句有可能被重复调用,所以语句在被DBServer的编译器编译后的执行代码被缓存下来,那么下次调用时只要是相同的预编译语句就不需要编译,只要将参数直接传入编译过的语句执行代码中就会得到执行。
——在statement语句中,即使是相同操作但因为数据内容不一样,所以整个语句本身不能匹配,没有缓存语句的意义.事实是没有数据库会对普通语句编译后的执行代码缓存.这样每执行一次都要对传入的语句编译一次.
——(语法检查,语义检查,翻译成二进制命令,缓存)
。PreparedStatement 可以防止 SQL 注入

5.6、通用数据访问对象(DAO)
1、使用PreparedStatement实现通用的更新方法,以实现数据库的添加、修改、删除操作
2、使用PreparedStatement实现通用的查询方法,以实现数据库查询结果集的封装
——ResultSetMetaData
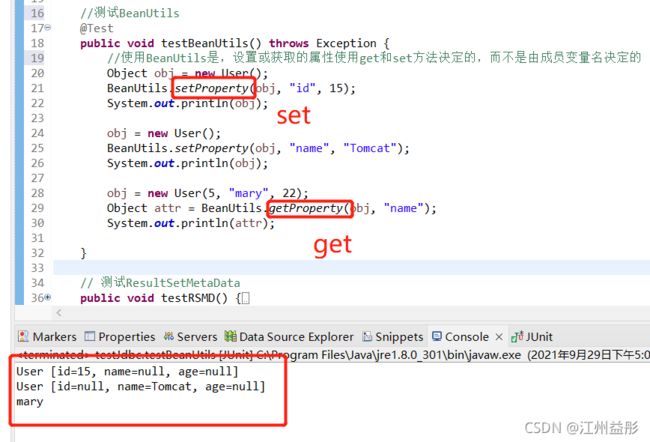
——BeanUtils
注意:不能处理事务。
5.6.1、使用PreparedStatement实现通用的更新方法,以实现数据库的添加、修改、删除操作

5.6.2、使用PreparedStatement实现通用的查询方法,以实现数据库查询结果集的封装
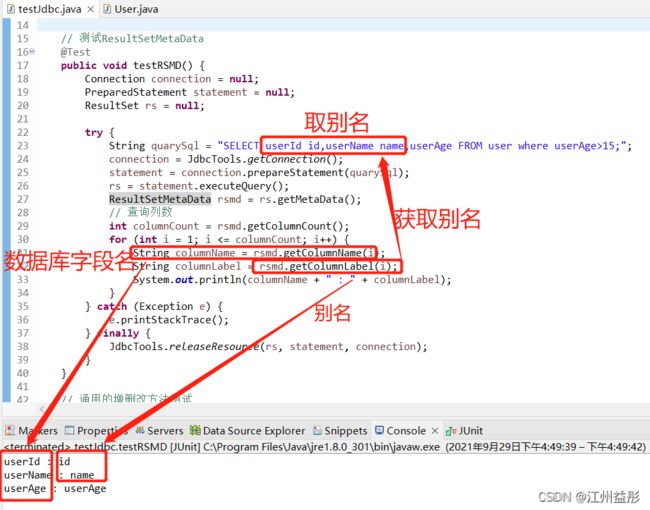
ResultSetMetaData的使用
可用于获取关于 ResultSet 对象中列的类型和属性信息的对象:
getColumnName(int column): 获取指定列的名称
getColumnLabel(int column): 获取结果集列的名称
getColumnCount(): 返回当前 ResultSet对象中的列数。
getColumnTypeName(int column): 检索指定列的数据库特定的类型名称。
getColumnDisplaySize(int column): 指示指定列的最大标准宽度,以字符为单位。
isNullable(int column): 指示指定列中的值是否可以为 null。
isAutoIncrement(int column): 指示是否自动为指定列进行编号,这样这些列仍然是只读的。
上面方法的使用:

