scrapy详解基础,一篇到进阶门槛
前言
将学scrapy过程中一些常用到但是不需要经常更改的代码记录下来,以便后面使用,同时打卡中间一些常错点。
创建和启用
常见的创建scrapy语句:
scrapy startproject 项目名
scrapy genspider 爬虫名 域名
scrapy crawl 爬虫名例如:

这些文件分别是:
scrapy.cfg: 项目的配置文件picture/: 该项目的python模块。之后您将在此加入代码。picture/items.py: 项目中的item文件.picture/pipelines.py: 项目中的pipelines文件.picture/settings.py: 项目的设置文件.picture/spiders/: 放置spider代码的目录.
下一步是创建爬虫,但是在创建爬虫之前,我们查看scrapy中文文档,发现scrapy其实一共提供了五种模板spider
它们分别是
Spider
Spider是最简单的spider。每个其他的spider必须继承自该类(包括Scrapy自带的其他spider以及您自己编写的spider)。 Spider并没有提供什么特殊的功能。 其仅仅请求给定的
start_urls/start_requests,并根据返回的结果(resulting responses)调用spider的parse方法。
CrawlSpider
爬取一般网站常用的spider。其定义了一些规则(rule)来提供跟进link的方便的机制。 也许该spider并不是完全适合您的特定网站或项目,但其对很多情况都使用。 因此您可以以其为起点,根据需求修改部分方法。当然您也可以实现自己的spider。
XMLFeedSpider
XMLFeedSpider被设计用于通过迭代各个节点来分析XML源(XML feed)。 迭代器可以从
iternodes,xml,html选择。 鉴于xml以及html迭代器需要先读取所有DOM再分析而引起的性能问题, 一般还是推荐使用iternodes。 不过使用html作为迭代器能有效应对错误的XML。
CSVFeedSpider
该spider除了其按行遍历而不是节点之外其他和XMLFeedSpider十分类似。 而其在每次迭代时调用的是
parse_row()
SitemapSpider
SitemapSpider使您爬取网站时可以通过 Sitemaps 来发现爬取的URL。
其支持嵌套的sitemap,并能从 robots.txt 中获取sitemap的url
在本文中我主要学习了前两种模板,后面三个,暂时没有学习,有兴趣的朋友可以前往scrapy-chs.readthedocs.io/zh_CN/0.24/topics/spiders.html自行查看。
那么怎么创建不同类型的模板呢?
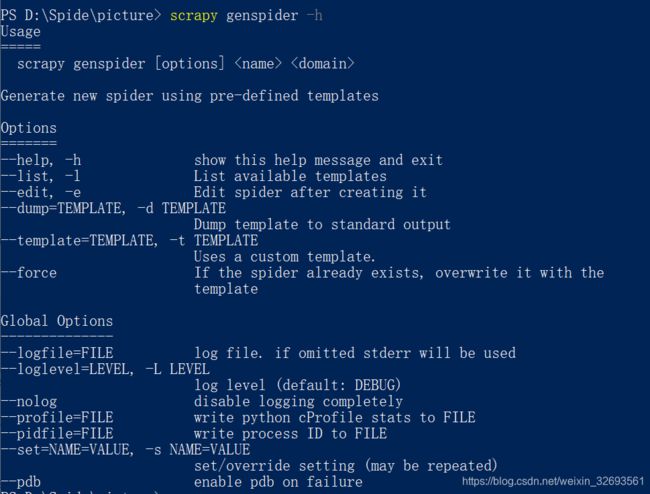

