Flink的DataStream API的使用------输出算子(Sink)
Flink的DataStream API的使用
文章目录
- ***Flink的DataStream API的使用***
-
- 一、Flink的DataStream API的使用------执行环境(Execution Environment)
- 二、Flink的DataStream API的使用------源算子(Source)
- 三、Flink的DataStream API的使用------转换算子(Transformation)
- 四、Flink的DataStream API的使用------输出算子(Sink)
-
- 1、输出到文件
- 2、☆输出到 Kafka☆
- 3、输出到 Redis
- 4、输出到 Elasticsearch
- 5、输出到 MySQL(JDBC)
一、Flink的DataStream API的使用------执行环境(Execution Environment)
执行环境这一节请点击超链接阅读https://blog.csdn.net/weixin_44328192/article/details/126952164
二、Flink的DataStream API的使用------源算子(Source)
源算子这一节请点击超链接阅读
https://blog.csdn.net/weixin_44328192/article/details/126988164
三、Flink的DataStream API的使用------转换算子(Transformation)
转换算子这一节请点击超链接阅读
https://blog.csdn.net/weixin_44328192/article/details/127049140
四、Flink的DataStream API的使用------输出算子(Sink)

Flink 作为数据处理框架,最终还是要把计算处理的结果写入外部存储,为外部应用提供支持,我们已经了解了Flink 程序如何对数据进行读取、转换等操作,最后一步当然就应该将结果数据保存或输出到外部系统了。
1、输出到文件
最简单的输出方式,当然就是写入文件了。对应着读取文件作为输入数据源,Flink 本来也有一些非常简单粗暴的输出到文件的预实现方法:如 writeAsText()、writeAsCsv(),可以直接将输出结果保存到文本文件或 Csv 文件。但我们知道,这种方式是不支持同时写入一份文件的;所以我们往往会将最后的 Sink 操作并行度设为 1,这就大大拖慢了系统效率;而且对于故障恢复后的状态一致性,也没有任何保证。所以目前这些简单的方法已经要被弃用。
Flink 为此专门提供了一个流式文件系统的连接器:StreamingFileSink,它继承自抽象类RichSinkFunction,而且集成了 Flink 的检查点(checkpoint)机制,用来保证精确一次(exactly once)的一致性语义。
StreamingFileSink 为批处理和流处理提供了一个统一的 Sink,它可以将分区文件写入 Flink支持的文件系统。它可以保证精确一次的状态一致性,大大改进了之前流式文件 Sink 的方式。它的主要操作是将数据写入桶(buckets),每个桶中的数据都可以分割成一个个大小有限的分区文件,这样一来就实现真正意义上的分布式文件存储。我们可以通过各种配置来控制“分桶”的操作;默认的分桶方式是基于时间的,我们每小时写入一个新的桶。换句话说,每个桶内保存的文件,记录的都是 1 小时的输出数据。
StreamingFileSink 支持行编码(Row-encoded)和批量编码(Bulk-encoded,比如 Parquet)格式。这两种不同的方式都有各自的构建器(builder),调用方法也非常简单,可以直接调用StreamingFileSink 的静态方法:
⚫ 行编码:StreamingFileSink.forRowFormat(basePath,rowEncoder)。
⚫ 批量编码:StreamingFileSink.forBulkFormat(basePath,bulkWriterFactory)。
在创建行或批量编码 Sink 时,我们需要传入两个参数,用来指定存储桶的基本路径(basePath)和数据的编码逻辑(rowEncoder 或 bulkWriterFactory)。
测试代码:
public class SinkToFileTest {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./home", 3000L),
new Event("Bob", "./cart", 3500L),
new Event("Alice", "./home", 3600L)
);
StreamingFileSink<String> stringStreamingFileSink = StreamingFileSink.<String>forRowFormat(new Path("./output"), new SimpleStringEncoder<>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withMaxPartSize(1024 * 1024 * 1024)
.withRolloverInterval(TimeUnit.MINUTES.toMillis(15))
.withInactivityInterval(TimeUnit.MINUTES.toMillis(5))
.build()
)
.build();
stream.map(data -> data.toString())
.addSink(stringStreamingFileSink);
env.execute();
}
}
