分布式键值存储ETCD
分布式键值存储
- 前言
- 实现分布式系统的目标以及挑战
- 分布式ETCD存储
-
- etcd介绍
- 基于etcd的使用场景
-
- 1、键值对存储
- 2、服务注册与发现
- 3、消息发布与订阅
- 4、分布式锁
- etcd相关术语(关键字解释)
-
- 那么为什么节点数要设置成奇数为上上策???
- 安装部署ETCD(以centos7为例)
- 详细介绍ETCD的各组件的配置
- golang 使用etcd(mac11.4+go1.17)
-
- etcd实现分布式锁
前言
前面的文章有介绍过实现分布式系统所使用的几个算法,这次来学习分布式的落地应用
- 那么什么是分布式系统
业务量的迅速增大,普通的单机系统无法满足要求,要么垂直扩展升级机器硬件,要么水平扩展堆廉价服务器。目前互联网领域选择了后者 水平扩展
- 分布式和集群的区别
**分布式(distributed): 在多台不同的服务器中部署不同的服务模块,通过远程调用协同工作,对外提供服务 **
集群(cluster): 在多台不同的服务器中部署相同的应用和服务模块,通过负载均衡设备对外提供服务
实现分布式系统的目标以及挑战
- 设计目标
1、可用性:可用性是分布式系统的核心诉求,其用于衡量一个分布式系统对外提供服务的能力
2、可扩展性:增加机器后不会改变或极少改变系统行为,并且能获得近似线性的性能提升
3、容错性:系统发生错误时,具有对错误规避及从错误中恢复的能力
4、对外服务的延迟响应和 吞吐率要能满足用户需求
- 挑战(需要解决的问题)
1、节点通讯问题-----》大部分采用rpc
2、分布式数据一致问题
3、节点错误恢复能力
4、同步调用使系统变得不具备扩展性
分布式ETCD存储
说到ETCD,那么不得不说说zookeeper和etcd的关系,他们都是分布式协调系统,zookeeper起源于Hadoop生态系统,比较成熟健壮,起步比较早;而etcd算是后起之秀,主要是容器编排技术kurbernetes后台支撑
- 为什么不使用Zookeeper
1、zookeeper的部署和维护比较困难,管理员需要掌握一系列的知识和技能。而zookeeper使用Paxos的强一致性算法也是复杂难懂;并且zookeeper的使用也比较复杂。
2、zookeeper是由java编写,java偏向重型应用,会引入大量的依赖。这可能会导致运维复杂
- etcd的优势
1、etcd更加稳定可靠,他的唯一目标就是把分布式一致性键值存储做到极致,其更注重稳定性和扩展性
2、在服务发现的实现上,etcd使用的是节点租约(Lease),并且Group(多key);而zookeeper使用的是临时节点,临时节点存在不少问题。
3、etcd支持MVCC多版本并发控制
etcd介绍
1、etcd是CoreOS基于Raft开发的分布式key-value存储,可用于服务发现、共享配置以及一致性保障(如数据库选注、分布式锁等)
2、etcd是一个go语言编写的分布式、高可用的一致性键值存储系统
3、etcd基于Raft协议,通过日志复制的方式来保证数据的强一致性
4、etcd默认数据一经更新就落盘持久化,数据持久化存储使用WAL(write ahead log,预写式日志)格式。WAL记录了数据变化的全过程,在etcd中所有数据在提交之前都要先写入WAL中;etcd的snapshot(快照)文件存储了某一时刻etcd的所有数据,默认设置为每10000条记录做一次快照,经过快照后WAL文件即可删除
5、etcd具有一定的容错能力,假设集群有n个节点,即便集群中(n-1)/2个节点发生了故障,只要剩下的(n+1)/2个节点达成一致,也能操作成功。因此,他能有效的应对网络分区和机器故障带来的数据丢失风险
在分布式系统中,如何管理节间的状态一直是个难题,etcd像是专门为集群环境的服务发现和注册而设计,他提供了数据TTL失效、数据改变监视、多值、目录监听、分布式锁原子操作等功能,可以方便的跟踪管理集群节点的状态
这里分享一个Raft算法的动图演示,助于理解Raft Raft算法的动画演示,你值得拥有
-
etcd包含了如下特性
- 键值对存储:将数据存储在分层组织的目录中,如同在标准文件系统中
- 监测变更:监测特定的键或目录以进行更改,并对值的更改做出反应
- 简单:curl可访问的用户的API(HTTP+JSON)
- 安全:可选的SSL客户端证书认证
- 快速:单实例每秒1000次写操作,2000+次读操作
- 可靠:使用Raft算法保证一致性
-
包含的主要功能
- 基本的key-value存储
- 监听机制
- key的过期及续约机制,用于监控和服务发现
- 原子Compare And Swap和Compare And Delete,用与分布式锁和leader选举
-
etcd的使用场景
- 也可以用于键值对存储,应用程序可以读取和写入etcd中的数据
- etcd比较多的应用场景式用于服务注册和发现
- 基于监听机制的分布式异步系统
-
etcd(server)大体上可以分为以下几个部分
