Elasticsearch的数据备份和恢复以及迁移
目录
1. 为什么备份?
2. 数据备份
3. 数据恢复
4. ES备份数据迁移目标服务器
5. 脚本备份恢复
1. 为什么备份?
常见的数据库都会提供备份机制,以解决在数据库无法使用的情况下通过备份来恢复数据减少损失。 Elasticsearch 虽然有良好的容灾性,但以下原因,其依然需要备份机制:
1) 数据灾备:在整个集群无法正常工作时,可以及时从备份中恢复数据。
2) 归档数据:随着数据的积累,比如日志类的数据,集群的存储压力会越来越大,不管是内存还是磁盘都要承担数据增多带来的压力,此时我们往往会选择只保留最近一段时间的数据,比如将1个月之前的数据删除。如果不想删除这些数据,以备后续有查看需求,那么就可以将这些数据以备份的形式归档。
3) 迁移数据:当你需要将数据从一个集群迁移到另一个集群时,也可以用备份的方式来实现。
Elasticsearch备份两种方式:
1) 将数据导出成文本文件,比如通过 elasticdump、esm 等工具将存储在 Elasticsearch 中的数据导出到文件中。
2) 备份 elasticsearch data 目录中文件的形式来做快照,借助 Elasticsearch 中 snapshot 接口实现的功能。
第一种方式相对简单,在数据量小的时候比较实用,当应对大数据量场景效率就显得乏力。这里本文着重讲解下第二种备份方式,即 snapshot api 的使用。其次,备份集群的唯一可靠方法是使用快照和还原功能。
版本兼容性:
1) 5.x中创建的索引快照可以还原为6.x
2) 2.x中创建的索引快照可以还原为5.x
3) 1.x中创建的索引快照可以还原为2.x
2. 数据备份
官方文档参考
1) 设置备份目录
修改elasticsearch.yml
配置文件elasticsearch.yml中添加 path.repo: ["/home/gocode/app/backup/elk"],重启ES。

创建ES数据备份的数据目录
# mkdir -p /home/gocode/app/backup/elk
# chmod 755 /home/gocode/app/backup/elk
# chown es:es /home/gocode/app/backup/elk //给es用户目录权限
2) 创建仓库(creating the repository)
备份数据之前,要创建一个仓库来保存数据,仓库的类型支持Shared filesystem, Amazon S3, HDFS、Azure Cloud选择。
创建了一个备份仓库名为datasvr 存储目录为/home/gocode/app/backup/elk 的备份仓库。
curl -H "Content-Type: application/json" -XPUT 'http://127.0.0.1:9200/_snapshot/datasvr' -d ' {"type":"fs","settings":{"location":"/home/gocode/app/backup/elk","compress":true}}'curl -H "Content-Type: application/json" -XPUT 'http://127.0.0.1:9200/_snapshot/datasvr' -d '
{
"type": "fs",
"settings": {
"location": "/home/gocode/app/backup/elk",
"compress": true
}
}'![]()
3) 创建快照(备份索引)
一个仓库可以拥有同一个集群的多个快照。在一个集群中快照拥有一个唯一名字作为标识。在仓库 datasvr 中创建名字为 snapshot_1 的快照。
#curl -H "Content-Type:application/json" -XPUT '127.0.0.1:9200/_snapshot/datasvr/snapshot_1'
备份名称为snapshot_1 (自行定义备份名称)
同步执行,加wait_for_completion 标志,备份完成后才返回,如果数据量大的话,会花很长时间
#curl -H "Content-Type:application/json" -XPUT '127.0.0.1:9200/_snapshot/datasvr/snapshot_1?wait_for_completion=true'
如果只想备份部分索引的话,可以加上indices 参数:
curl -H "Content-Type:application/json" -XPUT '127.0.0.1:9200/_snapshot/datasvr/snapshot_1' -d '
{
"indices": "index_1,index_2"
}'执行完后,查看备份数据目录下,已经备份在备份目录下

4) 查看仓库信息
浏览器中查看备份仓库信息
# http://172.20.32.241:9200/_snapshot/datasvr/
![]()
5) 查看仓库存储的所有快照
浏览器中查看备份仓库某个快照信息
http://172.20.32.241:9200/_snapshot/datasvr/snapshot_1
浏览器中查看备份仓库所有快照信息
http://172.20.32.241:9200/_snapshot/datasvr/_all
![]()
6) 删除快照
# curl -X DELETE "localhost:9200/_snapshot/datasvr/snapshot_1"
7) 删除仓库
仓库被注销时,ElasticSearch 只删除仓库存储快照的引用位置,快照本身没有被删除并且在原来的位置
# curl -X DELETE "localhost:9200/_snapshot/datasvr"
集群备份恢复:
注意: 以上是单机的备份方法,集群的备份恢复方法和单机模式一样,只不过需要增加一个集群共享目录用来存放备份数据,使所有节点可访问。
1) 配置集群共享目录
# yum install sshfs
2) 创建集群共享目录,并将各节点备份目录挂载到共享目录
创建集群共享目录
# mkdir -p /home/backup/elk_share
共享目录挂载
# sshfs [email protected]:/home/backup/elk_share /home/backup/elk -o allow_other
3) 数据备份恢复与单机备份恢复一样,参考单机备份恢复
3. 数据恢复
官方文档参考
# curl -H "Content-Type:application/json" -XPOST '127.0.0.1:9200/_snapshot/datasvr/snapshot_1/_restore'
![]()
用过head插件查看,数据已经恢复:
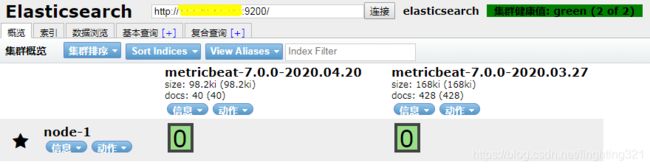
4. ES备份数据迁移目标服务器
1) 源数据备份
参考以上第二步
2) 源数据备份目录拷贝目标ES备份目录下
注意:这里为了方便,源备份目录和目标备份目录一致。
3) 目标ES机器创建源ES同名仓库
4) 目标ES查看快照
5) 目标ES执行恢复操作
5. 脚本备份恢复
将用到的api封装成shell脚本进行备份恢复操作较为方便,后续有时间在补充。