如何设计统一元数据
元数据管理是对数据采集、存储、加工和展现等数据全生命周期的描述信息,帮助用户理解数据关系和相关属性。元数据管理工具可以了解数据资产分布及产生过程。实现元数据的模型定义并存储,在功能层包装成各类元数据功能,最终对外提供应用及展现;提供元数据分类和建模、血缘关系和影响分析,方便数据的跟踪和回溯。
元数据是企业数据资源的应用字典和操作指南,元数据管理有利于统一数据口径、标明数据方位、分析数据关系、管理数据变更,为企业级的数据治理提供支持,是企业实现数据自服务、推动企业数据化运营的可行路线。
没有元数据,将带来诸如下面的一些问题:
1 无法寻找和访问数据。在不知道元数据的情况下,寻找和访问数据将会是很费时费力的事情,该过程无异于在没有索引的情况下,在图书馆找一本想要的书;
2 数据容易变成“数据沼泽”;
3 无法理解数据的结构、格式;
4 无法识别数据来源和评价数据的质量、可信度;
5 无法复用知识和数据资产
元数据本身内容非常丰富,包括技术元数据、业务元数据和操作元数据,本文只关注技术元数据,比如数据库、数据表、字段、分区、视图、索引、函数等。
构建元数据包含以下三个部分的内容:
元数据采集:包括从关系数据库系统、NOSQL数据库系统以及大数据平台等异构数据源中采集元数据
元数据管理:实现元数据的模型定义、存储,支持元数据的基本信息、属性、依赖关系、组合关系的增删改查操作与版本管理和权限隔离
元数据应用:包括数据地图,血缘分析、影响分析、全链分析、关联度分析、属性值差异分析等
Data Catalog
元数据通常按照Catalog、Database和Table三级形式组织。所谓Catalog(数据目录),简单讲是企业用于管理数据资产的方式。企业通过元数据来组织他们的数据。Catalog也有助于数据专家采集、组织、访问数据,同时也可用于数据发现和治理。Catalog在数据资产管理中处于核心位置。那么,Catalog需要具备什么样的能力呢?为说明这个问题,我们以 Flink Catalog来看看数据湖技术中是如何定义其功能的。
void open() throws CatalogException;
void close() throws CatalogException;
String getDefaultDatabase() throws CatalogException;
List listDatabases() throws CatalogException;
CatalogDatabase getDatabase(String databaseName);
boolean databaseExists(String databaseName) throws CatalogException;
void createDatabase(String name, CatalogDatabase database, boolean ignoreIfExists);
void dropDatabase(String name, boolean ignoreIfNotExists, boolean cascade);
void alterDatabase(String name, CatalogDatabase newDatabase, boolean ignoreIfNotExists);
List listTables(String databaseName) throws DatabaseNotExistException, CatalogException;
List listViews(String databaseName) throws DatabaseNotExistException, CatalogException;
CatalogBaseTable getTable(ObjectPath tablePath) throws TableNotExistException, CatalogException;
boolean tableExists(ObjectPath tablePath) throws CatalogException;
void dropTable(ObjectPath tablePath, boolean ignoreIfNotExists);
void renameTable(ObjectPath tablePath, String newTableName, boolean ignoreIfNotExists);
void createTable(ObjectPath tablePath, CatalogBaseTable table, boolean ignoreIfExists);
void alterTable(ObjectPath tablePath, CatalogBaseTable newTable, boolean ignoreIfNotExists);
List listPartitions(ObjectPath tablePath);
