庖丁解牛Linux内核分析01:操作系统工作原理基础
目录
1 存储程序计算机工作模型
2 IA-32汇编基础
2.1 寄存器概述
2.1.1 通用寄存器
2.1.2 段寄存器
2.1.3 标志寄存器
2.2 数据格式
2.3 寻址方式
2.3.1 立即数寻址
2.3.2 寄存器寻址
2.3.3 存储器引用寻址
2.4 内嵌汇编概述
2.4.1 内嵌汇编简单语法
2.4.2 内嵌汇编示例
3 深入理解函数调用栈
3.1 相关寄存器
3.2 相关指令
3.2.1 pushl & popl指令
3.2.2 call & ret指令
3.3 函数调用栈反汇编分析
3.3.1 C语言程序反汇编示例
3.3.2 函数调用栈状态变迁
3.4 对比ARMv8体系结构中的栈操作
3.4.1 寄存器约定用法
3.4.2 函数调用栈状态变迁
3.5 函数调用栈功能反汇编分析
3.5.1 保存局部变量
3.5.2 传递参数
3.6 实验:通过EBP寄存器实现栈回溯
3.6.1 实验程序框架
3.6.2 实验程序框架栈分析
3.6.3 代码实现
4 基于Linux构造实验操作系统内核
4.1 实验结构概述
4.2 实验环境搭建
4.3 实验框架代码分析
4.3.1 my_timer_handler函数
4.3.2 my_start_kernel函数
4.4 进程切换实验
4.4.1 实验内容
4.4.2 代码实现
4.4.3 运行结果
4.4.4 实验疑问与分析
1 存储程序计算机工作模型
冯.诺依曼体系结构就是指存储程序计算机,

1. 冯.诺依曼体系结构由运算器、存储器、控制器、输入设备和输出设备组成
3. 程序和数据在逻辑上是相同的,程序也可以存储在存储器中。在计算机内部,使用二进制来表示指令和数据
4. 将编写好的程序和数据存入存储器中,然后启动计算机工作,这就是存储程序的基本含义
说明1:存储程序计算机工作原理抽象
从程序员的角度对存储程序计算机的工作原理进行抽象,如下图所示,
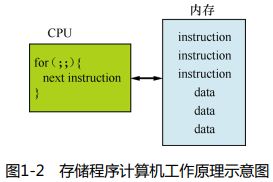
① 内存保存指令和数据
② CPU负责解释和执行这些指令
③ CPU抽象为一个for循环,不断从内存中取指执行
说明2:计算机之所以可以自动执行程序,是依靠CPU中的程序计数器PC(Program Counter)
① 在16位实模式中,PC实现为IP(Instruction Pointer)寄存器;在IA-32体系结构中,PC实现为EIP寄存器;在IA-64体系结构中,PC实现为RIP寄存器
② EIP寄存器中存储着将要执行的下一条指令在存储器中的地址
③ CPU从EIP指向的地址取出一条指令执行,执行完成后EIP会自动累加本条指令的长度(Intel体系结构中指令是不定长的),指向下一条指令
④ EIP寄存器不能被直接修改(或者说对程序员不可见),只能通过call / ret / jmp等指令间接修改。这些指令对应着C语言中的函数调用、return和if-else语句
2 IA-32汇编基础
2.1 寄存器概述
2.1.1 通用寄存器
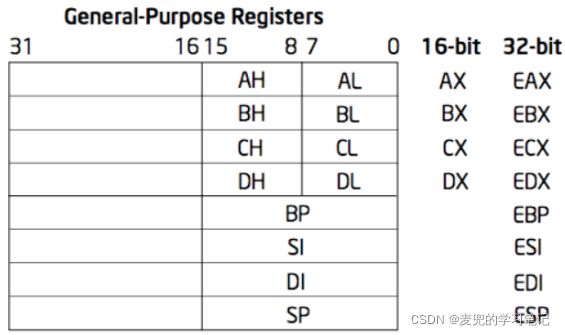
通用寄存器的通常用法如下,
| 寄存器 |
用法 |
| EAX(Accumulator) |
累加寄存器 |
| EBX(Base) |
基地址寄存器 |
| ECX(Count) |
计数器寄存器 |
| EDX(Data) |
数据寄存器 |
| ESP(Stack Pointer) |
栈指针寄存器 |
| EBP(Base Pointer) |
基指针寄存器 |
| ESI(Source Index) |
源变址寄存器 |
| EDI(Destination Index) |
目的变址寄存器 |
2.1.2 段寄存器
IA-32体系结构中,共有6个段寄存器,
| 段寄存器 |
用法 |
| CS(Code Segment) |
代码段寄存器 |
| DS(Data Segment) |
数据段寄存器 |
| SS(Stack Segment) |
栈段寄存器 |
| ES(Extra Segment) |
附加段寄存器 |
| FS(接续E编号) |
附加段寄存器 |
| GS(接续F编号) |
附加段寄存器 |
说明1:在IA-32体系结构中,段寄存器仍然是16位的,并且基于此构建了保护模式。在保护模式中,段寄存器中存储的不再是段基址,而是段选择子
说明2:在定位一条指令时,使用[CS : IP]来准确指明他的地址
2.1.3 标志寄存器
标志寄存器主要用于反映处理器的状态和ALU运算结果的某些特征,可用于控制指令的条件执行

说明:IA-64体系结构寄存器如下图所示,相较于IA-32体系结构,IA-64体系结构扩充了原有寄存器的位数,同时新增了通用寄存器和浮点数运算寄存器,但是使用方法上并没有改变

