Linux三剑客(awk、sed、grep) 和 正则表达式
本文章适用于一定工作经验(熟悉Linux基础)的同行,欢迎各位大佬批判指正。
上手三剑客(grep,sed,awk)之前,需要熟悉正则表达式,正则表达式——事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。而正则表达式又分普通正则和扩展正则。
正则表达式
| 符号 | 含义 |
| ^ | 匹配开头,如 ^123 以123开头,有则匹配出来 |
| $ | 匹配结尾,如123$ 以123结尾,有则匹配出来 |
| ^$ | 匹配空行,也就是那一行啥都没有(空格也不行)则匹配出来 |
| . | 任意一个字符(空行除外) |
| * | 前一个字符连续出现0次或者多次 |
| .* | 任意字符出现0次(多次),也就是代表所有 |
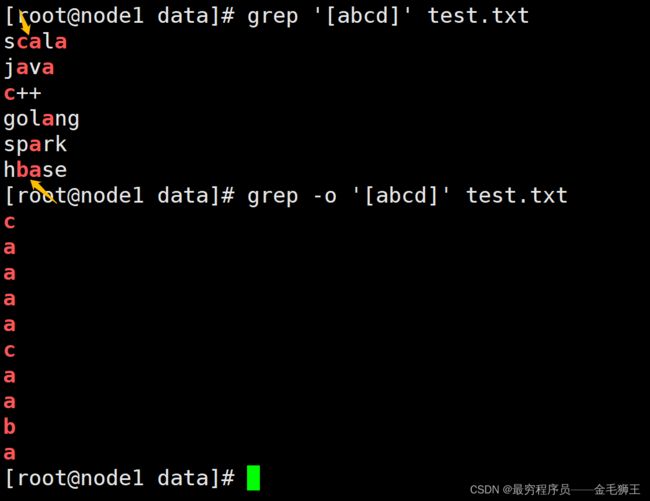
| [] | 一次匹配一个字符,可多样。[abcd],匹配a或者b或者c或者d |
| [^] | 取反,如[^abc],排查abc |
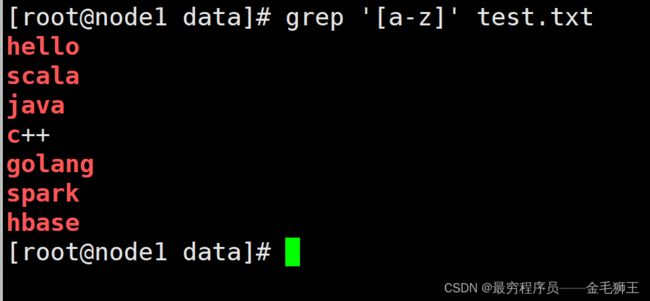
| [0-9]、[a-z]、[A-Z]、[a-Z] | 由于[abcdef]这种匹配写法比较繁琐,因此有区间简化写法。范围匹配,其中[a-Z]释义:匹配小写a到z和大写A到Z |
| \ | 反斜杠,适用于转义匹配,如匹配以.结尾 grep '\.$' filename |
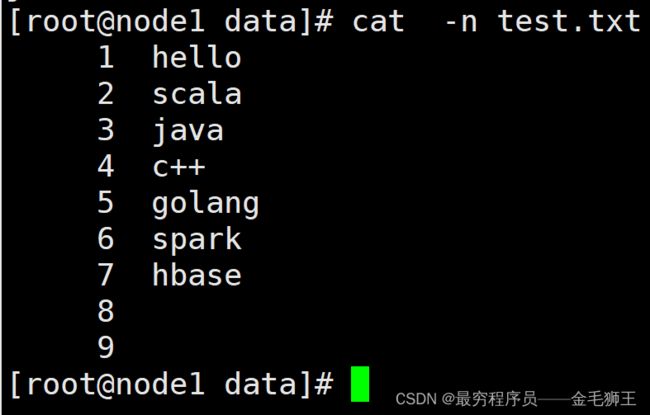
示例:其中准备的数据test.txt文件的8 9行为空行
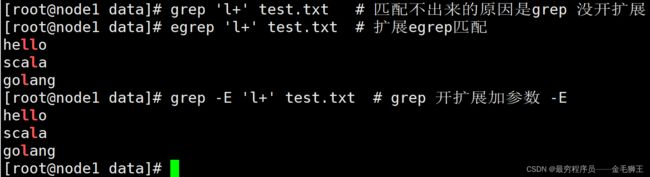
[root@node1 data]# # 匹配以s开头,可匹配出scala和spark
[root@node1 data]# # 匹配以a结尾,可匹配出scala和java
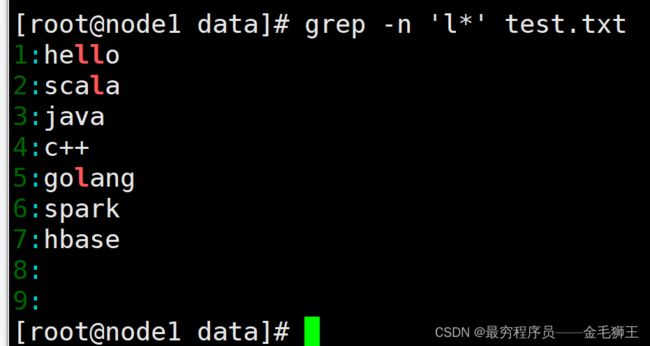
[root@node1 data]# # 匹配出空行,也就是匹配8 9 行
[root@node1 data]# # . 匹配出所有(空行除外),8 9为空行,则被过滤掉
[root@node1 data]# # * 匹配前一个字符连续出现0次或者多次
[root@node1 data]# # .* 表示所有(包括空行)
[root@node1 data]# # 一次匹配一个字符,可多样。[abcd],匹配a或者b或者c或者d,注意:匹配的scala和hbase中有ca、ba两个同时出现,要看具体匹配过程可加-o参数
[root@node1 data]# # 中括号区间匹配 [a-z],其中++不在小写a至z之间,所以没有高亮
[root@node1 data]# # 取反[^abc],即为排除abc(不高亮abc)
[root@node1 data]# # \反斜杠转义,第一个grep由于没有转义,匹配出任意的字符,所以所有字符都高亮显示了,而第二grep加了转义符"\"反斜杠,将.转义成普通的字符,所以高亮显示了awk.sed.grep
### 以上为基础正则语法,接下来的为扩展正则语法







