Scrapy 框架
介绍
Scrapy 是一个基于 Twisted 的异步处理框架,是纯 Python 实现的开源爬虫框架,其架构清晰,模块之间的耦合程度低,可扩展性极强,可以灵活完成各种需求。
Scrapy 框架的架构
如下图所示:

其中各个组件含义如下:
- Scrapy Engine(引擎):负责 Spiders、Item Pipeline、Downloader、Scheduler 之间的通信,包括信号和数据传输等。
- Item(项目):定义爬取结构的数据结构,爬取的数据会被赋值成该对象。
- Scheduler(调度器):负责接收引擎发送过来的 Request 请求,并按照一定的方式进行整理排列和入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载引擎发送的所有 Requests;并将其获取到的 Responses 交还给引擎,由引擎交给 Spider 来处理。
- Spiders(蜘蛛):负责处理所有 Responses,从中分析提取数据,获取 Item 字段需要的数据,并将需要跟进的 URL 提交给引擎,再次进入调度器。
- Item Pipeline(项目管道):负责处理 Spiders 中获取到的 Item 数据,并进行后期处理(比如清洗、验证和存储数据)。
- Downloader Middlewares(下载中间件):是一个可以自定义扩展下载功能的组件,主要是处理引擎与下载器之间的请求及响应。
- Spider Middlewares(蜘蛛中间件):是一个可以自定义扩展 Scrapy Engine 和 Spiders 中间通信的功能组件,主要是处理 Spiders 输入的响应和 Spiders 输出的请求。
Scrapy 框架运作流程
Scrapy 中的数据流由引擎控制,其过程如下:
- 引擎向 Spiders 请求第一个要爬取的 URL
- 引擎从 Spiders 中获取到第一个要爬取的 URL 并封装成 Request 交给调度器
- 引擎向调度器请求下一个要爬取的 Request
- 调度器返回下一个要爬取的 Request 给引擎,引擎将 Request 通过下载中间件转发给下载器
- 页面下载完毕之后,下载器生成一个该页面的 Response 并将其通过下载中间件发送给引擎
- 引擎从下载器中接收到 Response 并通过 Spider 中间件发送给 Spider 处理
- Spider 处理 Response 并返回爬取到的 Item 以及新的 Request 给引擎
- 引擎将爬取到的 Item 交给 Item Pipeline,将 Request 交给调度器
- 重复第二步到最后一步,直到调度器中没有更多的 Request
安装
pip install scrapy
Scrapy 项目结构
创建项目
scrapy startproject tutorial
cd tutorial
tree /f .
结果如下:

其中各个文件的功能描述如下:
- scrapy.cfg:它是 Scrapy 项目的配置文件,其内定义了项目的配置文件路径、部署相关信息等内容。
- items.py:它定义了 Item 数据结构,所有 Item 的定义都可以放在这里
- pipeline.py:它定义了 Item Pipeline 的实现,所有的 Item Pipeline 的实现都可以放在这里
- settings.py:它定义了项目的全局配置
- middlewares.py:它定义了 Spider Middlewares 和 Downloader Middlewares 的实现
- spiders:其内包含了一个个 Spider 的实现,每个 Spider 都有一个文件
基本使用
创建 Spider
scrapy genspider quotes quotes.toscrape.com
执行完成之后,可以发现 spiders 文件夹中多了一个 quotes.py 文件,其中文件内容如下图所示:

可以发现这里有三个属性和一个方法:
- name: 表示这个爬虫的识别名称。爬虫的名称在项目中是唯一的,不同的爬虫需要使用不同的名称。
- allowed_domains:它是允许爬取的域名,如果初始或后续的请求连接不是在这个域名下的,则请求链接会被过滤掉。
- start_urls:表示爬取的起始 URL 元组或列表,初始请求是由它来定义的。
- parse:它是 Spider 的一个方法。默认情况下,被调用时 start_urls 里面的链接构成的请求完成下载执行后,返回的响应就会作为唯一的参数传递给这个函数。该方法负责解析返回的响应、提取数据或进一步生成要处理的请求。
创建 Item
Item 是保存爬取数据的容器,创建 Item 需要继承 scrapy.Item 类,并且定义类型为 scrapy.Field 的字段。观察目标网站定义要爬取的内容:

解析 Response
parse 方法的参数 response 是 start_urls 里面的链接爬取后的结果。所以在 parse 方法中,可以直接对 response 变脸包含的内容进行解析,比如浏览请求结果的网页源代码,或者进一步分析源代码内容,或者找出结果中的链接而得到下一个请求。

运行
scrapy crawl quotes -o quotes.json
结果如下:

Middleware 的用法
Downloader Middleware
Downloader Middlewares 即下载中间件,它是处于 Scrapy Engine 和 Downloader 之间的组件,主要是处理引擎与下载器之间的请求及响应。
在引擎传递请求给下载器的过程中,下载中间件可以对请求进行处理(例如,增加 headers 信息,增加 proxy 信息等)。在下载器完成网络请求,传递响应给引擎的过程中,下载中间件可以对响应进行处理(例如,进行 gzip 压缩等)。
编写下载中间件只需要实现以下的一个或全部即可:
process_request(self, request, spider)
Request 被 Scrapy 引擎调度给 Downloader 之前,process_request 方法就会被调用,也就是在 Request 从队列里调度出来到 Downloader 下载执行之前,可以用 process_request 方法对 Request 进行处理。方法的返回值必须为 None、Response 对象、Request 对象之一,或者抛出 IgnoreRequest 异常。该方法的参数包括:
- request:要处理的 Request 对象
- spider:该 Request 对应的 Spider 对象
该方法的返回结果包括:
- 如果返回 None,Scrapy 将继续处理该 Request,接着执行其他 Downloader Middleware 的 process_request 方法,直到 Downloader 把 Request 执行后得到 Response 才结束。这个过程其实就是修改 Request 的过程,不同的 Downloader Middleware 按照设置的优先级顺序依次对 Request 进行修改,最后推送至 Downloader 执行。
- 如果返回 Response 对象,更低优先级的 Downloader Middleware 的 process_request 和 process_exception 方法就不会被继续调用,每个 Downloader Middleware 的 process_response 方法转而被依次调用。调用完毕之后,直接将 Response 对象发送给 Spider 来处理。
- 如果返回 Request 对象,更低优先级的 Downloader Middleware 的 process_request 方法会停止执行。这个 Request 会重新放到调度队列里,其实它就是一个全新的 Request,等待被调度。如果被 Scheduler 调度了,那么所有的 Downloader Middleware 的 process_request 方法会被重新按照顺序执行。
- 如果抛出一个 IgnoreRequest 异常,则所有的 Downloader Middleware 的 process_exception 方法会依次执行。如果没有一个方法处理这个异常,那么 Request 的 errorback 方法就会回调。如果该异常还没有被处理,那么它便会被忽略。
process_response(self, request, response, spider)
Downloader 执行 Request 下载之后,会得到对应的 Response。Scrapy 引擎便会将 Response 发送给 Spider 进行解析。在发送之前,我们都可以用 process_response() 方法来对 Response 进行处理。方法的返回值必须为 Request 对象、Response 对象之一,或者抛出 IgnoreRequest 异常。该方法的参数包括:
- request:是 Request 对象,即此 Response 对应的 Request。
- response:是 Response 对象,即此被处理的 Response。
- spider:是 Spider 对象,即此 Response 对应的 Spider。
该方法的返回结果包括:
- 当返回为 Request 对象时,更低优先级的 Downloader Middleware 的 process_response 方法不会继续调用。该 Request 对象会重新放到调度队列里等待被调度,它相当于一个全新的 Request。然后,该 Request 会被 process_request 方法顺次处理。
- 当返回为 Response 对象时,更低优先级的 Downloader Middleware 的 process_response 方法会继续调用,继续对该 Response 对象进行处理。
- 当返回为 Response 对象时,更低优先级的 Downloader Middleware 的 process_response 方法会继续调用,继续对该 Response 对象进行处理。
process_exception(self, request, exception, spider)
当 Downloader 或 process_request 方法抛出异常时,例如抛出 IgnoreRequest 异常,process_exception() 方法就会被调用。方法的返回值必须为 None、Response 对象、Request 对象之一。该方法的参数包括:
- request:即 Request 对象,即产生异常的 Request。
- exception:即 Exception 对象,即抛出的异常。
- spider:即 Spider 对象,即 Request 对应的 Spider。
该方法的返回结果包括:
- 当返回为 None 时,更低优先级的 Downloader Middleware 的 process_exception 会被继续顺次调用,直到所有的方法都被调度完毕。
- 当返回为 Response 对象时,更低优先级的 Downloader Middleware 的 process_exception 方法不再被继续调用,每个 Downloader Middleware 的 process_response 方法转而被依次调用。
- 当返回为 Request 对象时,更低优先级的 Downloader Middleware 的 process_exception 也不再被继续调用,该 Request 对象会重新放到调度队列里面等待被调度,它相当于一个全新的 Request。然后,该 Request 又会被 process_request 方法顺次处理。
实例
创建 Spider
scrapy genspider httpbin
将 start_urls 修改为 http://httpbin.org/get 结果如下:

运行
scrapy crawl httpbin --nolog
结果如下:

可以发现 Request 使用的 User-Agent 是 Scrapy/2.9.0 (+https://scrapy.org),这其实是由 Scrapy 内置的 UserAgentMiddleware 设置的,UserAgentMiddleware源码如下:

在 from_crawler 方法中,首先尝试获取 settings 里面的 USER_AGENT,然后把 USER_AGENT 传递给 init 方法进行初始化,其参数就是 user_agent。如果没有传递 USER_AGENT 参数就默认设置为 Scrapy 字符串。接下来,在 process_request 方法中,将 user_agent 变量设置为 headers 变量的一个属性,这样就成功设置了 User-Agent。
如果需要设置随机 User-Agent 就需要借助 Downloader Middleware,在 middlewares.py 里面添加一个 RandomUserAgentMiddleware 的类,如下所示:
class RandomUserAgentMiddleware:
def __init__(self):
self.user_agents = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11'
]
def process_request(self, request, spider):
request.headers['User-Agent'] = random.choice(self.user_agents)
接下来在 settings.py 中,将 DOWNLOADER_MIDDLEWARES 设置成如下内容:
DOWNLOADER_MIDDLEWARES = {
"tutorial.middlewares.RandomUserAgentMiddleware": 543,
}
重新运行 Spider,就可以看到 Uset-Agent 被成功修改为列表中所定义的随机的一个 User-Agent,如下图所示:

Item Pipeline 的用法
当 Item 在 Spiders 中被收集之后,会被传递到 Item Pipeline。用户可以在 Scrapy 项目中定义多个管道,这些管道按定义的顺序依次处理 Item。
每个管道都是一个 Python 类,在这个类中实现了一些操作 Item 的方法。其中,有的方法用于丢弃重复的 Item,有的方法用于将 Item 存储到数据库或文件等。以下是 Item Pipeline 的一些典型应用:
- 验证爬取的数据,检查 Item 包含某些字段,例如 name 字段。
- 查重,并丢弃重复数据。
- 将爬取结果保存到文件或者数据库中
自定义 Item Pipeline
自定义 Item Pipeline 很简单,每个 Item Pipeline 组件都是一个独立的 Python 类,该类中的 process_item 方法必须实现,每个 Item Pipeline 组件都需要调用 process_item 方法。
process_item 方法必须返回一个 Item 对象,或者抛出 DropItem 异常,被丢弃的 Item 将不会被之后的 Pipeline 组件所处理。该方法的定义如下:
process_item(self, item, spider)
该方法的 2 个参数分别是:
- Item:表示被爬取的 Item 对象。
- spider:表示生成该 Item 的 Spider 对象。
实例
- 生成爬虫文件
scrapy genspider imagesnetbian pic.netbian.com
- 构造请求
在 settings.py 里定义一个变量 MAX_PAGE,结果如下:

定义 start_request 方法,用来生成 10 次请求,结果如下:
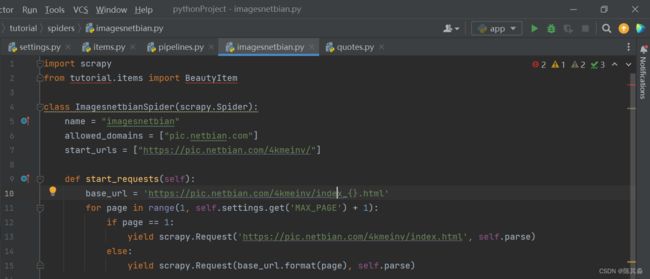
- 存储信息
用 MongoPipeline 将信息保存到 MongoDB 中,在 pipeline.py 里添加如下类的实现:
class MongoPipeline:
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB'))
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self, item, spider):
self.db[item.collection].insert_one(dict(item))
return item
def close_spider(self, spider):
self.client.close()
这里需要用到两个变量,MONGO_URI 和 MONGO_DB,即存储到 MONGODB 的链接地址和数据库名称。可以在 settings.py 里添加这两个变量,如下所示:
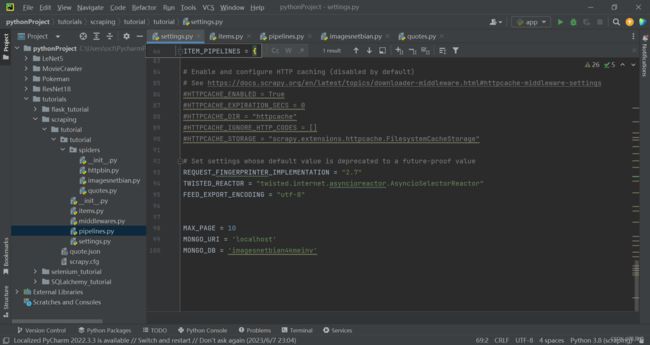
- 运行
scrapy crawl imagesnetbian --nolog
使用 MongoDB 客户端查看数据库可以发现结果已经保存到 MongoDB 中,结果如下:
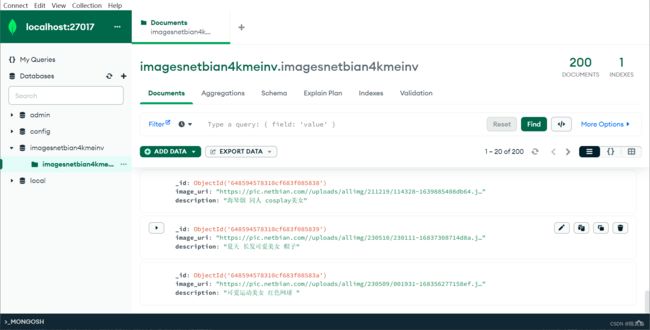
参考资料
- 崔庆才老师《Python3 网络爬虫开发实战》