基于知识问答的上下文学习中的代码风格11.20
基于知识问答的上下文学习中的代码风格
- 摘要
- 1 引言
- 2 相关工作
- 3 方法
-
- 3.1 概述
- 3.2 元函数设计
- 3.3 推理
- 4 实验
-
- 4.1 实验设置
- 4.2 实施细节
- 4.3 主要结果

摘要
现有的基于知识的问题分类方法通常依赖于复杂的训练技术和模型框架,在实际应用中存在诸多局限性。最近,大型语言模型(LLM)中出现的上下文学习(ICL)功能为KBQA提供了一个简单且无需训练的语义解析范例:给定少量问题及其标记的逻辑形式作为演示示例,LLM可以理解任务意图并生成新问题的逻辑形式。然而,目前功能强大的LLM在预训练期间几乎没有暴露于逻辑形式,导致高格式错误率。为了解决这个问题,我们提出了一种代码风格的上下文学习方法的KBQA,它转换到更熟悉的代码生成过程中的LLM的不熟悉的逻辑形式的生成过程。在三个主流数据集上的实验结果表明,该方法极大地缓解了生成逻辑表单时的格式错误问题,同时在少镜头设置下在WebQSP、GrailQA和GraphQ上实现了新的SOTA。
1 引言
基于知识的问答(KBQA)是NLP社区长期研究的问题。由于问题的复杂性和多样性,性能良好的模型通常具有复杂的建模框架或特殊的训练策略。然而,这些设计也导致模型需要大量的标记数据来帮助参数收敛,导致它们难以应用于新的领域。最近,大型语言模型(LLM)具有强大的泛化能力,受益于大量自然语言语料库和开源代码的预训练(图1顶部)。此外,上下文学习(ICL)功能的出现允许LLM在观察少量标记数据的同时完成复杂的推理任务。