| 符号 | 含义 |
| ? | 前一个字符连续出现0次或者1次,也就是出现0次或者1次 |
| + | 前一个字符出现1次或者1次以上 |
| {} | 前一个字符出现的次数。a{1,3}:a最少出现1次,最多出现3次。b{5}:b只出现5次,此处为精确匹配 |
| | | 或者,A|B:A或者B |
| () | 表示一个整体(java|scala),匹配java或者scala,这里当做一个整体匹配 |
示例:还是以刚才的test.txt文件为基础数据
特别说明:由于是用到了扩展正则,所以grep需要加参数 -E,你可能也见过egrep,egrep 和grep -E 完全一样,只是扩展的另一种写法,grep 常用的参数在后续会做出解释
[root@node1 data]# # 扩展正则+号,前一个字符出现1次或者1次以上,也就是至少匹配1次
[root@node1 data]# # 扩展正则|符号,匹配l或者k l|k
[root@node1 data]# # 扩展正则() ,匹配sa中间是c或者p的
[root@node1 data]# # 扩展正则 {} 次数匹配
[root@node1 data]# # 扩展正则 ? 匹配0次或者1次,其中小写l在后面的字母hello出现了1次,scala出现0次,golang也是0次。
### 至此,你对正则已经熟悉了解了,接下来则是三“贱”客






