零基础入门NLP之新闻文本分类_Task2
零基础入门NLP之新闻文本分类_Task2
Taks2中要完成的主要是对新闻数据的分布规律进行探索和了解。这里主要是对代码进行了复现与详解。
1.导入第三方模块
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from collections import Counter # python中自带的计数器
2.读取训练集,这里我导入了全量训练集
train_df = pd.read_csv(r'D:\Users\Felixteng\Documents\Pycharm Files\Nlp\data\train_set.csv', sep='\t')
train_df.head()
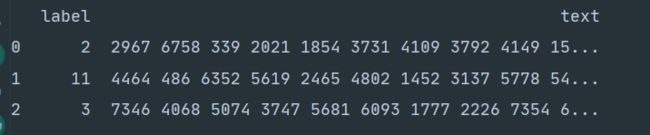
可以发现,数据主要由’text’和’label’两个部分构成。text由空格隔开。
3.句子长度分析
'''
数据中每行句子的字符使用空格进行隔开,所以可以直接统计单次的个数来得到每个句子的长度
%pylab inline 是jupyternotebook中用于调试的的魔法函数,pycharm中用回plt.show()即可
'''
train_df['text_len'] = train_df['text'].apply(lambda x: len(x.split(' '))) # text数据按空格分割后计数
print(train_df['text_len'].describe()) # 对每个句子的长度做统计性描述
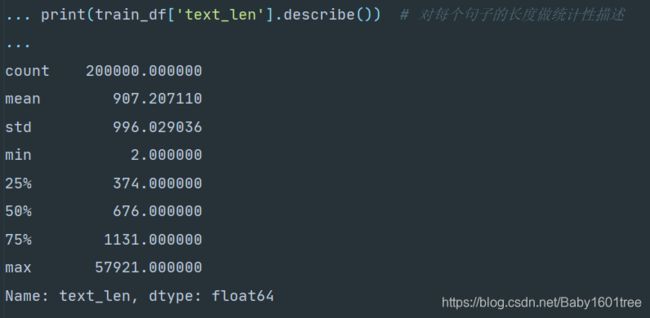
可以看出,数据文本较长,每个句子平均由907个字符构成,最短的句子长度为2,最长的句子长度为57921。
4.以句子长度绘制直方图
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
sns.distplot(train_df['text_len'], axlabel='Text char count', kde=False, bins=200)
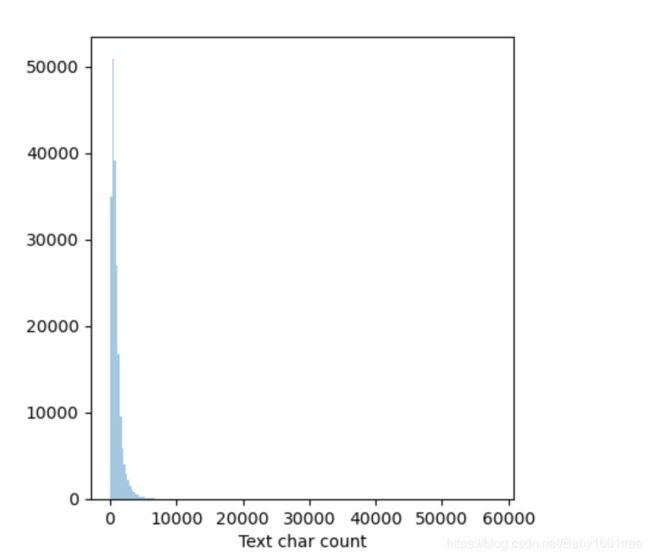
5.针对数据集的类别进行分布统计,具体统计每类新闻的样本个数
train_df['label'].value_counts().plot(kind='bar')
plt.xlabel('category')
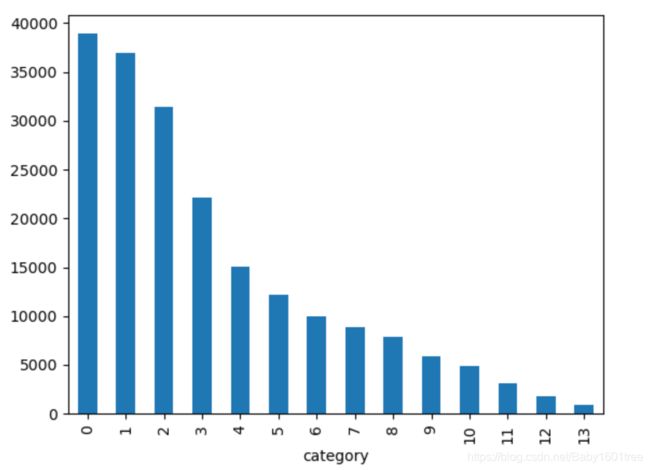
可以看出,数据集类别分布不均匀,训练集中科技类新闻最多(近4W),其次是股票类新闻,最少是星座类新闻(不到1K)
数据集中标签的对应关系如下
{‘科技’: 0, ‘股票’: 1, ‘体育’: 2, ‘娱乐’: 3, ‘时政’: 4, ‘社会’: 5, ‘教育’: 6,
‘财经’: 7, ‘家具’: 8, ‘游戏’: 9, ‘房产’: 10, ‘时尚’: 11, ‘彩票’: 12, ‘星座’: 13}
6.字符分布统计,统计每个字符出现的次数
# all_lines = ' '.join(list(train_df['text'])) # 将所有text用空格连接起来
# word_count = Counter(all_lines.split(" "))
# word_count = sorted(word_count.items(), key=lambda d: d[1], reverse=True)
因为电脑原因,我这里报了内存不足的错误:MemoryError.加大了pycharm的运行内存还是没能解决。
