中间件集群部署
一、安装jdk1.8
-
先卸载系统自带jdk
#查找系统自带jdk rpm -qa | grep java #卸载jdk yum -y remove java* #卸载完成 -
解压安装jdk
tar -zxvf jdk-8u221-linux-x64.tar.gz #删除tar包 rm -rf jdk-8u221-linux-x64.tar.gz -
配置系统环境变量
vim /etc/profile #在尾部添加环境变量 export JAVA_HOME=/data/jdk1.8.0_221 export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar #编译系统配置文件 source /etc/profile -
验证安装是否成功
java -version
二、ElasticSearch集群部署(三台机器)
一、准备工作
-
准备机器
准备3台机器,安装centos7.6,ip计划如下:
ip地址 Hostname 192.168.15.11 es-node1 192.168.15.12 es-node2 192.168.15.13 es-node3 -
关闭防火墙
systemctl stop firewalld systemctl disable firewalld -
安装jdk
本机安装jdk-8u221-linux-x64,并配置好环境 变量
-
禁用SELINUX
vim /etc/selinux/config #将SELINUX设置为disabled,然后重启机器 SELINUX=disabled #或者临时关闭(不用重启机器) setenforce 0 -
修改主机名
hostnamectl set-hostname es-node1 //修改主机名 hostname //显示主机名 -
创建用户
#添加组 groupadd es #添加用户 adduser es -g es #设置密码 passwd es给es用户赋予权限:
#编辑/etc/sudoers vi /etc/sudoers #在root ALL=(ALL) ALL下增加es配置,最终如下 root ALL=(ALL) ALL es ALL=(ALL) ALL -
修改系统配置文件
首先,修改/etc/sysctl.conf文件,增加如下配置即可:
#限制一个进程拥有虚拟内存区域的大小 vm.max_map_count=262144然后执行下面命令,让配置生效。
#配置生效 sysctl -p再修改vim /etc/security/limits.conf配置
* soft nofile 65536 * hard nofile 65536 * soft nproc 4096 * hard nproc 4096 * hard memlock unlimited * soft memlock unlimited其中,
- nofile 表示最大开打开文件描述符
- nproc 表示最大用户进程数
-
修改文件 /etc/systemd/system.conf ,分别修改以下内容
DefaultLimitNOFILE=65536 DefaultLimitNPROC=32000 DefaultLimitMEMLOCK=infinity改好后重启下系统
二、部署es
-
部署es
#将es的主文件夹的权限改为es用户 chown —R es:es /data/elasticsearch-7.12.1 chmod 770 /data/elasticsearch-7.12.1 #创建数据目录 mkdir -p /data/es-data #将es-data文件的权限改为es用户的 chown —R es:es /data/es-data -
修改elasticsearch-7.12.1/config/elasticsearch.yml
# ------------------------------------ Node ------------------------------------ node.name: es-node1 node.master: true node.data: true # ----------------------------------- Paths ------------------------------------ path.data: /data/es-data path.logs: /data/elasticsearch-7.12.1/logs # ----------------------------------- Memory ----------------------------------- bootstrap.memory_lock: true # ---------------------------------- Network ----------------------------------- network.host: 0.0.0.0 http.port: 9200 transport.tcp.port: 9300 node.name: es-node1 node.master: true node.data: true:: # --------------------------------- Discovery ---------------------------------- discovery.seed_hosts: ["192.168.15.11", "192.168.15.12","192.168.15.13"] cluster.initial_master_nodes: ["es-node1", "es-node2","es-node3"] discovery.zen.minimum_master_nodes: 2 http.cors.enabled: true http.cors.allow-origin: "*" -
启动es
./elasticsearch -
查看集群状态
http://192.168.15.11:9200/_cat/nodes?v
三、MySQL8.0.21部署
一、下载安装
- 下载mysql8.0.21版本的rpm包
在这里插入图片描述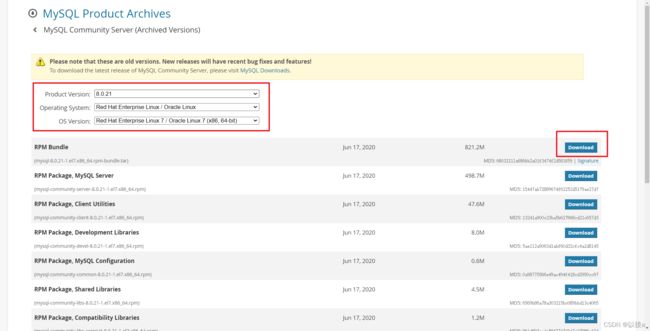
-
上传并解压安装包
tar -xvf mysql-8.0.21-1.el7.x86_64.rpm-bundle.tar -
执行安装命令
yum localinstall *.rpm执行过程中会自动处理依赖关系,全部输入y
二、启动和初始化
-
设置大小写不敏感(不区分大小写)
#先在/etc/my.cnf配置文件中修改 lower_case_table_names = 1 #再在mysql的bin目录下执行初始化命令 ./mysqld --usr=mysql --initialize --lower-case-table-names=1 --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data先安装数据库,然后初始化数据库时设置大小写不敏感,如果是后安装的数据库,先将数据库数据备份,之后将数据库的data目录的文件全部清除,如/data/app/mysql/data.
