前端面试题 —— 浏览器原理(二)
目录
一、有哪些可能引起前端安全的问题?
二、网络劫持有哪几种,如何防范?
三、浏览器渲染进程的线程有哪些
四、僵尸进程和孤儿进程是什么?
五、为什么需要浏览器缓存?
六、对浏览器的理解
七、CSS 如何阻塞文档解析?
八、如何优化关键渲染路径?
九、IndexedDB有哪些特点?
十、 如何阻止事件冒泡?
十一、同步和异步的区别
十二、什么是执行栈
十三、事件触发的过程是怎样的?
十四、什么是中间人攻击?如何防范中间人攻击?
十五、对Service Worker的理解
十六、点击刷新按钮或者按 F5、按 Ctrl+F5 (强制刷新)、地址栏回车有什么区别?
十七、什么是文档的预解析?
十八、正向代理和反向代理的区别
十九、Nginx的概念及其工作原理
一、有哪些可能引起前端安全的问题?
- 跨站脚本 (Cross-Site Scripting, XSS): ⼀种代码注⼊⽅式, 为了与 CSS 区分所以被称作 XSS。早期常⻅于⽹络论坛, 起因是⽹站没有对⽤户的输⼊进⾏严格的限制, 使得攻击者可以将脚本上传到帖⼦让其他⼈浏览到有恶意脚本的⻚⾯, 其注⼊⽅式很简单包括但不限于 JavaScript / CSS / Flash 等
- iframe的滥⽤: iframe中的内容是由第三⽅来提供的,默认情况下他们不受控制,他们可以在iframe中运⾏JavaScirpt脚本、Flash插件、弹出对话框等等,这可能会破坏前端⽤户体验
- 跨站点请求伪造(Cross-Site Request Forgeries,CSRF): 指攻击者通过设置好的陷阱,强制对已完成认证的⽤户进⾏⾮预期的个⼈信息或设定信息等某些状态更新,属于被动攻击
- 恶意第三⽅库: ⽆论是后端服务器应⽤还是前端应⽤开发,绝⼤多数时候都是在借助开发框架和各种类库进⾏快速开发,⼀旦第三⽅库被植⼊恶意代码很容易引起安全问题
二、网络劫持有哪几种,如何防范?
网络劫持分为两种:
(1)DNS劫持: (输⼊京东被强制跳转到淘宝这就属于dns劫持)
- DNS强制解析: 通过修改运营商的本地DNS记录,来引导⽤户流量到缓存服务器
- 302跳转的⽅式: 通过监控⽹络出⼝的流量,分析判断哪些内容是可以进⾏劫持处理的,再对劫持的内存发起302跳转的回复,引导⽤户获取内容
(2)HTTP劫持: (访问⾕歌但是⼀直有贪玩蓝⽉的⼴告),由于http明⽂传输,运营商会修改你的http响应内容(即加⼴告)
DNS劫持由于涉嫌违法,已经被监管起来,现在很少会有DNS劫持,⽽http劫持依然非常盛行,最有效的办法就是全站HTTPS,将HTTP加密,这使得运营商⽆法获取明⽂,就⽆法劫持你的响应内容。
三、浏览器渲染进程的线程有哪些
浏览器的渲染进程的线程总共有五种:
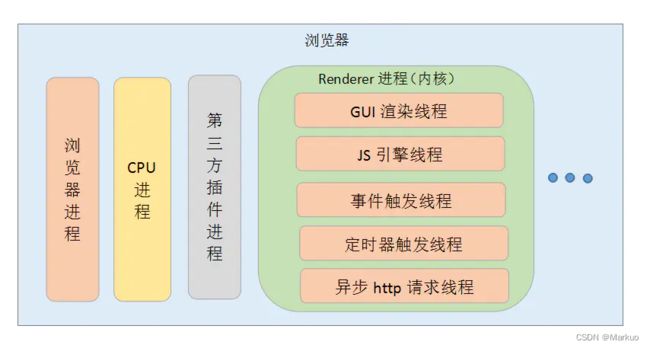
(1)GUI渲染线程
负责渲染浏览器页面,解析HTML、CSS,构建DOM树、构建CSSOM树、构建渲染树和绘制页面;当界面需要重绘或由于某种操作引发回流时,该线程就会执行。
注意:GUI渲染线程和JS引擎线程是互斥的,当JS引擎执行时GUI线程会被挂起,GUI更新会被保存在一个队列中等到JS引擎空闲时立即被执行。
(2)JS引擎线程
JS引擎线程也称为JS内核,负责处理Javascript脚本程序,解析Javascript脚本,运行代码;JS引擎线程一直等待着任务队列中任务的到来,然后加以处理,一个Tab页中无论什么时候都只有一个JS引擎线程在运行JS程序;
注意:GUI渲染线程与JS引擎线程的互斥关系,所以如果JS执行的时间过长,会造成页面的渲染不连贯,导致页面渲染加载阻塞。
(3)时间触发线程
