CPT104 操作系统学习笔记 xjtlu
目录
lec1 进程 process
1.1Characteristics of Operating Systems 操作系统的特点
1.2 操作系统概述(Operating System)
1.3 进程 (process)
进程的状态:
PCB进程控制块 (Process Control Block)
进程调度概述(Process Scheduling)
1.4 对进程的操作(Operations on Processes)
1.5 进程间通信(Inter-process Communication)
lec2 线程
2.1 线程的简要概述(thread)
2.2 线程的优点(Benefits of Threads)
2.3线程状态(Thread states)
2.3 单线程进程和多线程进程(Single and Multithreaded Processes)
2.4并发和并行(Concurrency vs. Parallelism)
2.5 多线程模型 (Multithreading Models)
2.6 线程库(Thread Libraries)
2.7 Managing threads
2.8 Threading Issues in Multithreading environments
lec3 进程同步(Process Synchronization)
3.1 Background
3.2 The Critical Section Problem
解决关键段问题的方法需要满足以下三个要求or原则:
基于原则解决关键段问题的方法可以分为以下几类:
3.3 Software solutions (Peterson’s Solution)
3.4 Hardware Solutions
单处理器环境 Single-processor environment
多处理器环境 Multi-processor environment
Hardware Solution优缺点
3.4 Operating Systems and Programming Language Solutions
互斥锁/互斥 Mutex Locks / Mutual exclusion
信号量 Semaphores
3.5 Mutex vs. Binary semaphore
3.6Classical Problems of Synchronization
The Bounded-Buffer / Producer-Consumer Problem有限缓冲问题
The Readers–Writers Problem
The Dining-Philosophers Problem
lec4 CPU进程调度
4.1 Basic Concepts
CPU–I/O Burst Cycle
Types of Processes
CPU scheduler
Scheduler & Dispatcher
4.2 Scheduling Criteria 调度标准
4.3 Scheduling Algorithms(Order of scheduling matters)
❑ First-Come, First-Served (FCFS) Scheduling非抢占
❑ Shortest-Job-First (SJF) Scheduling抢占
❑ Shortest Remaining Time First (SRTF) Scheduling 短剩余时间优先
❑ Priority Scheduling非抢占
❑ Round Robin(RR) Scheduling抢占
❑ Multiple-Level Queues Scheduling
❑ Multilevel Feedback Queue Scheduling
lec1 进程 process
1.1Characteristics of Operating Systems 操作系统的特点
1.2 操作系统概述(Operating System)
An operating system acts as an intermediary between a user and the computer hardware
操作系统主要有以下操作方式:
- 管理程序的开始与结束并在程序间共享 CPU Process Management
- 管理内存 Memory management
- 输入输出 I/O System Management
- 文件管理系统 File System Management
- 保护 Protection and Security
1.3 进程 (process)
- 进程process代表一个正在运行的程序 (A process is considered an 'active' entity)
- 程序program代表被存储在硬盘空间里的代码,是一个被动实体 (A program is considered to be a 'passive' entity (stored on disk (executable file)).)
- Program becomes process when executable file loaded into memory
进程的状态:
As a process executes, it changes state.
当进程执行时,会改变状态,状态象征着进程当前活动:
1. new:被创建
2. ready:已就绪,可以被执行
3. waiting:进程需要用户输入或其他进程运行结果而等待
4. running:指令正在被执行
5. terminated:被终止

PCB进程控制块 (Process Control Block)
本质上是数据结构-链表linked list,also called context of the process存储了一个进程的相关信息。所有进程的PCB都被包含在主存中。PID = Process identifier Unique number
进程对于多道(multiprogramming environment )有相当重要的作用。(PCB is important in multiprogramming environment as it captures the information pertaining to the number of processes running simultaneously)
单道批处理:单个程序进入计算机系统
多道:多个程序(进程)可同时进入处理机,磁带上的一批作业能自动的逐个运行
实时:要求高度可靠,响应度高,及时处理并交付任务
分时:各个进程分时间段依次占据处理机,交互性更好

进程调度概述(Process Scheduling)
进程调度既从某个地方选择进程,将其移到另一个地方。
一般维护以下进程:
- 作业队列Job queue:系统内所有进程的集合
- 就绪队列Ready queue:处于就绪状态的进程
- 设备队列Device queues:等待I/O设备输入输出的进程队列
三种调度类型:
- 长期调度(Long-Term Scheduler,Job Scheduler)也称作业调度,根据进程池中的所有进程进行规划并调度,选择一个或一批进程进入内存,作业完成后还需负责回收系统资源。 (controlling the Degree of Multiprogramming i.e. the total number of processes that are present in the ready state)
- 中期调度(Medium-term scheduler)将需要等待I/O的进程移出内存,存储于磁盘上,降低多道设计的程度,需要时再换回内存中-swapping(swapping of a process from the Main Memory to Secondary Memory and vice-versa (mid-term effect on the performance of the system))
- 短期调度 (Short-Term scheduler,CPU scheduler)选择一个就绪队列里的进程占据CPU运行,也是常说的调度 (selecting one process from the ready state for scheduling it on the running state.)
Context Switch 上下文切换:
当CPU内的进程发生切换(中断或系统调用)时,需要将被切换的进程的相关信息(临时变量,状态等)存储进PCB,同时,读取切进来的进程的相关信息,这个过程被称为上下文切换。save the state of the old process and load the saved state for the new process via a CONTEXT SWITCH Context of a process represented in the PCB
1.4 对进程的操作(Operations on Processes)
系统需要提供进程的创建creation和终止termination操作(mechanisms)。
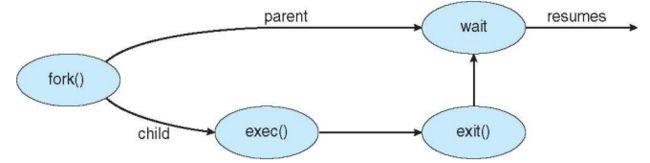
创建进程
进程可以被进程创建,例如,一个父母进程创建一个子进程。通过进程间的创建,可以形成一个进程树,进程树上的每个节点通过pid(process identifier)来唯一地被标识。(Parent process create children processes, which, in turn create other processes, forming a tree of processes)
父子进程的资源与执行的各个选项
资源策略 (Resource sharing options)
-
父母进程与子进程共享所有资源
-
共享部分资源
-
不共享资源
执行策略 (Execution options)
-
父母进程和子进程同时执行(concurrently)
-
子进程被终止后,父母进程执行(wait)
终止进程
进程执行最后一条语句,然后使用系统调用exit()让系统终止该进程。(Process executes last statement and then asks the operating system to delete it using the exit() system call. )
- Returns status data from child to parent
- Process’ resources are deallocated(被释放) by operating system
父级进程可以调用exit()终止子进程。(Parent may wait terminate the execution of children processes.)
- Child has exceeded(超过) allocated resource
1.5 进程间通信(Inter-process Communication)
- 独立进程(Independent Processes)
不与其他进程互相影响的进程。(neither affect other processes or be affected by other processes) - 合作进程(Cooperating Processes)
会被其他进程影响的进程
There are several reasons why cooperating processes are allowed:(优点)
- 资源共享information sharing:多个用户浏览(access)同一资源
- 计算加速computation speedup:并行计算提高速度problem变成多个sub-tasks to be solved simultaneously
- 模块化modularity:按照模块化方式构造系统(e.g. databases with a client-server architecture.)
- 便利性convenience:单个用户可能同时执行多个任务multi-tasking(such as editing, compiling, printing, and running the same code in different windows)
进程通信方式(Communications Models )
communication takes place by way of messages exchanged among the cooperating processes.
A message-passing facility provides at least two operations:
send(message)
receive(message)
The message size is either fixed or variable
分为两种方式:共享内存和消息传递
都使用一个叫缓冲区buffer的存储空间来存储消息:

共享内存(Shared-Memory)
processes can be able to exchange information by reading and writing all the data to the shared region
通过读写同一片缓冲区的信息去达到交换信息的目的
缓冲区:a region of memory is shared by cooperating processes
访问同片缓冲区代表着临界区问题
- 当缓冲区容量有限时(Bounded capacity):缓冲区的存储信息有上限
- 当缓冲区容量无限时(Unbounded capacity):缓冲区存放信息没有限制
消息传递(Message-Passing)
合作进程间通过消息发送与交换共享信息,
消息传递方法传递的消息存储在临时队列中(邮箱)exchanged messages by communicating processes reside in a temporary queue.
· 零容量(Zero capacity):has a maximum length of zero临时队列中不能有未被接受的消息(每一条消息都应被立即接受)
这种零容量的队列通常用于同步和通信的特殊情况。它强制发送者必须等待接收者立即处理消息,而不允许消息在队列中等待。这种情况下,发送者必须等待接收者准备好接收消息,然后直接将消息传递给接收者。因此,最大长度为零的队列无法在其中等待消息,消息必须立即被接收者处理,以保持队列为空。
· 有限容量(Bounded capacity):The queue has finite length n;临时队列有限,至多可以存储n条消息
· 无限容量(Unbounded capacity):The queue’s length is potentially infinite临时队列长度无限。
如果进程P和Q想要通信,则他们之间必须要有连结。这种连结可以是直接的,也可以是间接的
- 直接通信(direct communication):将消息直接发送给另外一个进程,在这之前接受者不知道聊天对象。直接通信是通过使用进程标识符来实现的。每个进程都被分配一个唯一的标识符,用于在通信过程中进行识别和定位。(Direct Communication is implemented when the processes use specific process identifier for the communication, but it is hard to identify the sender ahead of time这可能需要在通信过程中进行额外的识别和确认操作,以确定消息的实际发送者。)
- 间接通信(indirect communication):设置临时队列(temporary queue),合作进程将消息发送给临时队列,又能够从临时队列收取消息。(create a new mailbox (port) send and receive messages through mailbox)因为是临时的所以最后会destroy。
消息传递可以是同步的,也可以是异步的
- 同步(Synchronous):又被称为阻塞(blocking)
Blocking send: 当消息被发送,发送者会被阻塞进入waiting状态,直到接收者接受消息。
Blocking receive: 接收者会被阻塞,直到接收新消息 - 异步(Asynchronous):又被称为非阻塞(non-blocking)
Non-blocking send: 发送者可以发送消息然后继续运行
Non-blocking receive: 接收者可以在任意时刻接受消息, 消息可能有效可能为空
lec2 线程
2.1 线程的简要概述(thread)
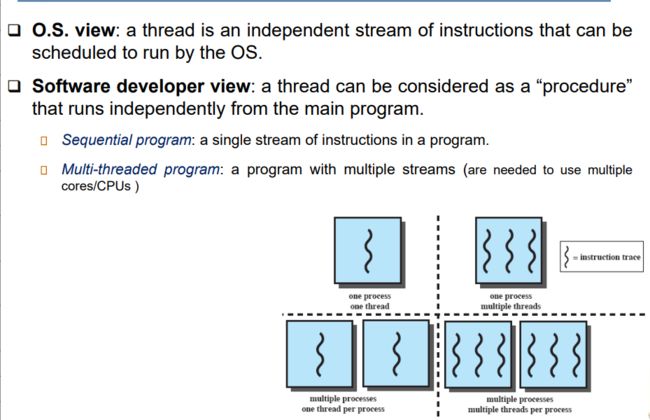
A thread is the smallest unit of processing that can be performed in an OS.
Thread is a fundamental unit of CPU utilization that forms the basis of multithreaded computer systems
- 线程是计算机操作系统执行的基本单元,也是CPU使用的基本单元。
-
在一个进程中可以有多个线程同时执行,每个线程都有自己的执行路径和执行状态。
线程是操作系统进行调度和执行的基本单位
- 线程也可以看成是简化的进程;
- 属于同一个进程的线程之间可以共享代码,数据,文件;
- 线程能够帮助程序“同时”执行多个任务。(Multiple tasks with the application can be implemented by separate threads)
一个线程主要包含:
线程ID,程序指针,寄存器集,栈。

TCB

分享shares示例如上上图
Thread Control Block (TCB) 是线程控制块,它包含了操作系统用来管理和跟踪线程的信息。下面是一些常见的TCB包含的内容:
-
执行状态 (Execution State): TCB中存储了线程的执行状态,包括CPU寄存器的值、程序计数器 (program counter) 的值以及指向线程堆栈 (stack) 的指针。这些信息用于保存线程的上下文,使得线程可以在被切换出去后能够恢复到之前的执行状态。
-
调度信息 (Scheduling info): TCB中包含了线程的调度信息,例如线程的状态 (state),优先级 (priority),以及已使用的CPU时间等。这些信息用于操作系统的调度器决定在何时执行该线程,并进行适当的调度。
-
指针 (Pointers): TCB中可能包含了指向其他数据结构或队列的指针,用于实现调度队列或其他数据结构。例如,可能包含指向所属进程的进程控制块 (PCB) 的指针,以及指向其他线程控制块的指针,以便于线程的管理和调度。
操作系统会将TCBs存储在受保护的内存区域中,通常以数组或链表的形式组织。数组可以提供快速的访问和索引,而链表可以支持动态的插入和删除操作。通过维护TCB的集合,操作系统能够有效地管理和跟踪所有的线程,进行线程的调度、切换和资源分配等操作。
2.2 线程的优点(Benefits of Threads)
1.Responsiveness (响应性)
- Allows a program continue running if part of it is blocked or its is performing a lengthy operation多线程?的一个好处是提供更好的响应性。当程序的某个部分被阻塞或正在执行长时间操作时,其他线程仍然可以继续运行。这意味着程序可以更快地响应用户的输入或其他事件,提供更好的用户体验。
2.Resource Sharing and Economy (资源共享和经济性)
- Threads share an address space, files, code, and data 可以共享地址空间、文件、代码和数据。
- Avoid resource consumption 访问和操作相同的资源,而不需要进行复制或额外的资源分配。这样可以避免资源的浪费
- Perform much a faster context switch 线程间切换的开销较小,线程间的切换速度比进程间的切换要快,从而提高了系统的经济性。
3.Utilization of multiprocessor MP Architectures (多处理器架构的利用)
- Place code, files and data in the main memory.
- Distribute threads to each of CPUs, and
- Let them execute in parallel
4.Deadlock avoidance (死锁避免)
死锁是指两个或多个线程因为彼此相互等待对方释放资源而无法继续执行的情况。多线程环境下,如果不正确地管理和同步线程对共享资源的访问,可能会导致死锁的发生。通过合理的线程设计和正确的同步机制,可以避免死锁的发生,确保线程能够顺利执行。
2.3线程状态(Thread states)
- 未创建的线程处于undefined状态;
- 当线程就绪时,处于ready状态;
- 同一时刻只能有一个线程处于running状态
- 当线程被中断运行(suspend),处于suspended状态,随后可调用resume()回归就绪状态
- 处于中断terminated状态的进程会被释放,随后处于销毁destroyed状态