-
启动mysql
systemctl start mysqld systemctl stop mysqld systemctl restart mysqld -
开放防火墙
firewall-cmd --zone=public --add-port=3306/tcp --permanent firewall-cmd --reload -
初始化MySQL数据库
#查看账号和随机密码 cat /var/log/mysqld.log | grep "A temporary password" #修改MySQL密码 mysql_secure_installation // 需要校验密码强度,弱密码将会提示 并重新输入 -
进入MySQL
mysql -u root -p -
修改随机密码
alter user 'root'@'localhost' identified by 'Root!123456'; 或set password for 'root'@'localhost'=password('Root!123456'); #刷新权限 flush privileges; -
修改数据库的密码验证规则
#用命令查看 validate_password 密码验证插件是否安装 SHOW VARIABLES LIKE 'validate_password%'; #调整密码验证规则 set global validate_password.policy=0; set global validate_password.length=1; #最后再修改数据库root密码 alter user 'root'@'localhost' identified by '123456'; -
Navicat远程连接数据库
use mysql; select host, user, authentication_string, plugin from user; #查看user表的root用户Host字段是localhost,说明root用户只能本地登录,现在把他改成远程登录 update user set host='%' where user='root'; #刷新权限 FLUSH PRIVILEGES; 加密规则改了也同样设置密码 ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '新的密码'; #刷新权限 FLUSH PRIVILEGES;
三、部署主从复制
-
修改my.cnf配置文件
主库的所有变更操作(写入更新)都会视为事件,被写入二进制日志文件中。从库通过读取主库的二进制日志文件,并在从库中执行这些事件,达到主从同步。
配置主数据库的 my.cnf 配置文件(只贴核心部分):
-
默认使用“mysql_native_password”插件认证
default_authentication_plugin=mysql_native_password
-
###主从数据库配置核心部分 # 设置同步的binary log二进制日志文件名前缀,默认为binlog log-bin=mysql-bin # 服务器唯一id,默认为1 主数据库和从数据库的server-id不能重复 server-id=1 ###可选配置 # 需要主从复制的数据库 binlog-do-db=test # 复制过滤:也就是指定哪个数据库不用同步(mysql库一般不同步) binlog-ignore-db=mysql # 为每个session分配的内存,在事务过程中用来存储二进制日志的缓存 binlog_cache_size=1M # 主从复制的格式(mixed,statement,row,默认格式是statement。建议是设置为row,主从复制时数据更加能够统一) binlog_format=row # 设置二进制日志自动删除/过期的天数,避免占用磁盘空间。默认值为0,表示不自动删除。 expire_logs_days=7 # 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。 # 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致 slave_skip_errors=1062
2.启动主数据库,创建一个同步复制用户(非必需,也可以用root用户):
-
create user 'repl'@'%' identified by '123456'
说明:
MySQL创建用户命令:create user ‘username’@‘host’ identified by ‘password’;
username:指定创建的用户名
host:指定用户登录的主机ip,% 表示任意主机都可远程登录,localhost 表示本地才能登录
password:指定该用户的登录密码
3.接着给创建的用户授权同步复制权限:
-
grant replication slave on *.* to 'repl'@'%'
说明:
MySQL创建授权命令:grant privilege on database.table to ‘username’@‘host’;
privilege :指定授权的权限,比如create、drop等权限,具体有哪些权限,可查看官网文档
database:指定哪些数据库生效,*表示全部数据库生效
table:指定所在数据库的哪些数据表生效,*表示所在数据库的全部数据表生效
username:指定被授予权限的用户名
host:指定用户登录的主机ip,%表示任意主机都可远程登录
4.最后刷新权限生效:
flush privileges
5.接着执行命令查看并记下binary log二进制日志文件名 File 以及位置 Position的值,需要在从数据库用到:
show master status
6.配置从数据库的my.cnf配置文件(只贴核心部分):
###主从数据库配置核心部分
# 设置同步的binary log二进制日志文件名前缀,默认是binlog
log-bin=mysql-bin
# 服务器唯一ID 主数据库和从数据库的server-id不能重复
server-id=2
###可选配置
# 需要主从复制的数据库
replicate-do-db=test
# 复制过滤:也就是指定哪个数据库不用同步(mysql库一般不同步)
binlog-ignore-db=mysql
# 为每个session分配的内存,在事务过程中用来存储二进制日志的缓存
binlog_cache_size=1M
# 主从复制的格式(mixed,statement,row,默认格式是statement。建议是设置为row,主从复制时数据更加能够统一)
binlog_format=row
# 设置二进制日志自动删除/过期的天数,避免占用磁盘空间。默认值为0,表示不自动删除。
expire_logs_days=7
# 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
# 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
# relay_log配置中继日志,默认采用 主机名-relay-bin 的方式保存日志文件
relay_log=replicas-mysql-relay-bin
