python学习第三天 :正则表达式(不是日记向了,是新手+总结向)(30分钟了解正则表达式x_x)
参考文档:https://deerchao.cn/tutorials/regex/regex.htm#grouping
笔者目前大二,上了一年c++,认为学到了许多,便开始坐井观天,如今开始自己学一门语言,才知道编程的路有多漫长...数据结构,计算机原理啥的都还没学过,便开始虚度生命 [唉] ,这是极为悲哀的,希望大家不要像我一样荒度了大一的一年时间吧。现在终于燃起了对一切的好奇,前两天F12打开开发者工具,里面一串代码直接晃瞎我...我真是太浅薄了
今天是python学习的第三天了,那个100天从菜鸟到大师,实在太! 难!了!它提到了正则表达式,然后某个地方还提到了HTTP协议,简单看了看,突然想起自己之前跟着网上教程改网页的时候用到过,所以特地认认真真的写一篇总结
请大家提出建议!我们一起变强大!!!
(废话有点多xx)
一、正则表达式
1.正则表达式是什么
我感觉它更多的像是一个搜索工具。就好似你在小说里搜索“恐怖如斯”这四个字出现的位置,又或者你在电话簿里搜索“12138”这样的电话号码出现情况。你肯定不喜欢搜索到的是“恐怖如斯丝丝”,或者“0121380”,为了更精确,我们就要用正则表达式加以限制。
2.常用的字符总结
首先先解释一下匹配 匹配是什么呢?拿插座来类比吧,你手里拿着一个三角插头,要找的插座必须是三孔的,你才可以插进去。能否插进去 就是匹不匹配的重要区分。而\w,\b就像是一个个插孔,找的字符就是插头,插的正正好好,就是匹配。
\w 可以匹配的是数字,字母,下划线,汉字。(注:只能是一个字符)
\b 可以匹配的是 单词的开始或结束
* 表示的是 前边的内容可以任意次调用。 (这个我看了好久才明白)为了方便理解,不如从符号意义出发,*不就是乘号嘛,(\w*)不就是(\w)乘了一个未知数嘛。所以就表示中间可以有任意个可以和(\w)匹配的字符
. 英文句号 可以匹配的是 除了换行符以外的任意字符
\s 可以匹配任意个空白符
^ 可以匹配字符串的开始
$ 可以匹配字符串的结束
\d 可以匹配数字
+ 前边的内容重复 一次及以上 [1,+∞]
? 前面的内容重复 0次或一次
{n} 前面的内容可以重复n次
{n,} 前面的内容可以重复n次及以上
{n,m} 前面的内容可以重复 n~m次
干巴巴的总结肯定看起来费劲,我们接下来就进入实例分析吧!
3.瞧瞧这些正则表达式的例子
我给你一串字符,你觉得下面的他们会找到什么呢?
hi,Bob,a handsome boy wants to make friends with you,do you want to make friends with him?
1)\bhi
前面我们说到,\b匹配的是单词的开头或结束,更精确的讲,它匹配的是 前一个字符或后一个字符不全是\w,就是说 如果hi在这样的位置 ohia,它不会去找的,因为它前后是有字符的,不符合\b的寻找要求。
所以它会找到什么呢?它会找到hi,him ,虽然从开头开始找,但结尾无法预估,如图
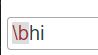

(变色的框就是它找到的位置)
2) \bhi\b
这个有了严格的限制,就是正正好好的一个完整单词hi,实际运行的时候是否是这样的呢?
![]()

(符合我们的猜想!!)
3) .*
.是什么,除了换行符以外它可以匹配任意字符,而*的存在,让它可以匹配任意个字符!如果它出现在搜索框中会出现什么?全部都会在搜索范围里!


4) \bhi\b.*\bBob\b
这个表示什么呢?我们来猜猜...它要求 先找到hi这个单词,然后中间掠过除了换行以外的任意个字符,然后直到找到Bob这个单词为止,结果是否如我们想象的那样呢?