这里我们创建了一个简单的文件 Sink,通过.withRollingPolicy()方法指定了一个“滚动策略”。“滚动”的概念在日志文件的写入中经常遇到:因为文件会有内容持续不断地写入,所以我们应该给一个标准,到什么时候就开启新的文件,将之前的内容归档保存。也就是说,上面的代码设置了在以下 3 种情况下,我们就会滚动分区文件:
⚫ 至少包含 15 分钟的数据
⚫ 最近 5 分钟没有收到新的数据
⚫ 文件大小已达到 1 GB
2、☆输出到 Kafka☆
Kafka 是一个分布式的基于发布/订阅的消息系统,本身处理的也是流式数据,所以跟Flink“天生一对”,经常会作为 Flink 的输入数据源和输出系统。Flink 官方为 Kafka 提供了 Source和 Sink 的连接器,我们可以用它方便地从 Kafka 读写数据。如果仅仅是支持读写,那还说明不了 Kafka 和 Flink 关系的亲密;真正让它们密不可分的是,Flink 与 Kafka 的连接器提供了端到端的精确一次(exactly once)语义保证,这在实际项目中是最高级别的一致性保证。
现在我们要将数据输出到 Kafka,整个数据处理的闭环已经形成,所以可以完整测试如下:
(1)添加 Kafka 连接器依赖
由于我们已经测试过从 Kafka 数据源读取数据,连接器相关依赖已经引入,这里就不重复介绍了。
(2)启动 Kafka 集群
(3)编写输出到 Kafka 的示例代码
我们可以直接将用户行为数据保存为文件 clicks.csv,读取后不做转换直接写入 Kafka,主题(topic)命名为“clicks”。
测试代码:
public class SinkToKafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.从Kafka中读取数据
Properties properties = new Properties();
properties.setProperty("bootstrap.server","localflink:9092");
properties.setProperty("group.id", "consumer-group");
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("auto.offset.reset", "latest");
DataStreamSource<String> kafkaStream = env.addSource(new FlinkKafkaConsumer<String>("clicks", new SimpleStringSchema(), properties));
//2.用Flink进行转换处理
SingleOutputStreamOperator<String> result = kafkaStream.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
String[] fields = value.split(",");
return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim())).toString();
}
});
//3.结果数据写入kafka
result.addSink(new FlinkKafkaProducer<String>("bigdata01:9092","events",new SimpleStringSchema()));
env.execute();
}
}
这里我们可以看到,addSink 传入的参数是一个 FlinkKafkaProducer。这也很好理解,因为需要向 Kafka 写入数据,自然应该创建一个生产者。FlinkKafkaProducer 继承了抽象类TwoPhaseCommitSinkFunction,这是一个实现了“两阶段提交”的 RichSinkFunction。两阶段提交提供了 Flink 向 Kafka 写入数据的事务性保证,能够真正做到精确一次(exactly once)的状态一致性。
3、输出到 Redis
Redis 是一个开源的内存式的数据存储,提供了像字符串(string)、哈希表(hash)、列表(list)、集合(set)、排序集合(sorted set)、位图(bitmap)、地理索引和流(stream)等一系列常用的数据结构。因为它运行速度快、支持的数据类型丰富,在实际项目中已经成为了架构优化必不可少的一员,一般用作数据库、缓存,也可以作为消息代理。
Flink 没有直接提供官方的 Redis 连接器,不过 Bahir 项目还是担任了合格的辅助角色,为我们提供了 Flink-Redis 的连接工具。
(1)导入的 Redis 连接器依赖
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.1.0</version>
</dependency>
(2)启动 Redis 集群
这里我们为方便测试,只启动了单节点 Redis。
(3)编写输出到 Redis 的示例代码
public class SInkToRedis {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.addSource(new ClickSource());
//创建一个jedis连接配置
FlinkJedisPoolConfig config = new FlinkJedisPoolConfig.Builder()
.setHost("bigdata01")
.build();
//写入redis
stream.addSink(new RedisSink<Event>(config, new MyRedisMapper()));
env.execute();
}
//自定义类实现RedisMapper接口
