聊天机器人有了长期记忆,遇到不懂的还能上网搜索
本文转载自量子位
聊天机器人一直是人工智障的代表。
尽管从GPT-3开始,AI生成的文本已经能做到以假乱真,但这仅限于生成一段话。
在连续聊天中,AI不会记得自己之前说过的话,就像下面这样:

AI这种前后矛盾的表现,在人类看来就是没有稳定的身份和个性,好像聊着聊着换人了,也难怪一直被当作人工智障。
现在,Facebook AI团队终于推出BlenderBot2.0,在1.0基础上添加了长期记忆和即时搜索功能。
首先要记住自己说过的话:

记下自己说过的“我喜欢很多种音乐”,和“Kanye West是我最喜欢的说唱歌手”这样的信息,避免后续聊天中出现矛盾。
人类说的话也要记住,比如最喜欢的专辑:

最后,如果人类提到了AI不知道的东西怎么办?
趁没人发现悄悄去网上搜索,还能把搜出来的信息显摆出来:
查到对方喜欢的艺人Beyonce的出生地,并用“我去过那里几次”接上对话。
是不是像极了在群里聊天吹水时偷偷百度的你?
如何告别智障
Facebook AI去年发布的BlenderBot1.0就已经做到了94亿参数,在单轮对话生成上取得了出色的效果。
这次升级的重点是一个检索增强算法,能从过去对话记忆和互联网上的资料中提取出能用在当前对话的信息。

对于训练数据,Facebook在众包平台上发布了任务。
让参与者在对话中扮演一个特定的人格,并隔几小时、隔几天对同一个话题进行讨论,收集成多轮对话数据集。
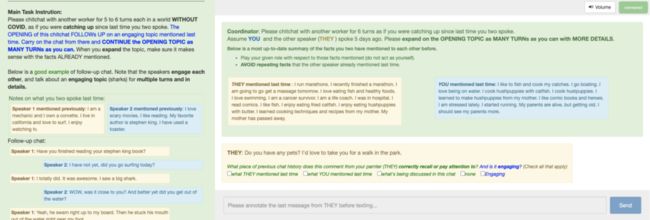
AI从网上搜索资料并用于聊天的能力,也是从人类那里学来的。
同样是在众包平台上,这次的任务是让一个人描述自己的兴趣开启话题,另一个人可以上网搜索并接上对话。

这样AI不仅能学到人类在面对不同话题的适合搜索什么关键词,还能学到最后什么样的信息可以用在聊天上。
实验结果上,BlenderBot2.0对之前对话内容的使用率提高了55%,在对话中的事实一致性提高了12%,而人类评估员打出的分数提高了17%。
能上网搜索信息还让AI能够参与人类世界中最新的话题,比如谈论新上映的电视剧。
如果和BlenderBot1.0聊起今年新片《旺达幻视》,他只能说我没看过,这天就聊死了。
Blender2.0就可以搜索后说出片中最喜欢的角色是谁,让人更有把对话继续下去的欲望。

AI的记忆不再静止于它完成训练的那一刻。
LeCun点赞,马斯克担忧它的三观
三巨头之一的LeCun第一时间转发了BlenderBot2.0并评价为“首个能对任意话题Hold住多轮对话的聊天机器人”

马斯克所担心的,是AI从开放互联网上获取信息很快会变得三观不正。
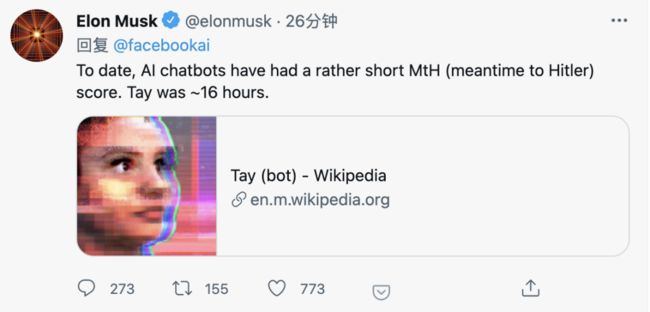
他举的例子是微软推出的Tay机器人在16小时左右就被网友聊成了纳粹支持者,最后被迫下架。
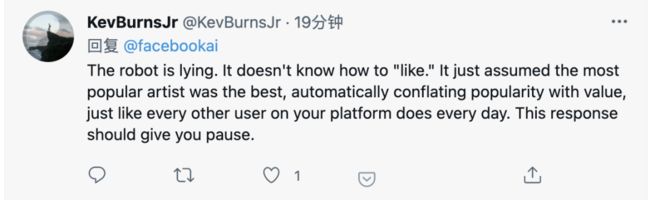
对于和AI讨论“最喜欢的作品”这回事,有人表现出了不信任:
AI不会喜欢某个作品,只是自动把最流行的作品当成最好的,和网上追逐热点的大多数人一样。
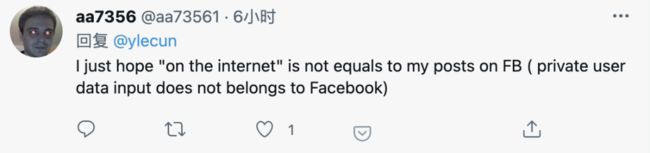
有人看出了潜在的隐私风险:
你们说让AI上网搜索,不会是在Facebook上搜索我发的帖子吧。
如果你感兴趣,可以到Facebook的Parlai平台下载模