一篇让你读懂java中的字符串(String)
目录
- 创建字符串
-
- 方式1
- 方式2
- 方式3
- 三种方式的内存图
-
- 方式1 方式2
- 方式3
- 总结
- 理解池的概念
- 回忆引用
- 字符串判断相等
-
- 判断字符串引用是否相等
- 代码1
- 代码2
- 代码3
- 代码4
- 总结
- 判断字符串内容是否相等
-
- 变量与变量进行比较
- 字符串常量与变量进行比较
- 理解字符串不可变
-
- 反射打破字符串不可变
- 字符与字符串
-
- 代码示例1:获取指定位置的字符
- 代码示例2:将字符数组所有内容变为字符串进行输出
- 代码示例3: 将字符数组部分内容变为字符串进行输出
- 代码示例4: 字符串与字符数组的转换
- 小练习:字符串的逆置
- 字节与字符串
-
- 代码示例1: 将整个字节数组转变为字符串
- 代码示例2: 将部分字节数组内容变为字符串
- 代码示例3: 将字符串以字节数组的方式返回
- 代码示例4:编码转换处理
-
- 情况1 当字符串为英文
- 情况2 当字符串为中文(分编码格式不同的情况)
- 总结
- 字符串常规操作
-
- 字符串比较
-
- 区分大小写比较
- 不区分大小写比较
- 比较两个字符串大小关系(conpareTo方法)
-
- 代码:观察conpareTo比较
- 字符串查找
-
- 代码示例1:contains方法
- 代码示例2:indexOf(String str)方法
- 代码示例3:indexOf(String str,int fromIndex)方法
- 代码示例4:lastIndexOf(String str)方法
- 代码示例5:lastIndexOf(String str,int fromIndex)方法
- 代码示例6:startsWith(String prefix)方法
- 代码示例7:startsWith(String prefix,int toffset)方法
- 代码示例8:endsWith方法
- 字符串替换处理
-
- 代码示例1:replaceAll方法
- 代码示例2:replaceFirst方法
- 代码示例3::replace方法
- 字符串拆分(用的非常多,需要多注意)
-
- 代码示例1:split(String regex)方法
- 代码示例2:split(String regex,int limit)方法
- 代码示例3:特殊情况
-
- 情况1:拆分ip地址这类(单个分隔符)
- 情况2:多个分隔符的拆分(使用连字符“|”)
- 字符串截取
-
- 代码示例1:substring(int beginIndex)方法
- 代码示例2:substring(int beginIndex,int endIndex)
- 其他操作方法
-
- trim方法
- toUpperCase方法
- toLowerCase方法
- intern方法(前面已经讲过)
- concat方法(不经常用,不做过多赘述)
- length方法
- isEmpty方法
- join方法
- StringBuffer 和 StringBuilder
-
- 代码示例
- String与StringBuffer(StringBuilder)的转换
- 总结
-
- String与StringBuffer,StringBuilder的区别(面试题)
- StringBuffer与StringBuilder区别(面试题)
- String与StringBuilder区别(面试题)
- 小结
- String练习题
-
- 练习题1
-
- 练习题2
创建字符串
创建字符串一共有三种方式:
方式1
String str1= "abc";
System.out.println(str1);
//输出结果
abc
方式2
String str2= new String("abc");
System.out.println(str2);
//输出结果
abc
方式3
char[] value={'a','b','c'};
String str=new String(value);
System.out.println(str);
//输出结果
abc
三种方式的内存图
方式1 方式2

在这里我们首先介绍一下字符串常量池的概念:
String类的设计使用了共享设计模式
在JVM底层实际上会自动维护一个对象池,这个对象池称为字符串常量池
对于方式1中的赋值形式来说,因为是直接赋值,所以赋值的内容将自动保存到字符串常量池当中,此时abc存入了字符串常量池,并将abc得地址0x999赋给了str1这个引用
对于方式2的赋值形式来说,如果字符串常量池当中有abc,就直接将abc的地址0x999赋给value数组,然后再将String类在堆上实例化的对象的地址0x888赋给str2引用,如果字符串常量池当中没有abc,那么就把新开辟的字符串对象abc存入常量池当中以供下次使用,然后把存进去的abc的地址赋给value数组,然后再将String类在堆上实例化的对象的地址0x888赋给str2引用,至于这里为什么出现了value数组,需要仔细剖析:
- 首先我们进行了String这个类的对象的实例化操作,所以一定会在堆上开辟内存.
- 此时再来看
String类的有参构造函数中参数为字符串的情况

可以看到我们将original的值赋给了value,再来看String类中value这个成员变量到底是什么把?

