第三章:odoo12开发之模型 -结构化应用数据
主要学习内容:
①、创建模型
②、创建字段
③、模型间的关系
④、计算字段
⑤、模型约束
1、创建模型:
①、模型属性:
模型类的常见属性:
A、_name 是我们创建办的 Odoo 模型的内部标识符,在创建新模型时必填;
B、_description 是用户模块记录标题,用户界面可查看模型显示;
C、_order 设置浏览模型记录时或列表视图的默认排序,其值为 SQL 语句中 order by 使用的字符串,可以传入符合SQL语法的任意值,可支持many-2-one字段名;
因此我们在之前定义的“library.book”模型中添加 _order 属性来默认图书名排序,然后按出版日期倒序排(新出版的在前):
class Book(models.Model):
_name = 'library.book'
_description = 'Book'
_order = 'name,date_published desc'

排序效果如下:

补充的部分属性:
A、_rec_name 在从关联字段中引用时作为记录描述,默认使用模型中常用的 name 字段,也可以指定任意其他字段;
B、table 是模型对应的数据表名,默认表名由 ORM 通过替换模块名中的点换为下划线来自定义(“.”换为“”)也可通过该属性指定表名;
C、_log_access=False 用于设置不自动创建审计追踪字段:create_uid、create_date、write_uid和write_date。
D、_auto=False 用于设置不自动创建模型对应的数据表,如有需要,可通过重载init()方法来创建数据库对象:数据表或试图;
E、_inherit和_inherits 属性主要用于继承模块;
②、模型名的定义:
A、在上一章节中我们继承model.Model类创建了“Book”类,且Odoo模型命名为:“library.book” ,Odoo的模型保存在中央注册表中(central registry)中,可以通过 env 环境对象获取,它是数据库保存所有可用模型类引用的字典,可通过聚义的代码“self.env[‘library.book’]”来获取标识 library.book 模型的模型类;
B、模型名必须全局唯一,类的命名规范则使用驼峰命名法;
③、临时模型和抽象模型:
A、临时模型继承(models.TransientModel类)主要用于向导式交互,数据会保存到数据库,但是是临时性的,会定时清空数据;例如:参数设置–>翻译–>加载翻译;
B、抽象模型继承(models.AbstractModel类) 不带有数据存储。抽象模型用作可复用的功能集,与使用 Odoo 继承功能的其他模型配合使用;
④、检查已有模型:
启动开发者模式,访问:参数设置–>技术–>模型:
点击对应模型即可查看相关详情表单信息:


2、创建字段
创建新模型后的第一步是添加字段,目前Odoo中常用字段如:文本字符串、整型、浮点型、布尔型、日期、日期时间、图片、二进制数据;
①、基础字段类型:
class Book(models.Model):
_name = 'library.book'
_description = 'Book'
_order = 'name, date_published desc'
# 字符串字段
name = fields.Char(string='书名',required=True)
isbn = fields.Char(string='ISDN')
book_type = fields.Selection(
[('paper','简装书'),
('hard','精装版'),
('electronic','电子书'),
('other','其他')],
'Type')
notes = fields.Text("内部注释")
descr = fields.Html("说明")
# 数字类字段
copies = fields.Integer(default=1)
avg_rating = fields.Float('Average Rating',(3,2))
price = fields.Monetary('Price','currency_id')
currency_id = fields.Many2one('res.currency')
publisher_id = fields.Many2one('res.partner',string='版社') # 出版公司多对一关联
author_ids = fields.Many2many('res.partner',string="作者") # 作者多对多关联
# 日期和时间日期
date_published = fields.Date(string='出版时间')
last_borrow_date = fields.Datetime(
'Last Borrowed On',
default=lambda self: fields.Datetime.now())
# 其他字段
active = fields.Boolean(string='是否在售',default=True)
image = fields.Binary(string='图书封面') # 存储图书封面的二进制字段
相关的字段说明