首先创建最基本的spider

再创建一个crawlspider


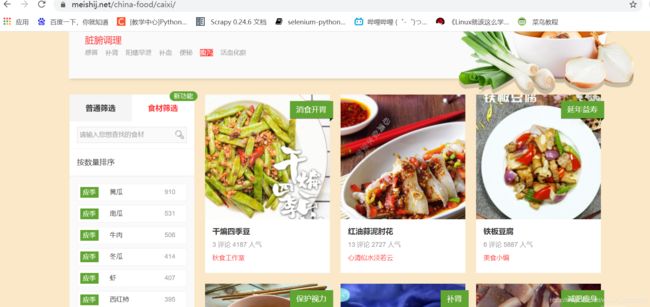
解释 一下,本次爬取网站为www.meishij.net/china-food/caixi/,一个美食网站,反爬措施比较少,方便新手学习。同时,对想学做菜的朋友们也有点用
Scrapy框架逻辑
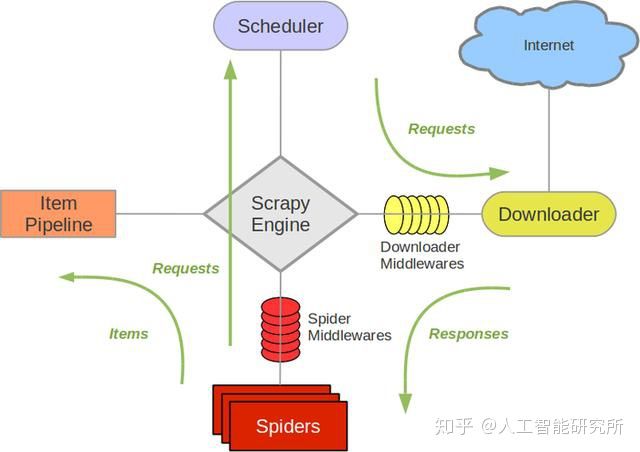
在这里,我就不解释这个框架图的意思了,网上有很多,摆出来主要方便后续解释运行逻辑。
想一想,如果我们不用scrapy框架来实现爬虫,应该是一个什么流程

