LV.2 Linux C语言高级
D1 软件包管理及shell命令
环境安装
装虚拟机需要将宿主机的虚拟化功能打开。
重启电脑。
Linux介绍
1969年,由KenThompson在AT&T贝尔实验室实现的。使用的是用汇编语言。
1970年,KenThompson(肯·汤普逊)和DennisRitchie(丹尼斯·里奇)使用 C语言对整个系统进行了再加工和编写,使得Unix能够很容易的移植到其他硬件的计算机上。
Unix家庭树
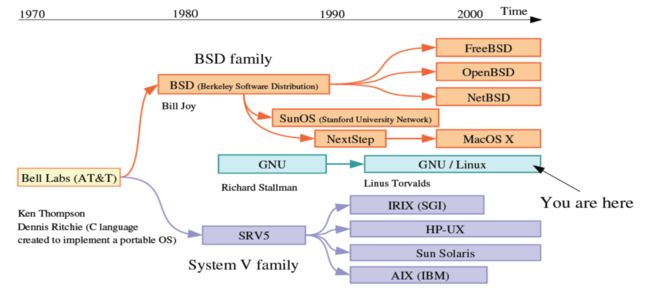
什么是Linux?
GNU&GPL 参考1 参考2
Linux确实存在,许多人都在使用它,但它仅仅是所用系统的一部分。Linux是内核:它是为你运行的其他程序分配计算机资源的程序。内核是操作系统的基本部分,但是它自己并无用处;它只能在完整的操作系统框架下才能发挥作用。Linux一般和GNU操作系统一起使用:整个系统基本上就是GNU加上Linux,或叫GNU/Linux。所有被叫做“Linux”的发行版实际上是GNU/Linux发行版。
GNU = GNU is Not Unix
由Richard Stallman(理查德·斯托曼)在1984创建
最初的软件:gcc、make、glibc…
GPL = General Public License (自由软件保护条款)
What is Copyleft? - GNU Project - Free Software Foundation(自由软件基金会)
学习用Ubuntu(每年4月份10月份发行一次)下载Ubuntu桌面系统 | Ubuntu
Linux发行版本

脱颖而出的Ubuntu

Ubuntu发行版本代号

体系结构
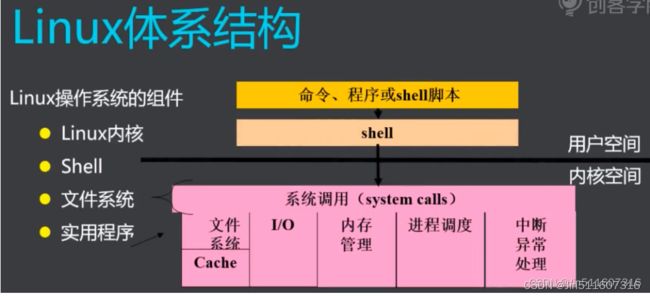

- 内核更新非常快,三天两头更新 The Linux Kernel Archives
- 选择命令终端窗口
目前,在桌面环境下的命令终端仿真器程序有很多,它们各有特色,都拥有各自的用户群。目前流行的终端窗口有:
Xterm、
Gnome-terminal、
Konsole、
Rxvt等
Ubuntu Linux默认安装的命令终端有Gnome-terminal、Xterm,其他的命令终端都需要另行安装。
Gnome-terminal是GNOME默认的命令终端。比Xterm具有更多、更强的功能,提供了剪切、粘贴、多标签显示,以及设置终端配置文件等功能,中文支持和用户界面也很友好。用户可以使用窗口菜单,或快捷键完成操作。

deb软件包管理机制
流行的两种软件包管理机制
Debian Linux(一种自由操作系统)首先提出软件包”的管理机制,Deb软件包;Redhat Linux(红帽)由此提出了 Rpm 软件包
将应用程序的二进制文件、配置文档、man/info帮助页面等文件合并打包在一个文件中,用户使用软件包管理器直接操作软件包,完成获取、安装、卸载、查询等操作。随着Linux操作系统规模的不断扩大,系统中软件包间复杂的依赖关系,导致Linux用户麻烦不断。
随着Linux操作系统规模的不断扩大,系统中软件包间复杂的依赖关系,导致Linux用户麻烦不断。
Debian Linux开发出了APT(Advanced Packaging Tool)软件包管理器。
检查和修复软件包依赖关系
利用Internet网络帮助用户主动获取软件包
APT工具再次促进了Deb软件包更为广泛地使用,成为Debian Linux的一个无法替代的亮点。
软件包的类型
Ubuntu有两种类型的软件包:二进制软件包(deb)和源码包(deb-src)
二进制软件包(Binary Packages):它包含可执行文件、库文件、配置文件、man/info页面、版权声明和其它文档。
源码包(Source Packages):包含软件源代码、版本修改说明、构建指令以及编译工具等。先由tar工具归档为.tar.gz文件,然后再打包成.dsc文件。
在用户不确定一个软件包类型时,可以使用file命令查看文件类型。 
软件包的命名

dpkg(Debian Package”的简写)命令
软件包管理工具分类
根据用户交互方式的不同,可以将常见的软件包管理工具分为三类。

命令行软件包管理工具(dpkg):
dpkg -i 安装一个在本地文件系统上存在的Debian软件包
dpkg -r 移除一个已经安装的软件包
dpkg -P 移除已安装软件包及配置文件
dpkg -L 列出安装的软件包清单
dpkg -s 显出软件包的安装状态
文本窗口软件包管理工具:

aptitude为一个高级包管理工具,也是目前首选的字符界面 APT前端。
一旦开始使用,最好一直使用它。否则将失去其包存放的软件安装清单,就不能享受自动删除多余软件包的功能
aptitude工具也可以在命令行操作
aptitude update 更新可用的包列表
aptitude upgrade 升级可用的包
aptitude dist-upgrade 将系统升级到新的发行版
aptitude install pkgname 安装包
aptitude remove pkgname 删除包
aptitude purge pkgname 删除包及其配置文件
aptitude search string 搜索包
aptitude show pkgname 显示包的详细信息
aptitude clean 删除下载的包文件
aptitude autoclean 仅删除过期的包文件
图形界面软件包管理工具(synaptic ):

APT 工作原理
Ubuntu采用集中式的软件仓库机制,将各式各样的软件包分门别类地存放在软件仓库中,进行有效地组织和管理。然后,将软件仓库置于许许多多的镜像服务器中,并保持基本一致。因此,对于用户,这些镜像服务器就是他们的软件源(reposity)。

在Ubuntu系统中,使用软件源配置文件/etc/apt/sources.list 列出最合适访问的镜像站点地址。 软件源配置文件只是告知Ubuntu系统可以访问的镜像站点地址。但那些镜像站点都拥有什么软件资源并不清楚。若是每安装一个软件包,就在服务器上寻找一边,效率是很低的。因而,就有必要为这些软件资源列个清单(建立索引文件),以便本地主机查询。这就是APT软件包管理器的工作原理。
软件源配置文件
/etc/apt/sources.list。本质就是一个普通的文本文件,可以在超级管理员授权下,使用任何文本编辑器进行编辑。在该文件中,添加的软件源镜像站点称为一个配置项,并遵循以下格式:

软件源
根据软件包的开发组织对该软件的支持程度,以及遵从的开源程度,划分为如下四类:
核心(Main):官方维护的开源软件,是由Ubuntu官方完全支持的软件,包括大多数流行的、稳定的开源软件,是Ubuntu默认安装的基本软件包;
公共(Universe):社区维护的开源软件,是由Ubuntu社区的计算机爱好者维护的软件。这些软件包没有安全升级的保障。用户在使用时,需要考虑这些软件包存在的不稳定性;
受限(Restricted):官方维护的非开源软件,是专供特殊用途,而且没有自由软件版权,不能直接修改软件,但依然被Ubuntu团队支持的软件;
多元化(Multiverse):非Ubuntu官方维护的非开源软件,用户使用这些软件包时,需要特别注意版权问题。
刷新软件源
修改了配置文件——/etc/apt/sources.list,目的只是告知软件源镜像站点的地址。但那些所指向的镜像站点所具有的软件资源并不清楚,需要将这些资源列个清单,以便本地主机知晓可以申请哪些资源。
使用“apt-get update”命令会扫描每一个软件源服务器,并为该服务器所具有软件包资源建立索引文件,存放在本地的/var/lib/apt/lists/目录中。
dpkg和apt软件包管理器有什么区别?
dpkg 在命令行模式下完成软件包管理任务。为完成软件包的获取、查询、软件包依赖性检查、安装、卸载等任务,需要使用各自不同的命令
Debian Linux开发出了APT软件包管理器。 用于,检查和修复软件包依赖关系 ,利用Internet网络帮助用户主动获取软件包
管理软件包
在Ubuntu Linux中,通常使用apt-get命令管理软件包,只需告知软件包名字,就可以自动完成软件包的获取、安装、编译和卸载,以及检查软件包依赖关系。 apt-get命令提供了一个软件包管理的命令行平台。在这个平台上使用更丰富的子命令,完成具体的管理任务。
apt-get subcommands(子命令) [ -d | -f | -m | -q | --purge | --reinstall | - b | - s | - y | - u | - h | -v ] (选项) pkg


修复软件包依赖关系
如果由于故障而中断软件安装过程,可能会造成关联的软件包只有部分安装。之后,用户就会发现该软件既不能重装又不能删除。
作为组合命令,下面前者用于检查软件包依赖关系,后者用于修复依赖关系。
“apt-get check”——“apt-get -f install”
在处理依赖关系上,apt-get会自动下载并安装具有依赖关系(depends)的软件包,但不会处理与安装软件包存在推荐(recommends)和建议(suggests)关系的软件包。
更新软件包
在Ubuntu Linux中,只需使用命令“apt-get upgrade”就可以轻松地将系统中的所有软件包一次性升级到最新版本
安装软件包
在准备好软件源并连通网络后,用户只需告知安装软件的名称,“apt-get install”命令就可以轻松完成整个安装过程,而无须考虑软件包的版本、优先级、依赖关系等。
使用“apt-get install”下载软件包大体分为四步:
STEP1,扫描本地存放的软件包更新列表(由apt-get update命令刷新更新列表),找到最新版本的软件包;
STEP2,进行软件包依赖关系检查,找到支持该软件正常运行的所有软件包;
STEP3,从软件源所指的镜像站点中,下载相关软件包;
STEP4 ,解压软件包,并自动完成应用程序的安装和配置。
重新安装软件包
当用户不小心损坏了已安装的软件包,而需要修复。或者,希望重新安装软件包中某些文件的最新版本,可以重新安装软件包。

