pandas
目录
1,两种数据结构
1.1 Series
1.1.1 定义
1.1.2 创建
1.1.3 基本用法
1.2 DataFrame
1.2.1 定义
1.2.2 创建
1.2.3 常用属性
1.3 数据的读取
1.4 提取数据
2,数据分析方法
2.1 基本统计分析方法
2.2 分组分析
2.3 分布分析
2.4 交叉分析
2.5 结构分析
2.6 相关分析
3,相关函数和操作
3.1 Pandas函数使用
3.1.1 可直接使用NumPy的通用函数
3.1.2 apply函数
3.1.3 格式化函数
3.1.4 排序与排名
3.1.5 利用函数或映射进行数据转换
3.2数据合并
3.3 缺失值和重复值处理
3.3.1 缺失值
3.3.2 重复值
3.4 字符串操作
3.4.1 全部转换为小写
3.4.2 全部转换为大写
3.4.3 首字母大写
3.4.4 计算字符串长度
3.4.5 查找某个字符串
3.4.6 删除字符串里所有的空格
3.4.7 删除字符串左边的空格
3.4.8 删除字符串右边的空格
3.4.9 字符串的替换
3,4,10 字段拆分
3.4.11 字段抽取
3.5 时间序列
1,两种数据结构
1.1 Series
1.1.1 定义
- Series是一种一维标记的数组型对象,由数据和索引组成,能够保存任何数据类型。
- 索引自动生成且索引长度与数据长度相同。
导入pandas库。
import pandas as pd1.1.2 创建
- 通过数组创建 pd.Series(数组名)
arr = np.arange(1,9)
s1 = pd.Series(arr)
s1- 通过字典创建 pd.Series(字典名)
dict = {
'name':'崔泽',
'age':18,
'num':'001'
}
s = pd.Series(dict)
s- 通过list创建 pd.Series(列表名)
这里也是通过先创建列表,然后通过 pd.Series(列表名)来创建Series。由于和上述步骤基本相同,因此这里不做过多的解释。
1.1.3 基本用法
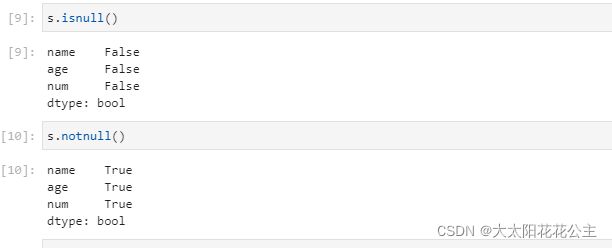
- 1检查缺失值
# 利用isnull和notnull检查缺失值
s.isnull() #为空则返回TRUE
s.notnull() #非空则返回TRUE
- 2.通过索引获取数据
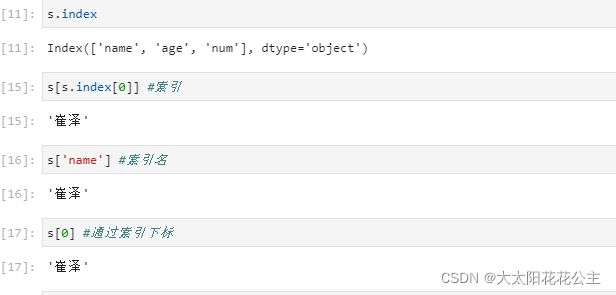
通过索引获取数据
s[s.index[0]]
通过索引下标获取数据
s[0] #通过索引下标获取数据通过索引名称获取数据
s['name'] #索引名运行结果如下:3
- 3选取数据
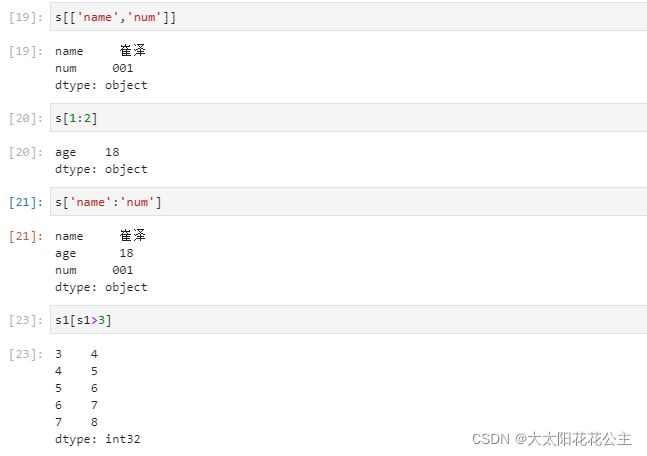
选取多个离散的值
s[['name','num']]
# 注意这里的方括号有两个!!!!!只选取name和num两个数据选取连续的值(不包含终止值)
s[1:2]
#切片的方式选取数据标签切片(包含终止值)
s['name':'num']
# 这里方括号只有一个!!!!选择name到num中的所有数据布尔索引
s1[s1>3]
#data[data>x]
#选择s1中大于3的所有值运行结果如下:
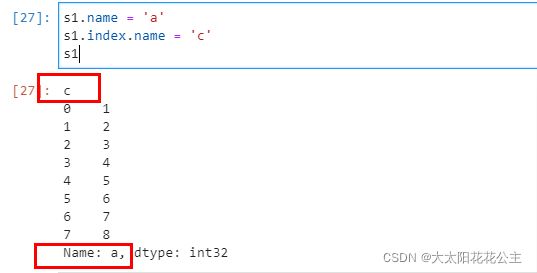
- 4name属性
s1.name = 'a'
s1.index.name = 'c'
s1运行结果如下:
1.2 DataFrame
1.2.1 定义
DataFrame是一种表格型的数据结构,包含一组有序列(也称之为索引),类似多维数组/表格数据,每一列可以是不同的数据类型。数据以二维结构存放,有行索引和列索引。
