grafana面板介绍
grafana 快速使用
背景
随着公司业务的不断发展,紧接来的是业务种类的增加、服务器数量的增长、网络环境的越发复杂以及发布更加频繁,从而不可避免地带来了线上事故的增多,因此需要对服务器到应用的全方位监控,提前预警,目前多采用prometheus/Zabbix + grafana的方式来解决这个问题。
Grafana简介
Grafana 是一个可视化工具,简单点说就是用来展示数据的。它和Zabbix、Prometheus 有本质区别,在于它不能解决监控问题,仅用于展示。也就是说,在监控领域,Grafana 需要配合 Zabbix、Prometheus 等工具一起使用,以获取数据源。
官网地址:https://grafana.com/
官方文档:https://grafana.com/docs/grafana/next/
官方模板地址: https://grafana.com/grafana/dashboards/
Grafana 官方还对 Grafana 的适用场景以及基本特征作了介绍:
-
工业物联网场景数据
grafana最常用于因特网基础设施和应用分析,但在其他领域也有机会用到,比如:工业传感器、家庭自动化、过程控制等等。
-
多租户和多维度的权限控制
支持多租户的场景·使用Org区分不同的用户,数据源和dashboard进行隔离。多种用户角色·除了支持用户也支持Team的管理。多维度的权限控制,支持org·folder·dashboard三层的权限控制·可满足各种使用场景。 -
仪表板和可视化
Grafana支持众多的显示pane!。可帮助您快速构建各类显示效果·满足各类场景的需求、同时通过简单的拖拉缩放即可快速进行排版布局,操作简易方便,支持变量,注释的特性,可方便制作动态panel。同一张dashboard通过动态切换变量更换显示的数据。 -
数据源和集成
支持众多的数据源,内置集成Graphite,Prometheus·InfluxDB,MySQL·PostgreSQL和Elasticsearch:等内置插件,另外支持众多的第三方数据源的插件·并可自行进行扩展·方便接入更多的数据来源并进行显示。每种数据源有自己特性化的查询编辑器·帮助用户简单方便掌握各类数据的查询配置。 -
警报和通知
Grafana附带内置警报引擎,允许用户设置一定的条件规则到特定panel上。数据刷新警报触发之后,可产生一系列的事件。并内置插件支持显示·同时结合notification通知功能·警报触发之后可自动发送通知·支持的方式众多(例如,Email,Slack,LINE,Telegram,自定义的webhook等) -
和Prometheus·Loki集成度高
Prometheus是一个领先的开源监控解决方案·属于一站式监控告警平台,依赖少、功能齐全。Loki是一个可水平伸缩、高可用、多租户的日志聚合系统。在grafana.上都有高度的集成和方便的使用。 -
插件化的结构·更易于扩展