时间触发线程属于浏览器而不是JS引擎,用来控制事件循环;当JS引擎执行代码块如setTimeOut时(也可是来自浏览器内核的其他线程,如鼠标点击、AJAX异步请求等),会将对应任务添加到事件触发线程中;当对应的事件符合触发条件被触发时,该线程会把事件添加到待处理队列的队尾,等待JS引擎的处理;
注意:由于JS的单线程关系,所以这些待处理队列中的事件都得排队等待JS引擎处理(当JS引擎空闲时才会去执行);
(4)定时器触发进程
定时器触发进程即setInterval与setTimeout所在线程;浏览器定时计数器并不是由JS引擎计数的,因为JS引擎是单线程的,如果处于阻塞线程状态就会影响记计时的准确性;因此使用单独线程来计时并触发定时器,计时完毕后,添加到事件队列中,等待JS引擎空闲后执行,所以定时器中的任务在设定的时间点不一定能够准时执行,定时器只是在指定时间点将任务添加到事件队列中;
注意:W3C在HTML标准中规定,定时器的定时时间不能小于4ms,如果是小于4ms,则默认为4ms。
(5)异步http请求线程
- XMLHttpRequest连接后通过浏览器新开一个线程请求;
- 检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件,将回调函数放入事件队列中,等待JS引擎空闲后执行;
四、僵尸进程和孤儿进程是什么?
- 孤儿进程:父进程退出了,而它的一个或多个进程还在运行,那这些子进程都会成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
- 僵尸进程:子进程比父进程先结束,而父进程又没有释放子进程占用的资源,那么子进程的进程描述符仍然保存在系统中,这种进程称之为僵死进程。
五、为什么需要浏览器缓存?
对于浏览器的缓存,主要针对的是前端的静态资源,最好的效果就是,在发起请求之后,拉取相应的静态资源,并保存在本地。如果服务器的静态资源没有更新,那么在下次请求的时候,就直接从本地读取即可,如果服务器的静态资源已经更新,那么我们再次请求的时候,就到服务器拉取新的资源,并保存在本地。这样就大大的减少了请求的次数,提高了网站的性能。这就要用到浏览器的缓存策略了。
所谓的浏览器缓存指的是浏览器将用户请求过的静态资源,存储到电脑本地磁盘中,当浏览器再次访问时,就可以直接从本地加载,不需要再去服务端请求了。
使用浏览器缓存,有以下优点:
- 减少了服务器的负担,提高了网站的性能
- 加快了客户端网页的加载速度
- 减少了多余网络数据传输
六、对浏览器的理解
浏览器的主要功能是将用户选择的 web 资源呈现出来,它需要从服务器请求资源,并将其显示在浏览器窗口中,资源的格式通常是 HTML,也包括 PDF、image 及其他格式。用户用 URI(Uniform Resource Identifier 统一资源标识符)来指定所请求资源的位置。
HTML 和 CSS 规范中规定了浏览器解释 html 文档的方式,由 W3C 组织对这些规范进行维护,W3C 是负责制定 web 标准的组织。但是浏览器厂商纷纷开发自己的扩展,对规范的遵循并不完善,这为 web 开发者带来了严重的兼容性问题。
浏览器可以分为两部分,shell 和 内核。其中 shell 的种类相对比较多,内核则比较少。也有一些浏览器并不区分外壳和内核。从 Mozilla 将 Gecko 独立出来后,才有了外壳和内核的明确划分。
- shell 是指浏览器的外壳:例如菜单,工具栏等。主要是提供给用户界面操作,参数设置等等。它是调用内核来实现各种功能的。
- 内核是浏览器的核心。内核是基于标记语言显示内容的程序或模块。
七、CSS 如何阻塞文档解析?
