lv11 嵌入式开发 ARM指令集中(汇编指令集) 6
目录
1.指令
1.1 数据处理指令:数学运算、逻辑运算
1.1.1数据搬移指令MOV 、MVN
1.1.2立即数
1.1.3 加法指令
1.1.4 减法指令
1.1.5 逆向减法指令
1.1.6 乘法指令
1.1.7 与、或、非、异或、左移、右移指令
1.1.8 位清零指令
1.1.9 格式扩展
1.1.10 数据运算指令对条件位(N、Z、C、V)的影响
总结:
练习:
1.2 跳转指令:实现程序的跳转,本质就是修改了PC寄存器
1.2.1 方式一:直接修改PC寄存器的值(不建议使用,需要自己计算目标指令的绝对地址)
1.2.2 方式二:不带返回的跳转指令,本质就是将PC寄存器的值修改成跳转标号下指令的地址
1.2.3 方式三:带返回的跳转指令,本质就是将PC寄存器的值修改成跳转标号下指令的地址,同时将跳转指令下一条指令的地址存储到LR寄存器
1.2.4 ARM指令的条件码
1.2.5 ARM指令集中大多数指令都可以带条件码后缀
练习
1.3 Load/Store指令:访问(读写)内存
1.3.1寻址方式就是CPU去寻找操作数的方式
练习:
1.3.2 多寄存器内存访问指令
1.3.3 栈的种类与使用
1.4 栈的应用举例
1.4.1.叶子函数的调用过程举例
1.4.2.非叶子函数的调用过程举例
练习:
1.5 状态寄存器传送指令:访问(读写)CPSR寄存器
1.6 软中断指令:触发软中断
1.7 协处理器指令:操控协处理器的指令
2 伪指令:本身不是指令,编译器可以将其替换成若干条等效指令
练习:
1.指令
指令:能够编译生成一条32位的机器码,且能被CPU识别和执行
1.1 数据处理指令:数学运算、逻辑运算
1.1.1数据搬移指令MOV 、MVN
@ 数据搬移指令
@ MOV R1, #1
@ R1 = 1
@ MOV R2, R1
@ R2 = R1
@ MVN R0, #0xFF
@ R0 = ~0xFF MVN与MOV的区别在于,MVN是取反
验证1:PC指针

下一条指令的地址是上一条指令地址+4,R15(PC)指针是不停变化的
验证2:ARM指令不同于复杂指令,所有指令都是32位
验证3: 指令的地址都是4的整数倍
验证4: PC用法,指针可以修改

验证5:PC的值也必须是4的整数倍,但是人为改可以随便写,但是最后两位是没有定义的,最后两位是00。
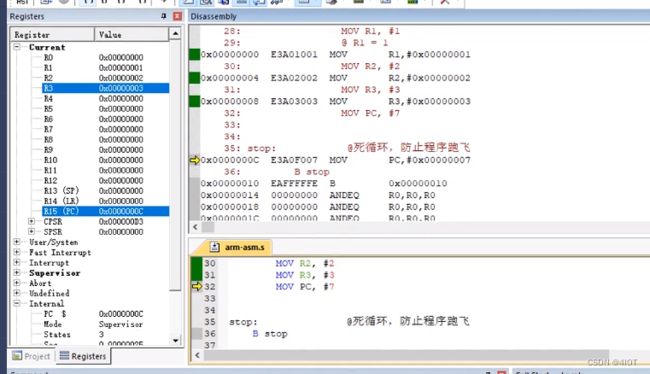
验证6:1条汇编对应1条机器码,不同指令对应不同机器码


1.1.2立即数
哪些是立即数?哪些不是立即数?编译通过就是,不通过就不是。能够直接放到MOV后面的叫立即数
@ 立即数
@ 立即数的本质就是包含在指令当中的数,属于指令的一部分
@ 立即数的优点:取指的时候就可以将其读取到CPU,不用单独去内存读取,速度快
@ 立即数的缺点:不能是任意的32位的数字,有局限性
@ MOV R0, #0x12345678 整个指令32位,单一个数超过了指令大小
@ MOV R0, #0x12
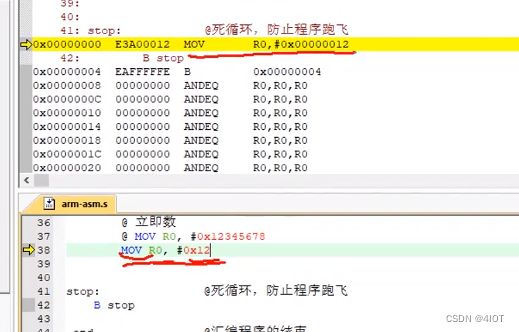
本质:
执行a++CPU的过程:从内存中取出变量a的值,取出+的值,再进行运算。(变量独占一个空间)立即数CPU的过程:从内存中取出指令带数据,指令中已经包含了执行的数,只需取1次。优点速度块。缺点:不可以是任意数。
问:MOV R0, #0xFFFFFFFF 不报错也不是立即数,为什么?
