python使用多线程爬取
/ 01 / 网页分析

小说章节内容接口由上图可知。
第几部、第几章,遍历一遍就完事了。
这里主要是利用多线程进行爬取,
一方面是减少爬取时间,另一方面也是对多线程进行一波简单的学习。
通过Python的threading模块,实现多线程功能。
不过爬太快还是会遭封禁...
所以本次的代码不一定能完全成功,可以选择加个延时或者代理池。
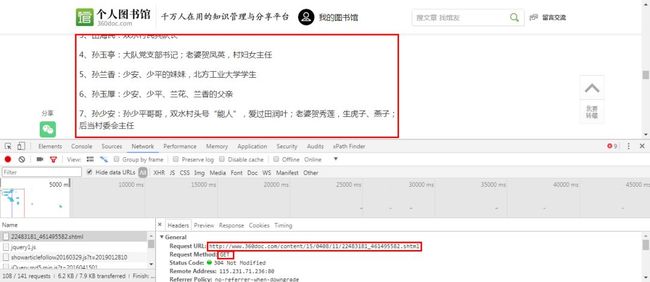
这里人物情况是网上找的,相对来说还是比较完全的。
所以也爬下来,当词典用。
/ 02 / 数据获取
不使用多线程。
import os
import time
import requests
from bs4 import BeautifulSoup
# 初始时间
starttime = time.time()
print(starttime)
# 新建文件夹
folder_path = "F:/Python/Ordinary_world_1/"
os.makedirs(folder_path)
# 遍历
a = [ yi , er , san ]
for i in a:
for j in range(1, 55):
headers = { User-Agent : Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 }
url = http://www.pingfandeshijie.net/di- + i + -bu- + str( %02d % j) + .html
response = requests.get(url=url, headers=headers)
# 设置编码格式
response.encoding = utf-8
soup = BeautifulSoup(response.text, lxml )
# 获取章节情况
h1 = soup.find( h1 )
print(h1.get_text())
# 获取段落内容
p = soup.find_all( p )
for k in p:
if 下一章 in k.get_text():
break
content = k.get_text().replace( S*锓 , )
filename = h1.get_text() + .txt
with open( F:\Python\Ordinary_world_1\ + filename, a+ ) as f:
try:
f.write(content +
)
except:
pass
f.close()
# 结束时间
endtime = time.time()
print(endtime)
# 程序运行总时间
print(round(endtime-starttime, 2))
使用多线程的。
import os
import time
import requests
import threading
from bs4 import BeautifulSoup
# 初始时间
starttime = time.time()
# 新建文件夹
folder_path = "F:/Python/Ordinary_world"
os.makedirs(folder_path)
def download(sta, end):
a = [ yi , er , san ]
for i in a:
for j in range(sta, end):
headers = { User-Agent : Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 }
url = http://www.pingfandeshijie.net/di- + i + -bu- + str( %02d % j) + .html
response = requests.get(url=url, headers=headers)
# 设置编码格式
response.encoding = utf-8
soup = BeautifulSoup(response.text, lxml )
# 获取章节情况
h1 = soup.find( h1 )
print(h1.get_text())
# 获取段落内容
p = soup.find_all( p )
for k in p:
if 下一章 in k.get_text():
break
content = k.get_text()
filename = h1.get_text() + .txt
with open( F:\Python\Ordinary_world\ + filename, a+ ) as f:
f.write(content +
)
f.close()
downloadThreads = []
for chap in range(1, 55, 6):
downloadThread = threading.Thread(target=download, args=(chap, chap+6))
downloadThreads.append(downloadThread)
downloadThread.start()
# 等待所有线程结束
for downloadThread in downloadThreads:
downloadThread.join()
print( Down )
# 结束时间
endtime = time.time()
# 程序运行总时间
print(round(starttime-endtime, 2))
使用多线程获取的小说内容。
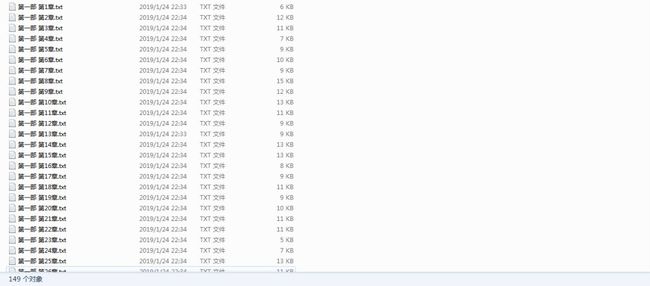
按道理应该是162个文件,但是却只获取了149个。
这是多线程导致的并发问题吗?