理论上,既然样式表不改变 DOM 树,也就没有必要停下文档的解析等待它们。然而,存在一个问题,JavaScript 脚本执行时可能在文档的解析过程中请求样式信息,如果样式还没有加载和解析,脚本将得到错误的值,显然这将会导致很多问题。所以如果浏览器尚未完成 CSSOM 的下载和构建,而我们却想在此时运行脚本,那么浏览器将延迟 JavaScript 脚本执行和文档的解析,直至其完成 CSSOM 的下载和构建。也就是说,在这种情况下,浏览器会先下载和构建 CSSOM,然后再执行 JavaScript,最后再继续文档的解析。
八、如何优化关键渲染路径?
为尽快完成首次渲染,我们需要最大限度减小以下三种可变因素:
- 关键资源的数量。
- 关键路径长度。
- 关键字节的数量。
关键资源是可能阻止网页首次渲染的资源。这些资源越少,浏览器的工作量就越小,对 CPU 以及其他资源的占用也就越少。同样,关键路径长度受所有关键资源与其字节大小之间依赖关系图的影响:某些资源只能在上一资源处理完毕之后才能开始下载,并且资源越大,下载所需的往返次数就越多。最后,浏览器需要下载的关键字节越少,处理内容并让其出现在屏幕上的速度就越快。要减少字节数,我们可以减少资源数(将它们删除或设为非关键资源),此外还要压缩和优化各项资源,确保最大限度减小传送大小。
优化关键渲染路径的常规步骤如下:
- 对关键路径进行分析和特性描述:资源数、字节数、长度。
- 最大限度减少关键资源的数量:删除它们,延迟它们的下载,将它们标记为异步等。
- 优化关键字节数以缩短下载时间(往返次数)。
- 优化其余关键资源的加载顺序:您需要尽早下载所有关键资产,以缩短关键路径长度
九、IndexedDB有哪些特点?
IndexedDB 具有以下特点:
- 键值对储存:IndexedDB 内部采用对象仓库(object store)存放数据。所有类型的数据都可以直接存入,包括 JavaScript 对象。对象仓库中,数据以"键值对"的形式保存,每一个数据记录都有对应的主键,主键是独一无二的,不能有重复,否则会抛出一个错误。
- 异步:IndexedDB 操作时不会锁死浏览器,用户依然可以进行其他操作,这与 LocalStorage 形成对比,后者的操作是同步的。异步设计是为了防止大量数据的读写,拖慢网页的表现。
- 支持事务:IndexedDB 支持事务(transaction),这意味着一系列操作步骤之中,只要有一步失败,整个事务就都取消,数据库回滚到事务发生之前的状态,不存在只改写一部分数据的情况。
- 同源限制:IndexedDB 受到同源限制,每一个数据库对应创建它的域名。网页只能访问自身域名下的数据库,而不能访问跨域的数据库。
- 储存空间大:IndexedDB 的储存空间比 LocalStorage 大得多,一般来说不少于 250MB,甚至没有上限。
- 支持二进制储存:IndexedDB 不仅可以储存字符串,还可以储存二进制数据(ArrayBuffer 对象和 Blob 对象)。
十、 如何阻止事件冒泡?
- 普通浏览器使用:event.stopPropagation()
- IE浏览器使用:event.cancelBubble = true
十一、同步和异步的区别
- 同步指的是当一个进程在执行某个请求时,如果这个请求需要等待一段时间才能返回,那么这个进程会一直等待下去,直到消息返回为止再继续向下执行。
- 异步指的是当一个进程在执行某个请求时,如果这个请求需要等待一段时间才能返回,这个时候进程会继续往下执行,不会阻塞等待消息的返回,当消息返回时系统再通知进程进行处理。
十二、什么是执行栈
可以把执行栈认为是一个存储函数调用的栈结构,遵循先进后出的原则。

当开始执行 JS 代码时,根据先进后出的原则,后执行的函数会先弹出栈,可以看到,foo函数后执行,当执行完毕后就从栈中弹出了。
平时在开发中,可以在报错中找到执行栈的痕迹:
function foo() {
throw new Error('error')
}
function bar() {
foo()
}
bar()
可以看到报错在 foo函数,foo函数又是在 bar函数中调用的。当使用递归时,因为栈可存放的函数是有限制的,一旦存放了过多的函数且没有得到释放的话,就会出现爆栈的问题
function bar() {
bar()
}
bar()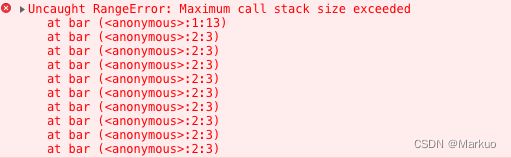
十三、事件触发的过程是怎样的?
