关于git,这一篇git命令汇总解析就够了
目录
Git:
前驱知识:版本控制
1.本地版本控制
2.集中版本控制:
3.分布式版本控制git
Git命令:
Git工作原理(核心):
Git项目搭建:
创建本地仓库的两种方法:.git文件夹
Git:
前驱知识:版本控制
比如说我们在开发的过程当中,肯定避免不了的一个问题就是代码的版本迭代问题,每次迭代都会有新的版本,那么新的版本和老的版本之间如何去进行管理就是Git。
这个就比如说我们在进行不断更新代码的时候,我们仓库当中有很多的代码,这个时候,我们要对任意的版本进行管理,可以随机的切换,更新等等的操作。
目的:
实现跨领域的对人协同开发
最终和记载一个或者多个文件的历史纪录
组织保护源代码
统计工作量
并行开发,提高效率
跟踪记录整个软件的开发过程
减轻开发人员的负担,节省时间,同时降低认为错误
简单点来说就是用于管理多人协同开发项目的工具。
注:多人开发肯定会使用git工具,或者SVN
主流的版本控制器如下:
Git
SVN
CVS
VSS
TFS等
1.本地版本控制
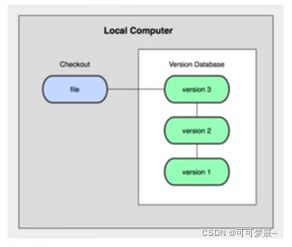
在本地记录文件的每一次的更新,就类似于上边的文档,这种只适合个人的使用,例如上边的文档,对人的话就会很乱。
2.集中版本控制:
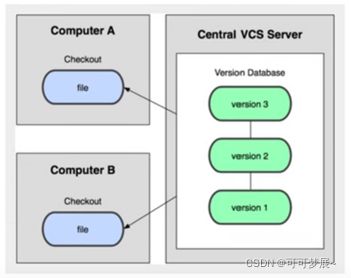
所有版本数据都保存在服务器上,协同开发者从服务器上同步更新或上传自己的修改。
相当于是公司只有一个服务器,同时有多个开发者,每次每个人只需要从服务器上下载一下最新的代码,然后进行今天的工作,工作完了之后在提交上去就ok了,但是这就会出像一个问题,比如说:两个员工同时修改了一个代码中的同一个变量,然后它们再提交的时候,就会产生冲突,因为,代码只有一份都在服务器上,但是员工有好几个,这种是很难解决的问题。或者说服务器挂了,那么所有的代码就完了。可以过一段时间保存一次,备份一次代码。SVN
3.分布式版本控制git
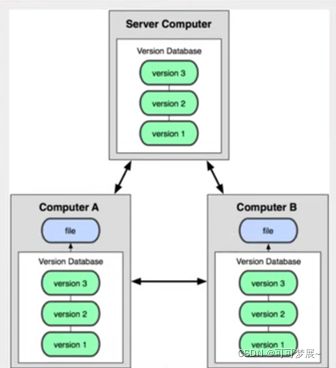
所有的版本都同步到本地的用户,每个人都拥有全部的代码,不需要再去公司的服务器仓库里边去看,缺点存在安全隐患,同时每一个人都有一份最新的备份的话,也会增加了内存的消耗。如果服务器坏了,只需要从任意一个用户手上拷贝一份过去就ok了。
SVN和Git的区别:VSCode
SVN是集中式的版本控制系统,版本是集中放在公司中央服务器上的,而工作的时候,用的都是自己的电脑,所以首先要从中央服务器上得到最新版本,然后完成工作之后,需要把自己干完的活,提交到中央服务器上,集中式版本控制系统必须联网才能使用,对带宽要求比较高。
Git是分布式版本管理系统,没有中央服务器,每个人的电脑是一个完整的版本库,工作不需要联网,因为所有的版本都在自己的电脑上。
Git是目前世界上最先进的分布式版本控制系统。
很多人都知道,Linus在1991年创建了开源的Linux,从此,Linux系统不断发展,已经成为最大的服务器系统软件了。
Linus虽然创建了Linux,但Linux的壮大是靠全世界热心的志愿者参与的,这么多人在世界各地为Linux编写代码,那Linux的代码是如何管理的呢?
事实是,在2002年以前,世界各地的志愿者把源代码文件通过diff的方式发给Linus,然后由Linus本人通过手工方式合并代码!