Grafana是插件化的架构·对于panel·data source·app都可以开发插件进行扩展·插件的开发轻量简易·放入指定插件目录下注册即可生效·对于显示效果的增加或是更多数据源的接入都可以轻松解决。 -
开源社区
拥有强大的用户社区和活跃的贡献者·它已拥有54个数据源·50个面板·17个应用程序和1732个仪表盘·在github上有25000多次提交,并且Star为35.6K之多·持续更新,快速进版增加新功能。
这里需要留意的是,上面官方列举的数据源都是时序型数据库。这也透露出 Grafana 的另一大适用性:Grafana 一般是配合时序数据库做数据展示的。
Grafana 与 Kibana 的区别
Kibana 是运维圈耳熟能详的后端数据实时展示工具。日常工作中,大家都用 Kibana 结合Logstash、ElasticSearch 等组件一起使用做日志展示、索引、分析的。但Kibana也可以接入其他数据源的,只不过最常见的用法还是展示日志。
Grafana 最早其实应该是 Kibana3 的一个分支。不同的是,Grafana 拥有自己的权限管理和用户管理系统,而 Kibana 没有权限管理系统。Kibana 和 ES 结合紧密,支持强大的ES语法,比较适合做一些多维度的分析和查询,而Grafana更适合用于展示,图形比Kibana美观很多。
简易安装
安装方式有很多,本次采用docker方式
docker run -d --name=grafana -p 3000:3000 grafana/grafana:9.5.7
浏览器访问: http://xx.xx.xx.xx:3000/login(要换成你的IP)
首次登陆账号和密码都是:admin
页面按钮功能介绍
搜索
搜索已有的面板

添加

- New dashboards:添加仪表盘
- Import dashboards:可导入模板仪表板文件或者json(模板地址:https://grafana.com/grafana/dashboards/)
- Create alert rule:创建告警规则
总览

Starred
仪表盘收藏:
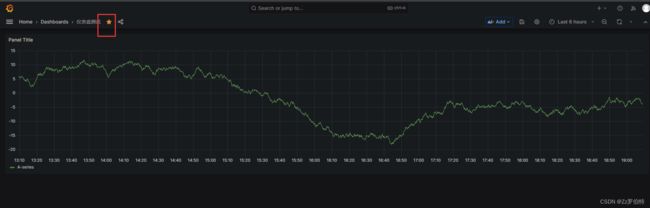
仪表盘管理
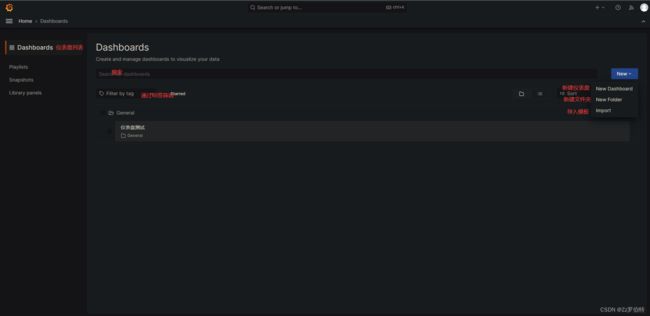
Palylist
播放列表
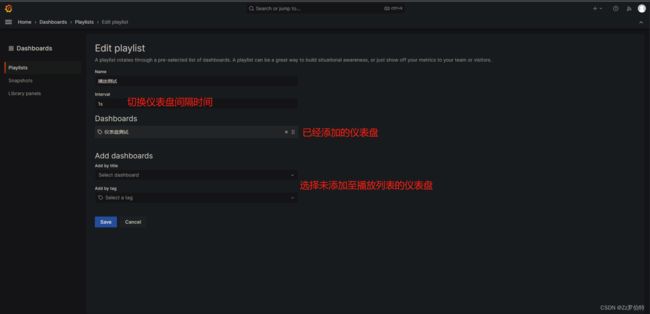
可以将多个仪表盘添加至播放列表,通过一个大屏循环播放。适合用作数据展示给公众浏览。
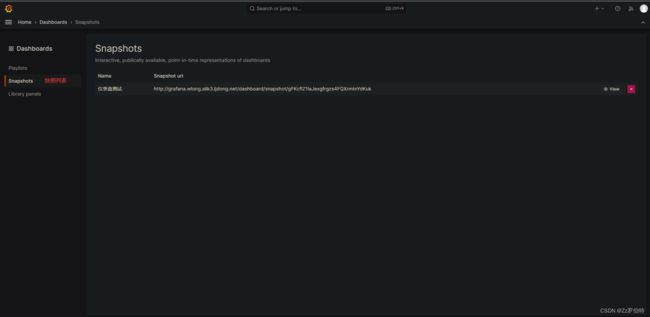
Snapshots
快照
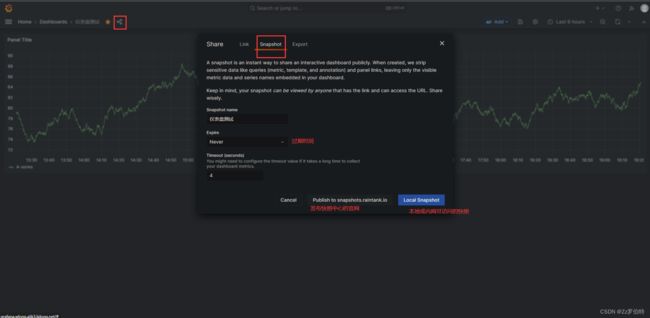
是一种公开共享仪表板,任何人都可以访问,剥离出查询等敏感数据,并不可操作,仅展示某一刻的可见的数据。
探索
以便专注于查询语句编写和数据展示,直到写出有一个有效的查询语句,然后再考虑构建仪表板。减少不必要信息元素的干扰,用于调试和查看数据。

告警通知
告警规则和告警设置
下面以添加一个webhook告警的例子来讲解,以下步骤存在顺序!!!