2.3 单线程进程和多线程进程(Single and Multithreaded Processes)
传统讲的单线程进程,任务被分配给了一个进程,其内只有一个线程,发生错误这个任务就挂掉了。
多线程进程,进程其内变成了多个线程,任务被分配给了许多线程,如果一个线程挂了对其他线程没影响,it can perform more than one task at time.
The stack pointer (SP) points to the top of the stack, which stores data
The program counter (PC), indicating the next instruction
2.4并发和并行(Concurrency vs. Parallelism)
Multicore Programming
单核系统并发处理任务,进程一个一个开始,中间互相穿插运行,直到结束完成。(一会吃饭一会看手机)
多核系统并行处理任务能够同时处理多个任务(一边吃饭一边看手机)

2.5 多线程模型 (Multithreading Models)
内核模式(Kernel Mode)
在该模式下执行的代码具有对底层硬件的完全和无限制的访问权限。(executing code has complete and unrestricted access to the underlying hardware.)
- 它可以执行任何CPU指令并访问任何内存地址。(It can execute any CPU instruction and reference any memory address.)
- 内核模式通常用于操作系统的最底层、最可信任的功能。(Kernel mode is generally reserved for the lowest-level, most trusted functions of the operating system)
- 内核模式下的崩溃是灾难性的,会导致整个计算机停止运行。(Crashes in kernel mode are catastrophic; they will halt the entire PC.)
用户模式(User Mode)
在该模式下执行的代码无法直接访问硬件或引用内存。(executing code has no ability to directly access hardware or reference memory)
- 在用户模式下运行的代码必须通过系统的应用程序接口(API)来访问硬件或内存。(Code running in user mode must delegate to system APIs (Application Programming Interface) to access hardware or memory.)
- 用户模式下的崩溃通常是可恢复的。(Crashes in user mode are always recoverable)
- 计算机上运行的大部分代码将在用户模式下执行。(Most of the code running on your computer will execute in user mode)
处理器根据运行在处理器上的代码类型而在两种模式之间切换。 应用程序在用户模式下运行,而核心操作系统组件在内核模式下运行。 虽然许多驱动程序在内核模式下运行,但有些驱动程序可能在用户模式下运行。
The processor switches between the two modes depending on what type of code is running on the processor. Applications run in user mode, and core operating system components run in kernel mode. While many drivers run in kernel mode, some drivers may run in user mode.
用户线程(User Threads)是由用户实现的执行单元,内核并不知道这些线程的存在。用户线程的管理由用户级线程库进行。 主要有三个主要的线程库:(is the unit of execution that is implemented by users and the kernel is not aware of the existence of these threads. Management done by user-level threads library)
- POSIX Pthreads
- Windows 线程
- Java 线程
- 在像 C#、Python 等编程语言中的线程编程中也有线程库的支持。
内核线程(Kernel Threads)由操作系统直接处理,线程管理由内核进行。(are handled by the operating system directly and the thread management is done by the kernel.)
例如,几乎所有通用操作系统都使用内核线程,包括:
- Windows
- Linux
- Mac OS X
- iOS
- Android
Difference between ULT & KLT
- 用户线程是在用户空间中管理和调度的,而内核线程是在内核空间中管理和调度的。用户线程的管理由用户级线程库负责,而内核线程的管理由操作系统内核负责。
- 用户线程的创建、销毁和切换开销相对较小,因为它们不涉及内核的介入。而内核线程的创建、销毁和切换涉及系统调用和内核开销。
- 用户线程之间的通信和同步需要通过用户级线程库提供的机制来实现,而内核线程可以直接使用操作系统提供的进程间通信(IPC)机制。
- 用户线程的阻塞或等待操作可能会导致整个进程的阻塞,而内核线程的阻塞只会影响该线程本身。