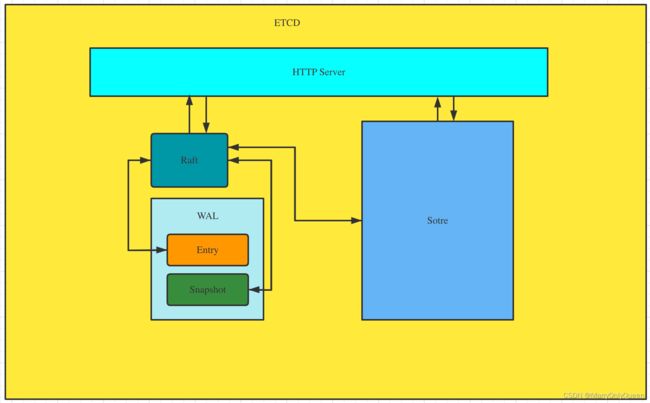
- HTTP Server: 提供翁落数据读写功能,监听服务端口;用于处理用户发送的API请求。以及其他etcd节点的数据同步和心跳信息请求
- Raft:Raft强一致性算法的具体实现,etcd的核心
- Store:用于处理etcd支持的各类功能的事务,包括数据索引、节点状态变更、监控与反馈、时间处理与执行等等,是etcd对用户提供的大多数API功能的具体实现
- WAL:Write Ahead Log (预写式日志),是etcd的数据存储方式。除了在内存中存有所有数据的状态以及节点的索引以外,etcd就通过WAL进行持久化存储。WAL中,所有数据提交前都会实现记录日志。Snapshot是为了防止数据过多而进行的状态快照;Entry表示存储的具体日志内容
通常,一个用户的请求发送过来,会经由HTTP Server转发给Store进行具体的事务处理。如果涉及到节点的修改,则交给Raft模块进行 仲裁和日志记录 ,然后再同步给别的etcd节点以确认数据提交,只有当半数以上的节点确认了该节点状态修改之后,才会真正进行数据的提交(持久化),然后再次同步。
各个节点在任何时候都可能变成Leader、Follower、Candidate等角色,同时为了减少创建连接开销,etcd节点在启动之初就会创建并维持与集群其他节点之间的连接
- 那么用户会从那个节点读写数据呢???
为了保证数据的强一致性,etcd集群中所有的数据流向都是一个方向,从Leader节点流向Follower,也就是Follower的数据必须与Leader一致,如果不一致会被覆盖。简单点说,用户可以对etcd集群中的所有节点进行读写。首先读取非常简单,因为每个节点保存的数据是强一致的。对于写入来说,etcd集群中的节点会选举Leader节点,如果写入请求来自Leader节点,则可以直接写入,然后Leader会把写入分发给所有Follower;如果写请求来自其他Follower节点,那么写入请求会转发给Leader节点,有Leader节点写入之后再分发给集群中的所有节点
基于etcd的使用场景
1、键值对存储
etcd是一个键值存储的组件,其他的应用都是基于其键值存储的功能展开的
- 采用kv型数据存储,一般情况下比关系数据库快
- 支持动态存储(内存)以及静态存储
- 分布式存储,可集成为多节点集群
- 存储方式,采用类似目录结构。(B+数据)
- 只有叶子节点才能真正存储数据,相当于文件
- 叶子节点的父节点一定是目录,目录不能存储数据
2、服务注册与发现
服务发现(server discovery)要解决的是分布式系统常见的问题之一,即在同一个分布式集群中的进程或者服务如何才能找到对方并建立连接。
从本质上说,服务发现就是要了解集群中是否有进程在监听UDP或者TCP端口,并且通过名字就可以进行查找和连接。要解决服务发现的问题,需要具备如下条件:
- 1、需要一个强一致性、高可用的服务存储目录,而基于Raft算法的etcd天生就是一个这样的 强一致性、高可用的服务存储目录
2、可以对服务进行注册,并且还能监控服务的健康状态;用户可以在etcd中注册服务,并且对注册的服务配置key TTL,定时保持服务的心跳以达到监控健康状态的效果
3、具备查找和连接服务的机制,在etcd指定的主题下注册的服务也能在对应的主题下找到;为了却确保连接,我们可以在各个服务器上都部署一个代理模式的etcd,这样就可以确保访问etcd集群的服务都可以相互连接
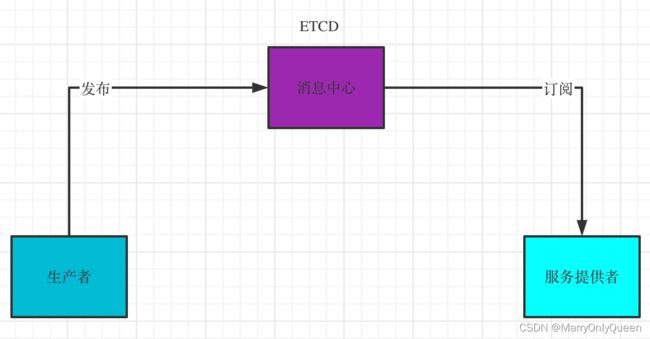
逻辑关系图如下:

可以看到我们的ETCD就是在充当注册中心,协调各个服务;图解:如果服务消费者需要使用服务提供者提供的服务,那么势必需要先去注册中心访问,注册中心会讲服务提供者的信息返还给服务消费者,供服务消费者使用
3、消息发布与订阅
在分布式系统中,最适用的一种组件间通信方式就是消息发布与订阅。那具体的的做法就是 构建一个配置共享中心,数据提供者在这个配置中心发布消息,而消息使用者则订阅他们关心的主题,一旦主题有消息发布,就会实时通知订阅者;通过这种方式可以做到分布式系统配置的集中式管理和动态更新。
- etcd管理配置信息
这类场景的使用方式通常是,应用在启动的时候主动从etcd获取一次配置信息,同时在etcd节点上注册Watcher并等待,以后每次配置有更新的时候,etcd都会实时通知订阅者,以此达到获取最新配置信息的目的
- 分布式日志收集系统
这个系统的核心工作就是收集分布在不同机器上的日志。收集器通常按照应用(或者主题)来分配收集任务单元,因此可以在etcd上创建一个以应用(或主题)为名字的目录,并将这个应用(或主题)相关的所有机器IP以子目录的形式存储在目录下,然后设置一个递归的etcd Watcher,递归式的监控应用(或主题)目录下所有信息的变动,这样就能实现在机器IP(消息)发生变动时,系统能实时接收收集器调整的任务分配
4、分布式锁
因为etcd使用Raft算法保持了数据的强一致性,操作之后存储到集群中的值就必然是全局一致的,所以etcd很容易实现分布式锁