三剑客——awk(老大)、sed(老二)、grep(老三)
| 名字 | 适用场景 |
| awk | 取列,统计计算。取对应列的值,后续用于对比、计算,以及数组的计算,由于数组计算使得awk排行老大 |
| sed | 替换,修改文件,日志取行。文件的修改以及日志的范围取行,如晚上0点到凌晨1点的日志 |
| grep | 用于过滤,grep的命令过滤是最快的 |
按照习惯,先易后难,下面解释grep 常用的参数,对于日常用已经够用啦,当然想深入学习可man grep 看官方解释。
三剑客老三:grep
grep 常用参数
实例:以我本机一段message日志为例
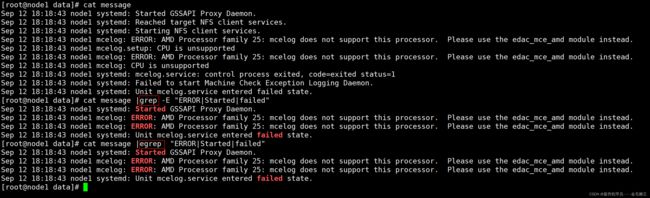
[root@node1 data]# cat message
Sep 12 18:18:43 node1 systemd: Started GSSAPI Proxy Daemon.
Sep 12 18:18:43 node1 systemd: Reached target NFS client services.
Sep 12 18:18:43 node1 systemd: Starting NFS client services.
Sep 12 18:18:43 node1 mcelog: ERROR: AMD Processor family 25: mcelog does not support this processor. Please use the edac_mce_amd module instead.
Sep 12 18:18:43 node1 mcelog.setup: CPU is unsupported
Sep 12 18:18:43 node1 mcelog: ERROR: AMD Processor family 25: mcelog does not support this processor. Please use the edac_mce_amd module instead.
Sep 12 18:18:43 node1 mcelog: CPU is unsupported
Sep 12 18:18:43 node1 systemd: mcelog.service: control process exited, code=exited status=1
Sep 12 18:18:43 node1 systemd: Failed to start Machine Check Exception Logging Daemon.
Sep 12 18:18:43 node1 systemd: Unit mcelog.service entered failed state.
grep -i :grep 默认是区分大小写的,-i参数则不区分大小写匹配
grep -v:反向匹配(取反,过滤掉匹配的)
grep -E :扩展正则表达式,匹配多个条件 "ERROR|Started|failed",egrep等同于grep -E
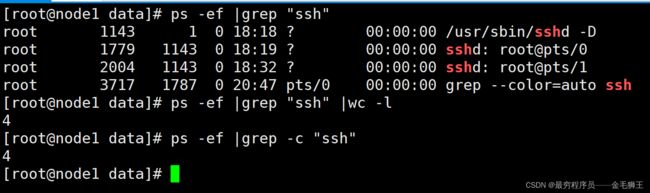
grep -w :精确匹配,主要用于过滤端口
grep -c :统计匹配次数(类似于wc -l)
grep -n:匹配后显示行号
### 以上为grep 常用参数以及实例,接下来则为sed




三剑客老二:sed
sed 命令: sed是以数据流方式读取文件内容,每次会读取一行进行匹配,看是否满足匹配要求,满足则做增删改查操作,操作完成后屏幕打印,打印出来后重复刚才的动作读取下一行进行匹配,以此循环,流程如下图。

| 功能 |
解释说明 |
| p |
p为打印(pringt) |
| s |
s为替换(substitute) |
| d |
d为删除(delete) |
| cai |
替换replace,追加append,插入insert |
以上简记为为增删改查(此增删改查非curd)
test.txt示例数据准备
在使用sed命令打印之前需了解-n参数,加了-n参数为取消自动打印,-n通常与p搭配(可以死记np组合),区别如下:
sed p查找打印——print
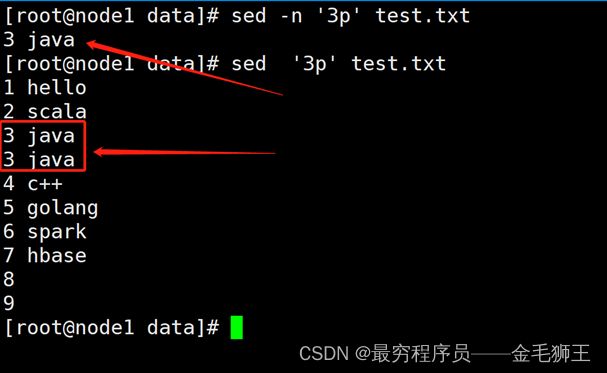
'1p'、'3p' 打印第1行,打印第3行,用于精确匹配行数
'1,3p'、'2,5p' 打印第一至第三行,第二至第五行,用于范围。扩展:'5,$p'——打印第五行至最后一行
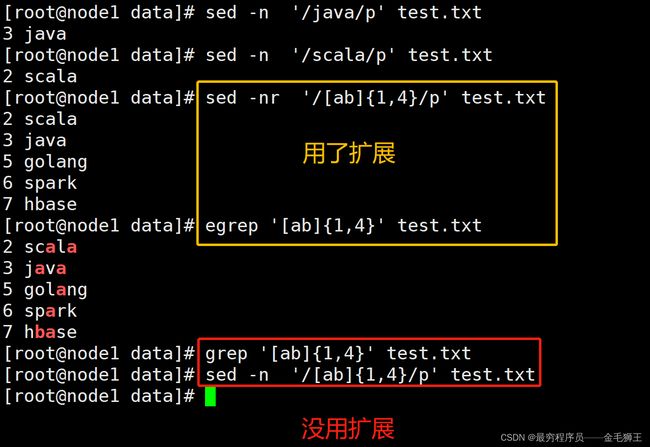
'/scala/p' 精确匹配出scala,类似于grep命令,// 斜线中间可写正则,/[abc]/,如果用到了扩展正则,则需要加 -r参数:如 sed -nr ’/[abc]?/’ test.txt
'/scala/,/spark/p' 表示匹配scala到spark范围内全部输出,通常用于日志时间
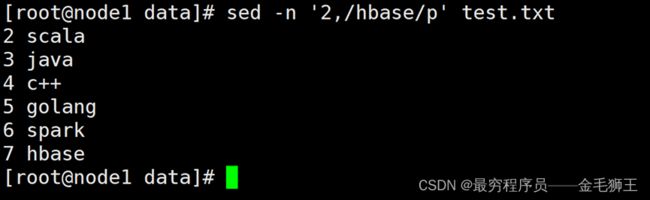
进阶用法:以上4种可混合搭配,如:sed -n '2,/hbase/p' test.txt
查找打印“p”总结 '1p'、'3p'
打印第1行,打印第3行,用于精确匹配行数
'1,3p'、'2,5p'
打印第一至第三行,第二至第五行,用于范围,扩展:'1,$p'——打印第一行至最后一行
'/scala/p'
精确匹配出scala,类似于grep命令
'/scala/,/spark/p'
表示范围匹配,从scala到spark




