第2章python编程基础
目录
目录
2.1Python语言基本语法
2.1.1基础数据类型
2.1.2变量和赋值
2.1.3运算符和表达式
2.1.4字符串
2.1.5流程控制
2.2内置数据类型
2.2.1列表
2.2.2元组
2.2.3字典
2.2.4集合
2.3函数
2.3.1函数的定义
2.3.2lambda函数
2.4文件操作
2.4.1文件处理过程
2.4.2数据的读取方法
2.4.3读取CSV文件
2.4.4文件写入与关闭
2.5本章小结
2.6本章习题
2.7本章实训
2.1Python语言基本语法
python最具特色的就是使用缩进来表示代码块,不需要使用大括号{ }。缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数。
【例2-1】python程序实例。

2.1.1基础数据类型
python3中有六种标准的数据类型:Number(数字)、String(字符串)、List(列表)、Tuple(元组)、Set(集合)、Dictionary(字典)。可变、不可变
python3支持的数据类型有int(整数)、float(浮点数)、bool(布尔数)、complex(复数)四种
只有int类型,表示为长整型,没有大小限制;
float就是通常说的小数,可以用科学计数法来表示;
bool型有True和False两个取值,分别对应的值为1和0并且可以和数字相加;
complex由实部和虚部两部分组成,用a+bj或complex(a,b)表示,实数部分a和虚数部分b都是浮点型。
2.1.2变量和赋值
python中的变量是不需要声明数据类型的,变量的“类型”是指的内存中被赋值对象的类型,例如:
brower='Google' #字符串类型
count=100 #整数类型
addsum=123.45 #浮点数类型
z=2+3j #复数类型
同一变量可以反复赋值,而且可以是不同类型,这也是Python语言被称为动态语言的原因,例如:
brower='Google' #字符串类型
brower=100 #整数类型
brower=123.45 #浮点数类型
brower=2+3j #复数类型
并且,python也允许同时为多个变量赋值。
【例2-2】多变量赋值实例

2.1.3运算符和表达式
python语言支持算术运算符、关系运算符、逻辑运算符
| 运算符 | 运算符 |
| + ,—,*,/, % , // ,** | 算术运算符:加、减、乘、除、取模、整除、幂 |
| <,<=,>,>=,!=,== | 关系运算符 |
| and,or,not | 逻辑运算符 |
优先顺序:逻辑运算符<关系运算符<算术运算符
| 运算符 | 说明 | 范例 | 结果 |
| — | 求反 | —5 | —5 |
| * | 乘法 | 8.5*3.5 | 29.75 |
| / | 除法 | 11/3 | 3 |
| % | 取余数 | 8.5%3.5 | 1.5 |
| + | 加法 | 11+3 | 14 |
| — | 减法 | 5-19 | —14 |
| ** | 乘方(幂) | 2**5 | 32 |
2.1.4字符串
字符串被定义为引号之间的字符集合,在python中字符串用单引号(')、双引号('')、三引号(''')括起来,且必须配对使用。
| 转义字符 | 说明 |
| \n | 换行 |
| \\ | 反斜杠 |
| \'' | 双引号 |
| \t | 制表符 |
python允许用r+" "的方式表示" "内部的字符串,默认不转义。
【例2-3】转义字符的使用。

1.字符串的运算
字符串子串可以用分离操作符([ ]或者[:])选取,python特有的索引规则为:第一个字符的索引是0,后续字符索引依次递增,或者从右向左编号,最后一个字符的索引号为-1,前面的字符依次减1.表2-4给出了字符串的常用运算。
| 运算符 | 说明 | 范例 | 结果 |
| + | 连接操作 | str1='Python' str2=',program!' str1+str2 |
'Python,program!' |
| * | 重复操作 | str='Python’ str*2 |
'PythonPython' |
| [ ] | 索引 | str='Python' str[2] str2[-1] |
't' 'n' |
| [:] | 切片 | str='Python' str[2:5] str[-4:-1] |
'tho' 'tho' |
注:如果*后面的数字是0,就会产生一个空字符串。例如 'Python' * 0 的运算结果是' '。
2.字符串常见方法属性
| 方法/函数 | 作用 |
| str.capitalize() | 返回字符串的副本,其首字符大写,其余字符小写 |
| str.count(sub[ ,start[ ,end]]) | 返回[start,end]内sub的非重叠出现次数,start和end可选 |
| str.endswith(sub[ ,start[ ,end]]) | 返回布尔值,表示字符串是否以指定的sub结束,同类方法为str.startswith() |
| str.find(sub[ ,start[ ,end]]) | 返回字符串中首次出现子串sub的索引位置,start和end可选,若未找到sub,返回-1,类似方法为str.index() |
| str.split(sep=None) | 使用sep作为分隔符拆分字符串,返回字符串中单词的列表,分割空字符串 |
| str.strip([chars]) | 删除字符串前端和尾部chars指定的字符集,如果省略或None,则删除空白字符 |
| str.upper()/str.lower() | 将字符串中所有字符转换为大小/小写 |
2.1.5流程控制
1条件语句
分支结构又称为选择结构,根据判断条件,程序选择执行特定的代码。在Python语句中,条件语句使用关键字if、elif、else来表示,基本语法格式如下:
if condition:
if-block
[elif condition:
elif-block
else:
else-block]
【例2-4】判断一个学生的考试成绩是否及格:如果成绩大于或等于60分,则打印“及格”,否则输出“不及格”。

