【ICCV 2023】EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction
EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction, ICCV 2023
论文:https://arxiv.org/abs/2205.14756
代码:https://github.com/mit-han-lab/efficientvit
解读:MIT Han Lab | EfficientViT:高分辨率低计算视觉识别的增强线性注意力 - 知乎 (zhihu.com)
EfficientViT | 边缘设备上实时语义分割-腾讯云开发者社区-腾讯云 (tencent.com)
摘要
高分辨率密集预测得到越来越多的应用,如计算摄影、自动驾驶等。然而,巨大的计算成本使得在硬件设备上部署最先进的高分辨率密集预报模型变得困难。本文提出EfficientViT,一个新的高分辨率视觉模型家族,具有新颖的多尺度线性特性。不同于现有的高分辨率密集预测模型依赖于大量的softmax注意力、硬件低效的大内核卷积或复杂的拓扑结构来获得良好的性能,多尺度线性注意力只需轻量级和硬件高效的操作就可以实现全局感受野和多尺度学习(高分辨率密集预测的两个理想特征)。
EfficientViT在移动CPU、边缘GPU和云GPU的各种硬件平台上,与以前sota相比,提供了显著的性能提升。在不损失Cityscapes性能的情况下,EfficientViT分别比SegFormer和SegNeXt提供高达13.9倍和6.2倍的GPU延迟降低。对于超分辨率,EfficientViT比Restormer提供高达6.4倍的加速,同时在PSNR中提供0.11dB的增益。对于SegmentAnything,EfficientViT提供与ViT-Huge类似的零样本图像分割质量,GPU吞吐量高84倍。
引言
高分辨率密集预测是计算机视觉中的一项基本任务,在现实世界中有着广泛的应用,包括自动驾驶、医学图像处理、计算摄影等。因此,在硬件设备上部署最先进的(SOTA)高分辨率密集预测模型可以使许多用例受益。然而,SOTA高分辨率密集预测模型所需的计算成本与硬件设备的有限资源之间存在很大差距。它使得在实际应用中使用这些模型变得不切实际。特别是,高分辨率密集预测模型需要高分辨率图像和强大的上下文信息提取能力才能很好地工作。 因此,直接从图像分类移植高效的模型架构不适合高分辨率密集预测。
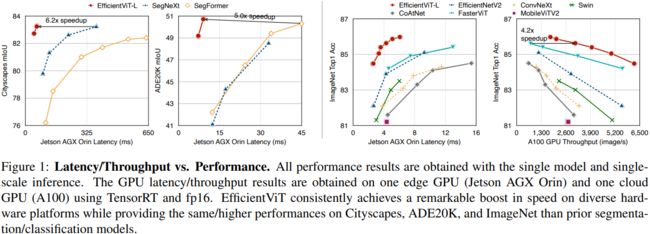
本文介绍了EfficientViT,一种用于高效高分辨率密集预测的新的视觉变换器模型家族。EfficientViT的核心是一个新的多尺度线性注意力模块,它能够通过硬件高效操作实现全局感受野和多尺度学习。
因此,本文模块的设计原则是能够实现这两个关键功能,同时避免硬件低效操作。具体而言,用轻量级ReLU线性注意力代替低效的softmax注意力,以获得全局感受野。ReLU线性注意利用矩阵乘法的关联性,可以在保持函数性的同时,将计算复杂度从二次降到线性。此外,它避免了像softmax这样的硬件低效操作,使其更适合硬件部署。
然而,由于缺乏局部信息提取和多个量表学习能力。因此,用卷积增强ReLU线性注意力,并引入多尺度线性注意力模块来解决ReLU线性注意的容量限制。具体来说,用小内核卷积聚合门附近的令牌,以生成多尺度令牌。对多尺度标记进行ReLU线性关注,以将全局感知场与多尺度学习相结合。还将深度卷积插入到FFN层中,以进一步提高局部特征提取能力。
在两个高分辨率密集预测任务上广泛评估了EfficientViT:语义分割和超分辨率。与先前的SOTA高分辨率密集预测模型相比,EfficientViT性能提升。更重要的是,EfficientViT不涉及硬件低效操作,因此其FLOP减少可以很容易地转化为硬件设备上的延迟减少。
还将EfficientViT应用于Segment Anything,这是一种新兴的可提示分割任务,允许将零样本转移到许多视觉任务。EfficientViT在A100 GPU上比ViT-Huge实现了84倍的加速,同时保持了相当的零样本图像分割质量。
贡献总结如下:
- 介绍了一种新的多尺度线性注意力模块,用于高效的高分辨率密集预测。它实现了全局感受野和多尺度学习,同时在硬件上保持了良好的效率。据论文所知,该工作首次证明了线性注意力对高分辨率密集预测的有效性。
- 设计了EfficientViT,这是一个新的高分辨率视觉模型家族,基于所提出的多尺度线性注意力模块。
- 与之前的SOTA模型相比,论文的模型在不同硬件平台(移动CPU、边缘GPU和云GPU)上的语义分割、超分辨率、Segment Anything和ImageNet分类方面显著加快。