而锁服务包含两种使用方式:保持独占和控制时序
- 1、保持独占
即所有试图获取锁的用户最终只有一个可以得到
etcd为此提供了一套实现分布式锁原子操作CAS(compare and swap)的API,通过设置prevExist,可以保证多个节点上同时创建某个目录时,只有一个节点能够成功,而成功的那个即可获得分布式锁。
核心实现:TTL & CAS
TTL(time to live)指的是给一个key设置一个有效期,到期后这个key就会被自动删除掉,这在很多分布式锁的实现上都会用到,可以避免死锁,保证锁的实时有效性。是不是似曾相识,因为redis里也这么设置的
Atomic Compare-and-Swap(CAS)指的是对key进行赋值的时候,客户端需要提供一些条件,当这些条件妈祖后,才能赋值成功。这些条件包括:
- prevExist:key当前赋值前是否存在
- prevValue:key当前赋值前的值
- prevIndex:key当前赋值的Index
这样的话,key的设置是有前提的,需要知道这个key当前的具体情况才可以对其设置
- 2、控制时序
试图获取锁的所有用户都会进入等待队列,获取锁的顺序是全剧唯一的,同时还能决定队列的执行顺序。
etcd为此提供了一套API(自动创建有序键),他会将一个目录的键值指定为POST动作,这样etcd就会在目录下生成一个当前最大的值作为键,并存储这个新的值(客户端编号);同时还可以使用API按顺序列出所有目录下的键值,此时这些键的值就是客户端的时序,而这些键中存储的值则可以是代表客户端的在编号。
但是etcd也是有缺点的:etcd有v2和v3两个版本,现在推荐使用v3。但是相对于etcd v2,v3版本的接口是通过grpc提供rpc接口,放弃了v2版本的HTTP接口,虽然这种改变可以明显提升连接效率,但是使用便利性不如v2,特别是不利于维护长连接的应用场景。此外,etcd的定位是通用的一致性KV存储,但是在面向服务注册与发现的场景中,过于广泛的通用性会是的每个应用的服务注册都有自己的元数据格式,不利于互相整合,受限于元数据格式的兼容性问题,也不利于实现更高级别的功能
etcd相关术语(关键字解释)
- Raft:etcd所采用的保证分布式系统强一致性的算法
- Node:一个Raft状态机实例
- Member:一个etcd实例,他管理着一个Node,并且可以为客户端请求提供服务
- Cluster:由多个Member构成的,遵循Raft一致性协议的etcd集群
- Peer:对同一个etcd集群中另外一个Member的叫法
- Client:凡是连接etcd服务器请求服务的,比如获取key-value、写数据,都统称为Client;所以etcd命令行连接工具、编写的连接etcd服务的代码对应的进程都是Client
- Proposal:一个需要经过Raft一致性协议的请求,例如写请求或配置更新请求
- Quorum:Raft协议需要的、能够修改集群状态的、活跃的集群成员数量称为Quarum(法定人数),通俗地讲就是etcd集群成员的半数以上。etcd使用仲裁机制,若集群中存在n个节点,那么集群中(n+1)/2个节点达成一致,则操作成功。建议的最优节点数3,5,7,9等奇数个,大多数用户场景中,一个包含7个节点的集群是足够的。更多的节点比如9,11等可以最大限度保证数据安全,但是写性能会受影响,因为需要向更多集群写入数据
- WAL:预写式日志,etcd用于持久化存储的日志格式
- Snapshot:etcd集群在某一节点的快照(备份),etcd为防止WAL文件过多而设置的快照,用于存储etcd的数据状态
- Candidate:Follower超过一定的时间还接受不到Leader的心跳时,会转变为Candidate开始竞选
- Term:某个节点称为Leader到下一次竞选的时间,称为一个Term
- Index:WAL日志数据项编号,Raft中通过Term和Index来定位数据
- Key:键
- Key space:键空间,etcd集群内所有键的集合
- Revision:etcd集群范围内64位的计数器,键空间的每次修改都会导致该计数器的增加
- Modification Revision:一个key最后一次修改的revision
- Lease:一个短时的(会过期),可续订的七月(租约),当他过期时,就会删除与之关联的所有键
- Transition:事务,一个自动执行的操作集,这个集合可以是一个key、也可以是在一个字典区间,例如(a,b],或者是大于某个key的所有key
- Endpoint:指向etcd服务或资源的URL
- Compaction:etcd的压缩(Compaction)操作,丢弃所有的etcd的历史数据请求取代一个给定revision之前的所有key;压缩操作通常用于重新声明etcd后端数据库的存储空间;其与Raft的日志压缩是一个原理
- key vision:键版本,即一个键从创建开始的写(修改)次数,从1开始;一个不存在或已删除的键版本是0,注意key vision和revison的概念不同
