K8s学习(8)---Pod详解(Pod生命周期)
我们一般将pod对象从创建至终的这段时间范围称为pod的生命周期,它主要包含下面的过程:
-
pod创建过程
-
运行初始化容器(init container)过程
-
运行主容器(main container)
-
容器启动后钩子(post start)、容器终止前钩子(pre stop)
-
容器的存活性探测(liveness probe)、就绪性探测(readiness probe)
-
-
pod终止过程

在整个生命周期中,Pod会出现5种状态(相位),分别如下:
- 挂起(Pending):apiserver已经创建了pod资源对象,但它尚未被调度完成或者仍处于下载镜像的过程中。
- 运行中(Running):pod已经被调度至某节点,并且所有容器都已经被kubelet创建完成。
- 成功(Succeeded):pod中的所有容器都已经成功终止并且不会被重启。
- 失败(Failed):所有容器都已经终止,但至少有一个容器终止失败,即容器返回了非0值的退出状态。
- 未知(Unknown):apiserver无法正常获取到pod对象的状态信息,通常由网络通信失败所导致。
创建和终止
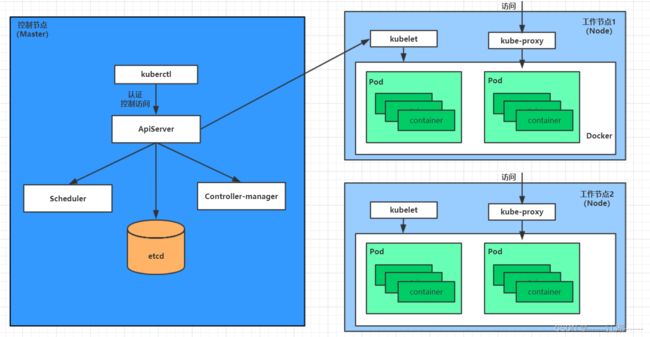
pod的创建过程
-
用户通过kubectl或其他api客户端提交需要创建的pod信息给apiServer。
-
apiServer开始生成pod对象的信息,并将信息存入etcd,然后返回确认信息至客户端。
-
apiServer开始反映etcd中的pod对象的变化,其它组件使用watch机制来跟踪检查apiServer上的变动。
-
scheduler发现有新的pod对象要创建,开始为Pod分配主机并将结果信息更新至apiServer。
-
node节点上的kubelet发现有pod调度过来,尝试调用docker启动容器,并将结果回送至apiServer。
-
apiServer将接收到的pod状态信息存入etcd中。
pod的终止过程
- 用户向apiServer发送删除pod对象的命令。
- apiServcer中的pod对象信息会随着时间的推移而更新,在宽限期内(默认30s),pod被视为dead。
- 将pod标记为terminating状态。
- kubelet在监控到pod对象转为terminating状态的同时启动pod关闭过程。
- 端点控制器监控到pod对象的关闭行为时将其从所有匹配到此端点的service资源的端点列表中移除。
- 如果当前pod对象定义了preStop钩子处理器,则在其标记为terminating后即会以同步的方式启动执行。
- pod对象中的容器进程收到停止信号。
- 宽限期结束后,若pod中还存在仍在运行的进程,那么pod对象会收到立即终止的信号。
- kubelet请求apiServer将此pod资源的宽限期设置为0从而完成删除操作,此时pod对于用户已不可见。
初始化容器
初始化容器是在pod的主容器启动之前要运行的容器,主要是做一些主容器的前置工作,它具有两大特征:
- 初始化容器必须运行完成直至结束,若某初始化容器运行失败,那么kubernetes需要重启它直到成功完成
- 初始化容器必须按照定义的顺序执行,当且仅当前一个成功之后,后面的一个才能运行
初始化容器有很多的应用场景,下面列出的是最常见的几个:
- 提供主容器镜像中不具备的工具程序或自定义代码
- 初始化容器要先于应用容器串行启动并运行完成,因此可用于延后应用容器的启动直至其依赖的条件得到满足
接下来做一个案例,模拟下面这个需求:
假设要以主容器来运行nginx,但是要求在运行nginx之前先要能够连接上mysql和redis所在服务器
为了简化测试,事先规定好mysql(192.168.109.201)和redis(192.168.109.202)服务器的地址
创建pod-initcontainer.yaml,内容如下:
apiVersion: v1
kind: Pod
metadata:
name: pod-initcontainer
namespace: dev
spec:
containers:
- name: main-container
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
initContainers:
- name: test-mysql
image: busybox:1.30
command: ['sh', '-c', 'until ping 192.168.109.201 -c 1 ; do echo waiting for mysql...; sleep 2; done;']
- name: test-redis
image: busybox:1.30
command: ['sh', '-c', 'until ping 192.168.109.202 -c 1 ; do echo waiting for reids...; sleep 2; done;']
# 创建pod
[root@master ~]# kubectl create -f pod-initcontainer.yaml
pod/pod-initcontainer created
# 查看pod状态
# 发现pod卡在启动第一个初始化容器过程中,后面的容器不会运行
root@master ~]# kubectl describe pod pod-initcontainer -n dev
........
