python 5 分布式爬虫(Distributed crawls)
scrapy分布式爬虫
文档:
Common Practices — Scrapy 2.11.0 documentation
Scrapy并没有提供内置的机制支持分布式(多服务器)爬取。不过还是有办法进行分布式爬取, 取决于您要怎么分布了。
如果您有很多spider,那分布负载最简单的办法就是启动多个Scrapyd,并分配到不同机器上。
如果想要在多个机器上运行一个单独的spider,那您可以将要爬取的url进行分块,并发送给spider。 例如:
首先,准备要爬取的url列表,并分配到不同的文件url里:
http://somedomain.com/urls-to-crawl/spider1/part1.listhttp://somedomain.com/urls-to-crawl/spider1/part2.listhttp://somedomain.com/urls-to-crawl/spider1/part3.list
接着在3个不同的Scrapd服务器中启动spider。spider会接收一个(spider)参数 part , 该参数表示要爬取的分块:
curl http://scrapy1.mycompany.com:6800/schedule.json -d project=myproject -d spider=spider1 -d part=1curl http://scrapy2.mycompany.com:6800/schedule.json -d project=myproject -d spider=spider1 -d part=2curl http://scrapy3.mycompany.com:6800/schedule.json -d project=myproject -d spider=spider1 -d part=3

scrapy-redis分布式爬虫
scrapy-redis巧妙的利用redis队列 实现 request queue和 items queue,利用redis的set实现request的去重,将scrapy从单台机器扩展多台机器,实现较大规模的爬虫集群
环境要求
- Python 2.7, 3.4 or 3.5
Scrapy-Redis 架构分析
scrapy任务调度是基于文件系统,这样只能在单机执行crawl。
scrapy-redis将待抓取request请求信息和数据items信息的存取放到redis queue里,使多台服务器可以同时执行crawl和items process,大大提升了数据爬取和处理的效率。
scrapy-redis是基于redis的scrapy组件,主要功能如下:
• 分布式爬虫
多个爬虫实例分享一个redis request队列,非常适合大范围多域名的爬虫集群
• 分布式后处理
爬虫抓取到的items push到一个redis items队列,这就意味着可以开启多个items processes来处理抓取到的数据,比如存储到Mongodb、Mysql
• 基于scrapy即插即用组件
Scheduler + Duplication Filter, Item Pipeline, Base Spiders.
scrapy原生架构
分析scrapy-redis的架构之前先回顾一下scrapy的架构
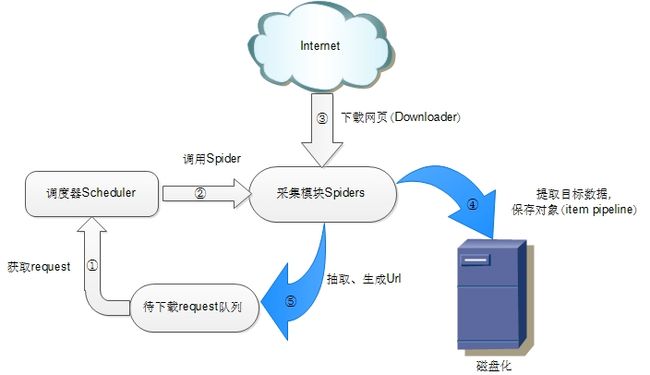
• 调度器(Scheduler)
- Redis >= 2.8
- Scrapy >= 1.0
- redis-py >= 2.10(python客户端)
调度器维护request 队列,每次执行取出一个request。
• Spiders
Spider是Scrapy用户编写用于分析response,提取item以及跟进额外的URL的类。
每个spider负责处理一个特定(或一些)网站。
• Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、验证数据及持久化(例如存取到数据库中)。
scrapy-redis 架构

如上图所示,scrapy-redis在scrapy的架构上增加了redis,基于redis的特性拓展了如下组件:
• 调度器(Scheduler)
scrapy-redis调度器通过redis的set不重复的特性,巧妙的实现了Duplication Filter去重(DupeFilter set存放爬取过的request)。Spider新生成的request,将request的指纹到redis的DupeFilter set检查是否重复,并将不重复的request push写入redis的request队列。调度器每次从redis的request队列里根据优先级pop出一个request, 将此request发给spider处理。
• Item Pipeline
将Spider爬取到的Item给scrapy-redis的Item Pipeline,将爬取到的Item存入redis的items队列。可以很方便的从items队列中提取item,从而实现items processes 集群
总结
scrapy-redis巧妙的利用redis 实现 request queue和 items queue,利用redis的set实现request的去重,将scrapy从单台机器扩展多台机器,实现较大规模的爬虫集群
那么如何安装scrapy-redis呢?