⚪ Char(string)是一个单行文本,唯一位置参数是string字段标签;
⚪ Text(string)是一个多行文本,唯一位置参数是string字段标签;
⚪ Selection(selection,string)是一个下拉选择列表。选项位置是一个[( ‘value’ , ‘Title’ ),]元组列表。元组第一个元素是存储在数据库中的值,第二个元素是展示在用户界面中的描述。该列表可由其他模块使用selection_add关键字参数扩展;
⚪ Html(string)存储为文本字段,但又针对用户界面HTML内容展示的特殊处理;
⚪ Integer(string)仅需字段标题字符串参数;
⚪ Float(string,digits)带有第二个可选参数digits,该字段是一个指定字段精度的(x,y)元组,x是字数总长,y是小数位;
⚪ Monetary(string,currency_field)与浮点字段类似,但带有货币的特殊处理。第二个参数currency_field用于存储所使用货币,默认应传入currency_id字段;
⚪ Date(string)和Datetime(string)字段只需一个字符串文本位置参数;
⚪ Boolean(string) 的值为True或False,可传入一个字符串文本位置参数;
⚪ Binary(string)存储文件类二进制文件,只需一个字符串文本位置参数,他可由base64编码字符串进行处理;
文本字符串:Char、Text和Html有一些特有属性:
⚪ size(Char)设置最大允许尺寸。无特殊需求不建议使用;
⚪ translate使用得字段内容可翻译,带有针对不同语言的不同值;
⚪ trim默认值为True,启动在网络客户端中自动去除周围的空格,可通过设置trim=false来取消;
②、常用字段属性:
⚪ string是字段的默认标签,在用户界面中使用。除Selection和关联字段外,它都是第一个位置参数,所以大多数情况下它用作关键字参数。如未传入,将由字段名自动生成。
⚪ default设置字段默认值。可以是具体值(如 active字段中的default=True),或是可调用引用,有名函数或匿名函数均可。
⚪ help提供 UI 中鼠标悬停字段向用户显示的提示文本。
⚪ readonly=True会使用户界面中的字段默认不可编辑。在 API 层面并没有强制,模型方法中的代码仍然可以向其写入。仅针对用户界面设置。
⚪ required=True使得用户界面中字段默认必填。这通过在数据库层面为列添加NOT NULL 约束来实现。
⚪ index=True为字段添加数据库索引,让搜索更快速,但同时也会部分降低写操作速度。
⚪ copy=False让字段在使用 ORM copy()方法复制字段时忽略该字段。除 to-many 关联字段外,其它字段值默认会被复制。
⚪ groups可限制字段仅对一些组可访问并可见。值为逗号分隔的安全组XML ID列表,如groups=’base.group_user,base.group_system’。
⚪ states传入依赖 state字段值的 UI 属性的字典映射值。可用属性有readonly, required和invisible,例如states={‘done’:[(‘readonly’,True)]}。
以下字段属性关键字参数的使用示例:
name = fields.Char(string='书名',
default=None,
index=True,
help='书的名字',
readonly=False,
required=True,
translate=False,)
如上所述“default”属性可带有固定值外,还可以调用引用函数来自动计算默认值,还可以使用匿名函数,如下就是计算当前日期和时间默认值的常用示例:
last_borrow_date = fields.Datetime(
'Last Borrowed On',
default=lambda self: fields.Datetime.now())
也可以是一个函数的引用,或待定义函数名字符串:
last_borrow_date = fields.Datetime(
'Lask Borrowed On',
default='_default_last_borrow_date',
)
def _default_last_borrow_date(self):
return fields.Datetime.now()
当模块数据结构在不同版本中变更时以下两个属性非常有用:
⚪ deprecated = True 在字段被使用时记录一条 warning 日志;
⚪ oldname = ‘field’ 是在新版本中重命名字段时使用,可在升级模块时将老字段中的数据自动拷贝到新字段中;
③、特殊字段名:
当模型中没有设置_log_access=False都会在新模型中自动创建:
⚪ create_uid 为创建记录的用户;
⚪ create_date 是记录创建的日期和时间;
⚪ write_uid 是最后写入记录的用户;
⚪ write_date 是最后修改记录的日期和时间;
一些字段名被保留并且不能再其他地方使用:
⚪ name (通常为 Char)默认作为记录的显示名称。通过是一个 Char,但也可以是 Text 或Many2one字段类型。用作显示名的字段可修改为_rec_name模型属性。