卸载软件包
不完全卸载 “apt-get remove”会关注那些与被删除的软件包相关的其它软件包,删除一个软件包时,将会连带删除与该软件包有依赖关系的软件包。
完全卸载 “apt-get --purge remove”命令在卸载软件包文件的同时,还删除该软件包所使用的配置文件。
清理软件包缓冲区
清理软件包缓冲区.如果用户认为软件包缓冲区中的文件没有任何价值了,有必要删除全部下载的软件包。可以使用“apt-get clean”清理整个软件包缓冲区,除了lock锁文件和partial目录。

按照依赖关系清理缓冲区中多余的软件包 如果用户希望缓冲区中只保留最新版本的软件包,多余版本全部清除,可以使用“apt-get autoclean”命令。

查询软件包描述信息
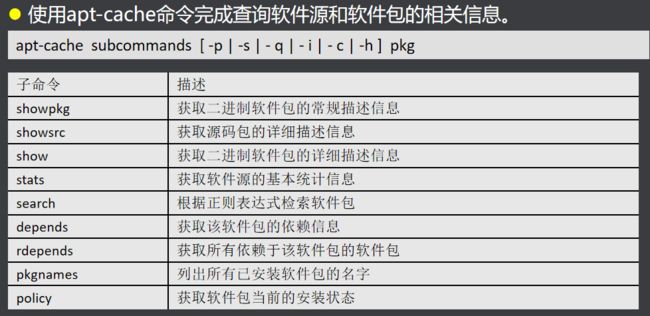
使用“apt-cache show”命令获取指定软件包的详细信息,包括软件包安装状态、优先级、适用架构、版本、存在依赖关系的软件包,以及功能描述。该命令可以同时显现多个软件包的详细信息。
获取软件包安装状态
使用“apt-cache policy”可以获取软件包当前的安装状态
如果用户仅想了解某个软件包依赖于哪些软件包,可以使用“apt-cache depends”命令
如果用户仅想了解某个软件包被哪些软件包所依赖,可以使用“apt-cache rdepends”命令。
总结与思考
本节课主要讲解了APT软件包管理器的工作原理及主要命令。
下列文件什么作用?
/etc/apt/sources.list
/var/lib/apt/lists/*
/var/cache/apt/archives
shell基本命令
shell简介
shll 直译为贝壳 ,Linux内核的一个外层保护工具,完成用户与内核之间的交互。将用户的命令或按键转化程序内核所能够理解的指令,控制操作系统做出响应,直到控制相关硬件设备。然后,将输出结果通过shell提交给用户。
命令是用户向系统内核发出控制请求,与之交互的文本流。
shell是一个命令行解释器,将用户命令解析为操作系统所能理解的指令,实现用户与操作系统的交互。
当需要重复执行若干命令,可以将这些命令集合起来,加入一定的控制语句,编辑成为shell脚本文件,交给shell批量执行。
用户在命令行提示符下键入命令文本,开始与Shell进行交互
接着,shell将用户的命令或按键转化成内核所能够理解的指令
控制操作系统做出响应,直到控制相关硬件设备
然后,shell将输出结果通过shell提交给用户

选择shell
最初的UNIX shell经过多年的发展,由不同的机构、针对不同的目的,开发出许多不同类型的shell程序。目前流行的shell主要有几种 :
- Bourne(/bʊən/ 小溪) Shell(简称sh):它是Unix的第一个shell程序,早已成为工业标准。目前几乎所有的Linux系统都支持它。不过Bourne Shell的作业控制功能薄弱,且不支持别名与历史记录等功能。
- C Shell(简称csh)
- Korn Shell(简称ksh)
- Bourne Again Shell(简称bash):能够提供环境变量以配置用户Shell环境,支持历史记录,内置算术功能,支持通配符表达式,将常用命令内置简化。
体验shell命令的乐趣
立即关机与重启
使用系统中的图形界面

使用shell命令

在命令行键入以上命令,系统立即关机 :


在命令行键入以上命令,系统立即重新启动 :
定时关机sudo shutdown -h +45 “this is all,game over.” 时间限定在45分钟内,否则计算机将自动关机
定时重启sudo shutdown -r +60 计算机会在60分钟后自动重启
shell命令格式
shell提示符标识了命令行的开始。用户在提示符后面输入一条命令并按Enter键,完成向系统提交指令。
通常shell命令提示符采用以下的格式:

username:用户名,显示当前登录用户的账户
hostname:主机名,显示登录的主机名,例如若远 程登录后,则显示登录的主机名;
direction:目录名,显示当前所处的路径,当在根目录下显示为“/”,当在用户主目录下显示为“~”;
通常一条命令包含三个要素:命令名称、选项、参数。命令名称是必须的,选项和参数都可能是可选项。命令格式如下所示:
KaTeX parse error: Expected 'EOF', got '#' at position 28: …当前用户为超级用户,提示符为“#̲”,其他用户的提示符均为“”;
Command:命令名称,Shell命令或程序,严格区分大小写
Options:命令选项,用于改变命令执行动作的类型,由“-”引导,可以同时带有多个选项;
Argument:命令参数,指出命令作用的对象或目标,有的命令允许带多个参数。
通常一条命令包含三个要素:命令名称、选项、参数。命令名称是必须的,选项和参数都可能是可选项。命令格式如下所示:
![]()
KaTeX parse error: Expected 'EOF', got '#' at position 28: …当前用户为超级用户,提示符为“#̲”,其他用户的提示符均为“”;
Command:命令名称,Shell命令或程序,严格区分大小写
Options:命令选项,用于改变命令执行动作的类型,由“-”引导,可以同时带有多个选项;
Argument:命令参数,指出命令作用的对象或目标,有的命令允许带多个参数。
一条命令的三要素中间用空格隔开
多行命令用 ‘;’ 分隔。
同一行命令换行结尾加 ‘\’ 声明未结束。
不带选项和参数

ls命令未带任何参数,列出当前目录中的所有文件,只显示文件名称。
命令不带选项或参数,通常意为使用默认选项或参数。
命令行操作
bash(Bourne Again Shell,简称bash)除了在命令编辑功能上比sh有很大改进外,还增加了特有功能极大地方便了用户在Shell命令行上的操作。
补齐命令与文件名 :按两下TAB或ESC键,用户命令补全, 按一次TAB用于文件名补全。
查询命令历史 : history

总结与思考
本节课先对shell做了基本介绍,然后讲解了linux命令的基本格式,最后介绍了常见的命令行操作
思考:
什么是shell?
如何更改历史记录容量?
历史记录如何删除?
shell中的特殊字符
通配符
当需要用命令处理一组文件,例如file1.txt、file2.txt、file3.txt……,用户不必一一输入文件名,可以使用shell通配符。shell命令的通配符含义如下表


管道
管道可以把一系列命令连接起来,意味着第一个命令的输出将作为第二个命令的输入,通过管道传递给第二个命令,第二个命令的输出又将作为第三个命令的输入,以此类推。就像通过使用“|”符连成了一个管道。

以上操作中,借助管道“|”,将ls的输出直接作为wc命令的输入。使用管道可以巧妙的将一些命令联合使用,得到单个命令所无法实现的效果。例如使用以上的命令组合,得到的是/usr/bin目录下文件的个数。
grep -rn “Linux” /etc/passwd | wc -w 查看文件行数
总结与思考
本节课主要介绍了shell中的几种特殊字符的用法以及管道的使用
思考
shell中有哪些特殊字符?
shell中管道的作用?
shell中grep命令和管道如何结合?
输入/输出重定向
输入/输出重定向是改变shell命令或程序默认的标准输入/输出目标,重新定向到新的目标。
linux中默认的标准输入定义为键盘,标准输出定义为终端窗口。
用户可以为当前操作改变输入或输出,迫使某个特定命令的输入或输出来源为外部文件。

cat命令功能为在标准输出上显示文件。下面通过一个实例,可以更好地理解重定向的功能。

命令置换
命令替换是将一个命令的输出作为另一个命令的参数。命令格式如下所示。
其中,命令command2的输出将作为命令command1的参数。需要注意,命令置换的单引号为ESC键下方的“`”键 
pwd命令用于显示当前目录的绝对路径。在上面的命令行中,使用命令置换符,将pwd的运行结果作为ls命令的参数。最终,命令执行结果是显示当前目录的文件内容。 
总结与思考
本节课首先介绍了shell中的输入输出重定向的用法,然后介绍了命令置换的 使用
思考:
什么叫输入输出重定向?
有哪些输入输出重定向符?
D2 linux shell命令
2.1shell基本系统维护命令
获取联机帮助
man 可以找到特定的联机帮助页,man ls 。联机帮助页提供了指定命令commandname的相关信息,包括:名称、函数、语法以及可选参数描述等。无论帮助有多长,都遵循这个格式显示。在页面很多的情况下使用PageUp和PageDown键翻页。最后,使用“:q”退出帮助页面。
NAME:命令的名称
SYNOPSIS:命令的语法格式
DESCRIPTION:命令的一般描述以及用途
OPTIONS:描述命令所有的参数或选项
SEE ALSO:列出联机帮助页中与该命令直接相关或功能相近的其他命令
BUGS:解释命令或其输出中存在的任何已知的问题或缺陷
EXAMPLES:普通的用法示例
AUTHORS:联机帮助页以及命令的作者
基本系统维护命令
passwd 修改当前用户的口令,sudo passwd
出于系统安全考虑,Linux系统中的每一个帐号都必须同时具备用户名和密码。
可以使用passwd命令,为已有账户重新修改用户口令。
需要说明的是,超级用户root可以修改所有其他用户的口令,而普通用户只能修改自己的用户口令,如果确要修改超级用户或其他用户口令的话,需要具有超级用户的权限
passwd命令的一般语法格式为:
![]()
单独使用passwd命令,意为修改当前用户自己的口令。下面命令实例用于修改用户自己的口令。

su
单独使用su命令,默认为要转换为超级用户root。
su命令用于临时改变用户身份,具有其他用户的权限。普通用户可以使用su命令临时具有超级用户的权限;超级用户也可以使用普通用户身份完成一些操作。当需要放弃当前用户身份,可以使用exit命令切换回来。su命令的一般语法格式为:

选项“-c”表示执行一个命令后就结束;-m表示仍保留环境变量不变;-表示转换用户身份时,同时使用该用户的环境。
echo
echo命令用于在标准输出——显示器上显示一段文字,一般起到提示作用。echo命令的一般语法格式为:

选项-n表示输出文字后不换行。提示信息字符串可以加引号,也可以不加。

date
date命令用于显示和设置系统日期和时间。date命令的一般语法格式为:

选项-s表示按照datestr日期显示格式设置日期;单独使用date命令,用于显示系统时钟中当前日期。时间的格式为:“hh:mm:ss”,日期格式为:“mm/dd/yy”。

clear 清屏 ctrl + l
df
df命令用于查看磁盘空间的使用情况。查看磁盘空间是用户应当经常做的事情,因为谁也不希望看到根或/var分区在不经意间填满,以便及时清理。df命令的一般格式为:

其中,参数Filesystem表示物理文件系统。各选项的含义如表所示。

从以下命令的执行结果可以看到,这台计算机只有一块硬盘(/dev/sda1),文件格式类型为Ext3,已经使用36%的存储空间。同时,可以发现计算机上还安装了CD-ROM(/dev/hdc)、USB存储器(/dev/sdb1)。其他分区均为专用的虚拟文件系统

df 命令常用参数:
-a :列出所有文件系统
-k :列出磁盘的分配情况(KB)
-h :同-k, 但大小以G、M,K单位显示
-l :仅列出本地文件系统
例:
#df -h
du
列出目录和文件使用的磁盘块。出目录和文件所使用的磁盘块数,每块占512个字节。
常用参数:
-a :仅列出空闲的文件数
-h :列出磁盘的使用情况(KB)
-s :列出总的空闲空间(KB)
例: #du –h /etc
2.2用户管理
/ etc :etc是Etcetera的缩写,是“等等”的意思,用于存放所有系统管理所需要的配置文件和子目录,基本上硬件和软件配置文件都在此目
用户管理
用户的属性
用户名
口令
用户ID(UID)
用户主目录(HOME)
用户shell
/etc/passwd文件
/etc/passwd文件是系统能够识别的用户清单。用户登陆时,系统查询这个文件,确定用户的UID并验证用户口令
登陆名
经过加密的口令
UID
默认的GID
个人信息
主目录
登陆shell
/etc/group文件
包含了UNIX组的名称和每个组中成员列表,每一行代表一个组,包括四个字段,组名、加密的口令、GID号、成员列表,彼此用逗号隔开。
group文件实例

添加用户
adduser
语法:adduser
实例:
# adduser newuser
添加用户名为newuser的新用户
adduser配置文件
/etc/adduser.conf
FIRST_UID=1000
LAST_UID=29999
USERS_GID=100
DHOME=/home
DSHELL=/bin/bash
SKEL=/etc/skel
SKEL模板
/etc/skel目录是被 /usr/sbin/useradd使用
把想要新用户拥有的配置文件从/etc/skel目录拷贝,常用的文件:
.bash_profile
.bashrc
.bash_logout
.dircolors
.inputrc
.vimrc
添加新用户的过程
系统
编辑passwd和shadow文件,定义用户帐号
设置一个初始口令
创建用户主目录,用chown和chmod命令改变主目录 的属主和属性
为用户所进行的步骤
将默认的启动文件复制到用户主目录中
设置用户的邮件主目录并建立邮件别名
2.2用户管理相关命令介绍
设置初始口令
使用passwd命令可以修改用户口令
root用户可以修改任何用户的口令
语法:passwd [-k] [-l] [u] [-f] [-d] [-S] username
使用方法:
passwd username
修改用户属性
usermod
语法:usermod [-u uid [-o]] [-g group] [-G gropup,…]
[-d home [-m]] [-s shell] [-c comment]
[-l new_name] [-f inactive][-e expire]
[-p passwd] [-L|-U] name
举例用户oldname改名为newname,注意要同时更改家目录:
usermod –d /home/newname –m –l newname oldname
删除用户
deluser
语法: deluser
使用方法:
deluser --remove-home user1
删除用户user1的同时删除用户的工作目录
添加用户组
addgroup
语法: addgroup groupname
使用方法:
addgroup groupname
删除用户组
delgroup
语法: delgroup groupname
使用方法:
delgroup groupname1
总结与思考
本节课主要介绍了linux系统中用户管理相关的重要配置文件以及用户管理相关的命令。
思考
用户相关的文件有哪些?
简述添加用户的过程。
2.3进程管理的相关命令
进程的概念
程序的一次执行就是一个进程
使用命令查看进程
ps 命令
显示进程 (process) 的动态
语法:
ps [options]
ps命令基本选项及参数释义
a:显示现行终端机下的所有程序,包括其他用户的程序。
c:列出程序时,显示每个程序真正的指令名称,而不包含路径,选项或常驻服务的标示。
e:列出程序时,显示每个程序所使用的环境变量。
f:用ASCII字符显示树状结构,表达程序间的相互关系。
g:显示现行终端机下的所有程序,包括群组领导者的程序。
h:不显示标题列。
u:以用户为主的格式来显示程序状况。
x:显示所有程序,不以终端机来区分。
r:只列出现行终端机正在执行中的程序。
v:采用虚拟内存的格式显示程序状况
-a:显示所有终端机下执行的程序,除了阶段作业领导者之外。
-c:显示CLS和PRI栏位。
-d:显示所有程序,但不包括阶段作业领导者的程序。
-e:显示所有程序。
-f:显示UID,PPIP,C与STIME栏位。
-H:显示树状结构,表示程序间的相互关系。
-u<用户识别码>:列出属于该用户的程序的状况,也可使用用户名称来指定。
-j:采用工作控制的格式显示程序状况
-l或l:采用详细的格式来显示程序状况。
常见的用法:
ps -elf 普通使用的标准
ps -aux BSD 使用的标准

进程的状态标志
D: 不可中断的静止
R: 正在执行中
S: 阻塞状态
T: 暂停执行
Z: 不存在但暂时无法消除
<: 高优先级的进程
N: 低优先级的进程
L: 有内存分页分配并锁在内存中
top命令
监视进程
通常会全屏显示,而且会随着进程状态的变化不断更新
整个系统的信息也会显示,为查找问题提供了便利
可以显示系统总共有多少CPU和内存资源以及负载平衡等信息。
top 实时检测进程 q退出

pstree命令
将所有行程以树状图显示, 树状图将会以 pid (如果有指定) 或是以init这个基本进程为根,如果有指定使用者id, 则树状图会只显示该使用者所拥有的进程。
参数:
-a 显示该进程的完整指令及参数, 如果是被记忆体置换出去的进程则会加上括号
-c 如果有重覆的进程名, 则分开列出
cd /proc/ 常用查看进程信息命令
终止进程
使用kill命令终止进程
kill [-signal] PID
signal是信号,PID是进程号
kill 命令向指定的进程发出一个信号signal,在默认情况下,kill 命令向指定进程发出信号15,正常情下,将杀死那些不捕捉或不忽略这个信号的进程
kill -l 查看信号含义
2.4文件系统的类型和结构
文件系统的类型
Linux文件系统
在任何一个操作系统中,文件系统无疑是其最重要的组件,用于组织和管理计算机存储设备上的大量文件,并提供用户交互接口。Linux同样具备完善的文件系统。用户既可以使用界面友好的Nautilus图形文件管理器,也可以使用功能强大的shell文件系统管理工具。
文件系统类型
linux是一种兼容性很高的操作系统,支持的文件系统格式很多,大体可分以下几类:
磁盘文件系统:指本地主机中实际可以访问到的文件系统,包括硬盘、CD-ROM、DVD、USB存储器、磁盘阵列等。常见文件系统格式有:autofs、coda、Ext(Extended File sytem,扩展文件系统)、Ext3、Ext4、VFAT、ISO9660(通常是CD-ROM)、UFS(Unix File System,Unix文件系统)、FAT、FAT16、FAT32、NTFS等;
网络文件系统:是可以远程访问的文件系统,这种文件系统在服务器端仍是本地的磁盘文件系统,客户机通过网络远程访问数据。常见文件系统格式有:NFS、Samba等;
专有/虚拟文件系统:不驻留在磁盘上的文件系统。常见格式有:TMPFS(临时文件系统)、PROCFS(Process File System,进程文件系统)和LOOPBACKFS(Loopback File System,回送文件系统)。
目前Ext4是Linux系统广泛使用的一种文件格式。在Ext3基础上,对有效性保护、数据完整性、数据访问速度、向下兼容性等方面做了改进。
最大特点是日志文件系统:可将整个磁盘的写入动作完整地记录在磁盘的某个区域上,以便在必要时回溯追踪。
查看文件系统的命令
mount\df\file\parted 



SCSI与IDE设备命名
sata硬盘的设备名称是“/dev/sda”
/dev/sda1 含义?
/dev/sdb3 含义?
IDE硬盘的设备名称是“/dev/hda”
/dev/hdc2 含义?
如果很在意系统的高性能和稳定性,应该使用SCSI硬盘
cat /proc/partitions
Linux分区的命名方式
字母和数字相结合
前两个字母表示设备类型
“hd”代表IDE硬盘
“sd”表示SCSI或SATA硬盘
第三个字母说明具体的设备
“/dev/hda”表示第一个IDE硬盘
“/dev/hdb”表示第二个IDE硬盘
交换分区
将内存中的内容写入硬盘或从硬盘中读出,称为内存交换(swapping)
交换分区最小必须等于计算机的内存
可以创建多于一个的交换分区
尽量把交换分区放在硬盘驱动器的起始位置
Linux文件系统的结构
文件系统逻辑结构
某所大学的学生可能在一两万人左右,通常将学生分配在以学院-系-班为单位的分层组织机构中。若需要查找一名学生时,最笨的办法是依次问询大学中的每一个学生,直到找到为止。如果按照从学院、到系、再到班的层次查询下去,必然可以找到该学生,且查询效率高。这种树形的分层结构就提供了一种自顶向下的查询方法。
如果把学生看作文件,院-系-班的组织结构看作是Linux文件目录结构,那么就同样可以有效地管理数量庞大的文件。
一直使用微软Windows操作系统的用户似乎已经习惯了将硬盘上的几个分区,并用A:、B:、C:、D:等符号标识。存取文件时一定要清楚存放在哪个磁盘的哪个目录下。
Linux的文件组织模式犹如一颗倒置的树,这与Windows文件系统有很大差别。所有存储设备作为这颗树的一个子目录。存取文件时只需确定目录就可以了,无需考虑物理存储位置。
分区与目录的关系
在Windows下,目录结构属于分区;在Linux下,分区属于目录结构。
如何知道文件存储的具体硬件位置呢?
在Linux中,将所有硬件都视为文件来处理,包括硬盘分区、CD-ROM、软驱以及其他USB移动设备等。为了能够按照统一的方式和方法访问文件资源,Linux中提供了对每种硬件设备相应的设备文件。一旦Linux系统可以访问到硬件,就将其上的文件系统挂载到目录树中的一个子目录中。
例如,用户插入USB移动存储器,Ubuntu Linux自动识别后,将其挂载到“/media/disk”目录下。而不象Windows系统将USB存储器作为新驱动器,表示为“F:”盘。
Linux文件系统就是一个树形的分层组织结构。将根(/)作为整个文件系统的惟一起点,其他所有目录都从该点出发。将Linux的全部文件按照一定的用途归类,合理地挂载到这颗“大树”的“树枝”或“树叶”上,如图所示。而这些全不用考虑文件的实际存储位置,无论是存在硬盘上,还是在CD-ROM或USB存储器中,甚至是网络终端。

