Privacy-preserving Serverless Computing using Federated Learning for Smart Grids论文总结
Privacy-preserving Serverless Computing using Federated Learning for Smart Grids论文总结
- Abstract
- I. INTRODUCTION
- II. RELATED WORK
- III. RESEARCH METHODOLOGY
-
- A. Design Objectives
- B. Proposed Model
- C. Implementation of Proposed BFMLP
-
- 1) Blockchain to Record the Smart Meters Data:
- 2) Maintain the Quality of Dataset:
- 3) Model Generation Process:
- D. Privacy Preservation
- 1) Perturbation of Parameters:
- 2) Perturbation in the Serverless Cloud:
- 3) Workload of HANs:
- 4) Workload of Serverless Cloud:
- 5) Federated Learning Process:
- IV. EXPERIMENTAL EVALUATION
-
- A. Manipulation Detection
- B. Computation Overhead
- C. Computation Cost
- D. Communication Cost
- E. Privacy Preservation
- F. Discussion
- V. CONCLUSION
Federated Learning for Smart Grids论文总结)
Abstract
智能电网是一种关键的能源基础设施,通过收集实时用电量数据来预测未来的能源需求。
现有的预测模型侧重于集中式框架,其中从各种Home Area Networks (HANs)家庭区域网络 (HAN) 收集的数据被转发到中央服务器。这个过程会导致网络安全威胁。
本文提出了一种基于联邦学习 (FL) 的模型,该模型使用无服务器云计算保护智能电网数据的隐私。
该模型考虑了每个 HAN 中支持Blockchain-enabled Dew Servers (BDS)区块链的 Dew Server (BDS),用于本地数据存储和本地模型训练。
Advanced perturbation and normalization techniques先进的扰动和归一化技术用于减少不规则工作量对训练结果的反向影响。
所提出的模型最大限度地减少了计算和通信成本、攻击概率,并提高了测试准确性。
总体而言,所提出的模型使智能电网具有强大的隐私保护和高精度。
Index Terms—Privacy-preserving, Serverless computing, dew computing, federated learning, blockchain, smart grid
I. INTRODUCTION
由于数据隐私和带宽限制,传统的基于服务器的学习方法并不适用——用户很乐意共享数据,因此数据只能在设备上访问。
联邦学习 (FL) 在这种情况下发挥作用,使用用户的私人数据来确保他们的隐私。 FL 的主要思想是将计算转移到数据源或本地设备,例如智能手机,并作为一个整体联合训练模型。
FL 允许边缘和物联网设备从设备上的数据中获得优势,而无需将数据传输到中央服务器。
在智能电网中,实时电力数据用于预测不同 HAN 的未来能源需求。目前的功耗预测解决方案主要强调将聚合数据从不同 HAN 发送到专用服务器的集中式方法。因此,在实时用电量数据的编制过程中,可能会发生大量网络安全事件。
不同分布式学习技术的发展可以通过任务共享、并行计算和数据共享机制来缓解多方协作学习问题。不幸的是,大多数学习解决方案都需要直接共享数据和学习模型且不受保护的来源,从而导致数据隐私受到损害。
本文提出了一种基于无服务器云计算联邦学习方法的智能电网系统分布式实时隐私保护数据分析解决方案。每个 HAN 使用本地数据训练全局模型。
该框架能够聚合 HANs 训练的模型并生成全局机器学习模型。
数据集的扰动在**local Dew Servers (DSs)**本地露水服务器 (DS) 和全球云上执行,以最大限度地保护隐私。
II. RELATED WORK
在智能电网中,数据空间分隔要么是水平的,要么是垂直的。
如果将分离的数据收集到中央服务器中进行分析,则通信和计算负载将是巨大的。
在大多数技术中,各方以直接和不安全的方式交换他们的数据和模型,导致数据隐私受到损害
[6] 中的作者开发了一种分散的机器学习策略,在模型训练中提出的系统中存在隐私问题。恶意或不受信任的用户可能会构成安全威胁并泄露敏感数据。
[7] 中的作者开发了一个 FL 框架,该框架有一个强有力的假设,即所有各方都是值得信赖的。但是,我们在没有这种假设的情况下考虑模型。
III. RESEARCH METHODOLOGY
研究方法论
本节描述了使用联邦学习和无服务器云计算在智能电网中隐私保护的设计目标、提出的架构和开发过程。
A. Design Objectives
设计目标
-
- Quality of Dataset:
数据集质量
可能会有一些不规范的用户分享不准确的信息。
产生低质量数据集的原因有很多,例如记录错误、智能电表故障、电表篡改等。
因此,不规则用户共享的梯度可能会影响训练过程的质量。
为了解决这个问题,本文提出了一种先进的perturbation and normalization technique扰动和归一化技术,以减少不规则工作量对训练结果的反向影响。
- Quality of Dataset:
-
- Privacy Preservation and Threat Model:
隐私保护和威胁模型:
提议的Blockchain and Federated Machine Learning based Privacy-preservation (BFMLP) 基于区块链和联邦机器学习的隐私保护(BFMLP)在每个 HAN 中部署了 DS(Dew Servers)

