【项目】云备份系统基础功能实现
目录
- 一.项目介绍
-
- 1.云备份认识
- 2.服务端程序负责功能与功能模块划分
- 3.客户端程序负责功能与功能模块划分
- 4.开发环境
- 二.环境搭建
-
- 1.gcc升级7.3版本
- 2.安装jsoncpp库
- 3.下载bundle数据压缩库
- 4.下载httplib库
- 三.第三方库认识
-
- 1.json
-
- (1)json认识
- (2)jsoncpp认识
- (3)json实现序列化
- (4)jsoncpp实现反序列化
- 2.bundle
-
- (1)bundle文件压缩库认识
- (3)bundle库实现文件压缩与减压
- 3.httplib
-
- (1)httplib库认识
-
- 1.1httplib库Request类
- 1.2httplib库Response类
- 1.3httplib库Server类
- 1.4httplibClient类
- (2)httplib搭建简单服务器
- (3)httplib搭建简单客户端
- 四.功能实现
-
- 1.服务端功能实现
-
- (1)工具类模块
-
- 1.1文件实用工具类设计
- 1.2 Json实用工具类
- 1.3 time实用工具类
- (2)配置信息模块
-
- 2.1系统配置信息
- 2.2 单例文件配置类设计
- (3)数据管理模块
-
- 3.1管理的数据信息
- 3.2数据管理类的设计
- 3.3数据管理类的设计
- (4)热点管理模块
-
- 4.1热点管理模块思路
- 4.2热点管理类设计
- (5)业务处理模块
-
- 5.1设计思想
- 5.2网络通信接口设计
- 5.4服务端业务处理类设计
- 2.客户端功能实现
-
- (1)数据管理模块
- (2)文件检测模块实现
- (3)数据管理类设计
- (4)文件备份类设计
云备份系统项目代码链接
一.项目介绍
1.云备份认识
自动将本地计算机上指定文件夹中需要备份的文件上传备份到服务器中。并且能够随时通过浏览器进行查看并且下载,其中下载过程支持断点续传功能,而服务器也会对上传文件进行热点管理,将非热点文件进行压缩存储,节省磁盘空间。

这个云备份项目需要我们实现两端程序,其中包括部署在用户机的客户端程序,上传需要备份的文件,以及运行在服务器上的服务端程序,实现备份文件的存储和管理,两端合作实现总体的自动云备份功能。
2.服务端程序负责功能与功能模块划分
功能:
- 针对客户端上传的文件进行备份存储。
- 能够对文件进行热点文件管理,对非热点文件进行压缩存储,节省磁盘空间。
- 支持客户端浏览器查看访问文件列表。
- 支持客户端浏览器下载文件,并且下载支持断点续传。
功能模块划分:
- 数据管理模块:负责服务器上备份文件的信息管理。
- 网络通信模块:搭建网络通信服务器,实现与客户端通信。
- 业务处理模块:针对客户端的各个请求进行对应业务处理并响应结果。
- 热点管理模块:负责文件的热点判断,以及非热点文件的压缩存储。
3.客户端程序负责功能与功能模块划分
功能:
- 能够自动检测客户机指定文件夹中的文件,并判断是否需要备份。
- 将需要备份的文件逐个上传到服务器。
功能模块划分:
- 数据管理模块:负责客户端备份的文件信息管理,通过这些数据可以确定一个文件是否需要备份。
- 文件检测模块:遍历获取指定文件夹中所有文件路径名称。
- 网络通信模块:搭建网络通信客户端,实现将文件数据备份上传到服务器。
4.开发环境
centos7.6、VS Code、g++、gdb、makefile 以及 windows10/vs2019
二.环境搭建
1.gcc升级7.3版本
- 因为后面的第三方库要求使用更高版本的gcc,若版本过低需要升级版本
- 查看gcc/g++版本的指令:
gcc -v、g++ -v
sudo yum install centos-release-scl-rh centos-release-scl
sudo yum install devtoolset-7-gcc devtoolset-7-gcc-c++
source /opt/rh/devtoolset-7/enable // 加载配置文件,该指令当前生效,重新打开终端后gcc版本不变
echo "source /opt/rh/devtoolset-7/enable" >> ~/.bashrc // 将加载配置文件放入配置文件中,使其永久有效
2.安装jsoncpp库
sudo yum install epel-release
sudo yum install jsoncpp-devel
[YX@localhost ~]$ ls /usr/include/jsoncpp/json/
assertions.h config.h forwards.h reader.h version.h
autolink.h features.h json.h value.h writer.h
#注意,centos版本不同有可能安装的jsoncpp版本不同,安装的头文件位置也就可能不同了。
- 安装后位置为
/usr/include/jsoncpp/json/
3.下载bundle数据压缩库
sudo yum install git
git clone https://github.com/r-lyeh-archived/bundle.git
bundle库Github链接
4.下载httplib库
git clone https://github.com/yhirose/cpp-httplib.git
httplib库Github链接
- 注意: bundle和httplib是github上的库,下载安装可能会比较慢甚至失败,建议在网络环境好的情况下多安装几次
三.第三方库认识
1.json
(1)json认识
json是一种数据交换格式,采用完全独立于编程语言的文本格式来存储和表示数据。
例如:小明同学的学生信息
char name = "小明";
int age = 18;
float score[3] = {88.5, 99, 58};
则json这种数据交换格式是将这多种数据对象组织成为一个字符串:
[
{
"姓名" : "小明",
"年龄" : 18,
"成绩" : [88.5, 99, 58]
},
{
"姓名" : "小黑",
"年龄" : 18,
"成绩" : [88.5, 99, 58]
}
]
json 数据类型:对象,数组,字符串,数字
对象:使用花括号 {} 括起来的表示一个对象。
数组:使用中括号 [] 括起来的表示一个数组。
字符串:使用常规双引号 “” 括起来的表示一个字符串
数字:包括整形和浮点型,直接使用。
(2)jsoncpp认识
jsoncpp 库用于实现 json 格式的序列化和反序列化,完成将多个数据对象组织成为 json 格式字符串,以及将json格式字符串解析得到多个数据对象的功能。
这其中主要借助三个类(Json数据类、序列化类、反序列化类)以及其对应的少量成员函数完成:
//Json数据对象类
class Json::Value{