你也许会想,为什么Linus不把Linux代码放到版本控制系统里呢?不是有CVS、SVN这些免费的版本控制系统吗?因为Linus坚定地反对CVS和SVN,这些集中式的版本控制系统不但速度慢,而且必须联网才能使用。有一些商用的版本控制系统,虽然比CVS、SVN好用,但那是付费的,和Linux的开源精神不符。
不过,到了2002年,Linux系统已经发展了十年了,代码库之大让Linus很难继续通过手工方式管理了,社区的弟兄们也对这种方式表达了强烈不满,于是Linus选择了一个商业的版本控制系统BitKeeper,BitKeeper的东家BitMover公司出于人道主义精神,授权Linux社区免费使用这个版本控制系统。
安定团结的大好局面在2005年就被打破了,原因是Linux社区牛人聚集,不免沾染了一些梁山好汉的江湖习气。开发Samba的Andrew试图破解BitKeeper的协议(这么干的其实也不只他一个),被BitMover公司发现了(监控工作做得不错!),于是BitMover公司怒了,要收回Linux社区的免费使用权。
Linus可以向BitMover公司道个歉,保证以后严格管教弟兄们,嗯,这是不可能的。实际情况是这样的:
Linus花了两周时间自己用C写了一个分布式版本控制系统,这就是Git!一个月之内,Linux系统的源码已经由Git管理了!牛是怎么定义的呢?大家可以体会一下。
Git迅速成为最流行的分布式版本控制系统,尤其是2008年,GitHub网站上线了,它为开源项目免费提供Git存储,无数开源项目开始迁移至GitHub,包括jQuery,PHP,Ruby等等。
历史就是这么偶然,如果不是当年BitMover公司威胁Linux社区,可能现在我们就没有免费而超级好用的Git了。
Git下载:
https://github.com/git-for-windows/git/releases/
下载完成了之后可以看到再程序处可以或者鼠标右击可以看到三个东西,分别是:
Git Bash:推荐使用,使用命令风格类似于Linux命令,例如:clear
Git CMD:使用风格类似于window中cmd命令,例如:cls
Git GUI:图形化界面的Git,不建议使用
Git命令:
查看git版本:
git version
查看git配置信息:
git config -l:
-l:参数代表list。注意:刚下载的git是没有name和email的配置的,一定要配置
查看系统配置的git信息:在/git/etc/gitconfig
git config --system --list
查看用户自己配置的git信息:在C:\Users\52170
git config --global --list/-l
配置用户自己的账号和邮箱:注:必须配置,不配置不能提交项目:
git config --global user.name “用户名”
git config --global user.email “邮箱地址”
注意所有听着很玄乎的配置信息其实就是一个个的文件
环境变量的作用和意义:环境变量只是为了在任何场景下都能使用该命令,比如说conda,但是我们的git不需要配置环境变量就可以在任意地方使用,因此不需要配置。
Git工作原理(核心):
Git本地有四个工作区域:工作区,缓存区,本地仓库/版本库,远程仓库。
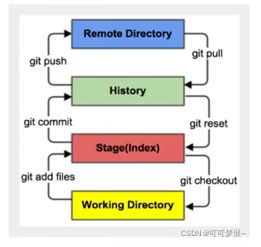
工作区:就是我们平时写代码的地方
缓存区:就是临时存放代码,事实上它只是一个文件,保存了即将提交的文件列表
本地仓库:就是安全存放数据代码的地方,这里有我们所有的提交的代码,其中有一个HEAD文件指向我们最新的放入仓库的版本
远程仓库:就是托管代码的服务器,可以简单的理解为,你们一个项目组中只有一个人的电脑用于连接远程数据进行交换,比如说github,gitee等
注意上述的6个命令,git add, git commit, git push, git clone, git reset, git checkout
注意:.git文件是一个隐藏文件夹
Git项目搭建:
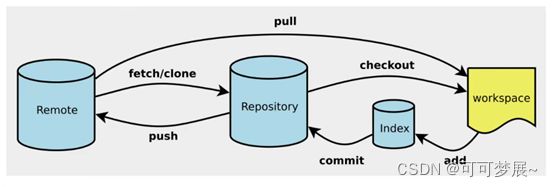
工作目录:一般你希望Git帮你管理的文件夹,可以是你的项目的目录也可以是一个空目录,建议不要有中文,常用的命令:
git add, git commit, git push, git clone, git reset, git checkout
创建本地仓库的两种方法:.git文件夹
- git init:初始化本地项目,也就是说从此以后当前项目就具备了本地管理的能力,可以 于git进行交互了。
- git clone:克隆远程项目和git init一样的作用,也是创建一个本地仓库,只不过git init 是将本地项目作为了本地仓库,而git clone是将远程仓库作为了本地仓库。
git clone + 地址
在本地库目录下创建文件,然后添加到暂存区,再提交到本地库,感觉这个逻辑很怪是吧,明明第一步就已经在本地库下就创建了文件,还提交干啥?