在威胁模型中,我们假设露水服务器是值得信赖的。此外,用于 DNN 训练的各种 HAN 中的不同 DS 之间存在非共谋关系。
威胁模型的第一个隐私保护要求是保持每个 DS 产生的梯度的机密性。云服务器可以进行逆向工程,从全局参数和梯度中恢复用户的敏感信息。因此,在 DS 计算的局部梯度必须在上传到云服务器之前进行加密。
第二个隐私要求是用户的可靠性必须保密,不能与其他用户和云共享。计算的聚合结果可能属于知识产权。因此,必须对汇总结果进行保密。
- Privacy Preservation and Threat Model:
B. Proposed Model
建议的模型
提议的智能电网 BFMLP 模型具有以下实体:(i) 具有智能电表 (SM) 和支持区块链的露水服务器 (BDS) 的家庭局域网 (HAN),(ii) 无服务器云计算 (SCC),以及 (iii) ) 电力中心 (PC) 或电网供应商。

1)带有智能电表(SM)的家庭局域网(HAN):在HAN中,智能电表安装在用户端,用于记录功率因数、电流、电压水平和电能信息。
2)支持区块链的露水服务器(BDS):BDS部署在HANs中,将用电信息存储在本地区块链中,以确保信息源附近的安全。
每个 BDS 有两个组件:(i) Dew Analytical Servers (DAS),它提供有关 DSs 使用情况的数据分析服务,(ii) 人工智能 Dew (AID),它使各种机器学习算法能够在本地执行。
3)无服务器云计算(SCC):
主要组件是区块链服务、应用程序管理器、无服务器管理器和资源管理器
训练好的神经网络和元数据使用区块链服务存储,以提供数据和训练模型的安全存储。
无服务器管理器管理云、DS 资源以及 DS 和云服务器之间的动态资源供应。
应用程序管理器将数据发送到资源调度。
The placement manager放置管理器处理数据的交换。
- 电力中心 (PC):
电力中心 (PC) 向智能电网提供太阳能和风能等可再生能源。
C. Implementation of Proposed BFMLP
提议的 BFMLP 的实施
提出的 BFMLP 模型旨在确保智能电表数据的隐私。
将横向联邦学习应用于协作训练过程。模型 FHM 由 N 个同质 HANs {H1,H2, …,HN} 构造,以找到不同特征 {P1, P2, …, PN} 的局部模型参数 PM 的值

每个 HAN Hi 都使用他们的本地数据进行训练,这些数据不会在不同的 HAN 之间共享。
计算出的局部梯度在应用同态加密后被传输。
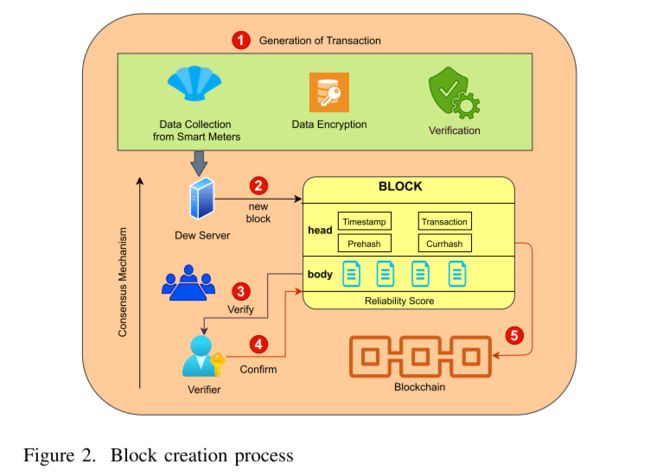
1) Blockchain to Record the Smart Meters Data:
区块链记录智能电表数据
信息的主要来源是智能电表。从智能电表收集的数据被加密并发送到 HAN 的 DS。 BDS 将信息存储在区块链中并计算局部梯度。
区块链生成所涉及的步骤如下所述:
-
Generation of Transaction:
事务的生成
SM 生成时间序列数据。根据特征{P1, P2, …, PN},在时隙Δt 的某个时间间隔后,从n 个SM 中收集数据Dij。
数据在 SM 中加密并上传到 HAN 中的 DS。 -
Verification:
验证:从安全网关经过适当的身份验证机制后,以加密形式接收的智能电表数据。 -
Block Creation:
区块创建:DS 中的微服务将交易 Ti 作为区块存储在区块链中。 -
Generation of Blockchain:
区块链的生成:使用 BDS 将新区块添加到 DS 的本地区块链中。
2) Maintain the Quality of Dataset:
保持数据集的质量:
采用同态加密将信息存储在 DS 的区块链中。
奖励机制旨在激励客户分享他们的信息以收集客户的使用行为。
将根据最低分数选择或拒绝智能电表数据。
基于奖励机制的中央区块链中的交易记录。客户和家庭区域网络的回报与数据考虑成正比。初始奖励给予智能电网生态系统中的 HAN 和智能电表。一旦在验证过程中接受更新,智能电表用户及其 HAN 的信誉将增加 1。否则,如果不接受更新,则该值将减少 1。
3) Model Generation Process:
模型生成过程:
- Local Model:
全局模型取决于每个 DS 的数据量及其与全局模型 MG 的聚合。本地模型 ML 依赖于它的特性并更新规则作为本地 DS 可用的数据。 - Global Model:
全局模型:无服务器云将节点上传的本地模型组装起来。全局模型使用聚合维护所有节点的属性。 - Aggregation:
在聚合过程中,所有本地节点将本地模型的更新发送给全局模型。全局模型可以将更新组合为每个局部模型的权重,并全局更新模型参数。
D. Privacy Preservation
机器模型是通过收集模型的各种家庭区域网络生成的。我们需要在每一轮之后更新模型,并根据分数考虑 HANs 模型的更新。此外,使用同态加密和区块链维护模型的隐私。
在本节中,我们将讨论联邦学习中的perturbation and normalization扰动和归一化。微扰理论是指对系统中微小变化的研究。可以在训练阶段使用各种参数的小扰动来设计鲁棒的联邦学习模型。这将有助于消除各种碰撞问题以避免恶意攻击。
1) Perturbation of Parameters:
参数扰动:
由于数据集的规模可能不同,因此需要对每个 HAN 中接收的数据集进行归一化。
随机扩展技术提高了数据的随机性。中间扰动数据是通过随机噪声生成生成的。
归一化方法提高了学习精度。
2) Perturbation in the Serverless Cloud:
无服务器云中的扰动:
扰动分布在各种HAN的DS之间。
3) Workload of HANs:
HANs 是数据实际受到干扰的位置。数据永远不会传输到无服务器云。本地参数根据从智能电表接收到的数据进行调整。
4) Workload of Serverless Cloud:
无服务器云的工作量:全局扰动过程在中央无服务器云中计算。这种方法可确保数据的安全性,因为用户不会共享实际数据。参数存储在云服务器上的区块链中。
5) Federated Learning Process:
一旦扰动完成,联邦学习模块就会触发。本地数据集用于训练本地机器模型。
联邦学习的设置分多轮进行,并根据不同组织的要求进行局部更新,以最大限度地提高准确性。
IV. EXPERIMENTAL EVALUATION
A. Manipulation Detection
操纵检测
由于区块链和联邦机器学习过程,使用提出的 BFMLP 模型可以克服攻击者的尝试。
操纵检测的性能如图 所示