替换成了MVN R0,#0x00000000,编译器发现替换指令达到的效果一样,即转换成立编译器可以执行的指令,所以不报错。类似伪指令。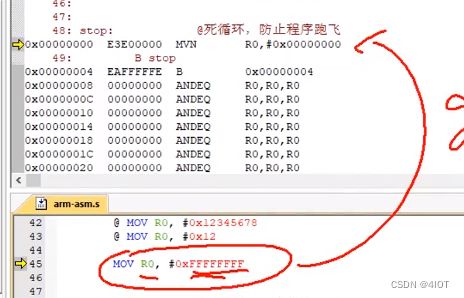
1.1.3 加法指令
@ 数据运算指令基本格式
@ 《操作码》《目标寄存器》《第一操作寄存器》《第二操作数》
@ 操作码 指示执行哪种运算
@ 目标寄存器: 存储运算结果
@ 第一操作寄存器:第一个参与运算的数据(只能是寄存器)
@ 第二操作数: 第二个参与运算的数据(可以是寄存器或立即数)
@ 加法指令
@ MOV R2, #5
@ MOV R3, #3
@ ADD R1, R2, R3
@ R1 = R2 + R3
@ ADD R1, R2, #5
@ R1 = R2 + 5
1.1.4 减法指令
@ 减法指令
@ SUB R1, R2, R3
@ R1 = R2 - R3
@ SUB R1, R2, #3
@ R1 = R2 - 3
1.1.5 逆向减法指令
因为第一操作寄存器:第一个参与运算的数据(只能是寄存器),所以产生了逆向减法指令
@ 逆向减法指令
@ RSB R1, R2, #3
@ R1 = 3 - R2
1.1.6 乘法指令
@ 乘法指令
@ MUL R1, R2, R3
@ R1 = R2 * R3
@ 乘法指令只能是两个寄存器相乘
1.1.7 与、或、非、异或、左移、右移指令
@ 按位与指令
@ AND R1, R2, R3
@ R1 = R2 & R3
@ 按位或指令
@ ORR R1, R2, R3
@ R1 = R2 | R3
@ 按位异或指令
@ EOR R1, R2, R3
@ R1 = R2 ^ R3
@ 左移指令
@ LSL R1, R2, R3
@ R1 = (R2 << R3)
@ 右移指令
@ LSR R1, R2, R3
@ R1 = (R2 >> R3)
1.1.8 位清零指令
@ 位清零指令
@ MOV R2, #0xFF
@ BIC R1, R2, #0x0F
@ 第二操作数中的哪一位为1,就将第一操作寄存器的中哪一位清零,然后将结果写入目标寄存器
1.1.9 格式扩展
格式扩展可以把后面整体看作第二操作数,然后再对第二操作数进行分解。
@ 格式扩展
@ MOV R2, #3
@ MOV R1, R2, LSL #1
@ R1 = (R2 << 1)
1.1.10 数据运算指令对条件位(N、Z、C、V)的影响
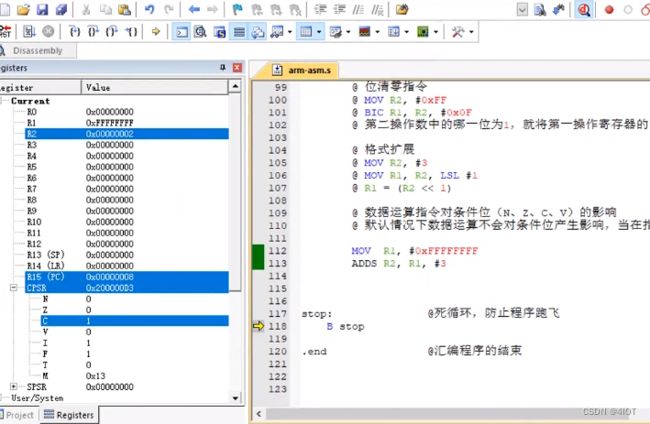
@ 数据运算指令对条件位(N、Z、C、V)的影响
@ 默认情况下数据运算不会对条件位产生影响,在指令后加后缀”S“才可以影响
@ 带进位的加法指令
@ 两个64位的数据做加法运算
@ 第一个数的低32位放在R1
@ 第一个数的高32位放在R2
@ 第二个数的低32位放在R3
@ 第二个数的高32位放在R4
@ 运算结果的低32位放在R5
@ 运算结果的高32位放在R6
@ 第一个数
@ 0x00000001 FFFFFFFF
@ 第二个数
