AAAI2023 | DeMT: CNN+Transformer实现多任务学习(分割/深度估计等四项SOTA!)
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
今天是春节后的第一篇原创,关于多任务学习,AAAI2023的work,如果您有相关工作需要分享,请在文末联系我们!
>>点击进入→自动驾驶之心技术交流群
论文名称:Deformable Mixer Transformer for Multi-Task Learning of Dense Prediction
卷积神经网络(CNN)和Transformer具有各自的优势,它们都被广泛用于多任务学习(MTL)中的密集预测。目前对MTL的大多数研究仅依赖于CNN或Transformer,本文结合了可变形CNN和query-based 的Transformer优点,提出了一种新的MTL模型,用于密集预测的多任务学习,基于简单有效的编码器-解码器架构(即,可变形混合器编码器和任务感知transformer解码器),称之为DeMT。首先,可变形混合器编码器包含两种类型的算子:信道感知混合算子,用于允许不同信道之间的通信(即,有效的信道位置混合),以及空间感知可变形算子,其可变形卷积应用于有效地采样更多信息的空间位置(即,变形特征)。第二,任务感知transformer解码器由任务交互block和任务查询block组成。前者用于通过自关注来捕捉任务交互特征,后者利用变形特征和任务交互特征,通过基于查询的Transformer生成相应的任务特定特征,用于相应的任务预测。在两个密集图像预测数据集NYUD-v2和PASCAL Context上的大量实验表明,本文的模型使用更少的GFLOP,但在各种指标上显著优于当前基于Transformer和CNN的模型。
代码:https://github.com/yangyangxu0/DeMT.
1领域背景介绍
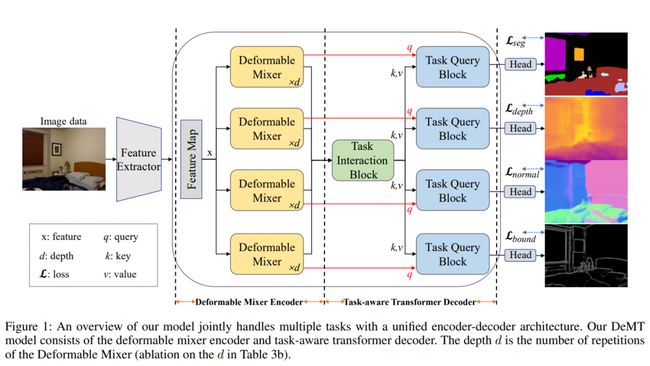
人类视觉可以从一个视觉场景执行不同的任务,如分类、分割、识别等。因此,多任务学习(MTL)研究是计算机视觉领域的热点。期望开发一个强大的视觉模型,以在不同的视觉场景中同时执行多个任务,有望高效工作。如图1所示,本文旨在开发一个强大的视觉模型同时学习多个任务,包括语义分割、人体部位分割、深度估计、边界检测、显著性估计和normal estimation。
尽管基于CNN的MTL模型被谨慎地提出以在多任务密集预测任务上实现有希望的性能,但这些模型仍然受到卷积运算的限制,即缺乏全局建模和跨任务交互能力。一些工作(Bruggemann et al.2021;Vandenhende et al.2020)开发了一种蒸馏方案,通过扩大感受野和堆叠多个卷积层来增加跨任务和全局信息传递的表达能力,但仍然无法直接建立全局依赖性。为了建模全局和跨任务交互信息,基于Transformer的MTL模型利用有效的注意力机制进行全局建模和任务交互。然而,由于query、key和value基于相同的特征,这种自关注方法可能无法关注任务感知特征,特定的自关注可能会导致高计算成本,并限制区分特定任务特征的能力。
基于CNN的模型可以更好地捕捉本地领域中的多任务上下文,但缺乏全局建模和任务交互。基于Transformer的模型更好地关注不同任务的全局信息。然而,它们忽略了task感知,并引入了许多计算成本。因此,开发更好的MTL模型的技术挑战是如何结合基于CNN和基于Transformer的MTL模式的优点。为了解决这些挑战,本文引入了可变形混合transformer(DeMT):一种基于可变形CNN和基于query的transformer优点的简单有效的多任务密集预测方法。
具体来说,DeMT由可变形混合器编码器和任务感知transformer解码器组成。受可变形卷积网络在视觉任务中的成功激励,本文的可变形混合器编码器基于更有效的采样空间位置和信道位置混合(即变形特征),为每个任务学习不同的变形特征。它学习多个变形特征,突出显示与不同任务相关的更多信息区域。在任务感知transformer解码器中,多个变形特征被融合并输入到任务交互模块。使用融合的特征,通过模型任务交互的多头自关注来生成任务交互特征。为了关注每个任务的任务感知,论文直接使用变形特征作为查询标记。希望候选key/value集来自任务交互特性。然后,任务查询块将变形特征和任务交互特征作为输入,并生成任务感知特征。通过这种方式,可变形混合器编码器选择更有价值的区域作为变形特征,以缓解CNN中缺乏全局建模的问题。任务感知transformer解码器通过自关注来执行任务交互,并通过基于查询的transformer来增强任务感知。这种设计既降低了计算成本,又注重任务感知功能。通过在几个公开的MTL密集预测数据集上实验,证明了所提出的DeMT方法在各种指标上取得了最先进的结果!
2DeMT方法介绍
如图1所示,DeMT是非共享编码器,首先,作者设计了一个可变形的混合器编码器来编码每个任务的特定空间特征。第二,提出了任务交互块和任务查询块来建模和解码任务交互信息,并通过自注意机制来解码任务特定特征。
1)特征提取
特征提取器用于聚合多尺度特征并为每个任务制造共享特征图,初始图像数据(3表示图像通道)被输入到主干,然后主干生成四个阶段的图像特征。然后将四个阶段的图像特征上采样到相同的分辨率,然后沿着通道维度将它们连接起来,以获得图像特征,其中H、W和C分别是图像特征的高度、宽度和通道!
2)Deformable Mixer Encoder
受可变形ConvNets和可变形DETR模型的成功启发,作者提出了可变形mixer编码器,该编码器自适应地为每个任务提供更有效的感受野和采样空间位置。为此,可变形mixer编码器被设计为分离空间感知可变形空间特征和信道感知位置特征的混合。