sed d删除——delete
有了查找的基础再来看删除就很简单了
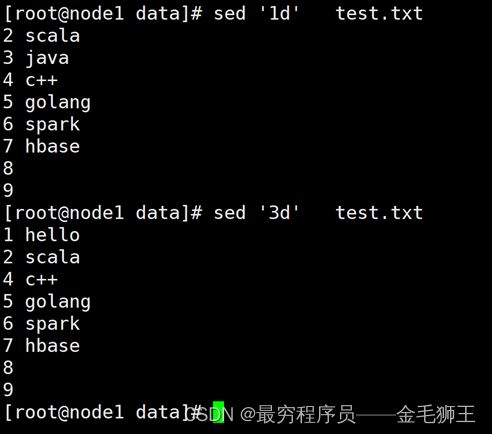
'1d'、'3d'
删除第1行,删除第3行,用于精确匹配行数
'1,3d'、'2,5d'
删除第一至第三行,第二至第五行,用于范围,扩展:'1,$d'——删除第一行至最后一行
'/scala/d'
精确匹配出scala并删除
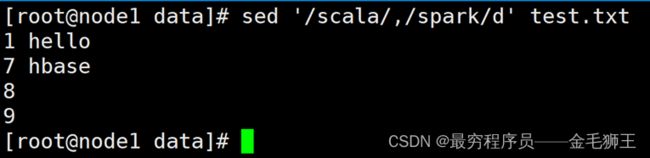
'/scala/,/spark/d'
表示范围匹配,删除从scala到spark
'1d'、'3d' 删除第1行,删除第3行,用于精确匹配行数
'1,3d'、'2,5d' 删除第一至第三行,第二至第五行,用于范围,扩展:'4,$d'——删除第四行至最后一行
'/scala/d' 精确匹配出scala并删除
'/scala/,/spark/d' 表示范围匹配,删除从scala到spark
实战案例:删除空行和#注释行
查找跟删除已经完结了,接下来是sed命令增加


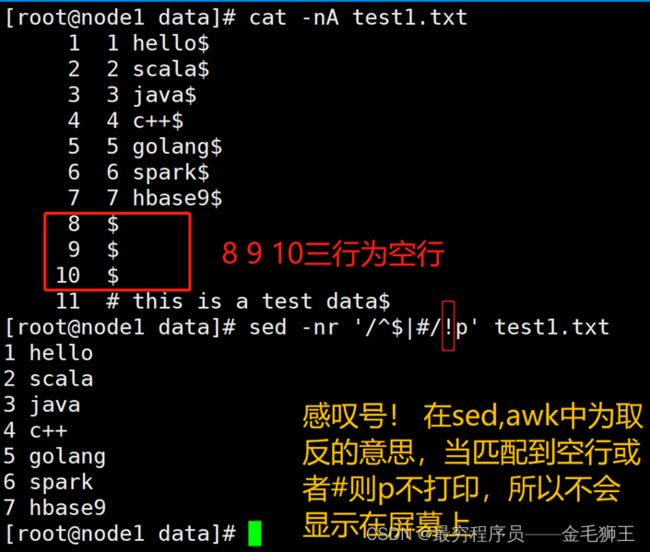
sed cai增加——replace、append、insert
参数解释 -cai c
replace 替换
a
append 行后追加
i
insert 行前插入
'3c this is replace' 将第三行替换成 this is replace
'3a this is append' 在第三行后面追加this is append
'3i this is insert' 在第三行前插入this is insert