2.2 数据格式
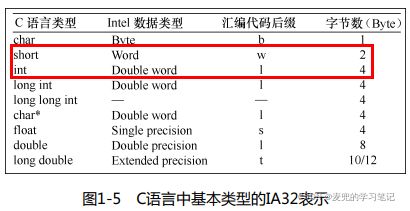
在Intel术语规范中,数据类型如下,
| 术语 |
数据长度 |
汇编代码后缀 |
| 字节(Byte) |
8位 |
b |
| 字(Word) |
16位 |
w |
| 双字(Double Words) |
32位 |
l |
| 四字(Quad Words) |
64位 |
q |
说明:汇编代码后缀
① 汇编代码后缀用于指定操作的数据长度
② 之所以要指定操作的数据长度,是因为在有些操作中,通过指令本身无法判断要操作的数据长度,以下面的指令为例
# 向ebx指向的内存中写入1B数据
movb 0x88, (%ebx)
# 向ebx指向的内存中写入2B数据
movw 0x88, (%ebx)
# 向ebx指向的内存中写入4B数据
movl 0x88, (%ebx)③ 这种指定要操作的数据长度的方式,依汇编器而异。以NASM汇编器为例,使用如下方式指定要操作的数据长度
# 向ebx指向的内存中写入1B数据
mov byte [ebx], 0x88
# 向ebx指向的内存中写入2B数据
mov word [ebx], 0x88
# 向ebx指向的内存中写入4B数据
mov dword [ebx], 0x882.3 寻址方式
2.3.1 立即数寻址
# 使用$开头,后面跟一个数值
movl $0x123, %edx2.3.2 寄存器寻址
# 使用%开头,后面跟一个寄存器名称
movl %eax, %edx2.3.3 存储器引用寻址
在存储器引用寻址中,是根据计算出的有效地址来访问存储器的某个位置,
2.3.3.1 直接(direct)寻址
# 将内存地址0x123处的数据传输到edx寄存器中
# 相当于C语言代码
# edx = *(int *)0x123;
movl 0x123, %edx2.3.3.2 间接(indirect)寻址
# 将ebx指向的内存地址处的数据传输到edx寄存器中
# 相当于C语言代码
# edx = *(int *)ebx;
movl (%ebx), %edx说明1:与直接寻址相比,间接寻址的内存地址存储在寄存器中,而不是在指令中直接给出
说明2:在16位实模式中,AX / BX / CX / DX不能作为基址和变址寄存器来存放内存地址。但是在32位保护模式中,EAX / EBX / ECX / EDX不仅可以传送数据、暂存数据保存算术逻辑运算结果,还可以作为指针寄存器
2.3.3.3 变址(displaced)寻址
# 在ebx指向的内存地址基础上加4,再将其中的数据传输到edx寄存器中
# 相当于C语言代码
# edx = *(int *)(ebx + 4);
movl 4(%ebx), %edx说明:与间接寻址相比,变址寻址在寄存器存储的内存地址上增加了一个偏移量
2.4 内嵌汇编概述
2.4.1 内嵌汇编简单语法
__asm__ __volatile__ (
汇编语句
:输出部分
:输入部分
:破坏描述部分
);1. __asm__是内嵌汇编的关键字,表示这是一条内嵌汇编语句
2. asm和__asm__可以互相替换使用
3. __volatile__也是关键字,此处用于告诉编译器不要优化代码,将汇编指令保持原样
2.4.2 内嵌汇编示例
下面通过一个示例说明内嵌汇编的使用方法,该示例实现val3 = val1 + val2的功能
#include
int main(void)
{
int val1 = 1;
int val2 = 2;
int val3 = 0;
printf("val1 = %d val2 = %d val3 = %d\n", val1, val2, val3);
__asm__ volatile(
"movl $0, %%eax\n\t" // movl $0, %eax
"addl %1, %%eax\n\t" // addl val1, %eax
"addl %2, %%eax\n\t" // addl val2, %eax
"movl %%eax, %0\n\t" // movl %eax, val0
: "=m"(val3) // val3参数编号为0,存储在内存中,且只写
: "c"(val1), "d"(val2) // val1参数编号为1,存储在ecx寄存器中
// val2参数编号为2,存储在edx寄存器中
);
printf("val1 = %d val2 = %d val3 = %d\n", val1, val2, val3);
} 示例代码运行效果如下,

说明1:关于参数编号
参数编号从输入部分 & 输入部分指定的第1个参数开始,初值为0,之后按出场次序递增
说明2:在内嵌汇编中使用寄存器,需要在寄存器名字之前加2个%
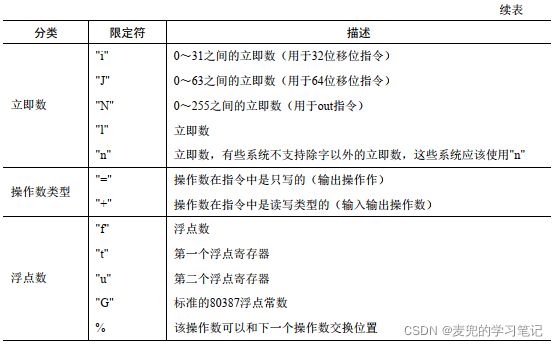
说明3:关于内嵌汇编修饰限定符
下表为常用的内嵌汇编修饰限定符,

3 深入理解函数调用栈
栈是C语言程序运行时必须使用的记录函数调用路径和参数存储的空间,栈的具体作用有记录函数调用框架、传递函数参数、保存返回值的地址、提供函数内部局部变量的存储空间等
3.1 相关寄存器
1. ESP:栈指针(Stack Pointer),记录当前函数调用栈栈顶
2. EBP:基址指针(Base Pointer),记录当前函数调用栈栈底