我们所说的提交到本地库,更实际的是保存本次的更新版本或记录,以便之后我们可以切换到这个历史版本
文件有四种状态:
- Untracked:未被跟踪,此文件在文件夹中,但是并没有加入到git库中,不参与版本的控制,通过git add变成Staged(暂存)
git status:查看状态
git status + 文件名:查看某个文件的状态
git add:添加文件,将工作区的提交记录提交到缓存区,缓存区是本地工作区和本地仓库 区的一个桥梁,当缓存区累计到一定量了之后,就可以将缓存区的东西一次行的 提交到本地仓库当中。
git add + 文件:添加指定文件
git add . :将文件从本地加载到缓存区,跟踪文件,文件待提交状态
git rm --cache + 文件名 :如果add错了文件,那么直接从缓存区删除即可
git diff + 文件名:查看工作区的该文件和缓存区的差别, ---a表示修改之前的文件,+++b 表示修改后的文件
git diff --cached:比较缓存区和版本库之间的差距
git diff HEAD -- + 文件名:查看工作区和版本库的区别
git commit:提交文件,将缓存区的文件提交到版本库/本地仓库,工作区--->缓存区---> 本地仓库
git commit -m + “修改说明”:提交缓存区的内容到本地仓库
-m:参数,代表每次提交跟新的信息,github为例
回退版本:
git log:打印所有提交过版本的信息
git log --pretty=oneline:只打印一行版本信息,包含哈希值(版本号)和修改说明
git reset --hard HEAD^:返回上一个版本,一个^表示一个版本
git reset --hard HEAD~1000:回退到前1000个版本
打印一下发现回退完了之后最新版本不见了,想要回到最新版本:
git reset --hard + 最新哈希号
当我们关闭了shell窗口已经找不到最新的版本号了,但是又想回到最新的版本
git reflog :可以查看我们之前操作的记录。reflog(回流)
讲到这个地方:除了了解了基础的git命令之外,还了解了三个概念:工作区,缓存区,本地仓库/版本库,它们的关系如下图所示:
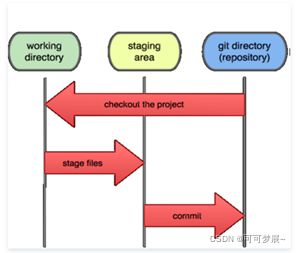
工作区:我们的文件目录就是工作区
缓存区和版本库:它们都在 .git 文件中,这个文件中的index文件就是缓存区
回退到上一版本的原理就是指针HEAD:


为什么说Git好,有一个很重要的原因就是说,它是跟踪并管理修改而不是文件。
第一次修改 -> git add -> 第二次修改 -> git commit
这样将不会把第二次的修改添加到版本库中,所以说git管理的是修改。
撤回操作:
假如说我们再写代码的时候,写完之后发现有些地方写错了,如果还没提交我们可以打印一下它的状态查看一下提示。
git restore + 文件名:将文件的修改撤回,撤回到和版本库一摸一样,restore(恢复)
或者git checkout -- 文件名:注意:一定要加上 --
一种是a.txt自修改后还没有被放到暂存区,撤销修改就回到和版本库一模一样的状态;
一种是a.txt已经添加到暂存区后,又作了修改,撤销修改就回到添加到暂存区后的状态。
第二种情况再怎么把缓存区的撤回到工作区?
- git reset HEAD + 文件名:可以把缓存区的撤回掉,重新放回工作区,HEAD能加^
然后再:git restore + 文件名:撤回添加到缓存区之前的状态就ok了
- git restore --staged + 文件名:可以把缓存区的撤回掉,重新放回工作区
然后再:git restore + 文件名:撤回添加到缓存区之前的状态就ok了
假设你不但改错了东西,还从暂存区提交到了版本库,怎么办呢?还记得版本回退一节吗?可以回退到上一个版本。不过,这是有条件的,就是你还没有把自己的本地版本库推送到远程。一旦你把错误的信息提交推送到远程版本库,准备好凉凉。
小复习:
场景1:当你错该了工作区某个文件的内容,想撤回工作区的修改。
场景2:当你错该了工作区某个文件的内容,还添加到了暂存区,想撤回工作区的修改,分两步,第一步先就回到了场景1,第二步按场景1操作。
场景3:当你错该了工作区某个文件的内容,还添加到了暂存区,还添加到了本地仓库,想撤回工作区的修改,直接退回上一个版本。
场景4:当你错该了工作区某个文件的内容,还添加到了暂存区,还添加到了本地仓库,还添加到了远程仓库,想要撤回工作取得修改。等死就行了!