基本目录
由于Linux是完全开源的软件,各Linux发行机构都可以按照自己的需求对文件系统进行裁剪,所以如此众多的Linux发行版本的目录结构也不尽相同。为了规范文件目录命名和存放标准,颁发了文件层次结构标准(FHS,File Hierarchy Standard),2004年发行版本FHS 2.3。Ubuntu Linux系统同样也遵循这个标准


绝对路径和相对路径
在认识到Linux文件系统是树形分层的组织结构,且只有一个根节点之后。在Linux文件系统中查找一个文件,只要确定文件名和路径,就可以惟一确定这个文件。例如
“/usr/games/gnect”
绝对路径:指文件在文件系统中的准确位置。通常在本地主机上,以根目录为起点。例如“/usr/games/gnect”就是绝对路径。
相对路径:指相对于用户当前位置的一个文件或目录的位置。例如,用户处在usr目录中时,只需要“games/gnect”就可确定这个文件。
Linux文件系统与Windows文件系统比较

2.5文件系统相关命令
file、ln命令
file命令
在Linux文件系统中,文件扩展名不总是被使用或被一致地使用。如果一个文件没有扩展名,或者文件与其扩展名不符时怎么办呢?file命令功能用于判定一个文件的类型。file命令一般语法格式为:
file [ filename ]
其中filename是文件名。命令的输出将显示该文件是二进制文件、文本文件、目录文件、设备文件,还是Linux中其他类型的文件。

创建链接文件
链接文件:在文件之间创建链接。这种操作实际上是给系统中已有的某个文件指定另外一个可用于访问它的名称。
Linux中有两种类型的链接:
硬链接是利用Linux中为每个文件分配的物理编号——inode建立链接。因此,硬链接不能跨越文件系统。
软链接(符号链接)是利用文件的路径名建立链接。通常建立软链接使用绝对路径而不是相对路径,以最大限度增加可移植性。
需要注意的是,如果是修改硬链接的目标文件名,链接依然有效;如果修改软链接的目标文件名,则链接将断开;对一个已存在的链接文件执行移动或删除操作,有可能导致链接的断开。假如删除目标文件后,重新创建一个同名文件,软链接将恢复,硬链接不再有效,因为文件的inode已经改变。
ln命令
命令可以用于创建文件的链接文件。ln命令一般语法格式为:
ln [ -s ] target link_name
其中,选项“-s”表示为创建软链接。在缺省情况下,创建硬链接。参数target为目标文件,link_name为链接文件名。如果链接文件名已经存在但不是目录,将不做链接。目标文件可以是任何一个文件名,也可以是一个目录。

以上命令为/proc/cpuinfo文件创建了一个软链接文件。使用“ls –l”命令可以查看到新创建的链接文件所指向的目标文件名。
文件的归档和压缩
压缩文件
用户在进行数据备份时,需要把若干文件整合为一个文件以便保存。尽管整合为一个文件进行管理,但文件大小仍然没变。若需要网络传输文件时,就希望将其压缩成较小的文件,以节省在网络传输的时间。因此本节介绍文件的归档与压缩。
文件压缩和归档
归档文件是将一组文件或目录保存在一个文件中。
压缩文件也是将一组文件或目录保存一个文件中,并按照某种存储格式保存在磁盘上,所占磁盘空间比其中所有文件总和要少。
归档文件仍是没有经过压缩的,它所使用的磁盘空间仍等于其所有文件的总和。因而,用户可以将归档文件再进行压缩,使其容量更小。
gzip是Linux中最流行的压缩工具,具有很好的移植性,可在很多不同架构的系统中使用。bzip2在性能上优于gzip,提供了最大限度的压缩比率。如果用户需要经常在Linux和微软Windows间交换文件,建议使用zip。

目前,归档工具使用最广泛的tar命令,可以把很多文件(甚至磁带)合并到一个称为tarfile的文件中,通常文件扩展名为.tar。然后,再使用zip、gzip或bzip2等压缩工具进行压缩。
压缩文件
shell归档和压缩工具
使用shell归档和压缩工具可以更直接地完成文档的打包任务。由于该类shell命令是成对使用的,因此下面按对介绍相关命令。
gzip与gunzip命令
与zip明显区别在于只能压缩一个文件,无法将多个文件压缩为一个文件。gzip命令符号模式的一般语法格式为:
其中,filename表示要压缩的文件名,gzip会自动在这个文件名后添加扩展名为.gz,作为压缩文件的文件名。
![]()

gunzip命令符号模式的一般语法格式为:
![]()
其中,选项“-f”用于解压文件时,对覆盖同名文件不做提示。
在执行gzip命令后,它将删除旧的未压缩的文件并只保留已压缩的版本。以下命令以最大的压缩率对文件file_1进行压缩,生成file_1.gz文件。使用“-l”选项可以查看压缩的相关信息。最后使用gunzip命令对文件进行了解压。与压缩时相反,file_1.gz文件会被删除,继之生成file_1。

tar命令
tar命令主要用于将若干文件或目录合并为一个文件,以便备份和压缩。当然,之后出现tar程序的改进版本,可以实现在合并归档的同时进行压缩。tar命令符号模式的一般语法格式为:

第一,将myExamples/目录下的所有文件全部归档,打包到一个文件中myExamples.tar;
第二,将myExamples/目录下的所有文件全部归档,并使用bzip2压缩成一个文件myExamples.tar.bz;
第三,将myExamples/目录下的所有文件全部归档,并使用gzip压缩成一个文件myExamples.tar.gz。

如果想查看一下归档文件中的详细内容,使用类似以下命令:
![]()
使用以下命令完成tar文件的释放。其中,“tar -xjf”和“tar –xzf”等效与先解压缩后释放tar文件。

Linux 网络配置管理
网络配置基础
用户既可以通过命令行的方式,也可以通过友好的图形界面,轻松完成网络配置。
实现Linux网络配置的惟一目标就是修改系统中众多的网络配置文件,如/etc/interfaces、/etc/hosts,/etc/resolv.conf 等等。
通常,用户可能使用普通以太网卡、无线网卡、调制解调器等不同类型的设备接入网络。不同类型的网络设备在主机中被映射为相应的网络接口,比如以太网卡映射为eth,无线网卡映射为wlan。有时,用户还可能同时使用多个网络设备,就会出现eth0、eth1…,或wlan0、wlan1…的情况。
那么,如何标识每个连接到Internet的网络接口呢?
解决办法是:为每个网络接口分配一个全世界范围内惟一的32bit的标识符。这个标识符就是IP(Internet Protocol)地址。
配置IP地址
IP地址
IP地址包括三部分:Internet网络号(Net-ID)、子网号(Subnet-ID)和主机号(Host-ID)。

因而可以这样解释:一个IP地址惟一标识了,处在某个互联网中的,某个子网的,某个网络接口。
根据Internet网络号的字段长度(1,2,3字节长),IP地址区分为A类、B类、C类。三类IP地址的掩码如下所示。
A类地址的默认子网掩码是255.0.0.0,或0xFF000000;
B类地址的默认子网掩码是255.255.0.0,或0xFFFF0000;
C类地址的默认子网掩码是255.255.255.0,或0xFFFFFF00;
IP网络中通常用最小的IP地址标识网络本身,将最大的IP地址作为该网络的广播地址,其余所有IP地址都分配给网络中的主机。然而,局域网中的主机并不能直接访问Internet,需要通过一个作为代理的网关或网络地址转换服务(NAT)才能访问Internet。通常将IP地址的第一个或最后一个留给该网络的Internet网关。
配置IP地址
接入网络的计算机主机依靠IP地址,惟一地标识其在网络中的身份,因此为主机配置IP地址是接入网络的关键。配置IP地址的方法有两种:
配置静态IP:在主机进入网络之前,事先为主机设置固定 的IP地址;
配置动态IP:选择DHCP(动态主机配置协议(Dynamic host configuration protocol))网络服务,在主机进入网络之后,动态随机获取IP地址。
网络相关命令
ifconfig命令
ifconfig是GNU/Linux中配置网卡的基本命令,包含在net-tools软件包中。它可用于显示或设置网卡的配置,如IP地址、子网掩码、最大分组传输数、IO端口等,还可以启动或禁用网卡。ifconfig命令有以下两种格式:

ifconfig的第一种格式用于查看当前系统的网络配置情况;第二种格式用于配置网卡,包括添加、删除网卡,以及绑定多个IP地址等。
从下面的运行结果可以看出,主机有两个接口eth0、lo。lo代表主机本身,也称回送接口(Loopback),其IP地址约定为127.0.0.1。

如果主机安装了第二块、第三块网卡,则有eth1,eth2标识。常见的接口类型还有以下几种(N表示接口号):
pppN表示调制解调设备
wlanN表示无线网卡
trN表示令牌环网卡
如果只是关心某个网络设备,可以在ifconfig后面加上接口名称,则只显示该设备的相关信息,例如:
![]()
假设主机现有的IP地址为192.168.182.129,需要为其重新分配IP地址192.168.182.128,即。使用ipconfig命令设置主机的第一块网卡(eth0)的IP地址。

配置动态IP地址
在大型网络中,由于存在许多的移动计算机系统,随时都可能进入网络,在每次更换网络时,就不得不重新配置网络信息。如果计算机在网络里能够自动获取IP地址、子网掩码、路由表、DNS服务器地址等网络信息,具有动态配置IP的能力,就可以大大简化客户端的网络配置难度。动态主机配置协议(DHCP,Dynamic Host Configuration Protocol)可以实现动态分配IP资源。
只要在局域网中架设有DHCP服务器,在Ubuntu Linux中为主机配置DHCP客户端是非常容易的。需要说明的是,通常普通以太网卡和无线网卡可以配置动态IP,而调制解调器等网络设备不能配置动态IP。