文档:
https://scrapy-redis.readthedocs.org.
安装scrapy-redis
之前已经装过scrapy了,这里直接装scrapy-redis
pip install scrapy-redis先从github上拿到scrapy-redis的example,然后将里面的example-project目录移到指定的地址
git clone https://github.com/rolando/scrapy-redis.git
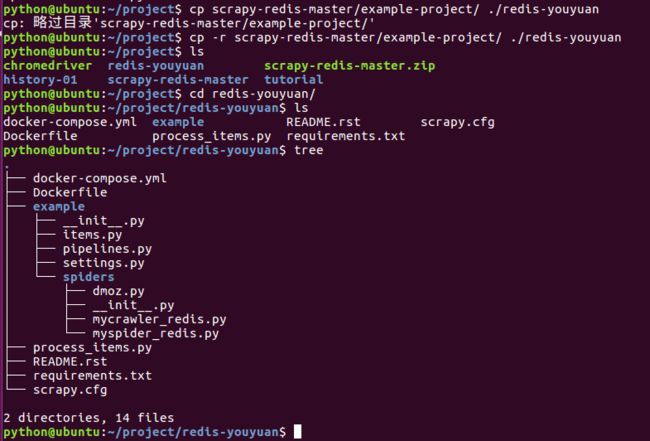
cp -r scrapy-redis/example-project ./scrapy-youyuan或者将整个项目下载回来scrapy-redis-master.zip解压后
cp -r scrapy-redis-master/example-project/ ./redis-youyuan
cd redis-youyuan/
tree查看项目目录
修改settings.py
下面列举了修改后的配置文件中与scrapy-redis有关的部分,middleware、proxy等内容在此就省略了。
https://scrapy-redis.readthedocs.io/en/stable/readme.html
注意:settings里面的中文注释会报错,换成英文
这里小编给大家试了大概是这个样子的:
指定使用scrapy-redis的SchedulerSCHEDULER = "scrapy_redis.scheduler.Scheduler"# 在redis中保持scrapy-redis用到的各个队列,从而允许暂停和暂停后恢复SCHEDULER_PERSIST = True# 指定排序爬取地址时使用的队列,默认是按照优先级排序SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'# 可选的先进先出排序# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderQueue'# 可选的后进先出排序# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderStack'# 只在使用SpiderQueue或者SpiderStack是有效的参数,,指定爬虫关闭的最大空闲时间SCHEDULER_IDLE_BEFORE_CLOSE = 10# 指定RedisPipeline用以在redis中保存itemITEM_PIPELINES = { 'example.pipelines.ExamplePipeline': 300, 'scrapy_redis.pipelines.RedisPipeline': 400}# 指定redis的连接参数# REDIS_PASS是我自己加上的redis连接密码,需要简单修改scrapy-redis的源代码以支持使用密码连接redisREDIS_HOST = '127.0.0.1'REDIS_PORT = 6379# Custom redis client parameters (i.e.: socket timeout, etc.)REDIS_PARAMS = {}#REDIS_URL = 'redis://user:pass@hostname:9001'#REDIS_PARAMS['password'] = 'itcast.cn'LOG_LEVEL = 'DEBUG'DUPEFILTER_CLASS = 'scrapy.dupefilters.RFPDupeFilter'#The class used to detect and filter duplicate requests.#The default (RFPDupeFilter) filters based on request fingerprint using the scrapy.utils.request.request_fingerprint function. In order to change the way duplicates are checked you could subclass RFPDupeFilter and override its request_fingerprint method. This method should accept scrapy Request object and return its fingerprint (a string).#By default, RFPDupeFilter only logs the first duplicate request. Setting DUPEFILTER_DEBUG to True will make it log all duplicate requests.DUPEFILTER_DEBUG =True# Override the default request headers:DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,/;q=0.8', 'Accept-Language': 'zh-CN,zh;q=0.8', 'Connection': 'keep-alive', 'Accept-Encoding': 'gzip, deflate, sdch',}
项目案例
以抓取有缘网 北京 18-25岁 女朋友为例
修改items.py
增加我们最后要保存的Profile项
class Profile(Item):
# 提取头像地址
header_url = Field()
# 提取相册图片地址
pic_urls = Field()
username = Field()
# 提取内心独白
monologue = Field()
age = Field()
# youyuan
source = Field()
source_url = Field()
crawled = Field()
spider = Field()修改爬虫文件
在spiders目录下增加youyuan.py文件编写我们的爬虫,之后就可以运行爬虫了。这里的提供一个简单的版本:
# -*- coding: utf-8 -*-
from scrapy.linkextractors import LinkExtractor