1.2.2 创建
- 1通过字典构造
- 数组、列表、元组构成的字典构造DataFrame
#数组、列表、元组构成的字典构造DataFrame
#构造字典
data0 = {'a':[1,2,3,4]
,'b':(5,6,7,8)
,'c':np.arange(9,13)
}
#构造DataFrame
pd0 = pd.DataFrame(data0)
pd0- Series构成的字典构造DdataFrame
#Series构成的字典构造DdataFrame
data1 = {'a':pd.Series(np.arange(3))
,'b':pd.Series(np.arange(3,5))
,'c':pd.Series(np.arange(2,8))
}
pd1 = pd.DataFrame(data1)
pd1- 字典构成的字典构造DataFrame
#字典构成的字典构造DataFrame(字典嵌套)
data2 = {
'name':['张三', '李四', '王五', '小明'],
'sex':['female', 'female', 'male', 'male'],
'year':[2001, 2001, 2003, 2002],
'city':['北京', '上海', '广州', '北京']
}
pd2 = pd.DataFrame(data2)
pd2- 2通过列表构造
- 2D ndarry构造DataFrame
#2D ndarry构造DataFrame
arr1 = np.arange(12).reshape(4,3)
pd01 = pd.DataFrame(arr1)
pd01- 字典构成的列表构造DataFrame
#字典构成的列表构造DataFrame
l1 = [{'apple':3.6,'banana':5.6}
,{'apple':3,'banana':5}
,{'apple':3.2}
]
pd02 = pd.DataFrame(l1)
pd02- Series构成的列表构造DataFrame
#Series构成的列表构造DataFrame
l2 = [pd.Series(np.random.rand(3)),pd.Series(np.random.rand(2))]
pd03 = pd.DataFrame(l2)
pd031.2.3 常用属性
pd2.index # 查看行索引/行名
pd2.columns # 查看列名
pd2.values # 查看数据
pd2.dtypes # 查看每一列数据类型
pd2.size # 查看数据个数:行*列
pd2.ndim # 查看维度
pd2.shape # 查看形状1.3 数据的读取
pd.read_csv("路径")或者pd.read_excel("路径"),具体使用哪个由具体使用的文件决定。
data=pd.read_csv("C:\\Users\\Yan\\Desktop\\scores.csv")
data常用方法
data.index # 查看数据的行索引
data.columns # 查看数据的列名
data.info() # 查看数据各列的信息
data.head() # 查看数据的前n行,默认前5行
data.tail() # 查看数据的后n行,默认后5行
data.sample() # 随机抽取n行1.4 提取数据
通过列名或以属性(.列名)的方式提取数据的列
#data[列名]的方式提取数据
data['num']
#data.列名的方式提取数据
data.num通过切片的方式提取数据的行(索引位置序号)
# data[m:n]:选择第m-n行(不包括n行)
data[1:10]DataFrame.loc(行索引名称(包含终止值)/条件,列索引名称)