boolean partitionExists(ObjectPath tablePath, CatalogPartitionSpec partitionSpec);
void createPartition(
ObjectPath tablePath,
CatalogPartitionSpec partitionSpec,
CatalogPartition partition,
boolean ignoreIfExists);
void dropPartition(
ObjectPath tablePath, CatalogPartitionSpec partitionSpec, boolean ignoreIfNotExists);
List listFunctions(String dbName) throws DatabaseNotExistException, CatalogException;
boolean functionExists(ObjectPath functionPath) throws CatalogException;
void createFunction(ObjectPath functionPath, CatalogFunction function, boolean ignoreIfExists);
void dropFunction(ObjectPath functionPath, boolean ignoreIfNotExists);
CatalogTableStatistics getTableStatistics(ObjectPath tablePath);
CatalogColumnStatistics getTableColumnStatistics(ObjectPath tablePath);
CatalogTableStatistics getPartitionStatistics(
ObjectPath tablePath, CatalogPartitionSpec partitionSpec);
...... 从Flink Catalog的接口定义来看,它提供了一系列元数据的操作接口,包括增删改查数据库、数据表、函数、分区、统计信息等,如果再看其他引擎框架,会发现它们也都实现了自己的Catalog,比如Spark、Iceberg、Trino、Hive(3.x)等,而且这些接口定义大同小异,都是有关元数据操作的接口定义,因此我们可以把Catalog看做是引擎提供的面向用户操作元数据的接口集合,但这些Catalog也有一些区别,表现在:
1.接口功能跟引擎绑定;
2 Flink、Iceberg、Spark和Trino虽然都定义了Catalog,但Flink、Iceberg和Spark有各自的元数据存储实现,Trino Catalog将元数据的存取请求代理到数据源本身;
3 Hive实现了独立的元数据存储(HMS),并成为元数据存储事实上的标准,其他引擎都兼容HMS;
4 HMS 3.x实现了对Catalog本身的持久化和管理,其他引擎没有实现对Catalog的持久化
在使用Catalog的时候,使用方既可以使用API来操作元数据,比如下面使用Java API实例化并注册一个HiveCatalog:
hiveConf = new HiveConf(new Configuration(), MyExample.class);
hiveCatalog = new HiveCatalog(hiveConf);
tableEnv.registerCatalog(catalogName, hiveCatalog);
tableEnv.useCatalog(catalogName);
tableEnv.executeSql("CREATE TABLE...");也可以使用SQL的方式,比如下面使用SQL定义一个类型为hive的Catalog:
--flink sql create a catalog which gives access to the backing Hive installation
CREATE CATALOG hive_catalog WITH (
'type'='hive',
'hive-conf-dir'='/opt/hive-conf'
);
use hive_catalog;定义Catalog之后就可以执行SQL语句,包括DDL等,对Flink Hive Catalog来说,还可以将其他数据源的表注册到当前Catalog,比如下面示例中在HiveCatalog中注册Mysql表:
--flink sql use hive_catalog;
CREATE TABLE MysqlTable (
user_id BIGINT,
name STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://10.0.30.12:3306/users',
'table-name' = 'Users'
