r语言与多维统计_Kaukatcr:多维空间语言设计的实验
r语言与多维统计
与Project Xanadu™[1]相关的各种项目之一是ZigZag™,ZigZag™是一种组织器系统或思维导图工具,围绕着称为ZZStructures的扭曲多维空间构建。
从一开始,我们就希望使该系统可编写脚本。 一些现有的内部实现支持使用常规语言编写脚本,而Ted想要一种类似于电子表格格式的语言(因为他认为ZZStructure是一种电子表格,其行和列从其网格中释放出来并以任意表达的方式缠结在一起) 。
当我在那里时,Jon Kopetz和我提出了一种语言的概念,该语言充分利用了可用的结构,并编写了概念验证实现。 它没有得到进一步的说服-非程序员实际上不能像公式系统那样使用这种语言,并且我们还有其他优先事项-但我认为其中一些想法很有价值,因为尽管有其所有局限性,但它的存在识字编程,堆栈编程和可视化编程的交集。
快速法律说明
Xanadu项目在内部产生了很多代码-比以前发布的代码要多得多-以及许多内部文档和讨论。 根据我为Xanadu编写的内容,我链接的代码是独立于内存编写的。 但是,该项目并没有得到官方认可,因此各种商标(Project Xanadu™,ZigZag™,易燃的X徽标以及其他商标)均不适用。 据我所知,该材料没有违反任何商业秘密-我曾公开将与ZigZag™相关的所有商业秘密。 同样,虽然已申请了与该技术相关的专利,但据我所知,当前没有适用的专利有效。
从现在开始,我将把类似ZigZag™的系统称为ZZ。 这些想法不一定依赖于ZigZag™的所有功能,而是可以应用于基于ZZStructure的任何系统。 另外,我讨厌输入商标标签。
ZZStructures和ZZ接口约定的速成班
ZZStructure是“单元”的集合-对象包含一个值和一个指向其他单元的成对指针的字符串键关联数组。[2]
程序员可以将单元格概念化为任意多个双向链接列表的交集,每个列表都有一个名称。 或者,他们可能会将单元格视为纠结的多维空间中的一个点(因此,赋予这些列表的名称称为“维度”)。

完整的ZZStructure实现可以用200行python编写。 为了说明起见,这是一个更加简化的版本:
cells=[]
class ZZCell:
def __init__(self, value=None):
global cells
self.cid=len(cells)
self.value=value
self.connections={}
self.connections[True]={}
self.connections[False]={}
cells.append(self)
# core operations
def getValue(self):
""" get cell's value. Use this, rather than the value attribute, unless you specifically don't want to handle clones """
return self.cloneHead().value
def getNext(self, dim, pos=True):
if dim in self.connections[pos]:
return self.connections[pos]
return None
def insert(self, dim, val, pos=True):
""" like setNext, except it will repair exactly one connection """
if(dim in self.connections[pos]):
temp=self.connections[pos][dim]
self.setNext(dim, val, pos)
val.setNext(temp, val, pos)
else:
self.setNext(dim, val, pos)
def breakConnection(self, dim, pos=True):
if self.getNext(dim, pos):
temp=self.connections[pos][dim]
temp.connections[not pos][dim]=None
self.connections[pos][dim]=None
def clone(self):
""" create a clone """
c=ZZCell()
self.rankHead("d.clone", True).setNext("d.clone", c)
return c
def cloneHead(self):
return self.rankHead("d.clone")
# underlying operations (usually not exposed through the UI)
def setNext(self, dim, val, pos=True):
self.connections[pos][dim]=val
val.connections[not pos][dim]=self
def rankHead(self, dim, pos=False):
""" Get the head (or tail) of a rank """
curr=self
n=curr.getNext(dim, pos)
while(n):
if(n==self):
break # handle ringranks
curr=n
n=curr.getNext(dim, pos)
return curr
def getDims(self):
return list(set(self.connections[True].keys() + self.connections[False].keys()))
一般而言,常规的ZZ界面(“视图”)将由两个窗格组成,每个窗格都选择了一个特定的单元格,并且将两个或三个维度映射到窗格的空间尺寸。 用户同时浏览两个窗格,或使用每个窗格查看同一单元的不同方面(以沿不同维度的连接形式)。
本文将以这种简化的ZZ界面的手绘图像进行说明。 ZZ键绑定和交互不在本文讨论范围之内,尽管我鼓励有兴趣的读者阅读“入门工具包”中的正式文档并观看演示视频 。



