容迟网络的路由算法学习笔记(五)
基于启发式的路由算法
研究意义
在不同的应用场景中, 节点间的相互联系不同,节点移动模式和运动特性不同,节点所能收集到的信息也各不相同。针对不同的应用场景,设计方法不尽相同。如对于节点稀疏部署的传感 器网络场景,采用零知识依赖的路由算法。对于节点有社会属性的移动社会网络场景,基于社会网络分析的方法设计路由算法。随着基于可控洪泛的路由技术逐渐成熟,研究者提出基于启发式的路由算法,利用历史信息,设计针对不同优化指标或不同场景的路由策略。
启发法(heuristics)是指依据有限的知识(或“不完整的信息”)在可接受的花费下(如计算时间)找到问题解决可行方案的一种技术,它依据关于系统的有限认知和假说得到关于此系统的结论。其特点是在解决问题时,利用过去的经验,选择已经行之有效的方法。启发式算法处理许多实际问题时通常可以在合理时间内得到不错的答案。但由于这种方法具有尝试错误的特点,所以也有失败的可能性。
基于跳数的启发式策略
信息收集
用跳数当指标来做出路由决策。让每个数据包携带经过的节点的信息。当数据包到达一个节点时,该节点将从这一数据包中获得跳数信息。利用滑动窗口,可以计算每对节点之间历史的平均跳数。矩阵用来记录所有节点的平均跳数信息,在路由过程中每个节点都维护这样一个矩阵。

先得到源节点的数据包Mk的ID,再将经过的所有节点陆续存放到数组序列中。第一个循环负责将跳数信息存放到对应的当前时刻t的滑动窗口中,第二个循环通过求滑动窗口中所有记录的平均值来计算矩阵A的元素的值。矩阵A中的每个元素反应最近一段时间内一对节点间的平均跳数。
启发式函数

hop(k)表示数据包Mk所经过的跳数,h(i,d)是当前节点 i 和消息Mk的目的节点d之间启发式跳数的值。
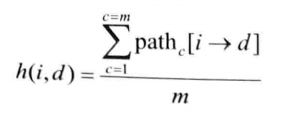
显示启发式函数h(i,d),其中path[i⟶d]表示节点i和d之间路径的估测跳数,m是节点i和d之间路径的总数。因此h(i,d)实际代表节点i和d之间所有路径的评估跳数的平均值。我们用这个值作为路由的启发式指标。

初始化了三个重要的变量h、c和M,这三个变量递归的更新内循环的每次遍历。C用来累加每次遍历路径的总数,M初始化为⋀并在循环过程的每次遍历乘以A。分别获得当前节点和目的 节点的ID。内循环直到矩阵mi,d的元素为0时结束。
路由过程


首先获得当前节点v的邻居集合,对于当前节点v和它的邻居节点u,有H(v,k),H(u,k) > hop(s,d)启发式跳数大于节点s和d之间的平均跳数, 这表示在平均跳数范围内节点v和u很难将消息传递到目的节点,因此触发多副本策略。如果H(u,k)
基于节点相似性的容迟网络路由算法
动机和出发点
Prophet算法利用节点间相遇的历史信息和传递性来选择下一条节点。虽然提高了网络的消息投递率,但由于网络中目的节点的位置未知,当节点缓存大小受限时,Prophet的传递率会变小。尤其当一个节点A的投递预测值P较低时,只要遇到比A高的节点时就复制消息,所以在洪泛的同时会导致大量消息副本的产生,增加了网络的负载。
为了进一步提高Prophet算法的网络性能,我们提出了基于节点相似性的容迟网络路由算法(a routing algorithm based on node similarity, RABNS)。利用历史信息,RABNS算法比较两个节点接触过的节点,从而了解两个节点运动范围的重合部分,并以此为指标定义节点相似性。若两节点运动范围和接触节点雷同度高, 则只需在这对节点中保留一份消息,进一步控制副本数量。
基于节点相似性容迟网络路由算法RABNS
(1)概率预测筛选节点:投递预测值的计算包含三部分:更新、衰退、传递性
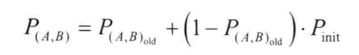
当两个节点相遇时,就根据式子更新到该节点的预测值。P(A,B)值越大表示两个节点相遇的概率越高。
![]()
如果在一段时间内一对节点没有彼此遇到,则表示它们不太可能会传递消息给对方,因此在这个过程中投递预测值按式子所示衰减,其中 为衰退参数,k表示从最后一次相遇到现在所经历的时间块的个数。
为衰退参数,k表示从最后一次相遇到现在所经历的时间块的个数。
![]()
投递预测值也具有传递性,假设节点A与节点B频繁相遇,同时节点B与节点C也相遇频繁,显而易见,节点A与节点C成功传递消息的概率也会较大,其中[0,1]是度量参数,该参数的值由传递性的比重决定。
(2)网络模型和变量定义:
相遇节点集合,其中表示节点 和
和 的相遇次数。记录从节点工作开始到现在的时间中与该节点接触的所有节点,值越大,则说明节点接触的节点越多,越活跃。
的相遇次数。记录从节点工作开始到现在的时间中与该节点接触的所有节点,值越大,则说明节点接触的节点越多,越活跃。
节点相似度。当两个节点和相遇,交换变量和 ,计算两个集合交集的权值。
,计算两个集合交集的权值。
(3) RABNS路由算法