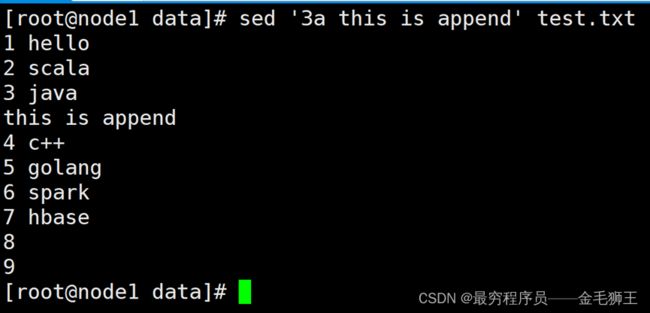

sed s 替换——substitute
参数释义: -s 为替换
-g 为全局替换(global),不加的话只替换每行的第一个匹配项
命令格式:sed 's///g' test.txt,sed 's###g' test.txt,sed 'sAAAg' test.txt,sed 's888g' test.txt,不管是///还是###,AAA这些,都能匹配,没有严格要求,但是尽量避免关键字符。比较常见的为###,///
替换这块主要是正则表达式书写能力,正则很强的话后面几个进阶案例会让你自然领悟
替换每行中0、1、2为aa
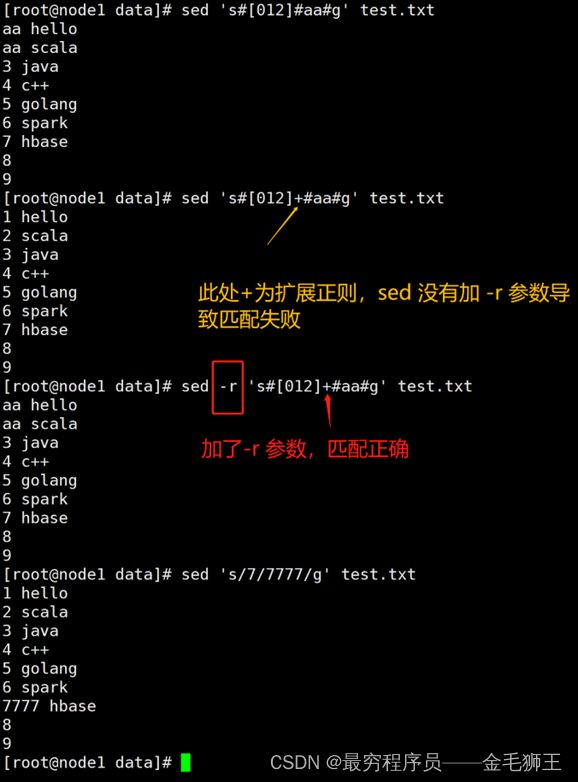
sed进阶之反向引用:先正则匹配出来分组,后续按组使用
把hello_linux 改成linux_hello
正则匹配这块可根据自己的习惯来,能匹配出来就行
上图的echo 'hello_linux' |sed -r 's#([a-z]+)_([a-z]+)#\2_\1#g' 和 echo 'hello_linux' |sed -r 's#(.*)_(.*)#\2_\1#g' 这两个匹配出来的结果是一样的

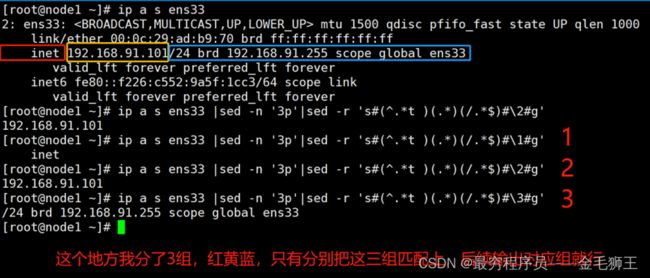
sed 进阶反向实战案例一:取ip
sed 进阶反向实战案例二:切出sync(切出/etc/passwd sync用户名)


