Multi-modal Sensor Fusion for Auto Driving Perception: A Survey(自动驾驶感知多模态传感器融合综述)
摘要
多模态融合是自动驾驶系统感知中的一个基本任务。然而,由于原始数据的噪声,信息的未充分利用和多模态传感器的失调,实现一个相当好的性能并不是一个容易的事情。在这片文章中,作者对于现有的基于多模态自动驾驶感知任务方法进行了文献综述。作者对于超过50片论文进行了一个详细的分析,利用感知传感器(包括激光雷达和相机)试图解决目标检测和语义分割的任务。
与传统的融合模型分类方法不同,作者提出了一种创新的方法,从融合阶段的角度来看,通过更合理的分类法将其分为两大类,四个小类;此外,作者还深入研究了目前的融合方法,关注了仍然存在的问题并且展针对于一些潜在的研究展开了讨论。
总结来说,本文希望提出一种针对于自动加沙感知任务的新的多模态融合的分类方法,激发一些未来基于融合的技术的思考。
introduction
感知
感知是自动驾驶的一个重要模块,这些任务包括但是不限于二维/三维目标检测、语义分割、深度完成和预测,这些任务依赖于安装在车辆上的感知器来从环境中采集原始数据。 大多数现有的方法是对激光雷达和相机捕获的点云和图像数据及逆行感知任务,有不错的效果。
单模态的缺陷
然而,单模态数据感知存在缺陷。比如摄像机的数据主要采集在前视图的下方位置,对象可能会在更加复杂的场景中被遮挡,给目标检测和语义分割带来了挑战。此外,由于机械结构,激光雷达在不同的距离下会有不同的分辨率,而且会受到一些障碍物比如青蛙和暴雨等极端天气的影响。
这两种模式在不同方面都擅长,如果两者可以结合,那么就会产生更好的感知性能。
多模态融合阶段
近年来,用于自动驾驶感知任务的多模态融合方法发展迅速,从更新进的跨模态特征表示和不同模态中更可靠的传感器到更复杂、更鲁棒的深度学习和多模态融合技术。
然而,关注多模态融合本身的比较少,其中大多数遵循传统把多模态融合分为三类:早期融合、深度融合和后期融合,关注的是在深度学习中融合特征的阶段,无论是数据级、特征级或者是建议级。
首先,这种分类方法并没有明确定义每个级别的特征表示;其次,建议激光雷达和相机两个分支在处理过程中总是对称的,忽视了激光雷达分支建议级特征和相机分支数据级特征融合情况。
本文中,作者提出一种创新的方法,从融合阶段的角度,通过更加合理的分类法,将50多篇论文分为两个主要类和四个次要类:
1、 本文提出一种创新的多模态融合方法分类,包括两大类:强融合和弱融合;强融合中的四个小类:早期融合、深度融合、晚期融合和不对称融合,这是由激光雷达和相机分支的特征表示明确定义的。
2、本文对于激光雷达和相机分支的数据格式和表示进行深入的调查,并且探讨他们的不同特征。
3、对于仍然存在的一些问题进行了细致的分析,探讨了潜在的研究方向。
自动驾驶中的感知任务和开放数据集
多模态传感器融合感知任务
一般来说,有一些任务可以解释为驱动感知任务,包括目标检测、语义分割、深度补全和预测等;本文主要关注前面两个任务,此外,它们还包括检测障碍物、交通灯、穿越交通标志、分割车道或者自由空间等等。下面这张图显示了自动驾驶过程中的感知任务概述:
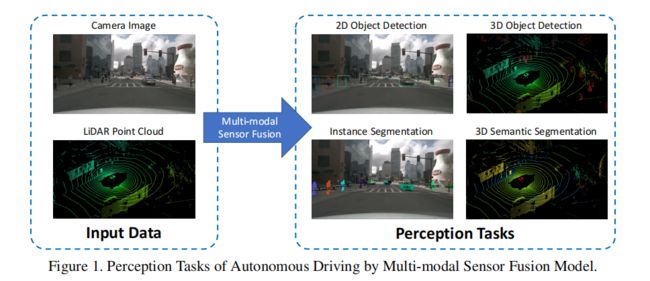
目标检测
对于了解汽车周围环境至关重要,无人驾驶的车辆需要检测道路上的静止和移动的障碍物。研究人员会建立(汽车、行人、自行车、等等)的框架,交通灯检测、交通标志检测也是。
一般来说,目标检测使用由参数表示的矩形或者长方体来来帮顶预定义类别的实体,比如汽车或者行人,这需要在定位和分类方面都很出色。由于缺乏深度通道,2D目标检测通常简单地表示为(x、y、h、w、c),而3D目标检测边界框通常表示为(x、y、z、h、w、l、θ、c)。
语义分割
可通行空间的检测是许多自动驾驶的模块,将地面的像素划分为可驾驶和不可驾驶的区域。一些车道线检测也会使用多类语义分割掩码来表示道路上的不同车道。
语义分割的本质是将输入数据的基本成分,比如像素和三维点聚类到包含特定语义信息的多个区域中。比如说给定图像像素或者3D点云数据和一组预定义的候选标签,使用一个模型来给每个像素或点di分配k个语义标签中选定的一个或所有概率。
其他感知任务
还包括目标分类、深度补全和预测。虽然本文没有详细介绍,但是可以看作是目标检测或者是语义分割的变体。
公开数据集
超过十个数据集与自动驾驶感知相关,然而,只有KITTI,Waymo和nuScenes常用。