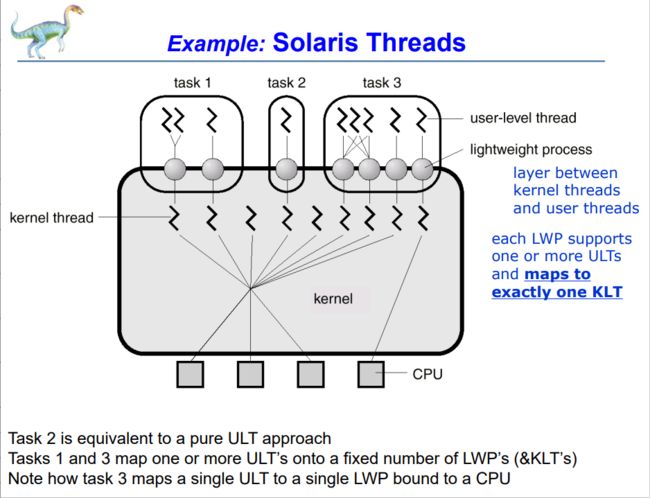
在将用户级线程映射到内核级线程的组合系统中,同一应用程序中的多个线程可以在多个处理器上并行运行。多线程模型有三种类型:
1. Many-to-One Model (Many user-level threads are mapped to a single kernel thread)
- 这意味着同一进程中的多个用户级线程在任意时刻只能有一个被执行,因为与该进程关联的只有一个内核级线程。(The process can only run one user-level thread at a time because there is only one kernel-level thread associated with the process.)
- 线程管理是在用户空间中通过线程库来实现的。用户级线程库负责用户级线程的创建、销毁和调度,以及线程之间的切换。线程库维护一个线程控制块(Thread Control Block,TCB)来存储线程的执行状态、调度信息和其他必要的数据。(Thread management done at user space, by a thread library)
由于只有一个内核级线程,多对一的多线程模型无法实现真正的并行性,因为同一进程中的多个用户级线程不能同时在不同的处理器上执行。然而,该模型的优点是实现简单,线程的创建、销毁和切换开销较小,因为它们在用户空间内完成,无需涉及内核的介入。
这种多线程模型通常适用于对并行性要求不高的应用程序,或者在系统资源有限的情况下,通过使用用户级线程来实现轻量级的并发编程。
Examples: ▪ Solaris Green Threads ▪ GNU Portable Threads
2. One-to-One Model(Each user thread mapped to one kernel thread)
- 在这种模型中,操作系统的内核实现了线程管理和调度。内核负责创建、销毁和调度内核级线程,并决定何时将处理器的控制权从一个线程切换到另一个线程。(Kernel may implement threading and can manage threads, schedule threads.)
- 一对一模型可以实现真正的并行性。当一个用户级线程被阻塞时,由于存在多个内核级线程,其他用户级线程仍然可以在不同的处理器上执行,从而提供更高的并发性。(Provides more concurrency; when a thread blocks, another can run.)
- Kernel is aware of threads
Examples: 一对一模型的一些示例包括Windows NT/XP/2000、Linux和Solaris 9及更高版本。这些操作系统通过实现内核级线程来支持多线程编程,使得用户可以同时运行多个线程,并充分利用多处理器系统的性能。
3. Many-to-Many Model(Allows many user level threads to be mapped to many kernel threads)
- 操作系统可以创建足够数量的内核级线程来支持用户级线程的并发执行。(Allows the operating system to create a sufficient number of kernel threads)
- 多对多模型可以根据特定的应用程序或特定的计算机配置,为其分配适当数量的内核级线程。(Number of kernel threads may be specific to an either a particular application or a particular machine.)
- 用户可以创建任意数量的线程,并且相应的内核级线程可以在多处理器系统上并行执行。(The user can create any number of threads and corresponding kernel level threads can run in parallel on multiprocessor.)
在多对多模型中,内核级线程和用户级线程之间存在一种灵活的映射关系,允许更高的线程并发性和并行性。用户级线程的创建和管理由用户级线程库负责,而内核级线程的创建和调度由操作系统内核负责。
Examples:
- Solaris 9之前的版本使用多对多模型。
- Windows NT/2000中的ThreadFiber软件包支持多对多模型。
- Solaris 9之前的旧版本使用两级关系多线程模型。
2.6 线程库(Thread Libraries)
是个Application Programming Interface (API)接口,程序员可以用它在应用里创建和管理线程。
线程库可以在用户空间或内核空间中实现(Threads may be implemented in user space or kernel space.)
- 在纯粹的用户空间线程库中,所有库的代码和数据结构都存在于用户空间中。调用库中的函数将导致在用户空间中进行本地函数调用,而不是系统调用。(▪ all code and data structures for the library exist in user space. ▪ invoking a function in the library results in a local function call in user space and not a system call.)
- 而在内核级线程库中,库的代码和数据结构存在于内核空间中。调用库中的API函数通常会导致对内核的系统调用。(▪ code and data structures for the library exist in kernel space. ▪ invoking a function in the API for the library typically results in a system call to the kernel.)
Three primary thread libraries: POSIX threads, Java threads, Win32 threads
2.7 Managing threads
- Explicit threading - the programmer creates and manages threads.
- Implicit threading - the compilers and run-time libraries create and manage threads.
用于设计多线程程序的三种替代方法的概述:
-
线程池:线程池是一种技术,程序在启动时创建一定数量的线程,并将它们放入一个池中。这些线程处于空闲状态,等待任务的到来。(Thread pool - create a number of threads at process startup and place them into a pool, where they sit and wait for work.)
-
OpenMP:OpenMP是一组用于C、C++和Fortran程序的编译指令,它指示编译器在适当的情况下自动生成并行代码。(OpenMP is a set of compiler directives available for C, C++, and Fortran programs that instruct the compiler to automatically generate parallel code where appropriate)
-
Grand Central Dispatch (GCD):GCD是苹果公司的MacOS X和iOS操作系统上的扩展,用于支持并行计算。它是一种基于C和C++的技术,可以帮助开发者利用系统资源实现并发执行和并行计算。(Grand Central Dispatch (GCD) - is an extension to C and C++ available on Apple’s MacOS X and iOS operating systems to support parallelism)
2.8 Threading Issues in Multithreading environments
1. fork() and exec() System Calls
a)fork()系统调用会创建一个新的进程作为父进程的副本。问题在于,这个新创建的进程是否会复制父进程的所有线程,或者只会变成单线程的副本。
实际上,fork()会将父进程中的所有线程复制到子进程中,包括调用fork()的线程和其他所有线程。这意味着子进程将与父进程具有相同数量和状态的线程。
b)而exec()系统调用,当被调用时会将指定的程序替换掉当前进程的程序,并且同时替换掉所有线程。换句话说,exec()会将整个进程(包括所有线程)替换为指定的程序。这意味着原来的线程将被终止,而新的程序将以单线程的形式开始执行。
总结起来,fork()会复制所有线程到子进程中,而exec()会用新的程序替换掉当前进程的所有线程。
2. Signal Handling
如果线程从不进行任何输入/输出操作,从不等待,也不释放控制权,会发生什么情况?
答案是利用外部事件。
- 中断:来自硬件或软件的信号,会停止正在运行的代码并跳转到内核。
- 计时器:类似于每隔(一定)毫秒触发的闹钟。

信号将如何传递给线程将由以下选项决定:
异步信号是从接收信号的进程外部产生的信号。
同步信号则是传递给引起信号发生的同一进程。
- 将信号传递给适用于该信号的线程。
- 将信号传递给进程中的每个线程。
- 将信号传递给进程中的特定线程。
- 指定一个特定的线程来接收进程中的所有信号。

3. Thread Cancellation
两种一般的取消线程的方法:
异步取消(Asynchronous cancellation)会立即终止目标线程。
- 如果要取消的线程正在更新共享数据,这可能会带来麻烦。
延迟取消(Deferred cancellation)允许目标线程定期检查是否应该被取消。
与目标线程相关的问题如下:
- 如果资源已分配给要取消的目标线程,会怎么样?
- 如果目标线程在更新与其他线程共享的数据时被终止,会怎么样?
-
如果资源已分配给要取消的目标线程:
- 在异步取消的情况下,如果目标线程被立即终止,那么它可能无法释放已经分配的资源,这可能导致资源泄漏或其他问题。
- 在延迟取消的情况下,目标线程可以定期检查取消请求,并在适当的时候释放已分配的资源,从而避免资源泄漏问题。
-
如果目标线程在更新与其他线程共享的数据时被终止:
- 在异步取消的情况下,如果目标线程被立即终止,它可能会导致共享数据的不一致性或损坏。
- 在延迟取消的情况下,目标线程可以在合适的检查点进行数据更新,并在检查取消请求时进行适当的处理,以确保共享数据的一致性。