@ 0x00000002 00000005
@ MOV R1, #0xFFFFFFFF
@ MOV R2, #0x00000001
@ MOV R3, #0x00000005
@ MOV R4, #0x00000002
@ ADDS R5, R1, R3
@ ADC R6, R2, R4
@ 本质:R6 = R2 + R4 + 'C'
@'C'代表进位+1,ADC表示可以把上一次带进位的加上
@ 带借位的减法指令
@ 第一个数
@ 0x00000002 00000001
@ 第二个数
@ 0x00000001 00000005
@ MOV R1, #0x00000001
@ MOV R2, #0x00000002
@ MOV R3, #0x00000005
@ MOV R4, #0x00000001
@ SUBS R5, R1, R3
@ SBC R6, R2, R4
@ 本质:R6 = R2 - R4 - '!C'
@ '!C'代表退位1,SBC表示可以把上一次带退位的减去总结:
学习汇编主要是以后在写C语言的时候,对程序有汇编的思想,因为一条C语言会对应很多条汇编,能用int,就不要用longlong,不用float,虽然arm能解决32位以上数的运算,包括浮动数的运行,但是这会对程序执行的效率产生影响。
练习:
编程实现使用32bit的ARM处理器实现两个128位的数据的加法运算。
注:
第一个数的bit[31:0]、bit[63:32]、bit[95:64]、bit[127:96]分别存储在R1、R2、R3、R4寄存器
第二个数的bit[31:0]、bit[63:32]、bit[95:64]、bit[127:96]分别存储在R5、R6、R7、R8寄存器
运算结果的bit[31:0]、bit[63:32]、bit[95:64]、bit[127:96]分别存储在R9、R10、R11、R12寄存器
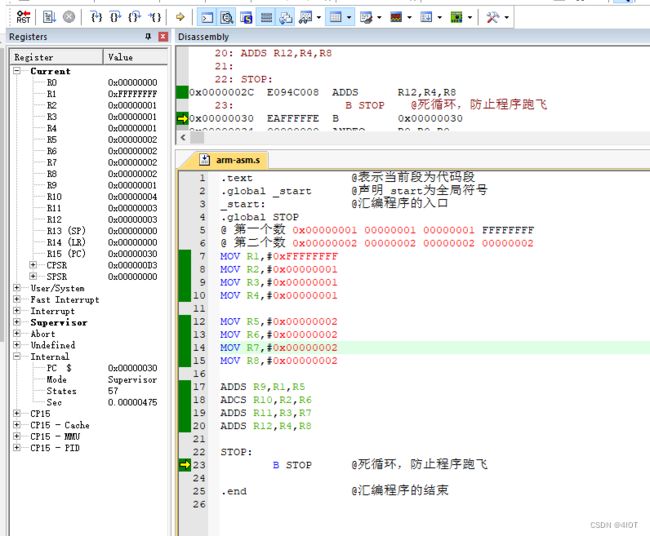
1.2 跳转指令:实现程序的跳转,本质就是修改了PC寄存器
PC指针会自增4,但是内存不会无限大,所以会有跳转指令
main、FUNC只是标号
1.2.1 方式一:直接修改PC寄存器的值(不建议使用,需要自己计算目标指令的绝对地址)
@ MAIN:
@ MOV R1, #1
@ MOV R2, #2
@ MOV R3, #3
@ B FUNC
@ MOV R4, #4
@ MOV R5, #5
@ FUNC:
@ MOV R6, #6
@ MOV R7, #7
@ MOV R8, #8
@ 方式三:带返回的跳转指令,本质就是将PC寄存器的值修改成跳转标号下指令的地址,同时将跳转指令下一条指令的地址存储到LR寄存器
@ MAIN:
@ MOV R1, #1
@ MOV R2, #2
@ MOV R3, #3
@ BL FUNC
@ MOV R4, #4
@ MOV R5, #5
@ FUNC:
@ MOV R6, #6
@ MOV R7, #7
@ MOV R8, #8
@ MOV PC, LR
