MongoDB之完整入门知识(集合操作、文档基本CRUD操作、文档分页查询、索引等相关命令)
MongoDB完整入门知识
- 一、相关概念
-
- 1、简介
- 2、体系结构
- 3、安装网址
- 二、MongoDB基本常用命令
-
- 1、Shell连接(mongo命令)
- 2、选择和创建数据库
-
- 2.1 选择和创建数据库的语法格式(如果数据库不存在,则自动创建)
- 2.2 查看有权限查看所有数据库的命令
- 2.3 查看当前正在使用的数据库命令
- 2.4 三个初始数据库作用
-
- (1)admin库
- (2)local库
- (3)config
- 2.5 数据库的删除(主要用来删除已经持久化的数据库)
- 3、集合操作
-
- 3.1 集合的显式创建
- 3.2 集合的隐式创建
- 3.3 查看数据库中的集合(表)
- 3.4 集合的删除
- 4、文档的基本CRUD操作
-
- 4.1 文档的插入
-
- (1)单个文档的插入
- (2)批量插入
- (3)文档插入使用try catch
- 4.2 文档的查询
-
- (1)查询所有
- (2)按条件查询
- (3)返回符合条件的第一条数据(最多只返回一条)
- (4)投影查询
- 4.3 文档的更新
-
- (1)更新文档的语法
- (2)覆盖修改(将该条记录完全覆盖)
- (3)局部修改(使用修改器$set来实现,默认只修改第一条数据)
- (4)批量修改(更新所有用户为100的数据)
- (5)列值增长的修改
- 4.4 删除文档
-
- (1)删除文档的语法
- (2)删除所有数据
- (3)删除_id = 1的记录
- 5、文档的分页查询
-
- 5.1 统计查询
-
- (1)统计comment集合的所有的记录数
- (2)按条件统计记录数
- 5.2 分页列表查询
-
- (1)基础语法
- (2)limit方法(返回前n条数据)
- (3)skip方法(跳过前n条数据)
- (4)分页样例
- 5.3 排序查询
-
- (1)基础语法
- (2)样例
- 5.4 注意
- 6、其它查询方式
-
- 6.1 正则复杂条件查询
-
- (1)基础语法
- (2)样例
- 6.2 比较查询
-
- (1)基础语法
- (2)样例
- 6.3 包含查询
-
- (1)基础语法及样例
- 6.4 条件连接查询
-
- (1)基础语法及样例
- 三、索引-Index
-
- 1、概述
- 2、单字段索引
- 3、复合索引
- 4、索引的管理操作
-
- 4.1 索引的查看
-
- (1)说明
- (2)语法
- 4.2 索引的创建
-
- (1)说明
- (2)语法
- (3)单字段索引
- (4)复合索引
- 4.3 索引的移除
-
- (1)说明
- (2)指定索引的移除
- (3)所有索引的移除
- 4.4 相关计划
-
- (1)执行计划
- (2)涵盖的查询
一、相关概念
1、简介
Mongo DB是一个开源的、高性能、无模式的文档型NoSQL数据库,能够很好地应对数据库高并发的读写需求、海量数据的高效率存储和访问的需求以及数据库的高扩展性和高可用性的需求。同时对Web2.0的网站也能从容面对。
它支持的数据结构非常松散,是一种类似于JSON的格式叫BSON,所以它既可以存储比较复杂的数据类型,又相当的灵活
MongoDB中的记录是一个文档,它是一个由字段和值对组成的数据结构。MongoDB文档类似于JSON对象,即一个文档认为就是一个对象。字段和数据类型是字符型,它的值除了使用基本的一些类型外,还可以包括其他文档、普通数组和文档数组。
2、体系结构
MongoDB 非关系型数据库(Database)----->Collection(集合)----->Document(文档)
MySQL 关系型数据库(Database)----->Table(数据库表)------->Row(数据记录行)
3、安装网址
MongoDB网址跳转
一般首先安装MongoDB Community Server 版本5.x的zip包就可以了,最新版本可能会出问题
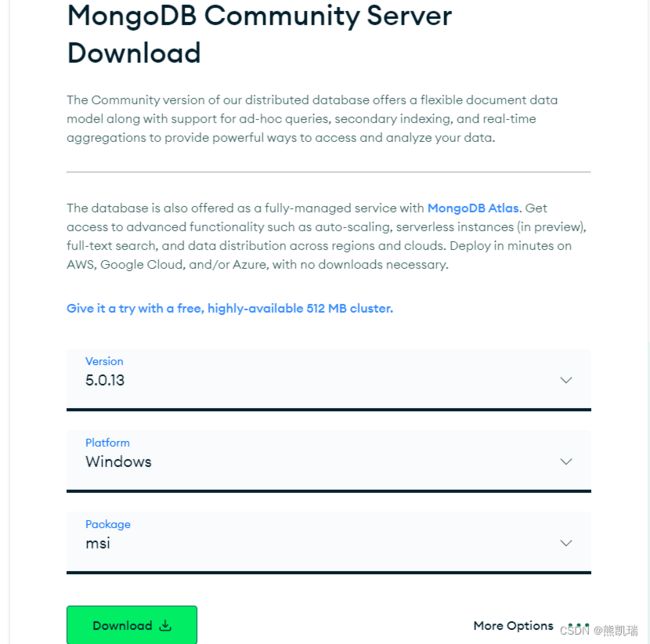
之后安装MongoDB Compass软件用来连接MongoDB就可以了。
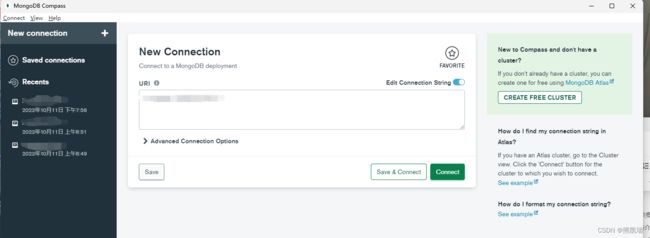
二、MongoDB基本常用命令
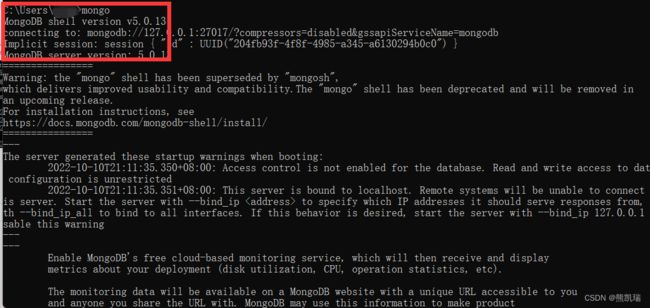