3.2 相关指令
3.2.1 pushl & popl指令
pushl & popl指令用于实现栈的操作,默认使用[SS : ESP]索引
pushl %eax
# 压栈操作相当于一次性完成如下2步操作
# subl $4, %esp
# movl %eax, (%esp)
popl %eax
# 出栈操作相当于一次性完成如下2步操作
# movl (%esp), %eax
# addl $4, %esp说明:可以看出IA-32体系结构中使用的是满减栈
3.2.2 call & ret指令
call & ret指令用于实现函数的调用与返回,该指令依赖函数调用栈工作
call 0x12345
# 函数调用操作相当于一次性完成如下2步操作
# pushl %eip (*)
# movl $0x12345, %eip (*)
ret
# 函数返回操作相当于完成如下操作
# popl %eip (*)说明1:上述带(*)的指令并不能实际操作,只是用于说明功能的伪代码
说明2:通过函数调用栈实现函数的返回
① call指令将当前的EIP寄存器值压栈,就是将call指令的下一条指令地址保存在栈中(因为EIP指向下一条要执行的指令地址)
② 被调函数中需要确保栈平衡,这样在调用ret指令时,栈顶为之前call指令压入的函数返回地址
③ ret指令将当前栈顶的4B弹出到EIP寄存器,从而使得执行流回到call指令的下一条指令处继续执行
说明3:call & ret指令的不配对使用
① ret指令的本质是将当前栈顶的4B弹出到EIP寄存器,这与之前是否执行过call指令无关,因此就存在call & ret指令不配对使用的场景
② call & ret指令不配对使用的主要应用场景,就是人为构造新建任务第一次被执行时的任务栈。对于新建任务,只要将任务的入口地址压栈,然后在该任务被首次调度时出栈该入口地址到EIP,就可以开始运行该任务
3.3 函数调用栈反汇编分析
3.3.1 C语言程序反汇编示例
要反汇编的C语言程序如下,

使用如下命令对源代码进行汇编,
# 此处增加-m32选项,是因为我们使用的虚拟机是64位的
# 但是我们希望生成32位汇编代码
gcc -S -o disassembly.s disassembly.c -m32汇编后生成的代码如下,我们重点分析call & ret指令进行的函数调用与返回操作,以及pushl & popl指令进行的栈操作

3.3.2 函数调用栈状态变迁
1. main函数调用f函数时的栈状态

2. f函数调用g函数时的栈状态
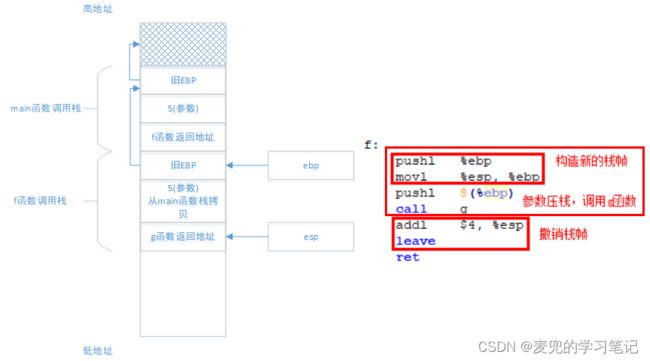
3. g函数函数栈

说明:通过EBP寄存器进行栈回溯
① 从上图中可以看出,各级函数的栈帧通过EBP寄存器串联起来,通过不断索引EBP寄存器的值,就可以实现栈的回溯
② (*ebp)的值就指向f函数调用栈,将(*ebp) + 4就可以取出f函数在调用g函数时压栈的参数。再往上一层,(**ebp)的值就指向main函数调用栈
4. g函数调用ret指令前的栈状态

可见此时ESP栈顶指向g函数的返回地址,在调用ret指令后,该地址将被出栈到EIP寄存器,从而实现函数返回
5. f函数调用ret指令前的栈状态

说明1:构造新的栈帧
① 函数栈是由一系列栈帧堆叠构成的,通过如下指令序列,可以在栈中构造一个新的栈帧
pushl %ebp
movl %esp, %ebp② 上述指令序列与enter指令效果相同
说明2:撤销栈帧
① 通过如下指令序列,可以撤销栈帧
movl %ebp, %esp
popl %ebp② 上述指令序列与leave指令效果相同
3.4 对比ARMv8体系结构中的栈操作
将上节的C语言程序汇编为ARMv8 AArch64格式

3.4.1 寄存器约定用法
在分析ARMv8体系结构栈操作前,需要了解ARMv8体系结构对通用寄存器的约定用法,
1. 栈指针(Stack Pointer,SP)
① 在AArch64中使用sp寄存器
② 指向当前正在使用的栈顶,即栈上的最低地址处(对于递减栈)
2. 帧指针(Frame Pointer,FP)
① 在AArch64中使用x29寄存器
② 指向当前正在使用的栈底,即栈上的最高地址处(对于递减栈)
3. 函数调用返回地址
① 在AArch64中使用x30寄存器
② 调用bl指令进行函数调用时,会将函数返回地址(即pc + 4)保存在x30寄存器
说明:FP和SP之间的内存空间,就是当前正在执行的函数的栈空间
3.4.2 函数调用栈状态变迁
1. main函数调用f函数时的栈状态

2. f函数调用g函数时的栈状态

3. g函数函数栈

说明:可以看出,在AArch64中,可以通过x29寄存器进行栈回溯,具体实例可参考04. 实验1:机器启动 chapter 5
3.5 函数调用栈功能反汇编分析
上面的示例展示了函数调用栈在C语言程序运行过程中的完整变迁状态(也就是通过函数调用栈保存函数调用框架的功能),下面通过示例分布函数函数调用栈的不同功能
3.5.1 保存局部变量
C语言代码如下,
反汇编结果如下,