当源节点或中继节点 携带着以
携带着以 为目的节点的消息
为目的节点的消息 与节点相遇时,首先彼此交换信息、和、,并利用集合信息计算节点相似度 S(a,b)。若到达目的节点的成功投递率不小于,代表节点遇到目的节点的可能性更高,则将消息传递给 ,增加消息成功传输的概率。
与节点相遇时,首先彼此交换信息、和、,并利用集合信息计算节点相似度 S(a,b)。若到达目的节点的成功投递率不小于,代表节点遇到目的节点的可能性更高,则将消息传递给 ,增加消息成功传输的概率。
然后比较节点相似度S(a,b)与门限参数α的值,若S(a,b)不小于α,则表示节点与节点的活动范围和接触环境大致相同,为了减小负载、提高网络资源利用率,那么将消息从携带节点的内存空间中删除。
基于统计分析和临时聚群的容迟网络路由算法
动机和出发点
消息副本数量越多意味着资源消耗越大,消息冗余越严重。有效的路由策略的关键问题是选择较少但较优的邻居作为下一跳的中继节点来扩散消息,从而实现可控的感染机制和高消息投递率与低资源消耗之间的良好平衡。
通过每对节点接触时间捕获的历史信息有很高的使用价值。两种方法来判断一个节点是否可以成为下一跳的中继节点。(1)如果在当前临时聚群中有一条到达目的节点的临时路径,那么存在于这条路径上的所有节点都是最理想的中继节点。这是因为这些节点可以快速并成功地完成这次消息传递。(2)如果不存在到达目的节点的临时路径,通过收集大量的相遇历史信息作为样本,我们用统计分析的方法计算不同的数据来客观准确的评估每个相遇的节点,然后选择有助于提高路由性能的邻居节点作为 下一跳的中继节点。
SATC路由结构
提出两种路由策略来准确评估每个相遇的节点,从而通过选择较少且较优的中继节点来扩散消息,很大程度上控制消息的冗余。
(1)基于临时聚群的路由策略
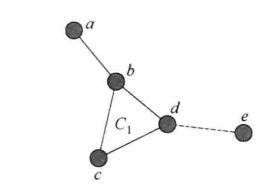
节点a只知道它的一跳邻居节点b,所以节点a可能没有分辨出节点b是一个很好的中继节点,最终错过成功传送消息的机会。
所以临时聚群的建立能够提高搜索最终目的节点的范围, 而不是只搜索当前节点的一跳邻居节点。为了找出所有的聚群成员,当前节点s需要广播一个本地路由探测包(local route discovery packet, LRDP)到临时聚群。一个LRDP探测包包括 以下信息:source_id;broadcast_id(广播地址);Hag;hop_count(路径长度);path;time_to_live(TTL即生存时间)。
群聚成员LRDP包的广播过程:当节点需要传递多个消息却不存在到目的节点的路径时,将开启路由发现程序。节点创建一个新的LRDP包并将这个LRDP包广播到它所有的一跳邻居节点。当邻居节点接收到LRDP包时,它首先增加hop_count的值并将自身节点加入到路径中, 然后需要将这个LRDP包再广播到该节点的一跳邻居节点。该邻居节点在将flag置为1后,沿着反向路径单播传送LRDP包到源节点。(收到来自不同邻居节点的相同LRDP包的不同副本的聚群节点仍然要将LRDP包重新广播给它的一跳邻居节点。)最终当接收到来自聚群成员的所有应答包时,源节点能构造一个临时的路由表。
若有多条路径,则选择最短路径来构建路由。通过标路径容量和跳数来选择。
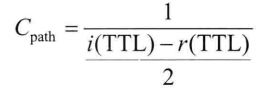 i(TTL)表示当源节点接收到应答包时分配给一个新LRDP的初始生存周期。r(TTL)表示LRDP剩余的生存周期,时间越少表示路径容量越高。如果所有路径的跳数都大于,那么我们选择路径容量最好的路径当作最短路径, 否则我们选择跳数最少的路径为最短路径。
i(TTL)表示当源节点接收到应答包时分配给一个新LRDP的初始生存周期。r(TTL)表示LRDP剩余的生存周期,时间越少表示路径容量越高。如果所有路径的跳数都大于,那么我们选择路径容量最好的路径当作最短路径, 否则我们选择跳数最少的路径为最短路径。
最终,源节点S会获得到所有聚群成员的路径。如果一个消息的目的地是某个已发现聚群成员,那么节点S会将相关的路由表项编码到这个消息中并沿着 路由表项中的路径将消息转发到相关的下一跳节点。
基于统计分析的路由策略:收集在最近几个周期的时间单元内两个节点之间的相遇次数信息,用统计分析的方法来计算几个用来评估每个相遇的节点的指标。DTN节点需要维护一个NxM的动态矩阵记录与其他N个节点的相遇历史信息。M等于L*P,其中P表示周期的数量,每个周期分为L个不同的时间单元。记录节点i和节点j在第k个时间单元内相遇的次数。