方法
多尺度线性注意力
Enable Global Receptive Field with ReLU Linear Attention
NLP中的线性注意力为softmax注意力,

本文使用ReLU作为核函数,对硬件更友好。公式(1)可改写为


线性注意力有两个关键优点:
- 允许利用矩阵乘法的关联属性来将计算复杂度从二次降低到线性而不改变功能。
- 在注意力模块中不涉及 softmax。 Softmax 在硬件上效率非常低,避免它可以减少延迟。
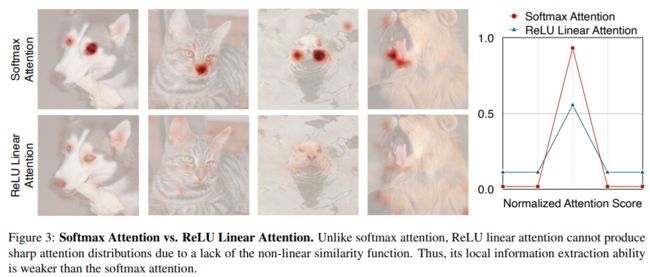
Softmax注意力与ReLU线性注意力比较。和softmax注意不同,由于缺乏非线性相似函数,ReLU线性注意不能产生尖锐的注意分布。它的局部信息提取能力弱于softmax注意力。
Softmax注意和ReLU线性注意的延迟比较。ReLU线性注意力比具有类似计算的softmax注意力快3.3-4.5倍,这要归功于消除了对硬件不友好的操作(softmax)。延迟是在高通Snapdragon 855 CPU上测量的,该CPU具有TensorFlow Lite、批量大小1和fp32。

Address ReLU Linear Attention’s Limitations
尽管ReLU线性注意力在计算复杂度和硬件稳定性方面优于softmax注意力,但ReLU线性注意有局限性。图3展示了softmax注意力和ReLU线性注意力的注意力图。由于缺乏非线性相似函数,ReLU线性注意力无法生成集中注意力图,使其在捕捉局部信息方面较弱。
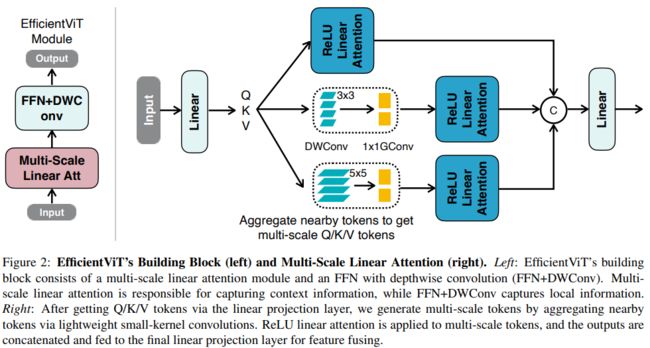
为了减轻它的局限性,建议用卷积来增强ReLU的线性注意力。具体来说,在每个FFN层中插入一个深度卷积。构建块的概述如图2(左)所示,其中ReLU线性注意力捕获上下文信息,FFN+DWConv捕获局部信息。
聚合来自附近Q/K/V令牌的信息,以获得多尺度令牌,从而提高ReLU线性模型的多尺度学习能力。该信息聚合过程对于每个头部中的每个Q、K和V是独立的。只使用小内核深度可分离卷积进行信息分离,以避免损害硬件效率。在实际实现中,在GPU上独立执行这些聚合操作是低效的。因此,利用组卷积来减少总运算次数。具体而言,将所有DWConv融合为单个DWConv,而将所有1x1 Conv组合为单个1x1组卷积,其中组的数量为3×#头,每组中的通道数量为d。在获得多尺度令牌后,对它们进行ReLU线性关注,以提取多尺度全局特征。最后,沿着头部维度连接特征,并将它们提供给最终的线性投影层以融合特征。
EfficientViT结构
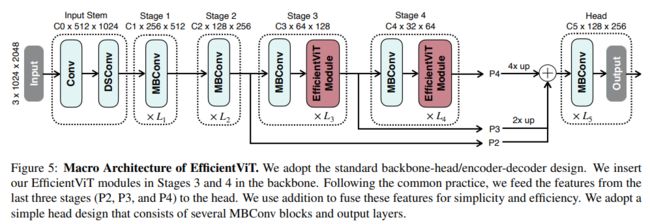
Backbone. EfficientViT的主干遵循标准设计,由input stem和四个stage组成,这些阶段的特征图大小逐渐减小,通道数量逐渐增加。在stage3和stage4插入EfficientViT模块,下采样使用MBConv。
Head. P2、P3和P4表示阶段2、3和4的输出,形成特征图的金字塔。使用1x1卷积和标准上采样操作(例如,双线性/双三次上采样)来匹配它们的空间和信道大小,并通过加法将它们融合。采用了一种简单的头部设计,该设计包括几个MBConv块和输出层(即预测和上采样)。
实验
多尺度学习的消融实验

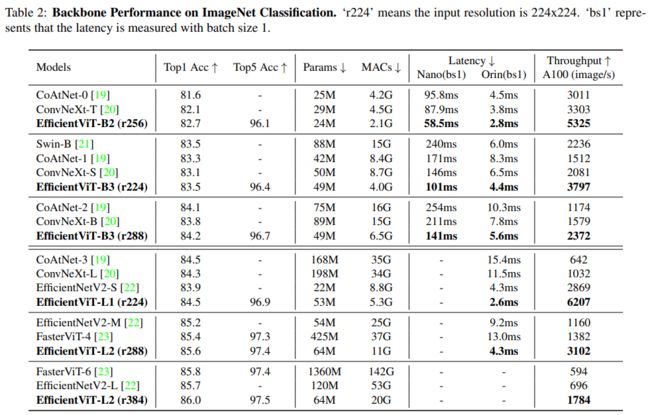
ImageNet分类比较实验
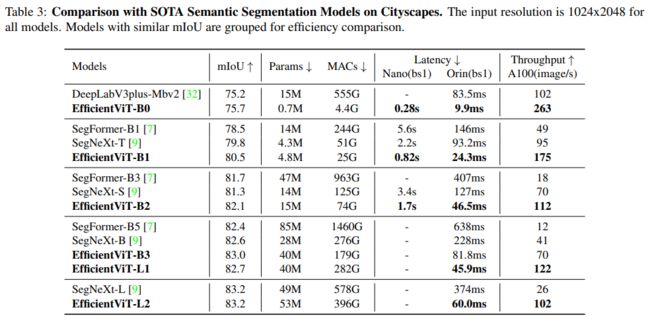
Cityscapes语义分割比较实验
ADE20K语义分割比较实验

超分辨率比较实验

COCO val2017零样本图像分割比较实验

可视化结果


关键代码
seg.py
#https://github.com/mit-han-lab/efficientvit/blob/master/efficientvit/models/efficientvit/seg.py
import torch
import torch.nn as nn
from efficientvit.models.efficientvit.backbone import EfficientViTBackbone, EfficientViTLargeBackbone
from efficientvit.models.nn import (
ConvLayer,
DAGBlock,
FusedMBConv,
IdentityLayer,
MBConv,
OpSequential,
ResidualBlock,
UpSampleLayer,
)