猜对了!
5) 0\d\d-\d\d\d\d\d\d\d
为了这个例子,我们再来最后一组数据,相信这组结束,剩下的我们靠脑瓜就可以想象出来
:“010-123456789012-98765321”
它会找到几处部分?在这里的0表示什么?
![]()
![]()
这是它找到的,0就是字符零。(好像印证了我开篇的猜测,这玩意就是个搜索工具,我们就是在不断的添加限制条件来找到我们的目标结果而已)
6) 0\d{2}-\d{8}
在上文的基础上,我们加了一点点小变化,那就是多了个{2}{7},这个表示的是重复,这对我们来说有问题吗?没有问题
我们都能猜到运行后搜到的东西了
没有猜错,和上面一样
7) \ba\w*\b
这个我们开始猜想,\bxxxx\b,很明显这是在找一个单词,\b后第一个字符是a,证明在找a开头的(\w*)个字符的单词,再解读一下就是,找a开头的所有英文单词。(好简单的样子)
聪明的你不妨想想,如果找a red apple 它会找到什么呢?包不包括单词a呢?
8) \d+
\d+,\d搜的是数字,\d+搜的是一个及以上的数字
9) ^\d{5,12}$
^表示字符串开头,$表示字符串结尾,{5,12}表示5~12次,所以这玩意找的是 整个输入是5-12位的数字
10) \\ \. \*
如果我们要找这句话出现了多少个英语句号,多少个斜杠,多少个*号怎么办?这相当于插了一个知识点,没猜出来在所难免(xx。\\找的就是\,\.找的就是英文句号,\*找的就是*
4.进一步的正则表达式学习
| 这个符号的意思是 或 比如 1|2 就是1或2
() 小括号就是分了组了 (123)这就是一个组 (123){3}表示这个组重复三次
[.?!] 这玩意表示 三个里面挑一个出来 [0-9]等同于\d
5.瞧瞧更进一步的例子
1) 0\d{2}-\d{8}|0\d{3}-\d{7}
我们开始解读 0后面两个数字 - 八个数字 或者 0后三个数字 - 七个数字
形如 012-12345678 0123-4567890
over!
2) \(?0\d{2}[) -]?\d{8}
可能有括号 0后两个数字 可能有右括号或-其中的一个 然后8个数字
形如 012-12345678 (012-12345678) 012)12345678
3) \(0\d{2}\)[- ]?\d{8}|0\d{2}[- ]?\d{8}
括号 0后两个数字 右括号 可能有-。8个数字 或者0后两个数字 可能有- 8个数字
形如 (012)12345678 或者 (012)-12345678
4) \d{5}-\d{4}|\d{5} \d{5}|\d{5}-\d{4}
这里为什么又会出现这个呢?是为了让大家意识到一个知识 :短路
左边这个对应的是 9位数字或5位数字,右边这个只是调换了顺序,但搜索结果截然不同
还是直接上图吧
![]()
![]()
![]()
![]()
看,右边这个找到5位数字后,就不会再尝试|后面的内容了,换而言之,被短路了 (划重点)
5) (\d{1,3}\.){3}\d{1,3}
这玩意就像是找一个ip地址,不介绍啦,大家想来应该可以分析出来啦!
6再进一步的学习
这些感觉不是很必要介绍了,我就简单说说自己的理解吧
如果想了解,不妨移步到https://deerchao.cn/tutorials/regex/regex.htm#grouping
这里面有最详细的解释
后向引用
就是\b(\w+)\b\s+\1\b 这样子的,第一个组就是\1,相当于缩写吧,\1就是(\w+)(至少我是这么理解的,不知道是不是过于简单了
组名也可以自己取 (?
零宽断言
你走到一个房间,打开之前,你就说:我断定,里面有隔壁老王!(顽梗)断言差不多就是这样吧?这只是我的浅薄分析,你断定这后面有这玩意,然后输出这后面的前面的这玩意,有点拗口,\b\w+(?=ing\b)这玩意就是说后面有ing,输出ing前面的,\b(?<=ing\w+\b)断定前面有ing,输出ing后面的。就是个这
负向零宽断言
这个我真不知道咋讲通俗易懂。(?<=<(\w+)>).*(?=<\/\1>)直接看这个例子吧,他要找的是之间的内容,不包括前缀后缀本身。想了解直接看那个链接里的介绍吧(唉)
注释
(?#注释)就行。
贪婪与懒惰
a.*b 匹配最长的a.....b字符串,a.*?b匹配最短的a.......b字符串。就这