大模型时代,企业如何重构 AI 应用落地范式?
近一年来,生成式人工智能(AIGC)技术的快速发展和各种大模型的涌现,引发了全球范围内对于通用人工智能(AGI)时代是否即将到来的讨论。在 AIGC 大模型公共服务逐渐被大众辩证地接受后,如何用 AIGC 技术重塑企业智能服务成为一个深水区。
现在,几乎所有的企业都在尝试 AIGC 技术在自身领域的落地,但是,在落地过程中会面临各种挑战和难题。然而,我们清晰地看到,新的人工智能(AI )技术已经改变了企业原来通过 AI 原子化能力赋能业务的链路。在统一的企业 AI 数据基础设施之上,通过大模型中沉淀的泛化的智能与精准的企业知识进行深度融合,再浓缩成特定场景化的服务,带领企业迈入真正的全面智能化时代。

2006年,Geoffrey Hinton 等发表了论文《Reducing the Dimensionality of Data with Neural Networks》,开启“深度学习”时代。到如今,通过近 20 年的时间,越来越多的企业已经构建了相对完善的 AI 应用开发和运维体系,这个体系通常分为三层:底层是机器学习平台,中间层是 AI 服务,最上层是基于 AI 服务的企业应用。
在深度学习时代的 AI 存在诸多落地问题:具体来说,在数据侧,由于传统小模型泛化能力较差,难以将现有模型直接结合更加完整的企业私有数据对外提供服务,企业私有数据在面向 AI 的应用方面并没有实现连通和链接;在 AI 服务生态方面,企业期望能够直接复用已有的 AI 服务来快速构建应用,但实际只有一小部分服务(如 OCR、语音识别等)实现了较高的可复用性,企业仍需为其自有数据和业务场景不断开发新的算法和模型,AI 应用的落地效率有待提高。

随着以大模型技术为核心的 AIGC 技术的快速发展,AI 时代的 iPhone 时刻正式来临,AI 正在从深度学习时代迈向大模型时代。全新的技术范式正在重新定义企业 AI 应用的落地方式,加速企业全面智能化升级,也将带来传统 AI 应用开发和运维的新变化。
大模型可以结合更多的企业数据进行智能化应用开发,而不局限于非常有限的数据进行 AI 智能化;大模型的泛化能力可以使一个大模型处理多个下游 AI 任务,节省模型开发时间和多个模型的运维成本;同时数百亿参数级别的大模型具有泛化能力和智能涌现能力,模型效果相较传统深度学习模型有较大提升。这些大模型优势也吹响了 AIGC 在企业落地的号角。
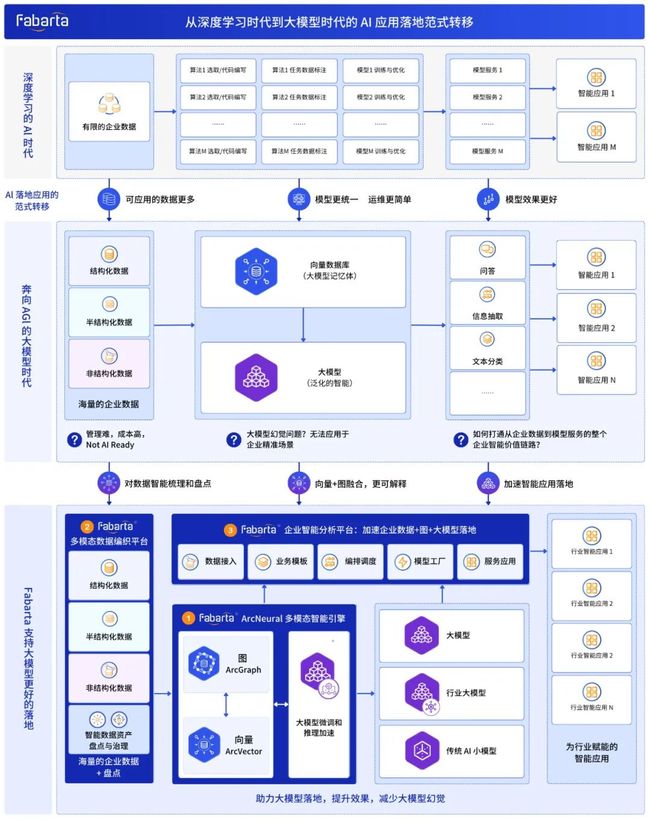
从深度学习时代到大模型时代的 AI 应用落地范式转移

大模型由于其技术优势,各企业已经逐步尝试结合企业数据进行落地。在实践过程中,也存在诸多挑战:
-
企业海量数据管理难、成本高,如何让企业丰富的数据为 AI 落地做好准备?
