redis篇-源码篇
一、字符串原理
1. 概述
redis字符串特点:
- redis字符串在内存中是字符数组
- redis字符串不是以NULL结尾的,因为要获取以NULL结尾的字符串的长度是使用strlen标准库函数来计算的,该算法的时间复杂度是O(n),需要对字节数组遍历,单线程的redis承受不起
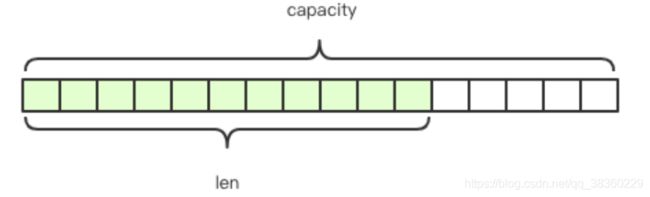
数据结构:redis的字符串为SDS,数据结构如下
struct SDS{
T capacity; // 数组容量
T len; // 数组长度
byte flags; // 特殊标志位
byte[] content; // 数组内容
} 其中,content存储了字符串内容,capacity表示所分配的数据的长度,len表示字符串的实际长度
append操作:redis字符串支持append操作,如果数组没有冗余空间,append会涉及分配新数组,然后将旧数组的内容复制过来,再append新内容。若字符串长度很长,内存分配和复制开销会很大
sds sdscatlen(sds s, const void *t, size_t len) {
// 1. 计算长度
size_t curlen = sdslen(s);
// 2. 按需调整内存空间,若内存不足,则分配新内存块并将旧数据复制到新内存
s = sdsMakeRoomFor(s, len);
// 3. 系统内存不足,分配失败
if(s == NULL) return NULL;
// 4. append操作
memcpy(s+curlen, t, len);
// 5. 设置追加后长度
sdssetlen(s, curlen+len);
s.content[curlen+len]='\0';
return s;
}sds优化:
- redis在字符串比较短时,capacity和len可以使用byte和short来表示
- redis规定字符串长度不得超过512MB,创建字符串时len和capacity一样长,不会分配冗余空间
2. embstr VS raw
a.概述
redis字符串有两种存储方式,在长度特别短时,使用embstr形式存储,而当超过44字节时,使用row存储
b.redis对象头
定义:所有redis对象都有以下数据结构,称为对象头
struct RedisObject{
int4 type;
int4 encoding;
int24 lru;
int32 refcount;
void *ptr;
}组成(16个字节):
- type(4bit):对象的类型
- encoding(4bit):不同对象的存储形式
- lru(24bit):记录对象lru替换时需要的时间戳
- refcount(32bit):4个字节,用以统计对象头的引用计数
- ptr(64bit):64位系统有8个字节,指向对象内容
c. embstr和row的区别
embstr:
- embstr将redisObject对象头和SDS对象连续存储在一起,使用malloc一次性分配
- 内存分配器分配内存时,一般分配的内存大小为2/4/8/16/32/64字节,为了容纳embstr对象,jemalloc最少会分配32字节,若长一些,就是64字节。超过64字节,则转换为raw编码
- 64字节的embstr可用空间为44字节(redisobject占16字节,SDS基础信息占3字节,embstr内容中NULL占1字节,剩余44字节)
raw:raw需要使用两次malloc付费,两个对象头在内存地址上一般不连续

3. 扩容策略
在字符串长度小于1MB之前,扩容空间采用加倍策略,当大于1MB时,每次扩容增加1MB
4. 模拟代码TODO
二、字典原理
1. 概述
定义:字典是redis服务器中出现最为频繁的复合型数据结构
redis中字典的应用范围:
- hash数据类型
- 整个redis数据库的所有key和value也组成了一个全局字典
- 带过期时间的key集合
- zset集合中存储的value和score值的映射
struct RedisDb {
dict* dict; // 所有keys 映射关系 key:value
dict* expires; // 所有过期key 映射关系 key:时间戳
...