⚪ active (Boolean型)允许我们关闭记录。带有active=False的记录会自动从查询中排除掉。可在当前上下文中添加{‘active_test’: False} 来关闭这一自动过滤。可用作记录存档或假删除(soft delete)。
⚪ state (Selection类型) 表示记录生命周期的基本状态。它允许使用states字段属性来根据记录状态以具备不同的 UI 行为。动态修改视图:字段可在特定记录状态下变为readonly, required或invisible。
⚪ parent_id和parent_path Integer和Char型)对于父子层级关系具有特殊意义。
3、模型间的关系
以图书应用为例,图书模型中就有如下关系:
⚪ 每本书有一个出版商,这是一个many-2-one关联,在数据库引擎中通过外键实现。反过来则是one-2-many关联,表示一个出版商可出版多本书。
⚪ 每本书可以有多名作者。这是一个many-2-many关联,反过来还是many-2-many关联,因为一个作者也可以有多本书。
①、Many-2-one:
Many-2-one关联是对其它模型中记录的引用,例如在图书馆模型中,publisher_id表示图书出版商,是对partner记录的一个引用:
publisher_id = fields.Many2one('res.partner',string='出版商')
Many-2-one字段的第一个位置是关联的模型,第二个参数是字段标签(string关键字参数);
Many-2-one模型字段在数据表中创建一个字段,并带有指向关联表的外键,其中为关联记录的数据库ID,以下是many-2-one字段可用的关键字参数:
⚪ ondelete 定义关联记录删除时执行的操作:
A.set null(默认值):关联字段删除时会置为空值;
B.restricted:抛出错误阻止删除;
C.cascade:在关联记录删除时同时删除当前记录;
⚪ context是一个数据字典,可在浏览关联时为网页客户端传递信息,比如设置默认值;
⚪ domain 是一个域表达式:使用一个元组列表过滤记录来作为关联记录选项;
⚪ auto_join=True允许ORM在使用关联进行搜索时使用SQL连接,使用时会跳过访问安全规则,用户可以访问安全规则不允许其访问的关联记录,但这样SQL的查询会更有效率且更快;
⚪ delegate=True 创建一个关联记录的代理继承。使用时必须设置required=True和ondelete=‘cascade’;
②、One-2-many反向关联:
one-2-many关联是many-2-one的反向关联,他列出引用该记录的关联模型记录,比如在图书模型中,publisher_id与parnter模型时一个many-2-one关联。这说明partner与图书馆可以有一个one-2-many的反向关联,列出每个出版商出版的图书;
我们需要创建partner模型,在library_app/models/res_partner.py文件中添加如下代码:
class Partner(models.Model):
_inherit = 'res.partner'
published_book_ids = fields.One2many(
'library.book',
'publisher_id',
string='Published Books'
)
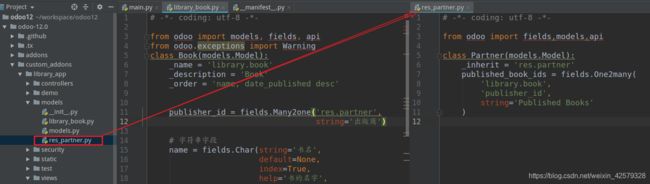
创建新模型后,不要忘记在library_app/models/init.py中导入该文件:
from . import library_book
from . import res_partner
One2many字段接收三个位置参数:
⚪ 关联模型
⚪ 引用该记录的模型字段(inverse_name关键字参数)
⚪ 字段标签(string关键字参数)
其它可用的关键字参数与many-2-one字段相同:context、domain和ondelete(此处作用于关联中的many这一方)
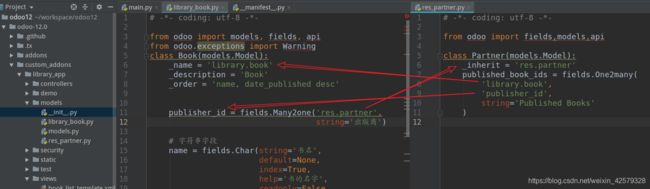
③、Many-2-many关联:
在两端都存在2-many关联时使用many-2-many关联,以图书为例,书和作者之间是many-2-many关联:一本书可以有多个作者,一个作者可以有多本书。图书馆有一个“library.book”模型:
class Book(models.Model):
_name = 'library.book'
_description = 'Book'
_order = 'name, date_published desc'
author_ids = fields.Many2many('res.partner',string="作者")
在作者端,我们也可以为res.partner添加一个反向关联:
class Partner(models.Model):
_inherit = 'res.partner'
book_ids = fields.Many2many('library.book',
string='图书作者')