Value &operator=(const Value &other); //Value重载了[]和=,因此所有的赋值和获取数据都可以通过
Value& operator[](const std::string& key);//简单的方式完成 val["姓名"] = "小明";
Value& operator[](const char* key);
Value removeMember(const char* key);//移除元素
const Value& operator[](ArrayIndex index) const; //val["成绩"][0]
Value& append(const Value& value);//添加数组元素val["成绩"].append(88);
ArrayIndex size() const;//获取数组元素个数 val["成绩"].size();
std::string asString() const;//转string string name = val["name"].asString();
const char* asCString() const;//转char* char *name = val["name"].asCString();
Int asInt() const;//转int int age = val["age"].asInt();
float asFloat() const;//转float
bool asBool() const;//转 bool
};
//json序列化类,低版本用这个更简单
class JSON_API Writer {
virtual std::string write(const Value& root) = 0;
};
class JSON_API FastWriter : public Writer {
virtual std::string write(const Value& root);
};
class JSON_API StyledWriter : public Writer {
virtual std::string write(const Value& root);
};
//json序列化类,高版本推荐,如果用低版本的接口可能会有警告
class JSON_API StreamWriter {
virtual int write(Value const& root, std::ostream* sout) = 0;
};
class JSON_API StreamWriterBuilder : public StreamWriter::Factory {
virtual StreamWriter* newStreamWriter() const;
};
//json反序列化类,低版本用起来更简单
class JSON_API Reader {
bool parse(const std::string& document, Value& root, bool collectComments = true);
};
//json反序列化类,高版本更推荐
class JSON_API CharReader {
virtual bool parse(char const* beginDoc, char const* endDoc, Value* root, std::string* errs) = 0;
};
class JSON_API CharReaderBuilder : public CharReader::Factory {
virtual CharReader* newCharReader() const;
};
- 之所以使用jsoncpp库实现序列化,而不是我们自己实现一个序列化库,是为了开发效率,减少不必要的成本(下边两个库也是相同的)
- 当然,有兴趣的同学也可以自己实现一个序列化和反序列化库
(3)json实现序列化
编写如下测试代码,测试json实现序列化,熟悉该库,为后面使用做准备
#include 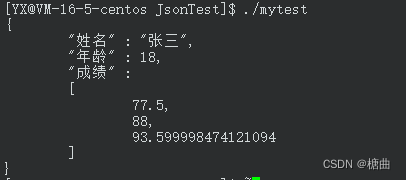
(4)jsoncpp实现反序列化
补充知识:
string str = R"({"姓名":"小明", "年龄":18, "成绩":[76.5, 55, 88]})";
上述为C++11的特殊用法,R"()"表示圆括号内的数据是一个原始字符串,所有字符去除特殊含义。
#include 
2.bundle
(1)bundle文件压缩库认识
Bundle是一个嵌入式压缩库,支持23种压缩算法和2种存档格式。使用的时候只需要加入两个文件bundle.h 和 bundle.cpp 即可。
namespace bundle
{
// low level API (raw pointers)
bool is_packed( *ptr, len );
bool is_unpacked( *ptr, len );
unsigned type_of( *ptr, len );
size_t len( *ptr, len );
size_t zlen( *ptr, len );
const void *zptr( *ptr, len );
bool pack( unsigned Q, *in, len, *out, &zlen );
bool unpack( unsigned Q, *in, len, *out, &zlen );
// medium level API, templates (in-place)
bool is_packed( T );
bool is_unpacked( T );
unsigned type_of( T );
size_t len( T );
size_t zlen( T );
const void *zptr( T );
bool unpack( T &, T );
bool pack( unsigned Q, T &, T );
// high level API, templates (copy)
T pack( unsigned Q, T );
T unpack( T );
}
(3)bundle库实现文件压缩与减压
string ReadData(string& ifilename) // 读取文件中的数据到body
{
ifstream ifs;
ifs.open(ifilename, ios::binary); // 打开原始文件
ifs.seekg(0, ios::end); //跳转读写位置到末尾
size_t fsize = ifs.tellg(); // 获取末尾偏移量 -- 文件长度
ifs.seekg(0, ios::beg); // 跳转到文件起始
string body;
body.resize(fsize); // 调整bidy大小为文件大小
ifs.read(&body[0], fsize); // 读取文件所有数据到body
ifs.close();
return body;
}