说明:早期的C语言编译器需要将声明放在代码块的最前面,就是为了方便预留栈空间
后来的编译器更加智能,可以扫描整个函数获取需要为局部变量预留的栈空间,因此不再需要在代码块最前面声明变量
3.5.2 传递参数
C语言代码如下,

反汇编结果如下,

说明1:与局部变量相比,局部变量是压入被调函数栈,函数参数是压入主调函数栈。其实函数参数也只能压入主调参数栈,因为此时被调参数的栈还没有建立
说明2:函数参数压栈顺序
① 函数参数的压栈顺序属于编译器对栈的使用规则,不同版本的编译器规则可能不同
② 对于当前的GCC + IA-32环境,是从右向左压入参数
3.6 实验:通过EBP寄存器实现栈回溯
3.6.1 实验程序框架

首先将stack_test递归调用5层,之后在最后一层进行栈回溯,实验程序框架的执行结果如下,
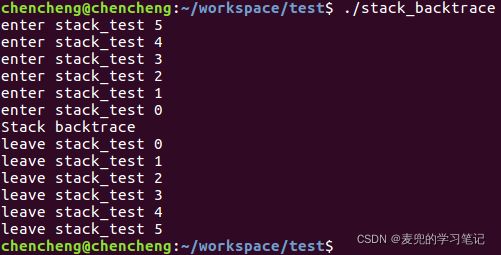
说明:为了避免编译器优化,我们使用如下方式编译该程序
gcc -O0 -o stack_backtrace stack_backtrace.c -m323.6.2 实验程序框架栈分析

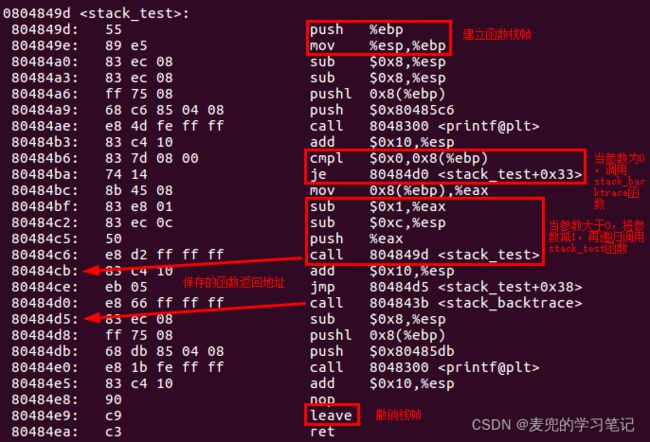

根据上述分析,可以得到如下函数调用栈结构图,其中忽略了对printf等函数调用的栈描述

可见EBP寄存器值将各级函数调用栈连接在一起,只要索引到一级EBP寄存器值,就可以获取上一级函数调用的返回地址与参数
3.6.3 代码实现
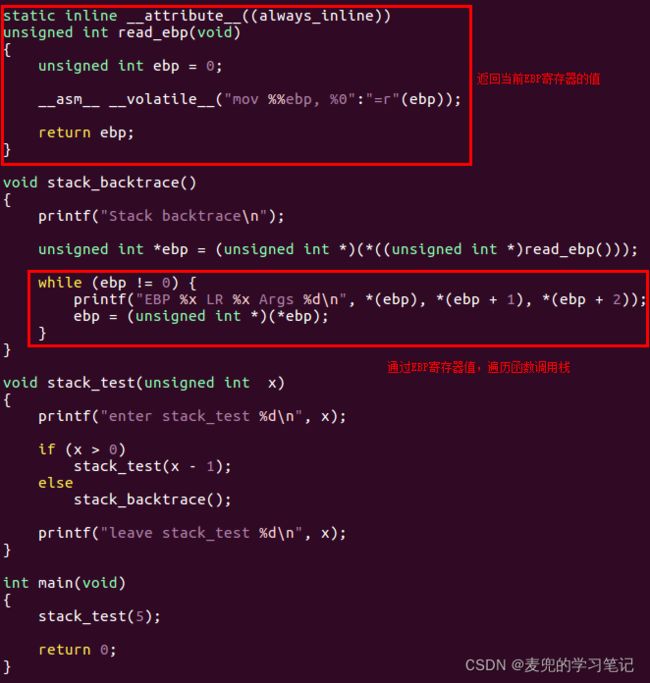
运行效果如下图所示,可见打印结果与上文分析一致

说明:关于__attribute__((always_inline))
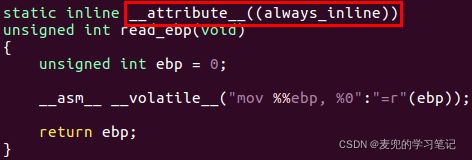
在read_ebp函数的实现中,通过__attribute__((always_inline))属性对函数进行修饰,确保该函数始终内联。如果不加该修改,则读取到的ebp可能是read_ebp函数所在栈帧的EBP寄存器的值,因此会多索引一级函数调用栈

4 基于Linux构造实验操作系统内核
4.1 实验结构概述
1. 使用qemu + Linux 3.9.4内核作为实验环境基础,其中qemu用于虚拟一个IA-32体系结构硬件平台,Linux 3.9.4内核提供实验程序框架
2. 对Linux 3.9.4内核代码进行2处修改,
① 在原有的时钟中断处理函数中增加调用my_timer_handler函数,实验将在该函数中标记是否需要调度
② 在原有的内核启动start_kernel函数中增加调用my_start_kernel函数,实验将在该函数中创建并启动进程
4.2 实验环境搭建
# 安装qemu
sudo apt-get install qemu
# 下载Linux 3.9.4内核代码
wget https://www.kernel.org/pub/linux/kernel/v3.x/linux-3.9.4.tar.xz
# 下载实验环境补丁
wget https://raw.github.com/mengning/mykernel/master/mykernel_for_linux3.9.4sc.patch
# 解压内核代码
xz -d linux-3.9.4.tar.xz
tar -xvf linux-3.9.4.tar
cd linux-3.9.4
# 安装实验环境补丁
patch -p1 < ../mykernel_for_linux3.9.4sc.patch
# 编译内核
make allnoconfig
make
# 启动虚拟机
qemu-system-i386 -kernel arch/x86/boot/bzImage
虚拟机启动后运行状态如下,