三剑客老大:awk
awk是一种用于处理文本的编程语言工具,很多方面都类似于shell(c语言),主要应用场景:统计日志,计算。其awk执行过程如下图。左边为案例,右边为流程图
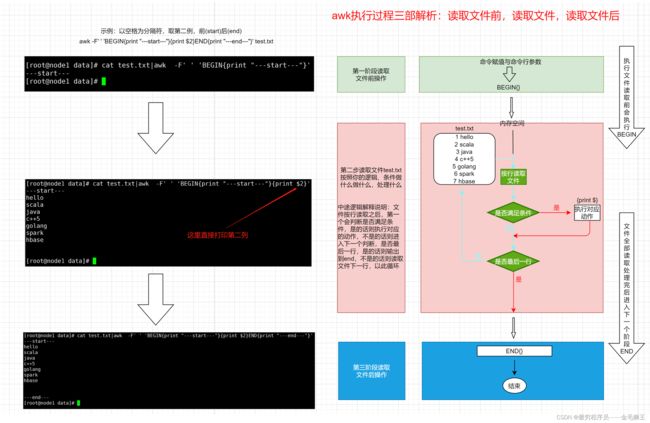
在上手awk之前首先了解什么是行与列,行——awk中称为记录,单行默认以回车分割;列——awk中称为字段(类似于数据库的字段),默认用空格分割。除了行与列还需要熟悉awk的常用内置变量,以下的内置变量在接下来的案例中都有使用到
| 内置变量 |
变量说明 |
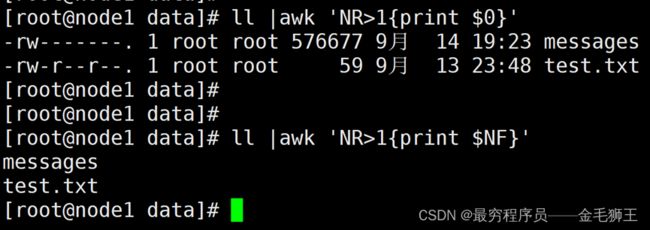
| NR |
行号 NR==2:第二行 |
| NF |
字段数量(多少列) $NF:最后一个字段 |
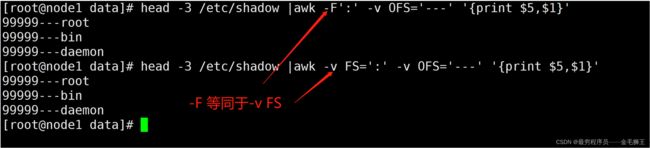
| FS |
输入字段分隔符,默认空格。-F: 等同于-v FS=: ----说明:-v 是修改awk变量 |
| OFS |
输出字段分隔符,默认空格。 |
awk取行
行号的内置变量是NR,运算符有> < >= <= == !=,有shell(c) 或者其他开发语言基础,都能理解吧
NR==1:取第一行
NR>=3 && NR<=6:取3到6行(范围取行)
/spark/:精确匹配取spark行,这个地方比sed简单,不需要那些-n p啥的
/java/,/spark/:也可以匹配范围取行,比如java到spark