因此,我们一步步通过这个流程,来看在scrapy的哪些位置进行相应的修改,处理
XXXXSpider.py
首先访问网站,第一步和第二步都在一个文件中,就是自己创建的spider中,笔者先用最基本的spider进行试验,等整个流程结束后,再用crawlspider做进阶试验
打开之前创建的picturespider.py文件
import scrapy
class PicturespiderSpider(scrapy.Spider):
name = 'picturespider'
allowed_domains = ['www.meishij.net/china-food/caixi/']
start_urls = ['http://www.meishij.net/china-food/caixi//']
def parse(self, response):
pass这里有三行代码
name = 'picturespider'
name是创建的spider的名字,必须唯一,是到时候启动spider进行爬取的参数
allowed_domains = ['www.meishij.net/china-food/caixi/']
可选。包含了spider允许爬取的域名(domain)列表(list)。 当
OffsiteMiddleware启用时, 域名不在列表中的URL不会被跟进。
start_urls = ['http://www.meishij.net/china-food/caixi//']
URL列表。当没有制定特定的URL时,spider将从该列表中开始进行爬取。 因此,第一个被获取到的页面的URL将是该列表之一。 后续的URL将会从获取到的数据中提取。
这行非必需品,但是如果要去掉,就必须要用替代品,怎么替代以及为什么要替代,请往下看
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
对spider来说,爬取的循环类似下文:
以初始的URL初始化Request,并设置回调函数。 当该request下载完毕并返回时,将生成response,并作为参数传给该回调函数。
spider中初始的request是通过调用
start_requests()来获取的。start_requests()读取start_urls中的URL, 并以parse为回调函数生成Request。在回调函数内分析返回的(网页)内容,返回
Item对象或者Request或者一个包括二者的可迭代容器。 返回的Request对象之后会经过Scrapy处理,下载相应的内容,并调用设置的callback函数(函数可相同)。在回调函数内,您可以使用 选择器(Selectors) (您也可以使用BeautifulSoup, lxml 或者您想用的任何解析器) 来分析网页内容,并根据分析的数据生成item。
最后,由spider返回的item将被存到数据库(由某些 Item Pipeline 处理)或使用 Feed exports 存入到文件中。
接下来,我将逐行对上述内容进行解释
start_urls
首先是第一条,这里的初始URL就是下文中的start_urls,后面的 ”spider中初始的request是通过调用 start_requests() 来获取的” 什么意思呢,这里也没有start_requests()
start_urls列表。当没有指定特定的url时,spider将从该列表中开始抓取,相当于爬虫访问的第一个网页,或者是第一批网页,因为这是一个列表,可以添加多个初始url
访问的网址有了,那么准备开始访问,而且访问的流程一般是用一个request去访问,然后返回得到一个response对象
现在的问题是谁去访问,怎么返回。这应该是个函数,是需要我们自己定义访问的函数嘛?对,但不完全对,也可以不自定义
在scrapy框架中已经给我们定义的默认的函数也就是上面的start_requests(),
构造request:
在scrapy中,如果我们使用 start_urls = ['http://www.meishij.net/china-food/caixi//']这个 列表作为起始的访问网址,且没有其他要求,框架会在暗地里使用一个叫做make_requests_from_url()方法(该方法的默认实现是使用start_urls的url生成request,该方法接受一个URL并返回用于爬取的
Request对象。 该方法在初始化request时被start_requests()调用,也被用于转化url为request。默认未被复写(overridden)的情况下,该方法返回的Request对象中,
parse()作为回调函数,dont_filter参数也被设置为开启)。该方法仅仅会被scrapy调用一次
request构造好了,谁用这个对象去访问呢,那就是start_requests()方法,这个方法也是框架内有的,不过在暗地里。
该方法的默认实现是使用 start_urls 的url生成Request,如果您想要修改最初爬取某个网站的Request对象,可以重写(override)该方法
我们如果不使用start_urls列表,我们可以直接越过上面两步,直接重写start_requests()方法,进行访问,并返回response对象,重写start_requests()一般也有两种写法,一种是使用上面的make_requests_from_url()方法,另一种就是不用,在此,我将不重写以及两种重写的方法都尝试一遍,
#重写start_request()方法,使用
import scrapy
class PicturespiderSpider(scrapy.Spider):
name = 'picturespider'
allowed_domains = ['www.meishij.net/china-food/caixi/']
start_urls = ['http://www.meishij.net/china-food/caixi//']
def parse(self, response):
print(response.status)#输出访问起始网址的状态码
![]()
状态码为200,访问成功
#重写方法,并使用make_requests_from_url()
import scrapy
class PicturespiderSpider(scrapy.Spider):
name = 'picturespider'
allowed_domains = ['www.meishij.net/china-food/caixi/']
#start_urls = ['http://www.meishij.net/china-food/caixi//']
def parse(self, response):
print(response.status)
#重写方法,并使用make_requests_from_url()
import scrapy
class PicturespiderSpider(scrapy.Spider):
name = 'picturespider'
allowed_domains = ['www.meishij.net/china-food/caixi/']
#start_urls = ['http://www.meishij.net/china-food/caixi//']
start_urls=[]
def start_requests(self):
url='http://www.meishij.net/china-food/caixi//'
yield self.make_requests_from_url(url)#该方法默认的回调函数即为下面的parse
def parse(self, response):
print(response.status)

#完全重写方法
import scrapy
class PicturespiderSpider(scrapy.Spider):
name = 'picturespider'
allowed_domains = ['www.meishij.net/china-food/caixi/']
#start_urls = ['http://www.meishij.net/china-food/caixi//']
start_urls=[]
def start_requests(self):
url='http://www.meishij.net/china-food/caixi//'
yield scrapy.Request(url,callback=self.parse)#与上一个方法相比,需要我们使用Request来生成request对象,并且指明回调函数的名字,因此,我们可以在这里可以不使用parse名字,而是自己定义
def parse(self, response):
print(response.status)