}
struct zset {
dict* dict; // 所有值 映射关系 value:score
zskiplist* zsl; // 跳表
}
2. 字典内部结构
结构:
- 字典结构内部包含两个hashtable,通常情况下只有一个hashtable有值,扩容时需要分配新的hashtable,然后进行渐进式扩容,这时候两个hashtable分别存储的是新的和旧的hashtable。迁移结束后,旧的hashtable删除,新的替代之

- hashtable使用开拉链法解决哈希冲突,数据结构为邻接矩阵
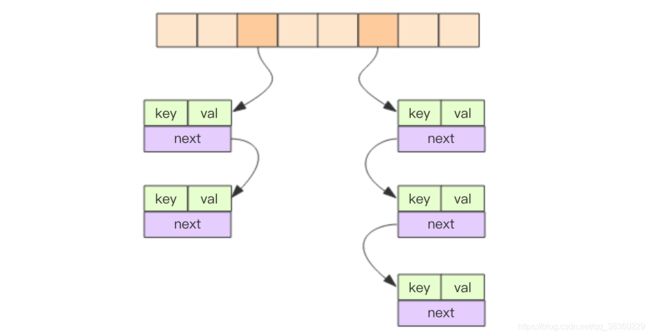
// 字典结构
struct dict {
...
dictht ht[2];
}
// 节点
struct dictEntry {
void *key;
void *val;
dictEntry *next;
}
// 邻接矩阵
struct dictht {
dictEntry **table; // 开拉链
long size; // 一维数组长度
long used; // hash表中元素个数
}
3. 渐进式 rehash
场景:大字典扩容耗时较长,需要重新申请新的数组,将旧数组的所有链表中的元素重新挂接到新的数组下,这是一个O(n)级别的操作。redis使用渐进式扩容,减少当次数据迁移的阻塞时间
过程:
- a. 搬迁过程会潜伏在当前字典的后续指令中(hset/hdel等)
dictEntry *dictAddRow(dict *d, void *key, dictEntry **existing){
long index;
dictEntry *entry;
dictht *ht;
// 小步迁移
if (dictIsRehashing(d)) _dictRehashStep(d);
// 计算key的下标,如果存在,则返回-1
if ((index = _dictKeyIndex(d, key, dictHashKey(d, key), existing)) == 1) return NULL;
// 判断字典是否处于rehash中,是则需要将新的元素挂载在新的数组下面
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
// 分配空间
entry = zmalloc(sizeof(*entry));
// 将新分配的节点加入数组中,作为数组的头结点
entry->next = ht->table[index];
ht->table[index] = entry;
ht->user++;
// 设置值
dictSetKey(d, entry, key);
return entry;
}- b. redis会在定时任务中对字典主动迁移
void databaseCron() {
...
// 主动rehash
if (server.activerehashing) {
for(int j = 0; j < dbs_per_call; j++) {
// 增量rehash,rehash_db指的是需要rehash的db下标
int work_done = incrementallyRehash(rehash_db);
// 如果函数进行了增量rehash,跳出循环,在下个周期循环在迁移
if(work_donw){
break;
} else {
rehash_db++;
rehash_db %= server.dbnum;
}
}
}
}4. 查找过程
查找过程:
T get(key){
int index = hash_fun(key) % size;
T entry = table[index];
while(entry!=NULL){
if(entry.key == key) {
return entry.value;
}
entry=entry.next;
}
return NULL;
}问题:hash_func将key映射成一个整数,若hash值均匀了,整个hashtable才会平衡,数组每个节点的链表才不会很长,查找性能才会比较稳定
hash函数:redis默认hash函数是siphash,算法在输入的key很小的情况下,也可以产生随机性特别好的输出,而且它的性能比较突出
hash攻击:若hash函数有偏向性,黑客可以利用偏向性对服务器进行攻击,导致hashtable的某个结点链表很长,进而导致查找效率由O(1)转换为O(n)
5. 扩容条件
条件:
- 正常情况下,hash表中元素个数等于第一维数组长度时,就会进行扩容,扩容后的数组长度是原来的2倍
- 如果redis在做bgsave,为减少内存页过多分离(COW),redis尽量不去扩容。如果元素个数已经达到了第一维数组长度的5倍,此时会进行强制扩容
static int _dictExpandIfNeeded(dict *d) {
// 字典正在rehash,直接返回
if (dictIsRehashing(d)) return DICT_OK;
// 如果hashtable为空,初始化hashtable大小
if (d->ht[0].size == 0) return dictExpand(d, DCIT_HT_INITAL_SIZE);
// 扩容条件,bgsave需要大于强制扩容比例,否则大于size即可