事件触发有三个阶段:
- window往事件触发处传播,遇到注册的捕获事件会触发
- 传播到事件触发处时触发注册的事件
- 从事件触发处往 window传播,遇到注册的冒泡事件会触发
事件触发一般来说会按照上面的顺序进行,但是也有特例,如果给一个body中的子节点同时注册冒泡和捕获事件,事件触发会按照注册的顺序执行。
// 以下会先打印冒泡然后是捕获
node.addEventListener(
'click',
event => {
console.log('冒泡')
},
false
)
node.addEventListener(
'click',
event => {
console.log('捕获 ')
},
true
)通常使用addEventListener注册事件,该函数的第三个参数可以是布尔值,也可以是对象。对于布尔值useCapture参数来说,该参数默认值为false,useCapture决定了注册的事件是捕获事件还是冒泡事件。对于对象参数来说,可以使用以下几个属性:
- capture:布尔值,和 useCapture 作用一样
- once:布尔值,值为 true 表示该回调只会调用一次,调用后会移除监听
- passive:布尔值,表示永远不会调用 `preventDefault`
一般来说,如果只希望事件只触发在目标上,这时候可以使用 stopPropagation 来阻止事件的进一步传播。通常认为 stopPropagation 是用来阻止事件冒泡的,其实该函数也可以阻止捕获事件。
stopImmediatePropagation 同样也能实现阻止事件,但是还能阻止该事件目标执行别的注册事件。
node.addEventListener(
'click',
event => {
event.stopImmediatePropagation()
console.log('冒泡')
},
false
)
// 点击 node 只会执行上面的函数,该函数不会执行
node.addEventListener(
'click',
event => {
console.log('捕获 ')
},
true
)十四、什么是中间人攻击?如何防范中间人攻击?
中间⼈ (Man-in-the-middle attack, MITM) 是指攻击者与通讯的两端分别创建独⽴的联系, 并交换其所收到的数据, 使通讯的两端认为他们正在通过⼀个私密的连接与对⽅直接对话, 但事实上整个会话都被攻击者完全控制。在中间⼈攻击中,攻击者可以拦截通讯双⽅的通话并插⼊新的内容。
攻击过程如下:
- 客户端发送请求到服务端,请求被中间⼈截获
- 服务器向客户端发送公钥
- 中间⼈截获公钥,保留在自己手上。然后自己生成⼀个伪造的公钥,发给客户端
- 客户端收到伪造的公钥后,⽣成加密hash值发给服务器
- 中间⼈获得加密hash值,用自己的私钥解密获得真秘钥,同时⽣成假的加密hash值,发给服务器
- 服务器⽤私钥解密获得假密钥,然后加密数据传输给客户端
十五、对Service Worker的理解
Service Worker 是运行在浏览器背后的独立线程,一般可以用来实现缓存功能。使用 Service Worker的话,传输协议必须为 HTTPS。因为 Service Worker 中涉及到请求拦截,所以必须使用 HTTPS 协议来保障安全。
Service Worker 实现缓存功能一般分为三个步骤:首先需要先注册 Service Worker,然后监听到 install 事件以后就可以缓存需要的文件,那么在下次用户访问的时候就可以通过拦截请求的方式查询是否存在缓存,存在缓存的话就可以直接读取缓存文件,否则就去请求数据。以下是这个步骤的实现:
// index.js
if (navigator.serviceWorker) {
navigator.serviceWorker
.register('sw.js')
.then(function(registration) {
console.log('service worker 注册成功')
})
.catch(function(err) {
console.log('servcie worker 注册失败')
})
}
// sw.js
// 监听 `install` 事件,回调中缓存所需文件