void WriteData(string& ofilename, string& packed) // 打开文件写入数据
{
ofstream ofs;
ofs.open(ofilename, ios::binary); // 打开压缩包文件
ofs.write(&packed[0], packed.size()); // 将压缩后的数据写入压缩包文件
ofs.close();
}
void compressed(string& ifilename, string& ofilename)
{
string body = ReadData(ifilename);
string packed = bundle::pack(bundle::LZIP, body); // 以lzip格式压缩文件数据
WriteData(ofilename, packed);
}
void decompress(string& ifilename, string& ofilename)
{
string body = ReadData(ifilename);
string unpacked = bundle::unpack(body); //对压缩包数据解压缩
WriteData(ofilename, unpacked);
}
int main(int argc, char* argv[])
{
if(argc < 4) return -1;
string ifilename = argv[1];
string ofilename = argv[2];
string command = argv[3];
if(command == "compressed")
{
compressed(ifilename, ofilename); // 压缩文件
}
else if(command == "decompress")
{
decompress(ifilename, ofilename); // 解压缩文件
}
return 0;
}
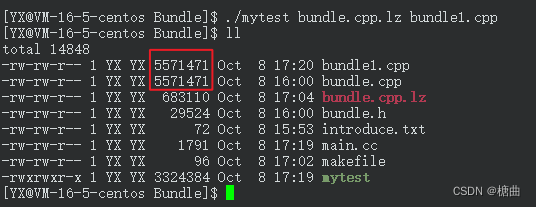
查看减压前后bundle1.cpp和bundle.cpp的md5sum是否一致

若两文件内容相同,它的md5sum值是相同的否则说明压缩/解压有问题。
3.httplib
(1)httplib库认识
httplib 库,一个 C++11 单文件头的跨平台 HTTP/HTTPS 库。安装起来非常容易。只需包含 httplib.h 在你的代码中即可。
httplib 库实际上是用于搭建一个简单的 http 服务器或者客户端的库,这种第三方网络库,可以让我们免去搭建服务器或客户端的时间,把更多的精力投入到具体的业务处理中,提高开发效率。
namespace httplib{
struct MultipartFormData {
std::string name;
std::string content;
std::string filename;
std::string content_type;
};
using MultipartFormDataItems = std::vector<MultipartFormData>;
struct Request {
std::string method;
std::string path;
Headers headers;
std::string body;
// for server
std::string version;
Params params;
MultipartFormDataMap files;
Ranges ranges;
bool has_header(const char *key) const;
std::string get_header_value(const char *key, size_t id = 0) const;
void set_header(const char *key, const char *val);
bool has_file(const char *key) const;
MultipartFormData get_file_value(const char *key) const;
};
struct Response {
std::string version;
int status = -1;
std::string reason;
Headers headers;
std::string body;
std::string location; // Redirect location
void set_header(const char *key, const char *val);
void set_content(const std::string &s, const char *content_type);
};
class Server {
using Handler = std::function<void(const Request &, Response &)>;
using Handlers = std::vector<std::pair<std::regex, Handler>>;
std::function<TaskQueue *(void)> new_task_queue;
Server &Get(const std::string &pattern, Handler handler);
Server &Post(const std::string &pattern, Handler handler);
Server &Put(const std::string &pattern, Handler handler);
Server &Patch(const std::string &pattern, Handler handler);
Server &Delete(const std::string &pattern, Handler handler);
Server &Options(const std::string &pattern, Handler handler);
bool listen(const char *host, int port, int socket_flags = 0);
};
class Client {
Client(const std::string &host, int port);
Result Get(const char *path, const Headers &headers);
Result Post(const char *path, const char *body, size_t content_length,
const char *content_type);
Result Post(const char *path, const MultipartFormDataItems &items);
};
};
1.1httplib库Request类
struct Request {
std::string method; // 请求方法:get、post..