# log_slave_updates表示slave将复制事件写进自己的二进制日志
log_slave_updates=1
# 防止改变数据(只读操作,除了特殊的线程)
read_only=1
7.启动从数据库,执行以下命令设置与主数据库的联系:
change master to MASTER_HOST='192.168.34.120',MASTER_PORT=3307,MASTER_USER='repl',MASTER_PASSWORD='123456',MASTER_LOG_FILE='mysql-bin.000007',MASTER_LOG_POS=825;
说明:
MASTER_HOST:主数据库的主机ip
MASTER_PORT:主数据库的端口,不设置则默认是3306
MASTER_USER:主数据库被授予同步复制权限的用户名
MASTER_PASSWORD:对应的用户密码
MASTER_LOG_FILE:在主数据库执行命令show master status 查询到的二进制日志文件名称
MASTER_LOG_POS:在主数据库执行命令show master status 查询到的位置 Position的值
8.指定复制库和表
#指定复制表
#在主服务器上的zhrj库中新增2 个表,user1,user2
create table user1;
create table user2;
#编辑从服务器上的配置参数,指定zhrj数据库中的user1表被复制,user2表不会被复制。
replicate-do-table=zhrj.user1
replicate-ignore-table=zhrj.user2
#指定数据库
#编辑从服务器上的配置参数,指定test数据库,zhengjun数据库被复制,test2数据库不会被复制。
replicate-do-db=test
replicate-do-db=zhengchengjun
replicate-ignore-db=test2
9.最后开启主从复制工作:
start slave;
10.可执行命令查看详细信息以及状态:
show slave status\G;
假如显示 Slave_IO_Running 和 Slave_SQL_Running 为 Yes ,以及Slave_IO_State 为 Waiting for master to send event,则证明主从复制成功!
11.假如需要停止主从复制工作,则执行以下命令:
stop slave
12.测试:
分别在主从数据库创建一个test数据库,并新建表结构一样的user表,然后在主数据库执行插入语句
四、Nacos在Linux(Centos7)下集群部署环境搭建
一、环境准备
-
三台centos7系统刀片机或虚拟机
-
JDK1.8
-
nacos-1.1.4安装包,因为官方说此版本为稳定版本
-
wget https://github.com/alibaba/nacos/releases/download/1.1.4/nacos-server-1.1.4.tar.gz -
Maven 3.2+
-
MySQL8.0.21环境(见上节MySQL8.0.21部署)
二、部署步骤:
-
集群配置文件修改
解压nacos安装包后进入nacos目录下conf目录,有配置文件cluster.conf.example,
复制成cluster.conf
cp cluster.conf.example cluster.conf请每行配置成ip:port。(请配置3个或3个以上节点)
# ip:port 192.168.15.11:8848 192.168.15.12:8848 192.168.15.13:8848 -
配置 MySQL 数据库
官方推荐生产使用主从,或采用高可用数据库,我这里只用一台mysql数据
初始化数据库,导入nacos解压目录下conf/nacos-mysql.sql 文件
修改conf/application.properties,增加 mysql 数据源配置
#主从配置可以输入2 db.num=1 db.url.0=jdbc:mysql://192.168.15.12:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true #多数据源,我这里只用一个数据库 #db.url.1=jdbc:mysql://192.168.15.12:3306/nacos_devtest?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true db.user=root db.password=123456 -
启动 nacos
进入nacos目录bin下: cd /usr/local/nacos/bin
启动命令: sh startup.sh 或 ./startup.sh
查看运行日志: tail -500f /usr/local/nacos/logs/start.out
-
查看
三台启动完毕后。
登录到界面控制台(用户名密码默认都是nacos):
http://192.168.2.150:8848/nacos
进入【集群管理】-【节点列表】:可以看到集群的三个节点
五、rabbitmq集群部署
1.安装编译环境
#安装gcc编译工具
yum -y install gcc gcc-c++ kernel-devel
#安装ncurses-devel模
yum install -y ncurses-devel
2.安装openssl,erlang需要openssl的支持(所有mq集群机器都要安装)
tar xzf openssl-1.1.1k.tar.gz
cd openssl-1.1.1k
#/usr/local/ssl为安装路径
./config --prefix=/usr/local/ssl && make && make install
3.安装erlang环境 (所有mq集群机器都要安装)
tar xzf otp_src_22.3.tar.gz
#/usr/local/erlang/为安装路径
mkdir /usr/local/erlang
cd otp_src_22.3
./configure --prefix=/usr/local/erlang/ --with-ssl=/usr/local/ssl && make && make install
4.添加环境变量(所有mq集群机器都需要操作)
vim /etc/profile
PATH=$PATH:/usr/local/erlang/bin
source /etc/profile
#输入erl出现如下则表示安装成功
[root@647aa5703a20 otp_src_22.3]# erl
Erlang/OTP 22 [erts-10.7] [source] [64-bit] [smp:16:16] [ds:16:16:10] [async-threads:1]
Eshell V10.7 (abort with ^G)
1>
5.上传rabbitmq至服务器 直接解压添加环境变量即可(所有mq集群机器都需要操作)
rabbitmq命令:
- 启动rabbitmq:rabbitmq-server start
- 后台启动:rabbitmq-server -detached