1、Shell连接(mongo命令)
如果不用Mongo Compass连接MongoDB的话,在命令提示符输入相关shell命令即可完成登录。
mongo
2、选择和创建数据库
2.1 选择和创建数据库的语法格式(如果数据库不存在,则自动创建)
use 数据库名称
2.2 查看有权限查看所有数据库的命令
show dbs
或者
show databases
注意:在MongoDB中,集合只有在内容插入后才会创建,也就是说创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
未添加内容时,暂存在内存里,添加内容后,则自动存到磁盘里
2.3 查看当前正在使用的数据库命令
db
MongoDB中默认的数据库是test,如果没有选择数据库,集合将存放在test数据库中。
2.4 三个初始数据库作用
(1)admin库
从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,则这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能在这个数据库运行,比如列出所有的数据库或者关闭服务器。
(2)local库
这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合。
(3)config
当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
2.5 数据库的删除(主要用来删除已经持久化的数据库)
db.dropDatabase()
3、集合操作
集合,类似于关系型数据库中的表
3.1 集合的显式创建
name:要创建的集合名称
db.createCollection(name)
例子
创建一个名为mycollection的普通集合
db.createCollection("mycollection")
3.2 集合的隐式创建
当向一个集合中插入一个文档的时候,如果集合不存在,则会自动创建集合
3.3 查看数据库中的集合(表)
show collections
或者
show tables
3.4 集合的删除
db.collection.drop()
或者
db.集合.drop()
删除成功,则drop()方法返回true,否则返回false
例子
db.mycollection.drop()
4、文档的基本CRUD操作
文档的数据结构和JSON基本一样,所有存储在集合中的数据都是BSON格式。
4.1 文档的插入
(1)单个文档的插入
使用insert( )或者save( )方法向集合中插入文档。
db.collection.insert(
<document or array of documents>,
{
writeConcern: <document>,
ordered: <boolean>
}
)
测试数据,向comment的集合中插入一条测试数据
db.comment.insert({"articleod":"10000","content":"今天天气真好","userid":"1001","createdatetime":new Date(),"state":null})
提示:
如果comment集合不存在,则会隐式创建。
mongo中的数字,默认情况下是double类型,如果要存整型,必须使用函数NumberInt(整型数字)。
插入当前日期使用new Date( )。
插入的数据没有指定_id,会自动生成主键值。
如果某字段没值,可以赋值为null,或不写该字段。
结果如下
![]()
(2)批量插入
使用insertMany()方法向集合中插入文档。
db.collection.insert(
[<document1> , <document1>],
{
writeConcern: <document>,
ordered: <boolean>
}
)
提示:
插入时指定了_id,则主键就是该值
如果某条数据插入失败,将会终止插入,但已经插入成功的数据不会回滚掉。
因为批量插入由于数据较多容易失败,因此可以使用try catch进行异常捕获处理,测试的时候可以不处理。
db.comment.insertMany([
{"_id":"1","articleId":"1001", "content":"吃饭喝水"},
{"_id":"2","articleId":"1001", "content":"吃饭喝水"},