说明1:实验环境安装的qemu版本如下
![]()
说明2:在Ubuntu 16.04环境中编译内核时会报出缺少compiler-gcc5.h文件,可以从网上下载该文件并拷贝至内核代码的include/linux目录

4.3 实验框架代码分析
4.3.1 my_timer_handler函数
4.3.1.1 函数实现
文件:linux-3.9.4/mykernel/myinterrupt.c
在my_timer_handler函数中进行打印,标识时钟中断发生

4.3.1.2 函数调用
文件:linux-3.9.4/arch/x86/kernel/time.c
在HPET中断的中断处理函数中调用my_timer_handler函数

说明:IA-32 Linux HPET中断注册过程
① HPET(High Precision Event Timer)是由Intel和Microsoft联合开发的高精度定时器,可提供一组可编程定时器
② HPET的中断处理函数直接调用setup_irq函数进行注册

③ HPET的初始化由hpet_time_init函数完成
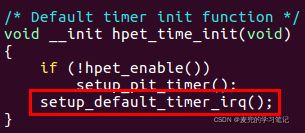
④ IA-32体系结构相关的初始化操作注册在x86_init结构体数组中,就包括对timer相关操作的注册。其中HPET的初始化函数被注册在x86_init.timers.timer_init
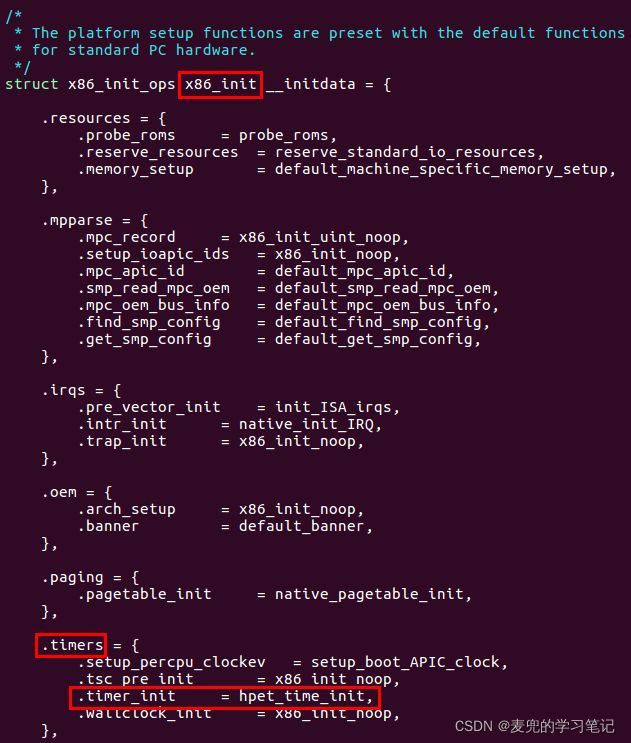
⑤ x86_init.timers.timer_init函数被x86_late_time_init函数调用

⑥ 而x86_late_time_init函数在time_init函数中被注册到late_time_init函数指针

⑦ 在start_kernel函数中调用注册的late_time_init函数,从而实现HPET的初始化


⑧ 而注册late_time_init的time_init函数,也是被start_kernel函数在早些时候调用
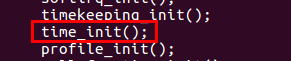
⑨ 下面汇总一下函数的调用过程,
start_kernel(init/main.c)
--> time_init(将x86_late_time_init函数注册到late_time_init函数指针)
--> late_time_init(相当于调用x86_late_time_init函数)
--> x86_init.timers.timer_init(相当于调用hpet_time_init函数)
--> setup_default_timer_irq(注册HPET中断处理函数)4.3.2 my_start_kernel函数
4.3.2.1 函数实现
文件:linux-3.9.4/mykernel/mymain.c
在my_start_kernel函数中构造死循环,进行累积计数与打印,标识内核现场在运行

4.3.2.2 函数调用
文件:linux-3.9.4/init/main.c
在start_kernel函数中调用my_start_kernel函数,从在而利用Linux内核完成系统初始化之后,将执行流切换到实验环境