那么为什么节点数要设置成奇数为上上策???
我们都知道,Raft算法是强领导共识算法,是实现集群一致性的过程,集群之中有且只能有一个Leader才能保证整个集群一致性。那么问题来了:如果会不会因为一些原因导致集群出现两个或者以上的Leader???还用想吗?提出此问题肯定是会的呀。。
1、问题引入:(脑裂)
那么为什么会出现上述原因呢??
因为在一个分布式集群中,只允许一个leader协调工作,但是由于实际存在 网络原因或其他原因,导致了一个集群分成了两个集群,产生了两个leader同时工作,违背了Raft算法的设计,此时集群不再具备对写一致性,这种现象我们称之为脑裂。
大多数集群选举的规则都是:要求当前集群 的可用节点数 > 总节点数/2,如如果出现网络分区,集群中最多也只能出现一个子集群可以提供服务的情况,即能满足可用节点数 > 总节点数/2的子集群最多只会有一个
- 比如:集群有5个节点,发生了脑裂,称为AB两个集群,那么就会出现两种分区情况
- 1、A:1个节点,B:4个节点
- 2、A:2个节点,B:3个节点
- 那么总会有一个小集群满足 可用节点数 > 总节点数/2 能选举leader,保持集群可用,只不过有一些节点失效了
- 再比如:集群有4个节点,发生了脑裂,称为AB两个集群,那么就会出现两种分区情况
- 1、A:1个节点,B:3个节点
- 2、A:2个节点,B:2个节点
- 那么第二中情况不满足 可用节点数 > 总节点数/2 能选举leader,保持集群可用,那么集群就彻底不可用了
2、提供更强的容错能力,节省资源
在容错能力相同的情况下,奇数节点更节省资源
leader选举要求:可用节点数量 > 总节点数量/2
(1)、假如集群中有3个节点,3/2=1.5,集群正常对外提供服务(即leader选举成功),至少需要两个节点。换句话说,3节点集群允许 一个节点宕机
(2)、假如集群中有4个节点,4/2=2,集群正常对外提供服务(即leader选举成功),至少需要3个节点。换句话说,4节点集群也允许 一个节点宕机
那么从这里看出,集群1和集群2都有允许一个节点宕机的能力,但是集群2比集群1多一个节点,那么相同容错能力的情况下,从资源节省的角度出发,是不是奇数个比较好呢。嘻嘻嘻
安装部署ETCD(以centos7为例)
- 1、安装etcd
yum -y install etcd
如果yum有问题,请自行解决。嘻嘻嘻
[root@VM-24-12-centos ~]# etcd --version
etcd Version: 3.3.11
Git SHA: 2cf9e51
Go Version: go1.10.3
Go OS/Arch: linux/amd64
- etcd的配置文件
#[Member]
#ETCD_CORS=""
ETCD_DATA_DIR="/var/lib/etcd/default.etcd" # etcd的数据存储目录
#ETCD_WAL_DIR=""
#ETCD_LISTEN_PEER_URLS="http://localhost:2380" # 和其他节点通讯使用的地址列表,相当于与此节点通讯的地址;当然也可以是多个地址,使用逗号隔开即可,地址格式为scheme://IP:PORT,scheme可以为http、https,但不可以使用域名
ETCD_LISTEN_CLIENT_URLS="http://localhost:2379" # 和ETCD_LISTEN_PEER_URLS类似,但是它是针对客户端的,也就是对外提供服务的地址
#ETCD_MAX_SNAPSHOTS="5"
#ETCD_MAX_WALS="5"
ETCD_NAME="default" #etcd节点名称
#ETCD_SNAPSHOT_COUNT="100000" # etcd多少次的事务将会出发一次快照
#ETCD_HEARTBEAT_INTERVAL="100" # etcd节点之间心跳传输的时间间隔,单位是毫秒
#ETCD_ELECTION_TIMEOUT="1000" #该节点参与选举的最大超时时间,单位毫秒
#ETCD_QUOTA_BACKEND_BYTES="0"
#ETCD_MAX_REQUEST_BYTES="1572864"
#ETCD_GRPC_KEEPALIVE_MIN_TIME="5s"
#ETCD_GRPC_KEEPALIVE_INTERVAL="2h0m0s"
#ETCD_GRPC_KEEPALIVE_TIMEOUT="20s"
#
#[Clustering]
#ETCD_INITIAL_ADVERTISE_PEER_URLS="http://localhost:2380" #该成员节点在整个集群中的通讯地址列表,这个地址用来传输集群数据的地址,因此这个地址必须可以连接集群中的所有成员
ETCD_ADVERTISE_CLIENT_URLS="http://localhost:2379" # 列出这个成员的客户端URL,通告给集群中的其他成员。这些 URL 可以包含域名。
#ETCD_DISCOVERY=""
