基于Scala版本的TMDB大数据电影分析项目
怒发冲冠为红颜
基于kaggle的TMDB电影数据集的数据分析,该数据集包括了大约5000部电影的相关信息。先来看一下TMDB电影数据集的数据

该数据集其实是csv文件,里面记录这美国这些年上映的电影,以及电影的种类,观看人数,主题,以及打分等详细信息。
先来看一下各个字段的意义

不过需要注意的是,在csv文件里面并没有表头,也就是说并没有上面字段。所以在使用Spark SQL处理该数据集的时候,需要创建StructType将上面的字段保存起来。
使用DataFrame处理
通过Spark读取csv文件就可以直接创建出来一个DataFrame对象,如果在本项目中直接读取csv文件虽然不会报错,但是切分字段的时候会出现错误,原因很简单,因为在genres字段里面有json数据,不是json的锅,是这个genres字段的锅,先来看一下这个genres字段把
[{""id"": 28, ""name"": ""Action""}, {""id"": 12, ""name"": ""Adventure""}, {""id"": 14, ""name"": ""Fantasy""}, {""id"": 878, ""name"": ""Science Fiction""}]大体上是这样的,里面有多个json,而且每个json都用",",所以在split分割字段的时候货到这这个genres字段也会根据","进行分割。
为了避免这种情况,第一种方法依旧使用","分割,依靠正则表达式进行分割
val value = sparkContext.textFile("date/tmdb_5000_movies.csv")
val value1 = value.map(_.split(",(?=([^\"]*\"[^\"]*\")*[^\"]*$)")(1))
value1.collect().foreach(println(_))来看一下genres字段是否被切分
![]()
显而易见,并没有被切分。其实上面这个最后是个RDD类型的,当然也可以隐式转换,toDF,转换成dataFrame.
下面介绍第二种方法
通过StructType对象,首先将所有字段名放到一个字符串里面,对字符串进行操作,对字符串进行切分,切分出来的字符串依次为他们创建StructField对象(StructField对象包含了字段名和字段类型)
spark读取csv文件的时候对csv进行配置参数,创建dataFrame。
这个方法是主要介绍的,来看一下具体操作把
//将转换操作构造成一个方法
def transform_demo() = {
//创建Spark SQL环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Spark Demo")
val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
//创建字段名字符串
val scheamdString = "budget,genres,homepage,id,keywords,original_language,original_title,
overview,"+"popularity,production_companies,production_countries,
release_date,revenue,runtime,spoken_languages,status" + "tagline,title,vote_average,vote_count"
//将上面的字符串拆分出来 并且map到每一个StructField对象里面
val fields = scheamdString.split(",").map(fieldname =>
StructField(fieldname, StringType, nullable = true))
//创建StructType对象,该对象包含每个字段的名称
val scheam = StructType(fields)
//csv文件所在的路径
val path = "date/tmdb_5000_movies.csv"
//创建mdf对象
val mdf = sparkSession.read.format("com.databricks.spark.csv")
.schema(scheam)
//指定所谓的表头
.option("inferSchema",value = false)
.option("header",value = true)
//schema就是header
.option("nullValue","\\N")
.option("escape","\"")
.option("quoteAll","true")
.option("seq",",")
.csv(path)
mdf }transform_Demo方法最后返回的是DataFrame对象。
来看一下dataFrame的schema
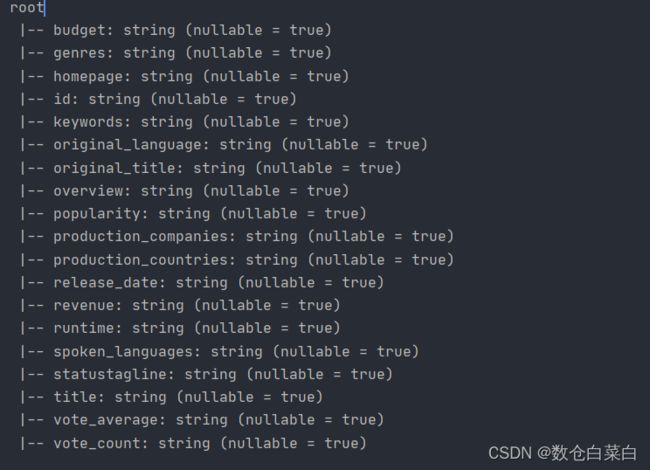
TMDB电影体裁的分布
什么是电影体裁的分布,说白了就是计数,所谓的WordCount。就是对genres字段进行计数,genres字段里面的数据
![]()
对里面的name进行wc。每个电影可能会属于多个体裁,因此本题的意义就是求出来所有电影的体裁,关于爱情片的电影有多少部,关于动作片的电影有多少部。
需要先解析json数据,从每个电影中取出对应的体裁,使用wc进行计数统计。
1.实现一个CountByJson()函数,该函数实现从json解析出来并进行计数
def countByJson(field:String):org.apache.spark.rdd.RDD[(String,Int)] ={
//对genres字段进行解析 genres字段只有id,name两个列名
//jsonSchema包含了列名
val jsonSchema =ArrayType(new StructType()
.add("id", IntegerType).add("name",StringType))
//mdf是上面创建出来的dataframe
//对genres字段进行查找筛选,
//[json{}.json{},json{}]
//from_json(数据,列名) 使用explode炸裂之后就是数组
mdf.select(mdf.col(field))
.filter(mdf.col(field).isNotNull)
//炸裂之后,重命名为 genres
.select(explode(from_json(mdf.col(field), jsonSchema))
.as(field))
//genres.concat("name") = => genres.name,直接访问name字段
.select(field.concat(".name"))
//转换成RDD
.rdd
//(体裁,1)
.map(name=>(name.toString(),1))
//分区数为1
.repartition(1)
//reducrByKey
根据key进行计数
.reduceByKey((x,y) => x + y) }来看一下精简的流程图,让大家对上面的步骤有更加深刻的印象
虽然经过上面的步骤,我们完成了对电影体裁的计数,但是细心的同学应该会发现里面的name被[]包着,为了更加让我们能够一目了然,我们对上面的结果进行转化内,将[]删除。只留下(name,count)。
def countByGenres()={ val genresRDD = countByJson("genres")
//将RDD的结果collect之后,对key进行转化内,去掉[]
val jsonString =genresRDD.collect().toList.map {
case(genre,count) => ((genre.replace("[","").replace("]","")),count) }
//遍历结果
jsonString.foreach(println(_)) }
可以看到,我们已经去掉了中括号。现在展示结果我们能更加的一目了然了。
前100个常见关键词
找出关键词中出现频率最高的前100个,依旧是词频统计进行WC。不过keywords单词是json格式的,意味着我们依旧需要对json进行解析。解析完成之后,进行上面的wc操作。
因此只需要更改函数countByJson里面的参数就可以。
看一下keywords的格式
![]()
思路很简单,通过CountByJson之后,返回的是一个RDD。经过reduceByKey之后处理的数据
(name,count)
做到这里,这道题目就已经结束了,如果为了美观也可以对(name,count)进行转化,和上面的一样,去掉[]。
def countByKeywords() = {
val keywordsRDD = countByJson("keywords").sortBy(_._2,false)
val jsonString = keywordsRDD.take(100).toList.map{
case(keywords,count) => {
(keywords.replace("[","").replace("]",""),count) } }
jsonString }需要注意的是,reducrByKey处理后的数据并没有进行排序,经过转换算子sortBy根据(name,count),元组中的count进行排序(从大到小)。
TMDB最常见的10种预算数
探究每个电影的预算数,首先对预算字段进行过滤,去除预算项目为0的电影项目,根据预算聚合并聚合,根据计数进行排序。取前十个为最终的结果。
先来看一下budget字段的信息
这种数据最简单,虽然在csv里面是整型的,但是我们在创建StructType对象的时候,创建的是字符串类型的。因此在使用DSL语言的时候需要先转化列的数据类型,分组聚合group + count()+order by取前10.
def countByBudget(order:String,ascending:Boolean):Array[Row]={
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Spark Demo")
val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
import sparkSession.implicits._
if(ascending){
//对budget字段进行转化类型
//filter过滤
//group by + count 分组聚合
//orderby排序
transform_demo().withColumn("budget",col("budget")
.cast("Integer")) .filter($"budget" > 0 ).groupBy("budget")
.count().orderBy(order)take(10) }
else{
transform_demo().withColumn("budget", col("budget")
.cast("Integer")).filter($"budget" > 0).groupBy("budget").count() .orderBy(desc(order)).take(10) } }TMDB中最常见的电影时长(只展示电影数>100的时长)
显而易见,这些小实验都是wc,不过是在wc的基础上增加了或多或少的数据操作。来看看这个电影时长的操作吧。
电影数>100 runtime > 100
先看一下runtime的数据类型