std::string path; // 资源路径
Headers headers; // 头部字段
std::string body; // 正文
// for server
std::string version; // 协议版本
Params params; // 查询字符串
MultipartFormDataMap files; // 保存客户端上传的文件信息
Ranges ranges; // 用于实现段点续传的请求文件区间
// 处理请求只需对上述数据逐个处理分析即可
// 查询头部字段中又没有某个字段
bool has_header(const char *key) const;
// 获取头部字段的值
std::string get_header_value(const char *key, size_t id = 0) const;
// 设置头部字段
void set_header(const char *key, const char *val);
// 是否包含某个文件(从files成员变量中的name字段文件名称查看)
bool has_file(const char *key) const;
// 获取文件信息
MultipartFormData get_file_value(const char *key) const;
};
请求报文结构如下:

Request类的作用:
- 客户端 保存 的所有 http请求 相关信息,最终组织http请求发送给服务器
- 服务器收到http请求之后进行解析,将解析的数据保存在Request类中,等待后序处理
1.2httplib库Response类
struct Response {
std::string version; // 协议版本
int status = -1; // 响应状态码
std::string reason; // (涉及不到)
Headers headers; // 头部字段
std::string body; // 有效载荷
std::string location; // Redirect location 重定向位置(涉及不到)
// 设置头部字段,设置好后放入headers
void set_header(const char *key, const char *val);
// 设置正文,设置好后放入body
void set_content(const std::string &s, const char *content_type);
};
响应报文结构如下:

Response类的作用:
- 用户将想要数据放到类中,httplib会将其中的数据按照http响应格式组织成为http响应,发送给客户端
- 这个类是我们在业务处理之后填充的类,由httplib组织成响应,在将其发送给客户端
1.3httplib库Server类
class Server {
// 函数指针类型
using Handler = std::function<void(const Request &, Response &)>;
// 请求与处理函数映射表
using Handlers = std::vector<std::pair<std::regex, Handler>>;
// 线程池,用于处理http请求
std::function<TaskQueue *(void)> new_task_queue;
// 以下六个接口,针对某种请求方法的某个请求设定映射的处理函数
Server &Get(const std::string &pattern, Handler handler);
Server &Post(const std::string &pattern, Handler handler);
Server &Put(const std::string &pattern, Handler handler);
Server &Patch(const std::string &pattern, Handler handler);
Server &Delete(const std::string &pattern, Handler handler);
Server &Options(const std::string &pattern, Handler handler);
// 搭建并启动http服务器
bool listen(const char *host, int port, int socket_flags = 0);
};
Server类的作用:用于搭建http服务器
其中:
- Handler: 函数指针类型,定义了一个http请求处理回调函数格式
httplib搭建的服务器收到请求后,进行解析,得到一个Request结构体,其中包含了请求数据
根据请求数据我们就可以处理这个请求了,这个处理函数定义的格式就是Handler格式- Request参数: 保存请求数据,让用户能够根据请求数据进行业务处理
- Response参数: 需要用户在业务处理中,填充数据,最终要响应给客户端
- Handlers: 是一个请求路由数组:其中包含两个信息(请求与处理函数映射表)
- regex: 正则表达式,用于匹配http请求资源路径
- Handler: 请求处理函数指针
可以理解为,Handlers是一张表,映射了一个客户端请求的资源路径和一个处理函数(用户自己定义的函数)
当服务器收到请求解析得到Request就会根据资源路径以及请求方法到这张表中查看有没有对应的处理函数。
如果有则调用这个函数进行请求处理,如果没有则响应404
说白了,handlers这个表就决定了,那个请求应该用那个函数处理 - new_task_queue: 线程池,处理http请求
线程池中线程的工作:- 接收请求,解析请求,得到Request类也就是请求的数据
- 在Handlers映射表中,根据请求信息查找处理函数,如果有则调用函数处理
void(const Request &, Response &) - 当处理函数调用完毕,根据函数返回的Response结构体中的数据组织http响应发送给客户端
1.4httplibClient类
class Client {
Client(const std::string &host, int port); // 传入服务器IP地址和断口
Result Get(const char *path, const Headers &headers); // 向服务器发送GET请求
// 向服务器发送post请求
Result Post(const char *path, const char *body, size_t content_length,
const char *content_type);
// POST请求提交多区域数据,常用于多文件上传
Result Post(const char *path, const MultipartFormDataItems &items);
};
(2)httplib搭建简单服务器
#include "httplib.h"
using namespace std;
void Hello(const httplib::Request &req, httplib::Response& rsp)
{