#ETCD_DISCOVERY_FALLBACK="proxy"
#ETCD_DISCOVERY_PROXY=""
#ETCD_DISCOVERY_SRV=""
#ETCD_INITIAL_CLUSTER="default=http://localhost:2380" #配置集群内部所有成员的地址,其格式为ETCD_NAME=ETCD_INITIAL_ADVERTISE_PEER_URLS,如果有多个使用逗号隔开
#ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
#ETCD_INITIAL_CLUSTER_STATE="new"
#ETCD_STRICT_RECONFIG_CHECK="true"
#ETCD_ENABLE_V2="true"
#
#[Proxy]
#ETCD_PROXY="off"
#ETCD_PROXY_FAILURE_WAIT="5000"
#ETCD_PROXY_REFRESH_INTERVAL="30000"
#ETCD_PROXY_DIAL_TIMEOUT="1000"
#ETCD_PROXY_WRITE_TIMEOUT="5000"
#ETCD_PROXY_READ_TIMEOUT="0"
#
#[Security]
#ETCD_CERT_FILE=""
#ETCD_KEY_FILE=""
#ETCD_CLIENT_CERT_AUTH="false"
#ETCD_TRUSTED_CA_FILE=""
#ETCD_AUTO_TLS="false"
#ETCD_PEER_CERT_FILE=""
#ETCD_PEER_KEY_FILE=""
#ETCD_PEER_CLIENT_CERT_AUTH="false"
#ETCD_PEER_TRUSTED_CA_FILE=""
#ETCD_PEER_AUTO_TLS="false"
#
#[Logging]
#ETCD_DEBUG="false"
#ETCD_LOG_PACKAGE_LEVELS=""
#ETCD_LOG_OUTPUT="default"
#
#[Unsafe]
#ETCD_FORCE_NEW_CLUSTER="false"
#
#[Version]
#ETCD_VERSION="false"
#ETCD_AUTO_COMPACTION_RETENTION="0"
#
#[Profiling]
#ETCD_ENABLE_PPROF="false"
#ETCD_METRICS="basic"
#
#[Auth]
#ETCD_AUTH_TOKEN="simple"
- 3、接下来配置我们自己的etcd集群(三个节点)
-
第一个节点madara
# 该etcd节点的名称 ETCD_NAME=madara # etcd数据的存储目录,直接采用默认的 ETCD_DATA_DIR="/var/lib/etcd/default.etcd" # 节点之间通讯默认使用2380端口,当然也可以使用别的;ip写为0.0.0.0 ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380" # 客户端来访问的话,端口默认使用2379,IP写成0.0.0.0 ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379" # 成员传输数据地址列表。此处的所在节点即可,ip需要写为对外ip ETCD_INITIAL_ADVERTISE_PEER_URLS="http://47.94.174.89:2380" # 所有节点地址 ETCD_INITIAL_CLUSTER="madara=http://47.93.174.89:2380,cristy=http://47.93.175.99:2380,slut=http://47.94.194.39:2380" # 列出这个成员的客户端URL,通告给集群中的其他成员。这些 URL 可以包含域名。 ETCD_ADVERTISE_CLIENT_URLS="http://0.0.0.0:2379" -
第二个节点cristy
# 该etcd节点的名称 ETCD_NAME=cristy # etcd数据的存储目录,直接采用默认的 ETCD_DATA_DIR="/var/lib/etcd/default.etcd" # 节点之间通讯默认使用2380端口,当然也可以使用别的;ip写为0.0.0.0 ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380" # 客户端来访问的话,端口默认使用2379,IP写成0.0.0.0 ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379" # 成员传输数据地址列表。此处的所在节点即可,ip需要写为对外ip ETCD_INITIAL_ADVERTISE_PEER_URLS="http://47.93.175.99:2380" # 所有节点地址 ETCD_INITIAL_CLUSTER="madara=http://47.93.174.89:2380,cristy=http://47.93.175.99:2380,slut=http://47.94.194.39:2380" # 列出这个成员的客户端URL,通告给集群中的其他成员。这些 URL 可以包含域名。 ETCD_ADVERTISE_CLIENT_URLS="http://0.0.0.0:2379" -
第三个节点slut