4.4 进程切换实验
4.4.1 实验内容
1. 在实验操作系统内核中创建多个进程,并启动0号进程
2. 在时钟中断的驱动下,实现进程间的切换
4.4.2 代码实现
4.4.2.1 进程结构定义
为了管理进程,都需要定义相应的进程结构体,实验中定义的PCB结构体如下,可见实验中的进程仅在内核态运行不会切换到用户态
// 进程内核栈为8KB
#define KERNEL_STACK_SIZE 8 * 1024
// 进程状态中与CPU相关的内容
// 可以理解为CPU进程上下文
struct Thread {
// 保存进程当前执行地址
unsigned long ip;
// 保存进程当前栈指针
unsigned long sp;
};
typedef struct PCB {
// 进程ID
int pid;
// 进程状态
// -1 unrunnable, 0 runnable, >0 stopped
volatile long state;
// 进程内核栈
char stack[KERNEL_STACK_SIZE];
// CPU进程上下文
struct Thread thread;
// 进程入口地址
// 也就是进程执行的首条指令的地址
unsigned long task_entry;
// 用于构成PCB单向循环链表
struct PCB *next;
} tPCB;4.4.2.2 创建多个进程
// 静态创建2个进程结构体
tPCB task[MAX_TASK_NUM];
// my_current_task指向当前正在执行的进程结构体
tPCB *my_current_task = NULL;
void my_process(void);
void __init my_start_kernel(void)
{
int i = 0;
// 初始化0号进程
task[0].pid = 0;
// 进程状态为runnable
task[0].state = 0;
// 进程入口地址与CPU进程上下文中的EIP均指向my_process函数
task[0].task_entry = task[0].thread.ip = (unsigned long)my_process;
// 指向该进程内核栈栈顶(地址高端)
// 因为是满减栈,这里计算时其实可以不减1
task[0].thread.sp = (unsigned long)&task[0].stack[KERNEL_STACK_SIZE - 1];
printk("pid[%d] stack: %lx\n", 0, task[0].thread.sp);
// 进程链表中只有1个进程
task[0].next = &task[0];
// 初始化其他进程
for (i = 1; i < MAX_TASK_NUM; i++) {
// 首先拷贝0号进程的PCB作为模板,再进行修改
// 这与fork创建进程的思路一致
memcpy(&task[i], &task[0], sizeof(tPCB));
// 修改进程ID
task[i].pid = i;
// 修改进程状态为unrunnable
task[i].state = -1;
// 修改进程内核栈
task[i].thread.sp = (unsigned long)&task[i].stack[KERNEL_STACK_SIZE - 1];
printk("pid[%d] stack: %lx\n", i, task[i].thread.sp);
// 将新进程加入进程单向循环链表的表尾
task[i].next = task[i - 1].next;
task[i - 1].next = &task[i];
}
// 下面启动0号进程
}说明:构成的PCB单向循环链表如下图所示