附加知识,使用BeanUtli
需要导入jar包

通用查询,查询方法接受的是一个泛型参数,返回也是泛型变量,这样不管查询user 还是member等数据都可以通用

六、数据库连接池(connection pool)
6.1、JDBC数据库连接池的必要性
。在使用开发基于数据库的web程序时,传统的模式基本是按以下步骤:
——在主程序(如servlet、beans)中建立数据库连接。
——进行sql操作
——断开数据库连接。
。这种模式开发,存在的问题:
——普通的JDBC数据库连接使用 DriverManager 来获取,每次向数据库建立连接的时候都要将 Connection 加载到内存中,再验证用户名和密码(得花费0.05s~1s的时间)。需要数据库连接的时候,就向数据库要求一个,执行完成后再断开连接。这样的方式将会消耗大量的资源和时间。数据库的连接资源并没有得到很好的重复利用.若同时有几百人甚至几千人在线,频繁的进行数据库连接操作将占用很多的系统资源,严重的甚至会造成服务器的崩溃。
——对于每一次数据库连接,使用完后都得断开。否则,如果程序出现异常而未能关闭,将会导致数据库系统中的内存泄漏,最终将导致重启数据库。
——这种开发不能控制被创建的连接对象数,系统资源会被毫无顾及的分配出去,如连接过多,也可能导致内存泄漏,服务器崩溃。
6.2、数据库连接池(connection pool)
。为解决传统开发中的数据库连接问题,可以采用数据库连接池技术。
。数据库连接池的基本思想就是为数据库连接建立一个“缓冲池”。预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去。
。数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是重新建立一个。
。数据库连接池在初始化时将创建一定数量的数据库连接放到连接池中,这些数据库连接的数量是由最小数据库连接数来设定的。无论这些数据库连接是否被使用,连接池都将一直保证至少拥有这么多的连接数量。连接池的最大数据库连接数量限定了这个连接池能占有的最大连接数,当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中。
6.3、数据库连接池的工作原理

6.4、数据库连接池技术的优点
。资源重用:
由于数据库连接得以重用,避免了频繁创建,释放连接引起的大量性能开销。在减少系统消耗的基础上,另一方面也增加了系统运行环境的平稳性。
。更快的系统反应速度
数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于连接池中备用。此时连接的初始化工作均已完成。对于业务请求处理而言,直接利用现有可用连接,避免了数据库连接初始化和释放过程的时间开销,从而减少了系统的响应时间
。新的资源分配手段
对于多应用共享同一数据库的系统而言,可在应用层通过数据库连接池的配置,实现某一应用最大可用数据库连接数的限制,避免某一应用独占所有的数据库资源
。统一的连接管理,避免数据库连接泄露
在较为完善的数据库连接池实现中,可根据预先的占用超时设定,强制回收被占用连接,从而避免了常规数据库连接操作中可能出现的资源泄露
6.5、两种开源的数据库连接池

6.6、数据库连接池的使用(参考其自带文档使用)
6.6.1、拷贝jar包到lib目录下

6.6.2、直接使用方式(不推荐)

6.6.3、通过配置文件使用方式(推荐)
创建c3p0配置文件
创建数据库连接池的连接工具



七、Apache-DBUtils——对jdbc进行封装
commons-dbutils 是 Apache 组织提供的一个开源 JDBC工具类库,它是对JDBC的简单封装,学习成本极低,并且使用dbutils能极大简化jdbc编码的工作量,同时也不会影响程序的性能。
API介绍:
——org.apache.commons.dbutils.QueryRunner
——org.apache.commons.dbutils.ResultSetHandler
工具类
——org.apache.commons.dbutils.DbUtils、。
7.1、向lib引入jar包