- 启动web插件:rabbitmq-plugins enable rabbitmq_management
- 创建用户:rabbitmqctl add_user mq mq
- 查看用户:rabbitmqctl list_users
- 设置用户标签:rabbitmqctl set_user_tags mq administrator
- 赋权:rabbitmqctl set_permissions mq -p / “." ".” “.*”
6.将master机器的.erlang.cookie文件同步到其他slave机器中并赋执行权限
chmod 600 .erlang.cookie
7.修改集群机器的/etc/hosts 文件添加集群机器的解析
192.168.1.1 master
192.168.1.2 slave1
192.168.1.3 slave2
8.停止slave机器的rabbitmq服务 并加入master(在slave机器操作)
./rabbitmqctl stop_app
./rabbitmqctl join_cluster rabbit@master
./rabbitmqctl start_app
9.设置镜像模式 (任意机器操作均可)
./rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
- ha-all:为策略名称
- :为匹配符,只有一个代表匹配所有,^zlh为匹配名称为zlh的exchanges或者queue
- ha-mode:为匹配类型,他分为3种模式:all-所有,exctly-部分,nodes-指定
六、Haproxy部署+keepalived双vip部署
一、部署Haproxy
-
解压安装(11服务器和12服务器同时安装Haproxy,下面步骤同步操作)
tar -zxvf haproxy-1.4.21.tar.gz #切到haproxy目录 cd haproxy-1.4.21 #编译安装(PREFIX指定安装目录) make install PREFIX=/usr/local/haproxy -
新建并编辑配置文件
haproxy.cnf#在安装目录下新建conf目录 mkdir conf #在conf下新建编辑haproxy.cnf touch haproxy.cfg -
编辑
haproxy.cnf#logging options global log 127.0.0.1 local0 info #日志输出配置,所有日志都记录在本机,通过local0输出 maxconn 5120 chroot /app/haproxy #haproxy 安装路径 uid 99 #所属运行的用户uid gid 99 #所属运行的用户组 daemon #后台运行 quiet nbproc 20 pidfile /var/run/haproxy.pid #指定PID文件路径 defaults log global #使用4层代理模式,"mode http"为7层代理模式 mode tcp #if you set mode to tcp,then you nust change tcplog into httplog option tcplog option dontlognull retries 3 option redispatch maxconn 2000 #连接超时时间 timeout connect 5s #客户端空闲超时时间为 60秒 则HA 发起重连机制 timeout client 60s #服务器端连接超时时间为 15秒 则HA 发起重连机制 timeout server 15s #front-end IP for consumers and producters listen rabbitmq_cluster bind 0.0.0.0:8101 #绑定协议端口 #配置TCP模式 #所处理的类别,默认采用http模式,可配置成tcp作4层消息转发 mode tcp #balance url_param userid #balance url_param session_id check_post 64 #balance hdr(User-Agent) #balance hdr(host) #balance hdr(Host) use_domain_only #balance rdp-cookie #balance leastconn #balance source //ip #简单的轮询 balance roundrobin #负载均衡策略 #rabbitmq集群节点配置 #inter 每隔五秒对mq集群做健康检查, 2次正确证明服务器可用,2次失败证明服务器不可用,并且配置主备机制 server es-node1 192.168.15.11:15672 check inter 5000 rise 2 fall 3 server es-node2 192.168.15.12:15672 check inter 5000 rise 2 fall 3 server es-node3 192.168.15.13:15672 check inter 5000 rise 2 fall 3 #配置haproxy web监控,查看统计信息 listen stats bind 192.168.15.11:8100 #前端浏览器中查看统计的WEB界面地址 mode http option httplog #日志类别,采用httplog stats enable stats auth mq:mq #设置查看统计的账号密码 #设置haproxy监控地址为http://localhost:8100/rabbitmq-stats stats uri /rabbitmq-stats stats refresh 5s #5s刷新一次 -
同步+修改配置haproxy文件
#将 11 服务器 上的haproxy文件同步至 12 服务器 scp haproxy.cfg root@es-node2:/usr/local/haproxy/conf/ -
修改12服务器上的haproxy.cnf(将haproxy服务器IP修改一下即可,其他保持默认)
#logging options global log 127.0.0.1 local0 info #日志输出配置,所有日志都记录在本机,通过local0输出 maxconn 5120 chroot /app/haproxy #haproxy 安装路径 uid 99 #所属运行的用户uid gid 99 #所属运行的用户组 daemon #后台运行 quiet nbproc 20 pidfile /var/run/haproxy.pid #指定PID文件路径 defaults log global #使用4层代理模式,"mode http"为7层代理模式 mode tcp #if you set mode to tcp,then you nust change tcplog into httplog option tcplog option dontlognull retries 3 option redispatch maxconn 2000 #连接超时时间 timeout connect 5s #客户端空闲超时时间为 60秒 则HA 发起重连机制 timeout client 60s #服务器端连接超时时间为 15秒 则HA 发起重连机制 timeout server 15s #front-end IP for consumers and producters listen rabbitmq_cluster bind 0.0.0.0:8101 #绑定协议端口 #配置TCP模式 #所处理的类别,默认采用http模式,可配置成tcp作4层消息转发 mode tcp #balance url_param userid #balance url_param session_id check_post 64 #balance hdr(User-Agent) #balance hdr(host) #balance hdr(Host) use_domain_only #balance rdp-cookie #balance leastconn #balance source //ip #简单的轮询 balance roundrobin #负载均衡策略 #rabbitmq集群节点配置 #inter 每隔五秒对mq集群做健康检查, 2次正确证明服务器可用,2次失败证明服务器不可用,并且配置主备机制 server es-node1 192.168.15.11:15672 check inter 5000 rise 2 fall 3 server es-node2 192.168.15.12:15672 check inter 5000 rise 2 fall 3 server es-node3 192.168.15.13:15672 check inter 5000 rise 2 fall 3 #配置haproxy web监控,查看统计信息 listen stats bind 192.168.15.12:8100 #前端浏览器中查看统计的WEB界面地址 mode http option httplog #日志类别,采用httplog stats enable stats auth mq:mq #设置查看统计的账号密码 #设置haproxy监控地址为http://localhost:8100/rabbitmq-stats stats uri /rabbitmq-stats stats refresh 5s #5s刷新一次 -
启动haproxy
./usr/local/haproxy/sbin/haproxy -f /usr/local/haproxy/conf/haproxy.cnf
二、部署keepalived双vip
-
解压安装keepalived-2.1.0
tar -zxvf keepalived-2.1.0.tar.gz cd keepalived-2.1.0 #编译源码 ./configure --prefix=/usr/local/keepalived #编译安装 make && make install -
修改keepalived的配置文件
cd /usr/local/keepalived/etc/keepalived #将原始配置文件失效 mv keepalived.conf keepalived.conf.bak -
重新新建配置文件
vrrp_instance VI_1 { state BACKUP interface ens33 virtual_router_id 100 mcast_src_ip 192.168.15.11 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } track_script { chk_nginx } virtual_ipaddress { 192.168.15.100 } }state BACKUP 表示这两个服务器都是备用服务器。
interface ens33 表示当前使用的网卡,通过ifconfig可以查看到,这我用的是ens33。
virtual_router_id 100 这个是个分组标记,在一个网内,所有的virtual_router_id为100的服务器自动分到一个组里面,由于这里面我把两台服务器的status都设置成为了BACKUP,那么这两台服务器就会利用priority这个值来决定谁是主服务器,谁是备用服务器,高的那个会抢占当前的vip,也就是它就会变成主服务器。
mcast_src_ip 填写你当前机器的真实ip即可
advert_int 1 没有仔细研究,应该是两台服务器之间的心跳间隔
authentication 就用默认的就可以了。
track_script 和vrrp_script chk_nginx 配合使用的。
virtual_ipaddress 两台机器共有的vip,注意,要和两台服务器在一个网关里面。
-
将主服务器的keepalived.conf发送到从服务器
scp keepalived.conf root@es-node2:/usr/local/keepalived/etc/keepalived/ -
12服务器的配置文件如下
vrrp_instance VI_1 { state BACKUP interface ens33 virtual_router_id 100 mcast_src_ip 192.168.15.12 priority 99 advert_int 1 authentication { auth_type PASS auth_pass 1111 } track_script { chk_nginx } virtual_ipaddress { 192.168.15.100 } } -
启动keepalived
./usr/local/keepalived/sbin/keepalived -f /usr/local/keepalived/etc/keepalived/keepalived.conf
七、Redis主从配置以及哨兵模式(一主二从)
-
在需要部署集群的机器上上传redis安装包并解压编译安装(所有redis集群集群都需要)
tar xzf redis-3.2.10.tar.gz cd redis-3.2.10 make MALLOC=libc cd src && make install -
修改redis配置文件(主)
bind 0.0.0.0 protected-mode no requirepass 123456 masterauth 123456 port 6379 tcp-backlog 511 timeout 0 tcp-keepalive 300 daemonize yes supervised no pidfile /var/run/redis_6379.pid loglevel notice logfile "/data/redis-3.2.10/logs/redis.log" databases 16 save 900 1 save 300 10 save 60 10000 stop-writes-on-bgsave-error yes rdbcompression yes rdbchecksum yes dbfilename dump.rdb dir ./ slave-serve-stale-data yes slave-read-only yes repl-diskless-sync no repl-diskless-sync-delay 5 repl-disable-tcp-nodelay