好了,三种方法,我都试过了,但是为什么我们要需要重写这个方法呢,就用默认的列表可以实现目的,另外两种(也可以说是一种方法)方法一般在什么情况下使用呢?
重写start_requests()情景:
一、伪装浏览器,防止反爬。
因为有很多网站是拒绝爬虫访问,所以要使用Request对象把爬虫伪装成浏览器访问,怎么伪装呢?比如说这样:
#设置用户代理为浏览器类型 headers = {"User-Agent" : "Mozilla***************************************"} def start_requests(self): url = "http://www.meishij.net/china-food/caixi//" yield Request(url, headers=self.headers, callback=self.parse)当然 ,还有很多其他可以加的,大家可以网上看怎么构造request对象的伪装信息,这是就不扩展了
二、urls列表内容太多,分页爬取。有时scrapy默认的start_requests无法满足我们的需求,例如分页爬取,那就要对它进行重写,添加更多操作。
比如我们想要爬取美食网中川菜的前10页就行了,毕竟,也学不完那么 多菜,我们怎么实现对这10个网址的访问呢(每页一个网址),有三种方法
1、是使用start_urls列表,在列表中存在10条网址
2、重写start_requests(),在方法中构造10个网址,逐条访问,如下:
import scrapy class PicturespiderSpider(scrapy.Spider): name = 'picturespider' allowed_domains = ['www.meishij.net/china-food/caixi/'] #start_urls = ['http://www.meishij.net/china-food/caixi//'] start_urls=[] def start_requests(self): base='https://www.meishij.net/china-food/caixi/chuancai/' for i in range(10): request_url=base+str(i) yield scrapy.Request(request_url,callback=self.parse) def parse(self, response): print(response.url)#打印访问的网址,看是否是前10页
这里,没有按顺序显示,为什么呢,因为scrapy是基于pythonr的twist异步框架写的,可以并行爬取,提高速度
(图片中后面加的参数 --nolog 的意思就是不要输出日志信息,方便查看输出内容,但是如果程序没有按照预定的目标输出,还是打开日志显示比较好,方便进行调试)
3、第三种方法就是在parse方法解析网页的过程中,跳转到下一页,这个等进入parse学习的时候,再举例

三、改写post请求。scrapy默认发起的是get请求,如果你想发起post请求,利用start_request方法,对该方法进行改写,进行post请求。
def start_requests(self): return [scrapy.FormRequest("http://www.example.com/login", formdata={'user': 'john', 'pass': 'secret'}, callback=self.logged_in)] def logged_in(self, response): # here you would extract links to follow and return Requests for # each of them, with another callback pass
四、实现动态入口。通过之前的学习我们知道scrapy是将start_urls作为爬取入口,而且每次都是直接硬编码进去一个或多个固定的URL,现在假设有这么个需求:爬虫需要先从数据库里面读取目标URL再依次进行爬取,这时候固定的start_urls就显得不够灵活了,好在scrapy允许我们重写start_requests方法来满足这个需求。
from scrapy.spider import BaseSpider#这个例子来自网上,仅作举例 from scrapy.http import Request import MySQLdb import os class PdfSpider(BaseSpider): name = "pdfspider" target_dir = "/home/newspace/pdfs" def start_requests(self): db = MySQLdb.connect(host="localhost", user="root", passwd="123456", db="scrapy", charset='utf8', use_unicode=False) cur = db.cursor() cur.execute("select url from tab_url") for url in cur.fetchall(): yield Request(url[0], self.parse) cur.close() db.close()
当然 ,还有一些 其他的用途,比较常见的,我就遇见这些,大家可以指点我一下,还有哪些常用的。
parse回调函数
当response没有指定回调函数时(在上面的start_request()方法中),该方法是Scrapy处理下载的response的默认方法。
parse 负责处理response并返回处理的数据以及(/或)跟进的URL。 Spider 对其他的Request的回调函数也有相同的要求。
该方法及其他的Request回调函数必须返回一个包含 Request 及(或) Item 的可迭代的对象。
现在,我们编写parse方法对网页进行解析,得到数据
首先,确定目标,看我们需要 哪些信息