可以看到是私有的且被final所修饰的char类型的value数组
注意:被final所修饰的成员变量此时在String类中并没有进行初始化,所以需要在构造方法中进行初始化,所以这也是为什么this.value=original.val出现的原因.因为value这个数组此时并没有直接初始化,所以通过构造方法进行 传参从而对value这个数组进行初始化.
方式3
方式3的赋值方式的内存图如下:

我们来分析下为什么是这样画的:
首先value是一个局部变量,所以先在栈上开辟内存,同时在堆上开辟内存存储’a’,‘b’,‘c’,‘d’,'e’这五个元素,接下来再继续在栈上开辟内存,存储str3这个局部变量.同时在栈上开辟内存存储String这个类的实例化对象.
接下来我们来看String这个类的有参构造函数中参数为数组时的源码的情况:
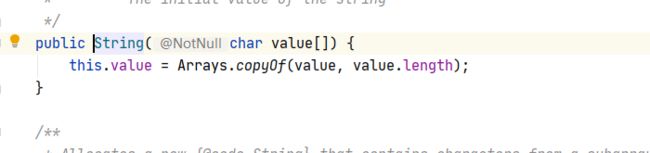
我们会发现其使用了copyof方法拷贝了一个新的数组,而新拷贝的数组其实就是我们的value数组的复制品.相当于是将拷贝后的数组赋值给了String类中所定义的value数组.
所以就如图中所画的一样,此时新拷贝的数组的地址为0x888,将这个地址赋值给String类中的成员变量value数组,然后再将String类在堆上的实例化对象的地址0x999赋值给我们的str3这个引用.
总结
这三种创建字符串常量的方式,底层其实都与源码中被private和final所修饰的char类型的数组有关
理解池的概念
“池” 是编程中的一种常见的, 重要的提升效率的方式, 我们会在未来的学习中遇到各种 “内存池”, “线程池”, “数据库连接池” …
然而池这样的概念不是计算机独有, 也是来自于生活中. 举个栗子:
现实生活中有一种女神, 称为 “绿茶”, 在和高富帅谈着对象的同时, 还可能和别的屌丝搞暧昧. 这时候这个屌丝被称为 “备胎”. 那么为啥要有备胎? 因为一旦和高富帅分手了, 就可以立刻找备胎接盘, 这样 效率比较高.
如果这个女神, 同时在和很多个屌丝搞暧昧, 那么这些备胎就称为 备胎池.
回忆引用
我们曾经在讲数组的时候就提到了引用的概念.
引用类似于 C 语言中的指针, 只是在栈上开辟了一小块内存空间保存一个地址. 但是引用和指针又不太相同, 指针能进行各种数字运算(指针+1)之类的, 但是引用不能, 这是一种 “没那么灵活” 的指针.
另外, 也可以把引用想象成一个标签, “贴” 到一个对象上. 一个对象可以贴一个标签, 也可以贴多个. 如果一个对象上面一个标签都没有, 那么这个对象就会被 JVM 当做垃圾对象回收掉.
Java 中数组, String, 以及自定义的类都是引用类型.
由于 String 是引用类型, 因此对于以下代码
String str1 = "Hello";
String str2 = str1;
内存图如下所示:

此时两个引用指向了同一个对象
那么有同学可能会说, 是不是修改 str1 , str2 也会随之变化呢?下面来看一段代码:
String str1 = "Hello";
String str2 = str1;
str1 = "hello";
System.out.println(str2);
System.out.println(str1);
事实上,这样的代码并不算 “修改” 字符串, 而是让 str1 这个引用指向了一个新的 String 对象.
内存图如下所示:

因为字符串是一种不可变对象(接下来会细讲),它的内容不可变,Sting类的内部实现也是基于char[]来实现的,因为String类源码中定义char[]类型时是如下格式:
![]()
也就是说char[]类型的数组被final所修饰时,其地址是不能被修改的,假如我们此时修改了Hello字符串的首字母H改为小写h,相当于产生了一个新的字符串常量hello,那么在常量池上就相当于产生了一个新的对象,就要分配新的地址,就不可能在原来Hello的地址上将其改为hello了,所以就如上图所示了
那么要想在原地址改为hello,需要用到反射,在下面字符串不可变那一章节我们会介绍反射这个概念。
字符串判断相等
判断字符串引用是否相等
如果现在有两个int型变量,判断其相等可以使用 == 完成。
int x = 10 ;
int y = 10 ;
System.out.println(x == y);
// 执行结果
true
如果说现在在String类对象上使用 == ,就是判断引用是否相等,来看下面几段代码,并判断字符串的引用是否相等
代码1
String str1 = "Hello";
String str2 = "Hello";
System.out.println(str1 == str2);
// 执行结果
true
代码1内存布局:

我们发现, str1 和 str2 是指向同一个对象的. 此时如 “Hello” 这样的字符串常量是在 字符串常量池 中.
如 “Hello” 这样的字符串字面值常量, 也是需要一定的内存空间来存储的. 这样的常量具有一个特点, 就是不需要修改(常量嘛). 所以如果代码中有多个地方引用都需要使用 “Hello” 的话, 就直接引用到常量池的这个位置就行了, 而没必要把 “Hello” 在内存中存储两次.也就是说我们每次在创建字符串的时候便会看常量池当中到底有没有当前所需要创建的字符串,如果有就不用在常量池中再创建一次了。
代码2
String str = "abc";
String str2 = new String("abc");
System.out.println(str1 == str2);
//输出结果
false
代码2 内存图如下