lec3 进程同步(Process Synchronization)
3.1 Background
PS(进程同步)是协调进程执行的任务,以确保在任何时间点上,没有两个进程可以同时访问同一共享数据和资源。(PS is the task of coordinating the execution of processes in a way that no two processes can have access to the same shared data and resources.
当有n个进程都竞争使用某个共享资源时,同时访问共享数据可能导致数据不一致性(data inconsistency.)。
为了保持数据一致性,需要使用机制来确保协作进程的有序执行。(Maintaining data consistency requires mechanisms to ensure the orderly execution of cooperating processes.)
竞争条件(Race condition)
当多个进程同时访问和操作统一数据,数据的结果因代码执行顺序而异,导致数据的不一致。
为了防止竞争,必须同步并发的进程。(To prevent race conditions, concurrent processes must be synchronized)
3.2 The Critical Section Problem
关键段(Critical Sections)是一段代码序列,不能在多个线程或进程之间交错执行。(Critical Sections are sequences of code that cannot be interleaved among multiple threads/processes)
每个并发的线程或进程都有一个代码段,称为关键段(Critical Section),用于访问共享数据。
使用关键段时,代码可以分为以下几个部分:
-
进入区(Entry Section):在进入关键段之前执行的代码段。它通常用于获取访问关键段的权限,比如获取互斥锁。
-
关键段(Critical Section):包含对共享数据进行读取、修改或其他操作的代码段。在关键段中,必须保证只有一个线程或进程能够访问共享数据,以避免数据不一致性和竞争条件的发生。
-
退出区(Exit Section):在离开关键段之后执行的代码段。它通常用于释放对关键段的访问权限,比如释放互斥锁。
-
剩余区(Remainder Section):在关键段之后执行的代码段。它用于执行与共享数据无关的其他操作。
通过将代码分解为以上不同的部分,并使用适当的同步机制(如互斥锁、信号量等),可以确保在关键段中只有一个线程或进程能够访问共享数据,从而避免数据竞争和不一致性。
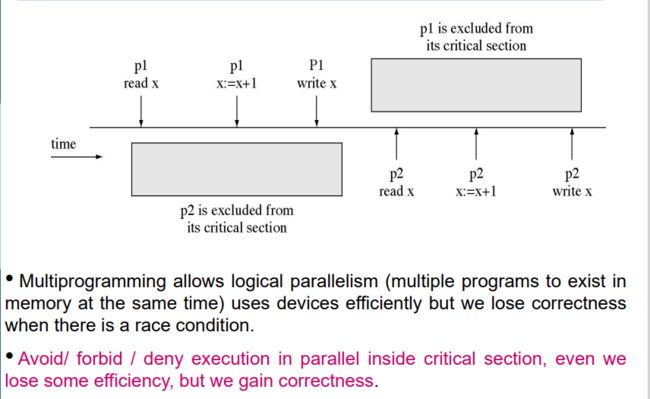
多程序设计(Multiprogramming)允许逻辑并行性(多个程序同时存在于内存中),可以高效地利用设备资源,但当存在竞争条件时,会导致程序的正确性受到损害。
为了确保程序的正确性,我们需要避免、禁止或拒绝在关键段内部进行并行执行,即同一时间只允许一个线程或进程进入关键段执行操作,即使这样可能会损失一些效率。
通过限制并发执行的访问,我们可以消除竞争条件和数据不一致性的问题,保证程序的正确性。虽然这可能会牺牲一些执行效率,但是我们通过确保关键段的互斥访问,获得了正确的结果和可靠的程序行为。
解决关键段问题的方法需要满足以下三个要求or原则:
-
互斥性(Mutual Exclusion):在任意给定的时刻,只允许一个进程进入临界区(Critical Section)执行,其他进程必须等待。通过互斥访问共享资源,确保同一时刻只有一个进程可以操作该资源,避免数据的不一致性。(When a process/thread is executing in its critical section, no other process/threads can be executing in their critical sections)
-
进展性(Progress):如果没有进程进入临界区且有其他进程请求进入临界区,则必须选择一个进程进入。也就是说,当没有进程在临界区时,不能因为其他进程的请求一直阻塞进程,保证进程的执行不会被无限期地延迟。(If no process/thread is executing in its critical section, and if there are some processes/threads that wish to enter their critical sections, then one of these processes/threads will get into the critical section. No process running outside its critical region may block any process)
-
有界等待(Bounded Waiting):对于任意一个进程,其等待进入临界区的时间有上限,即进程不能无限期地等待资源的分配。这个要求保证了所有进程都有机会进入临界区,避免出现某个进程饥饿的情况。(No process/thread should have to wait forever to enter into the critical section.)
通过满足这三个要求,可以设计出一种正确且公平的解决方案,以确保并发进程在使用共享资源时不会产生冲突,并且能够保证进程的执行顺序和资源的分配是合理的。
基于原则解决关键段问题的方法可以分为以下几类:
-
软件解决方案Software solutions:基于算法的解决方案,其正确性仅依赖于一次只有一个进程/线程可以访问内存位置或资源的假设。通过在代码中使用特定的同步机制和算法,如互斥锁、信号量、条件变量等,来保证临界区的互斥访问和同步。(algorithms whose correctness relies only on the assumption that only one process/thread at a time can access a memory location/resource)
-
硬件解决方案Hardware solutions:依赖特殊的机器指令来实现锁定操作。硬件层面可以提供原子操作和特殊的锁机制,如原子指令、比较交换指令等,用于实现互斥和同步操作。这些机制通常由处理器或硬件支持,并提供高效的并发控制。(rely on special machine instructions for “locking)
-
操作系统和编程语言解决方案Operating System and Programming Language solutions (e.g., Java):操作系统和编程语言提供了特定的函数和数据结构,供程序员使用来实现并发控制和同步。例如,操作系统提供了进程间通信(IPC)机制,如管道、共享内存、消息队列等,用于进程之间的通信和同步。编程语言也提供了各种同步机制和库函数,如线程同步原语、并发数据结构等,用于实现多线程编程中的同步和互斥访问。(provide specific functions and data structures for programmers to use for synchronization)
通过这些软件、硬件和操作系统/编程语言的解决方案,可以提供一系列的工具和机制,用于管理并发访问共享资源的互斥和同步,确保多个进程/线程可以正确、有序地访问和操作共享资源,避免数据竞争和冲突的发生。
3.3 Software solutions (Peterson’s Solution)
Peterson算法是用于实现互斥访问的解决方案,允许两个或多个进程在共享内存的情况下共享一个单一资源而不发生冲突。(is used for mutual exclusion that allows two or more processes to share a single-use resource without conflict, using only shared memory for communication)
Peterson算法针对只有两个进程(P0和P1)的情况进行设计。其核心问题是设计进入和退出临界区的过程。进程之间可能会共享一些变量来同步它们的操作。
Peterson算法由Gary L. Peterson于1981年提出。它使用了两个关键的共享变量:turn和flag[2]。进程通过使用这些变量来协调彼此的访问,以确保互斥访问、有界等待和进展。
当进程希望进入临界区时,它会将自己的标志位设置为true,并将turn变量设置为对方的进程编号。然后,进程会检查对方的标志位和turn变量的值,以确定是否能够进入临界区。如果对方的标志位为true且轮到对方进程执行(turn变量的值为对方的进程编号),则当前进程需要等待。只有当对方的标志位为false或轮到当前进程执行时,当前进程才能进入临界区执行,并在退出临界区后将自己的标志位设置为false,表示临界区不再被占用。
通过这种方式,Peterson算法实现了两个进程之间的互斥访问,确保同一时间只有一个进程能够进入临界区,避免了数据竞争和冲突的发生。此外,该算法还满足有界等待和进展的要求,确保进程能够按照一定规则进行访问和执行。