package com.dgut.jdbc;
import java.sql.Connection;
import java.util.List;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanHandler;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import org.apache.commons.dbutils.handlers.ScalarHandler;
import org.junit.jupiter.api.Test;
class TestDbutils {
// 使用ScalarHandler,只返回一个字段的值,这里返回第一行第一列的id
@Test
public void testScalarHandler() {
QueryRunner queryRunner = new QueryRunner();
Connection connection = null;
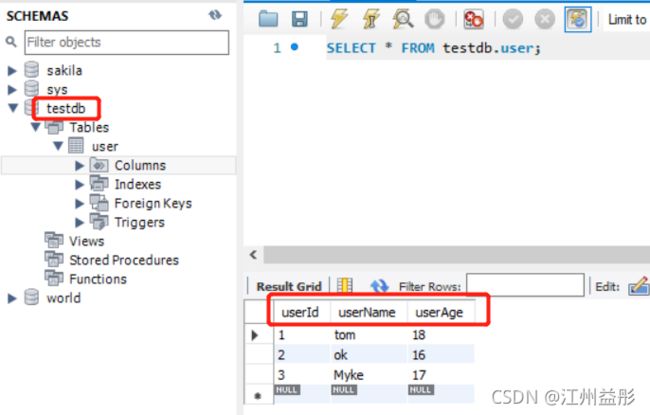
String sql = "SELECT userId id,userName name,userAge age FROM user where userId>2";
ScalarHandler<Integer> rsh = new ScalarHandler<Integer>();
try {
connection = JdbcTools.getConnection();//连接数据库
Integer count = queryRunner.query(connection, sql, rsh);//执行数据库的查询语句
System.out.println(count);
} catch (Exception e) {
e.printStackTrace();
} finally {
JdbcTools.releaseResource(null, connection);
}
}
// 使用BeanListHandler进行查询,将结果集中的每一行数据都封装到一个对应的JavaBean实例中,存放到List里
@Test
public void testBeanListHandler() {
QueryRunner queryRunner = new QueryRunner();
Connection connection = null;
String sql = "SELECT userId id,userName name,userAge age FROM user where userId>2";
BeanListHandler<User> rsh = new BeanListHandler<User>(User.class);
try {
connection = JdbcTools.getConnection();
List<User> customers = queryRunner.query(connection, sql, rsh);
System.out.println(customers);
} catch (Exception e) {
e.printStackTrace();
} finally {
JdbcTools.releaseResource(null, connection);
}
}
// 使用BeanHandler进行查询,将结果集中的第一行数据封装到一个对应的JavaBean实例中。
@Test
public void testBeanHandler() {
QueryRunner queryRunner = new QueryRunner();
Connection connection = null;
String sql = "SELECT userId id,userName name,userAge age FROM user where userId=2";
BeanHandler<User> bh = new BeanHandler<User>(User.class);
try {
connection = JdbcTools.getConnection();
User user = queryRunner.query(connection, sql, bh);
System.out.println(user);
} catch (Exception e) {
e.printStackTrace();
} finally {
JdbcTools.releaseResource(null, connection);
}
}
// 使用QueryRunner进行增删改
@Test
public void testUpdate() {
QueryRunner queryRunner = new QueryRunner();
Connection connection = null;
String sql = "INSERT INTO user (userId,userName, userAge) VALUES (?,?,?);";
Object[] objs = { 5, "bbb", 21 };
try {
connection = JdbcTools.getConnection();
queryRunner.update(connection, sql, objs);
} catch (Exception e) {
e.printStackTrace();
} finally {
JdbcTools.releaseResource(null, connection);
}
}
}
八、DAO的实现
8.1、只针对user实现(不推荐)