Many2many最少要包含一个关联模型位置参数,推荐为字段标签提供一个string参数;
从数据库层面上来看,many-2many关联不会再已有表中添加任何列,会自动创建一张表,来存储两张表的ID,例如我们的图书和作者关联,表名应为 library_book_res_partner_rel。
PostgreSQL数据库63个字符的上限,如果我们要重写这种默认的表名就需要如下的操作:
# Book ---- Authors关联
author_ids = fields.Many2many(comodel_name='res.partner', #关联模型
relation='library_book_res_partner_rel',#关联表名
column1='a_id',#本记录关联表字段
column2='p_id',#关联记录关联表字段
string="作者") # string标签文本
与one-to-many relational字段相似,many-to-many 字段还可以使用context, domain和auto_join这些关键字参数。
④、层级关联
父子树状使用同一模型中 many-2-one 关联表示,来将每条记录引用其父级,反向的one-2-many关联对应记录的子级;
Odoo通过域表达式附件的 child_of 和 parent_of 操作符改良了对这层级数据结构的支持。只要这些模型有 parent_id 字段就可以使用这些操作符;
通过设置 _parent_store=True 和添加 parent_path 帮助字段可结块层级数的查询速递,该字段存储用于加速查询速度的层级树结构信息;
代码演示,我们为图书应用添加一个分类,在 “library_app/models/library_book_category.py”文件中添加如下代码:
from odoo import api,fields,models
class BookCategory(models.Model):
_name = 'library.book.category'
_description = 'Book Category'
_parent_store = True
name = fields.Char(translate=True,required=True)
parent_id = fields.Many2one(
'library.book.category',
'Parent Category',
ondelete='restrict')
parent_path = fields.Char(index=True)
child_ids = fields.One2many(
'library.book.category',
'parent_id',
'Subcategories')
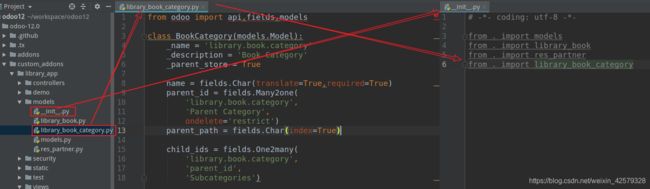
代码释义:
⚪ 定义了一个基本模型,包含引用父级记录的 parent_id 字段。
⚪ 为启动层级索引来加快树级搜索,添加一个 _parent_store=True模型属性;
⚪ 使用该属性必须要添加且必须要 parent_path 字段。引用父级的字段名应为 parent_id ,但如果声明了可选的 _parent_name 模型属性,则可以使用任意其他字段名;
特别提醒:“library_app/models/init.py”文件中导入创建的的模型,上图中以标记;
⑤、引用字段的弹性关联
普通关联字段指定固定的引用模型,但 Reference 字段类型不受这一限制,它支持弹性关联,因此相同字段不用限制只指向相同的目标类型。
代码示例,我们使用图书分类模型来添加引用重点图书或作者。因此该字段可引用图书或partner:
class BookCategory(models.Model):
_name = 'library.book.category'
......
highlighted_id = fields.Reference(
[('library.book','Book'),('res.partner','Author')],
'Category Highlight'
)
代码释义:
该段代码定义和selection字段相似,但这里选择项为该字段中可以使用的模型。在用户界面中,用户会选择列表中的模型,然后选择模型中的指定记录;
引用字段的一些其它技术细节:
⚪ 引用字段在数据库中以 model,id 字符串形式存储;
⚪ read()方法供外部应用使用,以格式化的(‘model_name’,id)元组返回,而不是常用的 many-2-one 字段的(id,‘display_name’)形式;
4、计算字段:
⚪ 字段值除普通的读取数据库中存储值外,还可自动由函数计算。
⚪ 计算字段的声明和普通字段相似,但有一个额外的 compute 参数来定义用于计算的函数;
需求说明:
图书有出版商,我们的例子是在图书表单中添加出版商的国别,实现该功能,我们会使用基于 publisher_id 的计算字段,将会从出版商的 country_id 字段中获取;
编辑 ‘library_app/models/library_book.py’文件中添加如下代码:
class Book(models.Model):
_name = 'library.book'
......