即多个线程同时读写变量,导致互相干扰,进而发生并发问题。
最后发现并不是,而是编码出现了问题。
下图是不使用多线程获取的小说内容。
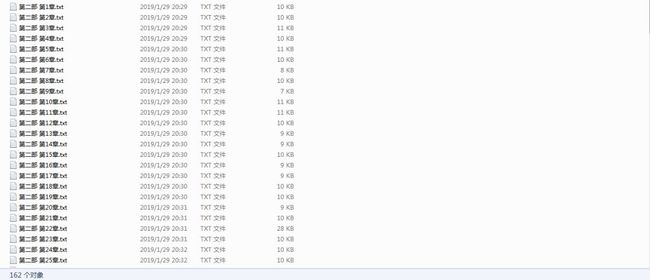
162个文件,确认过眼神,遇上对的人。
获取主要人物信息。
import re
import requests
from bs4 import BeautifulSoup
headers = { User-Agent : Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 }
url = http://www.360doc.com/content/15/0408/11/22483181_461495582.shtml
response = requests.get(url=url, headers=headers)
response.encoding = utf-8
soup = BeautifulSoup(response.text, lxml )
p = soup.find_all( p )
for i in p[7:-9]:
if : in i.get_text():
result = re.findall( 、(.*?):, i.get_text())
name = result[0].replace( 二队队长 , ).replace( “神汉” , ).replace( 地主 , ).strip()
with open( name.txt , a+ ) as f:
f.write(name +
)
f.close()
一共82个人物,还算是比较完整的。

计算人物出现频数。
import os
# 汇总文本信息
for i in os.listdir( F:\Python\Ordinary_world_1 ):
worldFile = open( F:\Python\Ordinary_world_1\ + i)
worldContent = worldFile.readlines()
for j in worldContent:
with open( world1.txt , a+ ) as f:
f.write(j)
f.close()
# 打开文件
file_text = open( world1.txt )
file_name = open( name.txt )
# 人物信息
names = []
for name in file_name:
names.append(name.replace(
, ))
# 文本信息
content = []
for line in file_text:
content.append(line)
# 人物出现频数
data = []
for name in names:
num = 0
for line in content:
if name in line:
num += 1
else:
continue
data.append((name, num))
# 生成字典
worddict = {}
for message in sorted(data, key=lambda x: x[1], reverse=True):
if message[1] == 0:
pass
else:
worddict[message[0]] = message[1]
print(worddict)
得到人物出现频数信息。

接下来便可以对人物数据进行词云可视化
/ 03 / 数据可视化
这里贴一张网上找的有关wordcloud的使用参数解释。
能够更好的生成一张好看的词云图。
class wordcloud.WordCloud(
font_path=None,
width=400,
height=200,
margin=2,
ranks_only=None,
prefer_horizontal=0.9,
mask=None, scale=1,
color_func=None,
max_words=200,
min_font_size=4,
stopwords=None,
random_state=None,
background_color= black ,
max_font_size=None,
font_step=1,
mode= RGB ,
relative_scaling=0.5,
regexp=None,
collocations=True,
colormap=None,
normalize_plurals=True)
##参数含义如下:
font_path : string //字体路径,需要展现什么字体就把该字体路径+后缀名写上,如:font_path = 黑体.ttf
width : int (default=400) //输出的画布宽度,默认为400像素
height : int (default=200) //输出的画布高度,默认为200像素
prefer_horizontal : float (default=0.90) //词语水平方向排版出现的频率,默认 0.9 (所以词语垂直方向排版出现频率为 0.1 )
mask : nd-array or None (default=None) //如果参数为空,则使用二维遮罩绘制词云。如果 mask 非空,设置的宽高值将被忽略,遮罩形状被 mask 取代。除全白(#FFFFFF)的部分将不会绘制,其余部分会用于绘制词云。
scale : float (default=1) //按照比例进行放大画布,如设置为1.5,则长和宽都是原来画布的1.5倍。
min_font_size : int (default=4) //显示的最小的字体大小
font_step : int (default=1) //字体步长,如果步长大于1,会加快运算但是可能导致结果出现较大的误差。
max_words : number (default=200) //要显示的词的最大个数
stopwords : set of strings or None //设置需要屏蔽的词,如果为空,则使用内置的STOPWORDS
background_color : color value (default=”black”) //背景颜色,如background_color= white ,背景颜色为白色。
max_font_size : int or None (default=None) //显示的最大的字体大小
mode : string (default=”RGB”) //当参数为“RGBA”并且background_color不为空时,背景为透明。
relative_scaling : float (default=.5) //词频和字体大小的关联性
color_func : callable, default=None //生成新颜色的函数,如果为空,则使用 self.color_func
regexp : string or None (optional) //使用正则表达式分隔输入的文本
collocations : bool, default=True //是否包括两个词的搭配
我主要是设置了文本的字体、颜色、排版方向。
更多信息详见上面,希望你也能做出一样好看的词云图。
不再是那么的不堪入目...