定义相关的接口

接口的实现和测试
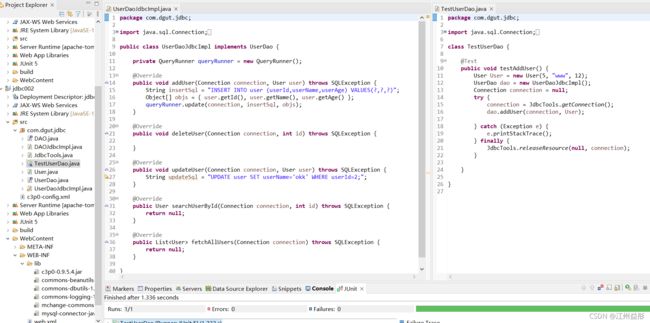
8.2、实现通用dao

定义通用的dao接口
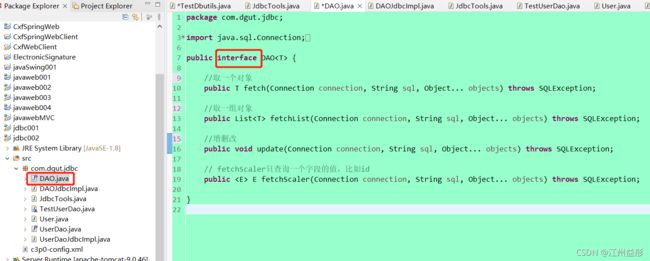
实现通用的dao接口
package com.dgut.jdbc;
import java.lang.reflect.ParameterizedType;
import java.lang.reflect.Type;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.List;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanHandler;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import org.apache.commons.dbutils.handlers.ScalarHandler;
public class DAOJdbcImpl<T> implements DAO<T> {
private QueryRunner queryRunner;
private Class<T> type;// 类型
// 确定泛型T的类型,User还是Member,等等
@SuppressWarnings("unchecked")
public DAOJdbcImpl() {
queryRunner = new QueryRunner();
type = getSuperClassGenricType(getClass(), 0);
}
@SuppressWarnings("rawtypes")
private Class getSuperClassGenricType(Class clazz, int index) {
Type = clazz.getGenericSuperclass();
if (!(genType instanceof ParameterizedType)) {
return Object.class;
}
Type[] params = ((ParameterizedType) genType).getActualTypeArguments();
if (index >= params.length || index < 0) {
return Object.class;
}
if (!(params[index] instanceof Class)) {
return Object.class;
}
return (Class) params[index];
}
// 将结果集中的第一行数据封装到一个对应的JavaBean实例中
public T fetch(Connection connection, String sql, Object... objects) throws SQLException {
BeanHandler<T> rsh = new BeanHandler<T>(type);
return queryRunner.query(connection, sql, rsh, objects);
}
// 将结果集中的每一行数据都封装到一个对应的JavaBean实例中,存放到List里
public List<T> fetchList(Connection connection, String sql, Object... objects) throws SQLException {
BeanListHandler<T> rsh = new BeanListHandler<T>(type);
return queryRunner.query(connection, sql, rsh, objects);
}
// 更新
public void update(Connection connection, String sql, Object... objects) throws SQLException {
queryRunner.update(connection, sql, objects);
}
// 获取一个字段的值,例如id
public <E> E fetchScaler(Connection connection, String sql, Object... objects) throws SQLException {
ScalarHandler<E> rsh = new ScalarHandler<E>();
return (E) queryRunner.query(connection, sql, rsh, objects);
}
}
实现通用接口的实现

测试
package com.dgut.jdbc;
import java.sql.Connection;
import java.util.List;
import org.junit.jupiter.api.Test;
class TestUserDao {
@Test
public void testAddUser() {
User User = new User(6, "ddd", 14);
UserDao dao = new UserDaoJdbcImpl();
Connection connection = null;
try {
connection = JdbcTools.getConnection();
dao.addUser(connection, User);
} catch (Exception e) {
e.printStackTrace();
} finally {
JdbcTools.releaseResource(null, connection);
}
}
@Test
public void testDeleteUser() {
int id = 6;
UserDao dao = new UserDaoJdbcImpl();
Connection connection = null;
try {
connection = JdbcTools.getConnection();
dao.deleteUser(connection, id);
} catch (Exception e) {
e.printStackTrace();
} finally {
JdbcTools.releaseResource(null, connection);
}
}
@Test
public void testUpdateUser() {
User User = new User(2, "heihei", null);
UserDao dao = new UserDaoJdbcImpl();
Connection connection = null;
try {
connection = JdbcTools.getConnection();
dao.updateUser(connection, User);
} catch (Exception e) {
e.printStackTrace();
} finally {
JdbcTools.releaseResource(null, connection);
}
}
@Test
public void testGetById() {
int id = 3;
UserDao dao = new UserDaoJdbcImpl();
Connection connection = null;
try {
connection = JdbcTools.getConnection();
User User = dao.searchUserById(connection, id);
System.out.println(User);
} catch (Exception e) {
e.printStackTrace();
} finally {
JdbcTools.releaseResource(null, connection);
}
}
@Test
public void testGetAll() {
UserDao dao = new UserDaoJdbcImpl();
Connection connection = null;
try {
connection = JdbcTools.getConnection();
List<User> Users = dao.fetchAllUsers(connection);
System.out.println(Users);
} catch (Exception e) {
e.printStackTrace();
} finally {
JdbcTools.releaseResource(null, connection);
}
}
}
五、MySql的下载和安装教程
5.1、下载MySql