publisher_country_id = fields.Many2one(
'res.country',string='Publisher Country',
compute='_compute_publisher_country'
)
@api.depends('publisher_id.country_id')
def _compute_publisher_country(self):
for book in self:
book.publisher_country_id = book.publisher_id.country_id
代码释义:
⚪ 以上代码添加了一个 publisher_country_id 字段,和一个计算其值的 _compute_publisher_country 方法。方法名作为字符串参数传入字段中,但也可以传递一个可调用引用(方法名,不带引号),但是方法必须在字段之前定义;
⚪ 如果计算依赖了其他字段的话就需要使用 @api.depends 装饰器,通常都会依赖其他字段。它告诉服务器何时重新计算或缓存值。参数可接受一个或多个字段名,点号标记可用于了解字段关联。如上述代码,只要图书 “publisher_id”的“country_id”变更了就会重新进行计算;
⚪ self参数是要操作的字符集对象。我们需要对其遍历来作用于每天记录。计算值通过常用(写)操作来设置,本例中计算相当简单,我们为其分配当前图书的 publisher_id.country_id 值;
⚪ 同一个方法可以在多个字段上使用,则在多个字段上添加 compute 字段,其将会为所以计算字段分配值;
界面显示:

①、搜索和写入计算字段:
A、写入计算字段
计算字段的值可读取但不可以写入和搜索,默认情况下计算字段是实时计算的,而不存储在数据库中,这也是无法像普通字段那样进行搜索的原因;
解决方法:
可通过实现特殊方法来开启搜索和写入操作。计算字段可与 compute 方法一起设置实现搜索逻辑的 search 方法,以及实现写入逻辑的 inverse 方法。使用该方法,计算字段可做如下修改:
class Book(models.Model):
_name = 'library.book'
......
publisher_country_id = fields.Many2one(
'res.country',string='Publisher Country',
compute='_compute_publisher_country',
inverse='_inverse_publisher_country',
search='_search_publisher_country',)
计算字段中的写入是计算的反向(inverse)逻辑。因此处理写入操作的方法称为 inverse, 本例中 inverse 方法很简单。计算将 book.publisher_id.country_id 的值复制给 book.publisher_country_id,反向操作是将写入 book.publisher_country_id 的值拷贝给 book.publisher_id.country_id field字段:
def _inverse_publisher_country(self):
for book in self:
book.publisher_id.country_id = book.publisher_country_id

代码释义:
这会修改出版商 partner 记录数据,因此也会修改相同出版商图书的相关字段,常规权限控制对这类写操作有效,因此仅有对 partner 模型有写权限的当前用户才有成功执行操作。
B、计算字段开启搜索操作:
需要为计算字段开启搜索操作,需要实现 search 方法,为此我们需要能够将计算字段的搜索转换为使用常规存储的搜索域。
本例中,实际的搜索可通过关联的 publisher_id Partner 记录的 country_id 来实现:
def _search_publisher_country(self,operator,value):
return [('publisher_id.country_id',operator,value)]

代码释义:
当域表达式的条件中出现该计算字段时就会调用这个搜索方法。它接受搜索的操作符和值,并将原搜索元素转换为一个域搜索表达式。country_id字段存储在关联的 partner 模型中,因此我们的搜索实现仅需要修改原搜索表达式来使用 publisher_id.country_id字段。
②、存储计算字段:
通过在定义时设置 store=True 还可以将计算字段值保存到数据库中。在任意依赖变更时值就会重新计算。因为值已被存储,所以可以像普通字段一样被搜索,也就不需要使用 search 方法了;
③、关联字段:
前面我们实现的计算字段时从关联记录中将值拷贝到模型自己的字段中;
关联字段通过关联模型的字段可在模型中直接可用,并且可通过点号标记法直接访问,这样在点标记法不可用时也可以使用该字段。