no slave-priority 100 appendonly yes appendfilename "appendonly.aof" appendfsync everysec no-appendfsync-on-rewrite no auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb aof-load-truncated yes lua-time-limit 5000 slowlog-log-slower-than 10000 slowlog-max-len 128 latency-monitor-threshold 0 notify-keyspace-events "" hash-max-ziplist-entries 512 hash-max-ziplist-value 64 list-max-ziplist-size -2 list-compress-depth 0 set-max-intset-entries 512 zset-max-ziplist-entries 128 zset-max-ziplist-value 64 hll-sparse-max-bytes 3000 activerehashing yes client-output-buffer-limit normal 0 0 0 client-output-buffer-limit slave 256mb 64mb 60 client-output-buffer-limit pubsub 32mb 8mb 60 hz 10 -
修改redis配置文件(从)
bind 0.0.0.0 protected-mode no port 6379 requirepass 123456 masterauth 123456 slaveof 192.168.15.11 6379 tcp-backlog 511 timeout 0 tcp-keepalive 300 daemonize yes supervised no pidfile /var/run/redis_6379.pid loglevel notice logfile "/data/redis-3.2.10/logs/redis.log" databases 16 save 900 1 save 300 10 save 60 10000 stop-writes-on-bgsave-error yes rdbcompression yes rdbchecksum yes dbfilename dump.rdb dir ./ slave-serve-stale-data yes slave-read-only yes repl-diskless-sync no repl-diskless-sync-delay 5 repl-disable-tcp-nodelay no slave-priority 100 appendonly no appendfilename "appendonly.aof" appendfsync everysec no-appendfsync-on-rewrite no auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb aof-load-truncated yes lua-time-limit 5000 slowlog-log-slower-than 10000 slowlog-max-len 128 latency-monitor-threshold 0 notify-keyspace-events "" hash-max-ziplist-entries 512 hash-max-ziplist-value 64 list-max-ziplist-size -2 list-compress-depth 0 set-max-intset-entries 512 zset-max-ziplist-entries 128 zset-max-ziplist-value 64 hll-sparse-max-bytes 3000 activerehashing yes client-output-buffer-limit normal 0 0 0 client-output-buffer-limit slave 256mb 64mb 60 client-output-buffer-limit pubsub 32mb 8mb 60 hz 10 aof-rewrite-incremental-fsync yes如果有多个从服务器,集群配置文件一致
-
修改哨兵配置文件(集群配置文件一致)
#端口默认为26379。 port 26379 #关闭保护模式,可以外部访问。 protected-mode no #设置为后台启动。 daemonize:yes #日志文件。 logfile "/data/redis-3.2.10/logs/sentinel.log" #指定主机IP地址和端口,并且指定当有2台哨兵认为主机挂了,则对主机进行容灾切换。 sentinel monitor mymaster 192.168.15.11 6379 2 #当在Redis实例中开启了requirepass,这里就需要提供密码。 sentinel auth-pass mymaster 123456 #这里设置了主机多少秒无响应,则认为挂了。 sentinel down-after-milliseconds mymaster 30000 #故障转移的超时时间,这里设置为三分钟。 sentinel failover-timeout mymaster 180000 -
启动redis以及哨兵模式
cd /data/redis-3.2.10/src #redis启动指定配置文件(先启动主服务器的redis和哨兵,再依次启动从服务器的服务网) ./redis-server /data/redis-3.2.10/redis.conf #启动哨兵模式 ./redis-sentinel /data/redis-3.2.10/sentinel.conf -
验证集群
#redis主从集群状态如下 [root@bogon ~]# redis-cli 127.0.0.1:6379> auth 123456 OK 127.0.0.1:6379> info replication # Replication role:master connected_slaves:2 slave0:ip=192.168.119.157,port=6380,state=online,offset=122518,lag=1 slave1:ip=192.168.119.157,port=6381,state=online,offset=122518,lag=1 master_repl_offset:122518 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:2 repl_backlog_histlen:122517 #哨兵集群状态如下 [root@bogon ~]# redis-cli -p 26379 127.0.0.1:26379> info sentinel # Sentinel sentinel_masters:1 sentinel_tilt:0 sentinel_running_scripts:0 sentinel_scripts_queue_length:0 sentinel_simulate_failure_flags:0 master0:name=mymaster,status=ok,address=192.168.119.157:6379,slaves=2,sentinels=3