3.4 Hardware Solutions
由硬件支持的同步,都是关于锁的,锁住gets a LOCK on required resources
单处理器环境 Single-processor environment

初始时:锁的值设置为0
当锁的值为0时,表示临界区目前为空闲状态,没有进程在其中。
当锁的值为1时,表示临界区目前被占用,有进程在其中。
满足互斥性要求,但不保证有界等待
多处理器环境 Multi-processor environment

在多处理器环境中,提供了特殊的原子硬件指令。原子意味着不可中断(即,该指令作为一个单元执行)。 全局变量lock被初始化为0。 只有找到lock=0的Pi才能进入临界区。 通过将lock设置为1,该Pi排斥所有其他Pj。
Hardware Solution优缺点

硬件解决方案的优点:
- 适用于任意数量的进程,无论是在单处理器还是多处理器共享主内存的环境下。
- 简单易验证。
- 可以用于支持多个临界区;每个临界区可以由自己的变量定义。
硬件解决方案的缺点:
- 忙等待是指一个进程在等待访问临界区时,它继续消耗处理器时间。
- 可能出现饥饿现象,即一个进程执行其临界区时,有多个进程等待很长时间。
- 死锁是一组进程永久地被阻塞,等待另一个被该组中的其他阻塞进程触发的事件(即临界区的释放)。
3.4 Operating Systems and Programming Language Solutions
互斥锁/互斥 Mutex Locks / Mutual exclusion
基于软件,允许多个程序线程不同时地访问同个资源。
· 核层面实现互斥时,会发生中断,导致上下文切换。为了减小中断可能对数据造成的损害,尽可能做完原语再中断,原语既完成一个数据操作的最小代码。
· 软件层面互斥,进程处于运行状态,需要忙等或产生自旋锁busy-wait mechanism or spinlock,既一直在循环检查是否被允许。
进程在进入前需要申请锁,退出临界区需要释放锁。
互斥锁(Mutex Lock)是一种编程标志,用于获取和释放对象。 当开始进行数据处理时,如果该数据在系统中的其他地方不能同时进行处理,那么互斥锁被设置为锁定状态,阻止其他尝试使用它的操作。 当数据不再需要或程序执行完成时,互斥锁被设置为解锁状态。
在内核级别强制执行互斥锁以防止共享数据结构的破坏时,禁用中断以执行最少数量的指令是最好的方式。
在软件领域强制执行互斥锁时,使用忙等待机制(busy-waiting mechanism)。 忙等待机制是一种机制,进程在一个无限循环中执行,等待一个锁变量的值指示资源的可用性。
互斥锁的使用目的是在进入临界区之前获取锁,并在退出时释放锁。 互斥锁对象由请求资源或释放资源的进程进行锁定或解锁。(Mutex object is locked or unlocked by the process requesting or releasing the resource)

这种类型的互斥锁被称为自旋锁(Spinlock),因为进程在等待锁变为可用时会"自旋"(即在一个循环中不断尝试获取锁)。
信号量 Semaphores

信号量是由Dijkstra于1965年提出的一种技术,用于管理并发进程。它是一个简单的非负整数值,可在线程/进程之间共享。
信号量具有三个原子操作:初始化、减少和增加。
- 减少操作可能导致进程的阻塞。
- 增加操作可能导致进程的解除阻塞。
当一个进程需要访问共享资源时,它会尝试减少信号量的值。如果信号量的值为正,表示资源可用,进程可以继续执行。如果信号量的值为零,表示资源已被占用,进程将被阻塞,直到资源可用。当一个进程不再需要访问共享资源时,它会增加信号量的值,以通知其他等待该资源的进程。这样,信号量提供了一种有效的方式来协调并发进程的执行,确保资源的正确使用和避免竞态条件的发生。

- wait()
信号量小于等于0就忙等,大于0就减一,代表申请到了锁。 - signal()
信号量加1,代表锁被释放
To allow k processes into CS at a time, simply initialize mutex to k
两种信号量
· 计数信号量 COUNTING SEMAPHORE允许任意资源计数可以限制同时访问某个资源的进程/线程的数量。(allow an arbitrary resource count. Its value can range over an unrestricted domain. It is used to control access to a resource that has multiple instances.)

信号量S被初始化为可用资源的数量。
每个使用资源的进程都会在信号量上执行一个等待(WAIT)操作(从而将可用资源的数量减少)。
当一个进程释放一个资源时,它执行一个信号(SIGNAL)操作(增加可用资源的数量)。
当信号量的计数值变为0时,表示所有资源都正在被使用。此后,希望使用资源的进程将被阻塞,直到计数值变为大于0为止。
· 二进制信号量 BINARY SEMAPHORE类似于互斥锁(Mutex Lock)。它只能有两个值:0和1。初始时,二进制信号量的值被设置为1。它确保只有一个进程能够进入临界区,从而实现互斥访问共享资源的目的。(– similar to mutex lock. It can have only two values: 0 and 1. Its value is initialized to 1. It is used to implement the solution of critical section problem with multiple processes)

二进制信号量可以被初始化为1。 等待(WAIT)操作(递减)会检查信号量的值。
- 如果值为0,则执行等待操作的进程被阻塞。
- 如果值为1,则将值改为0,进程继续执行。 信号(SIGNAL)操作(递增)会检查是否有进程被阻塞在该信号量上(信号量的值为0)。
- 如果有被信号操作阻塞的进程,则该进程被解除阻塞。
- 如果没有进程被阻塞,则将信号量的值设置为1。
3.5 Mutex vs. Binary semaphore
A key difference between the a mutex and a binary semaphore is that the process that locks the mutex (sets the value to zero) must be the one to unlock it (sets the value to 1). In contrast, it is possible for one process to lock a binary semaphore and for another to unlock it.
简而言之,互斥锁要求锁定和解锁操作由同一个进程执行,确保了独占性;而二进制信号量允许不同进程进行锁定和解锁操作,实现了多个进程之间的协作和资源的灵活共享。
Same issues of semaphore
Starvation - when the processes that require a resource are delayed for a long time. Process with high priorities continuously uses the resources preventing low priority process to acquire the resources.(是指需要某个资源的进程被长时间延迟。具有高优先级的进程持续使用资源,从而阻止低优先级进程获取资源)
Deadlock is a condition where no process proceeds for execution, and each waits for resources that have been acquired by the other processes(是一种状态,其中没有进程继续执行,每个进程都在等待被其他进程占用的资源。)
因此,饥饿和死锁都是进程调度和资源分配的问题。饥饿是指进程长时间等待资源,而死锁是指多个进程之间循环等待彼此持有的资源,导致系统无法继续执行。
3.6Classical Problems of Synchronization
The Bounded-Buffer / Producer-Consumer Problem有限缓冲问题