(1)平均数(AVG)
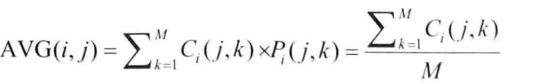 AVG是所有能客观反映集中趋势的样本的平均值,所以AVG (i,d)可以准确地描述出节点i与目的节点d相遇频率的级别。AVG值较大的邻居在不久的时间单元内与目的节点相遇的可能性通常比当前节点大。
AVG是所有能客观反映集中趋势的样本的平均值,所以AVG (i,d)可以准确地描述出节点i与目的节点d相遇频率的级别。AVG值较大的邻居在不久的时间单元内与目的节点相遇的可能性通常比当前节点大。
(2)平均周期(CAVG)
用来计算两个节点之间在不同活动周期的相同时间单元内的平均相遇次数。
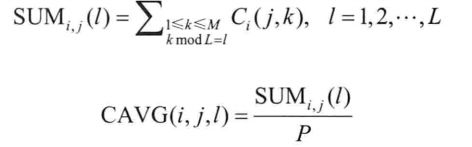 sum计算了在P个不同活动周期的每第l个时间单元节点i和节点j相遇次数的总和。CAVG值大的邻居节点在当前周期内的第l个时间单元比当前节点更有可能与目的节点再次相遇。
sum计算了在P个不同活动周期的每第l个时间单元节点i和节点j相遇次数的总和。CAVG值大的邻居节点在当前周期内的第l个时间单元比当前节点更有可能与目的节点再次相遇。
(3)众数(MODE)
MODE(i,d)表示节点i和节点d之间所有相遇次数的众数。MODE值大的邻居节点比当前节点更有可能与目的节点再次相遇。
(4)方差(VAR)
用来描述数据的稳定性,VAR值小表明样本更能准确地反映整体水平。
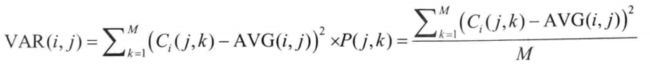
根据以上统计方法,可以客观评估一个邻居是否可以被选作下一跳的中继节点。 对于当前节点s、邻居节点j和目的节点d,首先考虑AVG。利用式(5.13)计算的效用值。当表明在AVG方面邻居j比当前节点s有明显优势,那么节点j将被选作下一跳的中继节点。其次考虑CAVG和MODE。假设当前是第l个时间单元,U2(j,d,l)>U2(s,d,l)时表明节点j在当前时间单元内更有可能与目的节点相遇,所以邻居j也被选作为下一跳的中继节点。同时节点不会复制所有的消息到所有被选中的邻居,VAR值越小,优先级越高。