@ 程序返回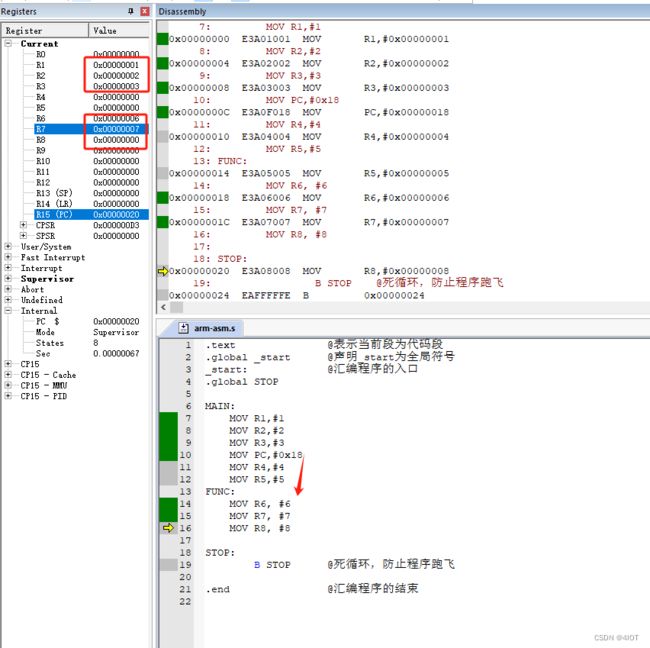
1.2.2 方式二:不带返回的跳转指令,本质就是将PC寄存器的值修改成跳转标号下指令的地址
@ MAIN:
@ MOV R1, #1
@ MOV R2, #2
@ MOV R3, #3
@ B FUNC
@ MOV R4, #4
@ MOV R5, #5
@ FUNC:
@ MOV R6, #6
@ MOV R7, #7
@ MOV R8, #8
1.2.3 方式三:带返回的跳转指令,本质就是将PC寄存器的值修改成跳转标号下指令的地址,同时将跳转指令下一条指令的地址存储到LR寄存器
@ MAIN:
@ MOV R1, #1
@ MOV R2, #2
@ MOV R3, #3
@ BL FUNC
@ MOV R4, #4
@ MOV R5, #5
@ FUNC:
@ MOV R6, #6
@ MOV R7, #7
@ MOV R8, #8
@ MOV PC, LR
@ 程序返回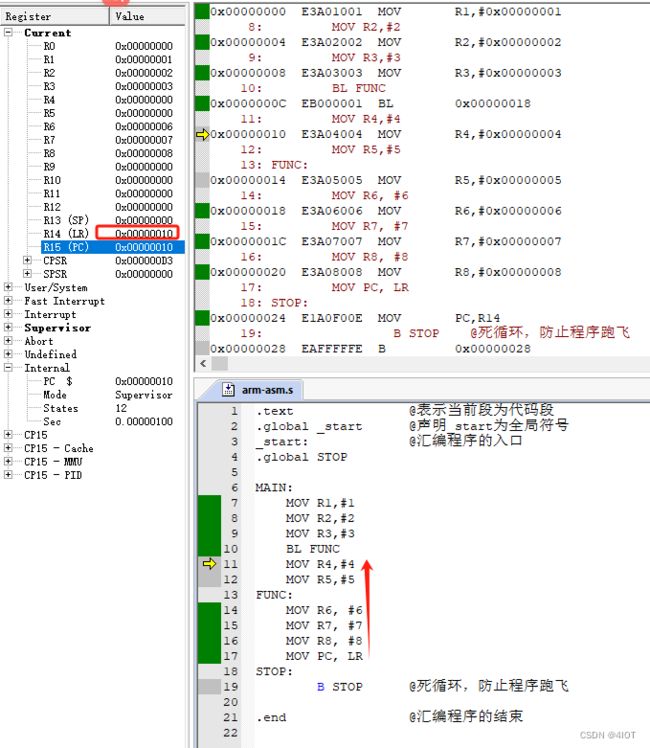
为什么要设计跳转BL,因为C语言调用完子程序后还要返回到原先的地方。CPU会帮我们在跳转的时候存储这个地址。
但是要注意,如果需要返回,自己需要加返回的代码,把PC指针指向LR
MOV PC,LR
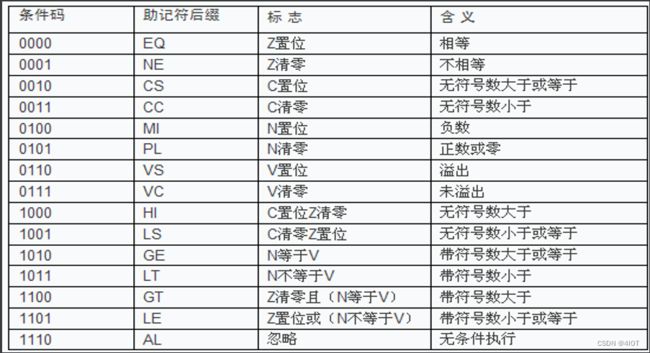
1.2.4 ARM指令的条件码
比较指令CMP
CMP指令的本质就是一条减法指令(SUBS),只是没有将运算结果存入目标寄存器。
比较的结果存在(NZCV),因为它的记过是布尔型的量,所以放在SPSR寄存器
@ MOV R1, #1
@ MOV R2, #2
@ CMP R1, R2
@ BEQ FUNC
@ 执行逻辑:if(EQ){B FUNC} 本质:if(Z==1){B FUNC}
@ BNE FUNC
@ 执行逻辑:if(NQ){B FUNC} 本质:if(Z==0){B FUNC}
@ MOV R3, #3
@ MOV R4, #4
@ MOV R5, #5
@ FUNC:
@ MOV R6, #6
@ MOV R7, #7常用条件码含义
- 等于 Z置1
- 不等于 Z=0
- 小于 C=0
- 小于等于 C=0 或 Z=1
- 大于 C=1 且 Z=0
- 大于等于 C=1

C语言中的if

1.2.5 ARM指令集中大多数指令都可以带条件码后缀
@ MOV R1, #1
@ MOV R2, #2
@ CMP R1, R2
@ MOVGT R3, #3练习
@ 练习:用汇编语言实现以下逻辑
@ int R1 = 9;
@ int R2 = 15;
@ START:
@ if(R1 == R2)
@ {
@ STOP();
@ }
@ else if(R1 > R2)
@ {
@ R1 = R1 - R2;
@ goto START;
@ }
@ else
@ {
@ R2 = R2 - R1;
@ goto START;
@ }
@ 练习答案
@ MOV R1, #9