if (d->ht[0].used >= d->ht[0].size && (dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}6. 缩容条件
当hash表因为元素逐渐被删除变的稀疏时,redis会对hash表进行缩容以减少hash表一维数组的长度,缩容的条件是元素个数低于数组长度的百分之十,缩容不考虑hash表是否在做bgsave
// rehash 条件
int htNeedsResize(dict *dict) {
long long size,used;
size = dictSlots(dict);
used = dictSize(dict);
return (size > DICT_HT_INITIAL_SIZE && (used*100/size < HASHTABLE_MIN_FILL));
}7. set结构
set底层也是字典,只不过所有的value都是NULL,其他特性和map一样
三、压缩列表原理
1. 概述
场景:redis为了节省内部空间,zset和hash容器对象在元素个数较少时,采用压缩列表(ziplist)进行存储。
c:\redis>redis-cli.exe
127.0.0.1:6379> zadd program 1.0 go 2.0 java
(integer) 2
127.0.0.1:6379> debug object program
Value at:00007FCD92428600 refcount:1 encoding:ziplist serializedlength:26 lru:2213161 lru_seconds_idle:14
127.0.0.1:6379> hmset settest name zzh age 11
OK
127.0.0.1:6379> debug object settest
Value at:00007FCD924285F0 refcount:1 encoding:ziplist serializedlength:30 lru:2215894 lru_seconds_idle:11ziplist结构:压缩列表是一块连续的空间,元素之间紧挨着存储,没有冗余空间。ziplist支持双向遍历,通过zltail_offset定位到最后一个元素的位置,然后倒着遍历
struct ziplist {
int32 zlbytes; // 整个压缩列表占用字节数
int32 zltail_offset; // 最后一个元素距离压缩链表起始位置的偏移量,可快速定位最后节点
int16 zllength; // 元素个数
T[] entries; // 元素内容,依次紧挨
int8 zlend; // 标志压缩列表结束,值恒为 0xFF
} 
entry结构:entry块随着容纳的元素类型不同,也会有不同的结构。
struct entry {
int prevlen; // 前一个entry字节长度
int encoding; // 元素类型编码
optional byte[] content; // 元素内容
} entry结构中的prevlen字段:
entry结构中的prevlen字段:
- prevlen字段表示前一个entry的字节长度,当压缩列表倒着遍历时,需要通过这个字段来快速定位到下一个元素的起始位置。
- prevlen字段是一个可变整数,当字符串长度小于254时,使用一个字节表示;若达到或者超出254时,使用5个字节表示,此时第一个字节恒为0xFE,剩余四个字节表示字符串长度
entry结构中的encoding字段:
- encoding字段存储了元素内容的编码类型信息,ziplist通过这个字段来决定后面的content的形式
- redis通过该字段前缀位来识别具体存储的数据形式:00xxxxxx 最大长度位数为63的短字符,后面6个位存储字符串位数,剩余字节是字符串内容;01xxxxxx xxxxxxxx是中等长度字符串,后面14位表示字符串长度,剩余字节是字符串内容;10000000表特大字符串;11000000表int16,等等
entry结构中的content字段:content字段是可选的,对于很小的整数而言,内容已经内联到encoding字段尾部
2. 增加元素
增加元素过程:
- ziplist是紧凑存储,没有冗余空间,插入一个新的元素就需要调整用realloc扩展内存。
- realloc可能会重新分配内存空间,将之前的内容一次性拷贝到新的地址,也有可能会在原有的地址上进行扩展,不需要将旧的内容进行拷贝。
- 若ziplist占用内存过大,重新分配内存和拷贝内存会有很大的消耗,因此ziplist不适合大型字符串,存储元素不宜过多
3. 级联更新
定义:
- 若entry经过修改,由253字节变成254字节,那么它的下一个entry的prevlen字段就要更新,从1字节变成5字节,若后面这个entry的长度本来也是253字节,则再后面的entry的prevlen字段还需要继续更新。
- 如果ziplist里面每个entry恰好存储了253字节的内容,那么第一个entry内容修改后,会导致后续entry级联更新
- 删除某个节点可能也会导致级联更新
源码解读(TODO)
4. intset小整数集合