Contact point
首先,在Contact point(链接点)添加一个webhook地址,如下:

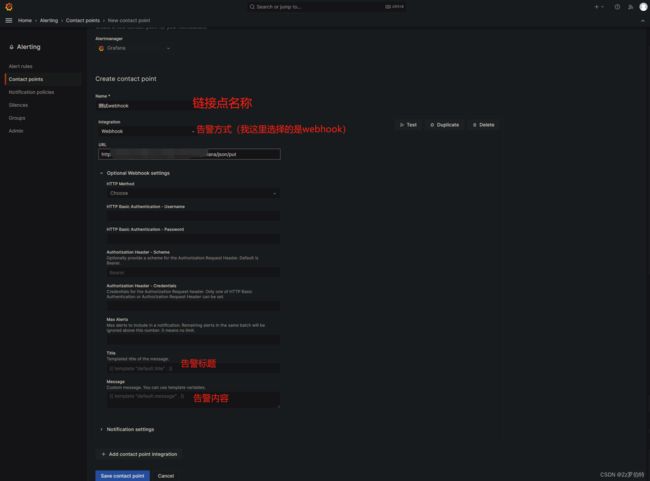
注意这里的
告警标题和告警内容(可以都不添加,不添加得话,grafana返回给webhook得json少两个字段,即title和message),他是模板化得一个配置,需要引用外部你用go语言自定义得模板我们这里先选择不添加!

grafana返回给webhook的是一个json体,如下:
来源:https://grafana.com/docs/grafana/v9.5/alerting/manage-notifications/webhook-notifier/ { "receiver": "My Super Webhook", "status": "firing", "orgId": 1, "alerts": [ { "status": "firing", "labels": { "alertname": "High memory usage", "team": "blue", "zone": "us-1" }, "annotations": { "description": "The system has high memory usage", "runbook_url": "https://myrunbook.com/runbook/1234", "summary": "This alert was triggered for zone us-1" }, "startsAt": "2021-10-12T09:51:03.157076+02:00", "endsAt": "0001-01-01T00:00:00Z", "generatorURL": "https://play.grafana.org/alerting/1afz29v7z/edit", "fingerprint": "c6eadffa33fcdf37", "silenceURL": "https://play.grafana.org/alerting/silence/new?alertmanager=grafana&matchers=alertname%3DT2%2Cteam%3Dblue%2Czone%3Dus-1", "dashboardURL": "", "panelURL": "", "valueString": "[ metric='' labels={} value=14151.331895396988 ]" }, { "status": "firing", "labels": { "alertname": "High CPU usage", "team": "blue", "zone": "eu-1" }, "annotations": { "description": "The system has high CPU usage", "runbook_url": "https://myrunbook.com/runbook/1234", "summary": "This