4.4.2.3 启动0号进程
void __init my_start_kernel(void)
{
// 初始化进程
// ...
// 启动0号进程
// 当前进程指向task[0]
my_current_task = &task[0];
asm volatile(
// mov task[0].thread.sp, %esp
// 将ESP指针指向task[0]的内核栈
"movl %1, %%esp\n\t"
// pushl task[0].thread.sp
// 本指令的目标是压入EBP,由于当前为空栈,EBP与ESP相同,所以将ESP压栈
// 此时是压入task[0]的内核栈
"pushl %1\n\t"
// pushl task[0].thread.ip
// 将进程入口地址压栈
"pushl %0\n\t"
// ret指令会将栈顶的进程入口地址出栈到EIP寄存器
// 从而实现执行流的切换
"ret\n\t"
// 这条指令不会被执行到,只是出于与之前push EBP的操作对称
"popl %%ebp\n\t"
:
: "c"(task[0].thread.ip), "d"(task[0].thread.sp)
// 0表示task[0].thread.ip,存储在ECX
// 1表示task[0].thread.sp,存储在EDX
);
}说明:启动0号进程的过程,就是构造一个从0号进程返回的场景,结合后续的进程切换过程小节可以更好的理解
4.4.2.4 进程切换时机
1. 在时钟中断中标记是否需要触发进程切换
volatile int time_count = 0;
extern volatile int my_need_sched;
void my_timer_handler(void)
{
if (time_count % 100 == 0 && my_need_sched != 1) {
printk(KERN_NOTICE "\n>>>my_timer_handler here<<<\n");
my_need_sched = 1;
}
time_count++;
}2. 在进程函数中根据my_need_sched值触发进程切换
void my_process(void)
{
int i = 0;
while (1) {
i++;
if (i % 1000000 == 0) {
printk(KERN_NOTICE "this is process %d -\n", my_current_task->pid);
if (my_need_sched == 1) {
printk(KERN_NOTICE "need sched\n");
my_need_sched = 0;
printk(KERN_NOTICE "this is process %d -\n",
my_current_task->pid);
// 触发进程切换
my_schedule();
printk(KERN_NOTICE "this is process %d +\n",
my_current_task->pid);
}
printk(KERN_NOTICE "this is process %d +\n", my_current_task->pid);
}
}
}4.4.2.5 进程切换过程
// 返回当前ESP寄存器的值
// 用于确认当前ESP是指向哪个进程的内核栈
static unsigned long read_sp(void)
{
unsigned long sp = 0;
asm volatile(
"movl %%esp, %0"
:"=m" (sp)
:
);
return sp;
}
void my_schedule(void)
{
tPCB *next = NULL;
tPCB *prev = NULL;
unsigned int sp = 0;
if (my_current_task == NULL || my_current_task->next == NULL)
return;
// 判断当前进程
printk(KERN_NOTICE ">>>my_schedule current is %d<<<\n",
my_current_task->pid);
sp = read_sp();
printk(KERN_NOTICE "1:sp = %lx\n", sp);
// 确定切换的前后进程
next = my_current_task->next;
prev = my_current_task;
printk("1:next is %d prev is %d\n", next->pid, prev->pid);
if (next->state == 0) {
// 要切换到的目标进程已经运行过
asm volatile(
// 将EBP压入当前进程内核栈
"pushl %%ebp\n\t"
// movl %esp, prev->thread.sp
// 保存要切换走的进程的内核栈指针到CPU进程上下文
"movl %%esp, %0\n\t"
// movl next->thread.sp, %esp
// 切换内核栈
// 这条命令执行后,ESP将指向目标进程内核栈
"movl %2, %%esp\n\t"
// movl $1f, prev->thread.ip
// 保存要切换走的进程下次继续执行的地址到CPU进程上下文
// 保存的是标号1的地址,也就是说,当该进程返回时,将从标号1的位置继续执行
"movl $1f, %1\n\t"
// pushl next->thread.ip
// 将目标进程继续执行的地址压入目标进程内核栈
"pushl %3\n\t"
// ret指令将上条指令压入的next->thread.ip出栈到EIP,实现执行流的切换
// 这条命令执行后,执行流就切换到目标进程
"ret\n\t"
// 进程被切换回来后,从该标号地址开始执行
"1:\t"
// 此处将保存在内核栈上的ebp寄存器值出栈
// 与这段内嵌汇编入口的pushl %%ebp对应
"popl %%ebp\n\t"
: "=m" (prev->thread.sp), "=m" (prev->thread.ip)
// 输出部分
// 0表示prev->thread.sp,存储在内存中,只写
// 1表示prev->thread.ip,存储在内存中,只写
: "m" (next->thread.sp), "m" (next->thread.ip)
// 输入部分
// 2表示next->thread.sp,存储在内存中
// 3表示next->thread.ip,存储在内存中
);
// 这段打印的作用后续会分析
printk(KERN_NOTICE "2:sp = %lx\n", sp);
printk("2:next is %d prev is %d\n", next->pid, prev->pid);
printk(KERN_NOTICE "before %d\n", my_current_task->pid);
// 切换当前进程指针,指向切换的目标进程
my_current_task = next;
printk(KERN_NOTICE "after %d\n", my_current_task->pid);
printk(KERN_NOTICE ">>>switch1 %d to %d <<<\n", prev->pid, next->pid);
} else {
// 要切换到的目标进程没有运行过
// 将目标进程状态修改为runnable
next->state = 0;
// 切换当前进程指针,指向切换的目标进程
my_current_task = next;
printk(KERN_NOTICE "switch2 %d to %d <<<\n", prev->pid, next->pid);
// 切换进程
asm volatile(
// 将EBP压入当前进程内核栈
"pushl %%ebp\n\t"
// movl %esp, prev->thread.sp
// 保存要切换走的进程的内核栈指针到CPU进程上下文
"movl %%esp, %0\n\t"
// movl next->thread.sp, %esp
// 切换内核栈
// 这条命令执行后,ESP将指向目标进程内核栈
"movl %2, %%esp\n\t"
// movl next->thread.sp, %ebp
// 由于进程是首次运行,所以内核栈为空栈,EBP与ESP相同
"movl %2, %%ebp\n\t"
// movl $1f, prev->thread.ip
// 保存要切换走的进程下次继续执行的地址到CPU进程上下文
// 保存的是标号1的地址,也就是说,当该进程返回时,将从标号1的位置继续执行
// 注意,这里的1标号在上面的if分支中定义,但是在else分支中依然可以使用
"movl $1f, %1\n\t"
// pushl next->thread.ip
// 将目标进程继续执行的地址压入目标进程内核栈
// 对于首次运行的进程,压入的是my_process函数的地址
"pushl %3\n\t"
// ret指令将上条指令压入的next->thread.ip出栈到EIP,实现执行流的切换
// 这条命令执行后,执行流就切换到目标进程
// 在else分支切换出去的进程,返回后也是从标号1处继续执行
"ret\n\t"
: "=m" (prev->thread.sp), "=m" (prev->thread.ip)
// 输出部分
// 0表示prev->thread.sp,存储在内存中,只写
// 1表示prev->thread.ip,存储在内存中,只写
: "m" (next->thread.sp), "m" (next->thread.ip)
// 输入部分
// 2表示next->thread.sp,存储在内存中
// 3表示next->thread.ip,存储在内存中
);
}
}说明1:由于栈是由ESP和EBP寄存器共同指向和维护的,所以在进程切换过程中,需要保存和恢复这2个寄存器
其中对EBP寄存器的保存和恢复,依靠相应的进程内核栈
说明2:上述进程切换过程只是切换了内核栈(ESP & EBP)和执行流(EIP),并没有涉及其他资源,因此更像是一般操作系统中的线程切换
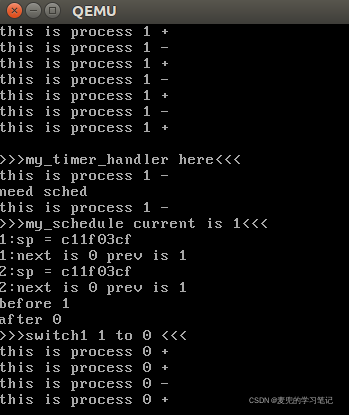
4.4.3 运行结果
可见2个进程之间可以在时钟中断的驱动下定期进行切换
4.4.4 实验疑问与分析
4.4.4.1 实验疑问
在进行实验的过程中,对于如下设置my_current_task指针的操作位置有疑惑

实验代码将对my_current_task指针的赋值放在进程切换之后,但是这里是有问题的,
1. prev和next是my_schedule函数中的局部变量,应该存储在调用my_schedule函数的进程的内核栈中
2. 假设当前是从0号进程切换到1号进程,则是由0号进程调用my_schedule函数,此时经过计算后,prev指向0号进程,next指向1号进程
在本次切换中,我们是期望将my_current_task指向1号进程
3. 但是实验代码中设置my_current_task的时机,是在进程切换之后。假设是从0号进程切换到1号进程,只有当切换回1号进程时,才会执行到设置my_current_task的语句
但是在返回的1号进程中,由于当时是从1号进程切换到0号进程,所以prev指向1号进程,next指向0号进程,那么此时给my_current_task设置的就是指向0号进程
4. 根据分析,如实验代码中设置my_current_task的方式应该不能正常工作,但是实际上却可以工作。经过增加各种打印,均不能解释疑惑,所以只能上GDB调试
4.4.4.2 调试环境搭建
4.4.4.2.1 编译带有调试信息的内核
之前编译的Linux内核并未带有调试信息,所以在使用GDB调试时无法通过对应的vmlinux文件获取到符号表
需要通过make menuconfig命令进入内核配置界面,并选择如下选项,
Kernel hacking
--> Compile the kernel with debug info
4.4.4.2.2 使用qemu + GDB调试内核
1. 在shell中以如下命令启动内核
qemu-system-i386 -kernel arch/x86/boot/bzImage -S -s
# -S: freeze CPU at startup (use 'c' to start execution)
# -s: shorthand for -gdb tcp::1234
# -gdb dev: wait for gdb connection on 'dev'2. 在另一个shell中以如下命令启动GDB
gdb --tui
# 我们是在内核源码目录执行该命令
# 这主要影响索引vmlinux文件的路径GDB启动后的界面如下,