八、minio部署集群
九、canal部署(es与mysql数据实时同步)
一、canal介绍
-
canal简介
canal主要用途是对MySQL数据库增量日志进行解析,提供增量数据的订阅和消费,简单说就是可以对MySQL的增量数据进行实时同步,支持同步到MySQL、Elasticsearch、HBase等数据存储中去。
-
canal工作原理
canal会模拟MySQL主库和从库的交互协议,从而伪装成MySQL的从库,然后向MySQL主库发送dump协议,MySQL主库收到dump请求会向canal推送binlog,canal通过解析binlog将数据同步到其他存储中去。
-
canal的各个组件的用途
canal-server(canal-deploy):可以直接监听MySQL的binlog,把自己伪装成MySQL的从库,只负责接收数据,并不做处理。
canal-adapter:相当于canal的客户端,会从canal-server中获取数据,然后对数据进行同步,可以同步到MySQL、Elasticsearch和HBase等存储中去。
canal-admin:为canal提供整体配置管理、节点运维等面向运维的功能,提供相对友好的WebUI操作界面,方便更多用户快速和安全的操作。
二、MySQL配置
-
说明
由于canal是通过订阅MySQL的binlog来实现数据同步的,所以我们需要开启MySQL的binlog写入功能,并设置binlog-format为ROW模式,
-
配置修改如下
[mysqld] ## 设置server_id,同一局域网中需要唯一 server_id=101 ## 指定不需要同步的数据库名称 binlog-ignore-db=mysql ## 开启二进制日志功能 log-bin=mall-mysql-bin ## 设置二进制日志使用内存大小(事务) binlog_cache_size=1M ## 设置使用的二进制日志格式(mixed,statement,row) binlog_format=row ## 二进制日志过期清理时间。默认值为0,表示不自动清理。 expire_logs_days=7 ## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。 ## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致 slave_skip_errors=1062 -
配置完重启mysql
#查看binlog是否启用 log_bin显示on则为成功 show variables like 'log_bin'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | log_bin | ON | +---------------+-------+ -
查看binlog模式
show variables like 'binlog_format'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | binlog_format | ROW | +---------------+-------+
三、创建数据库canal用户
-
创建用户
创建一个拥有从库权限的账号,用于订阅
binlog,这里创建的账号为canal:canalCREATE USER canal IDENTIFIED BY 'canal'; #赋予权限 Grant all privileges on *.* to 'canal'@'%';
四、canal-deployer使用(canal-server)
-
将我们下载好的压缩包
canal.deployer-1.1.5-SNAPSHOT.tar.gz上传到Linux服务器,然后解压到指定目录/mydata/canal-server,可使用如下命令解压;tar -zxvf canal.deployer-1.1.5-SNAPSHOT.tar.gz -
修改配置文件
conf/example/instance.properties,按如下配置即可,主要是修改数据库相关配置;# 需要同步数据的MySQL地址 canal.instance.master.address=127.0.0.1:3306 canal.instance.master.journal.name= canal.instance.master.position= canal.instance.master.timestamp= canal.instance.master.gtid= # 用于同步数据的数据库账号 canal.instance.dbUsername=canal # 用于同步数据的数据库密码 canal.instance.dbPassword=canal # 数据库连接编码 canal.instance.connectionCharset = UTF-8 # 需要订阅binlog的表过滤正则表达式 canal.instance.filter.regex=.*\\..* -
使用
startup.sh脚本启动canal-server服务;sh bin/startup.sh -
启动成功后可使用如下命令查看服务日志信息;
tail -f logs/canal/canal.log 2020-10-26 16:18:13.354 [main] INFO com.alibaba.otter.canal.deployer.CanalController - ## start the canal server[172.17.0.1(172.17.0.1):11111] 2020-10-26 16:18:19.978 [main] INFO com.alibaba.otter.canal.deployer.CanalStarter - ## the canal server is r
五、canal-adapter使用
-
将我们下载好的压缩包
canal.adapter-1.1.5-SNAPSHOT.tar.gz上传到Linux服务器,然后解压到指定目录/mydata/canal-adpter -
修改配置文件