KB-BINDER是第一个基于ICL范式的KBQA方法。具体来说,KB-BINDER使用多个(问题,逻辑形式)对作为演示示例,并引导LLM生成正确的逻辑形式根据这些演示示例,查看新问题(图1中)。
然而,我们发现这种最新的方法仍然存在几个严重的问题:
- (1)高格式错误率。由于逻辑形式的高度专业化,它们很难全部出现在LLM的训练语料中。因此,通过几个演示示例来生成具有正确格式的逻辑形式是具有挑战性的。在我们的初步实验中,强大的GPT3.5-turbo生成的逻辑形式在GrailQA上的格式错误率超过15%。如果没有繁琐的句法分析和纠错步骤,生成的逻辑形式甚至不能提供问题的最终答案;
- (2)低零样本泛化性能。在零样本泛化场景中,与测试问题相关的知识库(KB)领域架构先验无法通过训练集中的数据获得。换句话说,这意味着从训练集创建的演示示例在这种情况下,无法提供足够的信息来回答问题。考虑到标注的数据通常只覆盖知识库中的一小部分知识,这个问题不可避免地会影响到实际应用的性能。
要解决这些问题,关键是要深入了解LLM的行为。值得庆幸的是,一些关于LLM的经验观察提供了理想的见解,其中包括
- (1) 将原始任务转换为代码生成任务将降低后处理的难度;
- (2) 逐步推理可以提高LLM在复杂推理任务上的性能;
- (3) 检索增强有助于LLM处理不常见的事实知识。
受上述有价值的观察的启发,我们为KBQA提出了一种新的代码风格的上下文学习方法,它将逻辑形式的一步生成过程转换为Python中函数调用(Function Call)的渐进生成过程(图1底部)。
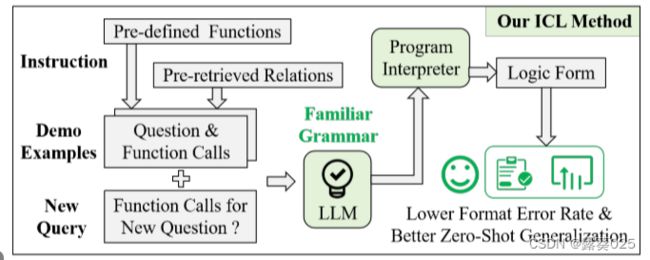
具体来说,我们首先为S-Expression定义了七个元函数,S-Expression是KBQA的一种流行逻辑形式,并在Python中实现了这些函数。请注意,此步骤使所有S表达式能够通过有限数量的预定义元函数调用生成。对于一个测试问题,我们在训练集中抽取了一些(question,S-Expression)对,并将它们转换为(question,function call sequence),其中函数调用序列可以在Python解释器中执行以输出S-Expression。最后,元函数的Python实现、所有(问题、函数调用序列)对和测试问题以代码形式重新格式化,作为LLM的输入。并期望LLM为新问题补充一个完整的函数调用序列,以获得正确的逻辑形式。此外,我们还发现了一种简单有效的方法来提高零次泛化场景下的性能:将测试问题视为查询,在知识库中检索相关关系,并将该关系提供给LLM以供参考。
我们的贡献可以总结如下:
- 我们提出了一种新的代码风格的上下文学习方法的KBQA。与现有的方法相比,我们的方法可以有效地减少格式错误率的逻辑形式生成的LLM,同时提供额外的中间步骤在推理过程中。
- 我们发现,提前提供与问题相关的关系作为LLM的参考可以有效地提高零次泛化场景中的性能。
- 基于ICL方法设计了一个无需训练的KBQA模型KB-Coder。在WebQSP、GrailQA和GraphQ上的大量实验表明,我们的模型在少镜头设置下实现了SOTA。在允许访问完整训练集的同时,与当前的监督SOTA方法相比,无需训练的KB-Coder实现了具有竞争力或更好的结果。
2 相关工作
根据最新LLM调查中的定义,我们将参数大于10 B的模型视为LLM,包括T5(编码器-解码器)和GPT 3(仅解码器)等。由于篇幅原因,我们在本节中只介绍与LLM相关的工作。
使用Code-LLM进行复杂推理
Codex首先引入了一个代码语料库来训练LLM,并发现获得的code-LLM具有出色的逻辑推理能力。随后,code-LLM以两种方式用于各种复杂任务。
第一种方式只隐含地使用了来自代码预训练的推理能力,并提出了诸如思想链之类的技术和问题分解等,并以另一种方式将任务形式转化为代码生成,通过创建实例引导LLM实现最初的任务目标,互补代码或生成SQL或逻辑形式。
LLM问答
我们根据LLM生成内容的类型来区分不同的方法。
- 第一类方法指导LLM直接生成答案。在这些方法中,将外部知识源中的知识转换为索引,然后将问题用作查询以通过稀疏或致密检索。然后将问题和相关知识拼接在一起,并输入LLM以直接生成答案。
- 第二类方法将LLM视为答案选择器,并引导LLM从候选集合中选择正确答案。
- 第三类方法将LLM视为语义解析器,并指导模型生成中间逻辑形式。
与直接生成答案相比,其他两类方法原则上可以消除生成假知识的风险,但无法实现端到端的方法。除了上述三个类,DECAF是一个特殊的情况,它指导LLM通过改变promp来生成逻辑形式和最终答案。
3 方法
3.1 概述
一般来说,我们提出的KBQA方法是一种基于语义分析的方法:
1)给定一个自然语言问题q和知识库 G = {(h,r,t),h,t ∈ E,r ∈ R},其中E是实体集,R是关系集,我们的方法可以被视为函数F,它将q映射到语义一致的逻辑形式 l l l = F(q)$ 。
2)然后将 l l l 转换为查询来执行,并将查询结果视为q的答案。具体来说,我们首先设计了七个元函数,它们可以覆盖特定逻辑形式的所有原子操作,并在Python中重新定义了这些元函数。
3)最后,对于一个新的问题,采用以下三个步骤来获得答案(图3):
- 通过代码式的上下文学习方法,使用LLM获取其函数调用序列;
- 在从函数调用中提取的实体提及(entity mentions)中,使用了一个密集型检索器来链接实体,同时使用另一个密集型检索器来匹配函数调用中提取的关系名(relation name)。
- 程序解释器用于执行生成的函数调用序列以获得逻辑形式 l l l,该逻辑形式 l l l将被进一步执行以获得答案a。

“Dense Retriever”(密集型检索器)是一种用于信息检索的组件或技术。它被设计用于从大规模的文本数据集中检索与给定查询相关的文档或句子。
3.2 元函数设计
在实践中,由于其简单性,我们使用S表达式作为逻辑形式 l l l。S表达式是一种用于嵌套列表(树结构)数据的类似名称的表示法,它符合“前缀表示法”的语法。具体来说,S-Expression通常由括号和其中的几个空格分隔的元素组成,其中第一个元素是函数名称,所有其余元素都是函数的属性。例如,对于“总共有多少个美国演讲者”的问题,其S表达式是:
其中m.09c7w0和m.015cjr是实体United States of America和Presenter的唯一标识符。这个S-Expression的对应树结构如图2的左侧所示。