我们会发现此时最终代码结果为false.
原因如图所示:str1与str2引用所指向的对象均不相同,所以其存储的地址也是不相同的,那么最终的比较一定为false.
那么在这个地方假如我们想让str1与str2这两个引用所存储的地址相同的话,此时便引入了一特殊的概念:即手工入池:利用intern()方法
首先来看代码:
String str1 = "hello" ;
String str2 = new String("hello") ;
System.out.println(str1 == str2);
// 执行结果
False
---------------------------------------------------------------------
String str1 = "hello" ;
String str2 = new String("hello").intern() ;
System.out.println(str1 == str2);
// 执行结果
true
来看这份代码的内存图:
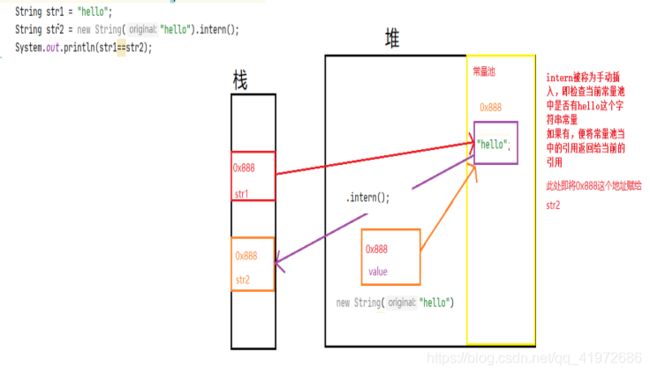
我们可以看到此时str1与str2引用的地址相同,这是为什么呢?
答:这便是intern()方法的功劳,intern被称为手工入池处理,对于
String str2 = new String(“hello”).intern() ; 这段代码来说,是检查此时字符串常量池当中是否有hello这个字符串常量,如果有,便将常量池中的引用返回给当前的引用,对于上述代码来说,此时常量池中是有hello这个字符串常量的,那么就将其在常量池当中的地址赋给引用str2,则str1与str2此时拥有相同的地址了,最终str1==str2结果为true.
代码3
1.public static void main(String[] args) {
2. String str1 = "hello";
3. String str2 = "hel" + "lo";//字符串常量在编译时就已经完成了字符串的拼接,所以此处等价于 String str2= "hello";
4. String str3 = new String("hel") + "lo";
5. String str4 = new String("hel") + new String("lo");
6.
7. //true
8. System.out.println(str1 == str2);
9. //false
10. System.out.println(str3 == str1);
11. //false
12. System.out.println(str1 == str4);
13. //false
14. System.out.println(str3 == str4);
15.}
首先来看str1与str2,str3的比较:

此时我们str2中我们会发现是两个字符串常量在相加,常量相加有一个特点就是其在编译时期就已经确定了,所以此时如果两个字符串常量相加的话就等价于拼接后的字符串,那么str1==str2最后的结果便为true
现在来看str3,此时是一个new String对象加一个字符串常量,在内存中可以看到此时String对象中是是hel字符串,在常量池中并没有,则放入常量池中,然后字符串常量lo也没有,也放进去,则此时堆上的对象指向常量池当中的hel
我们的代码为两者的拼接,那么就会在堆上开辟一个新的内存去存储两者拼接后的新字符串hello,然后将这个新拼接的对象的地址赋给我们的str3引用,很显然这是跟str1完全不一样的地址,所以最终str1==str3的值为false
下面是str1与str4的比较:
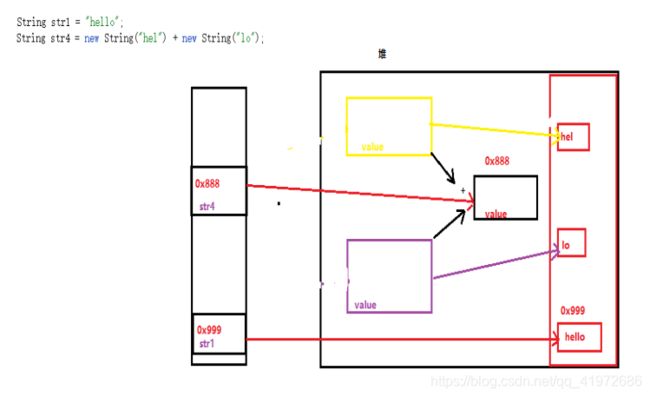
同样我们可以看到是两个不同的地址,所以最终结果为false
代码4
1.public static void main(String[] args) {
2. String str1 = "hello";
3. String str2 = "world";
4. //st1是变量,变量在程序运行时才知道里面存储的内容
5. String str3 = str1 + "world";
6. //两个字符串常量相加在编译时期就已经确定了,所以等价为helloworld
7. String str4 = "hello" + "world";
8. String str5 = "helloworld";
9. String str6=str1+str2;
10. //false
11. System.out.println(str3 == str5);
12. //true
13. System.out.println(str4 == str5);
14. //false
15. System.out.println(str5==str6);
16. }
此时我们可以看到str3中是一个变量和常量相加,在这里要注意,str1是变量,变量是只有在运行时才知道里面存储的是什么。而常量是编译时期就已经确定了,所以str3==str5为false。
Str4中是两个常量相加,而常量在编译的时候就已经确定了,所以str4等价于str5,则str4==str5为true
Str6同样为两个变量相加,变量是只有在运行时才知道里面存储的是什么,所以str5str6, str6str4都为false.
总结
String中使用==比较的时候比较的并不是其字符串内容是否相等,而比较的是两个引用类型地址是是否相同,也就是判断这两个引用是否指向了相同的对象,
判断字符串内容是否相等
如果要判断字符串的内容是否相等,此时就需要使用equals关键字
变量与变量进行比较
String str1 = new String("Hello");
String str2 = new String("Hello");
System.out.println(str1.equals(str2));
// System.out.println(str2.equals(str1)); // 或者这样写也行
// 执行结果
true
字符串常量与变量进行比较
现在需要比较 str 和 “Hello” 两个字符串是否相等, 我们该如何来写呢?
String str = new String("Hello");
// 方式一
System.out.println(str.equals("Hello"));
// 方式二
System.out.println("Hello".equals(str));
在上面的代码中, 哪种方式更好呢?
我们更推荐使用 "方式二". 一旦 str 是 null, 方式一的代码会抛出空指针异常, 而方式二不会.例如:
String str = null;
// 方式一
System.out.println(str.equals("Hello")); // 执行结果抛出 java.lang.NullPointerException 异常
// 方式二
System.out.println("Hello".equals(str)); // 执行结果 false
理解字符串不可变
字符串是一种不可变对象. 它的内容不可改变.
String 类的内部实现也是基于 char[] 来实现的, 但是这个char[]数组是私有的且被final所修饰的数组,String 类并没有提供 set 方法之类的来修改这个char类型的字符数组.
所以原则上来说字符串是一种不可变的对象,每创造一个新的字符串常量都要在字符串常量池当中重新开辟内存存储.
感受下形如这样的代码:
String str = "hello" ;
str = str + " world" ;
str += "!!!" ;
System.out.println(str);
// 执行结果
hello world!!!
形如 += 这样的操作, 表面上好像是在原地址修改了字符串, 其实不是. 内存变化如下:

+= 之后 str 打印的结果的确是变了, 但并不是在str引用第一次指向的对象“hello”的地址上原地发生拼接, 而是每次拼接完成后就要在常量池中开辟临时内存去存储新拼接的临时变量.因为每个字符串都是不可变的,相当于如果按照上述方法的话每次拼接完成后实际上都是一个新的对象,新的对象每次挨个存储在常量池中,str引用最终指向最后一个临时变量.
那么假如我们要拼接100次,例如下面的代码,那么就会在堆内存中的字符串常量池产生99个临时变量,这种方法是不可取的。这样的代码以后尽量不要出现在项目当中
1.public static void main(String[] args) {
2. String str1 = "abc";
3. for(int i = 0;i <= 100;i++) {
4. //要创造99个临时变量
5. str1 += i;
6. }
7. System.out.println(str1);
7.}
那么对于在循环中进行拼接产生大量临时变量,降低效率的情况,我们改怎样做呢?
此时需要用到
StringBuffer和StringBuilder可以来处理在循环过程中拼接的这样一个过程(单线程使用StringBuilder,多线程使用StringBuffer),使用两者共有的append方法进行拼接,append方法的拼接是不会产生临时变量的,后续我们在String与StringBuilder的 区别一栏中会给出详细解答,大家可以直接通过目录进行跳转,观看解答.
到了这里,我们可以了解到,字符串常量因为底部源码实现的问题,它是不可变的,每次所创建的新的字符串原则上是不能在原字符串上进行修改变动的,必须在堆内存上的字符串常量池中创建新的内存来存储变动的字符串,但是java中的反射打破了这一规则,当然后续我们也会仔细去讲解反射,现在我们就来大致了解下反射,以及如何通过反射来打破字符串不可变这一规则:
反射打破字符串不可变
还是来看之前的一段代码:
之前我们想将str1的“Hello”改成"hello"怎么做的呢?
常见办法:借助原字符串, 创建新的字符串
String str = "Hello";
str = "h" + str.substring(1);
System.out.println(str);
// 执行结果
hello
那么利用反射该怎么做呢?
使用 "反射" 这样的操作可以破坏封装, 访问一个类内部的 private 成员
IDEA 中 ctrl + 左键 跳转到 String 类的定义, 可以看到内部包含了一个 char[] , 保存了字符串的内容.被private所修饰,但是此时String类中并没有提供对这个数组的set方法.