注意:一个语句最多只能拥有有个else子句,且else子句必须是整条语句的最后一个字句,else没有条件。
【例2-5】将化学分子式翻译为其所表示物质对应的英文。

2.循环语句
循环语句是指满足一定的条件的情况下,重复执行特定代码块的一种编码结构。Python中,常见的循环语句是while循环和for循环。
(1)while循环语法格式
while condition:
while-block
【例2-6】求1+2+3+4+5的值。

注意print的缩进位置否则容易出错

while循环嵌套:语句块中的语句也可以是另一个while语句。
【例2-7】输出20以内能被3整除的数。

end=“ ”表示输出的结果以空格分隔
(2)for循环语法格式
for v in Seq:
for_block
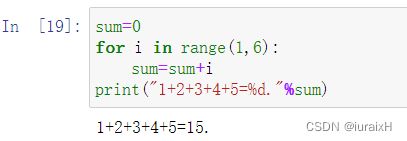
【例2-8】求1+2+3+4+5的值
【例2-9】将下面的数组中的奇数变成它的平方,偶数保持不变。

2.2内置数据类型
2.2.1列表
列表是可变的
1.列表的常用方法
(1)L.appnd(v):把元素V添加到列表L的结尾,相当于a[len(a)]=v
【例2-10】在列表中追加元素

(2)L.insert(i,v):将值V插入列表L的索引i处。
【例2-11】在列表中插入元素。

(3)L.index(x):返回列表中第一个值为X的元素的索引。
【例2-12】返回第一个指定值的索引。

(4)L.remove(v)从列表L中移除第一次找到的值v
【例2-13】删除列表中第一次找到的数值。

(5)L.pop([i]):从列表的指定位置删除元素,并将其返回。如果没有指定索引,L.pop()返回最后一个元素。
【例2-14】删除列表中的指定元素。

(6)L.reverse():倒排列表中的元素。
【例2-15】列表元素倒排。

(7)L.count(x):返回x在列表中出现的次数。
【例2-16】返回列表中指定数组的出现次数。

注意list的大小写
(8)L.sort(Key=None,reverse=False):对链表中的元素进行适当的排序。reverse=True为降序,reverse=False为升序(默认)。
【例2-17】列表元素排序。

2.列表推导式
列表推导式提供了从序列创建列表的简单途径。通常应用程序将一些操作应用于某个推导序列的每个元素,用其获得的结果作为生成新列表的元素,或者根据确定的判定条件创建序列。
语法格式为:
[
语义:
returnList=[]
for k in L:
if
returnList.append(
return returnList;
【例2-18】列表推导式实例。

注意X * Y之间要用空格隔开
【例2-19】随机生成30个整数构成列表,并计算列表均值,然后使用列表中每个元素逐个减去均值所得的数值重新构建列表。

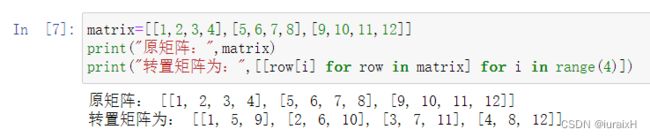
【例2-20】计算矩阵的转置矩阵。
2.2.2元组
元组是一种固定长度,不可变(即不能给元组的一个独立的元素赋值)序列。用途:坐标(x,y),数据库中的员工记录等。
元组和字符串一样,不可改变,即不能给元素的一个独立的元素赋值。
元组和列表的不同之处在于元组的元素圆括号(),而列表用的是方括号[ ]。
【例2-21】元组的创建。

2.2.3字典
字典也称映射,是一个由键/值对组成的非排序可变结合体。键/值对在字典中以如下方式标记。
dict={key1:value1,key2,value2}
| 方法 | 描述 |
| dict.get(key,default=None) | 返回指定键的值,若值不在字典中则返回default |
| dict.iitems( ) | 以列表返回可遍历的(键/值)元组数组 |
| dict.keys( ) | 以列表返回一个字典中所有的键 |
| dict.values( ) | 以列表返回字典中的所有值 |
【例2-22】字典应用实例。

2.2.4集合
集合是一个由唯一元素组成的非排序集合体(集合中的元素没有特定顺序且不重复)。使用set( )
创建的是空集合,使用{ }创建的是空字典
【例2-23】集合用法示例。

2.3函数
2.3.1函数的定义
函数定义的语法格式如下所示:
def function_name(arguments):
function_block
关于函数定义的说明:
(1)函数代码块以def关键字开头,后接函数标识符名称和圆括号( )。
(2)function_name是用户自定义的函数名称。
(3)arguements是零个或多个参数,且任何传入参数必须放入圆括号内。
(4)最后必须跟一个冒号(:),函数体从冒号开始开始,并且缩进。
(5)function_block是实现函数功能的语句块。
【例2-24】编写函数计算n!