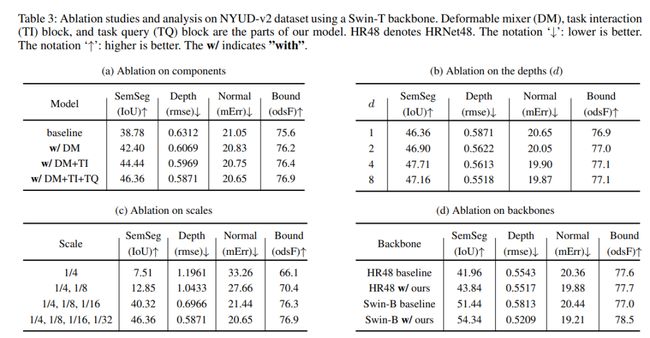
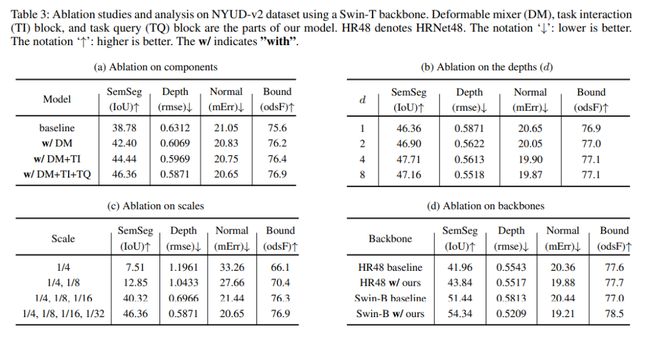
如图2(左)所示,空间感知可变形和信道感知混合算子被交错,以实现两个输入特征维度(HW×C)的交互。可变形的混合器编码器能够捕获与单个任务相对应的独特感受区域,可变形mixer只关注一小组可学习偏移的关键采样点,空间感知可变形体能够对空间上下文聚合进行建模。然后,空间感知可变形、通道感知混合和层归一化算子被堆叠以形成一个可变形混合器。可变形混合器叠层深度对模型的影响如表3b消融实验所示。
可变形混合器编码器结构如图2所示,首先,线性层降低了图像特征X通道维数更小的尺寸C0,线性层可以写成如下:
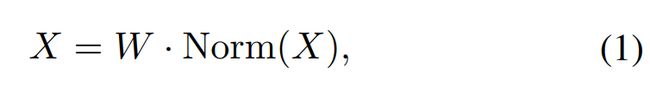
通道感知混合,channel感知混合允许不同通道之间的通信,应用标准逐点卷积(卷积核为1×1)来混合通道位置,它可以表示为:
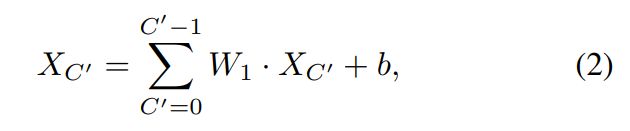
随后,还添加了GELU激活和BatchNorm,该操作计算如下:
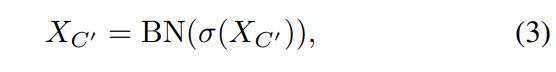
空间感知可变形操作!给定输入图像特征,根据等式(3)点(i,j)是单个通道上的空间位置。
为了生成相对于参考点的相对偏移,将图像特征馈送到卷积算子以学习所有参考点的对应偏移∆(i,j),对于图像上的每个位置点(i,j)特征X,空间可变形可写为:
3)任务感知的Transformer Decoder
在任务感知transformer解码器中,作者设计了任务交互块和任务查询块(见图2),MTL考虑任务交互非常重要。因此,提出了一个任务交互块,通过注意力机制来捕捉每个任务的任务交互。每个任务交互块由两个部分组成,即一个多头自关注模块(MHSA)和一个小型多层感知器(sMLP)。下游任务查询块还包括MHSA和sMLP。任务交互块和任务查询块之间的区别在于,它们的查询特征根本不同。该特征被投影到维度dk的查询(Q)、键(K)和值(V)中,并且自关注由Q、K和V计算,自关注运算如下: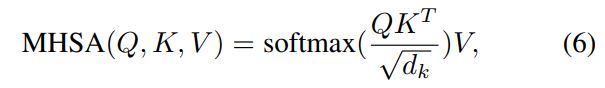
任务交互block,如图2(中间)所示,首先将可变形混合器编码器输出的变形特征连接起来!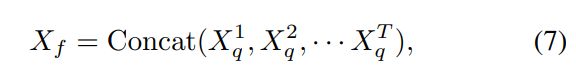 然后,为了高效的任务交互,通过融合特征构建了一种自我关注策略:
然后,为了高效的任务交互,通过融合特征构建了一种自我关注策略:

任务查询block。如图2(右)所示,将变形的特征Xq作为任务查询,将任务交互的特征Xf作为MHSA的键和值。变形特征在MHSA中作为查询应用,以解码针对每个任务的预测,从任务交互特征中提取任务感知特征。首先并行应用LayerNorm来生成查询Q、键K和值V:
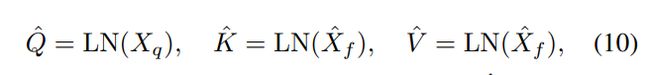
其中LN是层归一化,和分别是可变形混合器编码器和任务交互块的输出。然后,使用MHSA的任务查询block,计算为:
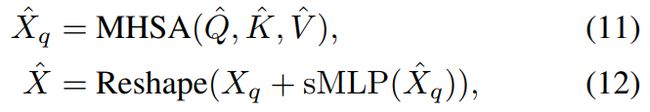
4)损失函数
为了平衡每个任务的损失贡献,我们设置权重α以确定任务t的损失贡献,特定任务损失的加权总和:
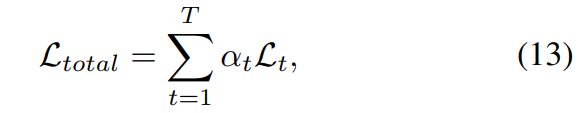
3实验结果
本节对两个广泛使用的密集预测数据集进行了实验,以评估论文的方法在不同度量上的性能,还展示了不同数据集上的可视化结果!主干生成四个尺度(1/4、1/8、1/16、1/32)特征,以在特征提取器中执行多尺度聚合,作者使用SGD训练模型,将学习率设置为10−3,权重衰减设置为5×10−4。整个实验使用ImageNet上的预训练模型进行,所有实验都是在Pytorch平台上进行的,平台上有八个A100 SXM4 40GB GPU。
数据集。在两个可公开访问的数据集NYUD-v2和PASCAL-Context 上进行了实验。NYUD-V2由795幅图像的RGB和深度帧组成训练集,654个图像用于测试。NYUD-V2通常主要用于语义分割(“SemSeg”)、深度估计(“depth”)、表面法线估计(“normal”)和边界检测(“Bound”)任务,为每个图像提供密集的标签。PASCAL-Context 训练和验证包含10103幅图像,而测试包含9637幅图像,PASCAL-Context 通常用于语义分割(“SemSeg”)、人体部位分割(“PartSeg””)、显著性估计(“Sal”)、表面法线估计(“normal”)和边界检测(“Bound”)任务,通过为整个场景提供注释!
论文采用了五个评估指标来将本文的模型与其它现有的多任务模型进行比较:mIoU、均方根误差(rmse)、均值误差(mErr)、最优数据集尺度F测度(odsF)和maxF。
PASCAL-Context 上的实验结果对比:

NYUD-v2数据集上的实验结果:

消融实验:
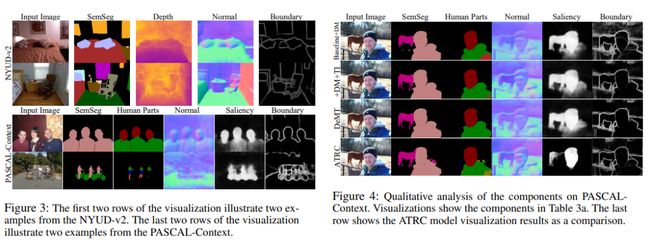
可视化结果:
4未来的改进方向
这项工作仅使用简单的操作来聚合多尺度特征,可以在两个方面进一步改进:考虑使用FPN或FPN变体来聚合多尺度特征,以及如何设计灵活的注意力来学习更多有价值的信息!
5参考
[1] DeMT: Deformable Mixer Transformer for Multi-Task Learning of Dense Prediction
往期回顾
史上最全综述 | 3D目标检测算法汇总!(单目/双目/LiDAR/多模态/时序/半弱自监督)


【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称