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 49s default-scheduler Successfully assigned dev/pod-initcontainer to node1
Normal Pulled 48s kubelet, node1 Container image "busybox:1.30" already present on machine
Normal Created 48s kubelet, node1 Created container test-mysql
Normal Started 48s kubelet, node1 Started container test-mysql
# 动态查看pod
[root@master ~]# kubectl get pods pod-initcontainer -n dev -w
NAME READY STATUS RESTARTS AGE
pod-initcontainer 0/1 Init:0/2 0 15s
pod-initcontainer 0/1 Init:1/2 0 52s
pod-initcontainer 0/1 Init:1/2 0 53s
pod-initcontainer 0/1 PodInitializing 0 89s
pod-initcontainer 1/1 Running 0 90s
# 接下来新开一个shell,为当前服务器新增两个ip,观察pod的变化
[root@master ~]# ifconfig ens33:1 192.168.109.201 netmask 255.255.255.0 up
[root@master ~]# ifconfig ens33:2 192.168.109.202 netmask 255.255.255.0 up
钩子函数
钩子函数能够感知自身生命周期中的事件,并在相应的时刻到来时运行用户指定的程序代码。
kubernetes在主容器的启动之后和停止之前提供了两个钩子函数:
- post start:容器创建之后执行,如果失败了会重启容器
- pre stop :容器终止之前执行,执行完成之后容器将成功终止,在其完成之前会阻塞删除容器的操作
钩子处理器支持使用下面三种方式定义动作:
-
Exec命令:在容器内执行一次命令
…… lifecycle: postStart: exec: command: - cat - /tmp/healthy …… -
TCPSocket:在当前容器尝试访问指定的socket
…… lifecycle: postStart: tcpSocket: port: 8080 …… -
HTTPGet:在当前容器中向某url发起http请求
…… lifecycle: postStart: httpGet: path: / #URI地址 port: 80 #端口号 host: 192.168.109.100 #主机地址 scheme: HTTP #支持的协议,http或者https ……
接下来,以exec方式为例,演示下钩子函数的使用,创建pod-hook-exec.yaml文件,内容如下:
apiVersion: v1
kind: Pod
metadata:
name: pod-hook-exec
namespace: dev
spec:
containers:
- name: main-container
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
lifecycle:
postStart:
exec: # 在容器启动的时候执行一个命令,修改掉nginx的默认首页内容
command: ["/bin/sh", "-c", "echo postStart... > /usr/share/nginx/html/index.html"]
preStop:
exec: # 在容器停止之前停止nginx服务
command: ["/usr/sbin/nginx","-s","quit"]
# 创建pod
[root@master ~]# kubectl create -f pod-hook-exec.yaml
pod/pod-hook-exec created
# 查看pod
[root@master ~]# kubectl get pods pod-hook-exec -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pod-hook-exec 1/1 Running 0 29s 10.244.2.48 node2
# 访问pod
[root@master ~]# curl 10.244.2.48
postStart...
