NIPS15 - 神经网络中的空间转换模块STN《Spatial Transformer Network》(含代码复现)
文章目录
-
- 原文地址
- 论文阅读方法
- 初识
- 相知
- 回顾
- 代码
原文地址
原文
论文阅读方法
三遍论文法
初识
CNN方法在计算机视觉领域大放异彩,在很多领域都已经代替了传统方法。然而卷积神经网络的架构缺乏空间不变性(Spatially Invariant),即使卷积和max-pooling操作在一定程度上引入了平移不变性和空间不变性,但如果输入发生了较大的空间变化,CNN就变得无法识别了。
因此本文提出了一个空间转换模块,并以此构建了空间转换网络,能在一定程度增加CNN的空间不变性。并且这是一个即插即用的模块,能较方便地插入到各种架构中。
相知
介绍主要技术和部分实验
基于矩阵操作的空间变换
熟悉传统图像处理的小伙伴肯定知道大多数空间转换就可以转换成基于矩阵的采样操作,假设输入图像(source)的像素点由( x i s , y i s x_i^s, y_i^s xis,yis)表示,输出图像(target)像素点由( x i t , y i t x_i^t, y_i^t xit,yit)表示,只要确定了一组变换参数θ就能确定一种空间变换。以2D放射变换矩阵为例:

矩阵 A θ A_θ Aθ可以有平移、旋转、缩放、错切等操作,只要确定了其中6个参数,就可以根据矩阵变换求得输出图像各像素点的值(视为从原图采样的操作)。
这里贴上恒等映射( θ 11 , θ 22 θ_{11}, θ_{22} θ11,θ22为1其他为0)和一种仿射变化的效果图:

了解更多关于2D仿射变换矩阵请参照这篇文章:仿射变换及其变换矩阵的理解
既然可以将空间变换确定为矩阵操作,那么不妨让网络去学习生成矩阵参数,从而学会空间转换。
整体架构

STN模块的整体结构如上图所示,其由localisation net、Grid generator和Sampler三部分组成,输入特征图U(也可以直接是RGB图像)经过空间变换模块得到输出特征图V。
其中Localisation net将输入特征图中送到一个子网中,得到空间变化参数θ;Grid generator根据θ确定一个空间变化,并创建采样网格(sampling grid, 确定输入图中哪些点会被用于变换);Sampler根据采样网格对输入特征图进行采样,从而得到最终的输出。
Localisation net
定位子网接受输入特征图,送到隐层中提取特征(可以是卷积层,也可以是全连接层),并根据预设的变换输出对应的参数(比如之前提到的仿射变换就是6个参数)。
Grid generator
其实就是根据参数构造转换矩阵,从而确定采样空间。
其中有一些细节需要注意,输入输出图的坐标均归一化到[-1, 1]之间
Image Sampling
想要通过梯度下降的方法来学习网络参数,那么就一定要注意操作的可导行。而采样操作本身并不是可导的,因为输入像素点是离散的,而空间转换会导致采样点并不是原图上的像素值。因此作者引入了插值操作,使得过程可导:

其中U是输入特征图,V是输出特征图,k为插值操作。
从而最近邻插值和 双线性插值,如下:
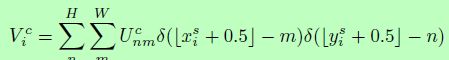

而插值过程是可导的,其的求偏导过程如下:

因此整个模块就可以通过反向传播算法进行参数更新,从而嵌入到网络中进行端到端训练。
部分实验
① 对MNIST数据进行一些扰动,使得其对于正常CNN难以分辨,而引入了STN模块后,经过变换后能够正常识别。

② 在门牌数字识别上,引入多重STN结构,提升了识别性能。

回顾
STN是15年的工作,但它的思想也影响了后面的一大批工作。其主要的亮点就是将空间变换变成一种参数的预测,然后通过插值的方式进行采样,从而能够嵌入到网络中进行端到端的训练。
但它的性能并不是想传说中的那么好,也无法替代随机增广的作用。因为没有对空间转换进行直接的约束,所以你无法期望它能达到你想要的变换形式。比如,在MNIST实验中,它之所以能学会将翻转的4变换复原,是因为整个类别大多数训练数据都是正向的,如果你整个类别都是翻转后的4,它是无法学会的,它的参数更新依赖于你整体的训练目标。
我在图像分类的比赛中用过这个模块,期望其能起到类似于Attention的作用,将图像中的关键信息进行放大,但实验效果并不好。
代码
Pytorch将STN网络的生成采样网络+采样两个主要操作已经封装到torch.nn.funcitonal里了,因此复现比较简单。
以下代码主要展示了STN模块,其中localisation net可以依据具体的任务和数据进行修正。这里默认输入图像维度为512x512x3:
# 基于卷积的下采样模块
def ConvBnRelu(in_channel, out_channel):
convbnrelu = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(out_channel),
nn.ReLU(inplace=True)
)
return convbnrelu
class SpatialTransformer(nn.Module):
""" Spatial Transformer Network """
def __init__(self):
super(SpatialTransformer, self).__init__()
self.localization = nn.Sequential(
# Conv-Bn-Relu (downsampling)
ConvBnRelu(3, 64),
ConvBnRelu(64, 128),
ConvBnRelu(128, 256),
ConvBnRelu(256, 512),
nn.Conv2d(512, 256, kernel_size=1, bias=False),
nn.Conv2d(256, 1, kernel_size=1, bias=False)
)
# 定位子网
self.fc_loc = nn.Sequential(
nn.Linear(32*32, 128),
nn.BatchNorm1d(128),
nn.ReLU(inplace=True),
nn.Linear(128, 2*3)
)
# initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# indentity transformation 初始化恒等映射
self.fc_loc[3].weight.data.fill_(0)
self.fc_loc[3].bias.data = torch.FloatTensor([1, 0, 0, 0, 1, 0])
def forward(self, img):
n = img.shape[0]
feature = self.localization(img).flatten(start_dim=1)
theta = self.fc_loc(feature).reshape(n, 2, 3)
# spatial transform
grid = F.affine_grid(theta, size=img.size(), align_corners=False)
trans_img = F.grid_sample(img, grid, align_corners=False)
return trans_img