# 该etcd节点的名称 ETCD_NAME=slut # etcd数据的存储目录,直接采用默认的 ETCD_DATA_DIR="/var/lib/etcd/default.etcd" # 节点之间通讯默认使用2380端口,当然也可以使用别的;ip写为0.0.0.0 ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380" # 客户端来访问的话,端口默认使用2379,IP写成0.0.0.0 ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379" # 成员传输数据地址列表。此处的所在节点即可,ip需要写为对外ip ETCD_INITIAL_ADVERTISE_PEER_URLS="http://47.94.194.39:2380" # 所有节点地址 ETCD_INITIAL_CLUSTER="madara=http://47.93.174.89:2380,cristy=http://47.93.175.99:2380,slut=http://47.94.194.39:2380" # 列出这个成员的客户端URL,通告给集群中的其他成员。这些 URL 可以包含域名。 ETCD_ADVERTISE_CLIENT_URLS="http://0.0.0.0:2379"
-
那么至此集群节点配置完毕
然后启动etcd
[root@VM-24-12-centos etcd]# systemctl start etcd
[root@VM-24-12-centos etcd]# etcdctl member list
5e87c6aea46f2c98: name=slut peerURLs=http://47.94.194.39:2380 clientURLs=http://0.0.0.0:2379 isLeader=true
1287c6ae908f2c65: name=cristy peerURLs=http://47.93.175.99:2380 clientURLs=http://0.0.0.0:2379 isLeader=false
2e87c689i46f2c5r: name=madara peerURLs=http://47.93.174.89:2380 clientURLs=http://0.0.0.0:2379 isLeader=false
可以看到我们的etcd集群已经正常启动了,而且leader节点是slut
详细介绍ETCD的各组件的配置
- member
- clustering
- Security
- 其他相关参数
golang 使用etcd(mac11.4+go1.17)
安装etcd v3
go get go.etcd.io/etcd/client/v3
报错:
go.etcd.io/etcd/clientv3 tested by
go.etcd.io/etcd/clientv3.test imports
github.com/coreos/etcd/auth imports
github.com/coreos/etcd/mvcc/backend imports
github.com/coreos/bbolt: github.com/coreos/[email protected]: parsing go.mod:
module declares its path as: go.etcd.io/bbolt
but was required as: github.com/coreos/bbolt
安装的时候总是由于grpc版本和bbolt的原因安装不上,找到一个解决方案:
go mod init
go mod edit -replace github.com/coreos/[email protected]=go.etcd.io/[email protected]
go mod edit -replace google.golang.org/[email protected]=google.golang.org/[email protected]
go mod tidy
replace google.golang.org/grpc => google.golang.org/grpc v1.26.0
# 然后就莫名其妙好了。。 真心吐槽go的依赖管理
etcd实现分布式锁
etcd通过以下特性来实现分布式锁
- lease租约机制