from efficientvit.models.utils import build_kwargs_from_config
__all__ = [
"EfficientViTSeg",
"efficientvit_seg_b0",
"efficientvit_seg_b1",
"efficientvit_seg_b2",
"efficientvit_seg_b3",
"efficientvit_seg_l1",
"efficientvit_seg_l2",
]
class SegHead(DAGBlock):
def __init__(
self,
fid_list: list[str],
in_channel_list: list[int],
stride_list: list[int],
head_stride: int,
head_width: int,
head_depth: int,
expand_ratio: float,
middle_op: str,
final_expand: float or None,
n_classes: int,
dropout=0,
norm="bn2d",
act_func="hswish",
):
inputs = {}
for fid, in_channel, stride in zip(fid_list, in_channel_list, stride_list):
factor = stride // head_stride
if factor == 1:
inputs[fid] = ConvLayer(in_channel, head_width, 1, norm=norm, act_func=None)
else:
inputs[fid] = OpSequential(
[
ConvLayer(in_channel, head_width, 1, norm=norm, act_func=None),
UpSampleLayer(factor=factor),
]
)
middle = []
for _ in range(head_depth):
if middle_op == "mbconv":
block = MBConv(
head_width,
head_width,
expand_ratio=expand_ratio,
norm=norm,
act_func=(act_func, act_func, None),
)
elif middle_op == "fmbconv":
block = FusedMBConv(
head_width,
head_width,
expand_ratio=expand_ratio,
norm=norm,
act_func=(act_func, None),
)
else:
raise NotImplementedError
middle.append(ResidualBlock(block, IdentityLayer()))
middle = OpSequential(middle)
outputs = {
"segout": OpSequential(
[
None
if final_expand is None
else ConvLayer(head_width, head_width * final_expand, 1, norm=norm, act_func=act_func),
ConvLayer(
head_width * (final_expand or 1),
n_classes,
1,
use_bias=True,
dropout=dropout,
norm=None,
act_func=None,
),
]
)
}
super(SegHead, self).__init__(inputs, "add", None, middle=middle, outputs=outputs)
class EfficientViTSeg(nn.Module):
def __init__(self, backbone: EfficientViTBackbone or EfficientViTLargeBackbone, head: SegHead) -> None:
super().__init__()
self.backbone = backbone
self.head = head
def forward(self, x: torch.Tensor) -> torch.Tensor:
feed_dict = self.backbone(x)
feed_dict = self.head(feed_dict)
return feed_dict["segout"]
def efficientvit_seg_b0(dataset: str, **kwargs) -> EfficientViTSeg:
from efficientvit.models.efficientvit.backbone import efficientvit_backbone_b0
backbone = efficientvit_backbone_b0(**kwargs)
if dataset == "cityscapes":
head = SegHead(
fid_list=["stage4", "stage3", "stage2"],
in_channel_list=[128, 64, 32],
stride_list=[32, 16, 8],
head_stride=8,
head_width=32,
head_depth=1,
expand_ratio=4,
middle_op="mbconv",
final_expand=4,
n_classes=19,
**build_kwargs_from_config(kwargs, SegHead),
)
else:
raise NotImplementedError
model = EfficientViTSeg(backbone, head)
return model
Backbone.py
# https://github.com/mit-han-lab/efficientvit/blob/master/efficientvit/models/efficientvit/backbone.py
import torch
import torch.nn as nn
from efficientvit.models.nn import (
ConvLayer,
DSConv,
EfficientViTBlock,
FusedMBConv,
IdentityLayer,
MBConv,
OpSequential,
ResBlock,
ResidualBlock,
)
from efficientvit.models.utils import build_kwargs_from_config
__all__ = [
"EfficientViTBackbone",
"efficientvit_backbone_b0",
"efficientvit_backbone_b1",
"efficientvit_backbone_b2",
"efficientvit_backbone_b3",
"EfficientViTLargeBackbone",
"efficientvit_backbone_l0",
"efficientvit_backbone_l1",
"efficientvit_backbone_l2",
"efficientvit_backbone_l3",
]
class EfficientViTBackbone(nn.Module):
def __init__(
self,
width_list: list[int],
depth_list: list[int],
in_channels=3,
dim=32,
expand_ratio=4,
norm="bn2d",
act_func="hswish",
) -> None:
super().__init__()
self.width_list = []
# input stem
self.input_stem = [
ConvLayer(
in_channels=3,
out_channels=width_list[0],
stride=2,
norm=norm,
act_func=act_func,
)
]
for _ in range(depth_list[0]):
block = self.build_local_block(
in_channels=width_list[0],
out_channels=width_list[0],
stride=1,
expand_ratio=1,
norm=norm,
act_func=act_func,
)
self.input_stem.append(ResidualBlock(block, IdentityLayer()))
in_channels = width_list[0]
self.input_stem = OpSequential(self.input_stem)
self.width_list.append(in_channels)
# stages
self.stages = []
for w, d in zip(width_list[1:3], depth_list[1:3]):
stage = []
for i in range(d):
stride = 2 if i == 0 else 1
block = self.build_local_block(
