泛型编程————浅析模板
目录
泛型编程
函数模板
类模板
模板声明定义分离编译
泛型编程
泛型编程最初提出时的动机很简单直接:发明一种语言机制,能够帮助实现一个通用的标准容器库。所谓通用的标准容器库,就是要能够做到,比如用一个List类存放所有可能类型的对象这样的事;泛型编程让你编写完全一般化并可重复使用的算法,其效率与针对某特定数据类型而设计的算法相同。泛型即是指具有在多种数据类型上皆可操作的含义,与模板有些相似。
泛型的第一个好处是编译时的严格类型检查。这是集合框架最重要的特点。此外,泛型消除了绝大多数的类型转换。如果没有泛型,当你使用集合框架时,你不得不进行类型转换。
关于泛型的理解可以总结下面的一句话,它是把数据类型作为一种参数传递进来。
函数模板
模板是泛型编程的基础,可分为函数模板和类模板两大类。
先说函数模板:
以swap函数为例,有时我们会觉得swap函数很麻烦,因为在C语言中,如果要交换的对象有int,有double,有char,那么就需要实现多个类似的swap函数来完成。但是它们除了参数类型不同,其它都基本一致,就会给我们一种重复工作的感觉(事实也是如此)。
void swapi(int* x, int* y)
{
int tmp = *x;
*x = *y;
*y = tmp;
}
void swapd(double* x, double* y)
{
double tmp = *x;
*x = *y;
*y = tmp;
}
void swapc(char* x, char* y)
{
char tmp = *x;
*x = *y;
*y = tmp;
}
int main()
{
int a = 10, b = 20;
double c = 0.1,d = 0.5;
char e = 'a', f = 'b';
swapi(&a, &b);
swapd(&c, &d);
swapc(&e, &f);
return 0;
}非常简单的一个函数却要搞得如此繁复,并且C语言还不允许函数重载,函数名还不能都用swap,这样就更难受了。
C++为了改善编程质量及效率,采用了模板这一概念。将繁复冗余的代码简洁化。
template
void Swap(T& left, T& right)
{
T tmp = left;
left = right;
right = tmp;
}
int main()
{
int a = 10, b = 20;
double c = 0.1, d = 0.5;
char e = 'a', f = 'b';
Swap(a, b);
Swap(c, d);
Swap(e, f);
return 0;
} 函数模板格式: template
这里关键字typename和class效果一样,后面名字用T或者Tp等等都可以。
有了模板以后实现那些重复的函数就方便多了,我们只需事先写好一个模板,其它交给编译器处理就可以,编译器会自动将模板推演转化为对应的函数。
比如上面Swap(a,b),因为a,b都是int类型的,所以编译器将模板自动推演转化为对应的void swap(int& left, int& right) 函数。

注意:我函数名Swap用的是大写,因为C++库里面有swap函数的实现 。

再来看下面的例子:
template
T Add(const T& x, const T& y)
{
return x + y;
}
int main()
{
int a1 = 10, a2 = 20;
double b1 = 0.1, b2 = 0.5;
cout << Add(a1, a2) << endl;
cout << Add(b1, b2) << endl;
//error
cout << Add(a1, b2) << endl;
cout << Add(b1, a2) << endl;
return 0;
} 这是一个简单的加法函数模板,Add(a1,a2)编译器会进行推演,这是int类型的,那就实现为
int Add(const int& x, const int& y)
{
return x + y;
}但是Add(a1,b2),两个是不同类型的,一个是int ,一个是double,那么这样叫编译器如何推演呢?因此就会报错。由此可知,模板不支持类型转换。
有三种解决方法:
1、用户自己强制类型转换
//强制类型转化
cout << Add(a1, (int)b2) << endl;
cout << Add(b1, (double)a2) << endl;
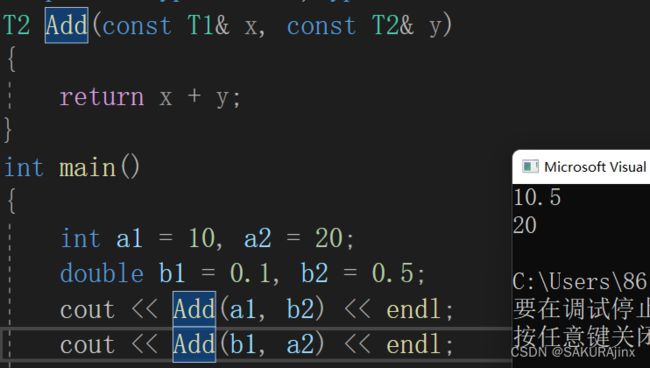
2、显示实例化
//显示实例化
cout << Add(a1, b2) << endl;
cout << Add(b1, a2) << endl;
如果类型不匹配,编译器会尝试进行隐式类型转换,如果无法转换成功编译器将会报错。
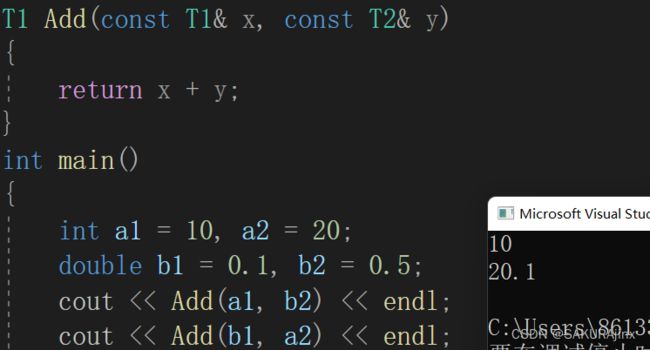
3、通用加法函数模板
template
T1 Add(const T1& x, const T2& y)
{
return x + y;
}
int main()
{
int a1 = 10, a2 = 20;
double b1 = 0.1, b2 = 0.5;