data.loc[7:10,'math']DataFrame.iloc(m:n,f:g)→选择第m-n行,f-g列的数据(不包含终止值n行,g列)
data.iloc[4:10,1:8]修改数据:找到指定数据的位置,进行赋值
pd2.loc[pd2['name']=='李四','year']=9999
pd2运行结果如下:

增加一列数据:设置一个新索引,进行赋值
#新增一列数据:设置一个新索引,进行赋值
pd2['R']=['a','b','c','d']
pd2
删除数据:drop(‘索引名/列名’,axis=0/ index:删除行;axis=1/columns:删除列)
这里要注意的是,这一操作不是在原数据进行修改,返回的是结果视图
pd2.drop('R',axis='columns') # 删除R列2,数据分析方法
2.1 基本统计分析方法
基本统计分析又称为描述性统计分析,常用的统计分析指标有计数、求和、求均值、方差、标准差等
describe()描述性统计为:个数、均值、标准差、 最小值、25%分位值、50%分位值、75%分位值,以及最大值。
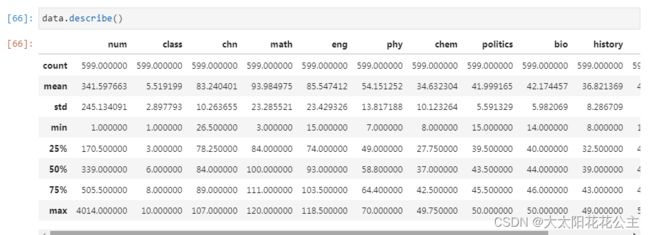
.value_counts():统计每一类数据出现的次数
# 统计这一列里有哪些数据,每个数据分别出现过多少次
data['class'].value_counts()
# 统计这一列数据的取值有多少类(有多少个不同取值的数据构成)
len(data['class'].value_counts())
# 统计这一列有多少个数据
data['class'].count()
.astype('category').describe()→'category'类型的描述性统计为:非空值个数,类别个数,频次最多的类别,频次最多的次数
data['class'].astype('category').describe()
# class为列名2.2 分组分析
分组分析(df.groupby(by=['列1','列2'])['列10','列20'].agg())
分组分析是指根据分组字段,将分析对象划分成不同的部分,以对比分析各组之间差异性的分析方法。
分组分析常用的统计指标是计数、求和、平均值
data.groupby(by='class')['math'].agg(np.max)
# 通过class分组,查看各班数学成绩的最大值
# classh和math均为列名2.3 分布分析
分布分析是指根据分析的目的,将定量数据进行等距或者不等距的分组,从而研究各组分布规律的一种分析方法。
如学生成绩分布、用户年龄分布、收入状况分布等。
在分布分析时,首先用cut()函数确定分布分析中的分层,然后再用groupby()函数实现分组分析。
pd.cut(data,bins,right=true,labels=None,include_lowest=False)
- data:进行划分的一维数组
- bins:取整数值,表示将x划分为多少个等距的区间。取序列值,表示将x划分在指定序列中
- right:分组时是否包含右端点,默认为True(包含)
- labels:分组时是否用自定义标签来代替返回的bins,可选项,默认为NULL。
- include_lowest:分组时是否包含左端点,默认为False(不包含)。代码示例:

2.4 交叉分析
交叉分析通常用于分析两个或两个以上分组变量之间的关系,以交叉表形式进行变量间关系的对比分析;
从数据的不同维度,综合进行分组细分,进一步了解数据的构成、分布特征。
2.4.1 透视表
交叉分析有数据透视表和交叉表两种,其中,pivot_table()函数返回值是数据透视表的结果,该函数相当于Excel中的数据透视表功能。