@ MOV R2, #15
@ START:
@ CMP R1,R2
@ BEQ STOP
@ SUBGT R1, R1, R2
@ SUBLT R2, R2, R1
@ B START
@ STOP:
@ B STOP1.3 Load/Store指令:访问(读写)内存
写内存
@ 写内存
@ MOV R1, #0xFF000000
@ MOV R2, #0x40000000
@ STR R1, [R2]
@ 将R1寄存器中的数据写入到R2指向的内存空间读内存
@ 读内存
@ LDR R3, [R2]
@ 将R2指向的内存空间中的数据读取到R3寄存器示例:
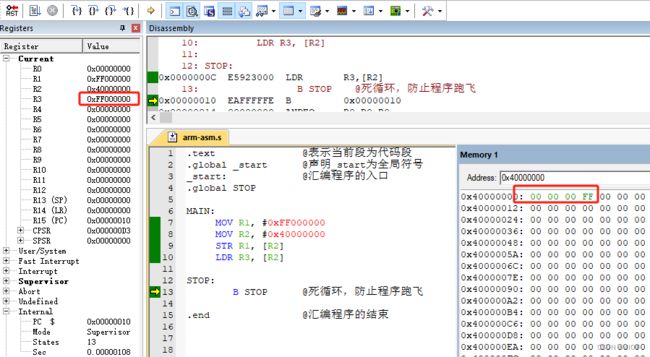
@ 读/写指定的数据类型
@ MOV R1, #0xFFFFFFFF
@ MOV R2, #0x40000000
@ STRB R1, [R2]
@ 将R1寄存器中的数据的Bit[7:0]写入到R2指向的内存空间
@ STRH R1, [R2]
@ 将R1寄存器中的数据的Bit[15:0]写入到R2指向的内存空间
@ STR R1, [R2]
@ 将R1寄存器中的数据的Bit[31:0]写入到R2指向的内存空间@ LDR指令同样支持以上后缀
1.3.1寻址方式就是CPU去寻找操作数的方式
立即寻址
@ MOV R1, #1
@ ADD R1, R2, #1寄存器寻址
@ ADD R1, R2, R3寄存器移位寻址
@ MOV R1, R2, LSL #1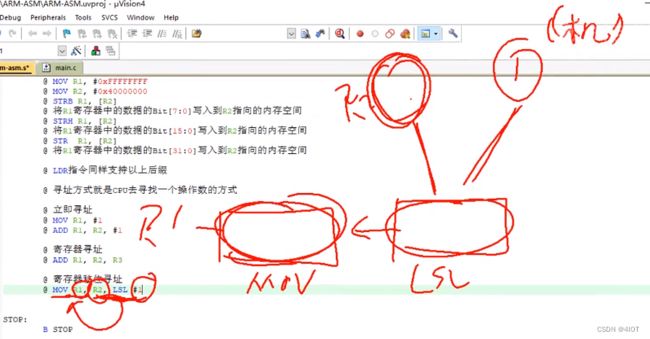
寄存器间接寻址
并没有直接操作R2寄存器,还是通过R2寄存器的指针去操作内存,所以称为间接寻址
@ STR R1, [R2] 基址加变指寻址
@ MOV R1, #0xFFFFFFFF
@ MOV R2, #0x40000000
@ MOV R3, #4
@ STR R1, [R2,R3]
@ 将R1寄存器中的数据写入到R2+R3指向的内存空间
@ STR R1, [R2,R3,LSL #1]
@ 将R1寄存器中的数据写入到R2+(R3<<1)指向的内存空间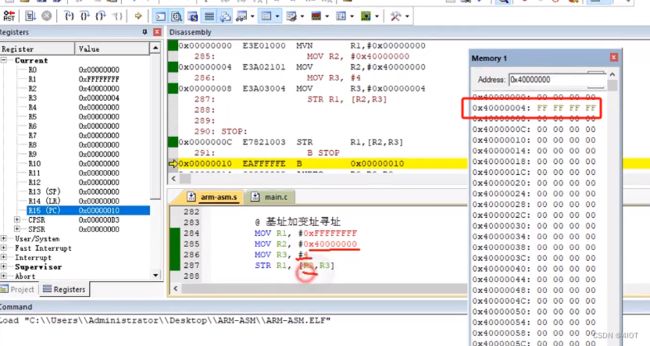
基址加变址寻址的索引方式
@ 前索引
@ MOV R1, #0xFFFFFFFF
@ MOV R2, #0x40000000
@ STR R1, [R2,#8]
@ 将R1寄存器中的数据写入到R2+8指向的内存空间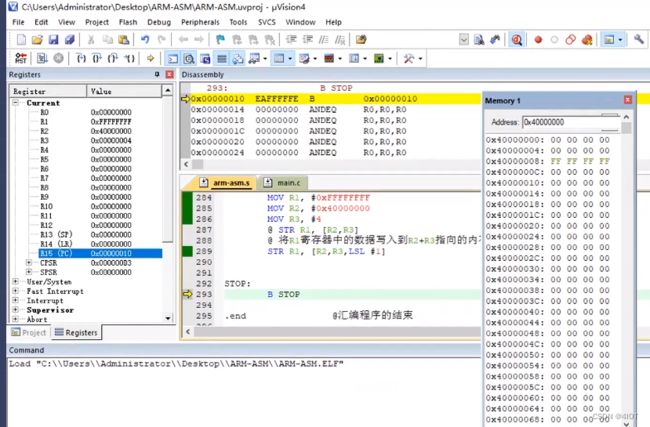
@ 后索引
@ MOV R1, #0xFFFFFFFF
@ MOV R2, #0x40000000
@ STR R1, [R2],#8
@ 将R1寄存器中的数据写入到R2指向的内存空间,然后R2自增8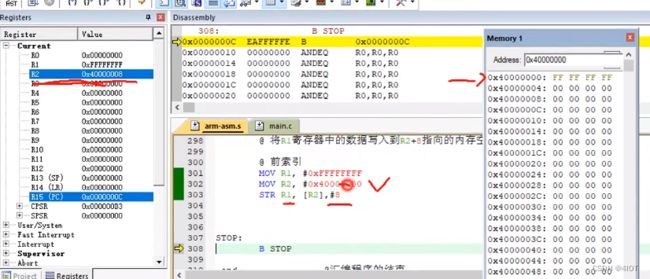
@ 自动索引
@ MOV R1, #0xFFFFFFFF
@ MOV R2, #0x40000000
@ STR R1, [R2,#8]!