容器探测
容器探测用于检测容器中的应用实例是否正常工作,是保障业务可用性的一种传统机制。如果经过探测,实例的状态不符合预期,那么kubernetes就会把该问题实例" 摘除 ",不承担业务流量。kubernetes提供了两种探针来实现容器探测,分别是:
-
liveness probes:存活性探针,用于检测应用实例当前是否处于正常运行状态,如果不是,k8s会重启容器
-
readiness probes:就绪性探针,用于检测应用实例当前是否可以接收请求,如果不能,k8s不会转发流量
livenessProbe 决定是否重启容器,readinessProbe 决定是否将请求转发给容器。
上面两种探针目前均支持三种探测方式:
-
Exec命令:在容器内执行一次命令,如果命令执行的退出码为0,则认为程序正常,否则不正常
…… livenessProbe: exec: command: - cat - /tmp/healthy …… -
TCPSocket:将会尝试访问一个用户容器的端口,如果能够建立这条连接,则认为程序正常,否则不正常
…… livenessProbe: tcpSocket: port: 8080 …… -
HTTPGet:调用容器内Web应用的URL,如果返回的状态码在200和399之间,则认为程序正常,否则不正常
…… livenessProbe: httpGet: path: / #URI地址 port: 80 #端口号 host: 127.0.0.1 #主机地址 scheme: HTTP #支持的协议,http或者https ……
下面以liveness probes为例,做几个演示:
方式一:Exec
创建pod-liveness-exec.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-exec
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
exec:
command: ["/bin/cat","/tmp/hello.txt"] # 执行一个查看文件的命令
创建pod,观察效果
# 创建Pod
[root@master ~]# kubectl create -f pod-liveness-exec.yaml
pod/pod-liveness-exec created
# 查看Pod详情
[root@master ~]# kubectl describe pods pod-liveness-exec -n dev
......
Normal Created 20s (x2 over 50s) kubelet, node1 Created container nginx
Normal Started 20s (x2 over 50s) kubelet, node1 Started container nginx
Normal Killing 20s kubelet, node1 Container nginx failed liveness probe, will be restarted
Warning Unhealthy 0s (x5 over 40s) kubelet, node1 Liveness probe failed: cat: can't open '/tmp/hello11.txt': No such file or directory
# 观察上面的信息就会发现nginx容器启动之后就进行了健康检查
# 检查失败之后,容器被kill掉,然后尝试进行重启(这是重启策略的作用,后面讲解)
# 稍等一会之后,再观察pod信息,就可以看到RESTARTS不再是0,而是一直增长
[root@master ~]# kubectl get pods pod-liveness-exec -n dev
NAME READY STATUS RESTARTS AGE
pod-liveness-exec 0/1 CrashLoopBackOff 2 3m19s
# 当然接下来,可以修改成一个存在的文件,比如/tmp/hello.txt,再试,结果就正常了......
方式二:TCPSocket
创建pod-liveness-tcpsocket.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-tcpsocket
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
tcpSocket:
port: 8080 # 尝试访问8080端口
创建pod,观察效果
# 创建Pod
[root@master ~]# kubectl create -f pod-liveness-tcpsocket.yaml
pod/pod-liveness-tcpsocket created
# 查看Pod详情
[root@master ~]# kubectl describe pods pod-liveness-tcpsocket -n dev
......
Normal Scheduled 31s default-scheduler Successfully assigned dev/pod-liveness-tcpsocket to node2
Normal Pulled kubelet, node2 Container image "nginx:1.17.1" already present on machine
Normal Created kubelet, node2 Created container nginx
Normal Started kubelet, node2 Started container nginx
Warning Unhealthy (x2 over ) kubelet, node2 Liveness probe failed: dial tcp 10.244.2.44:8080: connect: connection refused