alert was triggered for zone eu-1" }, "startsAt": "2021-10-12T09:56:03.157076+02:00", "endsAt": "0001-01-01T00:00:00Z", "generatorURL": "https://play.grafana.org/alerting/d1rdpdv7k/edit", "fingerprint": "bc97ff14869b13e3", "silenceURL": "https://play.grafana.org/alerting/silence/new?alertmanager=grafana&matchers=alertname%3DT1%2Cteam%3Dblue%2Czone%3Deu-1", "dashboardURL": "", "panelURL": "", "valueString": "[ metric='' labels={} value=47043.702386305304 ]" } ], "groupLabels": {}, "commonLabels": { "team": "blue" }, "commonAnnotations": {}, "externalURL": "https://play.grafana.org/", "version": "1", "groupKey": "{}:{}", "truncatedAlerts": 0, "title": "[FIRING:2] (blue)", "state": "alerting", "message": "**Firing**\n\nLabels:\n - alertname = T2\n - team = blue\n - zone = us-1\nAnnotations:\n - description = This is the alert rule checking the second system\n - runbook_url = https://myrunbook.com\n - summary = This is my summary\nSource: https://play.grafana.org/alerting/1afz29v7z/edit\nSilence: https://play.grafana.org/alerting/silence/new?alertmanager=grafana&matchers=alertname%3DT2%2Cteam%3Dblue%2Czone%3Dus-1\n\nLabels:\n - alertname = T1\n - team = blue\n - zone = eu-1\nAnnotations:\nSource: https://play.grafana.org/alerting/d1rdpdv7k/edit\nSilence: https://play.grafana.org/alerting/silence/new?alertmanager=grafana&matchers=alertname%3DT1%2Cteam%3Dblue%2Czone%3Deu-1\n" }