代码如下:
public static void main(String[] args) {
String str1 = "abc";
//Class对象
Class c1 = String.class;
//getDeclaredField方法可能会抛出NoSuchFieldException异常,需要被捕获
try {
// 获取 String 类中的 value 字段. 这个 value 和 String 源码中的 value 是匹配的.
Field field = c1.getDeclaredField("value");
// 将这个字段的访问属性设为 true
field.setAccessible(true);
//get方法可能会抛出IllegalAccessException异常,需要捕获.
try {
// 把 str1 中的 value 属性获取到.
char[] value = (char[]) field.get(str1);
//这块打印下获取到的value属性发现是【a,b,c】
System.out.println(Arrays.toString(value));
//打印下修改前的str1的值,为abc
System.out.println(str1);
// 修改 value 的值
value[0]='G';
//打印修改后的str1的值,为Gbc
System.out.println(str1);
} catch (IllegalAccessException e) {
e.printStackTrace();
}
} catch (NoSuchFieldException e) {
e.printStackTrace();
}
}
字符与字符串
字符串内部包含一个字符数组,String 可以和 char[] 相互转换.
代码示例1:获取指定位置的字符
String str = "hello" ;
System.out.println(str.charAt(0)); // 下标从 0 开始
// 执行结果
h
System.out.println(str.charAt(10));
// 执行结果如果超出下标范围,产生 StringIndexOutOfBoundsException 异常
代码示例2:将字符数组所有内容变为字符串进行输出
1.char[] value = {'a', 'b', 'c', 'd'};
2.String str = new String(value);
//输出结果为abcd
3.System.out.println(str);
代码示例3: 将字符数组部分内容变为字符串进行输出
1.char[] val = {'a', 'b', 'c', 'd'};
2.String str1 = new String(value, 1, 3);
3.//输出结果为bcd
4.System.out.println(str1);
offet为偏移量,是计算从哪个下标开始(下标从0开始奇数),例如为1就是从第二个数组元素开始,count为往后要的个数
假如此时个数超过了数组元素或者offset超过了数组长度-1,那么会发生StringIndexOutOfBoundsException异常
代码示例4: 字符串与字符数组的转换
String str = "helloworld" ;
// 将字符串变为字符数组
char[] data = str.toCharArray() ;
for (int i = 0; i < data.length; i++) {
System.out.print(data[i]+" ");
}
小练习:字符串的逆置
方法:先使用toCharArray方法将字符串转变为字符数组,然后再将char类型数组转变为字符串返回(共有三种方法返回).
public static String reverse(String string) {
//字符串转为数组
char[] chars = string.toCharArray();
int i = 0;
int j = chars.length-1;
while (i < j) {
char tmp = chars[i];
chars[i] = chars[j];
chars[j] = tmp;
i++;
j--;
}
//数组转化为字符串(三种方法)
//return new String(chars);
//return String.copyValueOf(chars);
return String.valueOf(chars);
}
字节与字符串
字节常用于数据传输以及编码转换的处理之中,String 也能方便的和 byte[] 相互转换.

代码示例1: 将整个字节数组转变为字符串
注意将字节数组转变为字符串时,是按照unicode编码进行转换的,例如97这个数字在unicode表中对应a这个字母
1.byte[] bytes={97,98,99,100,101,102};
2.String str=new String(bytes);
3.//输出结果为abcdef
4.System.out.println(str);
代码示例2: 将部分字节数组内容变为字符串
1.byte[] bytes1={97,98,99,100,101,102};
2.String str2=new String(bytes1,1,3);
3.//输出结果为bcd
4.System.out.println(str2);
代码示例3: 将字符串以字节数组的方式返回
1.String string="abcde";
2.byte[] bytes2=string.getBytes();
3.//输出结果为[97, 98, 99, 100, 101]
4.System.out.println(Arrays.toString(bytes2));
代码示例4:编码转换处理
情况1 当字符串为英文
String str3 = "gaobo";
try {
byte[] bytes3 = str3.getBytes("gbk");
System.out.println(Arrays.toString(bytes3));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
//输出结果
[103, 97, 111, 98, 111]
当字符串转变为字节数组的时候,此时我们字符串为英文,我们设置编码格式不管是gbk或者是utf8,最终的输出结果都是一样的
情况2 当字符串为中文(分编码格式不同的情况)
String str3 = "高博";
try {
byte[] bytes3 = str3.getBytes("gbk");
System.out.println(Arrays.toString(bytes3));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
//输出结果
[-72, -33, -78, -87]
当字符串转变为字节数组的时候,此时我们字符串为中文,我们设置编码格式不同,最终的输出结果都是不一样的,例如针对上述代码,gbk的输出结果为[-72, -33, -78, -87].
String str3 = "高博";
try {
byte[] bytes3 = str3.getBytes("utf8");
System.out.println(Arrays.toString(bytes3));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
//输出结果
[-23, -85, -104, -27, -11, -102]
当编码格式为utf8的时候,输出结果为[-23, -85, -104, -27, -115, -102]
总结
那么何时使用 byte[], 何时使用 char[] 呢?
- byte[] 是把 String 按照一个字节一个字节的方式处理,
这种适合在网络传输, 数据存储这样的场景下使用. 更适合针对二进制数据来操作. - char[] 是把 String 按照一个字符一个字符的方式处理,
更适合针对文本数据来操作, 尤其是包含中文的时候.
回忆概念: 文本数据 vs 二进制数据
一个简单粗暴的区分方式就是用记事本打开能不能看懂里面的内容.
如果看的懂, 就是文本数据(例如 .java 文件), 如果看不懂, 就是二进制数据(例如 .class 文件).
字符串常规操作
字符串比较
上面使用过String类提供的equals()方法,该方法本身是可以进行区分大小写的相等判断。除了这个方法之外,String 类还提供有如下的比较操作:

区分大小写比较
String str1 = "hello" ;
String str2 = "Hello" ;
System.out.println(str1.equals(str2));
// 输出结果
false
不区分大小写比较
String str1 = "hello" ;
String str2 = "Hello" ;
System.out.println(str1.equalsIgnoreCase(str2));
// 输出结果
true
比较两个字符串大小关系(conpareTo方法)
在String类中compareTo()方法是一个非常重要的方法,该方法返回一个整型,该数据会根据大小关系返回三类内容:
1.相等:返回0.
2.小于:返回内容小于0.
3.大于:返回内容大于0。
代码:观察conpareTo比较
System.out.println("A".compareTo("a")); // -32
System.out.println("a".compareTo("A")); // 32
System.out.println("A".compareTo("A")); // 0
System.out.println("AB".compareTo("AC")); // -1
System.out.println("刘".compareTo("杨")); //-5456
compareTo()是一个可以区分大小关系的方法,是String方法里是一个非常重要的方法。
它的比较规律如下:
字符串的比较大小规则:总结成三个字 “字典序” 相当于判定两个字符串在一本词典的前面还是后面. 先比较第一个字符的大小(根据 unicode 的值来判定), 如果不分胜负, 就依次比较后面的内容例如AB和AC中,一开始先比较A和A,发现两个相同则为0,继续往下比,B和C在unicode表中对应的数字分别为66,67,可以看出来B比C要小,所以返回负数,这个负数的数字为66-67=-1.
字符串查找
从一个完整的字符串之中可以判断指定内容是否存在,对于查找方法有如下定义

代码示例1:contains方法
String str = "helloworld" ;
System.out.println(str.contains("world")); // true
contains方法的判断形式是从JDK1.5之后开始追加的,在JDK1.5以前要想实现与之类似的功能,就必须借助、indexOf()方法完成。
来看contains方法的源码:

底层其实还是index方法
代码示例2:indexOf(String str)方法
String str = "helloworld";
System.out.println(str.indexOf("world")); // 结果为5,w开始的索引
System.out.println(str.indexOf("bit")); // 结果为-1,没有查到
if (str.indexOf("hello") != -1) {
System.out.println("可以查到指定字符串!");
}
代码示例3:indexOf(String str,int fromIndex)方法
fromIndex是从前往后确定的位置,例如5就是从前往后数下标为5的字母,意思就是从这个字母开始查找是否存在str这个字符串,有返回这个字符串的第一个字母,没有返回-1.
String str = "helloworld" ;
//结果为5
System.out.println(str.indexOf("world",5));
//结果为-1
System.out.println(str.indexOf("world",6));
代码示例4:lastIndexOf(String str)方法
lastIndexOf方法虽然是从后面开始往前数有没有world这个单词,如果有,返回数字的时候还是返回world这个单词中w所在的下标,没有返回-1
String str = "helloworld" ;
//结果为5
System.out.println(str.lastIndexOf("world"));
代码示例5:lastIndexOf(String str,int fromIndex)方法
String str = "ababcfacd" ;
//结果为2
System.out.println(str.lastIndexOf("ab",4));
此段代码相当于从下标为4处的字母开始从后往前寻找是否存在ab,如果有,直接返回2,没有返回-1.此时从c开始往前寻找ab,找到了以后返回第一次出现ab中a字母的下标
代码示例6:startsWith(String prefix)方法
String str = "ababcfacd" ;
//结果为true
System.out.println(str.startsWith("ab"));
代码示例7:startsWith(String prefix,int toffset)方法
String str = "ababcfacd" ;
//结果为false
System.out.println(str.startsWith("ab",4));
代码示例8:endsWith方法
String str = "ababcfacd" ;
//结果为false
System.out.println(str.endsWith("ab"));
字符串替换处理
使用一个指定的新的字符串替换掉已有的字符串数据,可用的方法如下:

代码示例1:replaceAll方法
String str = "helloworld" ;
//结果为he__owor_d
System.out.println(str.replaceAll("l", "_"));
代码示例2:replaceFirst方法
String str = "helloworld" ;
//结果为he_loworld
System.out.println(str.replaceFirst("l", "_"));
代码示例3::replace方法
String str = "helloworld" ;
//结果为he__owor_d
System.out.println(str.replace("l", "_"));
可以发现replace方法与replaceAll方法的效果一样
来看下replace方法的源码吧:

可以看到replace方法的底层代码中的参数是CharSequence类型,但是我们自己传参的时候是string类型,这是为什么呢?
答:是因为发生了向上转型,String类实现了CharSequence这个接口,如下图所示:

注意事项:由于字符串是不可变对象, 替换不修改当前字符串, 而是产生一个新的字符串
字符串拆分(用的非常多,需要多注意)
可以将一个完整的字符串按照指定的分隔符划分为若干个子字符串。
可用方法如下:

代码示例1:split(String regex)方法
split方法返回的是一个String类型的数组,以下是多次拆分的代码,以后会经常出现
String str = "username=zhangsan&password=123";
//以“&”这个符号进行切割,切割一次后为username=zhangsan password=123
String[] strings = str.split("&");
for (int i = 0; i < strings.length; i++) {
//继续对第一次切割后的字符串进行切割
String[] strings1 = strings[i].split("=");
for (int j = 0; j < strings1.length; j++) {
/*最终结果为:
username
zhangsan
password
123
*/
System.out.println(strings1[j]);
}
}
还有我们会在leetcode刷题的时候经常遇见的使用空格来进行分割:
public class TestDemo5 {
public static void main(String[] args) {
//注意此处bcd与def之间有两个空格
String str = "abc bcd def";
String[] str1 = str.split(" ");
for (String s : str1) {
System.out.println(s);
}
}
}
//输出结果为
abc
bcd
def
代码示例2:split(String regex,int limit)方法
limit=1说明只分了一组
String str = "username=zhangsan&password=123";
String[] strings = str.split("&",1);
for (int i = 0; i < strings.length; i++) {
//输出结果为username=zhangsan&password=123
System.out.println(strings[i]);
}
limit=2说明分为两组
String str = "username=zhangsan&password=123";
String[] strings = str.split("&",2);
for (int i = 0; i < strings.length; i++) {
/*输出结果为:
username=zhangsan
password=123
*/
System.out.println(strings[i]);
}
拆分是特别常用的操作. 一定要重点掌握. 另外有些特殊字符作为分割符可能无法正确切分, 需要加上转义
代码示例3:特殊情况
情况1:拆分ip地址这类(单个分隔符)
String str = "192.168.1.1" ;
String[] result = str.split("\\.") ;
for(String s: result) {
/*输出结果为
192
168
1
1
*/
System.out.println(s);
}
像ip地址这种拆分的时候,如果是拿点号(.)进行拆分的话,需要进行转义,第一次转义是转义点号,第二次转义是保留转义符号的作用,意思就是让第一个\作为转义符号来使用
情况2:多个分隔符的拆分(使用连字符“|”)
String str = "java-split#bit";
//用|作为连字符,将-和#这两个分隔符进行拆分
String[] strings = str.split("-|#");
for (int i = 0; i < strings.length; i++) {
/*输出结果为:
java
split
bit
*/
System.out.println(strings[i]);
}
注意事项:
字符"
|“,”*“,”+“都得加上转义字符,前面加上”\"而如果是"“,那么就得写成”\\".
如果一个字符串中
有多个分隔符,可以用"|"作为连字符.
字符串截取
从一个完整的字符串之中截取出部分内容。可用方法如下:
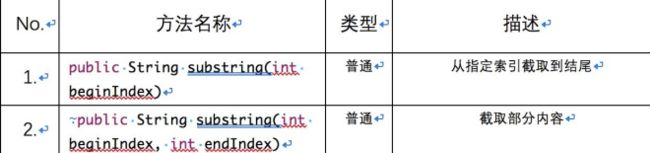
代码示例1:substring(int beginIndex)方法
String str = "abcdefg";
String str1= str.substring(3);
//输出结果为:defg
System.out.println(str1);
注意事项:
索引从0开始,3就是索引为3所对应的那个数字,也就是d
代码示例2:substring(int beginIndex,int endIndex)
String str = "abcdefg";
String str1= str.substring(0,5);
//输出结果为:abcde
System.out.println(str1);
从0下标开始截取,截取到4号下标,不包含5号下标所对应的字符
注意事项:
注意前闭后开区间的写法, substring(0, 5) 表示包含 0 号下标的字符, 不包含 5 号下标
其他操作方法

trim方法
trim 会去掉字符串开头和结尾的空白字符(
空格, 换行, 制表符等).
public class string {
public static void main(String[] args) {
String str = " abc de fg ";
//输出结果为: abc de fg
System.out.println(str);
String str1=str.trim();
//输出结果为:abc de fg
System.out.println(str1);
}
}
toUpperCase方法
public class string {
public static void main(String[] args) {
String str = "abc";
String str1=str.toUpperCase();
//输出结果为:ABC
System.out.println(str1);
}
}
toLowerCase方法
public class string {
public static void main(String[] args) {
String str = "ABabc";
String str1=str.toLowerCase();
//输出结果为:ababc
System.out.println(str1);
}
}
注意事项:toUpperCase方法和toLowerCase方法这两个方法只转换字母,不转换中文字符。
intern方法(前面已经讲过)
concat方法(不经常用,不做过多赘述)
length方法
public class string {
public static void main(String[] args) {
String str = "abc";
int length=str.length();
//输出结果为:3
System.out.println(length);
}
}
注意事项:数组长度使用数组名称.length属性,而String中使用的是length()方法
isEmpty方法
public class string {
public static void main(String[] args) {
//定义一个空字符串
String str = "";
boolean boolean1=str.isEmpty();
//输出结果为:true
System.out.println(boolean1);
}
}
注意有
两种方式可以表示空字符串
第一种方式:String str=“”,这种方式代表指向的字符串对象什么都没有.
第二种方式:String str=null,这种方式代表不指向任何对象
join方法