下载
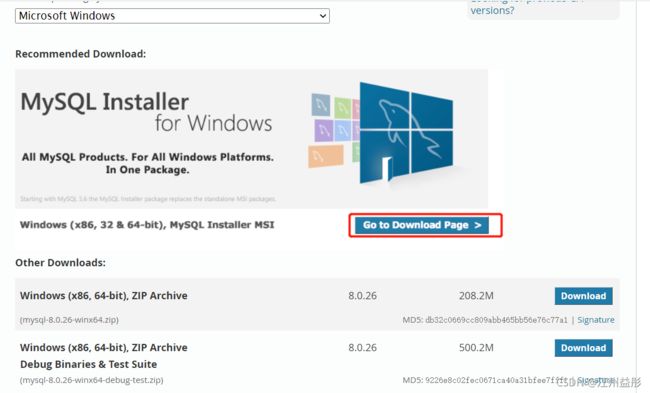
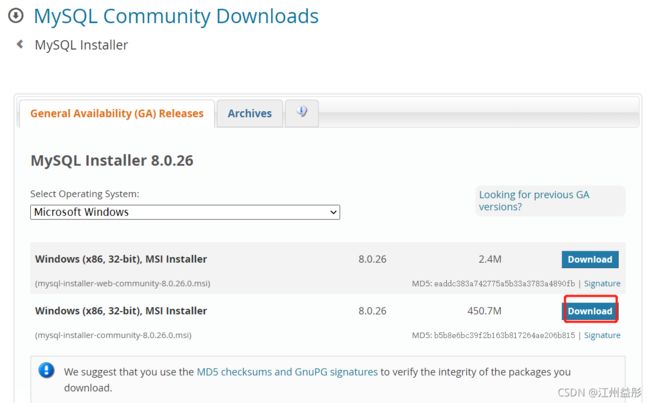
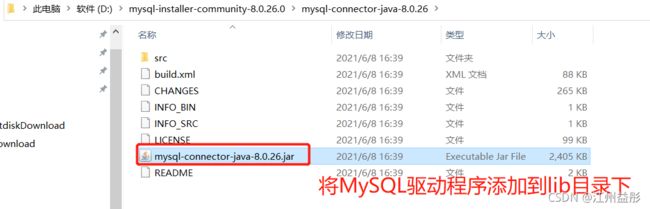
5.2、下载MySQL驱动