-
结合向量数据库和企业数据,大模型在落地过程中存在幻觉、不可解释等问题,如何应对企业对精准知识以及可解释性的需求?
-
如何在有限资源下实现更快的模型推理效果?
-
如何打通从企业数据到模型服务的整个企业智能价值链路?
为了应对以上挑战,实现 AI 应用的快速落地,企业需要建立针对大模型时代的 AI 基础设施,减少大模型幻觉问题,优化 GPU 资源使用,并提升服务推理能力;需要对企业各种类型数据进行智能的管理和盘点,为大模型提供高质量的数据输入;需要提供用户友好的工程化链路来打通从企业数据、模型服务到智能应用的价值链路。
3.1 统一的 AI 基础设施比以往任何时候更重要
归功于大模型的泛化能力和多模态能力,在未来,除了少数企业采用自有全新训练和微调( fine tune) 大模型外,多数企业将更多地基于大模型(通用大模型或行业大模型),再结合少量小模型进行快速应用落地。在此背景下,企业比以往更加关注私有数据、更为经济的算力以及开箱即用的模型。
在大模型场景下,企业也需要解决大模型幻觉问题、大模型长效记忆和推理问题,同时能基于有限的 GPU 资源提升服务推理效果。因此,针对大模型的统一数据、算力和模型的 AI 基础设施将成为未来企业在大模型时代的标配需求。
3.2 AI 是数据的最终出口,高质量的数据可以帮助企业打造高质量的本地模型以及 AI 应用
当前,商业智能(BI)仍是数据的重要出口之一。随着大模型技术的兴起,BI 和 AI 的融合将得到加速,AI 将成为数据的最终价值出口。从 BI 的数据使用历程来看,高质量的数据报表依赖于高质量、经过清洗的结构化数据。类似于 BI ,高质量的多模态数据也将是影响 AI 模型和应用质量的重要因素。
企业将从基于监管的数据治理转向以业务驱动的智能化数据资产盘点,为大模型和业务场景提供高质量的数据输入。但偏重人工实施的传统数据治理平台难以高效完成这些工作,因此,在大模型的能力驱动下,统一智能数据资产平台建设将有效保障高质量的企业数据,进而加速企业在大模型时代落地 AI 应用的能力。
3.3 打通数据和模型工厂的低代码平台才能真正帮助企业快速落地 AI 应用
在大模型时代之前,由于 AI 模型的泛化能力有限,很多情况下不同的 AI 应用需要单独建立新的 AI 模型,这导致新 AI 应用开发依赖专业的算法工程师和高级开发人员。而在大模型时代,企业人员可以更多地关注其私有数据并选择合适的大模型(或者是大模型和小模型的搭配),并通过提示工程或模型微调将模型同本地高质量的数据链接在一起。
更进一步,大模型可以理解业务场景,根据客户数据和业务场景来编织不同的模型共同完成业务目标。企业人员将更倾向于使用低代码化方式来关联其数据和模型,以实现 AI 能力在业务的快速落地。通过将企业多模态的数据“编织”起来,并利用不断升级的 AI 大模型的能力,重塑企业服务,最终产生新的业务价值。

4.1 Fabarta 产品矩阵
基于对大模型时代 AI 应用落地范式的理解,Fabarta 结合当前服务的多家大型头部金融、制造业等客户的业务痛点和需求,经历一定的产品打磨后,提出了“一体两翼”的产品矩阵。该产品矩阵旨在实现大模型时代数据、算力和模型的一体化,构建大模型时代的基础设施,帮助企业快速构建大模型时代的 AI 应用。
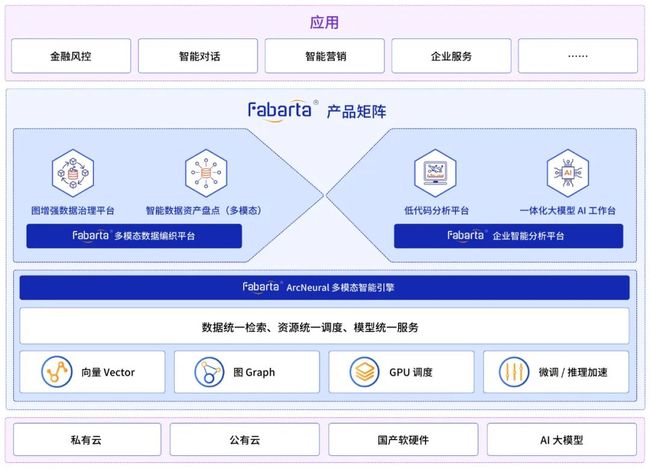
Fabarta “一体两翼”产品矩阵图