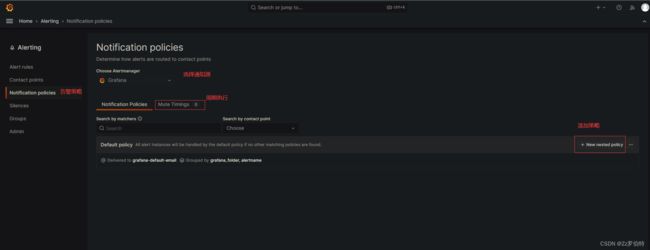
Notification policies
接下来我们来添加一下告警策略,点击 New nested policy
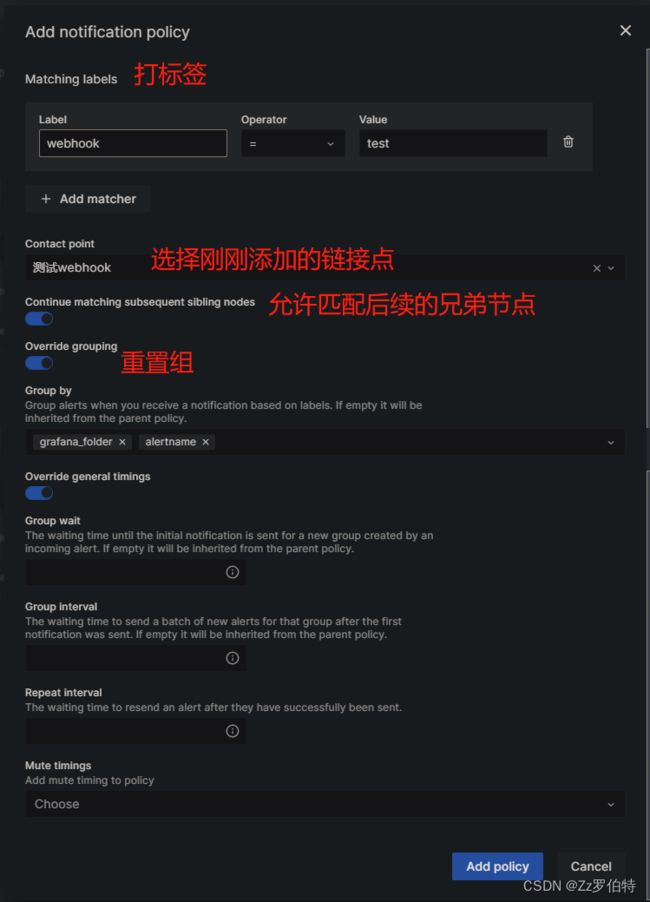
Matching labels指的是打标签,这里可以打多个标签;
Contact point 这里配的是链接点
这两个配置的意思是,告警将会根据标签匹配,如果标签完全匹配,则向链接点发送json数据
Continue matching subsequent sibling nodes: 暂时不清楚
Override grouping:暂时不清楚
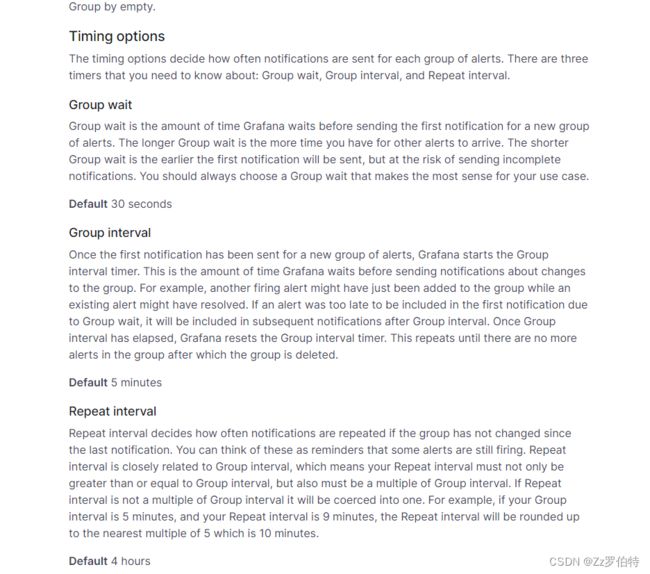
Override general timings:这个很重要!!!!!这个涉及到报警的频率
其中它包括3个参数,分别为Group wait,Group interval,Repeat interval
Group wait(分组等待时间):当多个告警条件同时满足时,Grafana会将这些告警分组,而Group wait表示在触发第一个告警后,等待其他告警条件满足的时间。举个例子,假设你有一个监控系统,同时监控服务器的CPU和内存使用率。如果设置了Group wait为5分钟,当CPU使用率和内存使用率同时超过阈值时,Grafana会等待5分钟,看是否还有其他告警条件满足。如果在这5分钟内没有其他告警条件满足,Grafana会触发告警。
Group interval(分组间隔时间):当多个告警条件同时满足且Group wait时间过去后,Grafana会触发告警并将这些告警分组。Group interval表示在触发第一个告警后,等待下一组告警的时间间隔。继续上面的例子,假设设置了Group interval为10分钟,当CPU使用率和内存使用率同时超过阈值并且Group wait时间过去后,Grafana会触发告警并将它们分组。然后,Grafana会等待10分钟,看是否还有其他告警条件满足。如果在这10分钟内有新的告警条件满足,它们会被添加到同一组告警中。
Repeat interval(重复间隔时间):当告警被触发后,Repeat interval表示在发送第一次告警通知后,等待下一次发送告警通知的时间间隔。举个例子,假设设置了Repeat interval为1小时,当某个告警触发后,Grafana会立即发送一次告警通知。然后,它会等待1小时,再次发送告警通知。这样的重复通知可以帮助确保持续关注并及时处理问题。
假设你有一个监控系统,用于监控公司的服务器。你设置了一个告警规则,当服务器的CPU使用率超过90%时,触发告警通知。同时,你将Repeat interval设置为30分钟。