cout << Add(a1, b2) << endl;
cout << Add(b1, a2) << endl;
return 0;
} 这种方式就避免了上述问题,能很好地生成对应函数模板,不论变量类型是什么,都可以隐式类型转换,返回用户需要类型的值(T1/T2类型)。
再来看一个问题:如果已经存在一个Add函数,那么编译器会调用该函数还是模板?
int Add(const int& x, const int& y)
{
return x + y;
}
template
T2 Add(const T1& x, const T2& y)
{
return x + y;
}
int main()
{
int a = 10, b = 20;
cout << Add(a, b) << endl; 通过调试,我们发现编译器调用的是int Add函数而非模板,因为模板不是函数,只是个样例,用户要使用加法函数的时候它才会推演生成对应函数实例,如果有现成的函数在(并且完全对应),那编译器为什么还要多此一举生成一个呢?
只有在模板能生成一个更加匹配需要的实例时,才会调用模板。
cout << Add(1, 5.0) << endl;
如果调用已有的 int Add函数,需要将5.0隐式类型转换为int,因此调用模板生成实例更好。
类模板
template
class 类模板名
{
// 类内成员定义
}; 格式与函数模板类似,作用范围是整个类。
以动态顺序表为例:
// 动态顺序表
// 注意:Vector不是具体的类,是编译器根据被实例化的类型生成具体类的模具
template
class Vector
{
public:
Vector(size_t capacity = 10)
: _pData(new T[capacity])
, _size(0)
, _capacity(capacity)
{}
// 使用析构函数演示:在类中声明,在类外定义。
~Vector();
void PushBack(const T& data);
void PopBack();
// ...
size_t Size() { return _size; }
T& operator[](size_t pos)
{
assert(pos < _size);
return _pData[pos];
}
private:
T* _pData;
size_t _size;
size_t _capacity;
};
// 注意:类模板中函数放在类外进行定义时,需要加模板参数列表
template
Vector::~Vector()
{
if (_pData)
delete[] _pData;
_size = _capacity = 0;
}
int main()
{
// Vector类名,Vector才是类型
Vector s1;
Vector s2;
return 0;
} 想要在同一个文件下生成不同类型的顺序表,就要用到模板, Vector是类名,Vector
并且 Vector
还要注意:类模板中函数放在类外进行定义时,需要加模板参数列表
template
Vector
类模板还可以用来读写数组的数据:
#define N 10
template
class arr
{
public:
inline T& operator[](size_t i)
{
return _a[i];
}
private:
T _a[N];
};
int main()
{
arra1;
for (size_t i = 0; i < N; ++i)
{
a1[i] = i;
}
for (size_t i = 0; i < N; ++i)
{
cout << a1[i] << " ";
}
cout << endl;
return 0;
} inline T& operator[](size_t i){
return _a[i]; }
这里引用返回可以修改数组,也就是读写数组数据,所以引用返回的两个用处就体现出来了:一是减少拷贝,提高效率;而是修改返回值。
inline作用:不建立函数栈帧,与静态数组效率相当。
相比于静态数组,它的优势在于安全检查。
静态数组越界时,有的情况检查不出来,因为编译器对数组越界是抽查,不是所有位置都能检查出来的。
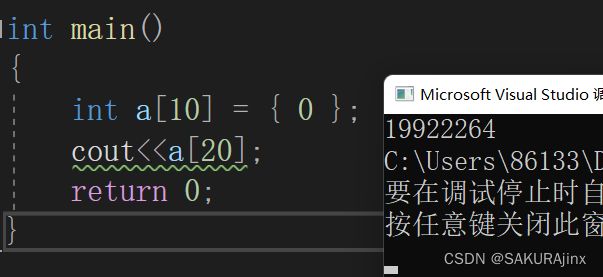
但是上面实现的数组可以避免检查不到的情况,用assert断言即可。
public:
T& operator[](size_t i)
{
assert(i < N);
return _a[i];
}
cout << a1[20];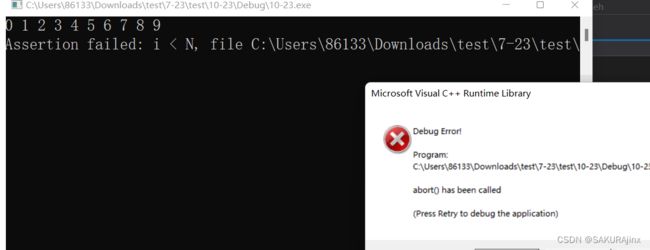
模板声明定义分离编译
Vector.h
#pragma once
#include
#include
// 动态顺序表
// 注意:Vector不是具体的类,是编译器根据被实例化的类型生成具体类的模具
template
class Vector
{
public:
Vector(size_t capacity = 10);
~Vector();
void PushBack(const T& data);
void PopBack();
// ...