KITTI
包括二维、三维和鸟瞰图检测任务。收集了7481张训练图像和7518张测试图像以及相应的点云。只有三个物体被标记为汽车、行人和骑自行车的人,有超过200K的3D对象注释,按照检测难度分为三类:易、中、难。对于KITTI目标检测任务,经常使用平均精度进行比较。此外,还利用平均方向相似度来评估联合检测对象和估计其三维方向的性能。
Waymo
有798个训练场景、202个测试验证、150个测试场景。每个场景跨度20秒,带有车辆、自行车和行人的注释。对于评估3D目标检测任务,Waymo由四个指标组成: AP/L1、APH/L1、AP/L2、APH/L2。更具体地说,AP和APH代表两种不同的性能度量,而L1和L2包含具有不同检测困难的对象。对于APH,其计算方法与AP相似,但按航向精度进行加权。
NuScenes
包括1000个驾驶场景,其中700个用于训练,150个用于验证,150个用于测试。配备了相机、激光雷达和雷达传感器,在每个关键帧中注释了23个对象类,包括不同类型的车辆、行人和其他车辆。NuScenes使用AP、TP进行检测性能评估。此外,它提出了一种创新的标量评分作为AP计算的nuScenes检测评分(NDS),隔离不同的误差类型。
激光雷达和图像表示
深度学习模型仅限于输入的表示,为了实现该模型,需要在将数据输入模型之前,通过一个复杂的特征提取器对原始数据进行预处理。
对于图像分支来说,大多数现有方法都保持于下游模块输入的原始数据相同的格式。然而,激光雷达的分支高度依赖于数据格式,它强调不同的特征,并且极大地影响下游模型的设计。因此,我们将它总结为因此,我们将它总结为基于点的、基于体素(三维空间中定义一个点的图象信息的单位)的和基于二维映射的点云数据格式,适合于异构型的深度学习模型。
图像表示
单目相机是二维或者三维目标检测和语义分割任务中最常用的数据采集传感器,提供了丰富的纹理信息的RGB图像。具体来说,对于每个像素为 ( u , v ) (u,v) (u,v)的图像,他有一个多通道特征向量 F ( u , v ) = { R , G , B , . . . } , F_{(u,v)}=\lbrace R, G, B, ...\rbrace, F(u,v)={R,G,B,...},,通常包括相机捕捉颜色,分解为红蓝绿通道或者其他手动设计的功能作为灰度通道。
然而,由于深度信息有限,单目相机很难提取出物体,因此在三维空间中直接检测物体相对具有挑战性。因此,许多国祚通过时空空间使用双目或者立体摄像系统来利用额外的 信息进行三维目标检测,比如深度估计、光流等。对于极端的驾驶环境,一些工作也使用门控或者红外线摄像头来提高鲁棒性。
基于点的点云表示
对于三维感知传感器,激光雷达使用激光系统扫描环境并生成点云.它采样世界坐标系中表示激光光线与不透明度表面相交的点。一般来说,大多数激光雷达的原始数据是四元组 ( x , y , z , r ) (x,y,z,r) (x,y,z,r),r代表每个点的折射率,不同的纹理将会导致不同的折射率,这在以下任务中提供了额外的信息。
Pengdi Huang, Ming Cheng, Yiping Chen, Huan Luo,