现在假设某个服务器的CPU使用率超过了90%,Grafana会立即发送一次告警通知,通知相关人员服务器出现了问题。然后,Grafana会等待30分钟,再次检查服务器的CPU使用率。
如果在这30分钟内,服务器的CPU使用率仍然超过90%,Grafana会再次发送告警通知,提醒相关人员问题仍然存在。然后,Grafana会再次等待30分钟,继续检查服务器的CPU使用率。
这个过程会一直重复下去,直到服务器的CPU使用率低于90%或者告警被关闭。每次重复间隔过后,Grafana都会重新检查服务器的状态,并决定是否发送新的告警通知。
对于这些字段的定义,官网地址如下:通知策略 |Grafana 文档
Mute timings:是否定期去执行
Alert rules
添加告警规则,找到你想添加告警的报表,来进行添加。

然后进去之后是下图这个页面
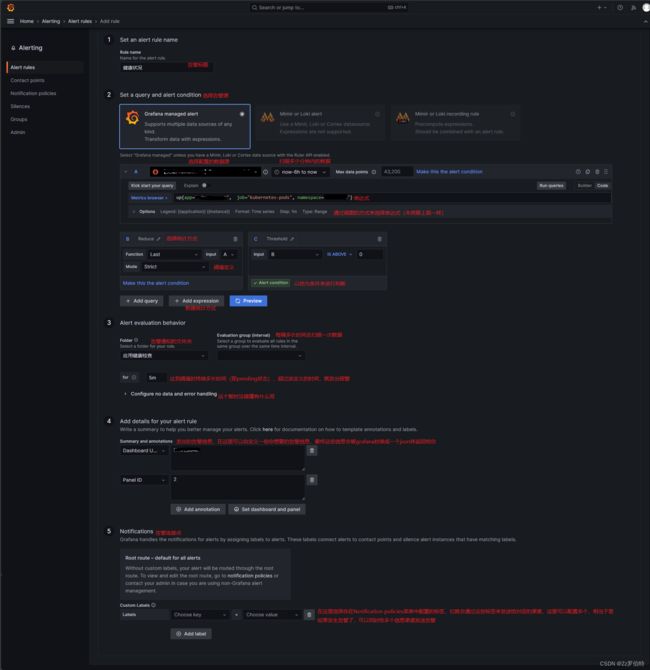
这里需要注意的地方是统计方式,你选择的函数不一样,就会导致计算结果不一样!
各个函数的含义,官方示意为:
地址:Queries and conditions | Grafana documentation
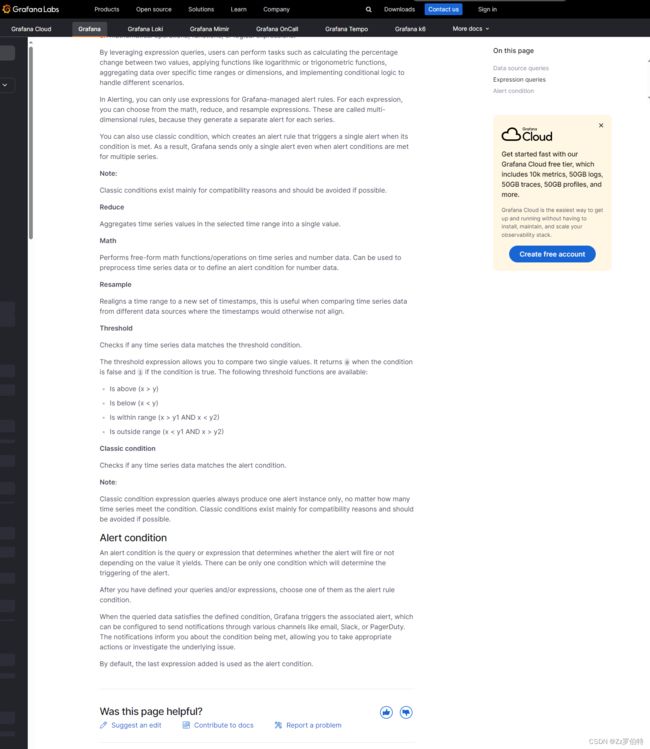
简单来说就是:
- Math:Math 选项允许您对数据进行数学运算。这可以用于执行各种统计任务,例如求平均值、求和、求积等。例如,您可以使用 Math 选项计算一个特定指标的移动平均值,以便更好地了解其趋势。
- Reduce:Reduce 选项允许您对数据进行聚合操作,即将多个数据点合并成一个或几个数据点。这可以用于计算总和、平均值、中位数等统计量。例如,您可以使用 Reduce 选项计算一个特定时间段内所有数据点的总和,以便了解该指标的整体表现。
- Classic conditions:Classic conditions 选项允许您根据特定条件过滤数据。这可以用于识别符合特定标准的数据点。例如,您可以使用 Classic conditions 选项过滤出所有温度超过特定阈值的数据点,以便更好地了解哪些设备可能存在问题。
- Resample:Resample 选项允许您对数据进行重新采样,即根据指定的时间间隔对数据进行聚合或平均。这可以用于降低数据点的数量,以便更好地理解数据的总体趋势。例如,您可以使用 Resample 选项将每秒的数据点减少到每分钟的平均值,以便更方便地进行数据分析。
- Threshold:Threshold 选项允许您设置阈值,以便识别超出特定范围的数据点。这可以用于检测异常情况或识别潜在的问题。例如,您可以使用 Threshold 选项设置一个阈值,当温度超过该阈值时,系统将自动发出警报,以便您能够及时发现并解决问题。
然后,报警就可以配置成功了,你可以观察一下是否报警,如果报警有延迟,或者没有到达预期时间,建议调节一下Override general timings 的三个指标!!