透视表 pd.pivot_table(data,values,index,columns,agg,func,fill_value,margins)
- ■ data:要应用透视表的数据框。
- ■ values:待聚合的列的名称,默认聚合所有数值列。
- ■ index:用于分组的列名或其他分组键,出现在结果透视表的行。
- ■ columns:用于分组的列名或其他分组键,出现在结果透视表的列。
- ■ aggfunc:聚合函数或函数列表,默认为'mean',可以是任何对groupby有效的函数。
- ■ fill_value:用于替换结果表中的缺失值。
- ■ margins:添加行/列小计和总计,默认为False。
在交叉分析时,可先用cut()函数确定交叉分析中的分层,然后再利用pivot_table()函数
实现交叉分析。 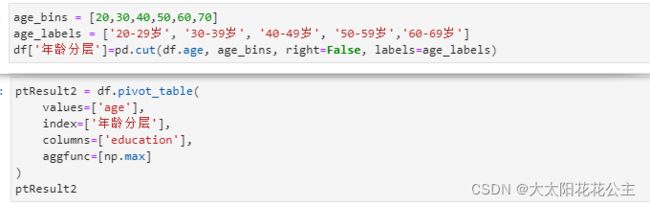
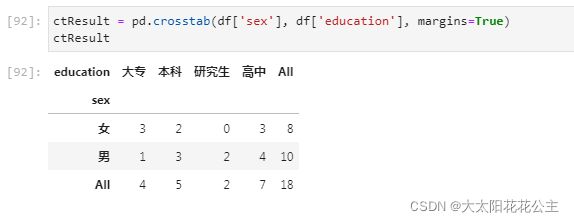
2.4.2 交叉表
交叉表(Cross-Tabulation,简称crosstab)是一种用于计算分组频率(size)的特殊透视表
pd.crosstab(待分组的行数据,待分组的列数据)
代码示例:
2.5 结构分析
结构分析是在分组和交叉的基础上,计算各组成部分所占的比例,进而分析总体的内部特征的一种分析方法。 重点在于了解各部分占总体的比例,例如:求公司中不同学历员工所占的比例,产品在市场的占有率、股权结构等。在结构分析时,先利用pivot_table()函数进行数据透视表分析,
然后,通过指定axis参数对数据透视表按行或列进行计算(当axis=0时按列计算,axis=1时按行计算)。 主要包括:add,sub,multiply,div;sum,mean,var,sd
2.6 相关分析
相关分析(Correlation Analysis)用于研究现象之间是否存在某种依存关系,
并探讨具有依存关系的现象的相关方向以及相关程度,是研究随机变量之间相关关系的一种统计方法。
线性相关关系主要采用皮尔逊(Pearson)相关系数r来度量连续变量之间线性相关强度:
r>0,线性正相关;
r<0,线性负相关;
r=0,表示两个变量之间不存在线性关系,但并不代表两个变量之间不存在任何关系
#计算data中math和chem之间的相关系数
corrResult1 = data.math.corr(data.chem)
corrResult1相关分析函数包括DataFrame.corr()和Series.corr(other)。计算相关系数的corr()函数只会对数据框中的数据列进行计算
- 如果由数据框调用corr()函数,那么将会计算列与列之间的相似度。
- 如果由序列调用corr()方法,那么只是该序列与传入的序列之间的相关度。函数返回值如下。
- DataFrame调用:返回DataFrame。
- Series调用:返回一个数值型数据,大小为相关度。
代码示例:

3,相关函数和操作
3.1 Pandas函数使用
3.1.1 可直接使用NumPy的通用函数
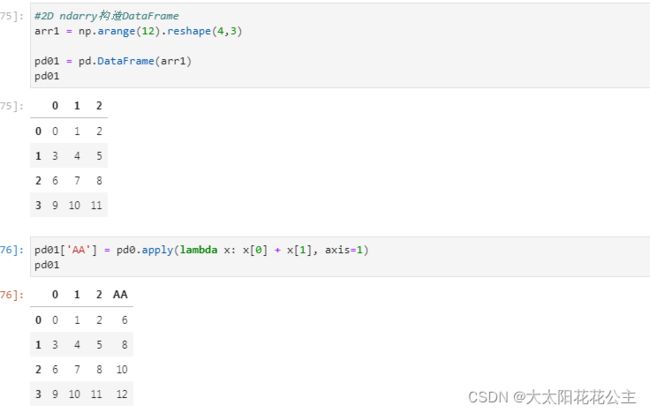
3.1.2 apply函数
通过apply()指定的轴方向应用自定义函数(axis=0:对列;axis=1:对行)
 3.1.3 格式化函数
3.1.3 格式化函数
- applymap():应用于数据框里每一个元素进行操作
- map():应用于数据框的某一列(series),这一列每个元素进行操作

3.1.4 排序与排名
1. 索引排序