定义:当set集合容纳的元素是整数,并且元素个数较少时,redis会使用intset来存储集合元素。intset是紧凑的数组结构,同时支持 int16/int32/int64
struct intset {
int32 encoding; // 决定整数位宽是16位/32位/64位
int32 length; // 元素个数
int contents; // 整数数组,可以是16位/32位/64位
} 
127.0.0.1:6379> sadd settestnew1 1
(integer) 1
127.0.0.1:6379> debug object settestnew1
Value at:00007FCD92428660 refcount:1 encoding:intset serializedlength:11 lru:2216050 lru_seconds_idle:3
127.0.0.1:6379> sadd settestnew1 zzh
(integer) 1
127.0.0.1:6379> debug object settestnew1
Value at:00007FCD92428660 refcount:1 encoding:hashtable serializedlength:7 lru:2216132 lru_seconds_idle:2四、快速列表原理
1. 概述
场景:早期redis使用压缩列表和双向链表表示list列表,考虑到链表prev和next指针需要占用空间大(64位系统,需要8字节),每个节点内存单独分配,导致内存碎片化,因此使用quicklist代替ziplist和linkedlist
127.0.0.1:6379> rpush listtestnew ttt kkk
(integer) 2
127.0.0.1:6379> debug object listtestnew
Value at:00007FCD924286B0 refcount:1 encoding:quicklist serializedlength:23 lru:2216584 lru_seconds_idle:12 ql_nodes:1 ql_avg_node:2.00 ql_ziplist_max:-2 ql_compressed:0 ql_uncompressed_size:21结构:quicklist是linkedlist和ziplist的结合体,它将linkedlist按段切分,每一段使用ziplist让存储紧凑,多个ziplist之间使用双向指针串联。redis还会使用LZF算法对ziplist进行压缩存储

struct quicklist {
quicklistNode *head;
quicklistNode *next;
long count; // 元素个数
int nodes; // ziplist节点的个数
int compressDepth; // LZF算法压缩深度
}
struct quicklistNode {
quicklistNode *prev;
quicklistNode *tail;
ziplist *zl; // 指向压缩列表
int32 size; // ziplist的字节总数
int16 count; // ziplist中的元素个数
int2 encoding; // 存储形式 2bit,原生字节数组还是LZF压缩存储
}每个ziplist存多少元素:quicklist默认单个ziplist长度为8KB(可通过list-max-ziplist-size决定),超过这个字节数,会另起一个ziplist。
2. 压缩深度
参数设置:
- quicklist默认压缩深度是0,即不对ziplist进行压缩(可通过list-compress-depth调节)。
- 若压缩深度设置为1,quicklist首尾两个ziplist不压缩;若为2,quicklist首尾第一&第二个ziplist不压缩,下图压缩深度为1
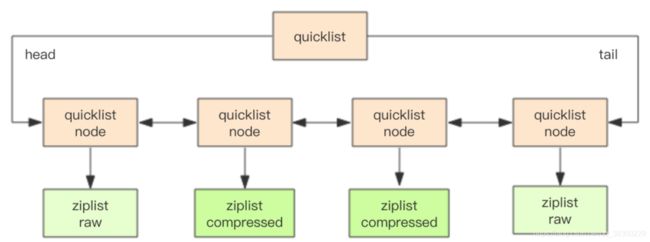
五、紧凑列表原理
1. 概述
场景:redis5.0引入了listpack,是ziplist升级版
结构:
- listpack与ziplist相似,少了zltail_offset字段
- listpack将长度字段放在尾部,存储的是当前字符的长度,因此listpack可以通过total_bytes字段和最后一个元素的长度字段计算出最后一个元素的位置。
struct listpack {
int32 total_bytes; // 占用总字节数
int16 size; // 元素个数
T[] entries; // 内容
int8 end; // 通zlen一样,恒为0xFF
} 
entry结构:
- listpack的entry长度字段使用varint编码,长度编码可以是1-5字节中任意一个长度。与UTF8编码类似,其通过每个字节最高位是否为1来决定编码长度

- entry对encoding字段也进行了设计

struct lpentry {
int encoding;
optional byte[] content;
int length;
}2. 级联更新
listpack设计消灭了ziplist存在级联更新的行为,元素与元素之间完全独立,不会因为元素长度变长导致后续元素内容受到影响