Cheng Wang, and Jonathan Li. Traffic sign occlusion detection using mobile laser scanning point clouds. IEEE Transportation on Intelligent Transportation Systems, 18(9):2364–
2376, 2017. 4
为了合并激光雷达的数据,一些方法通过基于点的特征提取backbone直接使用点。然而,点的四元数表示存在冗余或者速度缺陷。因此,许多研究人员试图将点云转换为体素或者二维投影,然后将其输入下游模块。
基于体素(三维空间中定义一个点的图象信息的单位)的点云表示
一些工作利用3D CNN将三维空间离散为三维体素,表示为 X v = { x 1 , x 2 , x 3 . . . x n } X_v=\lbrace{x_1,x_2,x_3...x_n}\rbrace Xv={x1,x2,x3...xn},每一个 x i x_i xi代表一个特征向量,也就是说 X i = { s i , v i } X_i=\lbrace{s_i,v_i}\rbrace Xi={si,vi}。 s i s_i si代表体素化长方体的质心, v i v_i vi代表一些基于统计的局部信息。
局部密度是一个由局部体素中的三维点的数量定义的常用的特征;局部偏移量通常定义为点实字坐标与局部体素质心之间的偏移量;其他的可能包含局部线性和局部曲率。
最近的工作可能考虑一种更加合理的离散方
法,即基于柱体的体素化。但是基于体素的点云表示,不同于上面提到的基于点的点云表示,大大减少了非结构化点云的荣冗余性。此外,能够利用三维稀疏卷积技术,感知任务不仅实现更快的训练速度,而且实现更高的精度。
基于二维映射的点云表示
一些工作并没有提出新的网络结构,而是利用复杂的2D CNNbackbone来编码点云。具体来说,他们试图将激光雷达数据作为两种常见的类型投射到图像空间中,包括相机平面地图和鸟瞰图。
CPM
通过将每个三维点 ( x , y , z ) (x,y,z) (x,y,z)投影到相机坐标系 ( u , v ) (u,v) (u,v)中的外部校准可以得到一个CPM。由于CPM具有与相机图像相同的格式,它们可以通过使用CPM作为一个额外的通道来进行融合。然而,由于投影后激光雷达的分辨率比较低,CPM中的许多像素的特征被破坏。因此,人们提出一些方法对特征图进行上采样,其它则空白。
BEV
BEV映射提供了鸟瞰图,它被用于检测和定位有两个原因:
- 首先,与安装在挡风玻璃后面的摄像头不同,大部分激光雷达在车辆顶部,有更少的遮挡
- 其次,将所有物体放置在BEV的地面上,模型可以在长宽不扭曲的情况下预测。BEV组件可能不同,有些是直接通过高度、密度或者强度转换为基于点或者基于体素的特征,而其它的则通过特征提取模块学习pillars中的激光雷达信息特征。
融合方法
从传统分类学角度来看,所有多模态数据融合方法都可以分为三种模式:数据集融合(早期融合)、特征级融合(深度融合)和对象级融合(晚期融合)。数据级融合通过空间对其直接融合原始传感器数据;特征融合通过连接元素或者元素级乘法在特征空间中混合跨模态数据;目标级融合将模型在每个模态中的预测结果结合起来,并作出最终决策。
然而,在最近的工作中,不是所有工作都可以分为这三类,所以在本文中,提出一种新的分类方法,将所有融合方法分为强融合与弱融合。下图展示了他们之间的关系:

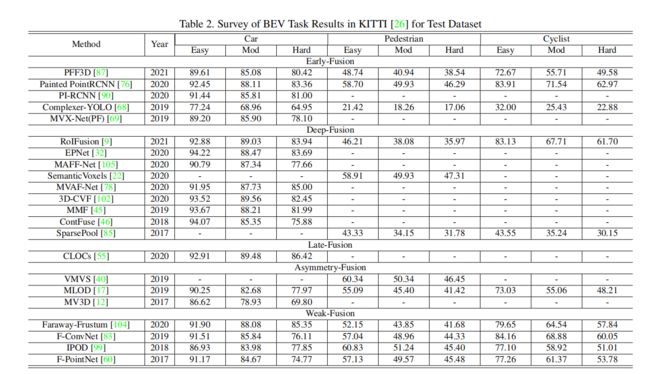
为了进行性能比较,本文主要关注于KITTI基准测试中的两个主要任务,如三维检测和鸟瞰对象检测,下面两张表分别给出了最近多模态融合方法的BEV和三维设置的KITTI测试数据集上的实验结果。

强融合
通过激光雷达和摄像机数据表示的不同组合阶段,我们将强融合分为早期融合、深度融合、晚期融合与不对称融合。从下图可以看出,强融合每个小类都是高度依赖于激光雷达点云,而不是摄像机数据。

早期融合
与传统的数据级融合的定义不同,早期融合是通过在原始数据级的空间排列和投影直接融合每种模式的数据,在数据级融合LiDAR数据,在数据级或特征级融合相机数据。下图是一个早期融合的例子:

- 对于上面提到的激光雷达分支,点云可以以三维点的反射率、体素化张量、前视图、范围视图、鸟瞰试图以及伪点云的形式使用。虽然这些数据都具有不同的内在特征,这些特征与后一个激光雷达主干高度相关,但是除了伪点云之外,大多数这些数据都是通过基于规则的处理产生的。此外,所有这些激光雷达的数据表示都可以直接可视化,因为与在特征空间中的嵌入相比,这个阶段的数据仍然具有可解释性。
- 对于图像路径,严格的数据集定义应该只包含RGB或者灰度等数据,缺乏通用性与合理性。与传统的早期融合定义相比,在这里将相机数据放松到数据级和特征级数据。特别是,这里将有利于三位对象检测的图像分支的语义分割任务结果作为特征级表示,因为这些对象级特征不同于整个任务的最终对象级建议。
深度融合
深度融合方法融合了激光雷达分支的特征级的跨模态数据,而不是图像分支的数据级和特征级。比如,一些方法利用特征提取器分别获得激光雷达点云和摄像机图像的嵌入表示,并通过一系列下游模块将特征融合成两种模式。然而,与其他强融合方法不同的是,深度融合有时以级联的方式融合特征,即利用原始信息和高级语义信息。深度融合的例子如下图:

晚期融合
在每个模态中融合管道结果的方法。例如,一些后期融合的方法同时利用激光雷达点云分支和摄像机图像分支的输出,根据两种模式进行最终预测。两个分支应该具有与实际结果相同的数据格式,但是在质量、数量和精度上不同。晚期融合可以看作是一种利用多模态信息来优化最终方案的集成方法。例子如下:

不对称融合
一些方法处理具有不同特权的跨模态分支,因此作者将一个分支的对象级信息和其他分支的数据级或者特征级融合方法定义为不对称融合。
不对称融合至少有一个分支占主导地位,其他分支提供辅助信息来完成最终任务。例子如下:

弱融合
弱融合不直接从多模式中的分支中融合数据或者特征或者对象,而是使用其他方式操作数据。基于弱融合的方法通常使用基于规则的方法,利用一种模态的数据作为监督信号来指导另一种模态的交互。下图是一个例子。比如,来自CNN在图像分支中的2D proposal可能会导致原始激光雷达点云中的困难,然而,弱融合直接将选择的原始激光雷达点云输入到激光雷达主干中,输出最终方案。