transform_demo生成的是DataFrame,我们可以直接在DataFrame上进行操作,需要先转换数据类型,将runtime转换成Integer整型然后根据下面的操作进行
filter + group by + count +orderby
直接来看代码吧
def distrbutionOfRuntime() = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Spark Demo")
val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
import sparkSession.implicits._
transform_demo().withColumn("runtime",col("runtime").cast("Integer")) .groupBy("runtime").count().filter($"count" > 100).orderBy($"count".asc)
.collect() }生产电影最多的10大公司
对生产公司这个字段'product_companies'
不过需要注意的是这个字段依旧是包含着多个json,使用countByJson就可以实现对这种字段进行json解析以及wc操作。经过countByJson之后,就已经是(name,count)这种形式,已经完成了计数。
计数完成之后,(name,count)这个元组,根据元组第二个元素进行SortBy排序,排序完成之后取前十个(name,count)就完成了目标
def countByCompanies() = {
val production_companiesRDD = countByJson("production_companies") .sortBy(_._2,false)
val list = production_companiesRDD.take(10).toList.map {
case (company, count) => {
(company.replace("[", "").replace("]", ""), count) } }
list }TMDB的10大电影语言
该字段同样也是json字段,使用countByJson方法进行解析之后,进行的操作差不多跟之前的操作千篇一律。
//TMDB中的10大电影语言 def countByLanguage() = {
val countByLanguage = countByJson("spoken_languages").sortBy(_._2,false)
val joinString = countByLanguage.take(10).toList.map {
case (language, count) =>
(language.replace("[", "").replace("]", ""), count) }
joinString }总结
这是一个入门案例,虽然说是入门案例,其实并不简单,对于还有json的字段,需要进行处理,单独split会报错,需要split+正则,使用Spark SQL需要创建StructType对象,使用相关的json解析函数。总之呢刚开始的时候可能会很难,但是做的多了发现并不是那么的难。
可能这个案例比较简单,之后会有更多的案例,不过到时候进行的操作可能更难。差不多五月份左右会将数仓项目梳理一遍。
这个项目很简单的,但是为了这个项目我花了有将近三天把,StructType不懂先去看了StructType,Spark SQL用到的相关函数不会又去看了看函数。
大家也要努力奥,好想好想她。