从图片中,我们可以看出,对于每道菜,可以简单地提取以下几个信息:
name:菜名
steps:做菜需要 几步
costTIme;需要的时间
ways:烹饪的方法
tasty;口味
imgUrl:保存这道菜的图片url,方便我们后续下载
当然 我们可以再加一个内容:texturl(详情页的url地址)
接下来进入网页分析,然后编写解析代码

可以看出 每道菜对应一个div块,因此 我们首先要做的是就是怎么从网页中提取这些div块出来,然后再在每个div块中提取每道 菜的对应信息
selector选择器
当抓取网页时,你做的最常见的任务是从HTML源码中提取数据。现有的一些库可以达到这个目的:
- BeautifulSoup 是在程序员间非常流行的网页分析库,它基于HTML代码的结构来构造一个Python对象, 对不良标记的处理也非常合理,但它有一个缺点:慢。
- lxml 是一个基于 ElementTree (不是Python标准库的一部分)的python化的XML解析库(也可以解析HTML)。
Scrapy提取数据有自己的一套机制。它们被称作选择器(seletors),因为他们通过特定的 XPath 或者 CSS 表达式来“选择” HTML文件中的某个部分。
XPath 是一门用来在XML文件中选择节点的语言,也可以用在HTML上。 CSS 是一门将HTML文档样式化的语言。选择器由它定义,并与特定的HTML元素的样式相关连。
Scrapy选择器构建于 lxml 库之上,这意味着它们在速度和解析准确性上非常相似。
在scrapy的parse中,参数response对象以 .selector 属性提供了一个selector选择器,用于提取网页数据
我将使用 Scrapy shell (提供交互测试)和位于Scrapy文档服务器的一个样例页面,来解释如何使用选择器:
http://doc.scrapy.org/en/latest/_static/selectors-sample1.html
这里是它的HTML源码:
Example website





效果如下:

首先, 我们打开shell:
scrapy shell http://doc.scrapy.org/en/latest/_static/selectors-sample1.html
接着,当shell载入后,您将获得名为 response 的shell变量,其为响应的response, 并且在其 response.selector 属性上绑定了一个selector。