sort_index():排序默认使用升序排序,ascending=False 为降序排序。按照索引来进行排序,只要不加inplace = True,返回是视图
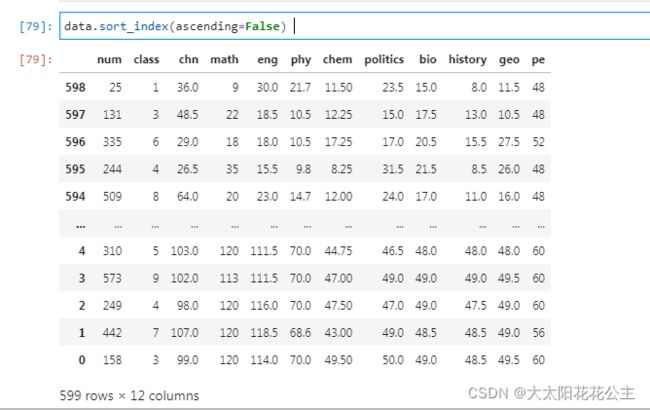
2. 按值排序
DataFrame.sort_values('columns',ascending=True,na_position)** →根据某个唯一的列名进行排序,如果有其他相同列名则报错。ascending:是否升序排列,默认True,降序则为False。 na_position:空值的位置,‘first’或‘last’, default ‘last'.(如果指定排序的列中有nan值,可指定nan值放在第一个还是最后一个)
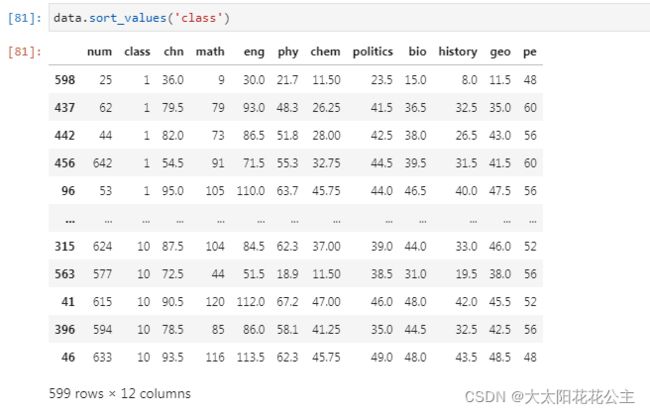
3. 排名
rank(ascending, method = ‘max’) →可计算排名的位次 ascending:是否升序排列,默认True,降序则为False。method排名相同时的取值,默认取均值

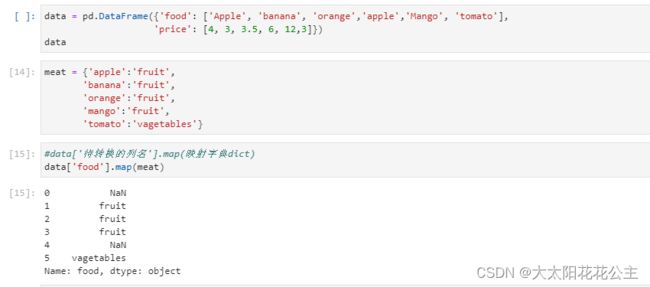
3.1.5 利用函数或映射进行数据转换
函数映射:先按数据类别创建映射字典dict, data[ 待转换的列名].map(映射字典dict)
3.2数据合并
通过数据合并,可以将多个数据集整合到一个数据集中,数据合并操作类似于数据库中运用SQL语句的 JOIN连接来实现多表查询。在pandas中,常用的数据合并函数有:
1. merge():inner:对两张表都有的键的交集进行联合;全连接 outer:对两者表的都有的键的并集进行联合; 左连接 left:对所有左表的键进行联合;右连接 right:对所有右表的键进行联合
pd.merge:(left, right, how='inner',on=None,left_index=True,right_index=True )
- left:合并时左边的DataFrame
- right:合并时右边的DataFrame
- how:合并的方式,默认'inner', 'outer', 'left', 'right'
- on:需要合并的列名,必须两边都有的列名,并以 left 和 right 中的列名的交集作为连接键
- 内连接 inner:对两张表都有的键的交集进行联合2. join():应用于两个数据框的列名没有重复的表,按照索引进行合并(并集)
3. concat():axis=0,以列名为主键,进行上下拼接;axis=1,以索引名为主键,进行左右拼接
3.3 缺失值和重复值处理
3.3.1 缺失值
1. isnull()/isnotnull:检测是否存在缺失值
2. np.sum(data.isnull(), axis):统计缺失值个数
np.sum(data2.isnull(), axis=0) #统计每一列缺失值的个数
np.sum(data2.isnull(), axis=1) #统计每一行缺失值的个数3. data.drop(['缺失值的列名'],axis='columns'):删除缺失值的列(删除列的方式)
4. data.dropna(axis=0, how='any', thresh=None) :删除缺失值函数
| dropna(axis=0, how='any', thresh=None, inplace=False):** - axis:轴;0或'index',表示按行删除;1或'columns',表示按列删除,默认删除行。 - how:筛选方式。‘any’,表示该行/列只要有一个以上的空值,就删除该行/列;‘all’,表示该行/列全部都为空值,就删除该行/列,默认'any',有缺失值即可。 - thresh:非空元素最低数量。int型,默认为None。如果该行/列中,非空元素数量小于这个值,就删除该行/列。 - inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操作,返回值为None。 |