考卡特尔
Kaukatcr (发音为“ cowcatcher ” [3])是一种基于堆栈的语言,在Forth上松散地建模。 它通过将单元边界视为单词边界来避免标记化。 与Forth一样,任何既不是内置单词也不是在已定义函数的词典中找到的单词都将被视为数据并压入堆栈。
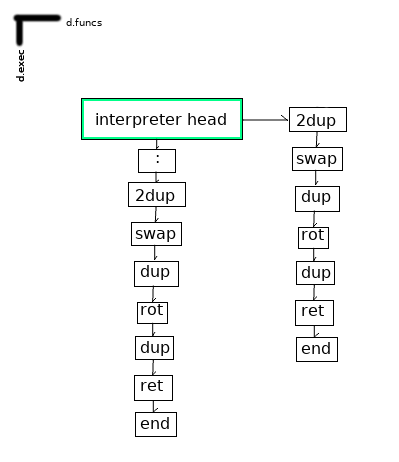
Kaukatcr有一个“解释器头” —对应于程序开始的单元格。 堆栈沿“ d.stack”的尺寸悬挂在解释器的头部; 已定义函数的名称沿'd.funcs'挂起; 调用栈沿“ d.call”挂起; 解释器沿着“ d.exec”进行迭代。
函数定义的名称沿'd.exec'开头。 “ d.branch”指向条件跳跃的目标。
按照惯例,我们将代码中的注释挂在'd.comment'中。
为了使非Forth程序员易于阅读,已将一些Forth关键字重命名:':'变为'def'和';;' 成为“终点”。[4] 尽管如此,函数定义的工作方式大致相同:
: 2dup swap dup rot dup ;;
变成:

要求使用“ ret”,因为我们不会在呼叫退出时自动从呼叫中返回-如果没有“ ret”,则程序在退出排名末尾时会终止。 这使得尽早退出程序变得容易一些,因此支持交互式编辑-人们可以在执行未完成的程序期间观察堆栈,也许对其进行编辑,然后在退出点继续执行。
读取了定义该函数的代码后,我们的解释器标题将如下所示:
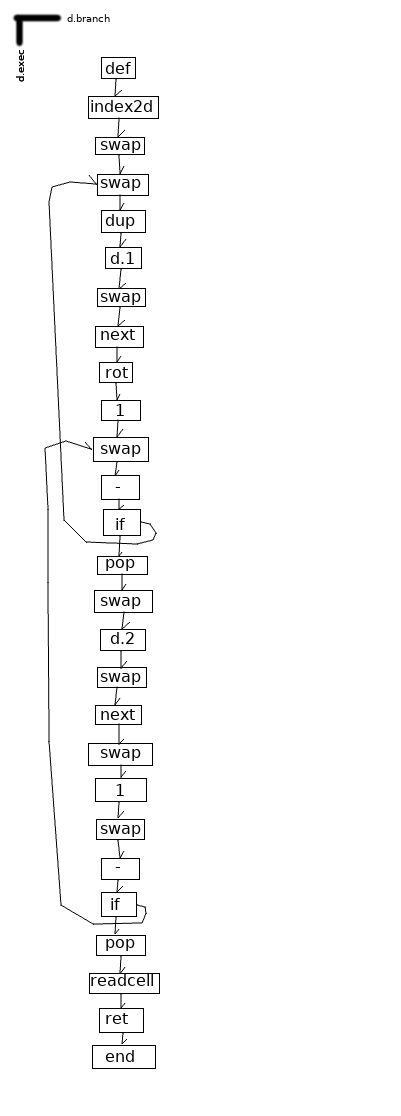
最后,这是一个同时包含函数和条件分支的示例:

与Forth的差异
尽管从Forth借用了一些语法和约定,但仍然存在根本的区别(甚至超出了标记化,在kaukatcr中无法配置)。
一个区别是内建函数不会被具有相同名称的已定义单词覆盖。 在参考实现中,用户定义的函数查找要比内置查找慢得多,以至于对于大型程序而言,在每个步骤上执行它都是不合理的。 此外,尽管重新定义内建函数非常强大,但在可以轻松地将其状态重置(以还原所有可能的重大更改)的系统中,它最有意义,而ZZ实现在理论上应该是基于映像的系统(例如smalltalk VM),其中每个更改将自动保存到持久状态。 (很少有实际的实现方式可以做到这一点,但是根据设计规范,所有这些实现都应该做到这一点。)
另一个区别是非线性的“ if”不带有“ else”,“ endif”和朋友。相反,它本质上是一个条件分支。 它与x86汇编中的“ jnz”指令等效。 结果,可以将“ if”修改为任意的“ goto”,只需在if之前将1压入堆栈,就可以无条件地跳转到代码中的任何位置。
在当前的实现中,由于我们跳转到链接单元而不是链接单元的clonehead [5],因此每个单元最多可以是一个直接分支的入口点,但是,我认为没有理由不能将其作为一个直接分支。与实现有关的决定或与方言有关的决定。 以这种方式限制跳转点使分析某些结构变得容易,因为它们会崩溃为定义明确的循环,但是要想从许多地方跳转到特定点,要避免这种情况,则需要注入一堆无操作指令,应避免这种情况。 6]


第三个差异是较大数据结构的操纵。 由于所有数据要么是ZZ单元格,要么是ZZ单元格的克隆,要么是存储在ZZ单元格中的字符串或数字[1],并且由于ZZ导航是公开的,因此很自然地将秩用作一维数组,并使用具有已知维数悬挂的单元格它们作为关联数组。 对于多维数组,我建议使用d.1,d.2,…,dn的约定,并按基数维的顺序导航这些结构(即,导航至(3,5,7),我们将走三步沿着d.1,从d.2向下走了五个台阶,然后在d.3上走了七个台阶),尽管显然Kaukatcr对于复杂矩阵算术不是一个很好的选择。
脚注
[1]项目Xanadu™是最早的超文本项目,成立于1960年,并且至今仍在进行。 从2011年到2016年,我以志愿者的身份在那里工作。这是西奥多·“泰德·尼尔森”的创意。 我建议查看官方网站以获取更多详细信息 。
[2]更准确地说,单元格的集合称为“切片”,ZZStructure可以由一个或多个切片组成。 所定义的模块仅支持一个切片(模块范围内的“单元”数组)。 在其他实现中,有一个slice类,它处理单元的创建,垃圾回收,序列化和单元ID的分配。 但是,对于那些不熟悉我要介绍的概念的人,我认为这可能会造成混淆。 无论如何,支持多个切片最为有趣,因为它具有跨切片边界进行链接的能力,而这种机制曾一度处于商业秘密之下。 尽管我认为这些商业秘密保护现已失效,但我谨慎行事,避免了对其的详细说明或实现。
[3]捕牛人是蒸汽火车前部的楔形结构。 它是由查尔斯·巴贝奇(Charles Babbage)发明的,他还发明了存储程序的机械计算机。 我们之所以选择这个名称,是因为指令指针在二维空间中的移动使我们想起了火车跟随轨道。 “ Kaukatcr”是最受欢迎的Lojban正字法中“ cowcatcher”的语音表示。
[4]我的一些示例偶然使用了':'。 因此,我相信是我最初开发的内部原型。 我修改了实现以支持Forth样式的单词定义。 使用真正的锯齿形界面非常容易编写和修改这种代码,但是在GIMP中却很尴尬!
[5]如果所讨论的细胞是克隆,则“克隆头”是从中克隆某些细胞的原始细胞。 从机械上讲,克隆在ZZ中的工作原理是在d.clone上悬挂一排空白单元格,使空白单元格悬空,因此,clonehead是d.clone上该级的头。 当我们获得单元格的内容/值时,我们会自动将该内容请求转发到克隆头,因此从UI角度(以及任何“读取”单元格内容的角度来看),克隆都包含与内容相同的内容。原版的。
[6]从示例中可以看到,取消引用克隆使某些类型的代码更易于编写,但是它对函数定义的工作方式(因为当前它仅克隆原始函数源)和常规用法都产生了影响。系统。 特别是,ZZ系统的用户可能希望能够从其他程序或其片段的非代码部分克隆数据片段到其代码中以对其进行操作,并且取消引用将以潜在的混乱方式破坏此行为。 。
翻译自: https://hackernoon.com/kaukatcr-an-experiment-in-language-design-for-multi-dimensional-spaces-cc038caafff9
r语言与多维统计