rsp.set_content("Hello World!", "text/plain");
rsp.status = 200;
}
void Numbers(const httplib::Request& req, httplib::Response& rsp)
{
auto num = req.matches[1]; // 0里保存的是整体path,往后下标中保存的是捕捉的数据
rsp.set_content(num, "text/plain");
rsp.status = 200;
}
void Multipart(const httplib::Request& req, httplib::Response& rsp)
{
auto ret = req.has_file("file");
if(ret == false)
{
cout << "not file upload\n";
rsp.status = 400;
return;
}
const auto& file = req.get_file_value("file");
rsp.body.clear();
rsp.body = file.filename; // 文件名称
rsp.body += '\n';
rsp.body += file.content; // 文件内容
rsp.set_header("Content-Type", "text/plain");
rsp.status = 200;
return;
}
int main()
{
httplib::Server server; // 实例化一个Server类对象用于搭建服务器
server.Get("/hi", Hello); // 注册一个针对/hi的Get请求的处理函数映射关系
server.Get(R"(/numbers/(\d+))", Numbers);
server.Post("/mutipart", Multipart);
server.listen("0.0.0.0", 8889);
return 0;
}
使用g++ buildServer.cc -o mytest -std=c++11 -lpthread生成可执行文件,因为httplib库用到了线程库,所以需要增加-lpthread
(3)httplib搭建简单客户端
#include "httplib.h"
using namespace std;
#define SERVER_IP "127.0.0.1"
#define SERVER_PORT 8889
int main()
{
httplib::Client client(SERVER_IP, SERVER_PORT); // 实例化client对象,用于搭建客户端
httplib::MultipartFormData item;
item.name = "file";
item.filename = "hello.txt";
item.content = "Hello World"; // 上传文件时,这里给的就是文件内容
item.content_type = "text/plain";
httplib::MultipartFormDataItems items;
items.push_back(item);
auto res = client.Post("/mutipart", items);
cout << res->status << endl;
cout << res->body << endl;
return 0;
}
使用g++ -o mytest buildClient.cc -std=c++11 -lpthread生成可执行文件,因为httplib库用到了线程库,所以需要增加-lpthread
四.功能实现
1.服务端功能实现
(1)工具类模块
1.1文件实用工具类设计
不管是客户端还是服务端,文件的传输备份都涉及到文件的读写,包括数据管理信息的持久化也是如此,因此首先设计封装文件操作类,这个类封装完毕之后,则在任意模块中对文件进行操作时都将变的简单化。
// 文件实用工具类设计:对文件进行操作
class{
private:
std::string _filename;
struct stat _st;
public:
size_t FileSize(); //获取文件大小
time_t LastMTime(); // 获取文件最后一次修改时间
time_t LastATime(); // 获取文件最后一次访问时间
std::string FileName(); // 获取文件路径名中的文件名称 /abc/test.txt -> test.txt
std::string FilePath(); // 获取文件相对路径(当获取文件不在当前目录下时,需要根据路径获取)
bool SetContest(std::string& body); // 向文件写入数据
bool GetContent(std::string* body); // 获取文件数据
bool GetPosLen(std::string* body, size_t pos, size_t len); //获取文件指定位置指定长度数据
bool GetDirectory(std::vector<std::string>* arry); //获取文件目录
bool Remove(); // 删除当前文件
bool CreateDirector(); //创建目录
bool Exits(); //判断文件是否存在
bool ScanDirectory(std::vector<std::string>* arrry);
bool Compress(const std::string& packname); //压缩当前文件,压缩包存放位置及文件名由packname决定
bool UnCompress(const std::string& unpackname); //解压缩,减压后的文件存放位置及文件名由unpackname决定
};
在实现该类时,我给出的代码中服务端文件工具类实用的是Linux系统提供的接口,而在客户端该类中则实用C++17给出的Filesystem库,大家可以按自己的需求来实用。
C++17中Filesystem library - cppreference.com
1.2 Json实用工具类
// 涉及两个接口,一个Json的序列化、一个反序列化
class JsonUtil
{
public:
static bool Serialize(const Json::Value& root, std::string* str); // 序列化
static bool UnSerialize(const std::string* str, Json::Value& root); // 反序列化
};
该类用来配合文件工具类对文件进行序列化和反序列化
1.3 time实用工具类
class TimeUtil
{
public:
static void AddressTime(time_t time, std::string& tartime); // 将时间转化为 年/月/日 时:分:秒 的格式
static time_t GetNowTime(); // 获取当前时间