self.addEventListener('install', e => {
e.waitUntil(
caches.open('my-cache').then(function(cache) {
return cache.addAll(['./index.html', './index.js'])
})
)
})
// 拦截所有请求事件
// 如果缓存中已经有请求的数据就直接用缓存,否则去请求数据
self.addEventListener('fetch', e => {
e.respondWith(
caches.match(e.request).then(function(response) {
if (response) {
return response
}
console.log('fetch source')
})
)
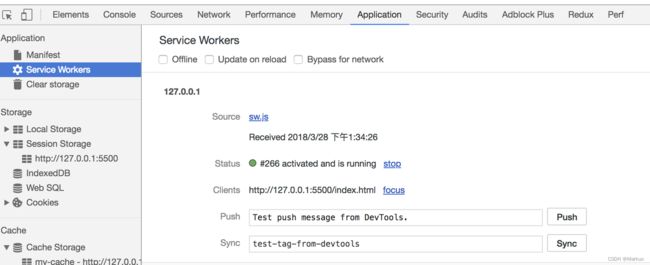
})打开页面,可以在开发者工具中的 Application 看到 Service Worker 已经启动了:
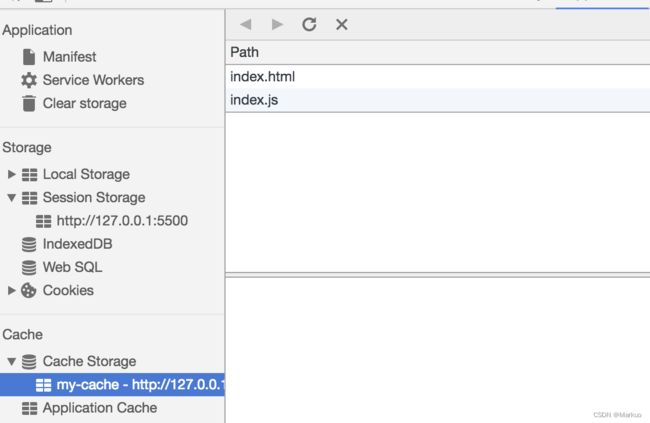
在 Cache 中也可以发现所需的文件已被缓存:
十六、点击刷新按钮或者按 F5、按 Ctrl+F5 (强制刷新)、地址栏回车有什么区别?
- 点击刷新按钮或者按 F5:浏览器直接对本地的缓存文件过期,但是会带上If-Modifed-Since,If-None-Match,这就意味着服务器会对文件检查新鲜度,返回结果可能是 304,也有可能是 200。
- 用户按 Ctrl+F5(强制刷新):浏览器不仅会对本地文件过期,而且不会带上 If-Modifed-Since,If-None-Match,相当于之前从来没有请求过,返回结果是 200。
- 地址栏回车: 浏览器发起请求,按照正常流程,本地检查是否过期,然后服务器检查新鲜度,最后返回内容。
十七、什么是文档的预解析?
Webkit 和 Firefox 都做了这个优化,当执行 JavaScript 脚本时,另一个线程解析剩下的文档,并加载后面需要通过网络加载的资源。这种方式可以使资源并行加载从而使整体速度更快。需要注意的是,预解析并不改变 DOM 树,它将这个工作留给主解析过程,自己只解析外部资源的引用,比如外部脚本、样式表及图片。
十八、正向代理和反向代理的区别
正向代理:客户端想获得一个服务器的数据,但是因为种种原因无法直接获取。于是客户端设置了一个代理服务器,并且指定目标服务器,之后代理服务器向目标服务器转交请求并将获得的内容发送给客户端。这样本质上起到了对真实服务器隐藏真实客户端的目的。实现正向代理需要修改客户端,比如修改浏览器配置。
反向代理:服务器为了能够将工作负载分不到多个服务器来提高网站性能 (负载均衡)等目的,当其受到请求后,会首先根据转发规则来确定请求应该被转发到哪个服务器上,然后将请求转发到对应的真实服务器上。这样本质上起到了对客户端隐藏真实服务器的作用。
一般使用反向代理后,需要通过修改 DNS 让域名解析到代理服务器 IP,这时浏览器无法察觉到真正服务器的存在,当然也就不需要修改配置了。
两者区别如图示:

正向代理和反向代理的结构是一样的,都是 client-proxy-server 的结构,它们主要的区别就在于中间这个 proxy 是哪一方设置的。在正向代理中,proxy 是 client 设置的,用来隐藏 client;而在反向代理中,proxy 是 server 设置的,用来隐藏 server。
十九、Nginx的概念及其工作原理
Nginx 是一款轻量级的 Web 服务器,也可以用于反向代理、负载平衡和 HTTP 缓存等。Nginx 使用异步事件驱动的方法来处理请求,是一款面向性能设计的 HTTP 服务器。
传统的 Web 服务器如 Apache 是 process-based 模型的,而 Nginx 是基于event-driven模型的。正是这个主要的区别带给了 Nginx 在性能上的优势。
Nginx 架构的最顶层是一个 master process,这个 master process 用于产生其他的 worker process,这一点和Apache 非常像,但是 Nginx 的 worker process 可以同时处理大量的HTTP请求,而每个 Apache process 只能处理一个。