from example.items import Profile
import re
from scrapy.dupefilters import RFPDupeFilter
from scrapy.spiders import CrawlSpider,Rule
class YouyuanSpider(CrawlSpider):
name = 'youyuan'
allowed_domains = ['youyuan.com']
# 有缘网的列表页
start_urls = ['http://www.youyuan.com/find/beijing/mm18-25/advance-0-0-0-0-0-0-0/p1/']
pattern = re.compile(r'[0-9]')
# 提取列表页和Profile资料页的链接形成新的request保存到redis中等待调度
profile_page_lx = LinkExtractor(allow=('http://www.youyuan.com/\d+-profile/'),)
page_lx = LinkExtractor(allow =(r'http://www.youyuan.com/find/beijing/mm18-25/advance-0-0-0-0-0-0-0/p\d+/'))
rules = (
Rule(page_lx, callback='parse_list_page', follow=True),
Rule(profile_page_lx, callback='parse_profile_page', follow=False),
)
# 处理列表页,其实完全不用的,就是留个函数debug方便
def parse_list_page(self, response):
print "Processed list %s" % (response.url,)
#print response.body
self.profile_page_lx.extract_links(response)
pass
# 处理Profile资料页,得到我们要的Profile
def parse_profile_page(self, response):
print "Processing profile %s" % response.url
profile = Profile()
profile['header_url'] = self.get_header_url(response)
profile['username'] = self.get_username(response)
profile['monologue'] = self.get_monologue(response)
profile['pic_urls'] = self.get_pic_urls(response)
profile['age'] = self.get_age(response)
profile['source'] = 'youyuan'
profile['source_url'] = response.url
#print "Processed profile %s" % response.url
yield profile
# 提取头像地址
def get_header_url(self, response):
header = response.xpath('//dl[@class="personal_cen"]/dt/img/@src').extract()
if len(header) > 0:
header_url = header[0]
else:
header_url = ""
return header_url.strip()
# 提取用户名
def get_username(self, response):
usernames = response.xpath('//dl[@class="personal_cen"]/dd/div/strong/text()').extract()
if len(usernames) > 0:
username = usernames[0]
else:
username = ""
return username.strip()
# 提取内心独白
def get_monologue(self, response):
monologues = response.xpath('//ul[@class="requre"]/li/p/text()').extract()
if len(monologues) > 0:
monologue = monologues[0]
else:
monologue = ""
return monologue.strip()
# 提取相册图片地址
def get_pic_urls(self, response):
pic_urls = []
data_url_full = response.xpath('//li[@class="smallPhoto"]/@data_url_full').extract()
if len(data_url_full) <= 1:
pic_urls.append("");
else:
for pic_url in data_url_full:
pic_urls.append(pic_url)
if len(pic_urls) <= 1:
return ""
return '|'.join(pic_urls)
# 提取年龄
def get_age(self, response):
age_urls = response.xpath('//dl[@class="personal_cen"]/dd/p[@class="local"]/text()').extract()
if len(age_urls) > 0:
age = age_urls[0]
else:
age = ""
age_words = re.split(' ', age)
if len(age_words) <= 2:
return "0"
#20岁
age = age_words[2][:-1]
if self.pattern.match(age):
return age
return "0"