拿到数据,如何用Python来做可视化分析?
前言
很多朋友现在都是学校布置好作业,有了爬下来的数据,结果老师说需要做个数据分析…
还能怎么办,做啊,都吩咐下来了,只能上网搜搜搜,这不今天就有个来找我的
我这里给大家分享分享一个可视化–关于Python开发岗位需求的数据分析,嘿嘿

okok,开始开始,直接展示代码
导入模块
import pandas as pd
from pyecharts.charts import *
from pyecharts import options as opts
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
2.导入数据
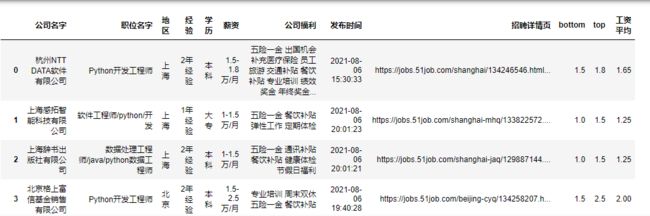
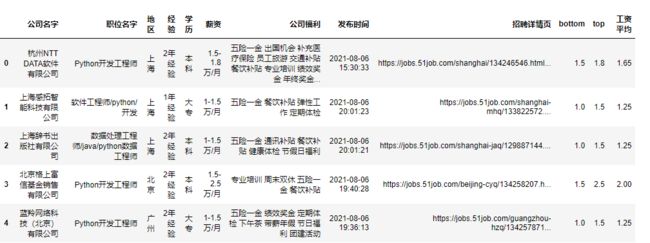
boss = pd.read_csv('招聘数据.csv', engine='python', encoding='utf-8')
boss
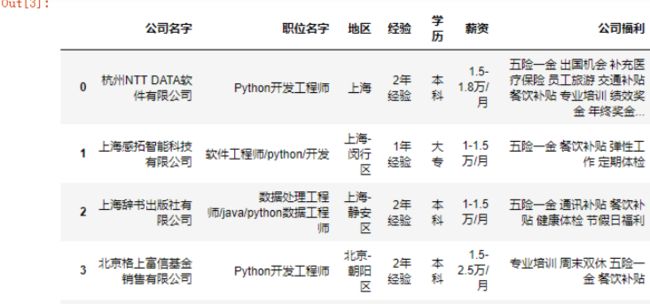
3.数据处理
3.1 查看重复值
【需要完整源码点击文末名片】
boss.duplicated().sum()
3.2 查看缺失值
boss.isnull().sum()
3.3 缺失值处理
boss.dropna(subset=['薪资'], inplace=True)
boss.isnull().sum()

boss['公司福利'].fillna('无', inplace=True)
boss.isnull().sum()
3.4 地区列处理
boss['地区'].unique()

boss['地区'] = boss['地区'].apply(lambda x:x.split('-')[0])
boss['地区'].unique()
3.5 经验列处理
boss['经验'].unique()
![]()

3.6 学历列处理
boss['学历'].unique()
![]()
boss['学历'].replace('招若干人','学历不限', inplace=True)
boss['学历'].replace('招1人','学历不限', inplace=True)
boss['学历'].replace('招2人','学历不限', inplace=True)
boss['学历'].replace('招10人','学历不限', inplace=True)
boss['学历'].replace('招3人','学历不限', inplace=True)
boss['学历'].unique()
3.7 薪资列处理
boss['薪资'].unique()


4.数据分析(数据可视化)