static bool JudgeHot(time_t&& time, time_t hotTime); // 若当前时间减去最后传输来的时间大于热点时间,文件为非热点文件
};
在浏览器页面展示时,需要显示文件信息,其中就有时间,需要将其转化为 年/月/日 时:分:秒 的格式
(2)配置信息模块
2.1系统配置信息
当我们运行系统时可以在配置文件中读出关键信息,在程序中使用。
使用配置文件,我们的配置信息就可以随时进行更改,更改配置信息后,我们的程序不需要重新生成重新编译,只需重启服务端程序,重新加载配置即可。
使用文件配置加载一些程序的运行关键信息可以让程序的运行更加灵活。
配置信息:
-
热点判断时间
热点管理:多长时间没有被访问的文件算是非热点文件,取决于热点判断时间 -
文件下载URL前缀路径 — 用于表示客户端请求是一个下载请求
url:http://服务器IP地址:端口号:相对文件根目录
当用户发来一个备份列表查看请求如:/listshow,我们如何判断这不是一个listshow的文件下载请求
所以规定,当给出的文件路径为/download/listshow时我们判断此时是要下载listshow文件 -
压缩包后缀名称
根据项目中使用的压缩格式自己来定义压缩包命名规则,在文件原名称之后加后缀 -
上传文件存放路径
决定了文件上传之后,实际存放在服务器的哪里 -
压缩文件存放路径
决定非热点文件压缩后存放的路径 -
服务端备份信息存放文件
该项目暂时未使用数据库存储,而是使用文件记录服务端记录的备份文件信息的持久化存储 -
服务器访问IP地址
当程序运行在其他主机上,则不需要修改程序,只需要改对应的服务器IP和端口即可 -
服务器访问端口
{
"hot_time" : 30,
"server_port" : 9191,
"server_ip" : "43.143.x.x",
"download_prefix" : "/download/",
"packfile_suffix" : ".lz",
"pack_dir" : "./packdir",
"back_dir" : "./backdir",
"backup_file" : "./cloud_dat"
}
- 已经实现了json的工具类,在存放时以json的格式存放,使用时更加方便
2.2 单例文件配置类设计
使用单例模式管理系统配置信息,能够让配置信息的管理控制更加统一灵活。
#define CONFIG_FILE "./cloud.conf"
class Config{
private:
int _hot_time; // 热点管理判断时间
int _server_port; // 服务器监听端口
std::string _download_prefix; // 下载的url前缀路径
std::string _packfile_suffix; // 压缩包后缀名称
std::string _back_dir; // 备份文件存放目录
std::string _pack_dir; // 压缩包存放目录
std::string _backup_file; // 数据信息存放文件,即上传文件存放相对根目录
std::string _server_ip; // 服务器IP地址
private:
static std::mutex _mutex;
static Config *_instance;
Config();
bool ReadConfig(const std::string &filename);
public:
int GetHotTime();
int GetServerPort();
std::string GetServerIp();
std::string GetURLPrefix();
std::string GetArcSuffix();
std::string GetPackDir();
std::string GetBackDir();
std::string GetManagerFile();
public:
static Config *GetInstance();
};
(3)数据管理模块
3.1管理的数据信息
后期要用到那些数据,就是我们需要管理的数据,如下:
-
文件实际存储路径
客户端下载文件时,从这个文件中读取数据进行响应
如果文件已经被压缩,则先从压缩目录下找到该文件,进行解压缩,存入实际路径 -
文件是否压缩标志
判断文件是否已经被压缩了 -
压缩包存储路径
如果这个文件时一个非热点文件回被压缩,则这个就是压缩包路径名称
客户端要下载文件,需要先减压缩,然后读取减压后的文件数据。 -
文件属性信息
如果用户只是需要文件的展示界面,不需要下载,我们不能将已经压缩的文件减压后获取其属性信息,这样效率太低,而是需要事先保存其如下属性(可添加)- 文件大小
- 文件最后一次访问时间
- 文件最后一次修改时间
-
文件访问URL中资源路径
如:/download/a.txt
告诉用户文件的下载路径是什么
3.2数据管理类的设计
-
用于数据信息访问:
内存中以文件访问URL为key,数据信息结构为val,使用哈希表进行管理,查询速度快。使用url作为key是因为往后客户端浏览器下载文件的时候总是以 url 作为请求。 -
持久化存储管理:
采用文件形式对数据进行持久化存储(序列化方式采用 json 格式或者自定义方式)
3.3数据管理类的设计
数据管理类:管理服务端系统中会用到的数据
/*data.hpp*/
typedef struct BackupInfo
{
int pack_flag; // 是否压缩标志
time_t mtime; // 文件最后访问时间
time_t atime; // 文件最后修改时间
size_t fsize; // 文件大小
std::string real_path; // 文件实际存储路径
std::string pack_path; // 压缩包存储路径名
std::string url; // 请求资源路径
bool NewBackupInfo(const std::string &realpath); // 将realpath中内容填写入当前对象
} BackupInfo;
class DataManager
{
private:
FileUtil _backup_file; // 持久化存储文件
pthread_rwlock_t _rwlock; // 读写锁--读共享,写互斥
std::unordered_map<std::string, BackupInfo> _table; // 内存中以hash表存储
public:
DataManager();
bool InitLoad(); // 初始化程序运行时从文件读取数据
bool Storage(); // 每次有信息改变则需要重新持久化存储一次,防止数据丢失
bool Insert(const BackupInfo &val); // 新增
bool Update(const std::string &key, const BackupInfo &val); // 修改
bool GetOneByURL(const std::string &key, BackupInfo *info); // 通过单个URL获取对应文件数据