3. 在GDB中读取符号表

4. 连接qemu中启动的GDB Server

5. 显示寄存器窗口
此时便可以在调试界面中实时显示寄存器状态

4.4.4.3 调试过程
4.4.4.3.1 进程内核栈地址值
首先将端点设置在my_start_kernel函数中,查看2个进程的内核栈地址值,后续可以据此判断在进程切换过程中,栈是否切换成功
将my_start_kernel函数运行到启动0号进程之前,此时2个进程的PCB已经初始化完毕,可以查看相应的内核栈地址


4.4.4.3.2 启动0号进程
经过验证,启动0号进程的内嵌汇编语句在调试时无法进入内部逐条命令进行调试,当内嵌汇编语句执行完成后,ESP和EIP寄存器状态如下。可见此时ESP确实指向0号进程的内核栈

说明:同时可以发现,此时EBP寄存器的值无明确意义,因为此时0号进程内核栈上尚未建立栈帧
4.4.4.3.3 从0号进程切换到1号进程
将断点设置在my_schedule函数,第一次执行到该函数时,说明要从0号进程切换到1号进程
1. ESP寄存器当前指向0号进程的内核栈

2. 由于是从0号进程切换到1号进程,所以计算出的prev指向0号进程,next指向1号进程

3. 由于1号进程尚未运行过,所以会进入my_schedule函数的else分支执行


4. 在切换到1号进程之前,将my_current_task指针指向1号进程


5. 在切换进程的内嵌汇编语句执行完成后,ESP、EBP和EIP寄存器状态如下,
① ESP和EBP均指向1号进程内核栈,即栈切换成功
② EIP指向my_process函数,即执行流切换到1号进程入口点
![]()
![]()
4.4.4.3.4 从1号进程切换到0号进程
继续执行程序,当再次执行到my_schedule函数时,说明要从1号进程切换到0号进程
1. ESP寄存器当前指向1号进程的内核栈

2. 由于是从1号进程切换到0号进程,所以计算出的prev指向1号进程,next指向0号进程

3. 由于0号进程已经运行过,所以会进入my_schedule函数的if分支执行


4. 在切换进程的内嵌汇编语句执行完成后,ESP、EBP和EIP寄存器状态如下,
① ESP指向0号进程内核栈,即栈切换成功
② EIP指向标号1之后继续运行,这是当时从0号进程切换走时保存的0号进程返回地址

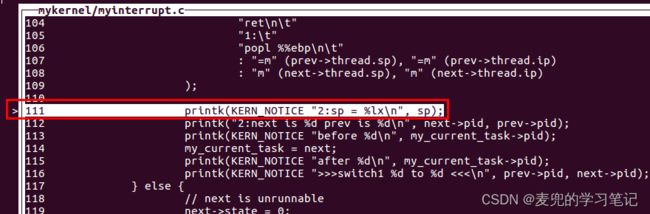
也就是说此时已经切换回0号进程继续执行,并且ESP也已经指向0号进程的内核
5. 根据我的理解,由于已经回到了0号进程内核栈,因此此时的prev应该指向0号进程,next应该指向1号进程。此时再使用next设置my_current_task指针,应该是不符合预期的(希望my_current_task指向0号进程,但是在当前栈中,my_current_tast会指向1号进程)
但实际的情况是,prev仍然指向1号进程,next指向0号进程。这与上文的分析是不符的

6. 经过破案,实际情况与分析不符的原因,是因为prev和next局部变量的地址始终保存在ebx和esi寄存器中,随着进程内核栈的切换,ebx和esi寄存器中的值其实没有变换过。因此,相当于prev和next局部变量一直使用的都是0号进程内核栈上的那份


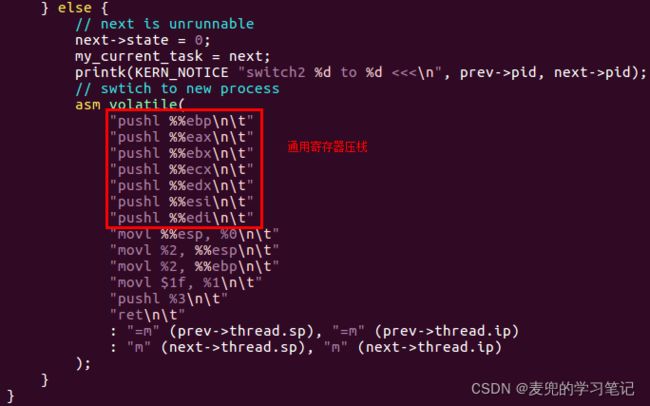
4.4.4.4 原因分析
导致该问题的原因是实验代码的栈切换是一种不完全的栈切换,只是保存了EBP / ESP / EIP,并没有保存完整的进程上下文(e.g. 其他通用寄存器)。从该问题的分析也可以看出保存进程上下文在进程切换中的重要作用
可以通过在代码中增加通用寄存器的保存与恢复来解决该问题,如下图所示,