租约机制(TTL, time to live),etcd可以为存储的key-value设置租约,当租约到期,key-value将失效删除;同时支持续约,以避免key-value过期失效。lease机制保证了锁的安全性,即使锁不能主动释放,也会因为租约而到期自动释放
- revision机制
每个key都带有一个Revision号,每进行一次事务便+1,他是全局唯一的,通过其大小可知道写操作的顺序。在实现分布式锁时,多个客户端同时抢锁,根据Revision版本号大小依次获得锁,避免"惊群(羊群)效应",实现公平锁。这和zookeeper的临时顺序节点+监听机制可变面羊群效应是一致的。"
- prefix机制
前缀机制。例如:一个名为/etcd/lock的锁,两个客户端争抢进行写操作,实际写入key分别为"/etcd/lock/uuid1"和"/etcd/lock/uuid2"。uuid表示全局唯一id,确保key的唯一性。写操作都会成功,但是返回的revision不一样,那么通过前缀/etcd/lock查询,返回包含两个key-value的列表,同时包含他们的revision,客户端可判断是否获得锁
- Watch机制
监听机制。watch机制支持watch某个固定的key,也支持一个范围(前缀机制)。当监听的key或者范围发生变化时,客户端将收到通知;在实现分布式锁时,如果抢锁失败,可通过prefix机制返回的key-value聊表获得revision比自己小且相差最小的key(称为pre-key),对pre-key进行监听,因为只有它释放锁,自己才能获得锁,如果watch到pre-key的delete事件,说明pre-key已经释放,自己将持有锁。
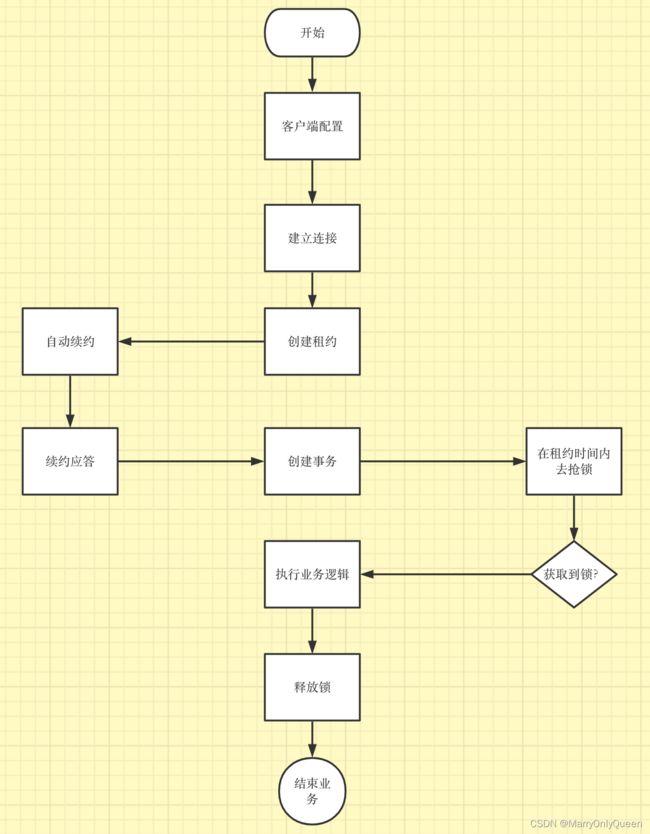
- 实现方式一
package main
import (
"context"
"fmt"
"time"
"github.com/coreos/etcd/clientv3"
)
func main() {
config := clientv3.Config{
Endpoints: []string{"127.0.0.1:2379"}, // 集群列表
DialTimeout: 5 * time.Second,
}
// 建立一个客户端
client, err := clientv3.New(config)
if err != nil {
fmt.Println(err)
return
}
// lease实现锁自动过期:
// op操作
// txn事务: if else then
// 1, 上锁 (创建租约, 自动续租, 拿着租约去抢占一个key)
lease := clientv3.NewLease(client)
// 申请一个5秒的租约
leaseGrantResp, err := lease.Grant(context.TODO(), 5)
if err != nil {
fmt.Println(err)
return
}
// 拿到租约的ID
leaseId := leaseGrantResp.ID
// 准备一个用于取消自动续租的context
ctx, cancelFunc := context.WithCancel(context.TODO())
// 确保函数退出后, 自动续租会停止
defer cancelFunc()
defer lease.Revoke(context.TODO(), leaseId)
// 5秒后会取消自动续租
keepRespChan, err := lease.KeepAlive(ctx, leaseId)
if err != nil {
fmt.Println(err)
return
}
// 处理续约应答的协程
go func() {
for {
select {
case keepResp := <-keepRespChan:
if keepResp == nil {
fmt.Println("租约已经失效了")
goto END
} else { // 每秒会续租一次, 所以就会受到一次应答
fmt.Println("收到自动续租应答:", keepResp.ID)
leaseResponse, err := lease.TimeToLive(ctx, leaseId)
if err != nil{
fmt.Printf("获取租约信息失败 %s\n", err)
}
fmt.Printf("获取租约信息成功 TL %d\n", leaseResponse.TTL)
}
}
}
END:
}()
// if 不存在key, then 设置它, else 抢锁失败
kv := clientv3.NewKV(client)
// 创建事务
txn := kv.Txn(context.TODO())
// 定义事务
// 如果key不存在
txn.If(clientv3.Compare(clientv3.CreateRevision("/demo/A/B1"), "=", 0)).
Then(clientv3.OpPut("/demo/A/B1", "xxx", clientv3.WithLease(leaseId))).