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import numpy as np
import random
# 设置文本随机颜色
def random_color_func(word=None, font_size=None, position=None, orientation=None, font_path=None, random_state=None):
h, s, l = random.choice([(188, 72, 53), (253, 63, 56), (12, 78, 69)])
return "hsl({}, {}%, {}%)".format(h, s, l)
# 绘制圆形
x, y = np.ogrid[:1500,:1500]
mask = (x - 700) ** 2 + (y - 700) ** 2 > 700 ** 2
mask = 255 * mask.astype(int)
wc = WordCloud(
background_color= white ,
mask=mask,
font_path= C:WindowsFonts华康俪金黑W8.TTF ,
max_words=2000,
max_font_size=250,
min_font_size=15,
color_func=random_color_func,
prefer_horizontal=1,
random_state=50
)
wc.generate_from_frequencies({ 田海民 : 76, 马来花 : 15, 雷区长 : 7, 胡得禄 : 9, 金富 : 60, 孙玉亭 : 268, 田润生 : 40, 田晓霞 : 113, 田福堂 : 460, 马国雄 : 27, 张有智 : 112, 黑白 : 15, 周文龙 : 35, 南洋女人 : 12, 卫红 : 32, 田福军 : 346, 冯世宽 : 83, 田润叶 : 45, 孙少平 : 431, 侯玉英 : 49, 王满银 : 134, 田四 : 14, 金俊山 : 128, 李登云 : 95, 金俊武 : 206, 石钟 : 13, 萝卜花 : 12, 惠英 : 86, 高步杰 : 6, 金光辉 : 7, 刘根民 : 50, 徐治功 : 138, 徐爱云 : 19, 武得全 : 2, 曹书记 : 38, 武宏全 : 3, 孙少安 : 385, 王彩娥 : 42, 杨高虎 : 19, 武惠良 : 62, 王世才 : 39, 田晓晨 : 1, 刘志祥 : 29, 苗凯 : 82, 藏族姑娘 : 14, 金俊斌 : 18, 徐国强 : 77, 胡永州 : 17, 憨牛 : 5, 高凤阁 : 26, 张生民 : 26, 白元 : 11, 孙兰香 : 12, 杜丽丽 : 21, 秦富功 : 12, 贾冰 : 43, 金俊海 : 37, 金波 : 235, 金秀 : 71, 胡得福 : 12, 顾尔纯 : 2, 金光亮 : 91, 贺耀宗 : 9, 白明川 : 63, 古风铃 : 32, 乔伯年 : 65, 刘玉升 : 71, 小翠 : 8, 金强 : 64, 胡永合 : 53, 安锁子 : 54, 金先生 : 17, 田五 : 49, 杜正贤 : 13, 孙玉厚 : 197})
plt.imshow(wc)
plt.axis( off )
wc.to_file("平凡的世界.jpg")
print( 生成词云成功! )
最后生成词云如下。

/ 04 / 总结
说来惭愧,小F并没有完整的看完《平凡的世界》。
所以对于书中内容不甚了解,也就不发表评论了。
不过还是希望日后,能抽抽时间读一读经典。
这里摘一段新周刊的评论。
小说里,孙少平到最后也还是一个普通人。
平凡的世界,才是大多数年轻人最后的归宿。
不过即使知道平凡的归宿,我们也要怀抱不平凡的憧憬。
热烈的迎接,燃烧且不辜负!