bool GetOneByRealPath(const std::string &realpath, BackupInfo *info); // 根据指定文件真实路径,获取对应文件数据
bool GetAll(std::vector<BackupInfo> *arry); // 获取所有信息
};
- 互斥锁是一个串行化的过程,同一时间只有一个线程可以访问临界资源,在该项目中是不合适的,在该项目中我们的多个线程可能不是需要去修改它,而是去访问获取数据而已。所以使用读写锁,读大家多可以读,而到了写的时候,一次只有一个线程可以进行写操作。
(4)热点管理模块
4.1热点管理模块思路
服务器端的热点文件管理是对上传的非热点文件进行压缩存储,节省磁盘空间。
而热点文件的判断在于上传的文件的最后一次访问时间是否在热点判断时间之内,比如如果一个文件一天都没有被访问过我们就认为这是一个非热点文件,其实就是当前系统时间,与文件最后一次访问时间之间的时间差是否在一天之内的判断。
而我们需要对上传的文件每隔一段时间进行热点检测,相当于遍历上传文件的存储文件夹,找出所有的文件,然后通过对逐个文件进行时间差的判断,来逐个进行热点处理。
基于这个思想,我们需要将上传的文件存储位置与压缩后压缩文件的存储位置分开。这样在遍历上传文件夹的时候不、至于将压缩过的文件又进行非热点处理了。
关键点:
- 上传文件有自己的上传存储位置,非热点文件的压缩存储有自己的存储位置
- 遍历上传存储位置文件夹,获取所有文件信息。
- 获取每个文件最后一次访问时间,进而完成是否热点文件的判断。
- 对非热点文件进行压缩存储,删除原来的未压缩文件。
4.2热点管理类设计
// 因为数据数据管理是要在多个模块中访问的,因此将其作为全局数据定义,在此处声明使用即可
extern DataManager* _data;
class HotManager
{
private:
std::string _back_dir; // 备份文件路径
std::string _pack_dir; // 压缩文件路径
std::string _pack_suffix; // 压缩包后缀名
time_t _hot_time; // 热点判断时间
public:
HotManager();
bool RunModule(); // 运行模块,完成热点管理所有功能
};
(5)业务处理模块
5.1设计思想
云备份项目中 ,业务处理模块是针对客户端的业务请求进行处理,并最终给与响应。而整个过程中包含以下要实现的功能:
- 借助网络通信模块httplib库搭建http服务器与客户端进行网络通信
- 针对收到的请求进行对应的业务处理并进行响应
- 文件上传请求:备份客户端上传的文件,响应上传成功
- 文件列表请求:客户端浏览器请求一个备份文件的展示页面,响应页面
- 文件下载请求:通过展示页面,点击下载,响应客户端要下载的文件数据,并且实现断点续传
5.2网络通信接口设计
业务处理模块要对客户端的请求进行处理,那么我们就需要提前定义好客户端与服务端的通信,明确客户端发送什么样的请求,服务端接收后应该给与什么样的响应,而这就是网络通信接口的设计。
-
HTTP文件上传:
服务器收到如下的请求:POST /upload HTTP/1.1 Content-Length:11 Content-Type:multipart/form-data;boundary= ----WebKitFormBoundary+16字节随机字符 ------WebKitFormBoundary Content-Disposition:form-data;filename="a.txt"; hello world ------WebKitFormBoundary--我们规定当服务器收到一个POST方法的/upload请求时,我们认为这是一个文件上传请求,解析该请求,得到文件数据,将数据写入文件中。
现其返回如下响应:// 成功处理 HTTP/1.1 200 OK Content-Length: 0 // 失败处理(根据不同的错误情况可以设计自己的错误码) HTTP/1.1 500 NO Content-Length: 0 -
HTTP展示页面:
服务器收到如下的请求:GET /listshow HTTP/1.1 ... // 或者如下 GET / HTTP/1.1 ...响应如下:
HTTP/1.1 200 OK Content-length: Content-Type: text/html <html> ... </html> <!-- 这是展示页面的数据 -->Content-type:决定了浏览器如何处理响应正文
-
HTTP文件下载:
服务器收到如下的请求:GET /download/test.txt HTTP/1.1 ...响应如下:
HTTP/1.1 200 OK Content-Length: 100000 ETags: "filename-size-mtime一个能够唯一标识文件的数据" Accept-Ranges: bytes 文件数据其中:
- ETags: 头部字段的作用是存储了一个资源的唯一标识,客户端第一次下载文件的时候,会收到这个响应信息,第二次下载,就会将这个信息发送给服务器,想要让服务器根据这个唯一标识判断这个资源是否被修改过,如果没有被修改过,直接使用原先缓存的数据,不用再重新下载。
这里我们根据文件名+文件大小+文件最后修改时间来组成一个ETage
HTTP协议本身对于etag中是什么数据并不关心,只要你服务端能够自己识别就行。
etag字段不仅仅是缓存会使用到,后边的断点续传也会使用到,段点续传也要保证文件没有被修改过。 - http协议的
Accept-Ranges:bytes字段:用于告诉客户端支持断点续传,并且数据单位以字节作为单位。
- ETags: 头部字段的作用是存储了一个资源的唯一标识,客户端第一次下载文件的时候,会收到这个响应信息,第二次下载,就会将这个信息发送给服务器,想要让服务器根据这个唯一标识判断这个资源是否被修改过,如果没有被修改过,直接使用原先缓存的数据,不用再重新下载。
-
HTTP断点续传:
服务器收到如下的请求:GET /download/a.txt http/1.1 Content-Length: 0 If-Range: "文件唯一标识" // 用于服务器判断这个文件与原先下载的文件是否一致(不一致重新下载,一致按照Range范围读取给客户端) Range: bytes=89-999 // 从第89个字节开始到999字节结束,告诉服务器客户端需要的区间范围响应如下:
HTTP/1.1 206 Partial Content Content-Length: Content-Range: bytes 89-999/100000 // 起始-结束/文件大小 Content-Type: application/octet-stream ETag: "inode-size-mtime一个能够唯一标识文件的数据" // 客户端收到响应保存这个信息 Accept-Ranges: bytes //告诉客户端服务器支持断点续传功能 对应文件从89到999字节的数据断点续传:
- 功能: 当文件下载过程中,因为某种异常而中断,如果再次进行从头下载,如果将之前已经传输的数据再次传输一遍,效率是很低的。因此,断点续传就是从上次下载断开的位置重新下载即可,之前已经传输过的数据将不需要重新传输。
- 目的: 提高文件的重新传输效率