动态IP的获取过程
可比作一个“租赁”过程。DHCP服务器好比是IP地址的出租方,用户主机(即DHCP客户端)好比是IP地址的临时租用者。
如果将用户主机设置为DHCP客户端之后,手动启动网络服务,就可以从执行结果中看出获取动态IP的过程。

执行过程中包括以下四个阶段。
客户端寻找DHCP服务器(DHCPDISCOVER):客户端广播申请动态IP的请求;
服务器提供可分配的IP地址(DHCPOFFER):所有接收到请求的DHCP服务器都将向客户端提供一个IP地址;
客户端接受IP地址租借(DHCPREQUEST):客户端从多个IP选择中挑选一个,通知DHCP服务器,并标识出所选中的服务器;
服务器确认租借IP(DHCPACK):被选中的DHCP服务器最后发出一个确认信息,包含IP地址、子网掩码、默认网关、DNS服务器和租借期(客户端使用这个IP的这段时间,称为租借期)。
最终客户端临时“租借”的IP地址为192.168.182.129。

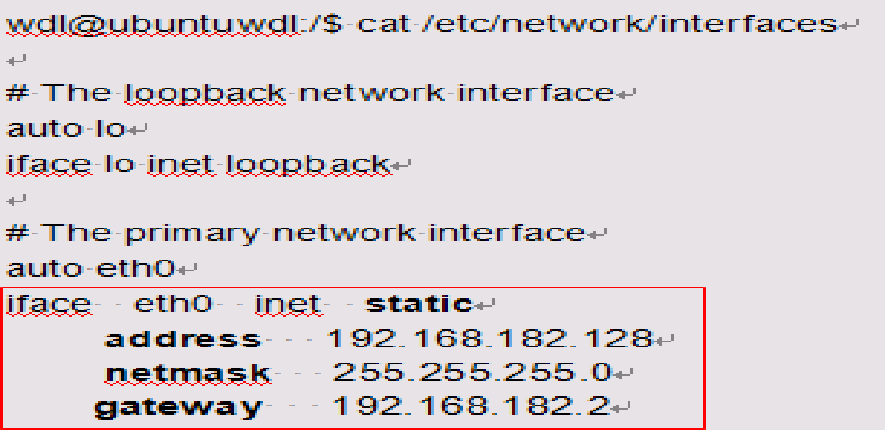
IP地址存放在哪里——interfaces配置文件
无论是配置静态IP还是动态IP,计算机系统将IP信息保存放在什么地方?答案是配置文件“/etc/network/interfaces”。在Ubuntu Linux启动时就能获得IP地址的配置信息。若是配置静态IP,就从配置文件中读取IP地址参数,直接配置网络接口设备;若是配置动态IP,就通知主机通过DHCP协议获取网络配置。
以下分别为配置静态IP和动态IP时,配置文件“/etc/network/interfaces”的实例。

DNS客户端配置文件—resolv.conf
Ubuntu Linux将DNS服务器地址保存在配置文件/etc/resolv.conf中。
依然延续上面的例子,添加DNS服务器IP地址后,查看配置文件/etc/hosts,如下所示。

ping命令
ping(Packet Internet Groper)命令可能是最有名气的网络连接检测工具。它使用了Internet控制报文协议(ICMP)回送请求与回送应答报文,测试两个主机之间的连通性。该命令的一般格式如下所示。
ping命令测试的远程主机,既可用域名,也可用IP地址标识。
![]()
可以使用该命令来判断主机与远程主机是否可达,或之间的网络是否拥塞。min/avg/max/mdev是ping命令的完成测试后的统计结果,分别表示最小响应时间/平均响应时间/最大响应时间/响应时间方差。这些指标用于反应网络的联通程度。
可以使用该命令来判断主机与远程主机是否可达,或之间的网络是否拥塞。min/avg/max/mdev是ping命令的完成测试后的统计结果,分别表示最小响应时间/平均响应时间/最大响应时间/响应时间方差。这些指标用于反应网络的联通程度。

ping命令执行时,会持续不断地向目的主机发送ICMP包。在得到对方的应答后,显示每次连接的统计数据,直到用Ctrl+C组合键中断执行。但是,目前很多主机通过设置防火墙,对ping命令不予应答。在这种情况下,ping命令由于不停地发送测试数据包,又得不到返回任何结果,而致使ping命令僵死。不过,使用-c参数设置发送测试数据包的次数,以便在有限时间内完成测试。
管理DNS服务器地址
DNS域名解析可以在更大范围的计算机网络、Internet,提供域名到IP地址的转换。网络中的每台计算机都是一个DNS客户端,向DNS服务器提交域名解析的请求;DNS服务器完成域名到IP地址的映射。
因此DNS客户端至少有一个DNS服务器地址,作为命名解析的开端。
nslookup命令
使用nslookup命令可以查看当前系统所使用的DNS服务器的IP地址。

服务器192.168.182.2完成了域名解析。Server表示提供服务的DNS服务器,Address中的#53表示TCP/UDP命名服务的端口号。若所有的DNS服务器都访问失败,则出现如下的执行结果。

D3 Linux shell 脚本编程
3.1 shell 脚本 变量
shell脚本的基础知识
shell脚本的本质
编译型语言
解释型语言
shell脚本语言是解释型语言 #!/bin/bash (指定shell 类型 )
shell脚本的本质: shell命令的有序集合
编程过程
基本过程分为三步:
step1. 建立 shell 文件
包含任意多行操作系统命令或shell命令的文本文件;
step2. 赋予shell文件执行权限
用chmod命令修改权限;
r--read 读权限 4 w--write 写权限 2 x--execute 执行权限 1
step3. 执行shell文件
直接在命令行上调用shell程序.
编程过程演示

shell变量
shell允许用户建立变量存储数据,但不支持数据类型(整型、字符、浮点型),将任何赋给变量的值都解释为一串字符
Variable=value
count=1
echo $count
DATE=date
echo $DATE
执行 ./filename.sh or bash filename.sh
Bourne Shell有如下四种变量:
用户自定义变量
位置变量即命令行参数
预定义变量
环境变量
用户自定义变量
在shell编程中通常使用全大写变量,方便识别
$ COUNT=1
变量的调用:在变量前加$
$ echo $HOME
Linux Shell/bash从右向左赋值,赋值时 ‘=’ 前后不能加空格
$Y=y
$ X=$Y
$ echo $X
y
使用unset命令删除变量的赋值
$ Z=hello
$ echo $Z
hello
$ unset Z
$ echo $Z
命令置换`` 符号不要搞错,命令置换使用的命令必须有输出
位置变量
$0 与键入的命令行一样,包含脚本文件名
$1,$2,……$9 分别包含第一个到第九个命令行参数
$# 包含命令行参数的个数
$@ 包含所有命令行参数:“$1,$2,……$9”
$? 包含前一个命令的退出状态
$* 包含所有命令行参数:“$1,$2,……$9”
$$ 包含正在执行进程的ID号
传10 个及以上参数,取参 10 {10} 10{11}${12}…
特殊符号记得加’'转义
环境变量
HOME: /etc/passwd文件中列出的用户主目录
IFS:Internal Field Separator, 默认为空格,tab及换行符
PATH :shell搜索路径
PS1,PS2:默认提示符($)及换行提示符(>)
TERM:终端类型,常用的有vt100,ansi,vt200,xterm等
shell 脚本-功能语句
shell 程序由零或多条shell语句构成。 shell语句包括三类:说明性语句、功能性语句和结构性语句。
说明性语句:
以#号开始到该行结束,不被解释执行
功能性语句:
任意的shell命令、用户程序或其它shell程序。
结构性语句:
条件测试语句、多路分支语句、循环语句、循环控制语句等。
说明性语句
说明性语句(注释行)
注释行可以出现在程序中的任何位置,既可以单独占用一行, 也可以接在执行语句的后面. 以#号开始到所在行的行尾部分,都不被解释执行. 例如:

常用功能性语句
常用功能性语句(命令)
read从标准输入读入一行, 并赋值给后面的变量,其语法为:
read var
把读入的数据全部赋给var
read var1 var2 var3
把读入行中的第一个单词(word)赋给var1, 第二个单词赋给var2, ……把其余所有的词赋给最后一个变量.
如果执行read语句时标准输入无数据, 则程序在此停留等侯, 直到数据的到来或被终止运行。
read -p “输入提示”
echo -n 代表不会在最后自动换行
echo -e 当指定-e选项时,则将解释反斜杠转义字符
应用实例
# example1 for read
echo "Input your name: \c"
read username
echo "Your name is $username“
#example2 for read
echo "Input date with format yyyy mm dd: \c"
read year month day
echo "Today is $year/$month/$day, right?"
echo "Press enter to confirm and continue\c"
read answer
echo "I know the date, bye!"
算数运算 expr 命令