Git删除:
我们可以直接从我们的工作区删除文件,但是这个时候在去打印状态的时候,git就会提示我们哪个文件删除了。
- 删对了,本意就是想要删除这个文件的
git rm + 文件名:删除库中的文件
git commit -m “注释说明”:把删除的信息提交到本地仓库
- 删错了,想要恢复过来
git checkout -- + 文件名:从版本库中一键还原
注意:从来没有被添加到版本库就被删除的文件,是无法恢复的!!!或者版本库中的也被删除了也无法还原!!!同时恢复的话默认恢复最新版本的!!!
截止到以上,工作区,缓存区,本地仓库就说完了
远程仓库:
Github,Gitlab,Gitee(码云):目的是为了托管我们代码的
- 注册:https://gitee.com/
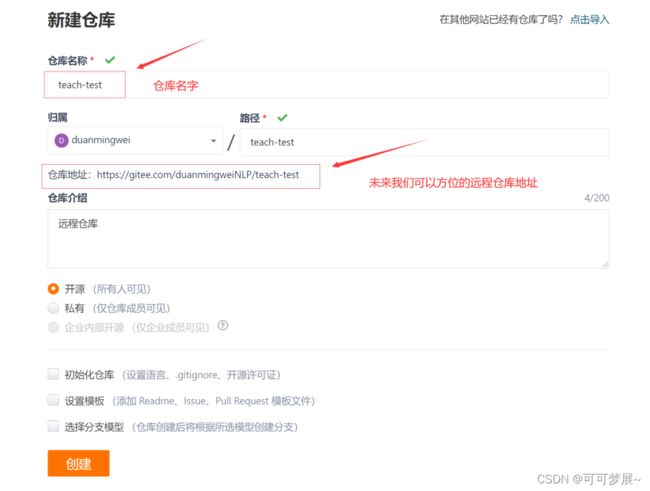
直接创建即可,不要初始化。
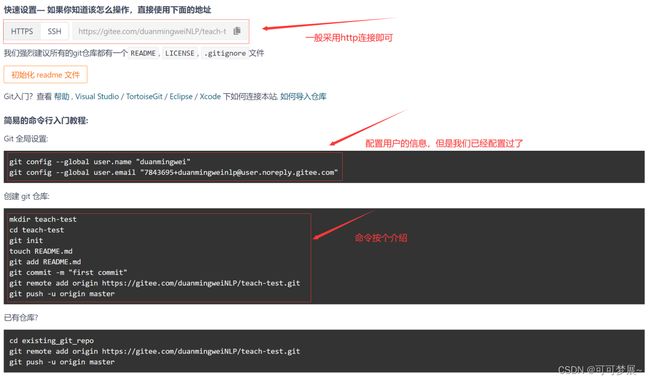
刚开始的时候会有个这样的新手教程。
搭建自己的远程仓库:托管代码
在这个过程当中我们使用了git push命令,git push:推送文件,如果是使用 git clone 命令克隆的本地项目,当工作到一定程度时可能需要将这部分工作成果推送到远程仓库,这时候使用 git push 命令完成本地版本的推送流程.
如果是使用 git init 命令初始化的本地项目,可能没有远程仓库,自然也就不需要推送.如果后来创建了远程仓库,那么你自然是想要将本地仓库推送到远程仓库的,因此你需要准确告诉 git 你要推送到哪个远程仓库.
使用 git remote add origin + http远程地址 命令添加远程仓库信息,这样就建立了本地仓库和远程仓库的关联,以后就可以正常推送到远程仓库了。
- 知道远程仓库在哪儿,不需要连接本地和远程直接:
git push -u origin master
- 不知道远程仓库在哪儿,需要做两步:
git remote add origin + 远程地址:将本地仓库和远程仓库关联起来,romote add:添 加远程,origin只是一个自己起的仓库名字,但是一般使用origin。
git push -u origin master
-u:由于远程库是空的,我们第一次推送master分支时,加上了-u参数,Git不但会把本地的master分支内容推送的远程新的master分支,还会把本地的master分支和远程的master分支关联起来,在以后的推送或者拉取时就可以不用-u了。只需要
git push origin master