因为我们处理的是HTML,选择器将自动使用HTML语法分析。
那么,通过查看 HTML code 该页面的源码,我们构建一个XPath来选择title标签内的文字:
>>> response.selector.xpath('//title/text()')
[]
由于在response中使用XPath、CSS查询十分普遍,因此,Scrapy提供了两个实用的快捷方式: response.xpath() 及 response.css():
>>> response.xpath('//title/text()')
[]
>>> response.css('title::text')
[] 如你所见, .xpath() 及 .css() 方法返回一个类 SelectorList 的实例, 它是一个新选择器的列表。这个API可以用来快速的提取嵌套数据
为了提取真实的原文数据,你需要调用 .extract() 方法如下:
>>> response.xpath('//title/text()').extract()
[u'Example website']注意CSS选择器可以使用CSS3伪元素(pseudo-elements)来选择文字或者属性节点:
>>> response.css('title::text').extract()
[u'Example website']下面我总结 一下通过XPath和css解析获取数据的常见方式
对内容的提取一般有两个方面,一是页面标签中的内容如上面的text就是标签内的内容,二是标签中的属性值 ,比如 图片的href属性
XPath:
IN:response.xpath('//title/text()').extract()#titlte标签全网页唯一 OUT:[u'Example website'] IN: response.xpath('//title/text()') OUT:[] #提取标签属性值 IN:response.xpath('//base/@href').extract() OUT:[u'http://example.com/'] IN:response.xpath('//a[contains(@href, "image")]/@href').extract()#获取href属性为image的a标签 的href属性 OUT:[u'image1.html', u'image2.html', u'image3.html', u'image4.html', u'image5.html'] IN:dlist=response.selector.xpath("//div[@class='house_left left'])#提取class属性为house_left left的所有div 块,XPath中我常用这种解析 使用相对XPaths
记住如果你使用嵌套的选择器,并使用起始为
/的XPath,那么该XPath将对文档使用绝对路径,而且对于你调用的Selector不是相对路径。比如,假设你想提取在
元素中的所有
元素。首先,你将先得到所有的元素:>>> divs = response.xpath('//div')开始时,你可能会尝试使用下面的错误的方法,因为它其实是从整篇文档中,而不仅仅是从那些
元素内部提取所有的
元素:>>> for p in divs.xpath('//p'): # this is wrong - gets all
from the whole document ... print p.extract()下面是比较合适的处理方法(注意
.//pXPath的点前缀):>>> for p in divs.xpath('.//p'): # extracts all
inside ... print p.extract()另一种常见的情况将是提取所有直系
的结果:
>>> for p in divs.xpath('p'): ... print p.extract()CSS:
# css方法: # 提取标签内容 IN: response.css('title::text').extract() OUT:[u'Example website'] IN:response.css('title::text') OUT:[] # 提取标签属性值 IN:response.css('base::attr(href)').extract() OUT:[u'http://example.com/'] IN:dlist=response.css('li.houst_ctn') css提取嵌套的选择器我觉得是比XPath用得更顺手一点,比如拿我们川菜的来直接实战
CSS嵌套提取
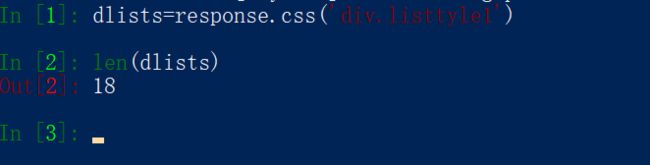
先看网页
我们发现所有的菜都是一个class属性为listtylel的div块,那我们能直接取这种div块嘛,先试一下(先切换shell,访问该川菜页面)
可以,正好对应第一页的18道 菜,但是有的时候,可能 要经过一次嵌套来获取这些列表块。
现在dlists 中的每一个元素都是一个selectorc对象
什么意思呢?就是我们对里面的内容还要再进行提取,不能直接拿到我们要数据
接下来开始提取
菜名name
分析:使用extract()提取的是一个列表,我们要取里面的值,有两种方法,一种是列表取值,另一种是还有一种方法是extract_first()方法取出列表的第一个值
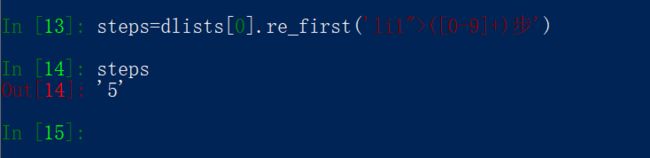
步骤steps
观察steps的位置,属于标签内容,但是内容中还有其他的,直接用取标签内容的方法,取出的值还有我们下一个要取的值,所以接下来的这四个值,我们可以用相同的办法获取:正则
selector对象可以使用正则进行内容匹配,函数 为.re_first()提取满足的第一个
因此 对于后面三个值,用同样的方法,就可以了,这里不一个一个进行,直接在下面代码里完整贴出
图片imgUrl
import scrapy class PicturespiderSpider(scrapy.Spider): name = 'picturespider' allowed_domains = ['www.meishij.net/china-food/caixi/'] #start_urls = ['http://www.meishij.net/china-food/caixi//'] start_urls=[] def start_requests(self): base='https://www.meishij.net/china-food/caixi/chuancai/' for i in range(1): if i >0:#不能用0,否则首页不对 request_url=base+str(i) else: request_url=base yield scrapy.Request(request_url,callback=self.parse) def parse(self, response): #print(response.url)#打印访问的网址,看是否是前10页 #提取每道菜对应的div块列表 dlists=response.css('div.listtyle1') for food in dlists: name=food.css('a::attr(title)').extract_first() steps=food.re_first('li1">([0-9]+)步') costTIme=food.re_first('大概([0-9]+)分钟') ways=food.re_first('li2">(.*?) /') tasty=food.re_first('li2">.*?/ (.*?)在这里需要 注意一点,就是在start_request()中构造url时,首页后面是不加0,否则不是我们需要 的当前页面,这一点需要 大家在实践中通过对当前网址检查,没有绝对
在最后我仅对name进行了输出