)这意味着在Flink中的Hive Catalog跟数据源是一对多的关系。同理,多个Catalog也可以注册相同的数据源的,比如Hive Catalog和JDBC Catalog都可以注册Mysql表,这意味着Catalog跟数据源是多对一的关系,因此对Flink来说,Hive Catalog跟数据源是多对多的关系,而在Trino等引擎中,HiveCatalog跟数据源是一对一的关系,也就是在HiveCatalog只能创建Hive表,在JdbcCatalog中只能创建mysql表。
元数据存储
明白了Catalog的功能与使用方式,接下来看看如何存储Catalog?实际上Flink、Spark和Iceberg支持多种Catalog的存储实现,除了都兼容HMS外,都实现了基于内存的元数据存储。因此有必要统一元数据存储,理由如下:
Flink和Spark默认使用内存型Catalog,基于内存的Catalog管理的元数据不能持久化且不能被其他引擎复用;
统一Catalog能够让不同引擎共享元数据,能够真正做到存算分离;
Hive Metastore作为元数据管理事实上的标准,Flink、Spark、Iceberg和Trino都兼容Hive Metastore,采用HMS或类似HMS的兼容方案更容易实现;
Flink、Spark和Iceberg的catalog跟数据源是多对多的关系,而trino的catalog跟数据源是一对一的关系,这导致在权限控制上比较困难,但基于Catalog粒度的权限控制相对比较容易;
HMS不支持多租户;
HMS单机服务不支持扩展,且接口查询性能较低;
HMS存在多版本兼容问题;
HMS 只支持HiveCatalog,不支持其他类型的Catalog;
HMS不支持动态切换存储引擎,目前修改底层存储引擎需要重启服务,且同一种类型的存储引擎只能有一个实例
基于以上诸多原因,这里选择基于HMS表结构来重新实现统一存储的元数据存储方案,它在元数据系统的位置如下图所示:
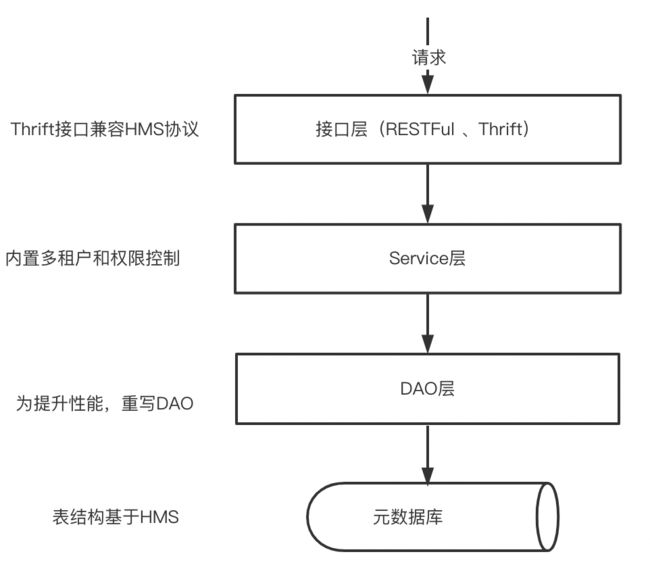
HMS可以基于Derby、Mysql、Postgrel来实现存储,它涉及到很多的表,包括Schema信息存储表、权限信息存储表、统计信息存储表以及权限信息存储表等,下面以HMS 3.x为例,看看它是如何实现元数据的存储的,这里只介绍一些跟Schema相关的表,主要包括:
表名称 |
表描述 |
CTLGS |
Catalog数据表 |
DBS |
DataBase数据表 |
TBLS |
Table数据表 |
COLUMNS_V2 |
存储字段信息,通过CD_ID与其他表关联 |
DATABASE_PARAMS |
DataBase参数数据表 |
TABLE_PARAMS |
Table参数数据表 |
SDS |
存储输入输出format等信息,包括表的format和分区的format。关联字段CD_ID,SERDE_ID |
SD_PARAMS |
SDS参数数据表 |
SERDES |
存储序列化反序列化使用的类 |
SERDE_PARAMS |
序列化反序列化相关信息,通过SERDE_ID关联 |
这些表根据外键关联,ER模型表示如下:
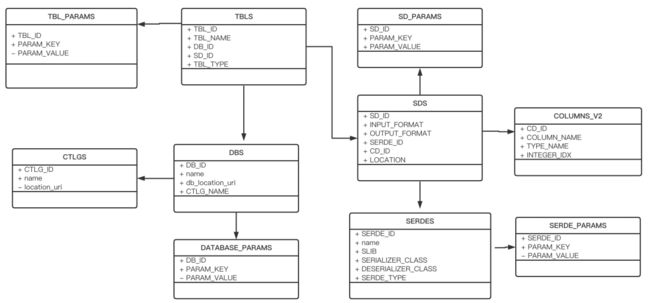
上述各表都是通过外键关联在一起的,比如根据DBS的主键DB_ID将DBS和TBLS关联起来,根据TBLS的主键TBL_ID将表TBLS、TBL_PARAMS、SDS(主键CD_ID)、COLUMNS_V2(主键CD_ID)关联在一起,下面以两个示例来说明HMS是如何查询这些表的。
查询所有表:使用TBLS的DB_ID外键关联表DBS:
--postgrel sql
--查询default库的所有表
select
db."NAME",
tb."TBL_NAME"
from "TBLS" tb
join "DBS" db on tb."DB_ID" = db."DB_ID" and db."NAME"='default';查询表的所有列:使用COLUMNS_V2的外键CD_ID关联TBLS,同时用TBLS的DB_ID外键关联表DBS:
--postgrel sql
--查询表default.t1的所有列
select
db."NAME",
tb."TBL_NAME",
c."COLUMN_NAME",
c."TYPE_NAME"
from "TBLS" tb
join "DBS" db on tb."DB_ID" = db."DB_ID"
join "COLUMNS_V2" c on c."CD_ID" = tb."TBL_ID" and db."NAME"='default' AND tb."TBL_NAME"='t1';统一元数据
上节中我们介绍了统一存储元数据的实现方案,在实际大数据平台应用环境还存在大量的数据源,比如Hive数据仓库、关系数据库、消息系统如Kafka、云数仓如Redishift、Elasticsearch等,在其上还有多种计算引擎如Spark、Hive、Flink、Trino等用来消费、处理和生成新的数据集,因为数据源的多样性,为了确保数据平台能够横跨这些数据集成为一个“单一”的数据仓库,需要在服务层面统一元数据,方便我们发现、处理和管理数据,形成真正的元数据统一,为此,它需要具备以下能力:
数据抽象和互操作性:通过引入通用的抽象层,提供统一的访问API,不同的引擎可以交互访问这些数据集。为便于与 Spark、Flink和 Trino等 集成,提供支持 Hive 的 Thrift 接口。
存储业务和用户自定义的元数据:统一元存储只存储技术元数据,实际上,还会有部分业务元数据和用户自定义元数据,例如 RDS 数据源)、配置信息、度量指标(Hive/S3 分区和表)以及数据表的 TTL(生存时间)等。它们是一种自由格式的元数据,可由用户根据自己的用途进行定义。业务元数据也可以大致分为逻辑元数据和物理元数据。有关逻辑结构(如表)的业务元数据被视为逻辑元数据。我们使用元数据进行数据分类 和标准化我们的 ETL 处理流程。数据表的所有者可在业务元数据中提供数据表的审计信息。他们还可以为列提供默认值和验证规则,在写入数据时会用到这些。存储在表中或分区中的实际数据的元数据被视为物理元数据。我们的 ETL 处理在完成作业时会保存数据的度量标准,在稍后用于验证。相同的度量可用来分析数据的成本和空间。因为两个表可以指向相同的位置(如 Hive),所以要能够区分逻辑元数据与物理元数据。两个表可以具有相同的物理元数据,但应该具有不同的逻辑元数据。
数据发现:作为数据的消费者,我们应该能够轻松发现和浏览各种数据集。为提升查询效率和能力,需要将Schema元数据和业务及用户定义的元数据发布到 Elasticsearch,以便进行全文搜索。SQL 编辑器因此能够实现 SQL 语句的自动建议和自动完成功能。将数据集组织为Catalog有助于消费者浏览信息,根据不同的主题使用标签对数据进行分类。我们还使用标签来识别表格,进行数据生命周期管理。
数据变更审计和通知:作为数据存储的中央网关,统一元数据能够捕获所有元数据变更和数据更新,通过构建基于事件驱动的系统架构,将元数据变更通知发布到消息系统,不仅有助于上下游系统解耦,还有助于下游系统响应的及时性。
Schema和元数据的版本控制:用于提供数据表的历史记录。例如,跟踪特定列的元数据变更,或查看表的大小随时间变化的趋势。能够查看过去某个时刻元数据的信息对于审计、调试以及重新处理和回滚来说都非常有用。
我们的统一元数据服务可以用形如下面的架构来描述:

它由三个部分组成:
1. 数据源:支持多种类型数据源的元数据收集,包括常用的关系型数据库(如Myql、Postgrel SQL)、NOSQL数据库(如Redis、Cassandra)、数据仓库(如Hive、Redshift)、分布式消息系统(如Kafka、Pulsar)等
2. 元数据存储:存储数据源的元数据,同元数据存储章节中介绍的基于Catalog-Database-Table的数据目录存储:
第一级 Catalog,按照数据源划分,每一种数据源示例作为一种Catalog
第二级 Database,它与大部分系统的 Database 保持一致。没有 Database 的系统默认使用 default 来代替
第三级 Table,也与系统的 Table 保持一致,比如Mysql的Table、消息队列的 topic 名、Elasticsearch 的索引名
为了支持部分业务元数据相关的功能,元数据存储需要增加一些表来实现此功能。特别是支持全文检索,还需要将元数据同步到ElasticSearch。为了保证第三方Hive元数据方便迁移到统一元数据,元数据存储方案应尽量保持HMS的基本结构。
3. 元数据服务暴露:元数据服务主要通过三种方式暴露:Restful API、Thrift RPC和消息队列。其中Restful API可用于数据发现等应用场景调用。Thrift RPC提供兼容HMS协议接口,可供标准的Hive Client调用。消息队列提供元数据的变更追踪与审计所需要的及时通知等能力。
实现上述功能,有几个挑战需要解决:
1. 不同数据源的元数据如何收集。目前有两种方案:从源数据即时请求和从源数据同步备份。统一元数据服务通常面向用户侧,如UI面板或者API服务,因此对服务的吞吐量和延时性要求较高,基于从源数据即时请求的方式显然无法保证这两个要求,如从Hive Metastore获取数据库列表信息通常需要数秒时间。从源数据同步备份虽然能够保证请求的吞吐量和延时性,但是如何备份、多久备份一次、备份失败怎么办等细节问题较多,增加了系统运维的复杂度。
2. 基于事件机制收集元数据还是基于调度的方式收集元数据。虽然基于事件机制的方式不仅能增量收集元数据,而且及时性较高,但不是每种数据源都支持事件机制。好消息是,实际中,可能大部分场景对及时性要求不高,此时基于调度的方式收集元数据是可行的,此时需要解决调度的可靠性和并发性等问题。
3. 元数据存储方式。包括不同数据源的元数据如何适配统一元数据的存储格式和大规模元数据的扩容问题。收集不同数据源的元数据,其数据规模会很可观,基于HMS的元数据存储支持关系数据库存储,但是关系数据库无法水平扩展,在大数据集下存在性能瓶颈,因此需要选择支持可扩展的分布式存储系统。