5.3、开始安装



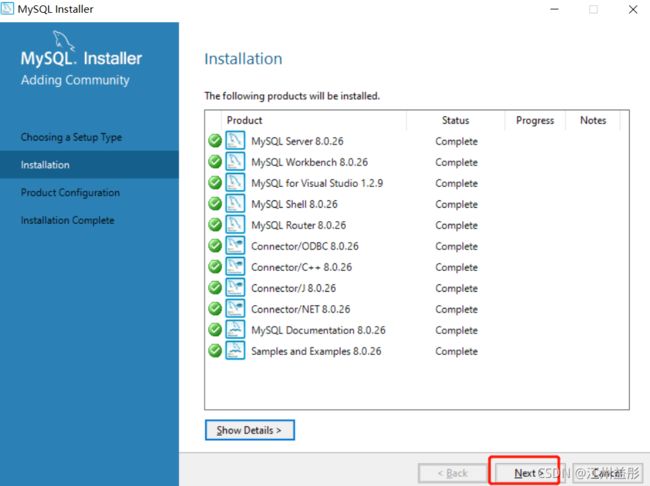

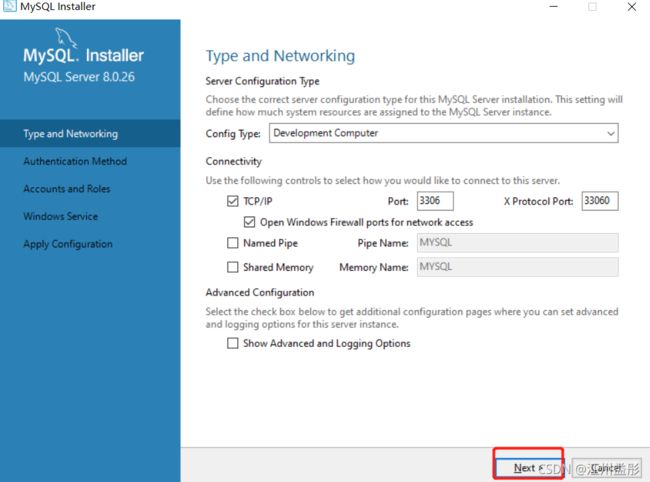


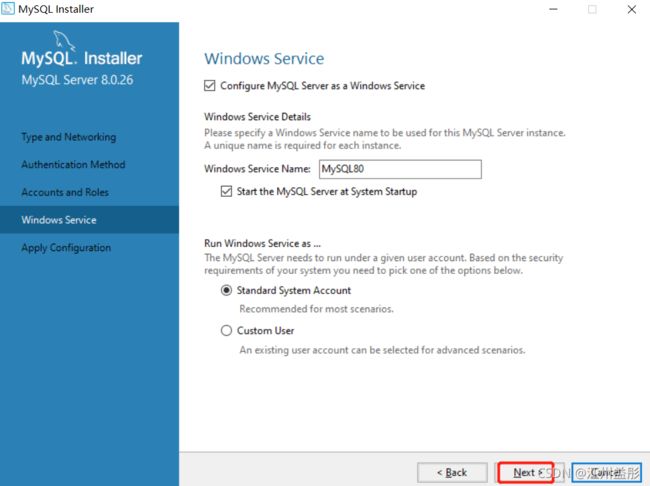
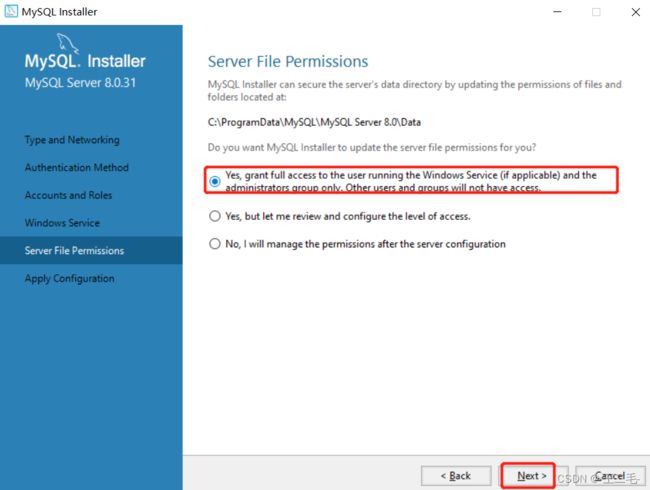








到此,成功安装
5.4、扩展
1.添加步骤:a.打开控制面板-系统和安全-系统 b.点击高级系统设置 c.点击环境变量 d.选择pathe.添加路径;
2.关于路径:在windows平台下找到MySQL的安装路径 (例如:Windows 10 64位系统默认安装在C:\Program Files\MySQL\MySQL Server 8.0\bin);或者打开mysql,输入select @@basedir as basePath from dual来查看路径