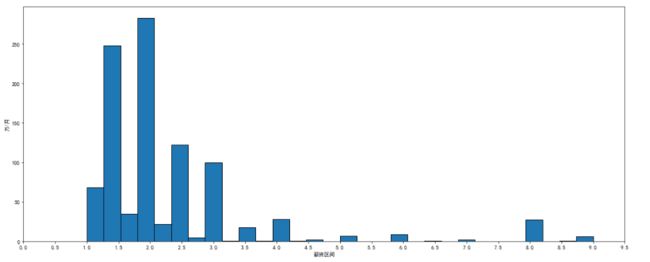
4.1 薪资区间
【需要完整源码点击文末名片】
import numpy as np
def shulie(first, end, step):
x = []
for i in np.arange(first, end, step):
x.append(i)
return x
list_1 = shulie(0,10,0.5)
boss['top'].plot.hist(bins=30,figsize=(20,8),edgecolor="black")
plt.xticks(list_1)
plt.xlabel('薪资区间')
plt.ylabel('万/月')
plt.show()
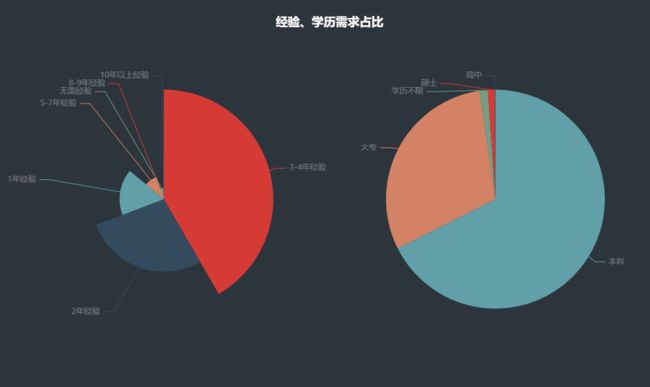
4.2 经验、学历要求情况
boss_1 = boss['经验'].value_counts()
x = boss_1.index.tolist()
y = boss_1.values.tolist()
完整源码+v:xiaoyuanllsll
boss_2 = boss['学历'].value_counts()
x_2 = boss_2.index.tolist()
y_2 = boss_2.values.tolist()
data_pair_1 = [list(z) for z in zip(x, y)]
data_pair_2 = [list(z) for z in zip(x_2, y_2)]

4.3 哪些地区招聘人员比较多


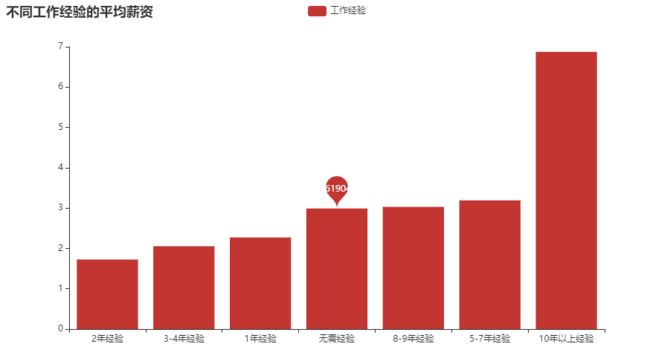
4.4 经验要求 和 薪资情况的情况 是不是薪资越高 经验要求越高

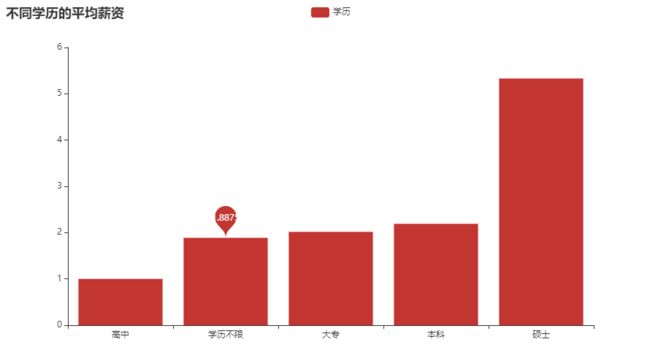
4.5 学历要求 和 薪资情况的情况
是不是薪资越高 学历要求越高
mean = boss.groupby('学历')['工资平均'].mean().sort_values()
x = mean.index.tolist()
完整源码+v:xiaoyuanllsll
y = mean.values.tolist()
c = (
Bar()
.add_xaxis(x)
.add_yaxis(
"学历",
y,
markpoint_opts=opts.MarkPointOpts(
data=[opts.MarkPointItem(name="学历不限", coord=[x[1], y[1]], value=y[1])]
)
)
.set_global_opts(title_opts=opts.TitleOpts(title="不同学历的平均薪资"))
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
c.render_notebook()

words = jieba.lcut(text)
#通过遍历words的方式,统计出每个词出现的频次
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0) + 1