public static class MyRedisMapper implements RedisMapper<Event>{
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.HSET,"clicks");
}
@Override
public String getKeyFromData(Event event) {
return event.user;
}
@Override
public String getValueFromData(Event event) {
return event.url;
}
}
}
4、输出到 Elasticsearch
ElasticSearch 是一个分布式的开源搜索和分析引擎,适用于所有类型的数据。ElasticSearch有着简洁的 REST 风格的 API,以良好的分布式特性、速度和可扩展性而闻名,在大数据领域应用非常广泛。
Flink 为 ElasticSearch 专门提供了官方的 Sink 连接器,Flink 1.13 支持当前最新版本的ElasticSearch。
(1)添加 Elasticsearch 连接器依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch7_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
(2)启动 Elasticsearch 集群
(3)编写输出到 Elasticsearch 的示例代码
public class SinkToEs {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./home", 3000L),
new Event("Bob", "./cart", 3500L),
new Event("Alice", "./home", 3600L)
);
//定义hosts的列表
ArrayList<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("bigdata01",9200));
//定义ElasticsearchSinkFunction
ElasticsearchSinkFunction<Event> elasticsearchSinkFunction = new ElasticsearchSinkFunction<Event>() {
@Override
public void process(Event element, RuntimeContext ctx, RequestIndexer indexer) {
HashMap<String, String> map = new HashMap<>();
map.put(element.user, element.url);
//创建一个IndexRequest
IndexRequest request = Requests.indexRequest()
.index("clicks")
.type("type")
.source(map);
indexer.add(request);
}
};
//写入redis
stream.addSink(new ElasticsearchSink.Builder<>(httpHosts,elasticsearchSinkFunction).build());
env.execute();
}
}
5、输出到 MySQL(JDBC)
关系型数据库有着非常好的结构化数据设计、方便的 SQL 查询,是 很多企业中业务数据存储的主要形式。MySQL 就是其中的典型代表。尽管在大数据处理中直接与 MySQL 交互的场景不多,但最终处理的计算结果是要给外部应用消费使用的,而外部应用读取的数据存储往往就是 MySQL。所以我们也需要知道如何将数据输出到 MySQL 这样的传统数据库。
写入数据的 MySQL 的测试步骤如下。
(1)添加依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
(2)启动 MySQL,在 database 库下建表 clicks
mysql> create table clicks(
-> user varchar(20) not null,
-> url varchar(100) not null);

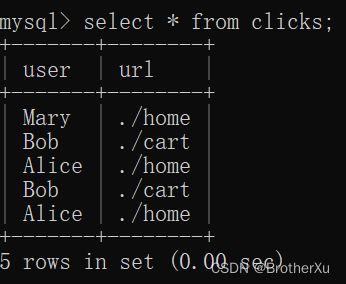
(3)编写输出到 MySQL 的示例代码
public class SinkToMySql {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./home", 3000L),
new Event("Bob", "./cart", 3500L),
new Event("Alice", "./home", 3600L)
);
stream.addSink(JdbcSink.sink(
"INSERT INTO clicks (user, url) VALUES (?, ?)",
(statement, event) -> {
statement.setString(1, event.user);
statement.setString(2, event.url);
},
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3306/test")
.withDriverName("com.mysql.cj.jdbc.Driver")
.withUsername("root")
.withPassword("LZHX2000")
.build()
));
env.execute();
}
}
(4)运行代码,用客户端连接 MySQL,查看是否成功写入数据。