六、跳跃列表原理
1. 概述
场景:redis的zset是一个复合结构,一方面需要hash结构存储value和score的对应关系,另一方面需要提供根据score排序的功能,还需要提供能够指定score范围来获取value列表的功能

内部结构:zset内部实现是一个hash字典+一个跳跃列表(skiplist)
2. 基本结构
redis跳表结构:
- redis跳跃列表共有64层,可容纳2^64个元素
- redis每个kv块对应zslnode结构,kv header也是这个结构,只不过value字段是NULL值,score是Double.MIN_VALUE
- kv之间使用指针串起来,形成双向链表结构,是有序排列的,从小到大
- 不同kv层高可能不一样,层数越高kv越少,同一层kv会用指针串起来
- 每一层元素遍历都是从kv header开始的

java模拟代码:
class zslnode {
public String value;
public double score;
zslnode[] forwards; // 多层连接指针
zslnode backward; // 回溯指针
}
class zsl {
zslnode header; // 跳跃列表头指针
int maxLevel; // 跳跃列表当前最高层
Map ht; // hash结构,key:value值 value:节点
} 3. 查找/插入过程
链表查找过程:若跳跃列表只有一层,查找/插入/删除操作需要遍历链表,时间复杂度为O(n)
跳表查找过程:
- 从header节点最高层开始遍历,直到找到第一个比target小的元素A
- 从元素A的下一层开始遍历,直到找到下一个比target小的元素
- 然后一直降低到最底层,直到找到值为target的元素,或者大于target值的元素(查找失败,退出循环)

4. 插入过程
概述:有了上诉的查找算法,就可以进行插入操作。插入之前需要确定新插入的节点层数
a. 随机层数
概述:对每一个需要新插入的节点,需要调用一个随机算法给它分配一个合理的层数。直观上的需求是50%的节点分配到level1,25%分配到level2,以此类推。redis中晋升率只有25%(相当于模拟代码中ZSKIPLIST_P=25)。层高较低,在单个层上需要遍历的节点数会比较多
随机层数问题:因为节点层数一般不高,遍历时从顶层往下遍历会十分浪费,因此跳跃列表会记录当前最高的层数maxLevel,遍历时从maxLevel开始
模拟代码:
final int ZSKIPLIST_P = 50;
final int ZSKIPLIST_MAXLEVEL = 64;
public int zslRandomLevel() {
int level = 1;
Random rnd = new Random();
while ((rnd.nextInt(100) & 0xFFFF) < (ZSKIPLIST_P & 0xFFFF)) {
level += 1;
}
return Math.min(level, ZSKIPLIST_MAXLEVEL);
}b. 插入过程
过程:
- 搜索合适的插入点
- 创建新节点,创建时给这个节点分配一个层数,再将搜索路径上的节点和新节点通过前后指针串起来
- 如果分配的新节点高度高于当前跳跃列表最大高度,则更新跳跃列表的最大高度
模拟代码TODO:
5. 删除过程
删除过程与插入类似,先找到搜索路径,然后对于每一层的相关节点重排前后指针,同时还要更新maxLevel
6. 更新过程
过程:
redis会先删除元素,再插入元素,经过两次路径搜索
模拟代码TODO:
7. 跳表的问题
a. 若score值一致
若值一致,跳表查找时间复杂度会退化为O(n)。redis为了解决这个问题,在zset时不止根据score排序,值相等时,还按value排序
b. 元素排名怎么算出来
span:redis在skiplist的forward指针上进行了优化,给每一个forward指针增加了span属性。span表示从前一个节点到后一个沿着当前forward指针跳到当前节点中间需要跳过多少个节点。redis在插入/删除时都会更新span值
rank计算:计算元素排名时,只需要将经过的所有节点的跨度span值叠加即可计算出rank值
七、基数树原理(Stream中使用,后续补充)
八、LFU VS LRU
1. 概述
场景:redis4.0里引入了新的淘汰策略-LFU
redis对象热度:redis所有的对象头结构中有一个24bit的字段(lru字段),这个字段用来记录对象热度
typedef struct redisObject {
unsigned type:4; // 对象类型,如zset/set/hash
unsigned encoding:4; // 对象编码,如ziplist/intset/skiplist
unsigned lru:24; // 对象的热度
int refcount; // 应用计数
void *ptr; // 指向对象的内容
}redis为什么缓存系统时间:redis若每次都获取系统时间戳,则需要频繁调用系统调用,比较耗时
redis为什么获取lruclock时使用原子操作:redis实际上并不是单线程,它背后几个异步线程也在工作,这几个线程也需要获取时钟,因此使用atomic读写确保lruclock数据一致性