7.反推标点符号
train_df['text_unique'] = train_df['text'].apply(lambda x: ' '.join(list(set(x.split(' ')))))
'''
set()函数表示创建一个集合,特点是集合内不会有重复的元素
text_unique可以理解成一句话中所有不重复的字符用空格连接而成的单元句子
'''
all_lines = ' '.join(list(train_df['text_unique'])) # 这里把所有去重后的句子用空格连接
word_count = Counter(all_lines.split(' ')) # 去重以后不报内存不足的错误了
'''
Counter()函数返回的是一个字典,包括了元素及其出现的次数
'''
word_count = sorted(word_count.items(), key=lambda d: int(d[1]), reverse=True)
'''
sorted(iterable, key, reverse)
iterable:可迭代对象;
key:主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,
指定可迭代对象中的一个元素进行排序,这里取字典中的第二个元素,也就是出现次数来进行排序;
reverse:排序规则,True-降序/False-升序(默认)
'''
print(word_count[0])
print(word_count[1])
print(word_count[2])
print(word_count[3])
发现字符3750,900,648覆盖率很高,很有可能是标点符号。
8.统计每类新闻中出现次数最多的字符,先根据label将数据集分类,创建一个分类标签的函数
def select_label(df, num):
df_num = df[df['label'] == num]
return df_num
以统计科技类新闻出现次数最多的字符为例
df_0 = select_label(train_df, 0)
all_lines_0 = ' '.join(list(df_0['text']))
word_count_0 = Counter(all_lines_0.split(' '))
word_count_0 = sorted(word_count_0.items(), key=lambda d: d[1], reverse=True)
print(word_count_0[0])
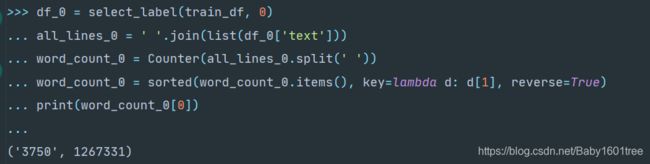
可以知道科技类出现最多的字符是3750。
如果一个个遍历觉得麻烦,可以创建一个函数,将数据按标签分类后使用lambda遍历
def top_count(x):
all_lines = ' '.join(list(x))
word_count = Counter(all_lines.split(' '))
word_count = sorted(word_count.items(), key=lambda d: int(d[1]), reverse=True)
return word_count[0]
这次任务主要是探索新闻文本数据,为下一次使用机器学习文本分类任务打下基础。