其他融合
有些方法不止一种融合方法,比如深度融合与晚期融合的结合,这些不是主流方法。
多模态融合的未来发展
更先进的融合方法
目前的融合模型存在错位和信息丢失的问题,此外,平面融合操作也组织了感知任务的进一步提高,因此可以总结为两个方面:
错位和信息丢失
照相机和激光雷达的内在性和外在性都有很大的不同,这两种方式下的数据都需要在一个新的坐标系统下重新组织。传统的早期和深度融合方法利用外部校准矩阵将所有的激光雷达点直接投射到相应的像素上,反之亦然。然而,由于感官噪声的存在,这种逐像素的对其还不够准确。因此,我们可以看到,除了这种严格的对应关系,一些工作利用周围的信息作为补充,可以获得更好的性能。
此外,在输入和特征空间的转换过程中还存在一些信息丢失。一般来说,降维操作的投影会不可避免地导致大量的信息丢失。例如,将三维激光雷达点云映射到二维BEV图像中。因此,通过将两个模态数据映射到另一个专门为融合而设计的高维表示中,未来的工作可以有效地利用原始数据。
更合理的融合操作
目前的研究工作采用了直观的方法来融合跨模态数据,例如连接和元素乘。这些简单的操作可能无法融合数据与较大的分布差异,因此,很难缩小两种模式之间的语义差距。一些工作试图使用更详细的级联结构来融合数据并且提高性能。在未来的研究中,双线性映射等机制可以融合具有不同特点的特征。
多源信息利用
前视图中的单帧是自动驾驶感知任务[26]的典型场景。然而,大多数框架利用有限的信息,而没有详细设计的辅助任务来进一步理解驾驶场景。我们将它们总结为具有更多潜在的有用信息和自我监督的表示学习。
提供更多潜在的有用信息
现有方法缺乏对于来自多个维度和来源的信息的有效利用,它们大多数集中在前视图上的单帧多模态数据上。因此,其它有意义的信息没有被充分利用,比如语义、空间和场景上下文信息。未来研究可以通过检测车道、交通灯和标志等各种下游任务,共同构建一个完整的城市景观场景的语义理解框架,以协助感知任务的表现。
此外,当前的感知任务主要依赖于一个忽略时间信息的单一框架。一些基于激光雷达的方法结合了一系列的帧来提高性能。时间序列信息包含序列化的监督信号,这比使用单个帧的方法可以提供更稳健的结果。因此,未来的工作可能会更深入地挖掘利用时间、上下文和空间信息的连续帧和创新的模型设计
自监督表示学习
相互监督信息自然存在于从同一真实场景但不同视角采样的跨模态之间。然而,目前方法并不能挖掘每个模态之间的相互关系,对数据缺乏深刻理解。在未来的研究可以机中在如何使用多模态数据进行自我监督学习,包括预训练、微调或者对比学习。通过实现这些最先进的机制,融合模型将导致对数据的更深入的理解,并取得更好的结果。
传感器中的内在问题
域偏置和分辨率与真实场景和传感器高度相关。这些意想不到的缺陷阻碍了自动驾驶深度学习模型的大规模训练和实现,这需要在未来的工作中得到解决
数据域偏差
在自动驾驶感知场景中,不同传感器提取的原始数据伴随着严重的领域相关特征。不同的照相机系统有它们的光学特性,而激光雷达可能从机械激光雷达到固态激光雷达而有所不同。更重要的是,数据本身可能是有领域偏见的,如天气、季节或位置,即使它被相同的传感器捕获。因此,检测模型不能平稳地适应新的场景。由于泛化的失败,这些缺陷阻碍了大规模数据集的收集和原始训练数据的可重用性。因此,在今后的工作中,找到一种消除领域偏差、自适应集成不同数据源的方法至关重要。
数据分辨率冲突
来自不同模式的传感器通常具有不同的分辨率。例如,激光雷达的空间密度明显低于图像。无论采用何种投影方法,由于找不到相应的关系,都会了一些信息。这可能导致模型是由一种特定模式的数据所主导的,无论是由于特征向量的不同分辨率,还是由于原始信息的不平衡。因此,未来的工作可以探索一种新的兼容不同空间分辨率传感器的数据表示系统。