- 实现思想: 客户端在下载文件时,要每次接收到数据写入文件后记录自己当前下载的数据量。当异常下载中断时,下次断点续传时,将要重新下载的数据区间(下载的起始位置,结束位置)发送给服务器,服务器收到后,仅仅回传客户端需要的区间数据即可。
- 考虑问题: 如果上次下载文件之后,这个文件在服务器上被修改之后,则这时不能重新断点续传,而是应该重新进行文件下载操作。
在http协议中断点续传的实现:主要关键点
- 在于能够告诉服务器区间范围
- 服务器上要能够检测上一次下载之后这个文件是否被修改过
5.4服务端业务处理类设计
//因为业务处理的回调函数没有传入参数的地方,因此无法直接访问外部的数据管理模块数据
//可以使用lamda表达式解决,但是所有的业务功能都要在一个函数内实现,于功能划分上模块不够清晰
//因此将数据管理模块的对象定义为全局数据,在这里声明一下,就可以在任意位置访问了
class Service
{
private:
int _server_port; // IP地址
std::string _server_ip; // 端口号
std::string _download_prefix; // 下载请求前缀
httplib::Server _server; // 使用该变量搭建服务器
private:
void Upload(const httplib::Request& req, httplib::Response& rsp); // 上传请求处理
void ListShow(const httplib::Request& req, httplib::Response& rsp); // 获取展示页面
void Download(const httplib::Request& req, httplib::Response& rsp); // 文件下载请求
public:
Server();
bool RunModule();
};
2.客户端功能实现
要实现的功能:自动对指定文件夹中的文件进行备份
进行的模块划分:
- 数据管理模块:管理备份的文件信息
- 目录遍历模块:获取指定文件夹中的所有文件路径名
- 文件备份模块:将需要备份的文件上传备份到服务器
客户端要备份文件,什么文件需要备份,都是通过数据管理判断的
(1)数据管理模块
客户端要实现的功能是对指定文件夹中的文件自动进行备份上传。但是并不是所有的文件每次都需要上传,我们需要能够判断,哪些文件需要上传,哪些不需要,因此需要将备份的文件信息给管理起来,作为下一次文件是否需要备份的判断。因此需要被管理的信息包含以下:
- 文件路径名称
- 文件唯一标识:由文件名,最后一次修改时间,文件大小组成的一串信息
其中的信息用来判断一个文件是否需要重新备份:
- 文件是否是新增的
- 不是新增的,则上次备份后有没有被修改过
客户端的程序开发是在Windows下开发,毕竟大家是在Windows下使用该功能,使用的工具是VS2017以上版本(需要支持C++17)
实现思想:
-
内存存储:高访问效率——使用的是hash表——unordered_map
-
持久化存储:文件存储
文件存储涉及到数据序列化:因为在VS中安装Jsoncpp有先麻烦,这里先不用该库,直接自定义序列化格式
key val:key是文件路径名,val是文件唯一标识,采用key val\nkey val\n的格式(\n为换行)
文件唯一标识:用来判断上次文件上传后有没有被修改过
(2)文件检测模块实现
这个其实与服务端的文件实用工具类雷同,只是功能需求并没有服务端那么多,复制过来即可。
// 文件实用工具类设计:对文件进行操作
class{
private:
std::string _filename;
public:
size_t FileSize(); //获取文件大小
time_t LastMTime(); // 获取文件最后一次修改时间
time_t LastATime(); // 获取文件最后一次访问时间
std::string FileName(); // 获取文件路径名中的文件名称 /abc/test.txt -> test.txt
std::string FilePath(); // 获取文件相对路径(当获取文件不在当前目录下时,需要根据路径获取)
bool SetContest(std::string& body); // 向文件写入数据
bool GetContent(std::string* body); // 获取文件数据
bool GetPosLen(std::string* body, size_t pos, size_t len); //获取文件指定位置指定长度数据
bool GetDirectory(std::vector<std::string>* arry); //获取文件目录
bool Remove(); // 删除当前文件
bool CreateDirector(); //创建目录
bool Exits(); //判断文件是否存在
bool ScanDirectory(std::vector<std::string>* arrry);
};
(3)数据管理类设计
class DataManager{
private:
std::unordered_map<std::string, std::string> _table; // 文件路径名称 : 文件唯一标识
std::string _back_file;
public:
DataManager(const std::string back_file);
bool InitLoad();//程序运行时加载以前的数据
bool Storage();//持久化存储
bool Insert(const std::string &key, const std::string &val);
bool Update(const std::string &key, const std::string &val);
bool GetOneByKey(const std::string &key, std::string *val);
};
(4)文件备份类设计
客户端需要将指定文件夹中的文件备份到服务器上
流程如下:
- 遍历指定文件夹,获取文件信息
- 逐一判断文件是否需要备份
- 需要备份的文件进行上传备份
#define SERVER_ADDR "43.143.x.x"
#define SERVER_PORT 9191
class Backup
{
private:
std::string _back_dir; // 要监控的文件夹
DataManager* _data;
public:
Backup(const std::string& backdir, const std::string& backup_file);
bool RunModule(); // 运行模块
std::string GetFileIdantifier(const std::string& filename); // 获取文件唯一标识
bool IsCanBeUpload(const std::string& filename); // 判断文件是否需要备份
bool Upload(const std::string& filename); // 上传文件
};