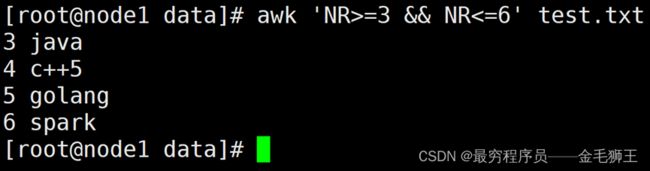


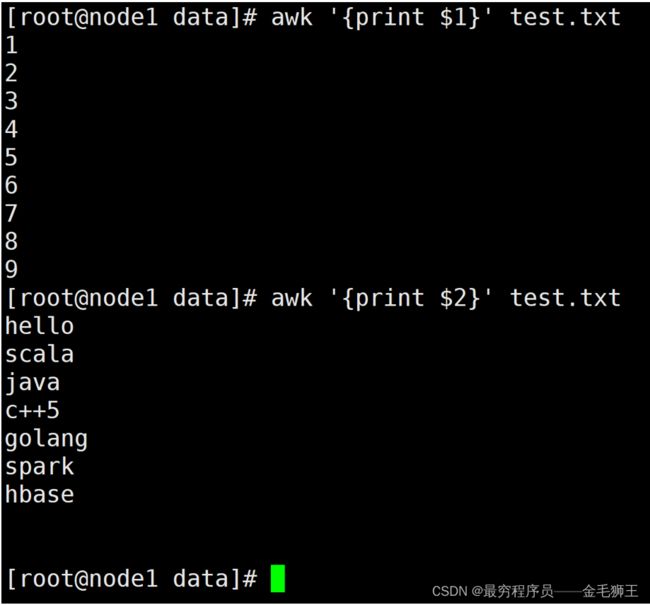
awk取列
参数说明:
-F : 指定分隔符——每一列的结束符,默认为空格、连续空格、制表符
$数字:awk中$数字就表示第几列,$0表示处理后输出的所有
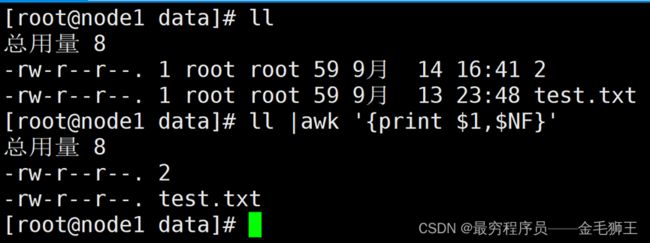
awk取第一列,第二列
取ll 显示的第1列和最后一列($NF)
取/etc/shadow的第1列和第五例,并置换位置,且输出分隔符用 ---
awk取行和列进阶案例:取出 /etc/passwd 第三行至第七行,并且置换第一列与第最后一列,屏幕输出列的分割符号用%
经典案例:切割ip
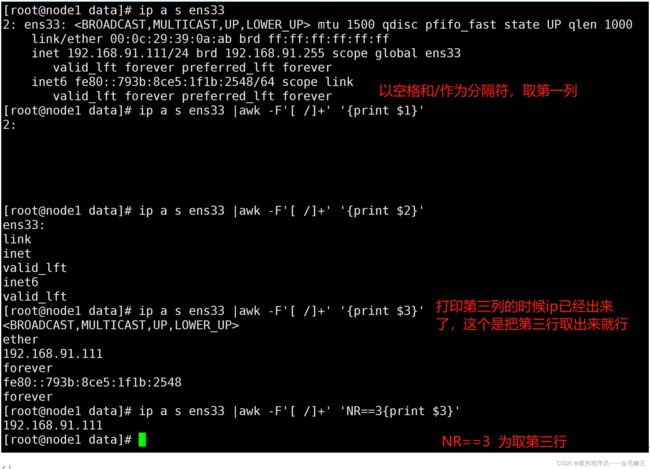

awk 模式匹配
awk -F'[ /]+' 'NR==3{print $3}'
awk——命令
-F ——选项
'NR==3{print $3}'——模式{动作} # 此处下面为模式说明
模式说明——
比较符:> < >= <= == !=
正则://,斜线里支持写扩展正则,能精确到单列,包含(~)和不包含(!~)
范围表达式:/开始/,/结束/;NR==2,NR==7 # 前者为方式一,后者为方式二
特殊模式:BEGIN{}、END{}
模式说明之比较符案例:从第二行开始取最后一列
模式说明之正则案例:取第二列以2开头
找最后一列,以a,b,c结尾的,并显示第1列和最后一列,以***分割输出


模式说明之范围表达式案例:显示message 18:50:01到19:10:01 月份日期和时间
模式说明之特殊模式:BENGIN{}、END{}
特殊模式——BEGIN:文件读取之前会执行里面的内容。适用于文件处理前添加说明;简单计算,统计;定义awk变量(和-v 一个意思)。以下表格为计算、统计方法说明(i为自定义变量),统计方法会在数组,日志计次,列求和常用。
特殊模式BEGIN——文件处理前添加说明案例:在文件读取前BEGIN添加说明" ---BEGIN---"
统计方法
简写
使用场景
i = i + 1
i++
统计次数
i = i + $? 这里 $? 以$1为例
i += $?
第一列求和
i[]=i[]+1
i[]++
数组分类统计次数
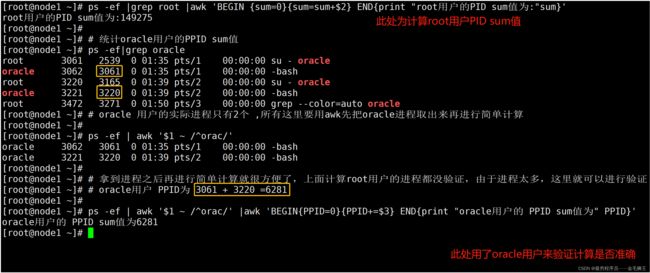
特殊模式BEGIN——简单计算和统计:root用户pid 求和
特殊模式——END:文件读取之后会执行里面的内容。 适用于文件处理后添加说明;对应之前BEGIN的计算在END输出结果;
END案例:求1到100的和(通过上面的bengin和end案例,你应该能写出来)