基于S-Expression的原始语法,我们总共定义了七个元函数(表1),包括它们的名称,域,范围和映射描述。与原语法相比,对新的元函数进行了自适应修改,并在附录中进行了详细描述。

典型的上下文学习范例通常包括指令 I I I ,K演示示例D = {d1,d2,… ,dK}和新的查询Q。如果LLM的输出表示为C,我们可以将上下文学习的过程表示为:
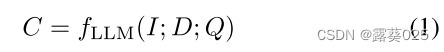
其中fLLM表示特定LLM。在我们的方法中,我们使用代码样式来构造 I 、 D 和 Q I、D和Q I、D和Q,并期望模型来为Q生成一段代码——一个元函数调用序列,如下演示示例所示。接下来,我们将详细描述如何分别构建每个部分。
指令I 与以前的代码LLM类似,指令由两部分组成:用于描述任务的提示注释和七个元函数的代码实现。由于Codex在Python中的成功实践,我们选择Python来实现这些函数。那么, I I I的完整内容如下:


其中,所有七个函数都是表1中同名函数的实现。
演示示例D
每个演示示例都是从训练集中的(question,S-Expression)对创建的,包含两个部分:一个名为question的变量和一个函数调用序列。具体来说,字符串变量question由question赋值,而函数调用序列由S-Expression转换。图2的右侧提供了函数调用序列的示例,其中每个函数调用可以对应于树结构中的一个非叶节点。因此,函数调用序列也可以被认为是树结构的自底向上解析的结果。如果将Instruction中的元函数定义与函数调用序列作为一个整体代码拼接到Python解释器中,我们可以通过访问变量表达式的值来获得完整的SExpression。由于KB中的实体标识符(如m.03yndmb)丢失了它们的语义信息,因此我们将所有实体标识符映射到它们的表面名称,以帮助LLM获得这些实体的语义信息。最后,将与图2对应的演示示例重新表述如下:

为了获得D,我们在训练集中总共采样K(question,S-Expression),将每对转换为上述形式,并使用换行符将它们拆分。
新的查询Q
与演示示例的形式相比,新的查询是一段不完整的代码,只包含变量问题的一部分,例如,问题“融合有多少宗教文本”将被重新表述为
![]()
对于每个Q,期望LLM补充与具有上下文学习能力的问题相对应的剩余函数调用序列。
在实践中,I保持不变。对于D,我们可以为数据集中的每个Q提供一致的D,以遵循少数镜头设置,或者我们可以基于相似性为每个Q选择不同的D,以获得更好的性能。这两种设置都将在后续实验中进行研究。
3.3 推理
在本节中,我们将描述对LLM生成的函数调用序列进行后处理的方法,以便将它们转换为查询,最终获得预测的答案。
实体链接和关系匹配
回想一下,LLM不能直接查看KB中的信息,这使得生成完全正确的实体名称和关系名称变得困难。然而,我们认为,生成的名称具有较高的语义相似度与正确性,所以生成的名称可以被视为实体链接和关系匹配的提及。得益于我们对元功能域的严格定义,实体提及和关系提及都可以很容易地被解析。具体来说,对于实体链接,我们首先通过现成的嵌入模型SimCSE将KB中所有实体的所有表面名称转换为表示并使用Faiss构建实体索引。当链接实体提及时,我们首先使用HARD MATCH策略来获得与提及具有相同表面名称的所有实体作为候选集。如果候选集的大小大于超参数Me,我们将只保留最受欢迎的Me实体引用FACC1。相比之下,如果size小于Me,我们将从现有的实体索引中搜索最相似的实体来填充候选项,托姆。类似地,我们使用相同的技术来索引KB中的所有关系,并检索Mr个语义上最相似的关系作为每个生成的关系名称的候选者。
答案预测
不失一般性,我们假设函数调用序列包含p个要链接的实体和q个要匹配的关系,将第i个实体提及的候选集表示为Cie,将第j个关系提及的候选集表示为Cjr。然后,我们可以获得有序元组集合![]()
![]()
其中×表示笛卡尔积。对于集合中的每个有序元组,让有序元组中的每个元素逐一替换函数调用序列中相应的生成名称,我们可以获得整个函数调用序列的候选项(图3)。最后,将(Me)P.(Mr)q 每个函数调用序列的候选项,对于某些特殊情况,这可能是一个巨大的数字。因此,我们会逐一执行函数调用序列,得到S-Expression,然后将SExpression转换为SPARQL执行,一旦查询到的结果不为null,我们就直接终止逐一尝试的过程,将查询到的结果视为问题的答案。
一种零样本泛化相关关系
码式上下文学习的相关关系使LLM更适应任务形式,从而降低格式错误率。然而,当查询域不涉及演示示例时,这被称为零样本泛化场景,LLM的性能仍然很差。这并不难理解,因为任务提示形式的变化并没有给LLM带来查询领域的新的额外知识。在分析了初步实验中的不良情况后,我们发现错误的最大问题是关系匹配,其中LLM生成的关系通常无法在零样本泛化场景下命中正确的关系。随后,我们通过为LLM提供额外的关系名称来缓解这个问题。具体来说,我们使用整个测试问题作为查询,从关系索引中检索相似关系,并将具有最高相似度的关系插入演示示例D和新问题Q之间,注释格式如下:

基于初步的实验,观察到一个关系带来最好的性能和更多的关系,性能上的改善不大。我们将分析关系的数量对结果的影响在实验部分有详细说明。
4 实验
4.1 实验设置

4.2 实施细节
在没有特别说明的情况下,我们报告了Me = 15和Mr = 100的实验结果。SimCSE实例sup-simcse-bert-base-uncased 2用于获得密集表示。与KBBINDER一致,我们对WebQSP和GraphQ进行了100次拍摄,对GrailQA进行了40次拍摄。在下面的部分中,我们使用不同的符号来表示不同的变体:
- KB-Coder(1):从训练集中随机抽取固定问题作为演示示例。LLM仅生成1个候选。
- KB-Coder(6):使用KBCoder(1)和LLM的相同采样设置生成6个候选项,并使用多数投票策略(Wang et al. 2022)来选择最终答案。由于LLM的自洽性,性能有望进一步提高。
- KB-Coder(1)-R:选择与测试问题最相似的问题作为演示示例。LLM仅生成1个候选。·
- KB-Coder(6)-R:与KBCoder(1)-R和LLM相同的采样策略生成6个候选,并使用多数投票策略来选择最终答案。
请注意,KB-Coder(1)和KB-Coder(6)严格地在少样本设置下,而其他两个变体则是在可以访问整个训练集时探索性能的上限。对于每个设置,我们重复三次,并报告平均值和标准差。
4.3 主要结果
我们在表2、表3和表4中报告了KB-Coder和其他基线在GrailQA、WebQSP和GraphQ上的性能。接下来,我们将分别分析格式错误率(FER)和性能指标(EM和F1)。回想一下,将逻辑表单生成转换为代码生成的动机之一是允许LLM执行更熟悉的任务,以确保生成的内容的格式的正确性。在所有三个数据集上的性能成功地验证了我们的方法在少镜头设置下的有效性:(1)在问题更简单的WebQSP上,现有方法生成的逻辑形式具有较低的FMR,但KB-Coder仍然可以进一步将FMR降低到更低的水平;(2)在问题复杂度较高的GrailQA和GraphQ上,KB-Coder比直接生成逻辑形式的两种方法有明显的提高;(3)利用LLM的自一致性,多数表决策略有助于缓解KBBINDER格式错误率问题。而KB-Coder可以使用多数票策略来推动FMR的新低。得益于较低的FER,与KB-BINDER相比,三个数据集的F1得分(或EM)在几乎所有设置下都有显著提高,特别是在两个没有引入多数票策略的设置下。(1)在WebQSP和GraphQ上,与全监督方法相比,无需训练的KB-Coder(6)-R实现了具有竞争力的结果,而我们的方法进一步缩小了与GrailQA上的全监督模型相比,KBCoder的性能下降;(2)与KB-BINDER相比,KBCoder通常在无依赖下获得实质性的领先,反映了我们方法的潜在性能更好;(3)与KB-BINDER相比,KB-Coder的性能波动更剧烈,这是我们在未来工作中需要重点解决的问题。