expr后边必须加空格 运算符(+-*/?) 前后必须加空格
test语句
test语句可测试三种对象:
字符串 整数 文件属性
每种测试对象都有若干测试操作符
例如:
test “$answer” = “yes”
变量answer的值是否为字符串yes
test $num –eq 18
变量num的值是否为整数18
test -d tmp
测试tmp是否为一个目录名
字符串测试
s1 = s2 测试两个字符串的内容是否完全一样,是返回0
s1 != s2 测试两个字符串的内容是否有差异,是返回0
-z s1 测试s1 字符串的长度是否为0,是返回0
-n s1 测试s1 字符串的长度是否不为0,是返回0
整数测试
举例子
1 #!/bin/bash
2 test 3 -eq 3
3 echo KaTeX parse error: Expected 'EOF', got '#' at position 4: ? #̲`? `包含前一个命令的退出状态
a -eq b 测试a 与b 是否相等
a -ne b 测试a 与b 是否不相等
a -gt b 测试a 是否大于b
a -ge b 测试a 是否大于等于b
a -lt b 测试a 是否小于b
a -le b 测试a 是否小于等于b
文件测试
举例子:
#!/bin/bash
test -f read.sh
echo $?
-d name 测试name 是否为一个目录
-e name 测试一个文件是否存在
-f name 测试name 是否为普通文件
-L name 测试name 是否为符号链接
-r name 测试name 文件是否存在且为可读
-w name 测试name 文件是否存在且为可写
-x name 测试name 文件是否存在且为可执行
-s name 测试name 文件是否存在且其长度不为0
f1-nt f2 测试文件f1 是否比文件f2 更新
f1-ot f2 测试文件f1 是否比文件f2 更旧
测试语句记得把test 写前边去
3.2 shell 脚本-结构性语句
结构性语句主要根据程序的运行状态、输入数据、变量的取值、控制信号以及运行时间等因素来控制程序的运行流程。
主要包括:条件测试语句(两路分支)、多路分支语句、循环语句、循环控制语句和后台执行语句等。
if 条件 then 处理逻辑 fi
条件语句
条件语句1
if…then…fi
语法结构:
if 表达式
then 命令表
fi
如果表达式为真, 则执行命令表中的命令; 否则退出if语句, 即执行fi后面的语句。
if和fi是条件语句的语句括号, 必须成对使用;
命令表中的命令可以是一条, 也可以是若干条。
实例
shell程序prog2.sh(测试命令行参数是否为已存在的文件或目录)。用法为:
./prog2.sh file
代码如下:
#The statement of if…then…fi (注释语句)
if [ -f $1 ] (测试参数是否为文件)
then
echo "File $1 exists" (引用变量值)
fi
if [ -d $HOME/$1 ] (测试参数是否为目录)
then
echo "File $1 is a directory" (引用变量值)
fi
执行prog2程序:
$ ./prog2.sh prog1.sh
File prog1.sh exists
$0为prog2.sh; $1为prog1.sh, 是一个已存在的文件.
$ ./prog2.sh backup
File backup is a directory
$0为prog2.sh; $1为backup,是一个已存在的目录.
如果不带参数, 或大于一个参数运行prog2, 例如:
$ ./prog2.sh (或 $ ./prog2.sh file1 file2)
会出现什么结果?
条件语句2
if…then…else…fi
语法结构为:
if 表达式
then 命令表1
else 命令表2
fi
如果表达式为真, 则执行命令表1中的命令, 再退出if语句; 否则执行命令表2中的语句, 再退出if语句.
注意: 无论表达式是否为真, 都有语句要执行.
实例
test命令的使用
test命令测试的条件成立时, 命令返回值为真(0),否则返回值为假(非0).
方式一:
test $name -eq $1
echo $?
方式二:
if test -f $filename
then
……
fi
方式三:
if [ -f $filename ]
then
……
fi
用方括号替代test语句,注意方括号前后至少有一个空格

实例
例子: shell程序prog3.sh, 用法为:
./prog3.sh file
内容如下:
#The statement of if…then…else…fi
if [ -d $1 ]
then
echo "$1 is a directory"
exit #(退出当前的shell程序)
else
if [ -f $1 ]
then
echo "$1 is a common file"
else
echo "unknown"
fi
fi
运行prog3.sh程序:
$ ./prog3.sh backup
backup is a directory
$ ./prog3.sh prog1
prog1 is a common file
$ ./prog3.sh abc
unknown
prog3.sh是对prog2.sh的优化, 逻辑结构更加清晰合理!
shell 布尔运算符

多路分支语句
case…esac

实例
实例. 程序prog4.sh检查用户输入的文件名, 用法为:
./prog4.sh string_name
# The statement of case…esac
if [ $# -eq 0 ]
then
echo "No argument is declared"
exit
fi
case $1 in
file1)
echo "User selects file1"
;;
file2)
echo "User selects file2"
;;
*)
echo "You must select either file1 or file2!"
;;
esac
循环语句
循环语句for的用法
当循环次数已知或确定时,使用for循环语句来多次执行一条或一组命令。 循环体由语句括号do和done来限定。格式为:
for 变量名 in 单词表
do
命令表
done
变量依次取单词表中的各个单词, 每取一次单词, 就执行一次循环体中的命令. 循环次数由单词表中的单词数确定. 命令表中的命令可以是一条, 也可以是由分号或换行符分开的多条。
如果单词表是命令行上的所有位置参数时, 可以在for语句中省略 “in 单词表” 部分。
实例
实例:程序prog5.sh拷贝当前目录下的所有文件到backup子目录下. 使用语法为: ./prog5.sh [filename]

#! /bin/bash
# for (( i=1; $i <=10 ; i=$i + 1 ))
# do
# echo "+++ i = $i"
# sleep 1;
# done
for I in 1 3 5 7 9
do
echo "$I"
done
#for (( ; ; )) #死循环
#do
# echo "+++"
# echo "---"
#done
while循环
语法结构为:
while 命令或表达式
do
命令表
done
while语句首先测试其后的命令或表达式的值,如果为真,就执行一次循环体中的命令,然后再测试该命令或表达式的值,执行循环体,直到该命令或表达式为假时退出循环。
while语句的退出状态为命令表中被执行的最后一条命令的退出状态。
实例
创建文件程序prog6, 批量生成空白文件,用法为:
prog6 file [number] ./a.sh file 6

循环控制语句
break 和 continue
break n 则跳出n层;
continue语句则马上转到最近一层循环语句的下一轮循环上,
continue n则转到最近n层循环语句的下一轮循环上.
实例. 程序prog7的用法为:
prog7 整数 整数 整数 …
参数个数不确定, 范围为1~10个, 每个参数都是正整数。

3.3 shell 脚本-函数
shell函数调用

实例
check_user( ) { #查找已登录的指定用户
user=`who | grep $1 | wc -l`
if [ $user –eq 0 ]
then
return 0 #未找到指定用户
else
return 1 #找到指定用户
fi
}
while true # MAIN, Main, main: program begin here
do
echo "Input username: \c"
read uname
check_user $uname # 调用函数, 并传递参数uname
if [ $? –eq 1 ] # $?为函数返回值
then echo "user $uname online"
else echo "user $uname offline"
fi
done
函数变量作用域
全局作用域:在脚本的其他任何地方都能够访问该变量。
局部作用域:只能在声明变量的作用域内访问。
声明局部变量的格式:
Local variable_name =value
#!/bin/bash
Scope()
{
local lclvariable=1
Gblvariable=2
echo "lclavariable in function = $lclvariable"
echo "Gblvariable in function = $Gblvariable"
}
Scope
echo "lclavariable in function = $lclvariable"
echo "Gblvariable in function = $Gblvariable"
结果

$(1-9)放函数内部,表示函数参数,不再是名令行参数
注意方法内的变量默认是全局的,局部变量需要加local 修饰。
D4 Linux C高级语言编程
4.1 gcc 编译器和gdb
gcc 编译器
GNU工具
编译工具:把一个源程序编译为一个可执行程序
调试工具:能对执行程序进行源码或汇编级调试
软件工程工具:用于协助多人开发或大型软件项目的管理,如make、CVS、Subvision
其他工具:用于把多个目标文件链接成可执行文件的链接器,或者用作格式转换的工具。
部分相关资源
http://www.gnu.org/
http://gcc.gnu.org/
http://www.kernel.org/
http://www.linux.org/
http://www.linuxdevices.com/
http://sourceforge.net/index.php
GCC简介
全称为GNU CC ,GNU项目中符合ANSI C标准的编译系统
编译如C、C++、Object C、Java、Fortran、Pascal、Modula-3和Ada等多种语言
GCC是可以在多种硬体平台上编译出可执行程序的超级编译器,其执行效率与一般的编译器相比平均效率要高20%~30%
一个交叉平台编译器 ,适合在嵌入式1领域的开发编译
GCC编译器的版本
GNU Compiler Collection
C, C++, Objective-C, Fortran, Java, Ada
http://gcc.gnu.org

gcc所支持后缀名解释
.c C原始程序
.C/.cc/.cxx C++原始程序
.h 预处理文件(头文件)
.i 已经过预处理的C原始程序
.ii 已经过预处理的C++原始程序
.s/.S 汇编语言原始程序
.o 目标文件
.a/.so 编译后的库文件
编译器的主要组件
分析器:分析器将源语言程序代码转换为汇编语言。因为要从一种格式转换为另一种格式(C到汇编),所以分析器需要知道目标机器的汇编语言。
汇编器:汇编器将汇编语言代码转换为CPU可以执行字节码。
链接器:链接器将汇编器生成的单独的目标文件组合成可执行的应用程序。链接器需要知道这种目标格式以便工作。
标准C库:核心的C函数都有一个主要的C库来提供。如果在应用程序中用到了C库中的函数,这个库就会通过链接器和源代码连接来生成最终的可执行程序
GCC的基本用法和选项
Gcc最基本的用法是∶gcc [options] [filenames]
-c,只编译,不连接成为可执行文件,编译器只是由输入的.c等源代码文件生成.o为后缀的目标文件,通常用于编译不包含主程序的子程序文件。
-o output_filename,确定输出文件的名称为output_filename,同时这个名称不能和源文件同名。如果不给出这个选项,gcc就给出预设的可执行文件a.out。
-g,产生符号调试工具(GNU的gdb)所必要的符号资讯,要想对源代码进行调试,我们就必须加入这个选项。
-O,对程序进行优化编译、连接,采用这个选项,整个源代码会在编译、连接过程中进行优化处理,这样产生的可执行文件的执行效率可以提高,但是,编译、连接的速度就相应地要慢一些。
-O2,比-O更好的优化编译、连接,当然整个编译、连接过程会更慢。
-I dirname,将dirname所指出的目录加入到程序头文件目录列表中,是在预编译过程中使用的参数。
-L dirname,将dirname所指出的目录加入到程序函数档案库文件的目录列表中,是在链接过程中使用的参数。
GCC 全称为GNU CC ,GNU项目中符合ANSI C标准的编译系统,编译如C、C++、Object C、Java、Fortran、Pascal、Modula-3和Ada等多种语言
GCC的错误类型及对策
第一类∶C语法错误
错误信息∶文件source.c中第n行有语法错误(syntex errror)。有些情况下,一个很简单的语法错误,gcc会给出一大堆错误,我们最主要的是要保持清醒的头脑,不要被其吓倒,必要的时候再参考一下C语言的基本教材。
第二类∶头文件错误
错误信息∶找不到头文件head.h(Can not find include file head.h)。这类错误是源代码文件中的包含头文件有问题,可能的原因有头文件名错误、指定的头文件所在目录名错误等,也可能是错误地使用了双引号和尖括号。
第三类∶档案库错误
错误信息∶链接程序找不到所需的函数库(ld: -lm: No such file or directory )。这类错误是与目标文件相连接的函数库有错误,可能的原因是函数库名错误、指定的函数库所在目录名称错误等,检查的方法是使用find命令在可能的目录中寻找相应的函数库名,确定档案库及目录的名称并修改程序中及编译选项中的名称。
第四类∶未定义符号
错误信息∶有未定义的符号(Undefined symbol)。
这类错误是在链接过程中出现的,可能有两种原因∶一是使用者自己定义的函数或者全局变量所在源代码文件,没有被编译、连接,或者干脆还没有定义;二是未定义的符号是一个标准的库函数,在源程序中使用了该库函数,而连接过程中还没有给定相应的函数库的名称,或者是该档案库的目录名称有问题,这时需要使用档案库维护命令ar检查我们需要的库函数到底位于哪一个函数库中,确定之后,修改gcc连接选项中的-l和-L项。
GCC使用实例
#include编译:gcc -0 test test.c
执行: ./test
查看更详细的信息:gcc -v -o test.c
GCC编译过程
GCC的编译流程分为四个步骤:
预处理(Pre-Processing)
编译(Compiling)
汇编(Assembling)
链接(Linking)