在该问题中,使用了互斥的二进制信号量(mutex binary semaphore)来实现对缓冲池的互斥访问,初始值设置为1。
另外,还使用了两个计数型信号量:empty(空缓冲区数量)和full(满缓冲区数量)。
- 信号量empty的初始值设置为n,表示有n个空缓冲区可以供生产者进程使用。
- 信号量full的初始值设置为0,表示初始时没有满缓冲区可供消费者进程使用。
生产者进程在生产数据时,会先申请空缓冲区(通过对empty信号量执行wait操作),然后将数据放入缓冲区,最后释放满缓冲区(通过对full信号量执行signal操作)。
消费者进程在消费数据时,会先申请满缓冲区(通过对full信号量执行wait操作),然后从缓冲区取出数据,最后释放空缓冲区(通过对empty信号量执行signal操作)。
通过使用信号量来控制生产者和消费者进程的访问,可以保证生产者和消费者之间的同步,以及缓冲区的正确使用。
The Readers–Writers Problem

这个问题涉及一个数据集被多个并发进程共享的情况。
- 在同一时间内,只允许一个写操作者访问共享数据,其他写操作者和读操作者必须被阻塞。
- 允许多个读操作者同时读取数据,但是写操作者必须被阻塞。
解决方案是使用读写锁(reader-writer lock)。读写锁允许进程以读模式或写模式获取锁:
- 以读模式获取锁的进程可以并发地读取共享数据,不会相互阻塞。
- 以写模式获取锁的进程可以独占地写入共享数据,其他读操作者和写操作者必须被阻塞,直到写操作完成并释放锁。
通过使用读写锁,可以在保证数据一致性的同时,允许多个读操作并发进行,提高系统的并发性能。
The Dining-Philosophers Problem

5个人坐一圈,人与人之间放一只筷子,人要么思考要么吃饭。吃饭前需要依次拿起左手与右手的筷子,思考时放下筷子。
死锁问题:所有人都在思考,然后同一时刻吃饭,所有人拿起左手的筷子后都在请求右手的筷子,产生死锁。解决方案:
- 最多允许四个人坐下
- 一次只允许一个左右手都有筷子的哲学家拿起两只筷子。
- 奇数位置的人先拿左手,再拿右手;偶数位置的人先拿右手,再拿左手。
lec4 CPU进程调度
4.1 Basic Concepts
CPU–I/O Burst Cycle

简而言之,进程执行包含了CPU执行和I/O等待的交替过程。不同类型的程序(I/O密集型或CPU密集型)在CPU执行阶段的长度上可能会有所区别。这些信息可以用于选择合适的CPU调度算法,以最大程度地提高系统性能和吞吐量。对于I/O密集型程序,可能更适合选择一种能够充分利用CPU空闲时间的调度算法,以尽可能减少I/O等待时间。而对于CPU密集型程序,可能更适合选择一种能够公平分配CPU时间片的调度算法,以避免某些进程长时间占用CPU资源而导致其他进程无法执行的情况发生。
Types of Processes

I/O密集型程序主要涉及与外部设备的交互,如文件读写、网络通信等,其CPU活动相对较短,大部分时间都在等待I/O操作完成。这些程序对用户的交互响应较为敏感,因此希望它们具有较高的优先级,以确保及时响应用户的操作。
CPU密集型程序主要进行大量的计算和数据处理,其主要活动集中在CPU的执行阶段,相对较少涉及I/O操作。这些程序对长时间的CPU执行阶段更为有利,因为它们需要充分利用CPU资源来完成复杂的计算任务。由于这些程序对I/O操作的需求较低,因此可以降低它们的优先级,以避免占用过多的系统资源,从而保证其他任务的正常执行。
- 交互式进程:需要与用户进行实时交互,响应时间较短的进程。
- 非交互式进程:不需要与用户进行实时交互的进程,可以在后台执行。
- CPU密集型进程:需要大量的CPU资源来执行计算密集型任务的进程。
- I/O密集型进程:需要大量的I/O操作来执行任务的进程,对CPU的需求相对较低。
- 前台进程:对用户非常重要,需要优先执行的进程,通常是交互式进程。
- 后台进程:对用户相对不太重要的进程,可以在后台执行,通常是非交互式进程。
CPU scheduler
The CPU scheduler is the mechanism to select which process has to be executed next and allocates the CPU to that process. Schedulers are responsible for transferring a process from one state to the other(CPU调度器是选择下一个要执行的进程并分配CPU资源给该进程的机制。调度器负责将进程从一种状态转换到另一种状态。)有三种调度器如前面学的几种调度。

❑ 长期调度器:负责从就绪队列中选择合适的进程,将其调度到内存中,并决定是否将其加入到可执行队列中。它决定了哪些进程可以进入系统,并控制系统的进程数量。
❑ 短期调度器:也称为CPU调度器,负责从就绪队列中选择一个进程,将其分配给CPU执行。它根据调度算法选择合适的进程,并决定进程的执行顺序,以最大程度地提高系统的吞吐量和响应时间。
❑ 中期调度器:负责在内存和磁盘之间进行进程的调度和交换。当系统内存紧张时,中期调度器可以将部分进程调出内存并放入磁盘上的交换区,以释放内存空间供其他进程使用。当这些进程再次需要执行时,中期调度器可以将它们调入内存,使其继续执行。
Scheduler & Dispatcher
- Schedulers are special system software that handles process scheduling in various ways.
- Dispatcher(分派器), module of the operating system, removes process from the ready queue and sends it to the CPU to complete
1.CPU Scheduling Policies

抢占式调度(PREEMPTIVE SCHEDULING)是指系统可以中断正在运行的进程,并进行上下文切换,将处理器分配给另一个进程。被中断的进程将被放回就绪队列中,并根据调度策略在未来的某个时间点进行调度。抢占式调度允许系统在运行的进程还没有完成时,暂停它的执行,并将处理器分配给其他进程。the CPU is allocated to the processes for a specific time period
非抢占式调度(NON-PREEMPTIVE SCHEDULING)是指当一个进程被分配到处理器上时,它可以一直执行到完成,即系统不能夺取该进程的处理器直到它退出。任何进入就绪队列的其他进程必须等待当前进程完成其CPU周期后才能执行。the CPU is allocated to the process until it terminates. the running process keeps the CPU until it voluntarily gives up the CPU
在非抢占式调度中,进程具有独占性,一旦获得处理器,它将一直运行直到结束,不会被系统中断。而在抢占式调度中,系统具有中断正在运行的进程的能力,可以根据优先级或时间片等策略决定何时中断进程并切换到其他进程。

2.Dispatcher

调度程序(Dispatcher)模块将CPU的控制权交给短期调度器所选的进程,这涉及以下操作:
- 切换上下文(Context Switching):保存当前运行进程的上下文信息,并加载新进程的上下文信息。
- 切换到用户模式(User Mode):将处理器从内核模式切换到用户模式,以便新进程可以执行用户程序。
- 跳转到用户程序中适当的位置以重新启动该程序:将处理器的指令流引导到新进程的指定位置,使其从该位置开始执行。
调度延迟(Dispatch Latency)是指调度程序停止一个进程并启动另一个进程所需的时间。调度延迟应尽可能地短,以确保进程切换的快速响应。
调度程序在每次进程切换时被调用,因此它应该尽可能地快速。调度程序的目标是尽快将CPU分配给新的进程,以最大限度地提高系统的处理能力和资源利用率。
4.2 Scheduling Criteria 调度标准