2.3.2lambda函数
Python使用lambda来创建匿名函数,准确地说,lambda只是一个表达式,函数体比def定义的函数简单得多,在lambda表达式中只能封装有限的逻辑。除此之外,lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间中的参数。
【例2-25】假如要编写函数实现计算多项式1+2x+y²+zy的值,可以简单地定义一个lambda函数来完成这个功能。

2.4文件操作
2.4.1文件处理过程
一般的文件处理过程为:
(1)打开文件:open()函数。
(2)读取/写入文件:read( )、readline( )、readlines( )、write( )等。
(3)对读取到的数据进行处理。
(4)关闭文件:close( )。
对文件操作之前需要用open( )函数打开文件,打开之后将返回一个文件对象(file对象),open函数的语法格式如下:
file_object=open(file_name[,access_mode="r",buffering=-1])
其中,file_object为打开文件的对象;file_name是包含要打开的文件名路径(绝对路径,或是相对路径)的字符串,包含路径名及扩展名。
2.4.2数据的读取方法
| 方法 | 描述 |
| read([size]) | 读取文件所有内容,返回字符串类型,参数size表示读取的数量,以byte为单位,可以省略。 |
| readline([size]) | 读取文件一行的内容,以字符串形式返回,若定义了size,则读出一行的一部分 |
| readlines([size]) | 读取所有行到列表里面[line1,line2,...,linen](文件每一行是list的一个成员),参数size表示读取内容的总长 |
【例2-26】读取txt文件。
所读取的txt文件内容如下所示。

file=open("泰戈尔的诗.txt",mode='r')
content=file.read()
print(content)
file.close()【例2-27】读取txt文件时指定读取数量。
f=open("泰戈尔的诗.txt",mode='r')
content=f.read(10) #设置读取内容的长度size
print(content)
f.close()
print(type(content))【例2-28】按行读取txt文件
f=open("泰戈尔的诗.txt",mode='r')
content=f.readlines()
print(content)
f.close()2.4.3读取CSV文件
CSV文件也称为字符分割值文件,因为分隔符除了逗号,还可以是制表符。CSV是一种常用的文本格式,用以存储表格数据,包括数字或者字符。CSV文件具有如下特点:
(1)纯文本,使用某个字符集,例如ASCII、Unicode或GB2312。
(2)以行为单位读取数据,每行一条记录。
(3)每条记录被分隔符分隔为字段。
(4)每条记录都有同样的字段序列。
python内置了csv模块,import csv之后就可以读取CSV文件了。
【例2-29】读取CSV文件。
import csv
with open("student.csv","r")as f:
reader=csv.reader(f)
rows=[row for row in reader]
for item in rows:
print(item)2.4.4文件写入与关闭
1.文件的写入
write( ) 函数用于向文件中写入指定字符串,同时需要将open( )函数中文件打开的参数设置为mode=w。其中,write( )是逐次写入,writelines( )可将一个列表中的所有数据一次性写入文件。如果有换行需要,则需要在每一条数据后增加换行符,同时用“字符串.join()”的方法将每个变量数据联合成一个字符串,并增加间隔符“\t”。此外,对于写入CSV文件的write( )方法,可以调用writerow( )函数将列表中的每个元素逐行写入文件。
【例2-30】文件的写入。
import csv
content=[['0','hanmei','23','81'],
['1','mayi','18','99'],
['2','jack','21','89']]
f=open("test.csv","w",newline='')
#如果不加newline="",就会出现空行
content_out=csv.writer(f) #生成writer对象存储器
for con in content:
content_out.writerow(con)
f.close()2.关闭文件
【例2-31】跳过文件的注释内容和缺失值。
def skip_header(f):
line=f.readline()
while line.startswith('#')
line=f.readline()
return line
def process_file(f)
#调用函数使其跳过文件头部
line=skip_header(f).strip()
print(line) #打印第一行有用数据
for line in f:
if line.startswith("-")or line.startswith("#"): #处理缺失值
line=line.strip()
print(line)
input_file=open("泰戈尔的诗a.txt",'r')
process_file(input_file)
input_file.close()2.5本章小结
本章主要介绍了Python编程基础,主要包括Python的基本用法、内置数据类型。函数以及文件操作。
2.6本章习题
略
2.7本章实训
略