awk数组
awk能排上老大的称号主要是因为数组统计,这个地方的统计主要用于日志,比如说高可用中探活时间统计,日志中用户名、ip出现次数等等……
| shell数组 |
awk 数组 |
|
| 定义方式 |
array[0]=hello |
array[0]=hello |
| 使用输出 |
echo ${array[0]} |
print array[0] |
| 批量输出 |
shell数组的批量输出是for循环,如: [root@node1 ~]# array[0]=hello [root@node1 ~]# array[1]=scala [root@node1 ~]# array[3]=java [root@node1 ~]# for i in ${array[*]};do echo $i ;done hello scala java |
awk中,数组的输出方法也是for循环,但是更加简洁。 坑一:由于在awk 中,所以定义数组的时候如果是字母,会被识别为变量导致变量失败,所以需要用双引,array[0]=”hello” 坑二:for 循环必须带上括号for (i in array) 坑三:print 打印需要带上index下标(有点类似于Python),如print array[0],不带的话直接print array 打印的是数组的index 案例: [root@node1 ~]# awk 'BEGIN{array[0]="hello";array[1]="scala";array[2]="java" ;for (i in array) print i "下标:"array[i]}' 0下标:hello 1下标:scala 2下标:java [root@node1 ~]# |
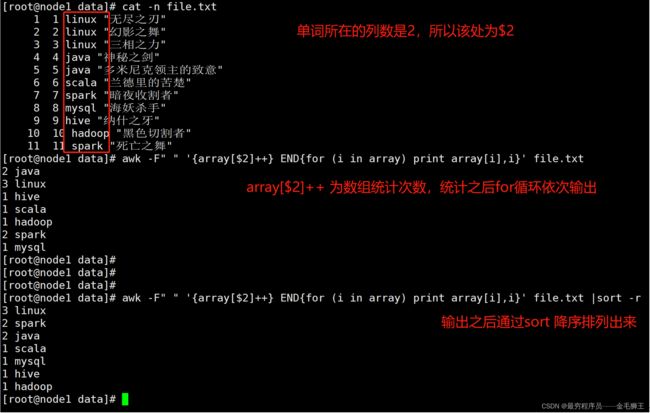
awk数组案例:统计file.txt中每个单词出现的,并按降序排列
file.txt文件数据
1 linux "无尽之刃"
2 linux "幻影之舞"
3 linux "三相之力"
4 java "神秘之剑"
5 java "多米尼克领主的致意"
6 scala "兰德里的苦楚"
7 spark "暗夜收割者"
8 mysql "海妖杀手"
9 hive "纳什之牙"
10 hadoop "黑色切割者"
11 spark "死亡之舞"
[root@node1 data]# awk -F" " '{array[$2]++} END{for (i in array) print array[i],i}' file.txt |sort -rn
3 linux
2 spark
2 java
1 scala
1 mysql
1 hive
1 hadoop
[root@node1 data]#
awk数组案例(进阶难度):统计file.txt中第二列首字母在r-z范围内,每个单词出现的次数,并按降序排列

awk循环与判断
| shell中for |
awk中for循环 |
| for((i=0;i<=100;i++)); do |
for(i=0;i<=100;i++) |
| shell中if 判断 |
awk中if判断 |
| if [];then echo |
if() |
awk for循环案例:
awk判断案例:输出磁盘使用率小于30%的所有信息
awk循环与判断进阶案例:echo "Life there are always frustrations, as long as we meet chaoyang, will see the light ahead.",输出语句中每个单词的字母数量大于等于5的单词



至此,下次遇到让你切割ip的面试问题,你能花式切割了吗?( *~▽~)
我知道大部分人都不喜欢看英文版的官文,这里分享一个中文命令手册!!!!
Linux命令手册:linux命令在线中文手册