缓存管理
 左侧部分优先级较高,消息首先从这里传递。右侧部分优先级较低,当缓冲区溢出时首先从这里删除消息。消息都按照FIFO (first in first out)的顺序分类。
左侧部分优先级较高,消息首先从这里传递。右侧部分优先级较低,当缓冲区溢出时首先从这里删除消息。消息都按照FIFO (first in first out)的顺序分类。
SATC算法

算法1〜13行是消息存储到左侧缓冲区的处理过程,其中2〜3行广播LRDP,而5〜7行是根据消息存储的相关路由表项,Ni将消息转发给相关的下一跳节点。在算法9〜10行,如果相应的下一跳节点不在Ni的一跳邻居节点的范围内,表明由于节点的移动当前路径已经被破坏。然后Ni将当前路由表项从消息中删除并将消息移到右侧的缓冲区。算法14〜22行是消息存储到右侧缓冲区的处理过程,其中14〜15行重构一张新的路由表,16〜21行通过当前路由表寻找可以到达目的节点的消息。然后Ni将相关的路由表项编码到相应的消息中并沿着路径将消息转发到下一跳节点。最后22行选择少量但较优的邻居来扩散剩余的消息。
基于效用的对时间敏感的机会主义容迟网络路由(TOUR)
动机:
基于效用的路由是一种基于所谓的实用复合度量的特殊的路由方法。每个正在传递的消息被分配一个固定的效益作为传输奖励。效用就是效益减去传递消息需要的总传输成本。目的是让每条消息在高度动态的网络中传输 时的效用最大化。每条消息都有一个随时间变化的效益,并随着时间线性衰减,衰减率被称为效益衰减系数。效用是时变的效益减去消息的传输成本。随着消息的传递,由于时延和成本持续增加,效用将逐渐减少,当效用变为0时消息将被丢弃。
提出的对时间敏感的效用模型通过最大化效用值,可以让具有不同效益和效益衰减系数的消息沿着不同的路径传递。
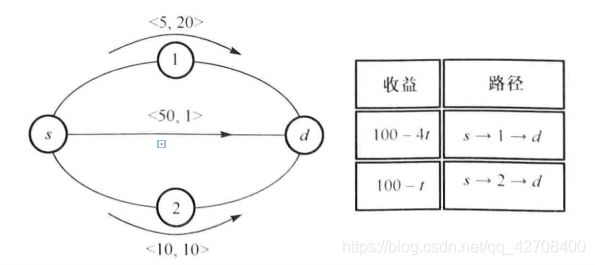
路由模型:
每条消息包含一个效益(benefit),记为b(t),表示将消息传送到目的节点的酬劳。最大效益初始化为b,随着时间的流逝,效益呈直线下降。重要级越高的消息初始效益越大。 为效益衰减系数。
为效益衰减系数。

效用(utility)定义为效益减去传输成本,用u(t)表示,c表示到时间t转发消息所产生的总成本。
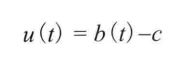
节点i的抵达效用用ui表示,节点i的效用差用Di(u)表示。Di(u)=E[u-ud]表示效用为u的消息从节点i到节点d而减少的平均效用值。TOUR的目的是使目的节点的期望效用E[ud]最大化。即每个节点i的效用差Di(u)最小化。