@ 将R1寄存器中的数据写入到R2+8指向的内存空间,然后R2自增8
@ 以上寻址方式和索引方式同样适用于LDR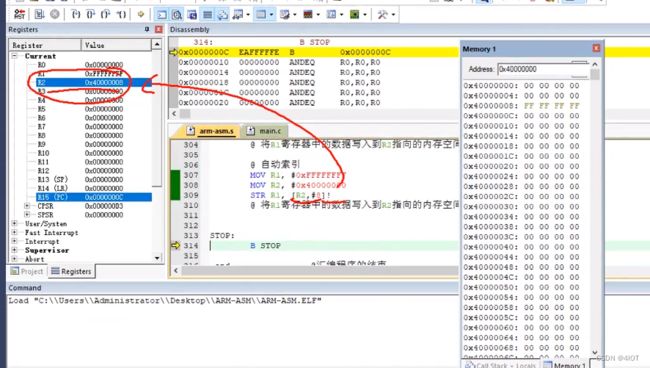
前索引用法,在C语言中,经常会遇到操作基地址,如数组、结构体访问中用到很多
char c[5] ,如果需要给c[3] = 'a'
后索引用法,希望操作完后下次操作下个值,要自增
以上寻址方式和索引方式同样适用于LDR
练习:
-
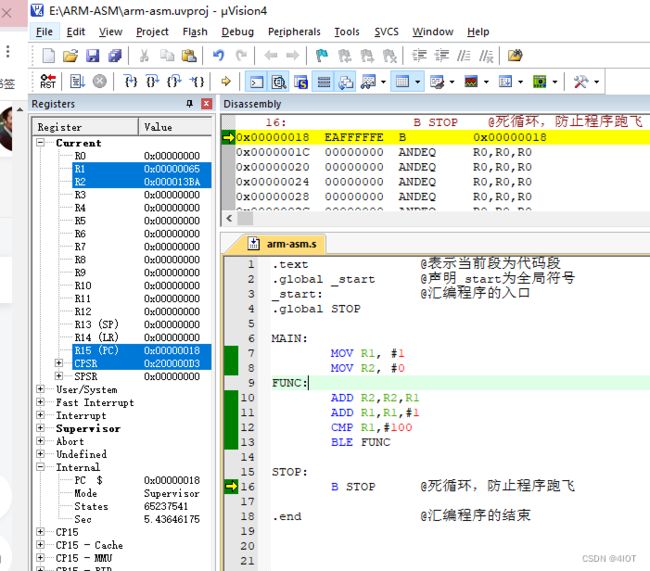
1.使用汇编语言实现100以内的正整数之和 注: 将最终的运算结果存储在R2寄存器
解答:
.text @表示当前段为代码段
.global _start @声明_start为全局符号
_start: @汇编程序的入口
.global STOP
MAIN:
MOV R1, #1
MOV R2, #0
FUNC:
ADD R2,R2,R1
ADD R1,R1,#1
CMP R1,#100
BLE FUNC
STOP:
B STOP @死循环,防止程序跑飞
.end @汇编程序的结束
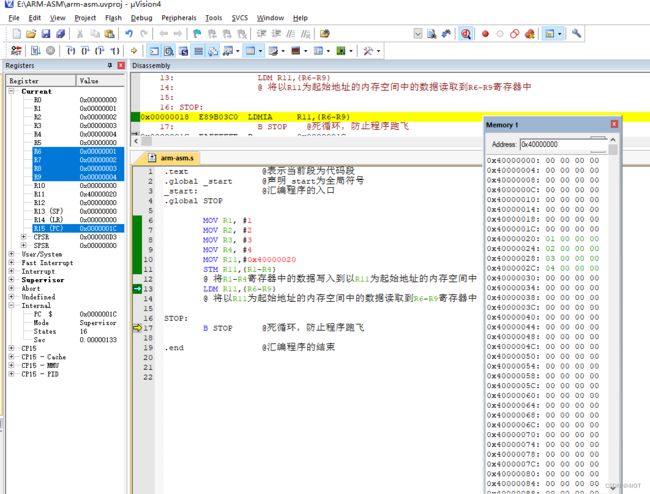
1.3.2 多寄存器内存访问指令
@ MOV R1, #1
@ MOV R2, #2
@ MOV R3, #3
@ MOV R4, #4
@ MOV R11,#0x40000020
@ STM R11,{R1-R4}
@ 将R1-R4寄存器中的数据写入到以R11为起始地址的内存空间中
@ LDM R11,{R6-R9}
@ 将以R11为起始地址的内存空间中的数据读取到R6-R9寄存器中
MOV R1, #1
MOV R2, #2
MOV R3, #3
MOV R4, #4
MOV R11,#0x40000020
@ 当寄存器编号不连续时,使用逗号分隔
STM R11,{R1,R2,R4}
@ 不管寄存器列表中的顺序如何,存取时永远是低地址对应小编号的寄存器
MOV R1, #1
MOV R2, #2
MOV R3, #3
MOV R4, #4
MOV R11,#0x40000020
STM R11,{R3,R1,R4,R2} 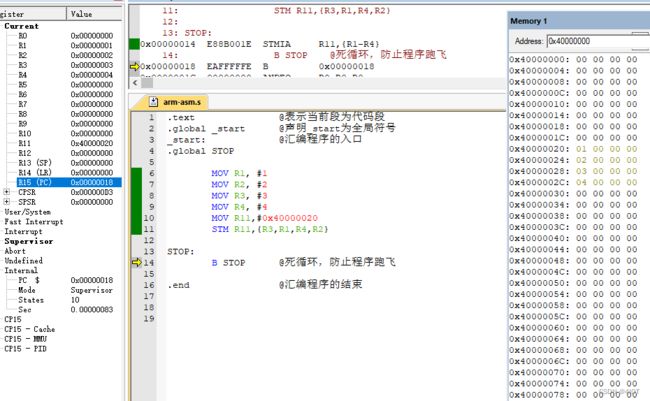
@ 自动索引照样适用于多寄存器内存访问指令
MOV R1, #1
MOV R2, #2
MOV R3, #3
MOV R4, #4
MOV R11,#0x40000020
STM R11!,{R1-R4}

@ 多寄存器内存访问指令的寻址方式
@ MOV R1, #1
@ MOV R2, #2
@ MOV R3, #3
@ MOV R4, #4
@ MOV R11,#0x40000020
@ STMIA R11!,{R1-R4}
@ 先存储数据,后增长地址
@ STMIB R11!,{R1-R4}
@ 先增长地址,后存储数据
@ STMDA R11!,{R1-R4}
@ 先存储数据,后递减地址
@ STMDB R11!,{R1-R4}
@ 先递减地址,后存储数据1.3.3 栈的种类与使用
@ 栈的种类与使用
@ MOV R1, #1
@ MOV R2, #2
@ MOV R3, #3
@ MOV R4, #4
@ MOV R11,#0x40000020
@ STMFD R11!,{R1-R4}
@ LDMFD R11!,{R6-R9}
1.4 栈的应用举例
1.4.1.叶子函数的调用过程举例
最后一个调用函数
@ 初始化栈指针
@ MOV SP, #0x40000020
@ MIAN:
@ MOV R1, #3
@ MOV R2, #5
@ BL FUNC