好了,现在已经 完成 对数据的解析
按照流程应该做是就是定义数据格式了,这个在items.py中
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class PictureItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name=scrapy.Field()
steps=scrapy.Field()
costTime=scrapy.Field()
ways=scrapy.Field()
tasty=scrapy.Field()
imgUrl==scrapy.Field()
在这里,我们需要 对前面的spider文件进行一下修改,通过这个 PictureItem来存储数据,具体如下:
import scrapy
from picture.items import PictureItem#如果这里导入出现 找不到该模块的错了,可能 是因为使用的集成开发环境对根目录的设定的原因
class PicturespiderSpider(scrapy.Spider):
name = 'picturespider'
allowed_domains = ['www.meishij.net/china-food/caixi/']
#start_urls = ['http://www.meishij.net/china-food/caixi//']
start_urls=[]
def start_requests(self):
base='https://www.meishij.net/china-food/caixi/chuancai/'
for i in range(1):
if i >0:#不能用0,否则首页不对
request_url=base+str(i)
else:
request_url=base
yield scrapy.Request(request_url,callback=self.parse)
def parse(self, response):
#print(response.url)#打印访问的网址,看是否是前10页
#提取每道菜对应的div块列表
dlists=response.css('div.listtyle1')
for food in dlists:
item=PictureItem()
item['name']=food.css('a::attr(title)').extract_first()
item['steps']=food.re_first('li1">([0-9]+)步')
item['costTime']=food.re_first('大概([0-9]+)分钟')
item['ways']=food.re_first('li2">(.*?) /')
item['tasty']=food.re_first('li2">.*?/ (.*?)
如果出现 No module named item的错误,可能主要有以下几个原因:
1.爬虫名字和项目名字一样,导致导入模块时出错:改爬虫或者项目名称
2.模块不存在:检查你的项目中的items,看看有没有出错
3.模块没有保存:在编辑好items模块时,记得运行编译
4.模块名字和引入的不一样:自行检查
5.手动添加自己创建的scrapy文件夹的路径:例如
import sys
sys.path.append(文件路径)
现在该是数据的存储,我将其放入mysql数据据中,在pipelines.py文件中
Pipelines.py
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。
每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。
以下是item pipeline的一些典型应用:
- 清理HTML数据
- 验证爬取的数据(检查item包含某些字段)
- 查重(并丢弃)
- 将爬取结果保存到数据库中
编写你自己的item pipeline很简单,每个item pipiline组件是一个独立的Python类,同时必须实现以下方法:
process_item(item, spider)
每个item pipeline组件都需要调用该方法,这个方法必须返回一个 Item (或任何继承类)对象, 或是抛出 DropItem 异常,被丢弃的item将不会被之后的pipeline组件所处理。
参数:
- item (
Item 对象) – 被爬取的item
- spider (
Spider 对象) – 爬取该item的spider
此外,他们也可以实现以下方法:
open_spider(spider)
当spider被开启时,这个方法被调用。
close_spider(spider)
当spider被关闭时,这个方法被调用
在本例中,我将实现两个pipeline类,一个用于将存储到mysql数据库,另一个用于保存菜品的图片,将使用到scrapy框架自带的一个图片下载类
MySqlPipeline类
(现在应该已经 在mysql数据库中创建 了一个名为eat_menu的数据库,和一个库中一个名为menus的表)