data.dropna()#删除有空值的行
data.dropna(how = 'all')#删除所有值为空的行
data.dropna(axis = 'columns')#删除有空值的列
data.dropna(how = 'all', axis = 'columns')#删除所有值为空的列
data.dropna(thresh = 3,axis = 'columns')#删除非空值个数小于3的列
5. data.fillna():填充缺失值
填充值可以是任意数值或者函数方法表示的值。
data.fillna(999999)#用具体数值填充缺失值
data.fillna(data2.mean())#用每一列的均值填充缺失值
data.fillna(round(data2.mean(),2))#用均值填充,并保留均值的两位小数
data.fillna({0:0.999,1:0.888,2:0.666})#对每一列进行分别填充3.3.2 重复值
1. data.duplicated():检测是否有重复值
2. data.drop_duplicates():删除重复值
3.4 字符串操作
3.4.1 全部转换为小写
s.str.lower() #s为字符串名称,下同
3.4.2 全部转换为大写
s.str.upper()3.4.3 首字母大写
s.str.capitalize()
3.4.4 计算字符串长度
s.str.len()3.4.5 查找某个字符串
s.str.contains('A')
3.4.6 删除字符串里所有的空格
s.str.strip().values
3.4.7 删除字符串左边的空格
s.str.lstrip().values
3.4.8 删除字符串右边的空格
s.str.rstrip().values
3.4.9 字符串的替换
s.str.replace('原字符串', '新字符串')
3,4,10 字段拆分
#字段拆分,即按照固定的字符,拆分已有的字符串
s.str.split(sep,n,expand)3.4.11 字段抽取
#字段抽取,根据已知列数据的开始和结束位置,抽取出新的数据
s.str.slice(start,stop)3.5 时间序列
import datetime1.创建时间对象
datetime.datetime.now()#获取当前时间datetime.datetime(年月日时分秒)
datetime.datetime(2021, 11, 23) (年月日时分秒) pd.Timestamp(2021-11-23")
2将字符串类型转换为时间对象
pd.to. _datetime("2021-11-17")3.时间周期时长),可进行时间运算
原时间+pd.Timedelta(5D)
# Y年; D天; H小时; min:分钟; S:秒4.若时间对象运算周期以月为单位:则可用eplace 函数进行计算, 方法如下:
now.replace(month=(now.month + addmonths- 1) % 12 + 1, year=now.year if now.month < 10 else now.year + 1)5.创建一组时间对象
pd.Series(pd.date. range(start='2021-11-17, periods= 10, freq='30min")
# D天; H:小时; min:分钟; M:月(从月底开始计算)