conf/application.yml,按如下配置即可,主要是修改canal-server配置、数据源配置和客户端适配器配置;canal.conf: mode: tcp # 客户端的模式,可选tcp kafka rocketMQ flatMessage: true # 扁平message开关, 是否以json字符串形式投递数据, 仅在kafka/rocketMQ模式下有效 zookeeperHosts: # 对应集群模式下的zk地址 syncBatchSize: 1000 # 每次同步的批数量 retries: 0 # 重试次数, -1为无限重试 timeout: # 同步超时时间, 单位毫秒 accessKey: secretKey: consumerProperties: # canal tcp consumer canal.tcp.server.host: 127.0.0.1:11111 #设置canal-server的地址 canal.tcp.zookeeper.hosts: canal.tcp.batch.size: 500 canal.tcp.username: canal.tcp.password: srcDataSources: # 源数据库配置 defaultDS: url: jdbc:mysql://127.0.0.1:3306/canal_test?useUnicode=true username: canal password: canal canalAdapters: # 适配器列表 - instance: example # canal实例名或者MQ topic名 groups: # 分组列表 - groupId: g1 # 分组id, 如果是MQ模式将用到该值 outerAdapters: - name: logger # 日志打印适配器 - name: es7 # ES同步适配器 hosts: 127.0.0.1:9200 # ES连接地址 properties: mode: rest # 模式可选transport(9300) 或者 rest(9200) # security.auth: test:123456 # only used for rest mode cluster.name: elasticsearch # ES集群名称 -
添加配置文件
canal-adapter/conf/es7/product.yml,用于配置MySQL中的表与Elasticsearch中索引的映射关系;重点:写SQL语句时canal对数据库的表名会大小写敏感,需要与库的表名大小写一样,否则同步数据会失败
dataSourceKey: defaultDS # 源数据源的key, 对应上面配置的srcDataSources中的值 destination: example # canal的instance或者MQ的topic groupId: g1 # 对应MQ模式下的groupId, 只会同步对应groupId的数据 esMapping: _index: canal_product # es 的索引名称 _id: _id # es 的_id, 如果不配置该项必须配置下面的pk项_id则会由es自动分配 sql: "SELECT p.id AS _id, p.title, p.sub_title, p.price, p.pic FROM product p" # sql映射 etlCondition: "where a.c_time>={}" #etl的条件参数 commitBatch: 3000 # 提交批大小 -
使用
startup.sh脚本启动canal-adapter服务;sh bin/startup.sh -
启动成功后可使用如下命令查看服务日志信息;
tail -f logs/adapter/adapter.log 20-10-26 16:52:55.148 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Load canal adapter: logger succeed 2020-10-26 16:52:57.005 [main] INFO c.a.o.c.client.adapter.es.core.config.ESSyncConfigLoader - ## Start loading es mapping config ... 2020-10-26 16:52:57.376 [main] INFO c.a.o.c.client.adapter.es.core.config.ESSyncConfigLoader - ## ES mapping config loaded 2020-10-26 16:52:58.615 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Load canal adapter: es7 succeed 2020-10-26 16:52:58.651 [main] INFO c.alibaba.otter.canal.connector.core.spi.ExtensionLoader - extension classpath dir: /mydata/canal-adapter/plugin 2020-10-26 16:52:59.043 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Start adapter for canal-client mq topic: example-g1 succeed 2020-10-26 16:52:59.044 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterService - ## the canal client adapters are running now ...... 2020-10-26 16:52:59.057 [Thread-4] INFO c.a.otter.canal.adapter.launcher.loader.AdapterProcessor - =============> Start to connect destination: example <============= 2020-10-26 16:52:59.100 [main] INFO org.apache.coyote.http11.Http11NioProtocol - Starting ProtocolHandler ["http-nio-8081"] 2020-10-26 16:52:59.153 [main] INFO org.apache.tomcat.util.net.NioSelectorPool - Using a shared selector for servlet write/read 2020-10-26 16:52:59.590 [main] INFO o.s.boot.web.embedded.tomcat.TomcatWebServer - Tomcat started on port(s): 8081 (http) with context path '' 2020-10-26 16:52:59.626 [main] INFO c.a.otter.canal.adapter.launcher.CanalAdapterApplication - Started CanalAdapterApplication in 31.278 seconds (JVM running for 33.99) 2020-10-26 16:52:59.930 [Thread-4] INFO c.a.otter.canal.adapter.launcher.loader.AdapterProcessor - =============> Subscribe destination: example succeed <=============