size_t Size();
T& operator[](size_t pos);
private:
T* _pData;
size_t _size;
size_t _capacity;
}; Vector.cpp
#include"vector.h"
template
Vector::Vector(size_t capacity)
: _pData(new T[capacity])
, _size(0)
, _capacity(capacity)
{}
template
Vector::~Vector()
{
if (_pData)
delete[] _pData;
_size = _capacity = 0;
}
template
size_t Vector:: Size()
{ return _size; }
template
T& Vector::operator[](size_t pos)
{
assert(pos < _size);
return _pData[pos];
} test.cpp
#include"vector.h"
int main()
{
Vectora1;
return 0;
} 以顺序表为例,将模板声明定义分离。注意:Vector.cpp中成员函数需要声明是模板类中函数,每一个函数前要加template
编译运行后,编译器报错,是link(链接)错误。

在链接的时候报错了,没有找到对应函数的地址。
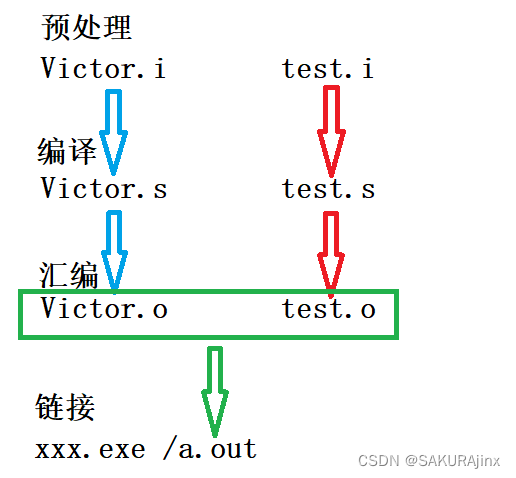
在预处理阶段,编译器生成 .i文件,编译阶段生成 .s文件,经过汇编生成 .o文件,到此为止,是单线程的,两个文件分别经过上述流程,在链接阶段,联系到一起,生成.exe(g++下生成.out文件)。
顺序表在编译过程中没有出错,因为编译器看到有定义有声明,就进行下去了,在链接过程中test.cpp调用类函数,但是没有函数的地址(符号表中找不到),因此就报链接错误了。
那为什么会找不到呢?明明文件中有声明也有定义。

这是因为,test.cpp中头文件会先展开,里面是类vector的声明,而test.cpp将对象实例化需要构造函数的地址也就是需要定义,但是.h文件中没有定义只有声明;而vector.cpp文件中只有定义没有实例化,因此它们之间都缺了一点,信息不足,所以会报链接错误。
解决方法一:显示实例化
在vector.cpp中显示实例化,这样有定义也有实例化,就可以链接了。
Vector.cpp
//显示实例化
template
class Vector; 但是这种方法也有缺陷,显示实例化只能
解决方法二:不分离
将vector.cpp的内容放到vector.h中,也就是合并两个文件。这样就不需要链接,也就不会报错了。
这种纯模板文件后缀定义为 .hpp
那有人会问,直接将定义放在类里面不就行了吗?————声明和定义分离的理由是:
1、方便项目代码、日志(代码量大、函数多)的阅读
2、保护源代码,减少被copy的风险
所以这种方法无可避免模板是会给用户看到的。