unsigned int LRU_CLOCK(void) {
unsigned int lruclock;
if (1000/server.hz <= LRU_CLOCK_RESOLUTION) {
// 原子操作执行分支
atomicGet(server.lruclock, lruclock);
} else {
// 直接通过系统调用获取时间戳,hz配置太低,lruclock更新不及时,需要实时获取系统时间戳
lruclock = getLRUClock();
}
return lruclock;
}2. LRU模式
LRU模式淘汰流程:
- LRU模式下,redis的lru字段存储的是redis时钟 server.lruclock(unix时间戳对2^24取模),大约97天折返,当某个key被访问一次,它的对象头结构的lru字段值会被更新为server.lruclock
- 默认redis时钟值每毫秒更新一次,在定时任务serverCron中主动设置
- 如果server.lruclock没有折返,则一直是递增的,因此lru字段不会超过server.lruclock的值;若超过,则说明折返。通过这个逻辑可算出对象多久没有被访问(对象空闲时间)
- 有了对象空闲时间,就可以相互比较谁新谁旧
unsigned long long estimateObjectIdleTime(robj *o) {
unsigned long long lruclock = LRU_CLOCK();
if(lruclock >= o->lru) {
return (lruclock - o->lru) * LRU_CLOCK_RESOLUTION;
}else{
return (lruclock + LRU_CLOCK_MAX - o->lru) * LRU_CLOCK_RESOLUTION;
}
}3. LFU模式
LFU淘汰过程:
- LFU模式下,lru字段4bit用来存储两个值,分别是 ldt(last decrement time) 和 logc(logistic counter)
- logc(8bit):用来存储访问频次的对数值,改值随着时间衰减。如果值比较小,就比较容易回收。为了新对象不被回收,新对象这8个bit会被初始化为一个大于0的值LFU_INIT_VAL(默认为5)
- ldt(16bit):用来存储上一次更新logc的时间,取的是分钟级别时间戳对2^16取模,大约每隔45天折返。idt不是对象被访问时更新,而是redis淘汰逻辑进行时更新。
- 每次淘汰时使用随机算法,获取若干key,更新key热度(logc和ldt),淘汰logc最小的key,
- ldt更新时会一同衰减logc值,算法为:现有的logc值减去对象的空闲时间再除以一个衰减系数lru_decay_time(默认为1)。若lru_decay_time值大于1,则会衰减得比较慢;若等于0,则表示不衰减
// LFU衰减算法
unsigned long LFUDecrAndReturn(robj *o) {
unsigned long ldt = o->lru >> 8; // 前16bit
unsigned long counter = o->lru & 255; // 后8bit
unsigned long num_periods = server.lfu_devay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
if(num_periods) {
counter = (num_periods > counter) ? 0 : counter - num_periods;
}
return counter;
}LFU更新过程:在key每次访问时会更新数据,采用概率法进行递增
// LFU增加频次算法
uint8_t LFULogIncr(uint8_t counter){
if (counter == 255) return 255;
double baseval = counter - LFU_INIT_VAL; // 减去初始对象计数值
if(baseval<0) baseval=0;
// 因为是对数加法,因此当baseval越大,+1 的概率越小
double p = 1.0/(baseval*server.lfu_log_factor+1);
double r = (double) rand() / RAND_MAX; // 取随机数,使得其在 (0,1) 之间
if( r < p ) counter++;
return counter;
}如何打开LFU模式:
redis4.0 给淘汰策略配置参数 maxmemory-policy增加了 volatile-lfu 和 allkeys-lfu,打开选项之后,就可以使用object freq指令获取对象LFU计数值
九、懒惰删除的牺牲
1. 概述
对删除节点进行回收的思路:
- 渐进式删除:需要控制回收频率,可采用自适应算法,判断内存增长的趋势是增加还是下降,调整回收频率系数。(繁忙时会影响QPS)
- 异步线程:异步线程从队列中取出数据进行回收,不过主线程和异步线程在内存回收分配器(jemalloc)的使用上有竞争关系
异步线程方案的问题:redis的共享机制会导致异步线程方案实现复杂