先使用硬编码 的方式连接数据库
from scrapy import Request
import pymysql
class MySqlPipeline(object):
"""docstring for MySqlPipeline"""
#mysql 连接方式
def open_spider(self,spider):
#连接数据库
self.connect=pymysql.connect(
host='127.0.0.1',
port=3306,
db='eat_menu',
user='root',
passwd='Woshi123',
charset='utf8',
use_unicode=True)
self.cursor=self.connect.cursor()
或者通过从setting.cfg配置文件中读取信息的方式来动态连接
def __init__(self,host,user,password,database,port):
self.host = host
self.user = user
self.password = password
self.database = database
self.port = port
@classmethod
def from_crawler(cls,crawler):
return cls(
host = crawler.settings.get("MYSQL_HOST"),
user = crawler.settings.get("MYSQL_USER"),
password = crawler.settings.get("MYSQL_PASSWD"),
database = crawler.settings.get("MYSQL_DBNAME"),
port = crawler.settings.get("MYSQL_PORT"),
)
def open_spider(self, spider):
'''负责连接数据库'''
self.db = pymysql.connect(host=self.host,user=self.user,passwd=self.password,db=self.database,charset="utf8",port=self.port)#这里必须要用指名的参数传入方式,否则可能会报错
self.cursor = self.db.cursor()
def process_item(self,item,spider):
self.cursor.execute(
"insert into menus(name,steps,costTime,ways,tasty) values ('%s','%s','%s','%s','%s')"%(item['name'][0],item['steps'],item['costTime'],item['ways'],item['tasty']))
self.db.commit()
return item
def close_spider(self,spider):
self.db.close()
现在到最后一步了,就是配置settings.cfg
settings.cfg
对于这个 配置文件的修改,最简单的来说,我们应该有下几个方面:
1.君子协议。原来的这个值为True,我们需要修改为False,否则很多的网站我们都无法爬取

2.重写header信息。

3.爬虫中间件和下载中间件。这两个地方可以用来开启自己写的中间件(不仅得有装备,还要给装备开关打开,才能使用)
4.开启pipeline的使用。后面的数字代表了执行的先后顺序,如果定义有不同的pipeline,用于规定先后顺序,越小越先执行,比如,我们如果再定义一个用于数据清洗的pipline,则序号就应该比它大

5.设置数据库连接的参数。IMAGES_STORE是设置菜品图片存储的位置,稍后写imagePipeline类时会用到
IMAGES_STORE = 'D:\\Spide\\picture'
# IMAGES_THUMBS = {
# 'small': (50, 50),
# 'big': (270, 270),
# }
MYSQKL_HOST= 'localhost'
MYSQL_DBNAME= 'eat_menu'
MYSQL_USER= 'root'
MYSQL_PASSWD='Woshi123'
MYSQL_PORT = 3306
这样,基本上就算是大功告成,现在试运行一下

再打开数据库瞧瞧

现在我们再回过头看前面 还有哪些坑
1.在parse方法中实现翻页,构造url继续访问
import scrapy
from picture.items import PictureItem
class PicturespiderSpider(scrapy.Spider):
name = 'picturespider'
allowed_domains = ['www.meishij.net/china-food/caixi/']
start_urls = ['http://www.meishij.net/china-food/caixi//']
page=2
# start_urls=[]
# def start_requests(self):
# base='https://www.meishij.net/china-food/caixi/chuancai/'
# for i in range(1):
# if i >0:#不能用0,否则首页不对
# request_url=base+str(i)
# else:
# request_url=base
# yield scrapy.Request(request_url,callback=self.parse)
def parse(self, response):
#print(response.url)#打印访问的网址,看是否是前10页
#提取每道菜对应的div块列表
dlists=response.css('div.listtyle1')
for food in dlists:
item=PictureItem()
item['name']=food.css('a::attr(title)').extract_first()
item['steps']=food.re_first('li1">([0-9]+)步')
item['costTime']=food.re_first('大概([0-9]+)分钟')
item['ways']=food.re_first('li2">(.*?) /')
item['tasty']=food.re_first('li2">.*?/ (.*?)
输出翻页的网址,看是否正确

2.实现用于保存图片的imgPipeline
3.spider中间件和下载中间件
4.crawlspider类的使用
5.代理池的使用
6.分布式爬虫
7.selenium的使用(解决Ajex加载和登录检验)
上面的剩下6个,等知识储备够了,再来详写。