最大CPU利用率(Max CPU Utilization):尽量让CPU保持繁忙状态,以最大限度地利用CPU资源,使其始终处于高负载状态。
最大吞吐量(Max Throughput):在单位时间内完成尽可能多的进程,以提高系统的处理能力和工作效率。
公平性(Fairness):给予每个进程公平的CPU份额,确保每个进程都有机会获得CPU时间,避免某些进程长时间占用CPU而其他进程被忽略的情况。
最小等待时间(Min Waiting Time):尽量减少进程在就绪队列中等待的时间,使进程能够尽快得到执行,提高系统的响应速度和效率。
最小响应时间(Min Response Time):CPU应立即响应进程的请求,使进程能够迅速获得CPU时间片,提高系统的实时性和交互性能。
4.3 Scheduling Algorithms(Order of scheduling matters)
用于衡量进程调度算法的效果和性能的指标

到达时间(Arrival Time,AT):进程到达就绪队列的时间。
完成时间(Completion Time):进程完成执行的时间。
执行时间(Burst Time):进程在CPU上执行所需的时间。
周转时间(Turnaround Time,TT):进程从首次到达就绪状态到完成执行所经过的总时间。
周转时间 = 完成时间 - 到达时间。
等待时间(Waiting Time,WT):进程在就绪状态中等待CPU执行的总时间。
等待时间 = 周转时间 - 执行时间。
响应时间(Response Time):进程首次获得CPU执行的时间。
❑ First-Come, First-Served (FCFS) Scheduling非抢占
先来先服务(FCFS)调度算法是按照进程到达的先后顺序来执行的。 这种算法的性能较差,因为平均等待时间较长。 这意味着如果有一个长时间运行的进程首先到达,那么后面到达的进程将不得不等待较长时间,直到前面的进程执行完成。 (Processes are executed on first come, first served basis)
❑ Shortest-Job-First (SJF) Scheduling抢占

调度算法是按照进程的执行时间(即CPU执行时间)来进行调度的。执行时间最短的进程会被首先调度执行。
disad:很难准确预测进程的执行时间,特别是在没有充分历史数据或对作业的先验知识的情况下。其次,这种调度算法可能导致长时间作业被短时间作业所抢占,从而导致长时间作业长时间等待,甚至可能出现饥饿的情况。

- If a=0, then recent history has no effect - If a=1, then only the most recent CPU bursts matter
❑ Shortest Remaining Time First (SRTF) Scheduling 短剩余时间优先
第一个进程先来先服务,第二个进程之后根据最短剩余时间进入,第一个进程可能会被抢占。

❑ Priority Scheduling非抢占

每个进程被分配一个优先级(一个整数值)。 CPU被分配给优先级最高的进程(最小的整数表示最高优先级)。
优先级可以是:
内部优先级:基于操作系统内部的条件。例如:内存需求。
外部优先级:基于操作系统外部的条件。例如:由管理员指定。
然而,使用优先级调度算法存在一个问题,即低优先级的进程可能永远无法执行(被饿死)。
为解决这个问题,引入了"老化"(Aging)机制。随着时间的推移,增加进程的优先级。例如:每隔15分钟将优先级增加1。
通过"老化"机制,可以确保低优先级的进程也有机会获得CPU执行时间,避免了饿死的问题。这样可以更好地平衡各个进程之间的执行机会,提高系统的公平性。
❑ Round Robin(RR) Scheduling抢占

每个进程被分配一个小单位的CPU时间(时间片或时间片段),通常为10-100毫秒。 当时间片用尽时,进程被抢占,并添加到就绪队列的末尾。就绪队列被视为循环队列。 如果就绪队列中有n个进程,并且时间片为q,则每个进程最多以q个时间单位的块,获得CPU时间的1/n。没有进程等待超过(n-1)q个时间单位。 性能方面:
- 如果q很大,则轮转调度(RR scheduling)等同于先来先服务(FCFS scheduling)。
- 如果q很小,则q必须相对于上下文切换来说要大,否则开销会太高。
通过时间片轮转调度算法,每个进程都能够获得一定的CPU执行时间,避免了某些进程长时间占用CPU而导致其他进程无法执行的问题。此算法可以在一定程度上提高系统的公平性和吞吐量,并且对于响应时间也有一定的控制。然而,选择适当的时间片大小对于平衡系统的开销和响应时间是至关重要的。

❑ Multiple-Level Queues Scheduling

就绪队列被分成多个独立的队列,例如,包含前台(交互式)进程的队列和后台(批处理)进程的队列。前台进程可能具有外部定义的优先级,优先于后台进程。 进程永久地与特定队列相关联,不会移动到其他队列。 多级队列调度中有两种类型的调度:
- 在队列之间的调度。
- 在所选队列的进程之间的调度。
不仅要对进程进行调度,还需要对队列进行调度:
- 固定优先级调度:先服务所有前台进程,然后服务后台进程。可能导致饥饿问题。
- 时间片轮转:每个队列都获得一定的CPU时间,可以在其进程之间进行调度;
- 前台队列占据80%的时间片,采用轮转调度(RR)算法;
- 后台队列占据20%的时间片,采用先来先服务(FCFS)调度算法。
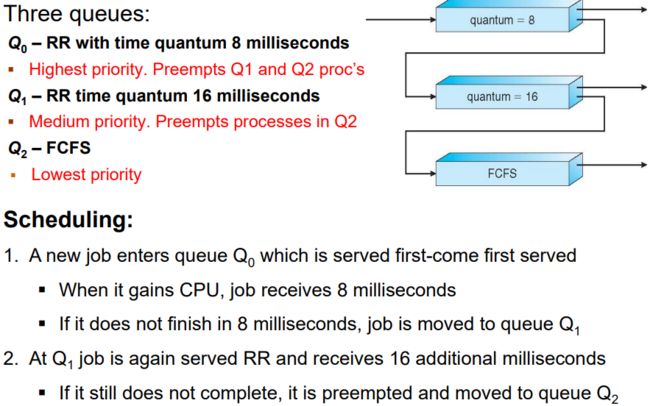
❑ Multilevel Feedback Queue Scheduling

多级反馈队列(Multilevel Feedback Queues)根据进程的CPU执行行为自动将其放入不同的优先级队列中。 I/O密集型进程会被放置在较高优先级的队列中,而CPU密集型进程会被放置在较低优先级的队列中。 一个进程可以在不同的队列之间移动。 多级反馈队列遵循两个基本规则:
- 新进程被放置在最高优先级队列中。
- 如果一个进程没有完成其时间片(quantum),那么它将保持在相同的优先级队列;否则,它将移动到下一个较低的优先级队列。
通过这种方式,多级反馈队列能够根据进程的执行情况进行动态调整,以提供适应不同类型进程的合适调度策略。这种调度算法可以在一定程度上平衡对CPU和I/O资源的需求,提高系统的性能和响应能力。