“一体”指的是统一构建企业在大模型的基础设施,实现对数据、算力以及模型运行时的管理,从基础层面实现为 AI 就绪的基础设施( Infrastructure Ready for AI),融合了图与向量计算的多模态智能引擎,既可以实现模型推理过程中的长效记忆,也可以优化模型的推理框架,使其具备更好的逻辑推理能力;“两翼”分别指数据和 AI,其中数据侧提供了完善的多模态数据管理功能,有效帮助企业治理并盘点数据资产。这些数据可以存储在“一体”中作为企业的私有数据,为 AI 提供高质量数据,从数据侧实现为 AI 就绪的数据( Data Ready for AI);AI 侧打通了模型工厂能力和企业私有知识融合能力,并采用低代码化方式,帮助企业快速使用大模型,基于微调或者提示模式结合企业私有知识进行 AI 应用的落地(AI Ready for Apps)。
4.2 Fabarta ArcNeural 多模态智能引擎
在 AI 时代已经诞生了多种多模态的数据库,很多传统数据库也可以通过扩展方式支持不同形式的数据存储,但是这些多模态数据库,究其本质依然是实现多种数据的存储和统一访问。在大模型时代,Fabarta 始终思考的是,除了支持多模态数据的存储和统一访问之外,对于大模型的支持,还能做到什么?
-
数据挑战:如何能够帮助企业构建统一的私有多模态数据层,并能够将该私有数据很好的与大模型结合起来?
-
算力挑战:企业若私有化部署大模型,如何在有限的算力情况下,支撑更高的并发?
-
模型挑战:大模型推理能力有限,如何帮助提高大模型的推理能力?企业对于大模型生成式回答有着非常高的确定性需求,如何有效减少大模型有模有样的乱生成问题?如何帮助企业实现可解释的智能?
ArcNeural 是以 Data-Centric AI 为核心构建的用于处理符号化数据图(Graph)和向量(Vector)的智能引擎,将传统数据库的“存储&计算”架构演进为“记忆&推理”架构,为 AI 应用提供私有记忆和精确可解释的推理,ArcNeural 是建立在 AI 三要素数据、算力和模型之上的基础设施,为上层 AI 智能应用提供支撑,加速业务智能化创新的进程。
例如,在知识库智能问答系统中,首先将企业的数据(原始的 Raw data,如 CRM 、ERP 数据、产品手册等)全部导入 ArcNeural,引擎将自动建模并生成符号化数据(Embedding&Graphing)。当用户提问时,ArcNeural 通过可解释的符号计算(图计算)和向量计算等分析问题、寻找相关高价值数据,并提供优化的运行时环境支撑大模型进行内容生成、归纳和总结。这样既保证了回答的准确性、实时性和私密性,又有效避免大模型的“胡说八道”,为用户提供智能友好的服务。同时,灵活可扩展的引擎架构也同时支撑独立的图数据库、图计算和企业级向量数据库的场景应用,灵活应对企业在业务智能化方面对基础设施的需求。
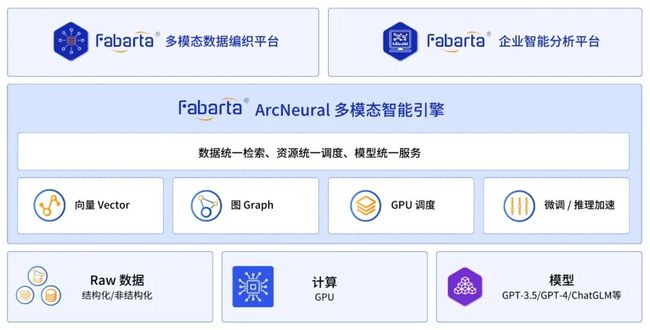
Fabarta ArcNeural 多模态智能引擎架构图
4.3 Fabarta 多模态数据编织平台
大模型技术的应用,需要打通企业海量私有数据,而当前企业数据类型多、数量大,质量杂,如何将“私有数据”梳理为 AI 可用?这对数据管理提出了全新挑战:
-
数据形态升级:从专注于核心经营报表,到全面覆盖原始的 Raw data,如 CRM 数据、ERP 数据、产品手册、规章制度、图片、视频文件等,不只是从结构化数据到非结构化数据的升级,更需要全新的数据连接、抓取的技术方式,也需要更普适的元数据管理方式;