“hello”的演变历程

生成预处理代码
gcc -E test.c -o tset.i
用wc 命令,查看两个阶段代码大小 wc test.c test

test.i比test.c增加了很多内容,主要是放在系统提供的include文件中的。
生成汇编代码
检查语法错误,并生成汇编文件
gcc -S test.i -o test.s
生成目标代码
方法一,直接从C源代码中生成目标代码 gcc -c test.c -o test.o
方法二,用汇编器从汇编代码生成目标代码 as test.s -o test.o
生成可执行程序
将目标程序链接库资源,生成可执行程序
gcc test.o -o test
./test
GDB调试工具
GDB(GNU symbolic debugger,GNU符号调试器)
调试器–Gdb调试流程
首先使用gcc对test.c进行编译,注意一定要加上选项‘-g’

流程
查看文件 l
查看变量值p n
设置断点 b 6
单步运行 n | s
查看断点情况 info b
恢复程序运行 c
运行代码 r
帮助 help
gdb中跳入函数的命令是step,相当于Visual Studio中的快捷键F11
gdb中跳出函数的命令是finish,相当于Visual Studio中的快捷键Shift+F11,函数完整执行后返回
gdb中还有一个直接返回的命令是return,它会跳过当前函数后面的语句直接返回,返回值可以自定义,紧跟在return命令后面即可
————————————————
版权声明:本文为CSDN博主「AlbertS」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/albertsh/article/details/102855983
Gdb的使用切记点
编译必须加入-g
只有在代码处于运行或暂停状态时才能查看变量值
设置断点后程序在指定行之前停止
gdb filename 进入调试模式
4.2 C语言高级编程-条件编译和结构体
条件编译
编译器根据条件的真假决定是否编译相关的代码
一、根据宏是否定义,其语法如下:
#ifdef
……
#else
……
#endif
#define _DEBUG_
#ifdef _DEBUG_
printf(“The macro _DEBUG_ is defined\n”);
#else
printf(“The macro _DEBUG_ is not defined\n”);
#endif
注意:#ifdef 可以写成 #ifndef 则功能相反
二、根据宏的值,其语法如下
#if
……
#else
……
#endif
#define _DEBUG_ 1
#if _DEBUG_
printf(“The macro _DEBUG_ is defined\n”);
#else
printf(“The macro _DEBUG_ is not defined\n”);
#endif
三、gcc 时宏的定义
在gcc中, 可在命令行中指定对象宏的定义:
e.g.
$ gcc -Wall -DMAX=100 -o tmp tmp.c
相当于在tmp.c中添加" #define MAX 100".
那么, 如果原先tmp.c中含有MAX宏的定义, 那么再在gcc调用命令中使用-DMAX, 会出现什么情况呢?
—若-DMAX=1, 则正确编译.
—若-DMAX的值被指定为不为1的值, 那么gcc会给出MAX宏被重定义的警告, MAX的值仍为1.
注意: 若在调用gcc的命令行中不显示地给出对象宏的值, 那么gcc赋予该宏默认值(1), 如: -DVAL == -DVAL=1
D5 Makefile
5.1 Make介绍
Make简介
工程管理器,顾名思义,是指管理较多的文件
Make工程管理器也就是个“自动编译管理器”,这里的“自动”是指它能够根据文件时间戳自动发现更新过的文件而减少编译的工作量,同时,它通过读入Makefile文件的内容来执行大量的编译工作
Make将只编译改动的代码文件,而不用完全编译。
Makefile基本结构
Makefile是Make读入的唯一配置文件
由make工具创建的目标体(target),通常是目标文件或可执行文件
要创建的目标体所依赖的文件(dependency_file)
创建每个目标体时需要运行的命令(command)
注意:命令行前面必须是一个”TAB键”,否则编译错误为:*** missing separator. Stop.
Makefile格式
target : dependency_files
command
例子
hello.o : hello.c hello.h
gcc –c hello.c –o hello.o
一个复杂一些的例子
sunq:kang.o yul.o
gcc kang.o yul.o -o sunq
kang.o : kang.c kang.h
gcc –Wall –O -g –c kang.c -o kang.o
yul.o : yul.c
gcc - Wall –O -g –c yul.c -o yul.o
注释:-Wall:表示允许发出gcc所有有用的报警信息.
-c:只是编译不链接,生成目标文件”.o”
-o file:表示把输出文件输出到file里
Makefile 注释符
# 字符是注释符
makefile 把 # 字符后面的内容作为注释内容处理(shell、perl 脚本也是使用 # 字符作为注释符)。
如果某行的第一个非空字符为 #,则此行会被 make 解释为注释行(命令行除外,如果 Tab 字符之后使用 # 字符,则会被 make 解释为命令行。
注释行的结尾如果存在反斜线(\),那么下一行也被作为注释行。
Makefile变量
创建和使用变量
创建变量的目的:用来代替一个文本字符串:
1. 系列文件的名字
2. 传递给编译器的参数
3. 需要运行的程序
4. 需要查找源代码的目录
5. 你需要输出信息的目录
6. 你想做的其它事情。
变量定义的两种方式
递归展开方式VAR=var
简单方式 VAR := var
变量使用 $(VAR)
用” ”则用” ”则用” ”则用”$”来表示
类似于编程语言中的宏
刚才的例子
OBJS = kang.o yul.o
CC = gcc
CFLAGS = -Wall -O -g
sunq : $(OBJS)
$(CC) $(OBJS) -o sunq
kang.o : kang.c kang.h
$(CC) $(CFLAGS) -c kang.c -o kang.o
yul.o : yul.c yul.h
$(CC) $(CFLAGS) -c yul.c -o yul.o
递归展开方式VAR=var
例子:
foo = $(bar)
bar = $(ugh)
ugh = Huh?
$(foo)的值为?
echo $(foo)来进行查看
优点:
它可以向后引用变量
缺点:
不能对该变量进行任何扩展,例如
CFLAGS = $(CFLAGS) -O
会造成死循环
简单方式:VAR:=var
m := mm
x := $(m)
y := $(x) bar
x := later
all:
echo $(x) $(y)
linux@linux:~/file/tmp$ make
echo later mm bar
later mm bar
用这种方式定义的变量,会在变量的定义点,按照被引用的变量的当前值进行展开
这种定义变量的方式更适合在大的编程项目中使用,因为它更像我们一般的编程语言
用?=定义变量
dir := /foo/bar
FOO ?= bar
FOO是?
含义是,如果FOO没有被定义过,那么变量FOO的值就是“bar”,如果FOO先前被定义过,那么这条语将什么也不做,其等价于:
ifeq ($(origin FOO), undefined)
FOO = bar
endif
为变量添加值
你可以通过+=为已定义的变量添加新的值
Main=hello.o hello-1.o
Main+=hello-2.o
特殊变量
预定义变量
AR 库文件维护程序的名称,默认值为ar。AS汇编程序的名称,默认值为as。
CC C编译器的名称,默认值为cc。CPP C预编译器的名称,默认值为$(CC) –E。
CXX C++编译器的名称,默认值为g++。
FC FORTRAN编译器的名称,默认值为f77
RM 文件删除程序的名称,默认值为rm -f
例子:
Hello: main.c main.h
$(CC) –o hello main.c
clean:
$(RM) hello
其他预定义变量
ARFLAGS 库文件维护程序的选项,无默认值。
ASFLAGS 汇编程序的选项,无默认值。
CFLAGS C编译器的选项,无默认值。
CPPFLAGS C预编译的选项,无默认值。
CXXFLAGS C++编译器的选项,无默认值。
FFLAGS FORTRAN编译器的选项,无默认值。
刚才的例子
OBJS = kang.o yul.o
CC = gcc
CFLAGS = -Wall -O -g
sunq : $(OBJS)
$(CC) $(OBJS) -o sunq
kang.o : kang.c kang.h
$(CC) $(CFLAGS) -c kang.c -o kang.o
yul.o : yul.c yul.h
$(CC) $(CFLAGS) -c yul.c -o yul.o
自动变量
$* 不包含扩展名的目标文件名称
$+ 所有的依赖文件,以空格分开,并以出现的先后为序,可能 包含重复的依赖文件
$< 第一个依赖文件的名称
$? 所有时间戳比目标文件晚的的依赖文件,并以空格分开
$@ 目标文件的完整名称
$^ 所有不重复的目标依赖文件,以空格分开
$% 如果目标是归档成员,则该变量表示目标的归档成员名称
make运行环境变量
make在启动时会自动读取系统当前已经定义了的环境变量,并且会创建与之具有相同名称和数值的变量
如果用户在Makefile中定义了相同名称的变量,那么用户自定义变量将会覆盖同名的环境变量
直接运行make
选项
-C dir读入指定目录下的Makefile
-f file读入当前目录下的file文件作为Makefile
-I 忽略所有的命令执行错误
-I dir指定被包含的Makefile所在目录
-n 只打印要执行的命令,但不执行这些命令
-p 显示make变量数据库和隐含规则
-s 在执行命令时不显示命令
-w 如果make在执行过程中改变目录,打印当前目录名
Makefile的隐含规则
隐含规则1:编译C程序的隐含规则
“.o”的目标的依赖目标会自动推导为“.c”,并且其生成命令是“$(CC) –c $(CPPFLAGS) $(CFLAGS)”
隐含规则2:链接Object文件的隐含规则
“
x : x.o y.o z.o
并且“x.c”、“y.c”和“z.c”都存在时,隐含规则将执行如下命令:
cc -c x.c -o x.o
cc -c y.c -o y.o
cc -c z.c -o z.o
cc x.o y.o z.o -o x
如果没有一个源文件(如上例中的x.c)和你的目标名字(如上例中的x)相关联,那么,你最好写出自己的生成规则,不然,隐含规则会报错的。
举例说明
源文件:

Makefile1
OBJS=f1.o f2.o
OBJS+=main.o
CC=gcc
CLFAGS=-Wall -O -g
test:$(OBJS)
gcc $(CLFAGS) $(OBJS) -o test #根据隐含规则2 可省略
f2.o:f2.c #根据隐含规则1 可省略,包括后边命令
gcc -c $^ -o f2.o
f1.o:f1.c #根据隐含规则1 可省略,包括后边命令
gcc -c $< -o f1.o
main.o:main.c #根据隐含规则1 可省略,包括后边命令
gcc -c main.c -o main.o
.PHONY:clean
clean:
rm *.o test
Makefile2
CC=gcc
CLFAGS=-Wall -O -g
test:f1.o f2.o main.o
.PHONY:clean
clean:
rm *.o test
静态模式2
Makefile 静态模式——$(objects): %.o: %.c
静态模式+自动化变量
举例
objects = foo.o bar.o
all: $(objects)
$(objects): %.o: %.c
$(CC) -c $(CFLAGS) $< -o $@
等价于⬇
foo.o : foo.c
$(CC) -c $(CFLAGS) foo.c -o foo.o
bar.o : bar.c
$(CC) -c $(CFLAGS) bar.c -o bar.o
伪目标
test:f1.o f2.o main.o
gcc f1.o f2.o main.o -o test
f2.o:f2.c
gcc -c f2.c -o f2.o
f1.o:f1.c
gcc -c f1.c -o f1.o
main.o:main.c
gcc -c main.c -o main.o
.PHONY:clean // 将clean 定义为伪目标,表明claen 不是一个可执行文件,避免在同级目录存在同名文件时,make 报错:
clean:
rm *.o test
设置伪目标前:

设置伪目标后:

生成多个可执行文件
makefile 默认只生成第一个可执行文件,所以为了同时编译多个可执行文件,我们用到了伪可执行文件,make 过程中并不生成 这个伪可执行文件,利用依赖的属性,同时生成三个可执行文件
all : init sender receiver
.PHONY : clean
init : init.o common.o
cc -pthread -o init init.o common.o
sender : sender.o common.o
cc -pthread -o sender sender.o common.o
receiver : receiver.o common.o
cc -pthread -o receiver receiver.o common.o
init.o : common.h
sender.o : common.h
receiver.o : common.h
clean :
rm init
rm receiver
rm sender
rm *.o
5.2 make命令的选项及Make
使用make 管理器非常简单,只需在make 命令的后面键入目标名即可建立指定的目标。如果直接运行make,则建立Makefile中的第一个目标。
命令行选项:
-C dir读入指定目录下的Makefile
-f file读入当前目录下的file文件作为Makefile
-i忽略所有的命令执行错误
-I dir指定被包含的Makefile所在目录
-n只打印要执行的命令,但不执行这些命令
-p显示make变量数据库和隐含规则
-s在执行命令时不显示命令
-w如果make在执行过程中改变目录,打印当前目录名
make命令参数传递
有时候,我们还是需要让make命令带入一些参数给makefile脚本。
比如,你在代码里面需要定义一个宏DEBUG来打开调试开关,代码如下:
int main(){int i=9;#ifdef DEBUGi=1;#elsei=0;#endifprintf("i=%d\n", i);return 0;}
一般来说,这个宏定义可以通过直接修改源代码进行,但这样显然不是很好的办法。另外一个办法是通过makefile修改,比如:
CFLAGS=-g -Wall -DDEBUG
object=myprog
all:$objectmyprog:a.c
gcc ${CFLAGS} a.c -o ${object}
如果更进一步,连makefile都不想修改,我们可以通过向make命令传递参数来进行,为此,我们需要适当的修改makefile如下:
CFLAGS=CFLAG
CFLAGS+=-g -Wall -DDEBUG
object=myprog
all:$objectmyprog:a.c
gcc ${CFLAGS} a.c -o ${object}
此时,如果想打开DEBUG宏,我们可以这样输入make命令:
[ychq@ICM3-2 net]$ make CFLAG=-DDEBUG
gcc -g -Wall -DDEBUG a.c
a.c: In function `main':
a.c:9: warning: implicit declaration of function `printf' [ychq@ICM3-2 net]$
我们可以发现,DEBUG宏已经被正确的传入。
更进一步的,我们可以通过传递不同的参数给make,让make编译不同的模块。
5.3 VPATH及嵌套的Makefile
Makefile的VPATH
VPATH : 虚路径
在一些大的工程中,有大量的源文件,我们通常的做法是把这许多的源文件分类,并存放在不同的目录中。所以,当make需要去找寻文件的依赖关系时,你可以在文件前加上路径,但最好的方法是把一个路径告诉make,让make在自动去找。
Makefile文件中的特殊变量“VPATH”就是完成这个功能的,如果没有指明这个变量,make只会在当前的目录中去找寻依赖文件和目标文件。如果定义了这个变量,那么,make就会在当当前目录找不到的情况下,到所指定的目录中去找寻文件了。
VPATH = src:…/headers
上面的的定义指定两个目录,“src”和“…/headers”,make会按照这个顺序进行搜索。目录由“冒号”分隔。(当然,当前目录永远是最高优先搜索的地方)
案例
CC=gcc
CFLAGS=-c -Wall -I include
VPATH=src1:src2:main
f1:f1.o f2.o main.o
$(CC) $(CFLAGS) $^ -o $@
.PHONY:clean
clean:
find ./ -name "*.o" -exec rm {} \;;rm f1
'linux中的 exec命令,-exec 后面跟的是linux的 command 命令,exec命令以分号结束‘;’, 该分号前面要放反斜杠转义 。{} 花括号代表前面的命令执行的结果
Makefile的嵌套
我们注意到有一句@echo $(SUBDIRS)
@echo off 的意思是关闭回显,不显示正在执行的批处理命令及执行的结果等。
语法:echo [{on off}] [message] 示例:@echo off / echo hello world。
当echo设置off值的时候,那么下面的指令都将只执行而不显示,当再次出现echo on时下面的语句才为可见的(回显)。
echo通常和@一起使用,@放在echo的前面,即是 @echo,作用是让@后面的句子不显示出来,而@本身也是不显示的
通过 @echo off 可达到不显示任何信息的效果。
@(RM)并不是我们自己定义的变量,那它是从哪里来的呢?
预定义变量 : RM 文件删除程序的名称,默认值为rm -f
make -C @ ‘ − C d i r 读入指定目录下的 M a k e f i l e ‘ ‘ @ ` -C dir读入指定目录下的Makefile` ` @‘−Cdir读入指定目录下的Makefile‘‘@ ——目标文件的名称`
课程案例
工程文件如下:


可以看主Makefile文件内容如下
CC=gcc
#同一行命令换行结尾加 '\' 声明未结束。
SUBDIRS=f1 \
f2 \
main \
obj
OBJS=f1.o f2.o main.o
BIN=myapp
OBJS_DIR=obj
BIN_DIR=bin
#export的作用是将变量传递给子目录下的Makefile文件以供它们使用
export CC OBJS BIN OBJS_DIR BIN_DIR
all:CHECK_DIR $(SUBDIRS)
CHECK_DIR:
mkdir -p $(BIN_DIR)
$(SUBDIRS):ECHO
make -C $@
ECHO:
@echo $(SUBDIRS)
@echo begin compile
CLEAN:
@$(RM) $(OBJS_DIR)/*.o
@rm -rf $(BIN_DIR)
其他案例:
在一些大的工程中,我们会把我们不同模块或是不同功能的源文件放在不同的目录中,我们可以在每个目录中都书写一个该目录的 Makefile,这有利于让我们的 Makefile 变得更加地简洁,而不至于把所有的东西全部写在一个 Makefile 中,这样会很难维护我们的 Makefile,这个技术对于我们模块编译和分段编译有着非常大的好处。
工程文件如下

可以看主makefile文件内容如下
CC =gcc
TOP_DIR :=$(PWD)
INCLUDE :=$(TOP_DIR)/headers
SRC_DIR :=$(TOP_DIR)/src
APP_DIR :=$(TOP_DIR)/app
VPATH := $(SRC_DIR):$(APP_DIR)
CFLAGS = -I $(INCLUDE)
export CC VPATH CFLAGS
.PHONY:all clean
all:
$(MAKE) -C $(SRC_DIR)
$(MAKE) -C $(APP_DIR)
clean:
$(MAKE) -C $(SRC_DIR) clean
$(MAKE) -C $(APP_DIR) clean
其中$(MAKE) -C ( S R C D I R ) 是到对应的子目录下执行 m a k e ,使用 (SRC_DIR)是到对应的子目录下执行make,使用 (SRCDIR)是到对应的子目录下执行make,使用(MAKE)是为了方便以后可以添加适当的make参数,-C参数是在进入或者退出目录时打印出来。
export的作用是将变量传递给子目录下的Makefile文件以供它们使用。
版权声明:本文为CSDN博主「juruiyuan111」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/juruiyuan111/article/details/119894932
注脚
简单来说,嵌入式技术是以应用为中心,以计算机技术为基础,并且软硬件可裁剪,适用于应用系统对功能、可靠性、成本、体积、功耗有严格要求的专用计算机系统技术。嵌入式系统是一种包括硬件和软件的完整的计算机系统,它的定义是:“嵌入式系统是以应用为中心,以计算机技术为基础,并且软硬件可剪裁,适用于应用系统对功能、可靠性、成本、体积和功耗有严格要求的专用计算机系统。”嵌入式系统所用的计算机是嵌入到被控对象中的专用微处理器,但是功能比通用计算机专门化,具有通用计算机所不能具备的针对某个方面特别设计的、合适的运算速度、高可靠性和较低比较成本的专用计算机系统。参考链接 ↩︎
这个静态模式就是一种自动编译模式,在这种模式下,我们可以容易的定义“多目标”规则,让我们的规则变得更加有弹性和灵活。它的语法如下:
< targets …> : < target-pattern > : < prereq-patterns …>
…
其中:
targets定义了一些列的目标文件,也就是多目标,可以有通配符,是目标的一个集合。
target-pattern 是targets的模式,也就是目标集模式
prereq-patterns 则是目标的“依赖”元素,
这么去说,可能还是比较拗口,不容易理解,我们还是把理论落地,举例一下吧:
我们把target-pattern 定义成 %.o 意思是我们的target集合都是以.o结尾。当然这里也可以使用通配符*,只不过%多用于Makefile,他们两个的区别,我们后面再讲。而我们的prereq-patterns则定义为%.c,这意思就是对 target-pattern中所形成的目标集进行二次定义,其计算方法是取target-pattern模式中的%代表部分(其实就是去掉.o后的文件名),并为其加上[.c]结尾,形成新的集合。
————————————————
版权声明:本文为CSDN博主「猪哥-嵌入式」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u012351051/article/details/88600562 ↩︎