B. Computation Overhead
计算开销
对从各种智能电表收集的数据进行验证,并应用同态加密将数据存储在区块链中。
收集和验证的过程具有计算开销。随着数据的增加,计算开销与其成正比。

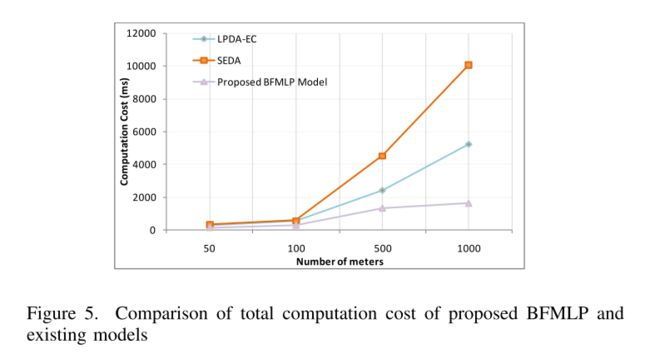
C. Computation Cost
计算成本
由于数据分布在 HANs 中,因此训练在 FL 过程中花费的时间更少。无服务器计算确保根据需求提供资源。这导致所提出的 BFMLP 模型的计算成本降低。
D. Communication Cost
通信成本
BFMLP 不会将智能电表数据传输到中央实体。因此,与其他模型相比,整体通信成本要低得多。

E. Privacy Preservation
训练过程总结了DP的噪声。我们改变了提议的 BFMLP 模型的局部和全局时期。所提出模型的测试精度在图 8 所示的时期变化情况下进行了测试。结果通过获得适当的平衡证明了高测试精度。

F. Discussion
BFMLP 模型具有巨大的性能和成本效益。联邦学习避免了与全球云共享的数据,从而减少了通信开销。 FL 使训练后的模型参数能够与全球云共享,而不是共享原始数据。因此,所提出的 BFMLP 在提供安全性和隐私性以及降低计算和通信成本方面具有优势。
V. CONCLUSION
许多应用程序,如智能电网、银行、医疗保健都有分布式系统。这些系统的分析需要一个强大的隐私保护模型。在本文中,我们提出了一种基于区块链和联合机器学习的隐私保护 (BFMLP) 模型。数据从家庭区域网络中的各种智能仪表收集并存储在 HAN 中使用的 DS 中。每个 HAN 中的 DS 控制本地数据扰动,而全局扰动由中央无服务器云处理。
所提出的模型显着改善了隐私保护并降低了响应时间。
将来,扰动过程可以针对 HAN 的不同属性进行。垂直联邦学习可以应用于这个过程。它还有助于减少属性的数量。