-
治理目标升级:治理的目标,从数据的“DAMA 六性”(Completeness 完整性、Uniqueness 唯一性、Timeliness 时效性、Validity 有效性、Accuracy 精确性、Consistency 一致性),升级为对语义的理解和对隐含关系的提取;
-
数据服务升级:数据治理的服务对象,从 BI 升级为 AI 进而演化为大模型,因此数据服务的形态,也从传统的二维表,升级为适配于大模型生态的知识服务。
Fabarta 多模态数据编织平台,是面向 AI 的数据管理平台,更加智能的连接、理解、治理数据,将企业数据转化为企业知识,为 AI 的应用落地提供数据驱动力,同时也兼容传统的数据治理场景。平台基于 ArcNeural 智能引擎,连接企业私有数据,自动获取并分析其中的元数据和数据语义,形成数据血缘和资产图谱,在此基础上提供智能化数据标准贯标、数据质量分析、指标链路优化、数据分类编目等功能,为业务应用和大模型提供数据服务。其核心模块包含:
-
图增强数据治理:采集并识别包括结构化数据库、文档、图片在内的多模数据的元数据信息,通过数据处理脚本、系统访问日志等原始技术信息解析数据血缘,全方位管控数据标准、数据质量、数据安全,并可兼容对接企业已有数据治理平台;
-
智能数据资产盘点:利用准确的元数据、血缘等信息,对海量企业数据进行筛选和分类,并通过智能化技术的辅助,对数据内容进行理解,提取隐含的数据关系,还原真实的数据模型(Data Model);
-
多模态数据服务:通过指标建模、数据虚拟化、知识服务等技术,同时适配传统 BI、AI 和大模型场景,提供全面的数据服务,也可对接 Fabarta 企业智能服务平台,快速落地 AI 应用。

Fabarta 多模态数据编织平台架构图
Fabarta 多模态数据编织平台作为 Fabarta 产品矩阵中的“数据翼”,充分利用大模型能力,实现智能数据管理,对接企业已有的大数据平台,梳理和治理企业海量多模态数据,构建数据资产地图,并为 AI 大模型落地提供智能数据基础,提供 AI 落地就绪的数据(Data Reay for AI)。
4.4 Fabarta 企业智能分析平台
在过去数十年间,AI 平台的主要用户还是专业的算法工程师和高级开发人员,平台则为其提供完备的 AI 开发工程链路、成熟的算法、高效的训练与推理框架。大模型以其出色的泛化推理能力吸引了各个行业的关注,尤其是如何能让企业中的业务用户、工程人员以较低的门槛就可以结合大模型把沉淀的私有数据给利用起来,直接为业务产生价值。从面向专精尖的 AI 开发者,到面向企业业务用户的大模型能力落地,这其中的转变的挑战则是这个时代的企业智能平台需要面对的:
-
面向大模型时代的数据准备:企业的多模数据如何在 AI 场景下更好的通过切分、再组织,转变为合适大模型的数据存储形态并结合业务场景选择微调或者提示模式,减少大模型的幻觉问题以保障企业级落地;
-
面向大模型时代的模型准备:企业如何在如雨后春笋般的开源、闭源大模型项目中,选择出符合自身业务场景的基础模型作为企业智能底座;
-
面向大模型时代的业务赋能:企业如何帮助业务人员聚焦自身的业务数据,结合大、小模型各自的优势,以拖拉拽的方式直接生成 AI 应用,自助式的完成普惠性的大模型场景的落地。

Fabarta 企业智能分析平台架构图