@ ADD R3, R1, R2
@ B STOP
@ FUNC:
@ 压栈保护现场
@ STMFD SP!, {R1,R2}
@ MOV R1, #10
@ MOV R2, #20
@ SUB R3, R2, R1
@ 出栈恢复现场
@ LDMFD SP!, {R1,R2}
@ MOV PC, LR1.4.2.非叶子函数的调用过程举例
@ MOV SP, #0x40000020
@ MAIN:
@ MOV R1, #3
@ MOV R2, #5
@ BL FUNC1
@ ADD R3, R1, R2
@ B STOP
@ FUNC1:
@ STMFD SP!, {R1,R2,LR}
@ MOV R1, #10
@ MOV R2, #20
@ BL FUNC2
@ SUB R3, R2, R1
@ LDMFD SP!, {R1,R2,LR}
@ MOV PC, LR
@ FUNC2:
@ STMFD SP!, {R1,R2}
@ MOV R1, #7
@ MOV R2, #8
@ MUL R3, R1, R2
@ LDMFD SP!, {R1,R2}
@ MOV PC, LR执行叶子函数时不需要对LR压栈保护,执行非叶子函数时需要对LR压栈保护
练习:
1.以下代码为使用汇编语言模拟C语言叶子函数的调用过程,按照如下要求补全代码
注:使用满减栈
MOV SP, #0x40000020
MIAN:
MOV R1, #3
MOV R2, #5
@调用FUNC子程序
1______________ BL FUNC
ADD R3, R1, R2
B STOP
FUNC:
@压栈保护现场
2______________ STMFD SP!, {R1,R2}
MOV R1, #10
MOV R2, #20
SUB R3, R2, R1
@出栈恢复现场
3______________ LDMFD SP!, {R1,R2}
MOV PC, LR
STOP:
B STOP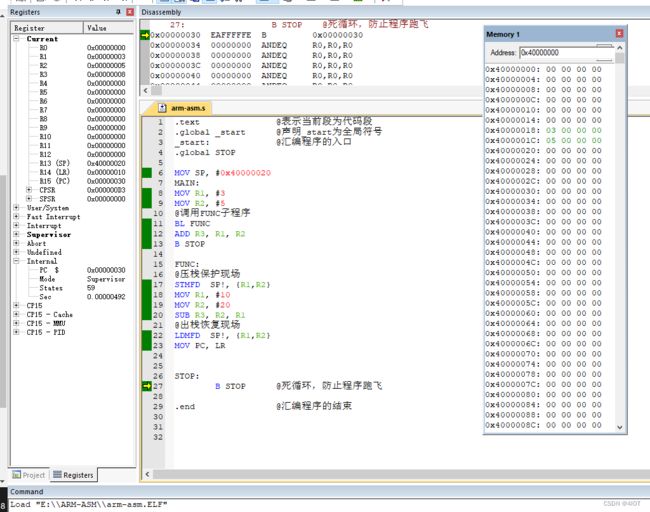
1.5 状态寄存器传送指令:访问(读写)CPSR寄存器
一般用于操作系统内部,上电后处于SVC模式时初始化系统,权限较高,可以使用,后面切换成USER模式。
Linux内部调用,也会用到状态寄存器的改写。
读写特有的指令,防止误操作,不让其他指令随意能操作CPSR寄存器。
@ 读CPSR
@ MRS R1, CPSR
@ R1 = CPSR
@ 写CPSR
@ MSR CPSR, #0x10
@ CPSR = 0x10
@ 在USER模式下不能随意修改CPSR,因为USER模式属于非特权模式
@ MSR CPSR, #0xD31.6 软中断指令:触发软中断
回顾






.text @表示当前段为代码段
.global _start @声明_start为全局符号
_start: @汇编程序的入口
.global STOP
MAIN:
MOV SP, #0x40000020
@ 初始化SVC模式下的栈指针
MSR CPSR, #0x10
@ 切换成USER模式,开启FIQ、IRQ
MOV R1, #1
MOV R2, #2
SWI #1
@ 触发软中断异常
ADD R3, R2, R1
B STOP
STOP:
B STOP @死循环,防止程序跑飞
.end @汇编程序的结束验证分析:
上电后CPSR的值为0x13,说明时SVC模式
执行完MSR CPSR, #0x10,切换成了USER模式
执行完SWI,CPSR拷贝到了SPSR
修改了CPSR的值,禁止IRQ置位
进入SVC模式
修改状态位进入ARM模式
保存返回地址到LR

 思考:什么进入SWI后,会跳转到MOC R1, #1?