Else(clientv3.OpGet("/demo/A/B1")) // 否则抢锁失败
// 提交事务
txnResp, err := txn.Commit()
if err != nil {
fmt.Println(err)
return // 没有问题
}
// 判断是否抢到了锁
if !txnResp.Succeeded {
fmt.Println("锁被占用:", string(
txnResp.Responses[0].GetResponseRange().Kvs[0].Value))
return
}
// 2, 处理业务
fmt.Println("处理任务")
time.Sleep(20 * time.Second)
// 3, 释放锁(取消自动续租, 释放租约)
// defer 会把租约释放掉, 关联的KV就被删除了
}
- 实现方式二
其实etcd已经帮助我们实现了分布式锁,我们只需要调用相关的API即可
package main
import (
"context"
"fmt"
"github.com/coreos/etcd/clientv3"
"github.com/coreos/etcd/clientv3/concurrency"
"log"
"os"
"os/signal"
"time"
)
func main() {
c := make(chan os.Signal)
signal.Notify(c)
// 实例一个客户端
cli, err := clientv3.New(clientv3.Config{
Endpoints: []string{"localhost:2379"},
DialTimeout: 5 * time.Second,
})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
prefix := "/lock"
go func() {
session, err := concurrency.NewSession(cli)
if err != nil {
log.Fatal(err)
}
// 以/lock为前缀声明实例一把锁
m := concurrency.NewMutex(session, prefix)
// 那么此处就是加锁操作。下面会把源码翻出来。其实是和上面自己实现的流程是一样的
if err := m.Lock(context.TODO()); err != nil {
log.Fatal("go1 get mutex failed " + err.Error())
}
fmt.Printf("go1 get mutex sucess\n")
fmt.Println(m)
time.Sleep(time.Duration(10) * time.Second)
m.Unlock(context.TODO())
fmt.Printf("go1 release lock\n")
}()
go func() {
time.Sleep(time.Duration(2) * time.Second)
session, err := concurrency.NewSession(cli)
if err != nil {
log.Fatal(err)
}
m := concurrency.NewMutex(session, prefix)
if err := m.Lock(context.TODO()); err != nil {
log.Fatal("go2 get mutex failed " + err.Error())
}
fmt.Printf("go2 get mutex sucess\n")
fmt.Println(m)
time.Sleep(time.Duration(2) * time.Second)
m.Unlock(context.TODO())
fmt.Printf("go2 release lock\n")
}()
<-c
}
让我们来看看源码是如何实现的
在mutex.go包中。我们看到
type Mutex struct {
s *Session
pfx string
myKey string
myRev int64
hdr *pb.ResponseHeader
}
func NewMutex(s *Session, pfx string) *Mutex {
return &Mutex{s, pfx + "/", "", -1, nil}
}
func (m *Mutex) Lock(ctx context.Context) error {
s := m.s
client := m.s.Client()
// 我们看到key是根据前缀和租约拼接而成的
m.myKey = fmt.Sprintf("%s%x", m.pfx, s.Lease())
// 然后etcd 首先 会判断这个是否已经存在。即锁已经存在,判断方式就是 =0.如果为0则锁不存在
cmp := v3.Compare(v3.CreateRevision(m.myKey), "=", 0)
// put self in lock waiters via myKey; oldest waiter holds lock
// 将key植入锁服务,并设置过期时间
put := v3.OpPut(m.myKey, "", v3.WithLease(s.Lease()))
// reuse key in case this session already holds the lock
// 通过key查询写入是否成功
get := v3.OpGet(m.myKey)
// fetch current holder to complete uncontended path with only one RPC
// 通过前缀和最早的一次key获取锁
getOwner := v3.OpGet(m.pfx, v3.WithFirstCreate()...)
// 如果所存在则开启事务获取锁,获取锁的规则为对比Revision,最小的即最先加锁的获取到锁
resp, err := client.Txn(ctx).If(cmp).Then(put, getOwner).Else(get, getOwner).Commit()
if err != nil {
return err
}
m.myRev = resp.Header.Revision
if !resp.Succeeded {
m.myRev = resp.Responses[0].GetResponseRange().Kvs[0].CreateRevision
}
// if no key on prefix / the minimum rev is key, already hold the lock
// 如果revision最小的key和自己的key相等并且版本号一致那么说明已经获取到了锁,return
ownerKey := resp.Responses[1].GetResponseRange().Kvs
if len(ownerKey) == 0 || ownerKey[0].CreateRevision == m.myRev {
m.hdr = resp.Header
return nil
}
// 如果没有则等待是释放锁,而监控锁是否释放则使用了watch,源码如waitDelete方法
// wait for deletion revisions prior to myKey
hdr, werr := waitDeletes(ctx, client, m.pfx, m.myRev-1)
// release lock key if wait failed
if werr != nil {
m.Unlock(client.Ctx())
} else {
m.hdr = hdr
}
return werr
}
func waitDelete(ctx context.Context, client *v3.Client, key string, rev int64) error {
cctx, cancel := context.WithCancel(ctx)
defer cancel()
var wr v3.WatchResponse
wch := client.Watch(cctx, key, v3.WithRev(rev))
for wr = range wch {
// 这里去监控锁的释放
for _, ev := range wr.Events {
if ev.Type == mvccpb.DELETE {
return nil
}
}
}
if err := wr.Err(); err != nil {
return err
}
if err := ctx.Err(); err != nil {
return err
}
return fmt.Errorf("lost watcher waiting for delete")
}
如果您觉得文章对您有所帮助,可以请囊中羞涩的博主吃个鸡腿饭,万分感谢。愿每一个来到这里的人生活幸福美满。
微信赞赏

支付宝赞赏