{"_id":"3","articleId":"1001", "content":"吃饭喝水"},
])
(3)文档插入使用try catch
try{
db.comment.insertMany([
{"_id":"1","articleId":"1001", "content":"吃饭喝水"},
{"_id":"2","articleId":"1001", "content":"吃饭喝水"},
{"_id":"3","articleId":"1001", "content":"吃饭喝水"},
]);
} catch(e){
print(e);
}
4.2 文档的查询
(1)查询所有
db.comment.find()
或
db.comment.find({})
db.comment.find()
(2)按条件查询
db.comment.find({userId:'1'})
按照userId为1来查询数据
(3)返回符合条件的第一条数据(最多只返回一条)
db.comment.findOne({userId:'1'})
(4)投影查询
如果要查询结果返回部分字段,则需要使用投影查询(不显示所有字段,只显示指定的字段)
显示userId、name、_id字段
db.comment.find({userId:"1"}.{userId:1, name:1, _id:1})
显示userId、name字段,不显示_id字段
db.comment.find({userId:"1"}.{userId:1, name:1, _id:0})
查询所有数据,只显示_id、userId、name
db.comment.find({}.{userId:1, name:1, _id:1})
4.3 文档的更新
(1)更新文档的语法
db.collection.update(query, update, options)
query:查询选择条件
update:更新的数据
options:可选。用于修改计数的额外选项
(2)覆盖修改(将该条记录完全覆盖)
db.comment.update({_id:"1"}.{name:NumberInt(1001)})
(3)局部修改(使用修改器$set来实现,默认只修改第一条数据)
db.comment.update({_id:"1"}.{$set:{name:NumberInt(1001)}})
(4)批量修改(更新所有用户为100的数据)
db.comment.update({userId:"100"}.{$set:{name:NumberInt(1001)}}.{multi:true})
(5)列值增长的修改
db.comment.update({_id:"3"}.{$inc:{num:NumberInt(1)}})
4.4 删除文档
(1)删除文档的语法
db.集合名称.remove(条件)
(2)删除所有数据
db.comment.remove({})
(3)删除_id = 1的记录
db.comment.remove({_id:"1"})
5、文档的分页查询
5.1 统计查询
db.collection.count(query, options)
query:查询选择条件
options:用于修改计数的额外选项
(1)统计comment集合的所有的记录数
db.comment.count()
(2)按条件统计记录数
统计userId为100的记录条数
db.comment.count({userId:"100"})
5.2 分页列表查询
(1)基础语法
使用limit()方法来读取指定数量的数据,使用skip()方法来跳过指定数量的数据。
db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
(2)limit方法(返回前n条数据)
返回指定条数的记录,可以在find方法后调用limit来返回结果
如下:返回前三条的数据
db.comment.find().limit(3)
(3)skip方法(跳过前n条数据)
skip方法同样接受一个数字参数作为跳过的记录条数。(前N个不要)默认值是0
db.comment.find().skip(3)
(4)分页样例
// 第一页
db.comment.find().skip(0).limit(3)
// 第二页
db.comment.find().skip(3).limit(3)
// 第三页
db.comment.find().skip(6).limit(3)
.....