思考:什么进入SWI后,会跳转到MOC R1, #1?
因为进入异常后会跳转到异常向量表,对应SWI的地址是0x08,刚好是MOV R1, #1的地址。
我们这段代码有问题,用掉了0x0-0x31异常向量表。
所以修改后代码
@ 异常向量表
B MAIN
B .
B SWI_HANDLER
B .
B .
B .
B .
B .
@ 应用程序
MAIN:
MOV SP, #0x40000020
@ 初始化SVC模式下的栈指针,不能挪到第二句,否则初始化的是USER模式下,R13是专用
MSR CPSR, #0x10
@ 切换成USER模式,开启FIQ、IRQ
MOV R1, #1
MOV R2, #2
SWI #1
@ 触发软中断异常
ADD R3, R2, R1
B STOP
@ 异常处理程序
SWI_HANDLER:
STMFD SP!,{R1,R2,LR}
@ 压栈保护现场
MOV R1, #10
MOV R2, #20
SUB R3, R2, R1
LDMFD SP!,{R1,R2,PC}^
@ 出栈恢复现场
@ 将压入到栈中的LR(返回地址)出栈给PC,实现程序的返回
@ ‘^’表示出栈的同时将SPSR的值传递给CPSR,实现CPU状态的恢复
STOP:
B STOP @死循环,防止程序跑飞 注意:MOV SP, #0x40000020不能挪到第二句,否则初始化的是USER模式下,R13是专用
恢复注意:
CPSR恢复
LR 恢复给PC(LR出栈给了PC)
LDMFD SP!,{R1,R2,PC}^
@ 出栈恢复现场
@ 将压入到栈中的LR(返回地址)出栈给PC,实现程序的返回
@ ‘^’表示出栈的同时将SPSR的值传递给CPSR,实现CPU状态的恢复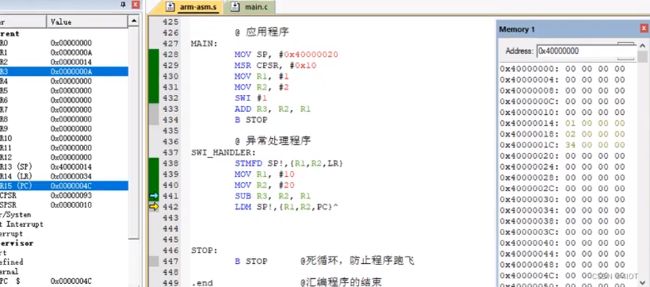
软中断对应C语言没有语句,后续用得比较多的是IRQ
1.7 协处理器指令:操控协处理器的指令
后面主要接触到:
FPU,浮点型
CP15,帮助ARM对存储器进行管理,高速缓存,异常向量表,控制MMU(管理物理地址和
虚拟地址映射关系)
主要需要知道3类协处理器指令:
@ 1.协处理器数据运算指令
@ CDP
@ 2.协处理器存储器访问指令
@ STC 将协处理器中的数据写入到存储器
@ LDC 将存储器中的数据读取到协处理器
@ 3.协处理器寄存器传送指令
@ MRC 将协处理器中寄存器中的数据传送到ARM处理器中的寄存器
@ MCR 将ARM处理器中寄存器中的数据传送到协处理器中的寄存器2 伪指令:本身不是指令,编译器可以将其替换成若干条等效指令
@ 空指令
NOP
@ 指令
LDR R1, [R2]
@ 将R2指向的内存空间中的数据读取到R1寄存器
@ 伪指令
LDR R1, =0x12345678
@ R1 = 0x12345678
@ LDR伪指令可以将任意一个32位的数据放到一个寄存器
LDR R1, =STOP
@ 将STOP表示的地址写入R1寄存器
LDR R1, STOP
@ 将STOP地址中的内容写入R1寄存器

练习:
1.编程实现通过状态寄存器传送指令,将ARM处理器的模式修改成USER模式并将FIQ与IRQ使能
MSR CPSR, #0x102.简述伪指令和指令的本质区别是什么
指令 能够编译生成一条32bit机器码,并且能被CPU识别和执行
伪指令 本身不是指令,编译器可以将其替换成若千千条指令