StringBuffer 和 StringBuilder
首先给出其官方网址:
StringBuffer 类:点我进入官网
StringBuilder 类:点我进入官网
首先来回顾下String类的特点:
任何的字符串常量都是String对象,而且String的常量一旦声明不可改变,如果改变对象内容,改变的是其引用的指向而已。
通常来讲String的操作比较简单,但是由于String的不可更改特性,为了方便字符串的修改,提供StringBuffer和StringBuilder类。
StringBuffer 和 StringBuilder 大部分功能是相同的,我们主要介绍 StringBuffer
在String中使用"+"来进行字符串连接,但是这个操作在StringBuffer类中需要更改为append()方法
使用了append方法进行拼接后,新产生的字符串在字符串常量池就不再生成内存了,就直接在原内存上的字符串进行拼接
代码示例
public class string {
public static void main(String[] args) {
//append方法的字符串拼接是在原字符串基础上进行拼接的,并不是生成新的字符串
StringBuffer stringBuffer=new StringBuffer("abcd");
//输出结果为abcdefg
System.out.println(stringBuffer.append("efg"));
}
}
为什么append方法会在原字符串上进行拼接呢?
来看append方法的源码:
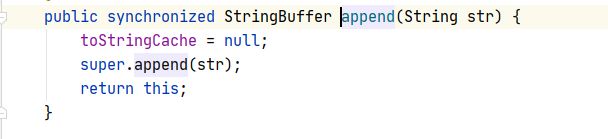
最后返回的是当前对象的引用(return this),所以就是在原字符串上进行拼接.
append方法可以传的参数类型很多:例如char[],char ,boolean,int,long,float,double,StringBuffer,CharSequence
String与StringBuffer(StringBuilder)的转换
String和StringBuffer(StringBuilder)类不能直接转换。如果要想互相转换,可以采用如下原则:
String变为StringBuffer(StringBuilder):利用StringBuffer(StringBuilder)的构造方法或append()方法 (常用)
StringBuffer(StringBuilder)变为String:调用toString()方法。(常用)
总结
String与StringBuffer,StringBuilder的区别(面试题)
-
StringBuffer,StringBuilder包含了一些String没有的方法 比如reverse方法
-
StringBuffer,StringBuilder是可变的,String是不可变的。String的每次拼接,都会产生新的对象。
StringBuffer,StringBuilder每次的拼接都返回的是this,说明是在原字符串上进行拼接的.
StringBuffer与StringBuilder区别(面试题)
先来看StringBuffer,StringBuilder的append方法:
StringBuffer类中的append方法是被synchronized修饰的,
这个关键字可以保证线程的安全.


总结:
StringBuilder和String出现在单线程情况下
StringBuffer因为有synchronized关键字,所以一般出现多线程情况下。
一般来说非多线程的情况下最好使用StringBuilder,原因是 synchronized关键字涉及到锁的问题,每次的开锁关锁都要消耗资源
StringBuffer采用同步处理,属于线程安全操作;而StringBuilder未采用同步处理,属于线程不安全操作
String与StringBuilder区别(面试题)
既然都运用于单线程的情况下,那么这两者到底有什么区别呢?
1:String的拼接”+“会被优化 优化为StringBuilder中的append方法,来看分析:
我们将下面这段代码进行编译:
public class string {
public static void main(String[] args) {
String str="abc";
str=str+"de";
System.out.println(str);
}
}
编译后得到的如下图所示:

可以看到底部进行了优化,那么对于上述代码来说其实底层在运行的时候的代码如下所示:(代码的执行方式跟图中是一样的)
public class string {
public static void main(String[] args) {
String str="abc";
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append(str);
stringBuilder.append("hello");
String str1 = stringBuilder.toString();
System.out.println(str1);
}
}
所以说对于String类的”+“的拼接,底层虽然是StringBuilder类的append方法的优化,但是其仍然会产生大量的临时空间
再来看之前遗留的一个问题:
public static void main(String[] args) {
String str = "abc";
for(int i = 0;i < 10;i++) {
str += i;
}
System.out.println(str);
}
上述代码之前我们说因为由于”+“号的拼接,导致会产生大量的临时变量,此时我们来使用StringBuilder的append方法来进行优化:
public class string {
public static void main(String[] args) {
String str = "abc";
//在循环外定义StringBuilder对象
StringBuilder sb = new StringBuilder();
sb.append(str);
for (int i = 0; i < 10; i++) {
//循环内部使用append方法
str = sb.append(i).toString();
}
System.out.println(str);
}
}
2:在循环当中 不可以使用String直接进行拼接 这样会产生大量的临时对象
包括优化之后的StringBuilder对象。所以每次定义StringBuilder对象的时候在循环外进行定义,然后在循环内部使用append方法.
小结
字符串操作是我们以后工作中非常常用的操作. 使用起来都非常简单方便, 一定要使用熟练. 指的注意的点:
1.字符串的比较, ==, equals, compareTo 之间的区别.
2.了解字符串常量池, 体会 “池” 的思想.
3.理解字符串不可变
4.split 的应用场景
5.StringBuffer 和 StringBuilder 的功能.
String练习题
练习题1
下面代码将输出什么内容:()

A.true
B.false
C.1
D.编译错误
答:B
原因是toLowerCase方法实际上返回值是一个新的字符串,我们来看源码:

再点toLowerCase:

可以看到返回的是new String这样的字符串,所以它的地址是对象中value数组的地址,而"admin"是存储在字符串常量池的,所以两者地址肯定不同.
练习题2
指出下列程序运行的结果()

A.good and abc
B.good and gbc
C.test ok and abc
D.test ok and gbc
答案:B