Silences
此处功能是告警抑制功能
有这么一个场景,一个项目出现问题后,会一直报警,然后你想在1天内,或者1个月内不想收到他的报警(报错一直未解决),就可以使用此功能!
我在项目中的应用是,项目每次通过jenkins发布的时候,不想让他告警(因为这个是正常的项目迭代,不是异常告警),就可以使用此功能!

相关的API接口如下:Swagger Editor
delete
/api/alertmanager/grafana/api/v2/silence/{SilenceId}
get
/api/alertmanager/grafana/api/v2/silence/{SilenceId}
/api/alertmanager/grafana/api/v2/silences
post
/api/alertmanager/grafana/api/v2/silences
{
"comment": "string",
"createdBy": "string",
"endsAt": "2023-11-18T06:46:52.218Z",
"id": "string",
"matchers": [
{
"isEqual": true,
"isRegex": true,
"name": "string",
"value": "string"
}
],
"startsAt": "2023-11-18T06:46:52.218Z"
}
如果有权限的话,需要增加header
如下
curl --location 'http://xxxxx/api/alertmanager/grafana/api/v2/silences' --header 'Authorization:Bearer glsa_xxxxbreEfWjpyrlMxxxxbNII1_31530b12' --header 'Content-Type:application/json' --data '{"startsAt":"2023-08-15T07:18:20.968Z","endsAt":"2023-08-15T09:18:20.968Z","comment":"created2023-08-1515:18","createdBy":"admin","matchers":[{"name":"project","value":"xxx","isEqual":true,"isRegex":true}]}'
权限在grafana列表页面的Administration-Service accounts中配置
踩坑点
grafana日志后台一直报错 database is locked
lvl=eror msg="failed to look up user based on cookie" logger=context error="database is locked"
原因:表示 sqlite 数据库存在问题。如果数据库在崩溃后处于不一致状态,或者磁盘出现问题,则可能会发生这种情况
解决方案:
Grafana Logs “database is locked” · Issue #16638 · grafana/grafana (github.com)
k8s方式:
在默认配置/etc/grafana/grafana.ini添加
[database]
type=sqlite3
cache_mode = shared
下面这种方式我没是成功:

还有一个方案也没有试成功:
“database is locked” - unable to use grafana anymore - General - Grafana Labs Community Forums
sqlite3 grafana.db '.clone grafana-new.db'
mv grafana.db grafana-old.db
mv grafana-new.db grafana.db
参考文献
Grafana 是什么_请叫我王运维的博客-CSDN博客_grafana
分分钟搞定Grafana(图文详解)_奔跑中的小猿的博客-CSDN博客_grafana
【精选】Grafana入门使用_W1nk的博客-CSDN博客
Prometheus+Grafana基础介绍及搭建使用_正在努力的小杰的博客-CSDN博客