要创建关联字段,我们像普通计算字段那样声明一个所需类型的字段,但使用的不是 compute 属性,而是 related 属性,设置用点号标记链来使用所需字段,我们可以使用引用字段来获取与上例 publisher_country_id 计算字段相同的效果:
publisher_country_id = fields.Many2one(
'res.country',string='Publisher Country',
related='publisher_id.country_id',)
代码释义:
本质上关联字段仅仅是快捷实现 search 和 inverse 方法的计算字段,也就是说可以直接对其进行搜索和写入,而无需书写额外的代码。默认关联字段是只读的,因inverse写操作不可用,可通过readonly=False字段属性来开启写操作;
注意:关联字段和计算字段一样可以使用store=True来在数据库中存储。
5、模型约束:
通常应用需保证数据完整性会对数据进行相关约束:主要分为两种 PostgreSQL 约束、Python逻辑代码约束
A、如避免重复、或检查值以符合某些简单条件,可使用PostgreSQL约束;
B、一些检查要求较为复杂的逻辑,就需要选择使用Python代码来实现;
①、SQL模型约束:
SQL约束加在数据表定义中,并由 PostgreSQL 直接执行。它由_sql_constraints类属性来定义,这是一个元祖组成的列表,并且每个元组的格式为(name,code,error):
⚪ name是约束标识名;
⚪ code是约束的PostgreSQL语法;
⚪ error 是在约束验证未通过时向用户显示的错误消息;
需求说明:
我们向图书模型添加两个SQL约束。
A、一条是唯一性约束,用于通过标题和出版日期是否相同来确保没有重复的图书;
B、另外一条是检查出版日期是否为未出版;
代码实现:
class Book(models.Model):
_name = 'library.book'
_description = 'Book'
_order = 'name, date_published desc'
_sql_constraints = [
('library_book_name_date_up', #约束唯一表示符
'UNIQUE (name,date_published)', #约束sql语法
'该书已存在'),
('library_book_check_date',
'CHECK (date_published <= current_date)',
'出版日期未出版'),
]
②、Python模型约束
Python约束可使用自定义代码来检查条件。检查方法应添加 @api.constrains 装饰器,并且包含要检查的字段列表,其中任意字段被修改就会触发验证,并且在未满足条件时抛出异常。就目前的例子中就时防止插入不正确的 ISBN 号。我们已经在 _check_isbn()方法中书写了ISBN的校验逻辑。可以在模型约束中使用它来防止保存错误数据:
代码如下:
from odoo.exceptions import Warning,ValidationError
class Book(models.Model):
_name = 'library.book'
_description = 'Book'
_order = 'name, date_published desc'
@api.constrains('isbn')
def _constrain_isbn_valid(self):
for book in self:
if book.isbn and not book._check_isbn():
raise ValidationError('%s is an invalid ISBN'% book.isbn)
6、Odoo中的相关base模型:
Odoo中提供了一些内置模型,Odoo内核中有一个base插件模型。提供了Odoo所需要的基本功能,同时也有一些内置插件模型来提供标准产品中的官方应用和标准。
base模块中包含两类模型:
⚪ 信息仓库, ir.*模型
⚪ 资源, res.*模型
信息仓库用于存储Odoo所需数据,如菜单、视图、模型、Action、以及Technical菜单下的数据通常都存储在信息仓库中,相关例子如下:
⚪ ir.actions.act_window 用于窗口操作
⚪ ir.ui.menu 用于菜单项
⚪ ir.ui.view 用于试图
⚪ ir.model 用于模型
⚪ ir.model.fields 用于模型字段
⚪ ir.model.data 用于XML ID
资源包含基本数据,基本上用于应用。以下是一些重要的资源模型:
⚪ res.partner 用于业务伙伴,如客户、供应商和地址等
⚪ res.company 用于公司数据
⚪ res.currency 用于货币
⚪ res.country 用于国家
⚪ res.users 用于应用用户
⚪ res.groups 用于应用安全组
7、常用模型的简写:
在XML中我们除了使用了之外的元素,如
⚪ 是窗口操作模型 ir.actions.act_window;
⚪