# 观察上面的信息,发现尝试访问8080端口,但是失败了
# 稍等一会之后,再观察pod信息,就可以看到RESTARTS不再是0,而是一直增长
[root@master ~]# kubectl get pods pod-liveness-tcpsocket -n dev
NAME READY STATUS RESTARTS AGE
pod-liveness-tcpsocket 0/1 CrashLoopBackOff 2 3m19s
# 当然接下来,可以修改成一个可以访问的端口,比如80,再试,结果就正常了......
方式三:HTTPGet
创建pod-liveness-httpget.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-httpget
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
httpGet: # 其实就是访问http://127.0.0.1:80/hello
scheme: HTTP #支持的协议,http或者https
port: 80 #端口号
path: /hello #URI地址
创建pod,观察效果
# 创建Pod
[root@master ~]# kubectl create -f pod-liveness-httpget.yaml
pod/pod-liveness-httpget created
# 查看Pod详情
[root@master ~]# kubectl describe pod pod-liveness-httpget -n dev
.......
Normal Pulled 6s (x3 over 64s) kubelet, node1 Container image "nginx:1.17.1" already present on machine
Normal Created 6s (x3 over 64s) kubelet, node1 Created container nginx
Normal Started 6s (x3 over 63s) kubelet, node1 Started container nginx
Warning Unhealthy 6s (x6 over 56s) kubelet, node1 Liveness probe failed: HTTP probe failed with statuscode: 404
Normal Killing 6s (x2 over 36s) kubelet, node1 Container nginx failed liveness probe, will be restarted
# 观察上面信息,尝试访问路径,但是未找到,出现404错误
# 稍等一会之后,再观察pod信息,就可以看到RESTARTS不再是0,而是一直增长
[root@master ~]# kubectl get pod pod-liveness-httpget -n dev
NAME READY STATUS RESTARTS AGE
pod-liveness-httpget 1/1 Running 5 3m17s
# 当然接下来,可以修改成一个可以访问的路径path,比如/,再试,结果就正常了......
至此,已经使用liveness Probe演示了三种探测方式,但是查看livenessProbe的子属性,会发现除了这三种方式,还有一些其他的配置,在这里一并解释下:
[root@master ~]# kubectl explain pod.spec.containers.livenessProbe
FIELDS:
exec 下面稍微配置两个,演示下效果即可:
[root@master ~]# more pod-liveness-httpget.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-liveness-httpget
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
httpGet:
scheme: HTTP
port: 80
path: /
initialDelaySeconds: 30 # 容器启动后30s开始探测
timeoutSeconds: 5 # 探测超时时间为5s
重启策略
在上一节中,一旦容器探测出现了问题,kubernetes就会对容器所在的Pod进行重启,其实这是由pod的重启策略决定的,pod的重启策略有 3 种,分别如下:
- Always :容器失效时,自动重启该容器,这也是默认值。
- OnFailure : 容器终止运行且退出码不为0时重启
- Never : 不论状态为何,都不重启该容器
重启策略适用于pod对象中的所有容器,首次需要重启的容器,将在其需要时立即进行重启,随后再次需要重启的操作将由kubelet延迟一段时间后进行,且反复的重启操作的延迟时长以此为10s、20s、40s、80s、160s和300s,300s是最大延迟时长。
创建pod-restartpolicy.yaml:
apiVersion: v1
kind: Pod
metadata:
name: pod-restartpolicy
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- name: nginx-port
containerPort: 80
livenessProbe:
httpGet:
scheme: HTTP
port: 80
path: /hello
restartPolicy: Never # 设置重启策略为Never
运行Pod测试
# 创建Pod
[root@master ~]# kubectl create -f pod-restartpolicy.yaml
pod/pod-restartpolicy created
# 查看Pod详情,发现nginx容器失败
[root@master ~]# kubectl describe pods pod-restartpolicy -n dev
......
Warning Unhealthy 15s (x3 over 35s) kubelet, node1 Liveness probe failed: HTTP probe failed with statuscode: 404
Normal Killing 15s kubelet, node1 Container nginx failed liveness probe
# 多等一会,再观察pod的重启次数,发现一直是0,并未重启
[root@master ~]# kubectl get pods pod-restartpolicy -n dev
NAME READY STATUS RESTARTS AGE
pod-restartpolicy 0/1 Running 0 5min42s