5.3 排序查询
sort( )方法对数据进行排序,sort( )方法可以通过参数指定排序的字段,并使用1和-1来指定排序的方式,其中1为升序排列,而-1是用于降序排列。
(1)基础语法
db.COLLECTION_NAME.find().sort({KEY:1})
db.集合名称.find( ).sort(排序方式)
(2)样例
对userId降序排列,并对number进行升序排列
db.comment.find().sort({userId:-1,number:1})
5.4 注意
执行顺序:先sort( ),再是skip( ),最后是limit( )和命令编写顺序无关
6、其它查询方式
6.1 正则复杂条件查询
(1)基础语法
MongoDB的模糊查询是通过正则表达式的方式实现的
db.collection.find({field:/正则表达式/})
或
db.集合.find({字段:/正则表达式/})
完全支持JS的正则写法,功能强大
(2)样例
查询food里包含蛋糕的所有文档
db.comment.find({food:/蛋糕/})
6.2 比较查询
(1)基础语法
<,<=,>,>=相关操作符,格式如下
db.集合名称.find({"field":{$gt:value}}) //大于:field>value
db.集合名称.find({"field":{$lt:value}}) //小于:field
db.集合名称.find({"field":{$gte:value}}) //大于等于:field>=value
db.集合名称.find({"field":{$lte:value}}) //小于等于:field<=value
db.集合名称.find({"field":{$ne:value}}) //不等于:field!=value
(2)样例
查询数量大于700的记录
db.comment.find({number:{$gt:NumberInt(700)}})
6.3 包含查询
(1)基础语法及样例
包含使用$in操作符
查询集合中userId字段包含100或101的文档
db.comment.find({userId:{$in:["100","101"]}})
不包含使用$nin操作符
查询集合中userId字段不包含100和101的文档
db.comment.find({userId:{$nin:["100","101"]}})
6.4 条件连接查询
(1)基础语法及样例
查询同时满足两个以上的条件,需要使用$and操作符将条件进行关联
$and:[{ },{ },{ }]
例如:查询集合中number大于等于700并且小于2000的文档
db.comment.find({$and:[{number:{$gte:NumberInt(700)}},{number:{$lt:NumberInt(2000)}}]})
查询两个以上条件之间是或者的关系
$or:[{ },{ },{ }]
例如:查询集合中userId为10,或者点赞数小于100的文档记录
db.comment.find({$or:[{userId:"10"}, {number:{$lt:100}}]})
三、索引-Index
1、概述
索引支持在MongoDB中高效地执行查询。如果存在适当的索引,MongoDB可以使用该索引限制必须检查的文档数,提高查询效率。索引是特殊的数据结构,以易于遍历的形式存储集合数据集的一小部分。索引存储特定字段或一组字段的值,按字段值排序。索引项的排序支持有效的相等匹配和基于范围的查询操作。此外,MongoDB还可以使用索引中的排序返回排序结果。
MongoDB索引使用B树数据结构(B-Tree,MySQL是B+Tree)
2、单字段索引
MongoDB支持在文档的单个字段上创建用户定义的升序/降序索引,称为单字段索引。
对于单个字段索引和排序操作,索引键的排序顺序(即升序或降序)并不重要,因为MongoDB可以在任何方向上遍历索引。
3、复合索引
MongoDB支持多个字段的用户定义索引,即复合索引
复合索引中列出的字段顺序具有重要意义,若复合索引由{userId:1, score:-1}组成,则索引先按userId正序排序,然后在每个userId的值内,再按score倒序排序。
4、索引的管理操作
4.1 索引的查看
(1)说明
返回一个集合中的所有索引的数组
(2)语法
db.collection.getIndexes()
查看comment集合中所有的索引概况
4.2 索引的创建
(1)说明
在集合上创建索引
(2)语法
db.collection.createIndex(keys,options)
keys:包含字段和值对的文档,其中字段是索引键,值描述该字段的索引类型,上升索引,值为1,降序索引,值为-1。
options:可选。包含一组控制索引创建的选项的文档
(3)单字段索引
db.collection.createIndex({userId:1})
(4)复合索引
db.collection.createIndex({userId:1, name:-1})
4.3 索引的移除
(1)说明
可以移除指定的索引,或移除所有索引
(2)指定索引的移除
语法
db.collection.dropIndex(index)
index:索引名称或索引规范
示例
db.collection.dropIndex({userId:1})
(3)所有索引的移除
语法
db.collection.dropIndexes()
4.4 相关计划
(1)执行计划
分析查询性能通常使用执行计划(解释计划、ExplainPlan)来查看查询的情况。
db.collection.find(query, options).explain(options)
(2)涵盖的查询
当查询条件和查询的投影仅包含索引字段时,MongoDB直接从索引返回结果,而不扫描任何文档或将文档带入内存。