TOUR基本策略:
(1)对时间敏感的机会主义转发
每个节点i维护一个时变的转发集合。时间敏感的机会主义转发策略就是每个节点首先确定其最佳转发集合(是能使节点i取得最小效用差的转发集合),然后将消息转发给在它转发集合中遇到的任何节点。
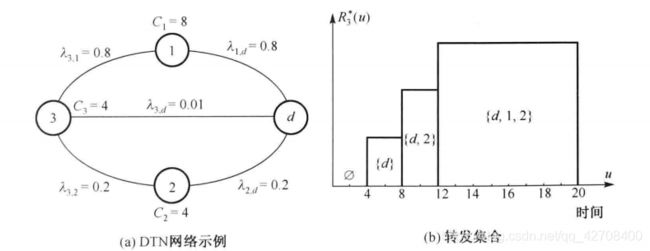
节点3的最佳转发策略包括当u>12时, 可以将消息转发给集合{d,1,2}中的节点,当8
(2)确定单一节点的最佳转发集合
公式计算对于任意转发集合R(u)(0≤u≤μ)节点i的效用差值,即Di(u)|R(u)。假设节点i转发消息的效用为μ,分别考虑转发成功和转发失败的情况。当效用变为u(c≤u≤μ)时,如果节点i遇到节点j∈R(u),那么节点i把消息转发给节点j。对应的效用差值是节点i转发消息到节点j减少的效用值与节点j的抵达效用uj的总和,即μ-ui+D(uj)。如果节点i不能遇到R(u)中的任何节点,消息将会被丢弃,因此对应的效用差为μ。
![]()
(会导致集合以指数增长的负载)搜寻所有可能的集合 R(μ) Ni,计算相应的Di(u)|R(u),找到使Di(u)最小的最佳的R(μ),因此确定节点i的R*i(μ)。
Ni,计算相应的Di(u)|R(u),找到使Di(u)最小的最佳的R(μ),因此确定节点i的R*i(μ)。
贪心算法:对每个给定的效用μ,节点i比较每个邻近节点j的效用差值Di(μ-ci),按照效用差的升序排列这些邻近节点,并将这些有序的邻近节点一个接一个的添加到转发集合R(μ)中,同时计算Di(μ)的值。在扩充集合R(μ)的过程中,Di(μ)的值会先降后升,第一个拐点正是最小值,然后停止扩充过程,可以推断出当前转发集合R(μ)是最佳的。
(3)确定所有节点的最佳转发集合
递归执行以上的计算过程,能够确定所有节点的最佳转发集合。
容迟网络中的最佳机会主义路由算法(Leapfrog)
DTN主要关心的问题是如何路由消息,使端到端的传输时延尽可能低。 可以研究单副本消息路由问题,并提出最佳机会主义的路由策略 -Leapfrog路由,应用于节点以某个固定频率相遇接触的DTN网络中。推导出迭代计算公式,使每个节点到目的节点的期望传递时延最小化。在最佳路由策略中,以蛙跳(Leapfrog)形式使消息从高延迟节点传递到低延迟节点。
动机:
机会主义路由策略本质上是动态路由策略,根据网络实际连接状态选择中继节点。在机会主义路由策略中,尽管低传输延迟的节点被遇到的可能性低,但选择低传输延迟的节点能够降低传输时延。
问题形式化:
如何确定最佳路由策略,使得节点s以最低期望时延传输消息到节点。
Ci描述节点s实时的接触状态,向量元素Ci,j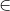 {0,1}表示节点i做路由决策的时间段内节点i与节点j是否发生接触,值为1表示接触发生,值为0表示接触没有发生。
{0,1}表示节点i做路由决策的时间段内节点i与节点j是否发生接触,值为1表示接触发生,值为0表示接触没有发生。


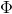 表示一系列路由选择函数中的一个具体策略,Ri是节点i的中继节点集合。
表示一系列路由选择函数中的一个具体策略,Ri是节点i的中继节点集合。 表示节点r被选为下一跳中继节点的概率。
表示节点r被选为下一跳中继节点的概率。
最佳机会主义路由:
对每个节点s需要确定它的最佳路由决策函数。并计算最小期望传输时延。用两步解决这个问题,第一步确定单个节点s的最佳路由决策函数,即假设已提前知道最小期望传输时延,然后基于此确定最佳路由决策函数;第二步,反复第一步确定所有节点的最佳路由决策函数。
(1)单个节点的最佳路由决策函数
当节点s的中继集合Rs给定时,先找出最佳路由决策函数并计算相应的最小期望传输时延。
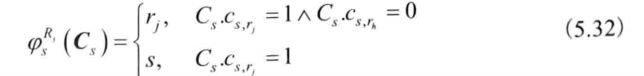
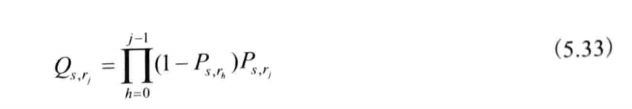

找出最佳中继集合Rs减小期望传输时延,来确定最佳路由决策函数。
(2)所有节点的最佳路由决策函数
反向迪杰斯特拉函数。