in_channels=in_channels,
out_channels=w,
stride=stride,
expand_ratio=expand_ratio,
norm=norm,
act_func=act_func,
)
block = ResidualBlock(block, IdentityLayer() if stride == 1 else None)
stage.append(block)
in_channels = w
self.stages.append(OpSequential(stage))
self.width_list.append(in_channels)
for w, d in zip(width_list[3:], depth_list[3:]):
stage = []
block = self.build_local_block(
in_channels=in_channels,
out_channels=w,
stride=2,
expand_ratio=expand_ratio,
norm=norm,
act_func=act_func,
fewer_norm=True,
)
stage.append(ResidualBlock(block, None))
in_channels = w
for _ in range(d):
stage.append(
EfficientViTBlock(
in_channels=in_channels,
dim=dim,
expand_ratio=expand_ratio,
norm=norm,
act_func=act_func,
)
)
self.stages.append(OpSequential(stage))
self.width_list.append(in_channels)
self.stages = nn.ModuleList(self.stages)
@staticmethod
def build_local_block(
in_channels: int,
out_channels: int,
stride: int,
expand_ratio: float,
norm: str,
act_func: str,
fewer_norm: bool = False,
) -> nn.Module:
if expand_ratio == 1:
block = DSConv(
in_channels=in_channels,
out_channels=out_channels,
stride=stride,
use_bias=(True, False) if fewer_norm else False,
norm=(None, norm) if fewer_norm else norm,
act_func=(act_func, None),
)
else:
block = MBConv(
in_channels=in_channels,
out_channels=out_channels,
stride=stride,
expand_ratio=expand_ratio,
use_bias=(True, True, False) if fewer_norm else False,
norm=(None, None, norm) if fewer_norm else norm,
act_func=(act_func, act_func, None),
)
return block
def forward(self, x: torch.Tensor) -> dict[str, torch.Tensor]:
output_dict = {"input": x}
output_dict["stage0"] = x = self.input_stem(x)
for stage_id, stage in enumerate(self.stages, 1):
output_dict["stage%d" % stage_id] = x = stage(x)
output_dict["stage_final"] = x
return output_dict
def efficientvit_backbone_b0(**kwargs) -> EfficientViTBackbone:
backbone = EfficientViTBackbone(
width_list=[8, 16, 32, 64, 128],
depth_list=[1, 2, 2, 2, 2],
dim=16,
**build_kwargs_from_config(kwargs, EfficientViTBackbone),
)
return backbone