Fabarta 企业智能分析平台作为 Fabarta 产品矩阵中的“AI 翼”,旨在以低代码无代码(Low-Code No-Code LCNC)的方式帮助企业中的 AI 开发者、业务用户、应用开发者快速落地 AI 能力。其特点如下:
-
大模型落地加速:帮助企业结合自身业务、数据选择最优大模型,支持自有数据与主流大模型进行微调,直接使用大模型与本地知识库构建知识服务;
-
支持大模型应用演进:企业级的 AI 应用更多依赖特定大模型并结合多个小模型的方式渗透到业务的方方面面,平台通过模型工厂、模型编排,全面支持企业级 AI 应用的大模型化;
-
企业智能用户生态全覆盖:通过数据与 AI 开发、业务分析、服务与应用的三层架构加速数据从开发到业务的全流程。帮助数据面向行业、场景产生业务价值;
-
LCNC 分析能力串联:LCNC 应用已不仅仅是前端组件的拖拉拽,更是通过将复杂的业务分析逻辑进行预封装,帮助业务用户更多的聚焦数据与业务本身,通过平台能力直接生产业务应用,全面提高 AI 的普惠性;
-
行业能力的沉淀与复用:帮助企业将自身行业特色的业务知识、技术原子能力进行沉淀,以平台能力支撑其业务场景横向扩展时的复用性,加速行业能力的落地;
-
面向可解释的图智能:利用图数据天然的可解释性,结合图计算算法、决策引擎、分析画布、图 BI、数据探查等能力帮助最终业务用户知其然、知其所以然。

Fabarta 利用其核心产品,已经帮助多个头部企业客户进行智能化转型:
-
利用图和大模型技术赋能的数据血缘链路跟踪技术,帮助某头部城商全面追溯数据血缘并提升数据洞察力,确保基于可靠的数据进行决策; 通过深入分析数据血缘,可以快速定位数据质量问题,实现对数据的探索,为构建数据编织打下坚实的基础;
-
利用企业智能分析平台,结合多模智能引擎中的图技术和图算法,帮助某头部商业银行快速开发贷后风控应用,实现风险管理中的预警配置、风险评价、风险排查、客户视图等功能,降低风险监控成本,做到风险监控的一站式管理;
-
利用融合向量和图的多模智能引擎,帮助某头部制造企业快速对接内部知识库 ,构建智能问答系统,实现大模型对企业数据的赋能,充分挖掘和发挥企业数据的价值。
迈向大模型时代的新范式,Fabarta 通过多模智能引擎管理以向量和图为主的大模型时代符号化数据,提供算力和模型加速支持,作为新时代的 AI 基础设施;同时通过数据编织平台实现对数据的探索、智能盘点和使用,为大模型提供高质量企业数据;利用企业智能分析平台帮助企业快速连接本地数据,利用大模型赋能业务应用。
Fabarta 秉承“数联世界、智见未来”的理念,致力于构建大模型时代的 AI 基础设施,与合作伙伴和客户一起,共创大模型时代的智能企业。
如对我们的产品或技术感兴趣,欢迎通过[email protected]与我们联系。

Fabarta 是一家 AI 基础设施公司,通过探索和联结数据资源,助力企业实现智能驱动的持续创新。目前 Fabarta 的产品体系分为三层:在引擎层,打造面向 AI 的技术基础设施,提供支持图、向量和 AI 推理能力融合的 ArcNeural 多模态智能引擎;在平台层,通过企业智能分析平台加速可解释图智能和新一代 AI 技术在企业场景的落地,同时利用多模态数据编织平台帮助企业梳理多模态的数据资产,让企业充分发挥数据流动带来的价值;此外,Fabarta 可以基于多模态智能引擎、企业智能分析平台和多模态数据编织平台与客户和伙伴一同构建行业应用,加速企业数智化转型和 AI 技术的落地。